在人工智能與自然語言處理交匯點,有一種技術正悄然改變與數據交互的方式——將日常語言轉化為精準SQL查詢。這一“text-to-sql”轉換任務,使非專業人士也能輕松駕馭復雜的數據庫操作,極大地拓寬了數據應用的邊界。
然而,現有前沿方法往往依賴于封閉源代碼的大型語言模型,它們雖然功能強大,卻伴隨著模型透明度缺失、數據隱私風險增大以及高昂推理成本等難題。有沒有既開放、高效又安全的替代方案呢?魯班模錘今天帶來的論文《CodeS: Towards Building Open-source Language Models for Text-to-SQL》正在嘗試破局。

課題背景
Text-to-sql的任務是指將用戶的自然語言的提問(文本)轉化成能在數據庫上執行的結構化查詢查詢語言(SQL)。下圖為對某一 “銀行金融”數據庫提出自然語言的問題,再轉化為數據庫查詢語言(SQL)的過程。這個過程使得不熟悉SQL或數據庫結構的用戶也能夠使用自然語言與數據庫交互。

依賴部分現有的大模型也能實施,例如閉源的大語言模型 DIN-SQL(基于GPT-4)、SQL-PaLM(基于PaLM-2)或是C3(基于GPT-3.5)。盡管這些模型在Text-to-sql性能上表現出色,但也可能存在以下問題:
-
閉源模型隱藏了落地的具體架構以及訓練/推理細節,阻礙了針對特定應用的持續開發。(這里突然想起來最近有位大佬說某大廠堅持閉源,回頭另文點評)
-
通過API調用這些云端模型可能會帶來數據隱私風險,因為必須將數據發送給模型提供商。
-
大多數閉源模型具有大量參數(例如基于GPT-3.5則有175B個參數),導致顯著的推理開銷,通常反映在調用API的花銷上
綜上所述,研究者推出了專為SQL生成而設計的開源語言模型CodeS。其特點是體量小,與ChatGPT和GPT-4比小10-100倍,而性能上卻可以比肩SOTA。
知識補充:SOTA是“State of the Art”的縮寫,這個術語通常用于描述某個領域或技術中當前最先進的成果或最高水平的性能。

基座模型StarCoder
StarCoder 和 StarCoderBase 是針對代碼的大語言模型 (代碼 LLM),模型基于 GitHub 上的許可數據訓練而得,訓練數據中包括 80 多種編程語言、Git 提交、GitHub 問題和 Jupyter notebook。與 LLaMA 類似,基于 1 萬億個詞元訓練了一個約15B參數的模型。此外還針對一個35B詞元的Python 數據集對 StarCoderBase 模型進行了微調,從而獲得了一個稱之為 StarCoder 的新模型。當然這個系列有1B/3B/7B/15B四種規模的基座模型。


