隨著輸入長度的增加,大型語言模型(LLMs)中的鍵值(KV)緩存需要存儲更多的上下文信息以維持性能,這導致內存消耗和計算時間急劇上升。KV緩存的增長對內存和時間效率的挑戰主要表現在兩個方面:一是在處理長文本時,模型需要更多的內存資源來存儲KV緩存,這不僅增加了硬件成本,還可能因內存限制而影響模型規模的擴展;二是在生成文本時,模型需要對KV緩存中的每個鍵值對進行注意力計算,隨著緩存的增大,這個過程變得更加耗時,從而降低了模型的解碼速度。
在深入分析大型語言模型(LLMs)的注意力機制時,研究者發現了一些關鍵模式,這些模式對于優化KV緩存至關重要。某些鍵在令牌生成期間始終吸引著模型的注意力,無論上下文的長度如何,這些“活躍”的鍵展現出穩定的高注意力權重。在長摘要和問答任務中,問題的位置(無論是在提示的開頭還是結尾)對模型的注意力分配模式影響不大,顯示出模型在處理長文本時的魯棒性。研究者還發現注意力模式高度依賴于上下文,與用戶的具體指令密切相關,這意味著不同的指令會引導模型關注不同的信息。
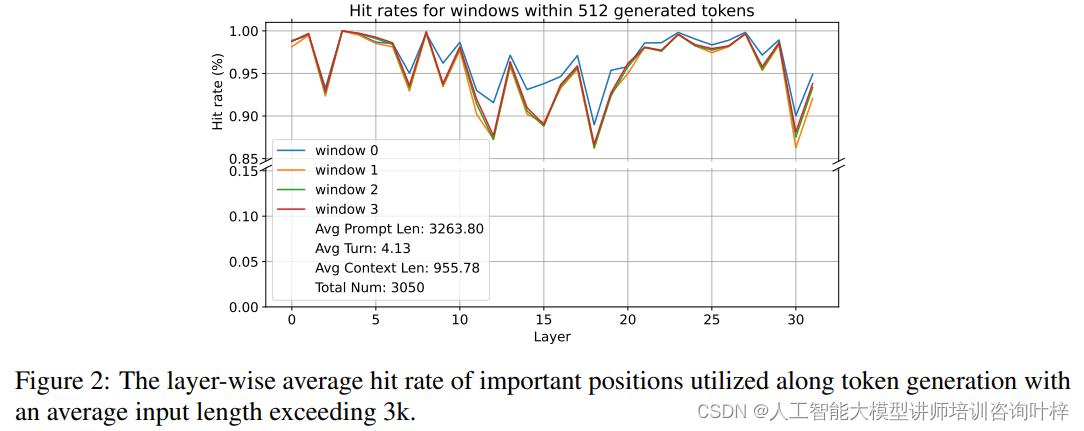
這些觀察結果促成了SnapKV的開發,它是一種創新的KV緩存壓縮方法。SnapKV的創新之處在于它提出了一種無需微調的壓縮方法,通過觀察模型在生成過程中的注意力分配模式,自動識別并壓縮KV緩存中的關鍵信息。SnapKV通過“投票”機制選出每個注意力頭關注的關鍵KV位置,并通過聚類算法保留這些關鍵特征周圍的信息,從而在不犧牲準確性的前提下顯著減少KV緩存的大小。這種方法不僅減少了計算開銷,還提高了內存效率,使得模型在處理長文本時更為高效。SnapKV在解碼速度上實現了3.6倍的提升,在內存效率上實現了8.2倍的提升,同時在多個長序列數據集上保持了與基線模型相當的性能。SnapKV還能夠與現有的深度學習框架輕松集成,僅需少量代碼調整,為長文本處理提供了一種實用的解決方案。
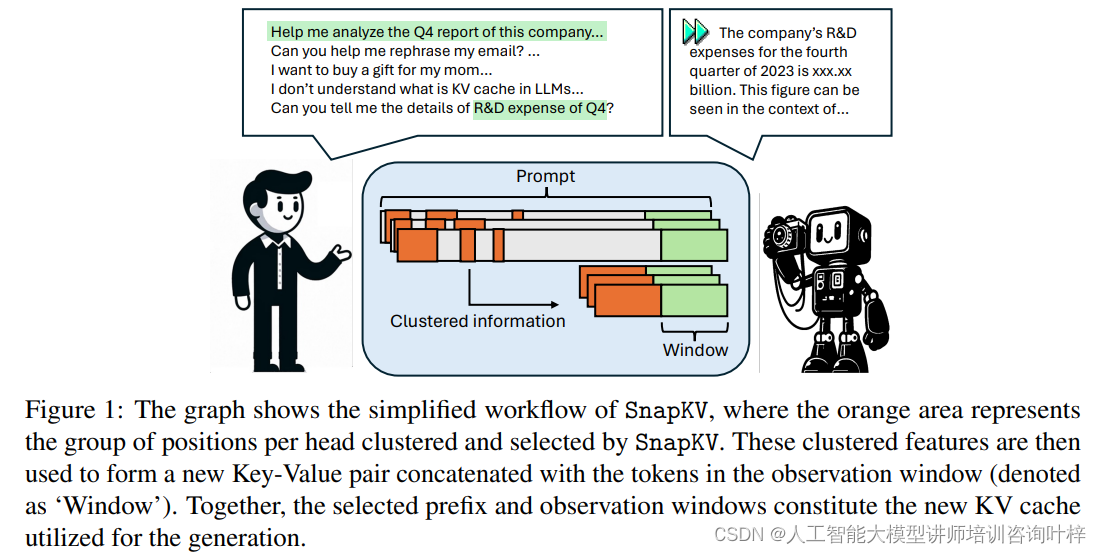
SnapKV 的核心思想是在生成過程中保持提示(prompt)的 KV 緩存數量恒定,從而顯著減少長上下文 LLMs 的服務時間。這是通過識別和選擇每個注意力頭(attention head)最關鍵的注意力特征(attention features)來實現的,以此創建一個新的、更小的 KV 緩存。
實現步驟
SnapKV 的實現分為兩個主要階段:
-
投票選擇重要特征(Voting for Important Previous Features):
- 利用定義好的投票過程(如公式1所示),基于觀察窗口(observation window)——即提示的最后部分——來選擇重要的特征。
- 通過分析發現,這些特征在整個序列生成過程中表現出顯著的一致性,表明它們對后續生成至關重要。
- 此外,實施聚類算法以保留選定特征周圍的特征,這有助于保留信息的完整性并避免丟失上下文。
-
更新和存儲截斷的鍵和值(Update and Store Truncated Key and Value):
- 將選定的特征與觀察窗口的特征連接起來,這些特征包含了所有提示信息。
- 將連接后的 KV 緩存存儲起來,以供后續生成使用,同時節省內存使用。
代碼示例
