GPT-SoVITS是一款強大的少量樣本語音轉換與語音合成開源工具。當前,GPT-SoVITS實現了如下幾個方面的功能:
- 由參考音頻的情感、音色、語速控制合成音頻的情感、音色、語速
- 可以少量語音微調訓練,也可不訓練直接推理
- 可以跨語種生成,即參考音頻(訓練集)和推理文本的語種為不同語種
硬件建議要求:
INT4 : RTX3090*1,顯存24GB,內存32GB,系統盤200GB
更低配的GPU硬件也可以進行推理,但是推理速度會更慢。
環境準備
模型準備
手動下載以下幾個模型(體驗時幾個模型不一定需全下載)
本文統一放在模型存檔目錄:/u01/workspace/models/GPT-SoVITS
pretrained_models
git clone https://huggingface.co/lj1995/GPT-SoVITS
uvr5_weights
https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/uvr5_weights
asr model:
git clone https://hf-mirror.com/Systran/faster-whisper-large-v3
可選模型: speech_fsmn_vad_zh-cn-16k-common-pytorch,speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch, punc_ct-transformer_zh-cn-common-vocab272727-pytorch
下載地址分別為:
git clone https://www.modelscope.cn/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch.git
git clone https://www.modelscope.cn/iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch.git
git clone https://www.modelscope.cn/iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch.git
注意存放目錄結構方便后面Docker 掛載目錄后能直接找到相關的模型
root@itserver03:/u01/workspace/models/GPT-SoVITS# tree -d
.
├── GPT_weights
├── pretrained_models
│ ├── chinese-hubert-base
│ └── chinese-roberta-wwm-ext-large
├── SoVITS_weights
└── tools├── asr│ └── models│ ├── faster-whisper-large-v3│ ├── punc_ct-transformer_zh-cn-common-vocab272727-pytorch│ │ ├── example│ │ └── fig│ ├── speech_fsmn_vad_zh-cn-16k-common-pytorch│ │ ├── example│ │ └── fig│ └── speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch│ ├── example│ └── fig└── uvr5└── uvr5_weights└── Onnx_dereverb_By_FoxJoy下載源碼
git clone https://github.com/RVC-Boss/GPT-SoVITS.git;
cd GPT-SoVITS
Docker 容器化部署
Dockerfile樣例
注意 根據官方的Dockerfile自己build出滿足自身環境需要的鏡像。
# Base CUDA image
# FROM cnstark/pytorch:2.0.1-py3.9.17-cuda11.8.0-ubuntu20.04
FROM pytorch/pytorch:2.2.1-cuda12.1-cudnn8-runtimeLABEL maintainer="breakstring@hotmail.com"
LABEL version="dev-20240209"
LABEL description="Docker image for GPT-SoVITS"# Install 3rd party apps
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=Etc/UTC
ENV TZ=Etc/UTC
ENV LANG=zh_CN.UTF-8
ENV LC_ALL=zh_CN.UTF-8RUN apt-get update && \apt-get install -y --no-install-recommends tzdata ffmpeg libsox-dev parallel aria2 git git-lfs && \git lfs install && \rm -rf /var/lib/apt/lists/*# Copy only requirements.txt initially to leverage Docker cache
WORKDIR /workspace
COPY requirements.txt /workspace/
RUN pip install --no-cache-dir -r requirements.txt# Define a build-time argument for image type
ARG IMAGE_TYPE=full# Conditional logic based on the IMAGE_TYPE argument
# Always copy the Docker directory, but only use it if IMAGE_TYPE is not "elite"
COPY ./Docker /workspace/Docker
# elite 類型的鏡像里面不包含額外的模型
RUN if [ "$IMAGE_TYPE" != "elite" ]; then \chmod +x /workspace/Docker/download.sh && \/workspace/Docker/download.sh && \python /workspace/Docker/download.py && \python -m nltk.downloader averaged_perceptron_tagger cmudict; \fi# Copy the rest of the application
COPY . /workspaceEXPOSE 9871 9872 9873 9874 9880CMD ["python", "webui.py"]
本文對官方的Dockerfile做了簡單修改以便滿足自己需要。 采用基礎鏡像
pytorch/pytorch:2.2.1-cuda12.1-cudnn8-runtime
同時需要修改鏡像的語言的環境變量,否則webui 會展示為英文界面:
ENV LANG=zh_CN.UTF-8
nltk_data 文件下載
如果啟動時找不到nltk_data 的幾個語料庫,系統會自動下載,但時前提是你的網絡已經完美的科學上網了。否則不出意外應該會出錯。 nltk_data 文件可以掛載到容器,但也可以通過更改Dockerfile直接拷貝到鏡像中。
下載地址:
https://www.nltk.org/nltk_data/
需要下載的語料庫:
- cmudict
- averaged_perceptron_tagger
存放目錄結構:
root@itserver03:/u01/workspace/nltk_data# tree
.
