一、if的條件判斷
1-1 if elif else
-
判斷年齡屬于哪個年齡段
# 判斷學生
core = input('請輸入成績')
?
if int(core) >=90 :print('優秀')
elif int(core) >=70 and int(core) <90:print('中等')
elif int(core) >=60 and int(core) <70:print('及格')
else:print('不及格')?
時間段, 成績的劃分,星座判斷
1-2 if 嵌套
if 判斷條件1:if 判斷條件2:if 判斷條件3:else:第3個條件不成時執行else:第2個條件不成時執行 else:第1個條件不成時執行
可以控制判斷的執行順序,進行多次判斷
# if嵌套使用
name = input('請輸入用戶名:')
password = input('請輸入密碼:')
# 先判斷用戶名是否正確
if name == '張三':# 在判斷密碼是否正確if password=='123456':print('登錄成功')
?else:print('密碼不正確')
else:print('用戶名不正確')
二、While循環
保證Python程序根據要求能持續運行
可以使用循環語句的語法實現循環運行,可以執行循環條件,當不滿足條件后退出循環
-
語法格式
-
循環的代碼邏輯要在下一行開始,開頭空四格
-
條件成立,循環中代碼邏輯會一直執行
-
while 數據判斷條件:編寫循環執行的業務邏輯修改退出條件數據
# while 一般用在需要程序持續運行時使用
a = 1
while a == 1:# 條件成立,會一直運行while內的代碼邏輯name = input('請輸入用戶名:')password = input('請輸入密碼:')# 先判斷用戶名是否正確if name == '張三':# 在判斷密碼是否正確if password == '123456':print('登錄成功')# 通過修改變量值,改變判斷條件不成立,此時就可以退出循環a = 2else:print('密碼不正確')else:print('用戶名不正確')
?
-
控制循環輸入次數不能超過三次
a = 1
while a <= 3:# 條件成立,會一直運行while內的代碼邏輯name = input('請輸入用戶名:')password = input('請輸入密碼:')# 先判斷用戶名是否正確if name == '張三':# 在判斷密碼是否正確if password == '123456':print('登錄成功')# 通過修改變量值,改變判斷條件不成立,此時就可以退出循環a = 6else:print('密碼不正確')else:print('用戶名不正確')
三、For循環
while 主要控制數據處理的次數
for 遍歷獲取數據(容器形式的數據)中每個元素數據,字符串,列表,字典,元祖,集合,range方法
for循環的次數是有容器內的元素個數決定
-
語法格式
for i(臨時變量,接收循環的元素數據) in 容器數據:對臨時變量中的數據進行操作
-
range的使用,可以根據指定數值生成范圍內的容器數據
-
range(10) 生成0-10范圍內的數據 起始從0開始
-
range(2,10) 生成的范圍是 2-10
-
生成的范圍數據是左閉右開 [0,10) 0可以取到值,10取不到值
-
# for循環 [0,5) for i in range(5):print(i) ? for i in range(2,5): # [2,5)print(i)
四、Break和Continue
break 跳出循環或結束循環
continue 跳過當前這一次循環,執行下次循環
可以對循環的數據進行判斷,如果符合條件可以進行跳出循環或跳過循環
-
break退出for循環
for num in range(3): # [0,3) 0,1,2name = input('請輸入用戶名:')password = input('請輸入密碼:')# 先判斷用戶名是否正確if name == '張三':# 在判斷密碼是否正確if password == '123456':print('登錄成功')# 使用break關鍵,會結束循環,不再進行取值breakelse:print('密碼不正確')else:print('用戶名不正確')
-
遍歷1-10數據,只對偶數數據輸出
for data in range(1,11):# 對data數據進行奇數判斷if data % 2 !=0:# 跳過continue# continue被執行,continue后面邏輯就不會被執行print(data)
五、容器類型介紹
容器就是存放數據的
python 中的容器數據有多種形式,每種形式有自己的存儲格式, 數據存儲特性不一樣
字符串 str 就是容器 存放一個一個字母 格式 : 單引號 '數據' ,雙引號 "數據" ,三個引號 """ 數據 """
列表 list 格式: [數據1,數據2,數據3.....]
