
rtemis?是一個集機器學習與可視化于一體的 R 包,用于各種高級機器學習研究和應用。整體而言,該軟件有三個目標:
-
「應用數據科學」:使高級數據分析高效且易于使用
-
「機器學習研究」:提供一個平臺以開發和測試新穎的機器學習算法
-
「教育」:通過提供簡明的案例、代碼和可視化,使機器學習概念易于理解
比較有特點的是,rtemis 為數據處理、監督學習和聚類提供了大量算法的通用函數接口。小編在官網中看到的包裝功能確實也多:
-
預處理
-
保持完整樣本:可以選擇僅保留沒有缺失數據的樣本。
-
移除常量特征:刪除所有值都相同的列。
-
移除重復樣本:刪除重復的行。
-
根據缺失數據比例移除樣本或特征:根據缺失數據的閾值刪除樣本或特征。
-
數據類型轉換:將整數、邏輯值和字符變量轉換為因子、數字或其他類型。
-
數值變量的分箱:將數值變量根據區間或分位數進行分箱處理。
-
處理缺失值:生成指示缺失數據的新布爾列,并選擇多種方法進行缺失值插補。
-
數據縮放和中心化:對列進行標準化處理。
-
獨熱編碼:將因子變量進行獨熱編碼。
-
-
重采樣
-
bootstrap:標準自助法,即帶放回的隨機抽樣。
-
strat.sub:分層樣本抽樣。
-
strat.boot:先進行分層子樣本抽樣,然后隨機復制一些訓練樣本以達到原始長度或指定長度。
-
kfold:k折交叉驗證。
-
loocv:留一交叉驗證。
-
-
無監督學習
-
聚類
-
分解 / 降維
-
-
監督學習
-
回歸與分類
-
自動調參與測試
-
實驗記錄
-
集成法
-
提升法
-
RuleFit 算法
-
類別不平衡數據的處理
-
集成模型
-
疊加樹模型
-
線性疊加樹模型
-
在本文中,僅僅展示如何使用 rtemis 快速進行分類與回歸,更多個性化的內容大家可以參照下方的「官方文檔」:
-
https://rtemis.lambdamd.org/
0. R包下載
用戶可以通過以下代碼安裝或者引用:
#?從GitHub上安裝該包
remotes::install_github("egenn/rtemis")
#?其它潛在的依賴包
install.packages("mlbench")
install.packages("pROC")
install.packages("PRROC")
install.packages("progressr")
install.packages("future.apply")
1. 回歸模型
① 生成用于回歸的模擬數據框dat:
x?<-?rnormmat(500,?5,?seed?=?2019)
y?<-?x?%*%?rnorm(5)?+?rnorm(500)
dat?<-?data.frame(x,?y)#?check?函數用于檢查數據集的整體概況
check_data(dat)
#??dat:?A?data.table?with?500?rows?and?6?columns
#??Data?types
#??*?6?numeric?features
#??*?0?integer?features
#??*?0?factors
#??*?0?character?features
#??*?0?date?features#??Issues
#??*?0?constant?features
#??*?0?duplicate?cases
#??*?0?missing?values#??Recommendations
#??*?Everything?looks?good#?最后簡單看一下dat
head(dat)
#??????????X1?????????X2??????????X3?????????X4?????????X5??????????y
#1??0.7385227?-0.5201603??1.63030574??1.9567386?-0.7911291??3.9721257
#2?-0.5147605??0.5388431??0.47104282??0.8373285??0.8610578?-1.7725552
#3?-1.6401813??0.2251481?-0.73062473?-0.6192940??1.1604909?-3.3698612
#4??0.9160368?-1.5559318?-0.05606844??0.4602711?-0.9290626??5.1083103
#5?-1.2674820?-0.2355507??0.71840950?-0.9094905?-1.1453902?-2.8096872
#6??0.7382478??1.1090225??0.80076099??1.1155501??1.5148726?-0.3089569dat的行代表樣本,列X1-X5分別代表不同的特征變量,列y代表用于回歸的目標變量(因變量)。同樣的,對于自己的數據也是按照類似的格式準備。
②?重新采樣,生成訓練集與測試集列表res:
res?<-?resample(dat,resampler?=?"strat.sub",?#?選用分層抽樣。stratify.var?=?y,????????#?用于分層的指定變量strat.n.bins?=?4,???????#?將分層變量劃分為3個區間,確保每個區間的數據在訓練集和測試集中都能存在,使得測試集的結果更為可信train.p?=?0.75,?????????#?每層中隨機選取75%的樣本作為新的數據集n.resamples?=?10????????#?需要生成的重采樣數據集數量)
這里使用的是默認參數resampler = "strat.sub"進行分層抽樣,其原理根據指定的分層變量(stratify.var參數,這里是y)將數據集分成多個組(層),在每個層內按照指定的比例(train.p=0.75)隨機抽取樣本,產生新的隊列。n.resamples設置為10,意味著將分別抽樣10次,總共生成10個新的隊列,并以列表res返回抽樣對列的行索引。
#?簡單看一下res,每個Subsample_*對應不同的索引,可以用于提取指定的抽樣數據集
str(res)
#List?of?10
#?$?Subsample_1?:?int?[1:374]?1?4?6?8?9?12?14?17?18?19?...