├── corpora
│ └── cmudict
│ └── cmudict
└── taggers└── averaged_perceptron_tagger└── averaged_perceptron_tagger.pickle4 directories, 2 files
構建image
docker build -t qingcloudtech/gpt-sovits:v1.0 .
運行
修改docker-compose.yaml文件用自己編譯的容器鏡像:
version: '3.8'services:gpt-sovits:image: qingcloudtech/gpt-sovits:v1.0container_name: gpt-sovits-containerenvironment:- is_half=False- is_share=Falsevolumes:- ./output:/workspace/output- ./logs:/workspace/logs:rw- ./TEMP:/workspace/TEMP- /u01/workspace/nltk_data:/usr/share/nltk_data- /u01/workspace/models/GPT-SoVITS/pretrained_models:/workspace/GPT_SoVITS/pretrained_models- /u01/workspace/models/GPT-SoVITS/SoVITS_weights:/workspace/SoVITS_weights- /u01/workspace/models/GPT-SoVITS/GPT_weights:/workspace/GPT_weights- /u01/workspace/models/GPT-SoVITS/tools/asr/models:/workspace/tools/asr/models- /u01/workspace/models/GPT-SoVITS/tools/uvr5/uvr5_weights:/workspace/tools/uvr5/uvr5_weights- ./reference:/workspace/referenceworking_dir: /workspaceports:- "9880:9880"- "9871:9871"- "9872:9872"- "9873:9873"- "9874:9874"shm_size: 16Gdeploy:resources:reservations:devices:- driver: nvidiacount: "all"capabilities: [gpu]stdin_open: truetty: truerestart: unless-stopped