元祖 tuple 格式: (數據1,數據2,數據3,)
集合 set 格式: {數據1,數據2,數據3,}
字典 dict 格式: {key1:value1,key2:value....}
數據存儲的特性
有序和無序
有序: 字符串,列表,元祖,字典
無序: 集合
數據重復性
允許數據重復 字符串,列表,元祖,字典的value部分可以重復
不允許重復 集合,字典的key值
數據是否允許修改
允許修改 列表,字典value數據可以修改,
不允許修改 字符串 ,元祖
常用的字符串,列表和字典
六、字符串
字符串就是有一個一個字母構成,使用引號包裹數據
data_str1 = '數據' data_str2 = "數據" data_str3 = '''數據'''
6-1 下標取值
在有序的容器中,會對數據的順序進行編號,該編號就稱為數據下標。可以通過下標取出對應位置中的數據
下標編號是從0開始
數據:i t c a s t
下標:0 1 2 3 4 5
-
字符串的下標取值
-
一次取出一個下標對應的數據
-
# 有序容器的下標取值 data_str = 'itcast' ? # 下標取一個值 print(data_str[2])
-
切片
-
指定下標范圍進行取值
-
[起始下標:結束下標] 下標的范圍是左閉右開的,結束下標的值取不到
-
# 有序容器的下標取值 data_str = 'itcast' ? # 下標取一個值 print(data_str[2]) ? # 下標取多個值 使用切片 [起始下標:結束下標] 取值范圍也是左閉右開 結束下標的數據無法取到 print(data_str[1:4]) ? ? ?
-
間隔步長取值
# 有序容器的下標取值 data_str = 'itcast' ? # 下標取一個值 print(data_str[2]) ? # 下標取多個值 使用切片 [起始下標:結束下標] 取值范圍也是左閉右開 結束下標的數據無法取到 print(data_str[1:4]) ? # 間隔取多個值 使用切片 [起始下標:結束下標:步長] print(data_str[1:6:2]) # 起始從1開始 下一個值是 1+2=3 ? 1+2+2=5
-
下標的其他操作
# 單個取值時超過下標值或報錯 print(data_str[6])
![]()
# 切片進行多個數據取值超出下標,不會報錯,將后面的數據全部取出 print(data_str[1:1000])
# 取值的下標可以是負數 print(data_str[-4:-2])
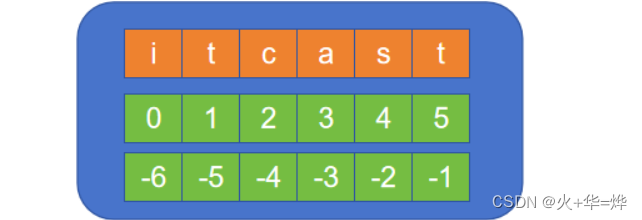
# 如果需要改變起始位置從右邊開始,則需要將步長設置為-1 # 可以實現字符串的反轉 print(data_str[-1:-7:-1]) # 需要獲取所有的的字符可以省略起始和結束下標 print(data_str[::-1])
6-2 for循環取值
依次從字符串中取出每一個字母,該過程叫做數據遍歷
# 遍歷字符串數據 data = 'itcast' for i in data:print(i)
6-3 函數方法
-
find 找字符在字符串中位置,返回對應的首字母的下標,數據不存在返回-1
# 字符串的函數操作方法
# 查找字符在字符串中的下標位置
data = 'itcast'
# num接收查找到的下標 如果存在返回對應位置下標,不存在返回-1
num = data.find('w')
print(num)
-
index 找字符在字符串中位置,返回對應的首字母的下標,數據不存在報錯
num2 = data.index('w')
print(num2)
-
split 字符串的切割
-
切割后的數據會放入列表中返回
-
data_str = 'python,hadoop,spark,flink'
# split的切割字符串
res = ?data_str.split(',')
print(res)
-
replace 字符串的替換,替換字符串中的數據
-
除了可以替換數據,還可以清洗數據
-
data_str2 = '2024-10-11'
# 字符串替換
res2 = data_str2.replace('-','/')
print(res2)
?
?
data_str3 = '機器哦@我覺得#千庫網'
# 通過replace的替換去除特殊字符
res3 = data_str3.replace('@','').replace('#','')
print(res3)
七、列表
7-1 列表定義
語法格式
[數據1,數據2.....]