#?$?Subsample_2?:?int?[1:374]?2?3?4?5?6?8?10?11?14?15?...
#?$?Subsample_3?:?int?[1:374]?1?2?3?4?6?8?9?10?11?13?...
#?$?Subsample_4?:?int?[1:374]?1?3?4?5?6?7?8?12?14?15?...
#?$?Subsample_5?:?int?[1:374]?2?4?5?6?8?10?12?14?15?16?...
#?$?Subsample_6?:?int?[1:374]?1?2?3?4?5?6?7?8?9?10?...
#?$?Subsample_7?:?int?[1:374]?3?4?5?6?7?8?10?11?12?14?...
#?$?Subsample_8?:?int?[1:374]?1?2?3?5?6?7?8?10?11?13?...
#?$?Subsample_9?:?int?[1:374]?1?2?3?4?5?6?7?8?9?10?...
#?$?Subsample_10:?int?[1:374]?1?2?4?5?6?7?8?10?11?12?...
#?-?attr(*,?"class")=?chr?[1:2]?"resample"?"list"
#?-?attr(*,?"N")=?int?10
#?-?attr(*,?"resampler")=?chr?"strat.sub"
#?-?attr(*,?"train.p")=?num?0.75
#?-?attr(*,?"strat.n.bins")=?num?4
③?指定訓練集與測試集并構建模型
#?訓練集為分層采樣后的第一個數據集
dat.train?<-?dat[res$Subsample_1,?]
#?第一個數據集分層采樣剩下的數據集作為測試集
dat.test?<-?dat[-res$Subsample_1,?]
#?構建模型
mod?<-?s_GLM(dat.train,?dat.test)
mod$describe()
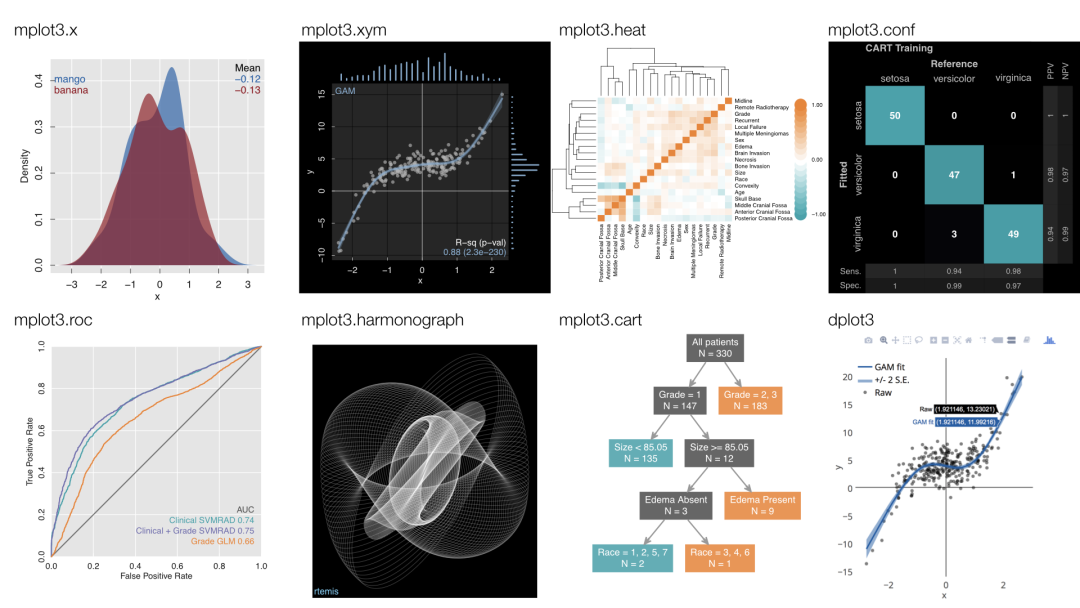
#Generalized?Linear?Model?was?used?for?regression.