CodeS結構拆解
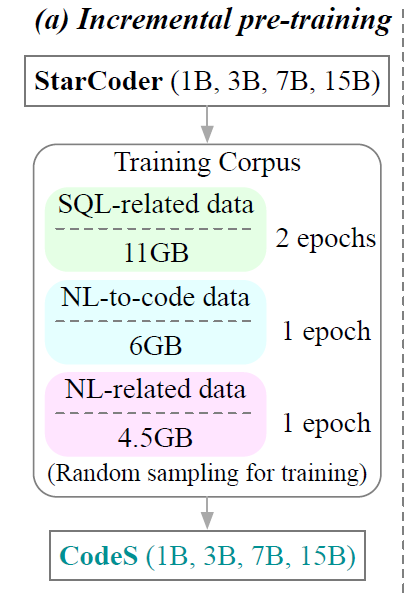
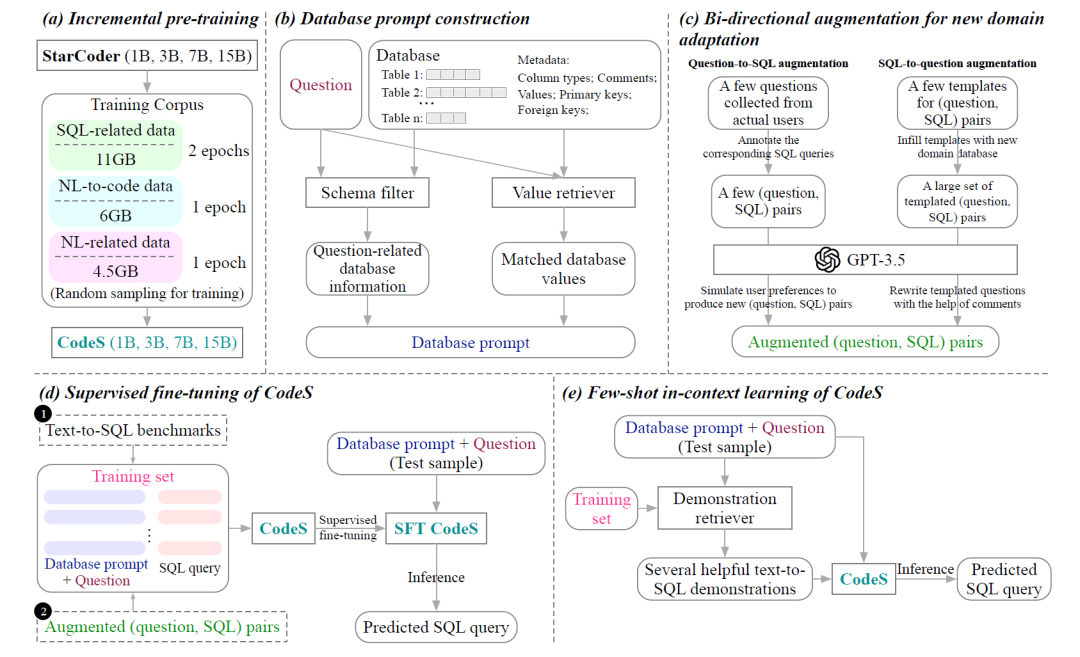
首先A階段為了提高現有語言模型的SQL生成和自然語言理解能力,研究人員采集了新語料庫,該語料庫由來自不同來源的11GB SQL相關數據、6GB NL-to-code(自然語言轉代碼)數據和4.5 GB NL相關數據集組成。基于StarCoder,采用該語料庫進行增量預訓練,并獲得預訓練的語言模型CodeS(StarCoder按照上文而言擁有1B、3B、7B和15B 4種規模)。
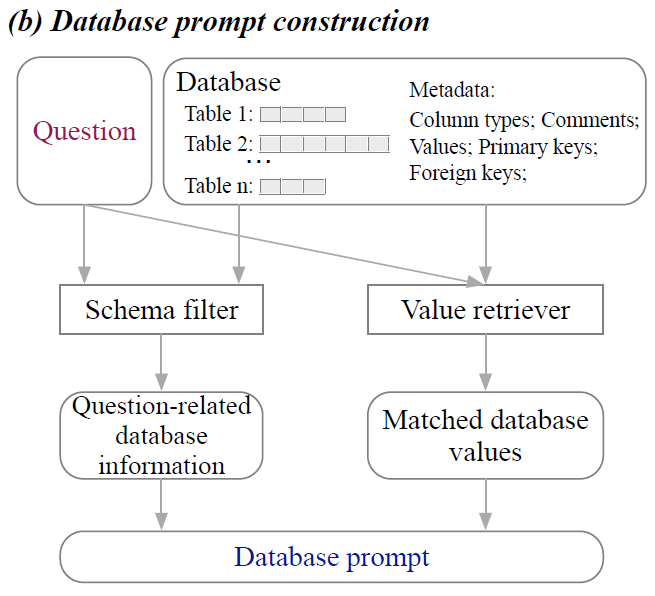
緊接著來到了B階段,研究人員提出一種全面的數據庫提示構建方法來生成高質量的數據庫提示。該策略主要包含模式過濾器和值檢索器。模式過濾器是根據給定的問題消除不相關的表和列。值檢索器經過定制可以提取與問題相符的潛在有用的數據庫值。?除了表名和列名之外,還合并了各種元數據,包括數據類型、注釋、代表性列值以及主鍵和外鍵的信息。?如此為文本到SQL的轉化提供更加真實而且豐富的上下文。

