 標題:用于自然駕駛行為識別的多注意力Transformer
標題:用于自然駕駛行為識別的多注意力Transformer
源文鏈接:https://openaccess.thecvf.com/content/CVPR2023W/AICity/papers/Dong_Multi-Attention_Transformer_for_Naturalistic_Driving_Action_Recognition_CVPRW_2023_paper.pdf![]() https://openaccess.thecvf.com/content/CVPR2023W/AICity/papers/Dong_Multi-Attention_Transformer_for_Naturalistic_Driving_Action_Recognition_CVPRW_2023_paper.pdf
https://openaccess.thecvf.com/content/CVPR2023W/AICity/papers/Dong_Multi-Attention_Transformer_for_Naturalistic_Driving_Action_Recognition_CVPRW_2023_paper.pdf
源碼鏈接:https://github.com/wolfworld6/Aicity2023-Track3![]() https://github.com/wolfworld6/Aicity2023-Track3
https://github.com/wolfworld6/Aicity2023-Track3
發表:CVPR-2023
目錄
摘要?
1. 簡介
2. 方法
2.1 數據預處理
2.2 特征提取
2.3 時間動作定位
2.4 時間校正
3. 實驗
3.1 訓練
?3.1.1 特征提取模型
3.1.2 時間動作定位模型
3.2 結果
3.2.1 數據預處理結果
3.2.2 多視角模型結果
3.2.3 后視圖模型結果
4. 結論
讀后總結
摘要?
為了檢測AI City Challenge Track 3中未剪輯視頻中每個動作的開始時間和結束時間,本文提出了一種強大的網絡架構——多注意力Transformer。之前的方法通過設置固定滑動窗口來提取特征,這意味著一個固定的時間間隔,并預測動作的開始和結束時間。我們認為,采用一系列固定窗口會破壞包含上下文信息的視頻特征。因此,我們提出了一種多注意力Transformer模塊,該模塊結合了局部窗口注意力和全局注意力來解決這個問題。采用VideoMAE提供的特征的方法在驗證集A2上取得了66.34的得分。然后使用時間校正模塊將得分提高到67.23。最終,我們在AI City Challenge 2023的Track 3 A2數據集上獲得了第三名。我們的代碼可在以下地址獲取:https://github.com/wolfworld6/Aicity2023-Track3。
1. 簡介
分心駕駛可能非常危險。如今,自然駕駛研究和計算機視覺技術的發展為消除和減少分心駕駛行為的發生提供了急需的解決方案。自然駕駛研究對于研究駕駛員行為至關重要。它們可以幫助我們捕捉交通環境中的駕駛員行為,并分析駕駛員在駕駛時的分心情況,這是減少分心駕駛的關鍵之一。AI City Challenge的Track 3提供了車內駕駛員的視頻片段,這些片段覆蓋了三個不同的視角,并包含了16種不同類型的駕駛員動作。在這一賽道中,參與者需要實現一個算法來標注視頻中的各種動作,并識別它們的開始和結束時間。
