文章目錄
- 一、類的內存對齊
- 1.1規則
- 1.2原因
- 二、位段
- 2.1介紹
- 2.2內存分配問題
- 2.3跨平臺問題
- 2.4使用的注意事項
- 三、位圖的應用
- 3.1 給40億個不重復的無符號整數,找給定的一個數。(int的范圍可以到達42億多)
- 3.2 給定100億個整數,設計算法找到只出現一次的整數
- 3.3給兩個文件,分別有100億個整數,我們只有1G的內存,如何找到兩個文件的交集
- 3.4位圖應用變形:1個文件有100億個int,1G內存,設計算法找到出現次數不超過兩次的所有整數
- 四、布隆過濾器
- 4.1作用和介紹
- 4.2誤判的概率與什么有關?
- 4.3布隆過濾器的實現
- 五、哈希切割
- 5.1給一個超過100G大小的log ?le, log中存著IP地址, 設計算法找到出現次數最多的IP地址?
- 5.2給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件交集?
- 六、一致性哈希

一、類的內存對齊
1.1規則
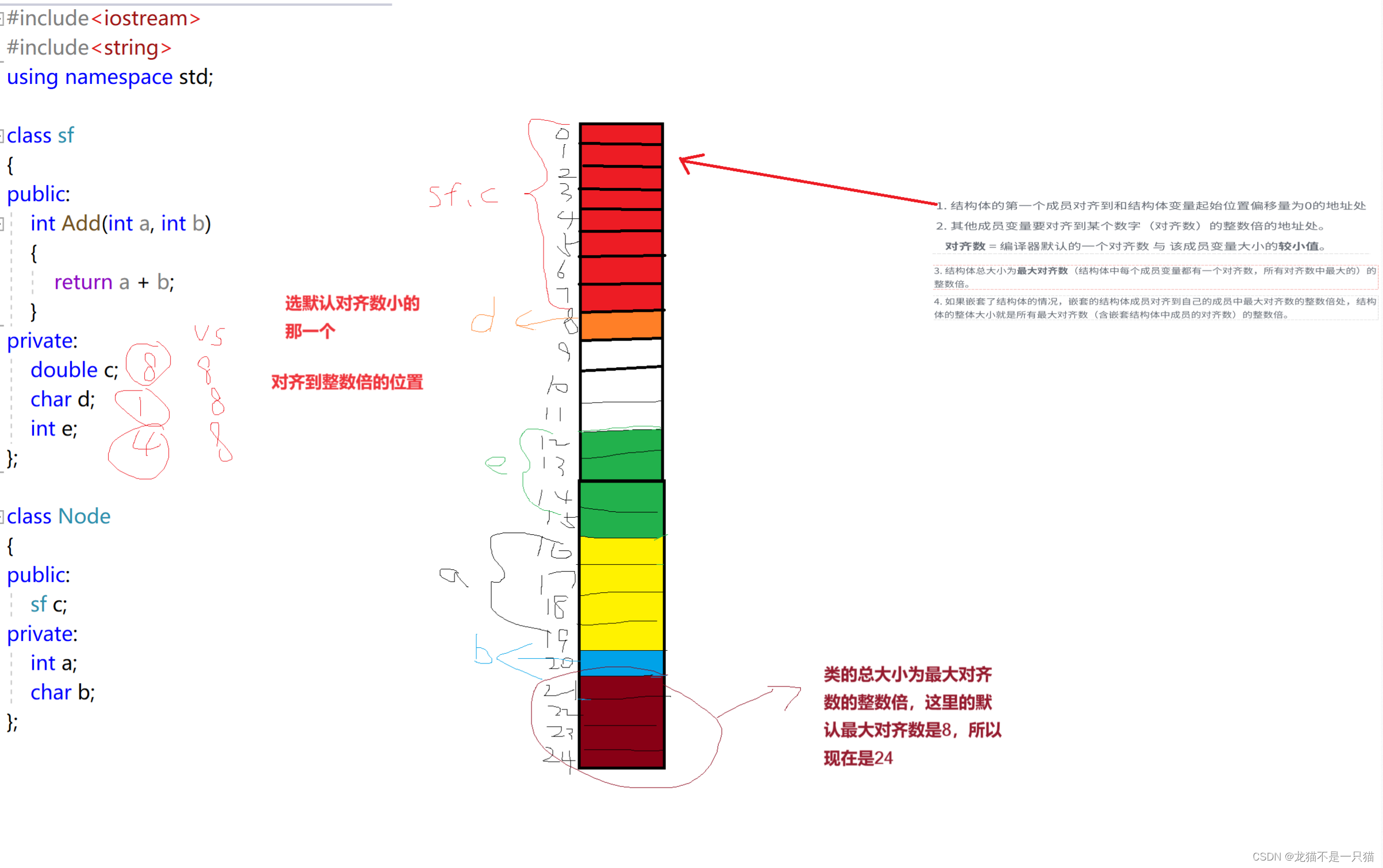
1.類的第一個成員對齊到和類的起始位置偏移量為0的地址處
2.其他成員變量要對齊到某個數字(對齊數)的整數倍的地址處
對齊數 = 編譯器默認的一個對齊數與該成員變量的大小的較小值
——VS中默認對齊數為8
——Linux中gcc沒有默認對齊數,對齊數就是成員自身的大小