** 注意重點:** 幾個掛載文件的路徑:
- ./output:/workspace/output
- ./logs:/workspace/logs:rw
- ./TEMP:/workspace/TEMP
- /u01/workspace/nltk_data:/usr/share/nltk_data
- /u01/workspace/models/GPT-SoVITS/pretrained_models:/workspace/GPT_SoVITS/pretrained_models
- /u01/workspace/models/GPT-SoVITS/SoVITS_weights:/workspace/SoVITS_weights
- /u01/workspace/models/GPT-SoVITS/GPT_weights:/workspace/GPT_weights
- /u01/workspace/models/GPT-SoVITS/tools/asr/models:/workspace/tools/asr/models
- /u01/workspace/models/GPT-SoVITS/tools/uvr5/uvr5_weights:/workspace/tools/uvr5/uvr5_weights
運行
docker-compose up -d
幾個重要的頁面:
下面幾個頁面并非啟動后都可以直接訪問,需要根據需要點選相應的啟動按鈕后方可訪問。
主頁面: http://127.0.0.1:9874/
UVR5人聲伴奏分離&去混響去延遲工具 :** http://127.0.0.1:9873/**
TTS推理WebUI:http://127.0.0.1:9872/
語音文本校對標注工具:** http://127.0.0.1:9871/**
操作演示:
本操作過程僅僅演示如何快速的開始,讓平臺真正用起來,需要完整了解相關的內容的請參考和研究官方提供的相關手冊。
第一步: 進主頁面:
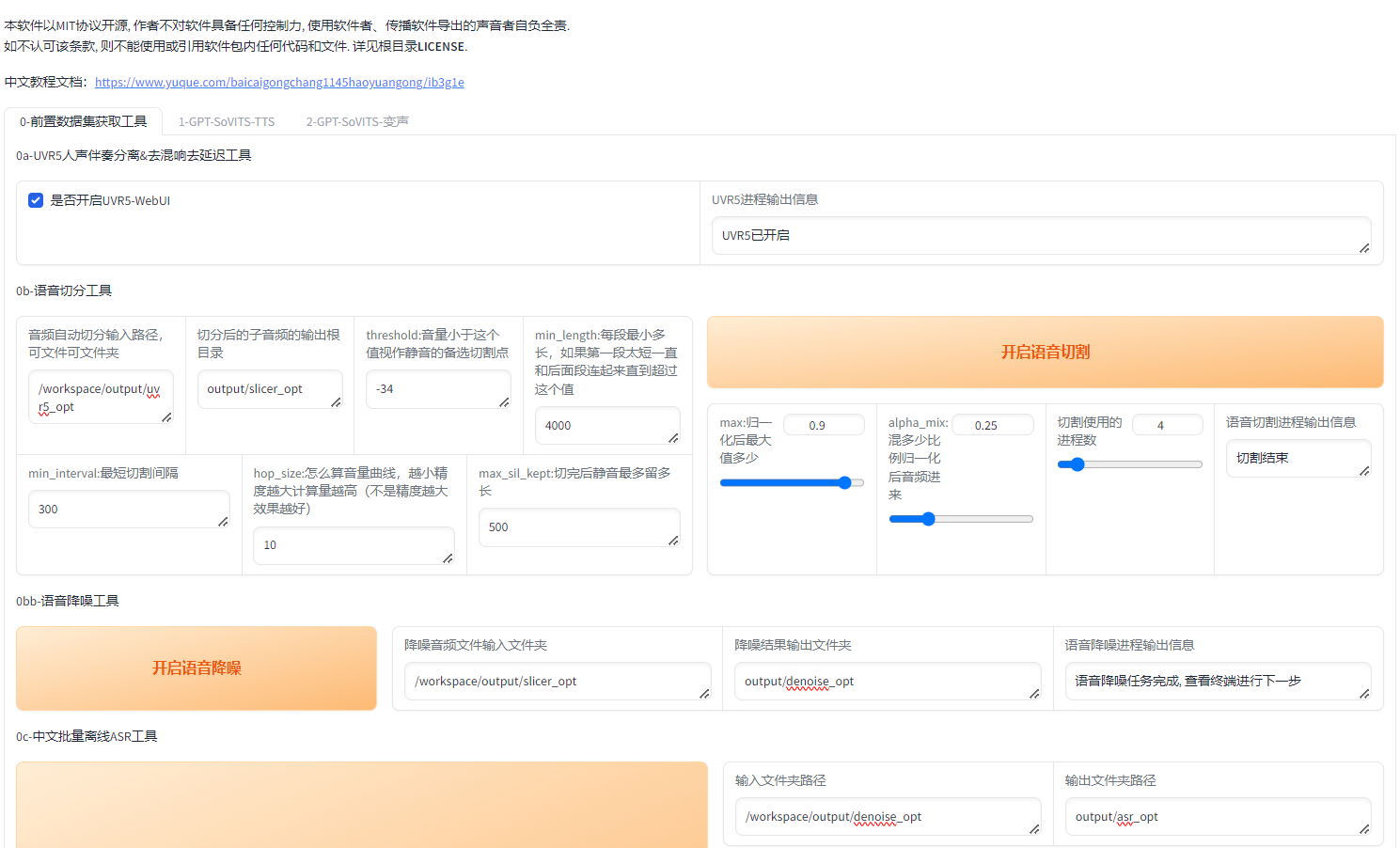
第二步: 開啟UVR5-WebUI 進入到URV5 界面:
上傳音頻文件,選擇模型: HP3, 點擊轉換, 轉換成功后,輸出文件默認會存放在/workspace/output/uvr5_opt

第三步: 返回主界面,分別執行如下幾個步驟

0b-語音切分工具
0bb-語音降噪工具
0c-中文批量離線ASR工具
這三步中,不要更改輸出文件夾,每一步的輸入信息均為上一步的輸出目錄。
0d-語音文本校對標注工具
勾選【是否開啟打標WebUI】后訪問http://127.0.0.1:9871/