def snap_kv(query_states, key_states, value_states, window_size, max_capacity_prompt, kernel_size):bsz, num_heads, q_len, head_dim = query_states.shape# 確保當前是處理提示階段assert key_states.shape[-2] == query_states.shape[-2]if q_len < max_capacity_prompt:return key_states, value_stateselse:# 計算觀察窗口的查詢和前綴上下文的鍵的注意力權重attn_weights = compute_attn(query_states[..., -window_size:, :], key_states, attention_mask)# 沿著查詢維度對權重求和attn_weights_sum = attn_weights[..., -window_size:, :-window_size].sum(dim=-2)# 應用1D池化進行聚類attn_cache = pool1d(attn_weights_sum, kernel_size=kernel_size, padding=kernel_size // 2, stride=1)# 基于池化后的權重選擇每個頭的top-k索引,以識別重要位置indices = attn_cache.topk(max_capacity_prompt - window_size, dim=-1).indices# 擴展索引以匹配頭維度進行聚集indices = indices.unsqueeze(-1).expand(-1, -1, -1, head_dim)# 根據選定的索引聚集壓縮的過去鍵和值狀態k_past_compress = key_states[..., :-window_size, :].gather(dim=2, index=indices)v_past_compress = value_states[..., :-window_size, :].gather(dim=2, index=indices)k_obs = key_states[..., -window_size:, :]v_obs = value_states[..., -window_size:, :]# 將壓縮后的過去鍵和觀察窗口的鍵拼接在一起key_states = torch.cat([k_past_compress, k_obs], dim=2)# 將壓縮后的過去值和觀察窗口的值拼接在一起value_states = torch.cat([v_past_compress, v_obs], dim=2)return key_states, value_statessnap_kv?函數接受查詢狀態?query_states、鍵狀態?key_states、值狀態?value_states,以及其他參數如窗口大小?window_size、最大提示容量?max_capacity_prompt?和池化核大小?kernel_size。- 首先,檢查是否處于處理提示的階段,如果不是,則直接返回原始的鍵和值狀態。
- 然后,計算觀察窗口內查詢和前綴上下文鍵之間的注意力權重?