3.類的總大小為最大對齊數(類中每個成員變量都有一個對齊數,所有對齊數中最大的)的整數倍。
4.如果出現類的嵌套,嵌套的類的成員對齊到自己的成員中最大對齊數的整數倍處
offsetof(type,成員)計算偏移量

1.2原因
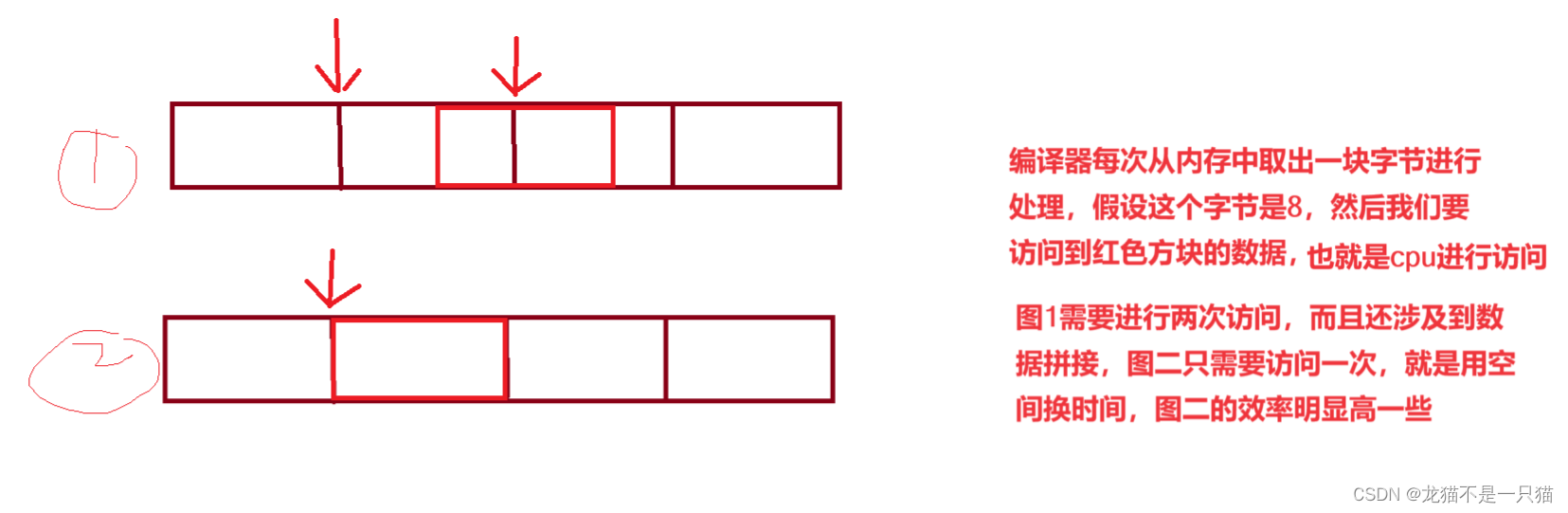
1.不是所有的硬件平臺都能訪問任意地址上的任意數據的;某些硬件平臺只能在某些地址處取某些特定類型的數據,否則拋出硬件異常
2.數據結構(尤其是棧)應該盡可能的在邊界對齊。因為為了訪問未對齊的內存,編譯器需要進行兩次訪問,對齊了的內存,編譯器只需要進行一次訪問。
二、位段