這個任務可以看作是視頻理解領域的時間動作定位(TAL)任務。這項任務中的視頻通常是較長的未編輯視頻,但每個單獨動作的時間間隔相對較短。在時間動作定位算法中,一個直觀的想法是預定義一組不同時間長度的滑動窗口,并將它們在視頻上滑動,如S-CNN [17]、TURN [6] 和 CBR [5]。然后,逐一判斷每個滑動窗口內的時間間隔內的動作類別。受兩階段目標檢測算法的啟發,基于候選時間間隔的算法首先從視頻中生成一些可能包含動作的候選時間間隔,然后判斷每個候選時間間隔內的動作類別并校正間隔邊界,如R-C3D [19] 和 TAL-Net [3]。此外,單階段目標檢測的理念也可以應用于時間動作定位,如SSAD [12] 和 GTAN [15]。目前,Transformer模型在計算機視覺的各個領域中表現出了卓越的性能,如目標檢測 [2],[21],[10],[9],圖像分類 [4],[13],和視頻理解 [7],[14]。然而,當在長時間視頻中使用Transformer模型時,視頻幀數量的增加將導致計算量顯著增加。Gedas Bertasius等人 [1] 進行了廣泛的實驗,發現了一種可分離的時空注意力方法,為Transformer模型在長視頻理解中的應用打開了大門。其次,由于不同動作的持續時間可能差異很大,在Transformer模型中設置固定的窗口和塊大小來提取適當的特征是具有挑戰性的。Kai Han等人 [8] 提出了Transformer中的Transformer (TNT) 模型,該模型融合了外部塊和內部塊的特征,豐富了特征信息,提高了特征表達。
受上述觀察的啟發,我們提出了一個多注意力Transformer模塊,該模塊不僅用于建模不同剪輯窗口之間的關系,還用于建模全局窗口內的關系。此外,我們設計了一個時間校正模塊,以融合和校正高置信度的預測結果,從而獲得更準確的結果。
2. 方法
2.1 數據預處理
我們在視頻中檢測人體并裁剪每一幀。為了確保視頻的穩定性,我們對視頻的每一幀進行人體檢測,并將檢測區域最大的幀保存為整個視頻的裁剪標準,以避免由于不同幀中的檢測尺寸不同而導致的背景抖動。裁剪操作保留了與人體相關的信息,去除了冗余信息。一方面,它減少了其他噪音對動作特征的干擾。另一方面,它使模型更容易學習人體動作。
2.2 特征提取
我們在不同的視頻表示模型和A1視頻的三個視角上進行了多次實驗。由于VideoMAE [18] 在表1中顯示了更好的性能,因此在本文中采用它對后視和儀表盤視角進行特征提取。我們使用了在不同數據集上預訓練的公共權重,并在A1數據上進行了微調。本文中使用的權重如表 2所示。我們分別對后視和儀表盤視角的視頻進行了微調,并提取了A2數據集的特征。


2.3 時間動作定位
Actionformer [20] 結合了多尺度特征表示和局部自注意力,并使用輕量級解碼器對每個時刻進行分類并估計相應的動作邊界。如圖1所示,在Actionformer的基礎上,我們提出了一個多注意力Transformer,不僅用于建模不同剪輯窗口之間的關系,還用于建模全局窗口內的關系。