#R-squared?was?0.98?(training).#?簡單看一下常見的幾個回歸指標
mod$error.train??????#?訓練集
#MSE?=?1.02?(97.81%)
#RMSE?=?1.01?(85.18%)
#MAE?=?0.81?(84.62%)
#r?=?0.99?(p?=?1.3e-310)
#R?sq?=?0.98
mod$error.test??????#?測試集
#MSE?=?0.98?(97.85%)
#RMSE?=?0.99?(85.35%)
#MAE?=?0.76?(85.57%)
#r?=?0.99?(p?=?2.7e-105)
#R?sq?=?0.98#?測試集上的預測結果,訓練集的預測結果可以通過mod$fitted打印
mod$predicted
#??[1]??-6.9228634??13.5473120??-4.4142316??-6.4150050??-3.1899404???5.8635544??10.9276092??-3.3697528???7.3197323???4.5917325???3.8279902
#?[12]??-2.5436844??-8.4399966??-3.2597535???3.0558347??10.1805533??-4.5057564??-0.1087756??-0.7984958??-8.4851937??-4.8099938??-0.7611819
#?[23]??-0.3023645??-1.1838060???6.2697071???2.9259362???2.9894219???3.5715647???3.2065868???2.3246177??-1.1029005??-3.1490491??-7.2180310
#?[34]???1.3552666???8.1584272??-2.2085630??-1.5803727??-0.7588147???1.4364268???0.6639963???5.3642140???0.3600681??-4.2238833?-18.8447897
#?[45]??-6.2053170??-5.6646543??-6.3526682???5.9058403??-2.9385554??-1.8897201???3.3465618???3.1953050???1.9692337??-8.0531435???0.4722245
#?[56]??14.6760641??-1.6578528??11.2129667??-9.2015635???0.6143482??-2.8688158??-1.5580413???0.3452240?-19.3633269??-4.7365043??-1.7222169
#?[67]??-3.5001696???2.0906088??-5.5367285??16.0566618??-2.2632949??10.1779890???4.8057160???5.0095983??-3.4675440??-7.8418409???1.5149870
#?[78]??-1.0510093???1.2397077???7.8981605???0.1196208?-13.6210350??-2.1589314??-4.5641406??-4.9111480??-0.5444266???3.8954173?-15.3977663
#?[89]??-6.3044076??-5.8120357???0.2301799??-1.8128115???4.7353047?-11.5507244???2.2981759?-11.6778343??-4.4418715???4.5915911??13.0456691
#[100]???2.3961443??11.6771535???2.9362587???3.4500863??14.6597287???7.2120194??-6.8395880?-17.1198556???8.7869138??-3.8199982??-5.0879467
#[111]??-3.9051859??-9.9320098???0.5141523??-6.2265527??-6.1502030??10.6211752??-1.2735560???3.0118796???3.2969205??-1.8482288???3.6860180