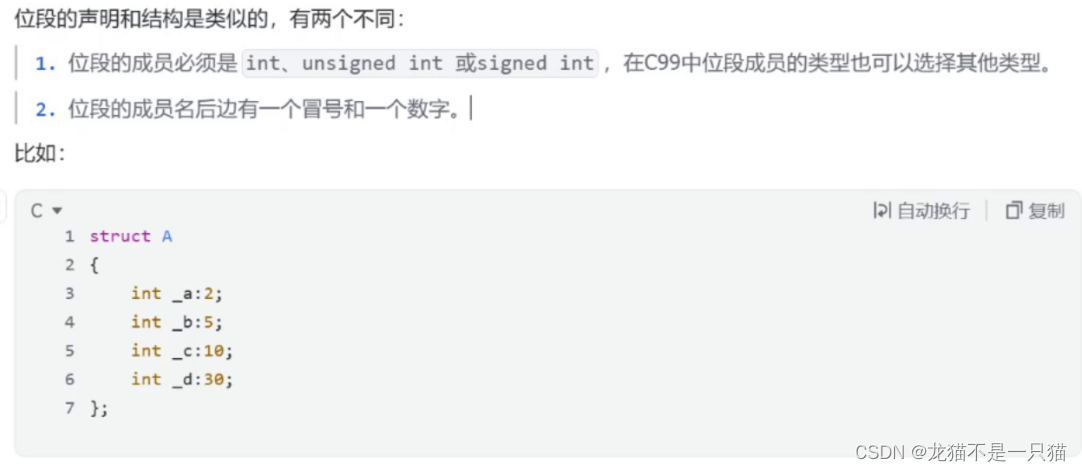
2.1介紹
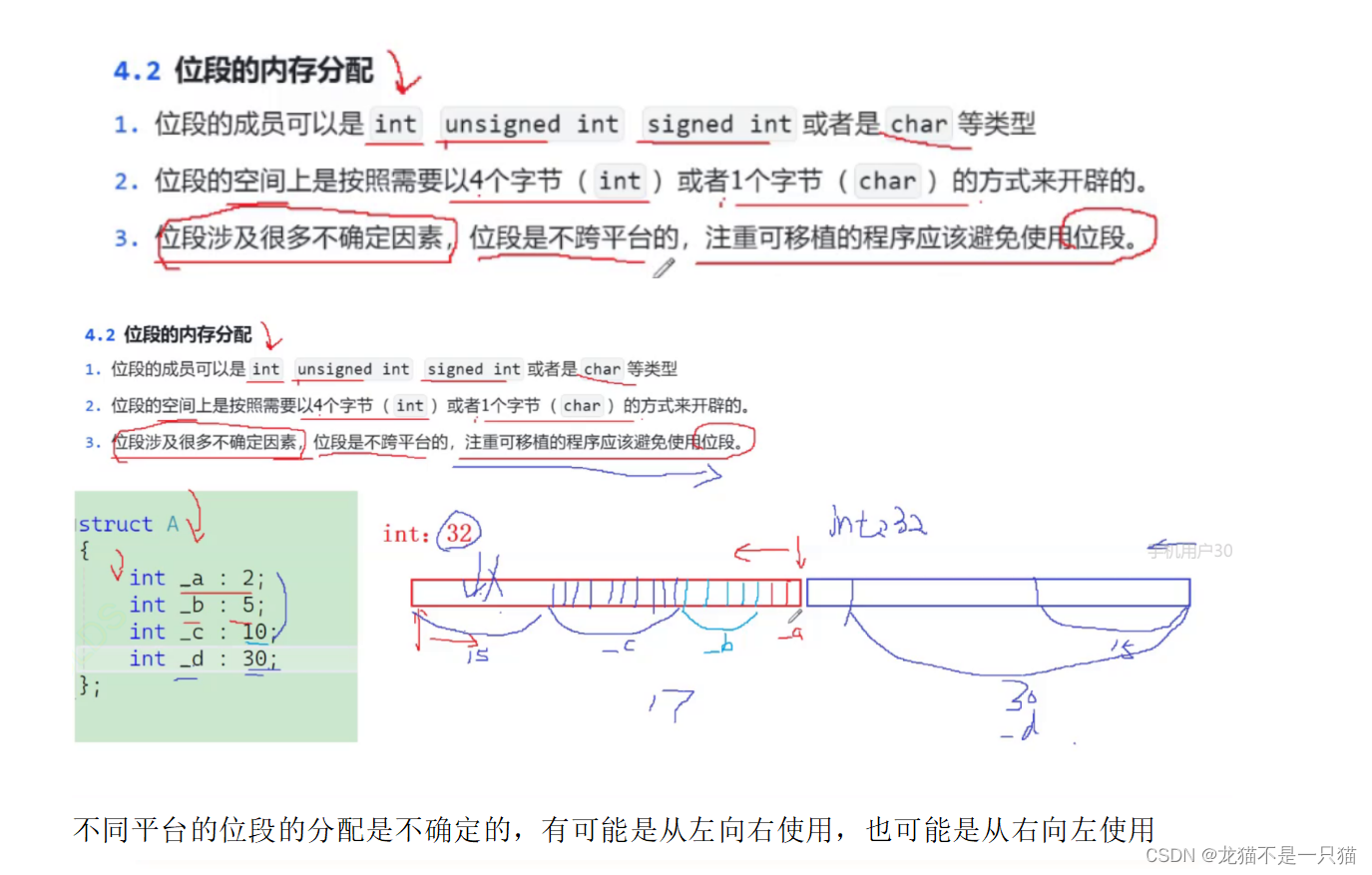
2.2內存分配問題
2.3跨平臺問題

2.4使用的注意事項

三、位圖的應用
3.1 給40億個不重復的無符號整數,找給定的一個數。(int的范圍可以到達42億多)
方法1(不可取):用二分的方法,80億個字節大概需要7.4個G,沒有那么大的存儲空間,雖然二分的查找效率很高,但是需要數據處于有序的狀態
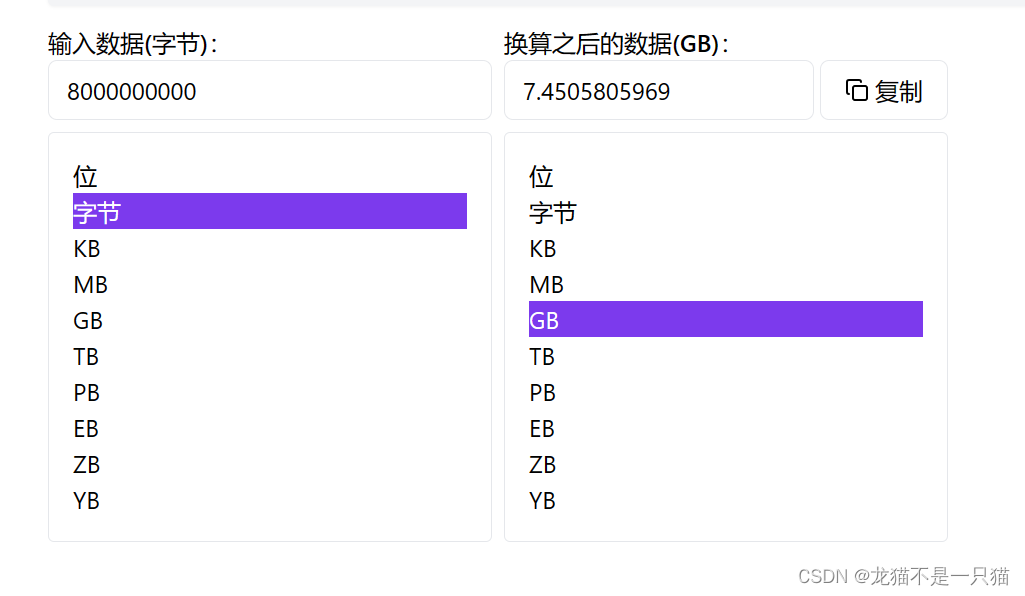
方法2:位圖
我們利用哈希桶的原理,用每一個數映射一個比特位,大概42億個比特位,加起來應該是0.5個G左右,這樣消耗的內存低,并且每一個數映射一個比特位,又保證了查找效率O(1)