attn_weights。 - 對這些權重進行求和?
attn_weights_sum,然后應用一維池化?pool1d?來聚類,以便選擇重要的特征。 - 使用?
topk?方法根據池化后的權重選擇每個頭的重要位置?indices。 - 根據這些索引聚集壓縮后的鍵和值狀態?
k_past_compress?和?v_past_compress。 - 最后,將壓縮的鍵和值狀態與觀察窗口的鍵和值狀態拼接起來,形成新的鍵和值狀態,這些狀態將用于后續的生成過程。
SnapKV方法論包含兩個主要階段:首先是通過一個稱為“投票”的過程來識別重要的先前特征,其次是更新并存儲截斷的鍵和值。
在第一階段,SnapKV利用了一個觀察窗口,這個窗口位于提示的末端,它的作用是捕捉模型在生成過程中所關注的關鍵特征。通過計算觀察窗口中每個查詢的注意力權重,并在所有注意力頭上聚合這些權重,SnapKV能夠突出顯示被認為是最重要的前綴位置。這個過程稱為投票,它幫助系統識別出那些在生成文本時需要特別關注的KV位置。
第二階段中,SnapKV將這些選出的重要特征與觀察窗口中的特征結合起來,形成一個新的鍵值對。這個新的鍵值對隨后被用于生成過程,同時通過僅保留這些關鍵特征,系統能夠顯著減少所需的內存和計算資源。