#[122]???0.6108124??10.0208633???5.8474645???1.4720176???0.2498226
需要注意,構建回歸模型的函數s_GLM默認使用最后一列作為因變量/目標變量(其實這個函數參數超級多,感興趣的鐵子可以自行學習指定)。同時,s_GLM 既支持?線性回歸?和?邏輯回歸(單分類任務),也支持?多項邏輯回歸(也就是多分類任務)。對于多分類任務,如果 y 有兩個以上的類別,s_GLM內部使用nnet::multinom進行多項邏輯回歸。
④?可視化模型結果:
#?可視化訓練集擬合結果
mod$plotFitted(theme?=?'white')
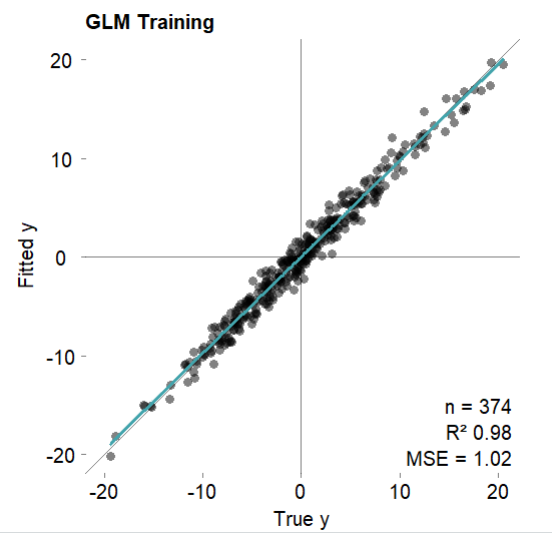
#?可視化測試集擬合結果
mod$plotPredicted(theme?=?'white')
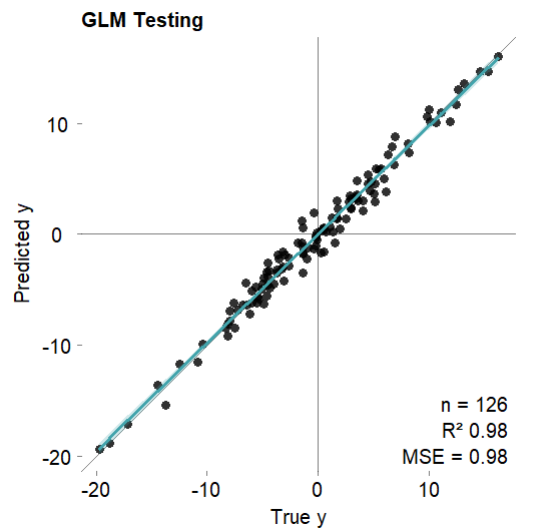
#?可視化特征重要性
mod$plotVarImp(theme?=?'white')
需要注意,返回的mod是 R6 類對象。R6 對象包含屬性和函數,同時支持 S3 方法,因此用戶可以訪問所有熟悉的 R 泛型。
2. 分類模型
①?示例數據的準備,這里使用的是mlbench的內置數據集,總共有 60 個特征與最后一列的 Class 的分類屬性:
data(Sonar,?package?=?'mlbench')
str(Sonar)
#'data.frame':?208?obs.?of??61?variables:
#?$?V1???:?num??0.02?0.0453?0.0262?0.01?0.0762?0.0286?0.0317?0.0519?0.0223?0.0164?...
#?$?V2???:?num??0.0371?0.0523?0.0582?0.0171?0.0666?0.0453?0.0956?0.0548?0.0375?0.0173?...
#?$?V3???:?num??0.0428?0.0843?0.1099?0.0623?0.0481?...
#?$?V4???:?num??0.0207?0.0689?0.1083?0.0205?0.0394?...
#?$?V5???:?num??0.0954?0.1183?0.0974?0.0205?0.059?...
#?$?V6???:?num??0.0986?0.2583?0.228?0.0368?0.0649?...
#?$**?.........................................
#?$?V60??:?num??0.0032?0.0044?0.0078?0.0117?0.0094?0.0062?0.0103?0.0053?0.0022?0.004?...
#?$?Class:?Factor?w/?2?levels?"M","R":?2?2?2?2?2?2?2?2?2?2?...#?檢查一下數據
check_data(Sonar)
#??Sonar:?A?data.table?with?208?rows?and?61?columns
#??Data?types
#??*?60?numeric?features
#??*?0?integer?features
#??*?1?factor,?which?is?not?ordered
#??*?0?character?features
#??*?0?date?features
#??Issues
#??*?0?constant?features
#??*?0?duplicate?cases
#??*?0?missing?values
#??Recommendations
#??*?Everything?looks?good
②?數據重采樣分組(與上面回歸模型的一致):
res?<-?resample(Sonar)
sonar.train?<-?Sonar[res$Subsample_1,?]
sonar.test?<-?Sonar[-res$Subsample_1,?]