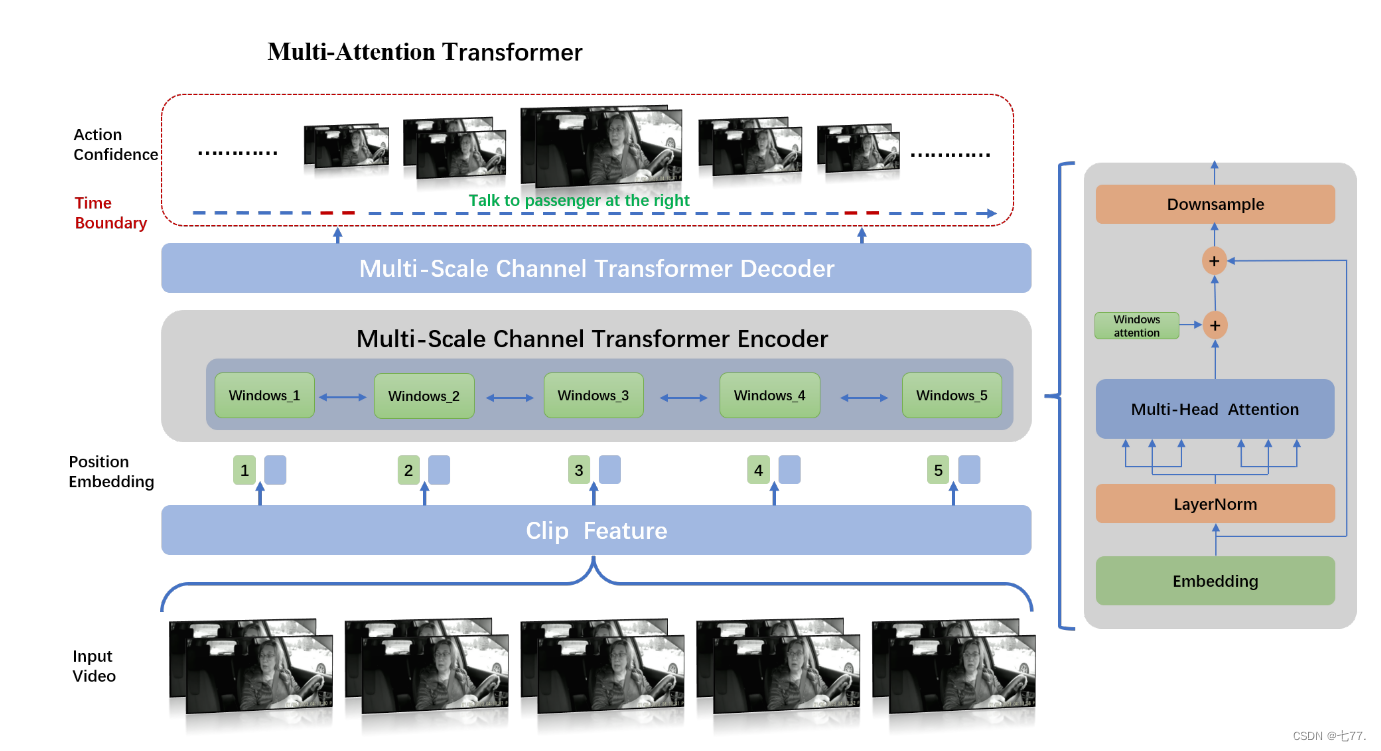
圖1. 我們模型架構的概述。我們的方法構建了一個基于Transformer的模型,用于動作分類并估計每個時刻的動作邊界。在特征提取階段,我們通過VideoMAE提取一系列視頻剪輯特征,然后對這些特征進行嵌入。嵌入的特征將通過窗口注意力和全局注意力模塊進行編碼。在每個時間步,通過使用分類頭預測動作類別和回歸頭預測動作時間邊界,生成候選動作。
多注意力:如圖1右側所示,在多尺度通道Transformer編碼器中,從視頻片段中提取的特征 輸入到LayerNorm、多頭注意力和窗口注意力模塊,然后進行下采樣以獲得特征
。特征
重新輸入編碼器,經過LayerNorm、多頭注意力、窗口注意力和下采樣后,獲得特征
。這種操作重復N-1次,以獲得
。之后,
輸入到多尺度通道Transformer解碼器進行解碼,通過不同的全連接層回歸動作的類別信息和相應的時間信息。
在多頭注意力模塊中,所有輸入特征之間進行特征融合;由于輸入特征是按照視頻時間段排列的,多頭注意力模塊將利用時間軸上的信息。在窗口注意力模塊中,特征融合既針對相鄰位置的視頻片段特征,也針對所有特征進行,但不同之處在于,特征融合僅在通道維度上進行。
我們的模型有N層Transformer層,采用多尺度來捕捉不同時間尺度上的動作。每一層由局部多頭自注意力(MSA)和全局多頭自注意力(GMSA)組成。為了在不同的注意力下捕捉動作,這個操作被公式化為:
其中, 指的是第i層的MSA,
指的是第i層的GMSA。一個標準的Transformer塊結構包括多頭自注意力(MSA)和多層感知器(MLP)。為了提高效率,我們采用了一個多注意力模塊,該模塊由剪輯窗口注意力模塊和全局注意力模塊組成,可以從不同區域的不同表示子空間中學習信息。具體來說,每個剪輯窗口通道的嵌入進行平均,然后通過頭對頭Transformer獲得相同數量的注意力值。注意力值將相應地乘或加在通道上。該模塊通過維度級別的注意力實現特征增強,僅增加少量參數。
2.4 時間校正
時間動作定位模型的輸出包含大量低分數的預測結果,這些結果在時間上有大量重疊的區域。評分標準要求每個正確的結果盡可能只匹配一個預測,并且該預測的時間范圍與正確的結果差異盡量小。這意味著需要過濾大量的結果,只保留置信度高的結果。因此,我們設計了時間校正模塊,以融合和校正置信度高的預測結果,并獲得時間更準確的最終結果。
時間校正操作包括三個主要步驟,分別是:
1. 對于每個視頻ID的所有預測結果,僅保留具有相同標簽結果中得分最高的一個,丟棄其他項目。
2. 分別對幾個不同模型執行步驟1,并拼接得到的結果;
3. 對于步驟2中獲得的結果,根據時間交集并集(tIoU)融合相同標簽和相同視頻ID的結果;具體的融合操作包括:
(1)移除所有時間長度小于1秒的結果;移除所有時間長度大于30秒的結果;
(2)對于具有相同視頻ID和相同標簽的所有結果,將結果分成不同的集合,使得每個集合中所有時間區域的tIoU大于集合閾值;
(3)移除長度為1的集合;
(4)對步驟(3)中獲得的所有集合,計算每個集合中所有時間點的平均值;由于每個集合中的所有結果具有相同的視頻ID和相同的標簽,將集合中所有開始時間的平均值計算為該視頻ID和該標簽的開始時間;將集合中所有結束時間的平均值計算為該視頻ID和該標簽的結束時間。第i個視頻ID和第j個標簽的動作的開始時間和結束時間可以通過以下公式計算:
其中,是第i個視頻ID和第j個標簽的動作的開始時間,
是第i個視頻ID和第j個標簽的動作的結束時間。
表示視頻ID為i且標簽為j的預測集合。N是
的長度。
表示
中第p個預測的開始時間,
表示
中第p個預測的結束時間。
此外,在融合相同視頻ID和相同標簽的結果時,除了描述的第四步中取所有時間點的平均值的方法外,我們還嘗試另一種方法:根據它們的分數對時間節點的融合進行加權,公式如下:
其中,?表示
中第p個預測的分數。
3. 實驗
3.1 訓練
?3.1.1 特征提取模型
使用了 VideoMAE-L 和 VideoMAE-H 在 A1 數據集上進行微調,訓練裁剪大小為 224。初始學習率為 2e-3。幀數為 16,采樣率為 4。實驗在 8 個 Nvidia V100 GPU 上以批量大小 2 運行。VideoMAE-L 訓練了 35 個 epoch,而 VideoMAE-H 訓練了 40 個 epoch。
3.1.2 時間動作定位模型
我們在 A1 數據集上進行實驗,將數據劃分為訓練集和測試集,比例為 7:3。實驗后,我們使用所有 A1 數據作為訓練集。首先,我們將 32 個連續幀作為輸入提供給預訓練模型 UniFormerV2,使用步幅為 16 的滑動窗口,并從原始視頻中提取了覆蓋左、中、右三部分的 3072-D 特征,以優化網絡結構。使用 mAP@[0.1:0.5:5] 來評估我們的模型。其次,我們還對提取的 1024D 特征進行了一些消融實驗。我們的 TAL 模型訓練了 40 個 epoch,線性預熱了 5 個 epoch。初始學習率為 1e-3,采用余弦學習率衰減,權重衰減為 5e-2。最后,我們使用預訓練的 VideoMAE 提取 1028-D 特征和 1024-D 特征。該方法可適用于不同的特征,并測試模型在多視角、單視角和多特征上的性能。
3.2 結果
3.2.1 數據預處理結果
針對裁剪操作是否增強了模型效果,我們進行了消融實驗來驗證。實驗結果表明,裁剪操作確實起到了作用。如表3所示,使用具有 FH(k400)(1280) 特征的 Multi-Attention 模型,裁剪操作可將后視和儀表盤視圖上的 mAP 從 83.67 提升到 87.79。
3.2.2 多視角模型結果
我們開始進行實驗,并在 A1 數據集上使用預訓練模型 UniFormerV2 提取所有視角視頻的 3072-D 特征,我們使用驗證集進行訓練。窗口大小的超參數設定為 9,小批量大小為 4,最大段數設定為 2304。表4總結了結果,我們的方法在平均 mAP 上達到了 67.33%,在 tIoU=0.5 時的 mAP 為 59.02%。通過簡單設計和強大的多注意力Transformer模型的結合,模型性能得到了提升。此外,我們嘗試了各種超參數,包括使用具有8個頭的FPN架構,將窗口大小增加到13,并將中心樣本半徑設定為2.5。結果,mAP 從 67.33% 提高到了 70.69%。
考慮到不同區域包含屏幕目標的不同信息,我們盡可能地進行了大量實驗,以便對具有不同裁剪部分和不同調整大小模式的視頻特征進行公平比較。結果如表5所示。與表4中的結果(mAP 67.33%)相比,差別不大,因此我們在后續實驗中刪除了裁剪模式。