此外,為了保持信息的完整性并避免因過度壓縮而導致的細節丟失,SnapKV采用了一種基于池化的聚類算法。這個算法通過池化層對信息進行細粒度的壓縮,確保了在壓縮KV緩存的同時,依然能夠保留足夠的上下文信息,從而維持模型的準確性。
SnapKV的實現是高效的,因為它只需要對現有的深度學習框架進行少量的代碼調整。這意味著它可以輕松地集成到現有的系統中,而無需進行大規模的重構。在實驗中,SnapKV顯示出了卓越的性能,它不僅在解碼速度上實現了顯著的提升,還在內存效率上達到了大幅度的增強。這些改進使得SnapKV成為一個在處理長文本方面極具潛力的解決方案,特別是在需要處理大量輸入序列的應用場景中,如聊天機器人、代理服務、文檔處理等。SnapKV通過其創新的方法論,為長文本處理中的內存和時間效率問題提供了一個有效的解決方案。
在對SnapKV進行的實驗中,研究團隊采取了一系列嚴謹的測試,旨在評估該方法在不同模型和長文本數據集上的性能。實驗的目的是驗證SnapKV在減少計算和內存負擔的同時,是否能夠保持或甚至提升模型的生成質量和效率。
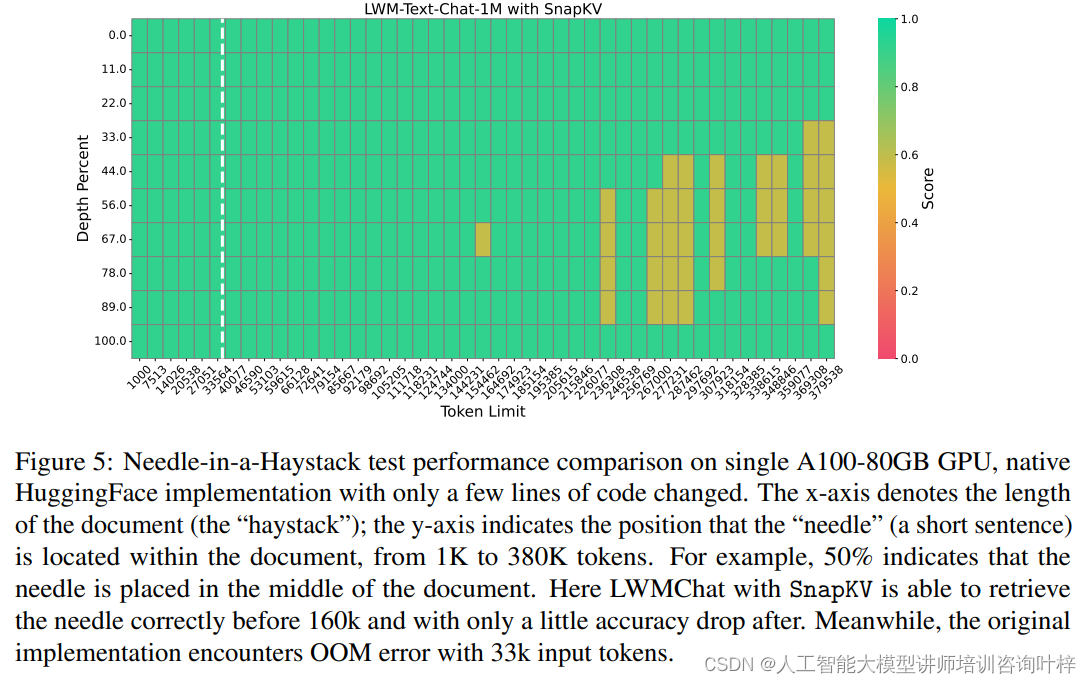