③?模型的構建,s_Ranger函數是該包提供的用于構建隨機森林的分類/回歸模型,內部提供了多種參數(包括常見的mtry,用于自動調參的autotune等等)
mod?<-?s_Ranger(sonar.train,?sonar.test)
#?簡答看看模型的描述
mod$describe()
#Ranger?Random?Forest?was?used?for?classification.
#Balanced?accuracy?was?1?(training)and?0.83?(testing).
④?可視化結果(基本上訓練集測試集都有,命名也是具有統一規律,這邊就只展示其中一張)
mod$plotPredicted(theme?=?'white')?#?測試集,分類性能的四格熱圖
mod$plotFitted(theme?=?'white')????#?訓練集
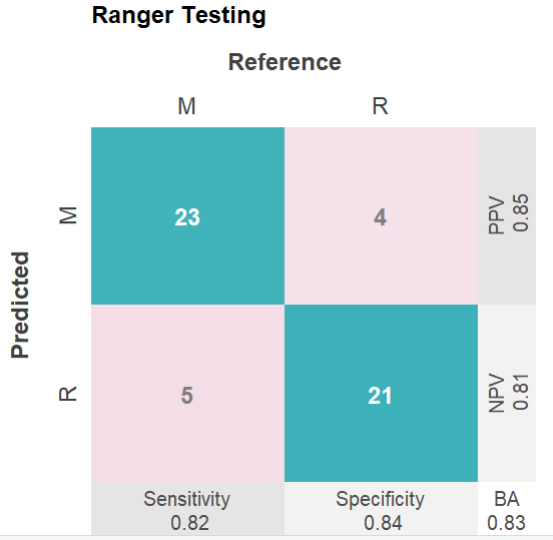
mod$plotROCpredicted(theme?=?'white')#?測試集,分類性能的roc曲線
mod$plotROCfitted(theme?=?'white')???#?訓練集
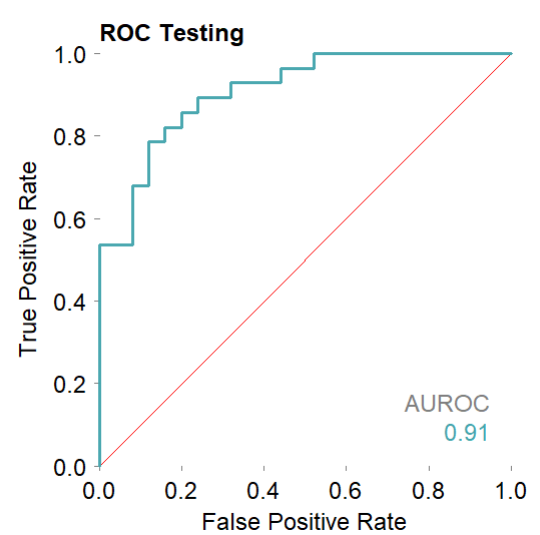
mod$plotPRpredicted(theme?=?'white')#?測試集,分類性能的PR曲線
mod$plotPRfitted(theme?=?'white')???#?訓練集

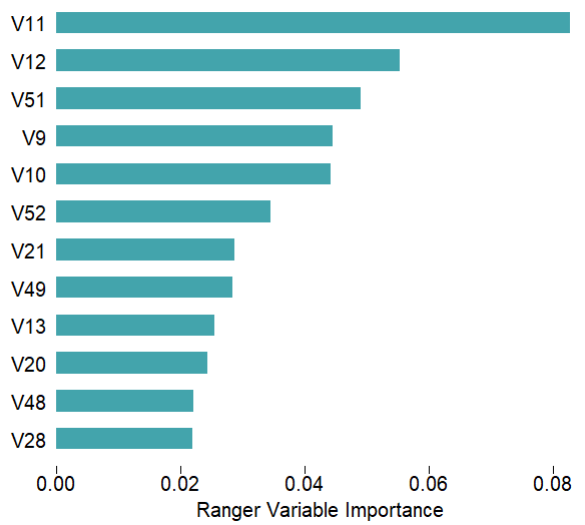
mod$plotVarImp(theme?=?'white')#?特征重要性
三. 可視化主題
①?配色系列,rtpalette函數提供了多種可供選擇的配色系列:
rtpalette()
#[1]?"ucsfCol"?????????????"pennCol"?????????????"imperialCol"?????????"stanfordCol"?????????"ucdCol"?????????????