3.2.3 后視圖模型結果
通過實驗發現,使用后視圖的分類模型的準確性更高,如表1所示。我們測試了使用不同的VideoMAE背景模型提取的后視圖和儀表盤視圖特征的模型性能。如表6所示,不同的特征在時間動作定位上具有不同的性能。
3.2.4 時間校正模塊結果
時間校正模塊的實驗結果如表7所示。模型M1到M10的具體信息如表8所示。由于系統提供的評估次數有限,我們無法對每個模型組合遍歷所有方法以獲得最佳的評估結果。因此,在總結每個比較實驗中的模式后,我們直接為更好的模型使用最佳處理方法。我們在第2.4節介紹了時間校正模塊。在第二步中,將幾個不同模型的結果拼接在一起,與使用單個模型相比,結果更高。單個模型M1的平均重疊分數為0.6382,但在拼接三個模型的結果并采用時間校正后,評估結果的性能提高到了0.6482。此外,四個模型M7 + M8 + M9 + M10的拼接結果比三個模型M7 + M8 + M9的拼接結果將評估分數從0.6634提高到了0.6723。第三步中,移除了長度為1的集合。這個操作也提升了結果。在添加此操作后,與沒有此操作的時間校正模塊的結果相比,評估分數從0.6325提高到了0.6482。針對A1數據集進行了動作持續時間的統計,發現持續時間都在1-30秒的范圍內,因此我們限制了預測結果的持續時間范圍。此外,當融合相同視頻ID和相同標簽的結果時,我們嘗試了兩種方法:取所有時間點的平均值和根據它們的分數對時間節點進行加權融合。然而,實驗結果表明,使用平均值更令人滿意。使用相同的模型組合M4 + M5 + M6,加權和平均方法分別得到0.6514和0.6593。賽道的總體排名和得分如表9所示。表7中M7 + M8 + M9 + M10模型組合的結果是我們團隊最終的預測結果,在公共排行榜上平均重疊分數為0.6723,排名第三。在這個組合中,M7、M8和M9分別表示使用表2中的特征FL(hybrid)(1024)、FL(ego)(1024)和FH(k400)(1280)訓練的時間動作定位模型。而M10代表Tridet模型。毫無疑問,通過將更強大的視頻特征背景與目標檢測結果相結合,我們方法在AI城市挑戰賽的Track 3上的結果可以進一步提高。
4. 結論
本文提出了一種基于多注意力Transformer的時間動作定位方法。該方法的強大之處在于我們的設計選擇,特別是將特征與多注意力模塊的方法相結合,以對視頻中的更長時間范圍的上下文進行建模。此外,我們進行了大量實驗,比較了不同的視頻視角、不同的特征提取網絡、不同的預訓練數據集,以找到具有更好特征表示能力的視角和網絡。此外,我們還提出了一個時間校正模塊來提高時間精度。
讀后總結
創新點1:在實現時間動作定位部分,提出多注意力Transformer模塊,在transformer中加入局部窗口注意力,通過局部窗口注意力和全局窗口注意力的組合來代替固定窗口。
創新點2:提出時間校準模塊,對視頻段的預測結果進行融合和處理(平均,加權平均)等處理,實現時間定位更加準確。












)





![[前端|vue] 驗證器validator使用筆記 (筆記)](http://pic.xiahunao.cn/[前端|vue] 驗證器validator使用筆記 (筆記))