這個時候來到了C階段,畢竟不同的客戶擁有不同的業務數據庫,但是又無法提供足夠多的適配樣本。因此研究人員提出了一種雙向數據增強方法,為新應用場景自動化的生成大量新語料(提問和對應的SQL語句)。?那么如何操作呢?在文本-SQL方向的語料方面,從現實的業務場景入手需要人工標記一些數據項,再交由GPT-3.5模擬生成進行語料庫擴展。而在SQL-文本方向的語料方面則需要研究人員從現有的文本-SQL的基準中提煉模板,然后用新的業務數據庫填充模板,然后使用 GPT-3.5 來自動的精煉語料。?這種雙向策略創建了最小人力標注投入,但是能夠構建一個強大和好用的訓練集。
|
|
|
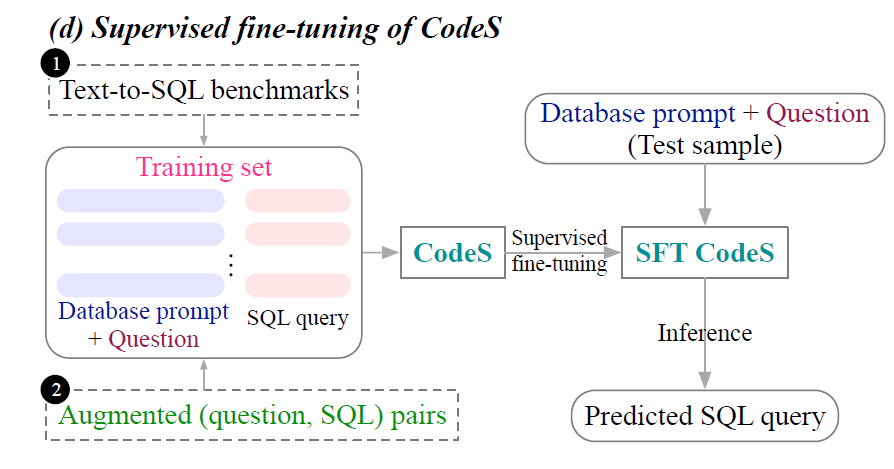
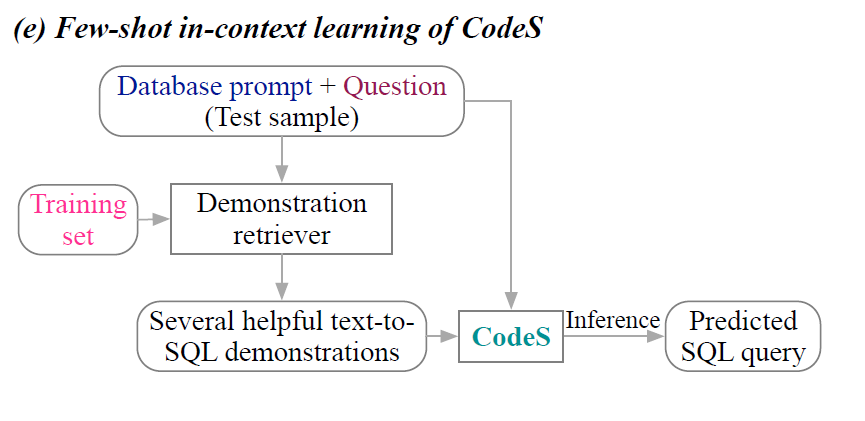
若有著豐富的訓練數據,CodeS出現的D階段就可以執行,利用SFT進行模型訓練(后續會解釋,這里可以理解為對于大模型的部分參數進行微調)。
相反,若訓練數據有限,那么只能使用不改變模型參數的In-Context學習(階段E),只能提供一些文本到sql的演示,在不微調模型的情況下利用大模型的學習和模仿能力快速給出答案。
在這兩種模式種,Incremental pre-traning(階段A)和Database prompt construction(階段B)都是其基石,而在SFT策略模式中還需要Bi-directional augmentation for new domain adaptation(階段C)的輔助。下篇文章將開啟具體組件的詳細解讀。














![[牛客網]——C語言刷題day4](http://pic.xiahunao.cn/[牛客網]——C語言刷題day4)


)