實驗首先在LWM-Text-Chat-1M模型上進行了壓力測試,這是當時最先進的模型之一,能夠處理長達一百萬個令牌的上下文。測試中,SnapKV展現了其算法效率,特別是在硬件優化方面。通過“Needle-in-a-Haystack”測試,即在長達380K令牌的文檔中準確檢索特定句子的能力,SnapKV證明了其在極端條件下處理長文本的能力,即便在極高的壓縮比下也能保持精確性。
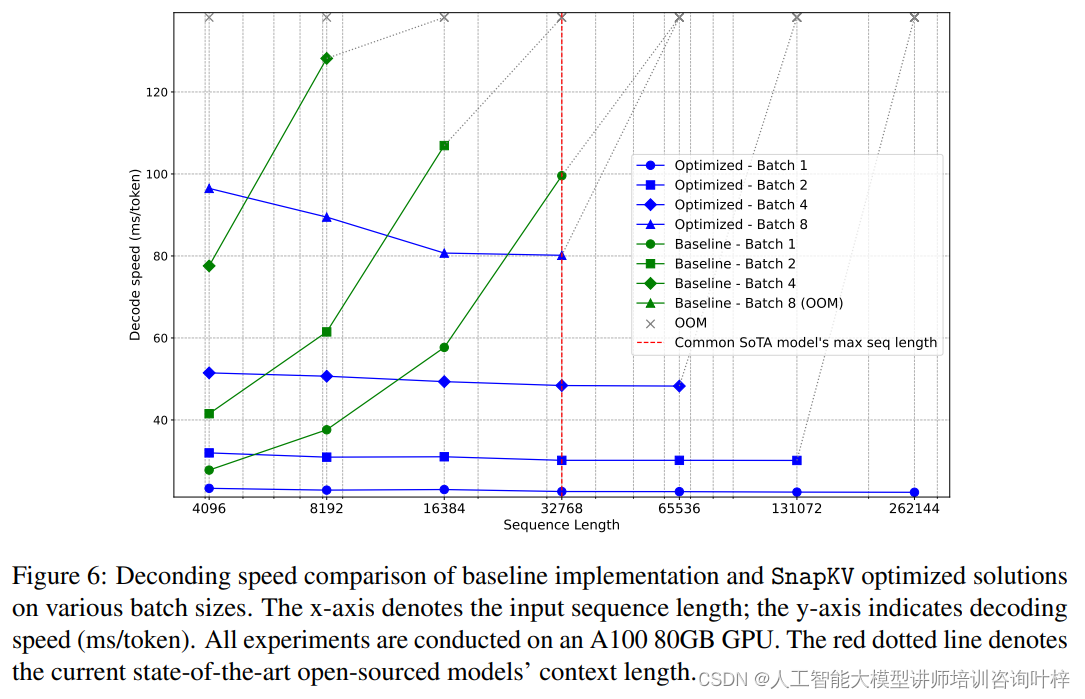
實驗通過不同的批處理大小對LWM-Text-Chat-1M模型進行了解碼速度和內存限制的基準測試。結果表明,SnapKV優化的模型在解碼速度上保持了穩定,與輸入序列長度的增加無關,這與基線實現形成了鮮明對比,后者的解碼速度隨輸入長度的增加而指數級增長。SnapKV顯著提高了模型處理長序列的能力,顯著減少了內存消耗。
為了進一步驗證SnapKV的有效性,研究團隊還對Mistral-7B-Instruct-v0.2模型進行了消融研究,以理解池化技術對模型信息檢索性能的影響。消融研究結果表明,通過池化增強了檢索準確性,這可能是因為強大的注意力機制傾向于關注令牌序列的初始部分。
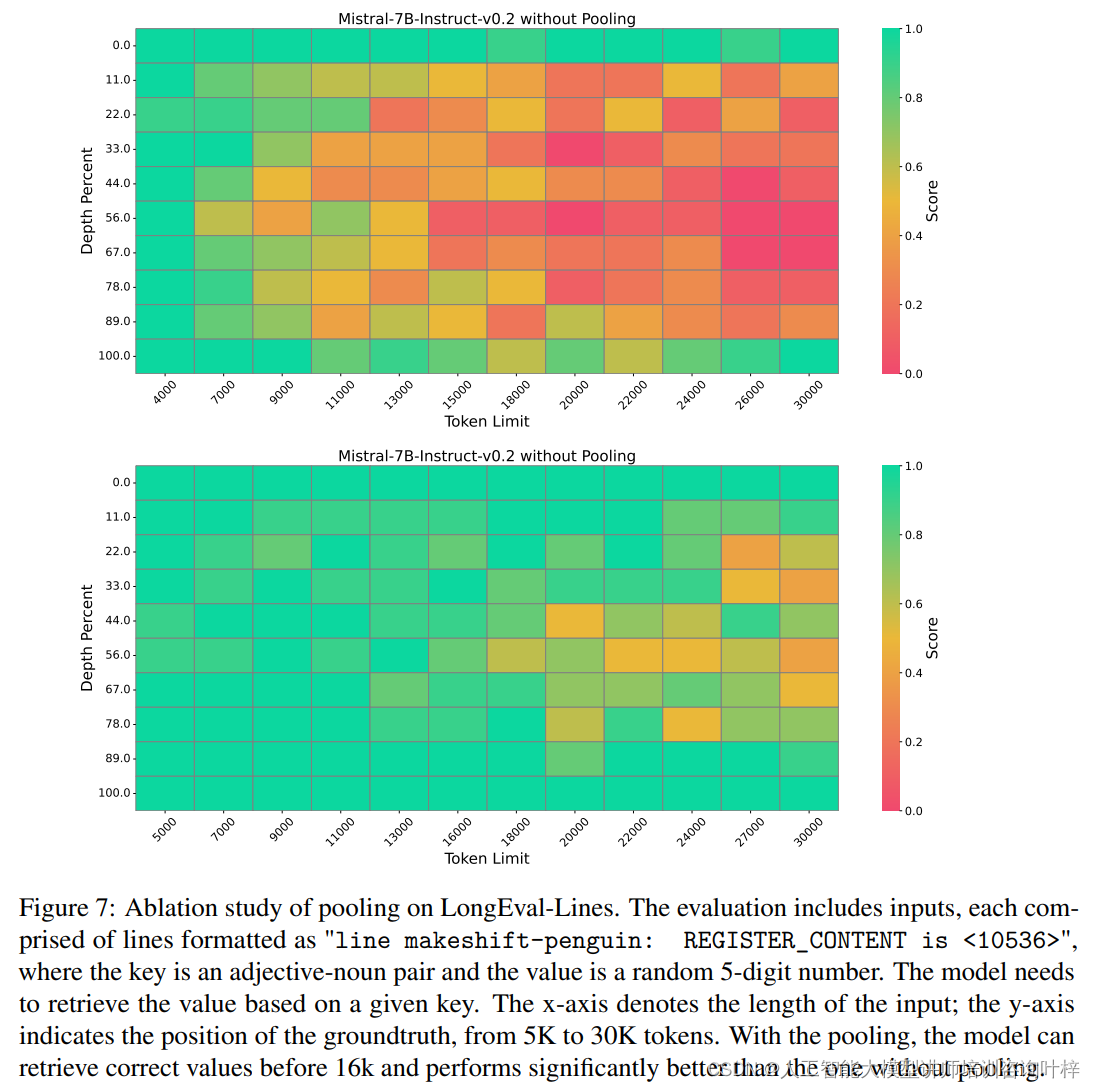