第四步: 進入主界面,點擊第二個Tab頁:
直接輸入文本標注文件地址:點擊一鍵三聯即可,其他參數熟練之后隨意調整。

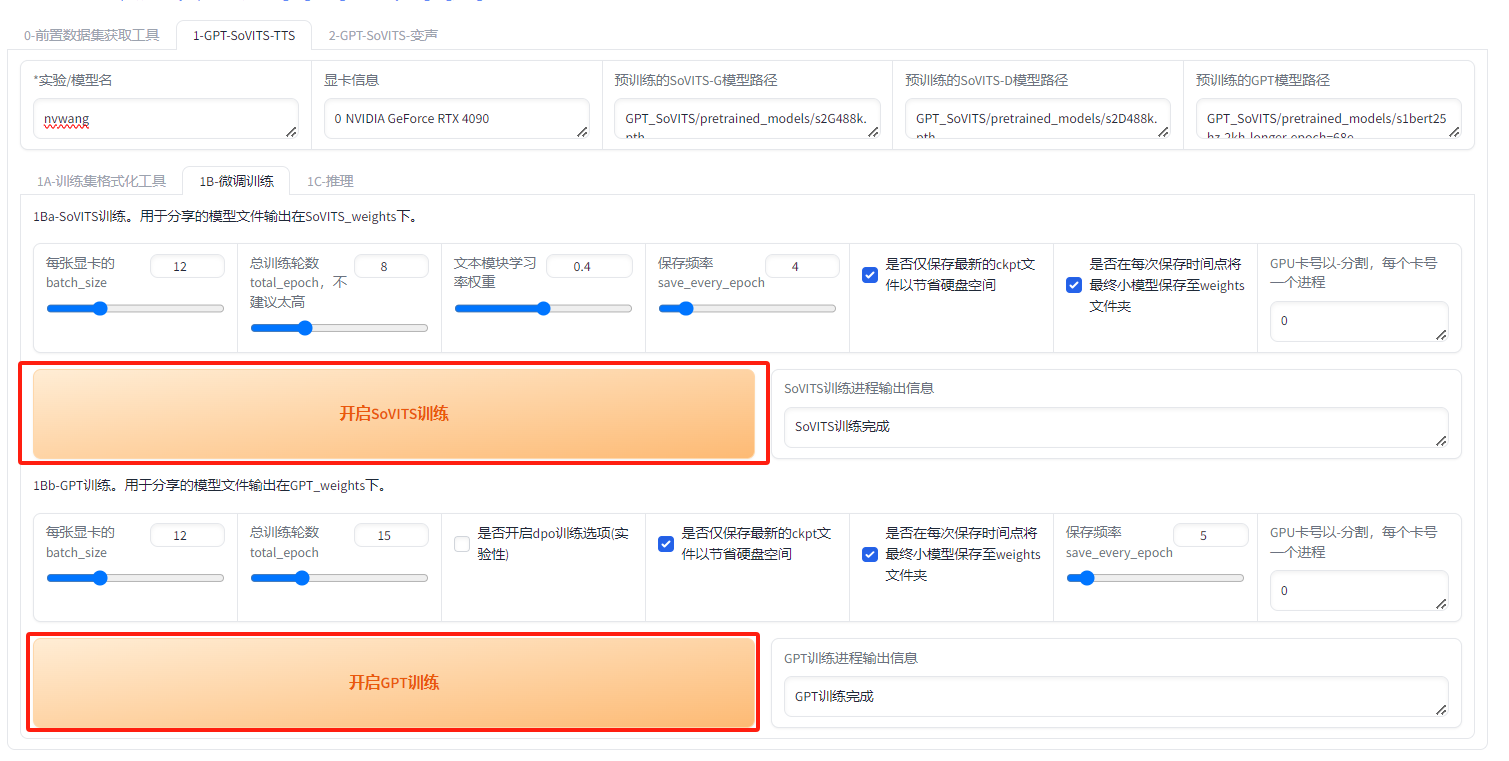
第五步:微調訓練
直接點擊頁面中的兩按鈕,等待一段時間即可完成微調:
第六步:推理
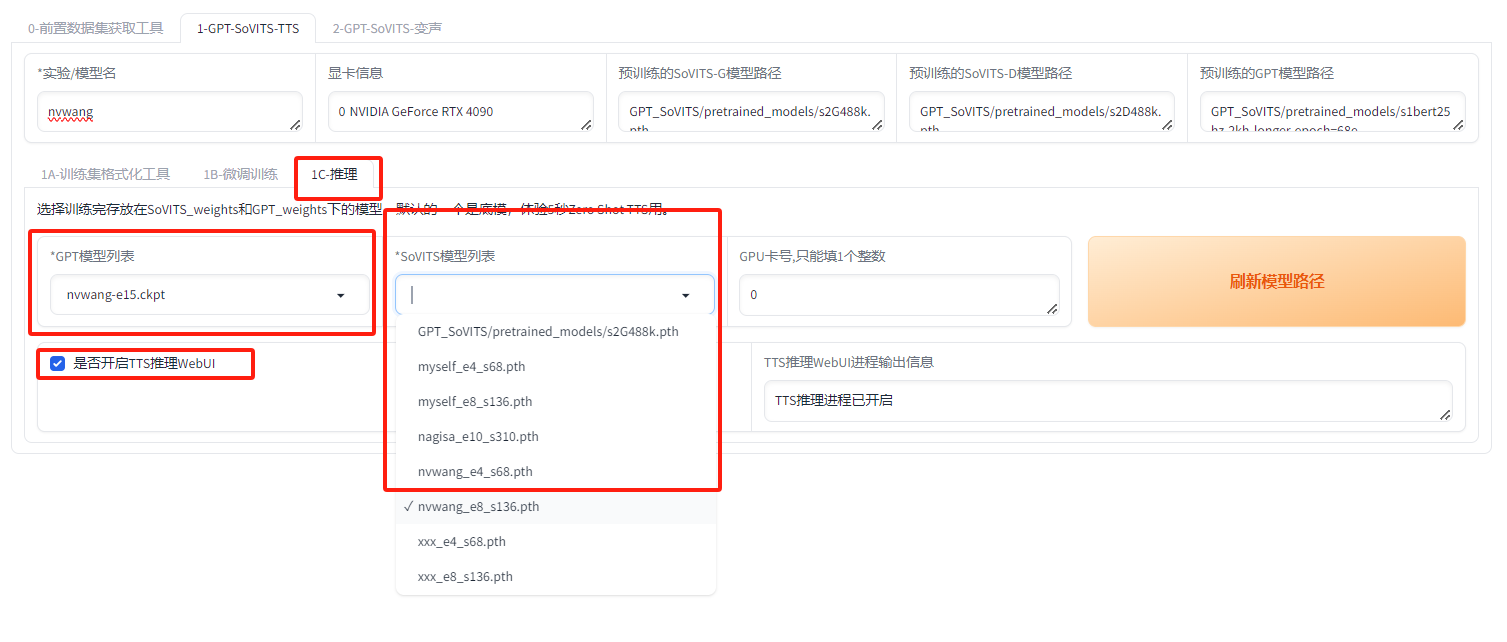
刷新模型路徑,直接選擇剛剛微調出來的模型,可能有多個,注意選擇合適的模型,然后再開啟推理界面:
http://127.0.0.1:9872/
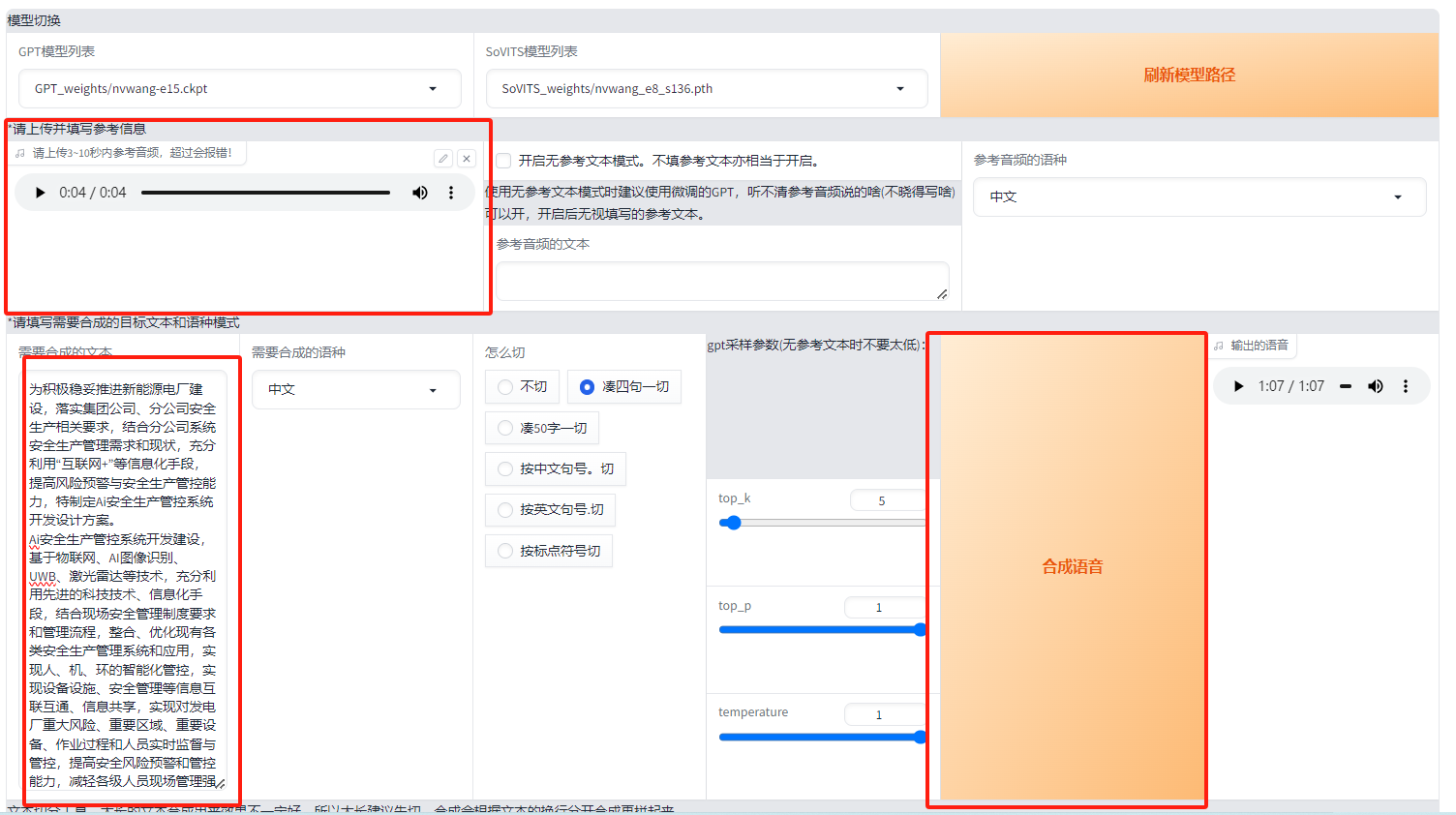
選擇參考模型,參考模型文本(可不填),需要合成的文本, 點擊合成語音,即可完成語音克隆。
【Qinghub Studio 】更適合開發人員的低代碼開源開發平臺
【QingHub企業級應用統一部署】
【QingHub企業級應用開發管理】
【QingHub** 演示】**
【https://qingplus.cn】


)






)
![[CocosCreator]Android的增加AndroidX的動態權限](http://pic.xiahunao.cn/[CocosCreator]Android的增加AndroidX的動態權限)






--父組件傳子組件)

、內存使用)