# 列表的定義及取值 # 在列表中可以定義指定多個數據內容,盡量保證數據類型一致 data_list = [1, 20, 33, 15, 18, 21] data_list2 = ['spark', 'hadoop', 'flink', 'python'] data_list3 = [1, '張三', 20]
7-2 列表取值
可以通過下標和切片取值
for循環遍歷取值
# 列表的定義及取值 # 在列表中可以定義指定多個數據內容,盡量保證數據類型一致 data_list = [1, 20, 33, 15, 18, 21] data_list2 = ['spark', 'hadoop', 'flink', 'python'] data_list3 = [1, '張三', 20] ? # 列表也是有序容器,所以支持下標取值 # 單個取值 print(data_list[1]) print(data_list2[2]) ? # 切片取多個值 print(data_list[1:5]) ? # 步長間隔取值 print(data_list[1:5:2]) ? # 循環遍歷取值 for i in data_list3:print(i) ? ? # 列表嵌套列表 data_list4 =[[1,2,3],['a','b','c']] ? print(data_list4[1][0])
7-3 列表的增刪改查方法
增加
-
append
-
常用來增加一個元素數據
-
-
extend
-
將另一個列表的數據合并當前列表
-
-
insert
-
指定下標位置增加數據
-
# 添加列表數據
data_book = [] ?# 定義一個空列表
# append添加數據,將數據添加到列表末尾
data_book.append('昆侖')
data_book.append('滄海')
data_book.append('五大賊王')
# 查看原始數據
print(data_book)
# insert 可以指定下標位置添加
data_book.insert(1, '青盲')
# 查看數據
print(data_book)
?
# extend將一個列表數據合并另一個列表中
data_book_new = ['大魔術師', '冒死記錄']
data_book.extend(data_book_new)
print(data_book)
?
# 使用運算符 + 將列表合并
data_book_new2 = ['死亡通知單', '暗黑者', '攝魂谷', '兇畫']
res = data_book + data_book_new2
print(res)
?
刪除
-
del 數據[下標] 刪除指定下標的數據
-
remove 刪除列中指定的數據
-
pop() 彈出列表中的數據,數據彈出后會從列表中刪除
-
默認從最后一個數據彈出
-
-
clear() 清除所有列表中的數據,變成空列表
# 刪除列表中的數據
data_book = ['誅仙','斗破蒼穹','盜墓筆記','年少荒唐','極品家丁','壞蛋是怎么練成的']
?
# 通過指定下標刪除
del data_book[3]
print(data_book)
# 指定數據刪除
data_book.remove('極品家丁')
print(data_book)
# 彈出數據刪除 將末尾數據彈出 可以定義接收變量,接收彈出的數據
res = data_book.pop()
print(data_book)
# 清空列表數據
data_book.clear()
print(data_book)
修改
-
指定下標對應的數據進行修改
-
列表[下標] = 修改的值
-
-
列表數據的反轉 修改順序
-
排序
# 修改列表數據 data_book = ['紫川', '三重門', '從你的全世界路過', '夢里花落知多少'] ? # 通過下標修改數據 data_book[1] = '善惡的彼岸' print(data_book) ? # 列表反轉 data_book.reverse() print(data_book) ? # 列表排序 data_list = [1,7,2,4,3] data_list.sort(reverse=False) print(data_list) data_list.sort(reverse=True) print(data_list)
查詢
-
index 查詢數據在列表中的下標位置
-
count 查詢數據出現的次數
-
in 查找數據是否在列表中
-
not in 不在列表中
-
-
len 獲取列表的元素個數
# 查詢列表數據
data_book = ['道德的譜系','反基督','瞧,這個人','飛鳥集']
?
# index查詢數據
num = data_book.index('反基督')
print(num)
# num = data_book.index('aa')
# print(num)
?
# count 統計數據出現次數
num2 = data_book.count('飛鳥集')
print(num2)
?
# 查詢元素個數
num3 = len(data_book)
print(num3)
?
# 判斷元素是否在列表中
if '道德的譜系' in data_book:print('數據在列表中')# not in 是判斷不在列表中



)


的使用)

退出小程序方法)
)






![springboot2+mybatis-plus+vue3創建入門小項目[學生管理系統]02[實戰篇]](http://pic.xiahunao.cn/springboot2+mybatis-plus+vue3創建入門小項目[學生管理系統]02[實戰篇])