最后,實驗使用了LongBench,這是一個多任務基準測試,旨在全面評估長文本理解能力。SnapKV在多個不同設置下進行了測試,包括壓縮KV緩存到1024、2048和4096個令牌,并使用最大池化和觀察窗口。測試結果顯示,即使在壓縮率高達92%的情況下,SnapKV與原始實現相比,在16個不同數據集上的性能下降可以忽略不計,某些情況下甚至超過了基線模型。
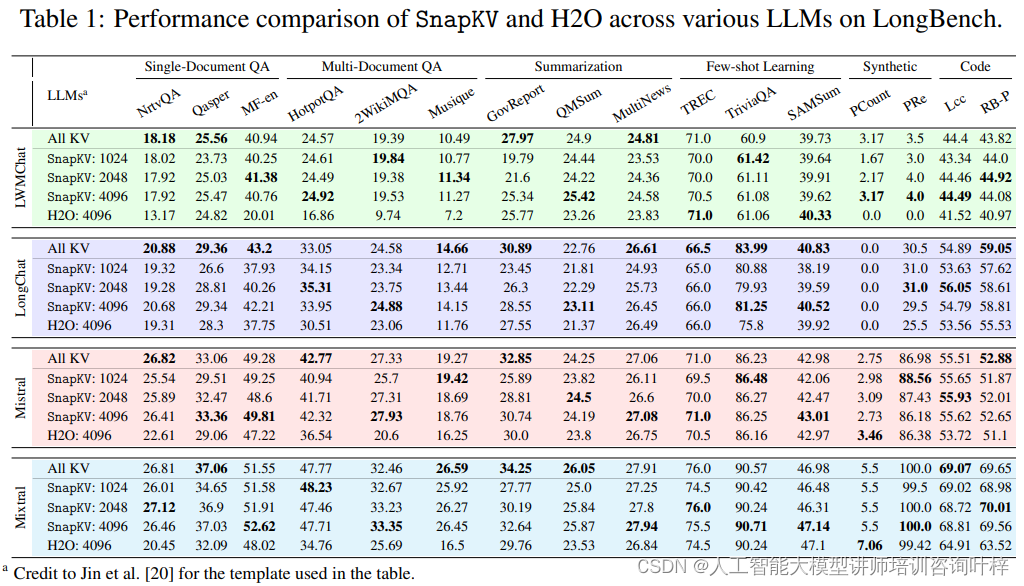
實驗結果,SnapKV證明了其作為一種有效的KV緩存壓縮方法,在保持大型語言模型處理長文本的能力的同時,顯著提升了效率和減少了資源消耗。這些發現不僅證實了SnapKV的實用性,還為未來的研究和應用提供了有價值的見解。
SnapKV代碼可在https://github.com/FasterDecoding/SnapKV上找到
論文鏈接:https://arxiv.org/abs/2404.14469


有哪些鉤子可以用)



【三、MQ的核心類-消息類的存儲(用文件存儲消息)】? ★)
)


-附代碼)
)

useEffect、useRef、useImperativeHandle、useLayoutEffect)
)


)