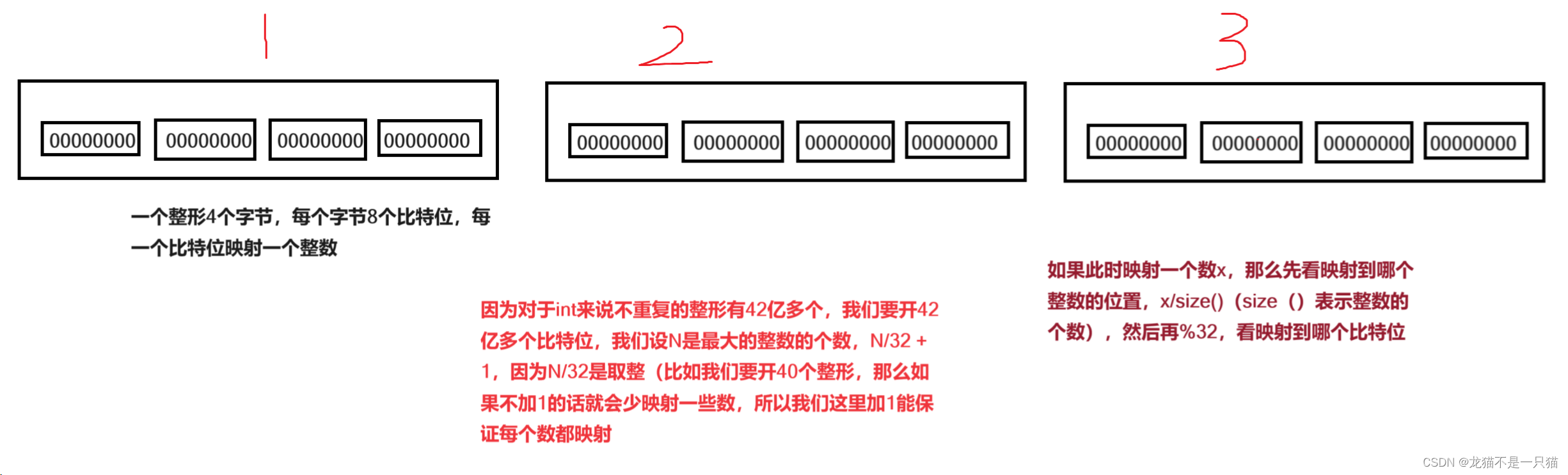
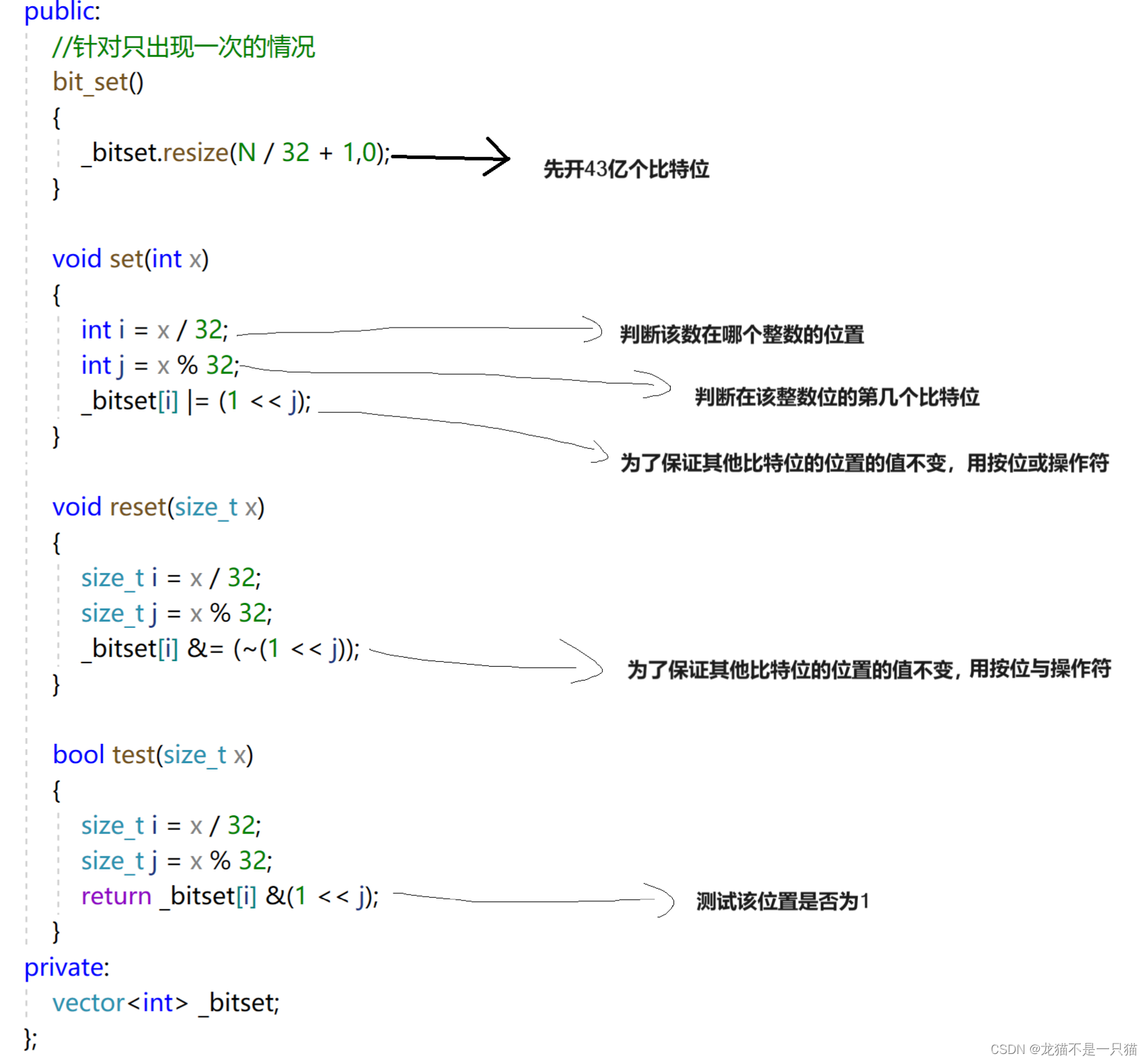
3.2 給定100億個整數,設計算法找到只出現一次的整數
用兩個位圖來表示這個整數出現的次數

3.3給兩個文件,分別有100億個整數,我們只有1G的內存,如何找到兩個文件的交集
同上
3.4位圖應用變形:1個文件有100億個int,1G內存,設計算法找到出現次數不超過兩次的所有整數
同上
四、布隆過濾器
4.1作用和介紹
作用:可以提高測試數據在該數據庫中是否存在,如果有上千百億的數據都從數據庫中尋找的話,那么效率就會非常非常低,用了布隆過濾器之后,可以排除掉一部分不在數據庫里面的數據。
介紹:布隆過濾器就是一個字符串映射多個位,這個可以大大減少誤判的可能性,一個字符串映射多個位可以降低誤判的可能性,但是此時的空間效率就降低了,布隆過濾器的實質目的就是為了提高空間效率,這樣得不償失,我們只能根據適用情況判斷到底映射幾個位
4.2誤判的概率與什么有關?
1.與映射的哈希函數的個數有關
2.與映射的位有關
3.與哈希函數的特性有關
4.3布隆過濾器的實現
用三種不同的哈希函數進行實現,一共映射3個比特位

五、哈希切割
5.1給一個超過100G大小的log ?le, log中存著IP地址, 設計算法找到出現次數最多的IP地址?