#[6]?"berkeleyCol"?????????"ucscCol"?????????????"ucmercedCol"?????????"ucsbCol"?????????????"uclaCol"????????????
#[11]?"ucrColor"????????????"uciCol"??????????????"ucsdCol"?????????????"californiaCol"???????"scrippsCol"?????????
#[16]?"caltechCol"??????????"cmuCol"??????????????"princetonCol"????????"columbiaCol"?????????"yaleCol"????????????
#[21]?"brownCol"????????????"cornellCol"??????????"hmsCol"??????????????"dartmouthCol"????????"usfCol"?????????????
#[26]?"uwCol"???????????????"jhuCol"??????????????"nyuCol"??????????????"washuCol"????????????"chicagoCol"?????????
#[31]?"pennstateCol"????????"msuCol"??????????????"michiganCol"?????????"iowaCol"?????????????"texasCol"???????????
#[36]?"techCol"?????????????"jeffersonCol"????????"hawaiiCol"???????????"nihCol"??????????????"torontoCol"?????????
#[41]?"mcgillCol"???????????"uclCol"??????????????"oxfordCol"???????????"nhsCol"??????????????"ethCol"?????????????
#[46]?"rwthCol"?????????????"firefoxCol"??????????"mozillaCol"??????????"appleCol"????????????"googleCol"??????????
#[51]?"amazonCol"???????????"microsoftCol"????????"pantoneBalancingAct"?"pantoneWellspring"???"pantoneAmusements"??
#[56]?"grays"???????????????"rtCol1"??????????????"rtCol3"??
簡單給各位鐵子看看:
previewcolor(rtpalette("imperialCol"),?"Imperial",?bg?=?"white")

previewcolor(rtpalette("ucsfCol"), "UCSF", bg = "white")

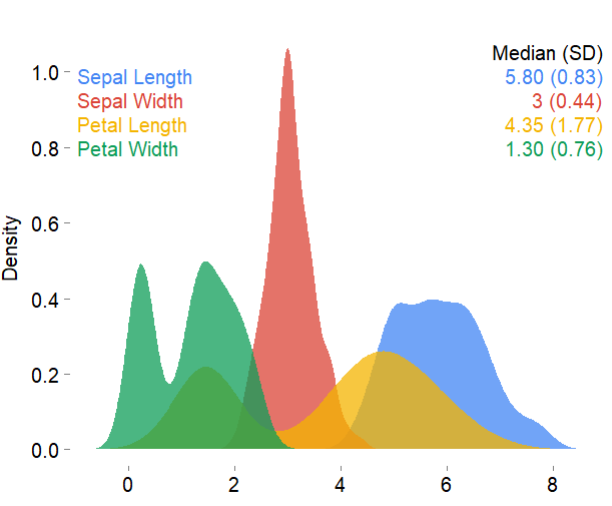
具體使用的時候可以指定參數palette:
mplot3_x(iris,?palette?=?"google",?theme?=?'white')
②?主題,可選的主題包括以下幾種:
-
white
-
whitegrid
-
whiteigrid
-
black
-
blackgrid
-
blackigrid
-
darkgray
-
darkgraygrid
-
darkgrayigrid
-
lightgraygrid
-
mediumgraygrid
具體使用的時候指定theme參數即可:
set.seed?=?2019
x?<-?rnorm(200)
y?<-?x^3?+?12?+?rnorm(200)
mplot3_xy(x,?y,?theme?=?'whitegrid',?fit?=?'gam')
傳統的機器學習 R 包確實不少
但今天分享的有一些特點?
首先是大量可供選擇的算法
封裝的不錯,參數很多?
簡便易行
其次是提供建模前的預處理方法
最后是兼顧數據可視化
就分享到這

-優化器提示)

,MATLAB代碼)





)






 v1.30.1 創建本地鏡像倉庫 使用本地docker鏡像倉庫部署服務 Discuz X3.5 容器搭建論壇)


)