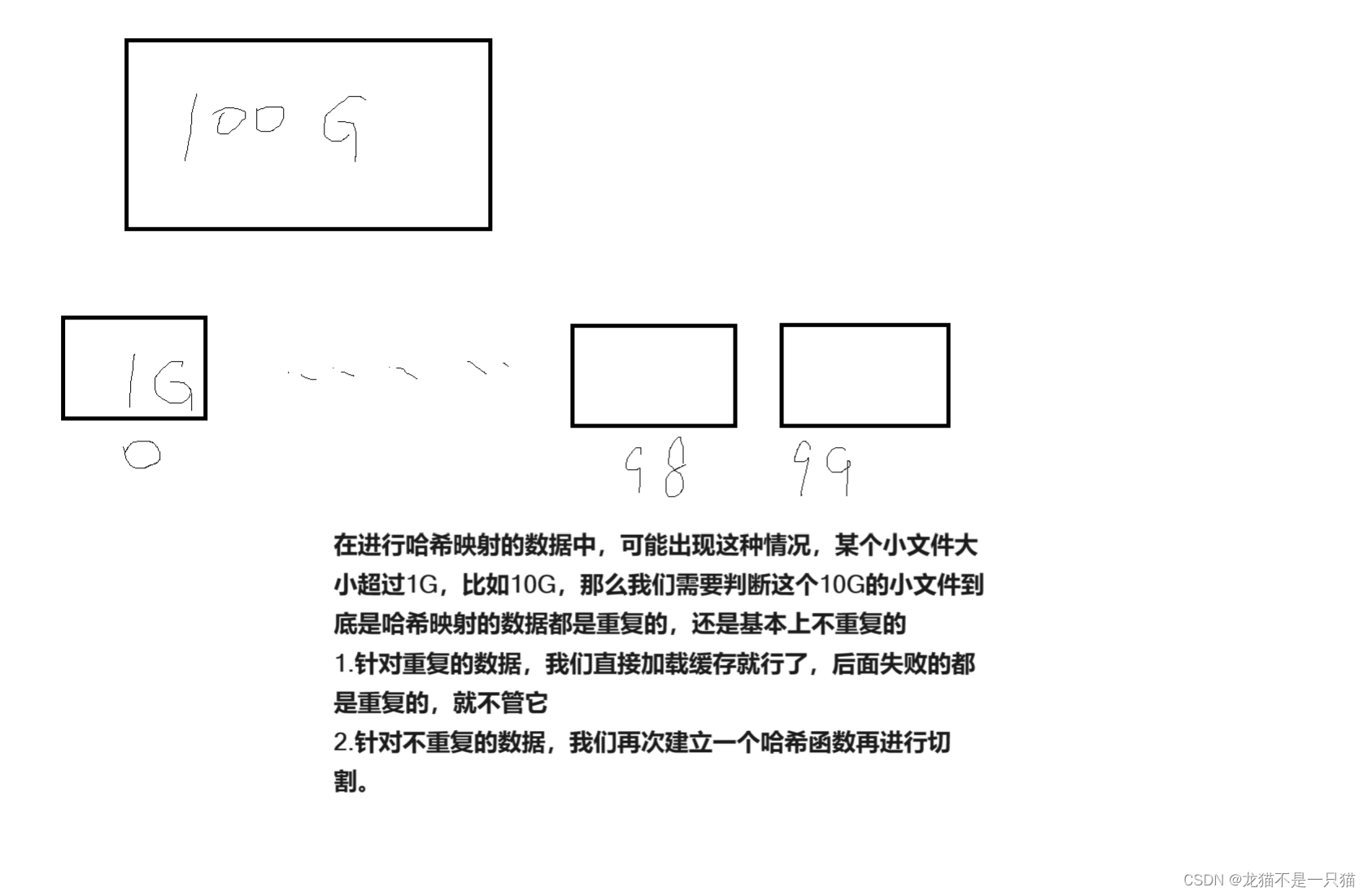
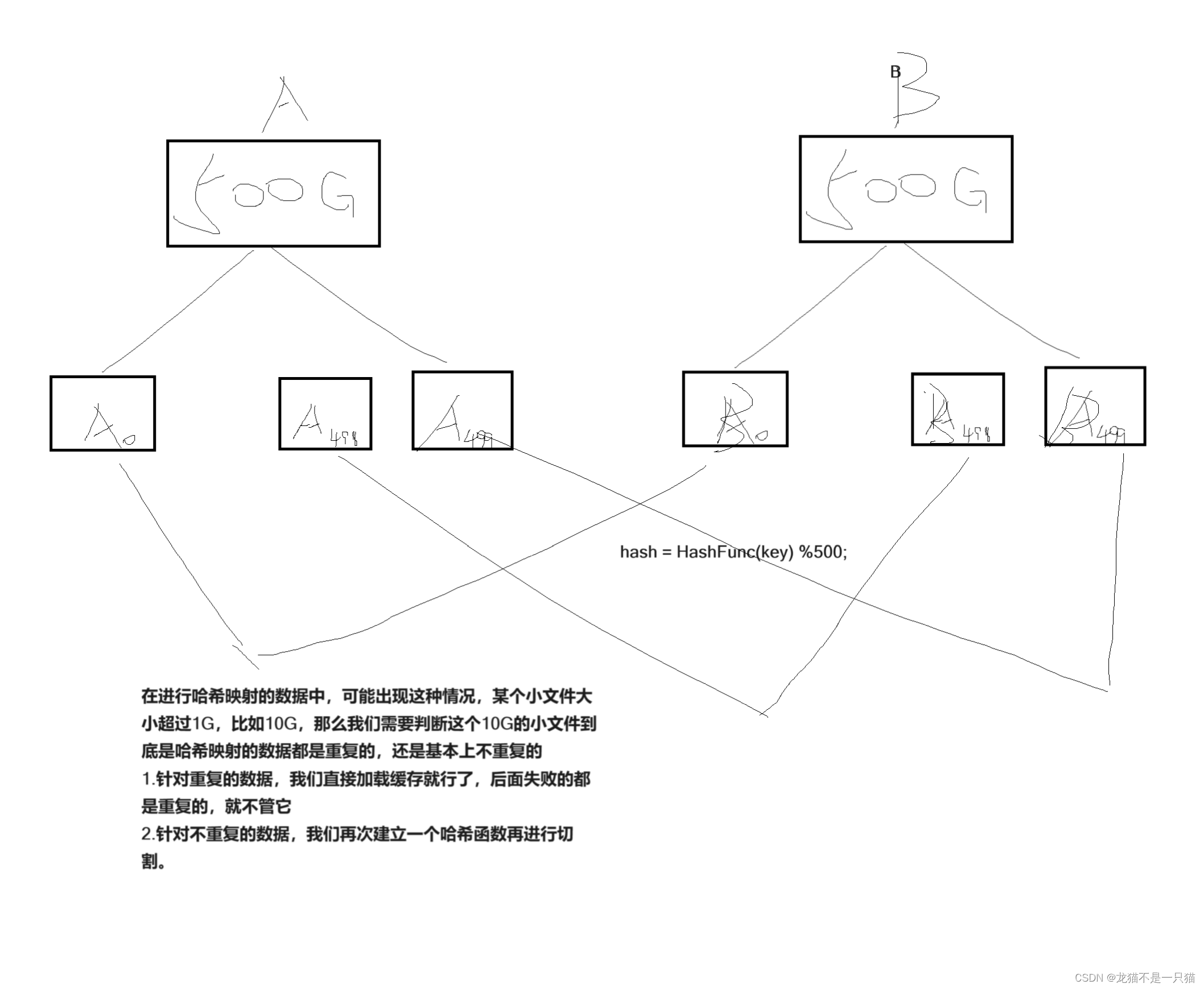
5.2給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件交集?
六、一致性哈希
下面這篇別人講的文章非常詳細,可參考
一致性哈希的文章



)



)





閱讀筆記)


—— 類與對象(二))



(100分))