基于Django實現的(bert)深度學習文本相似度檢測系統設計
-
開發語言:Python
- 數據庫:MySQL
- 所用到的知識:Django框架
- 工具:pycharm、Navicat、Maven
系統功能實現
-
登錄頁面
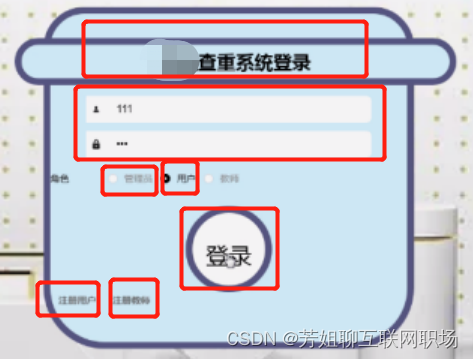
注冊頁面:用戶賬號,密碼,確認密碼,用戶姓名,聯系方式

主頁面:文件管理模塊
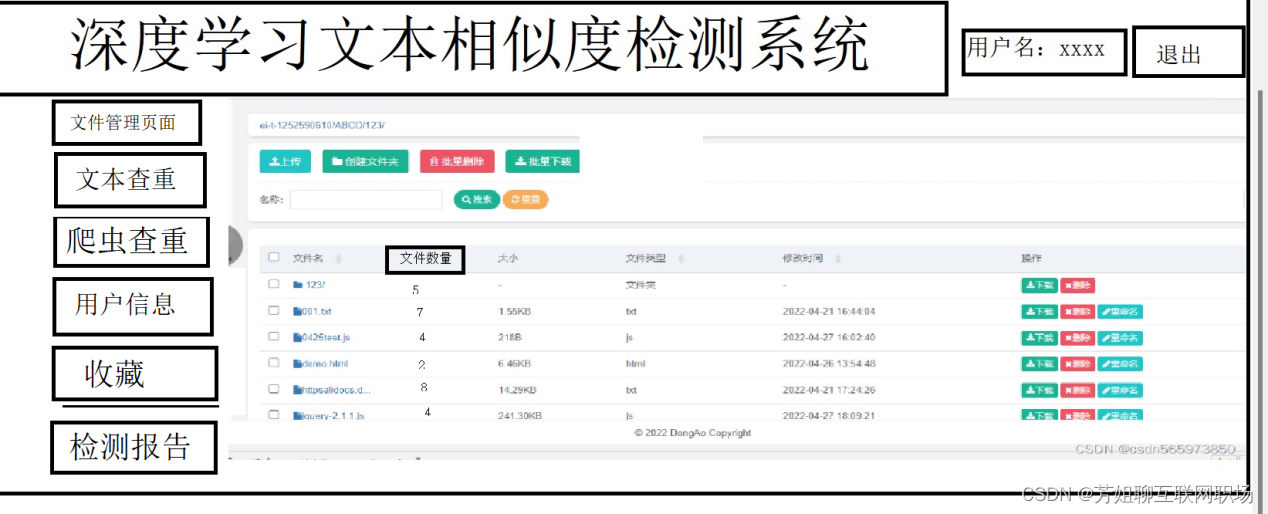

上傳功能
(3)批量刪除文件夾功能,可選
![]()
(4)批量下載文件夾,可選
(5)搜索功能(文件夾)
(6)單獨文件夾按鈕下載
(7)收藏功能按鈕

文件屬性:下載按鈕,編輯按鈕(文本內增減刪),刪除按鈕,收藏按鈕,文本內容查詢
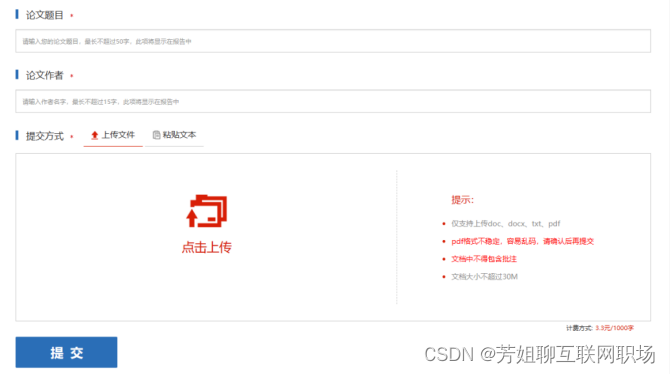
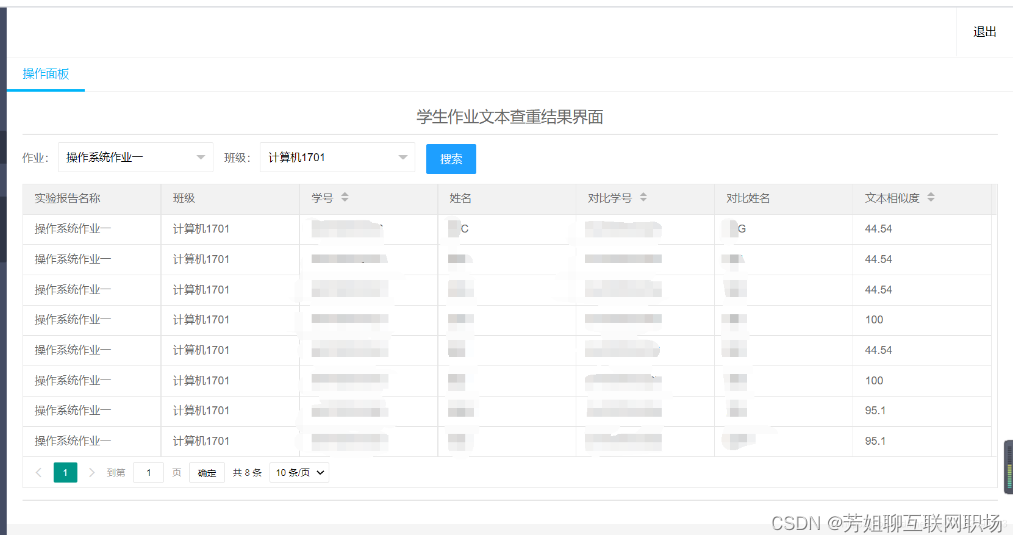
 文本查重模塊
文本查重模塊
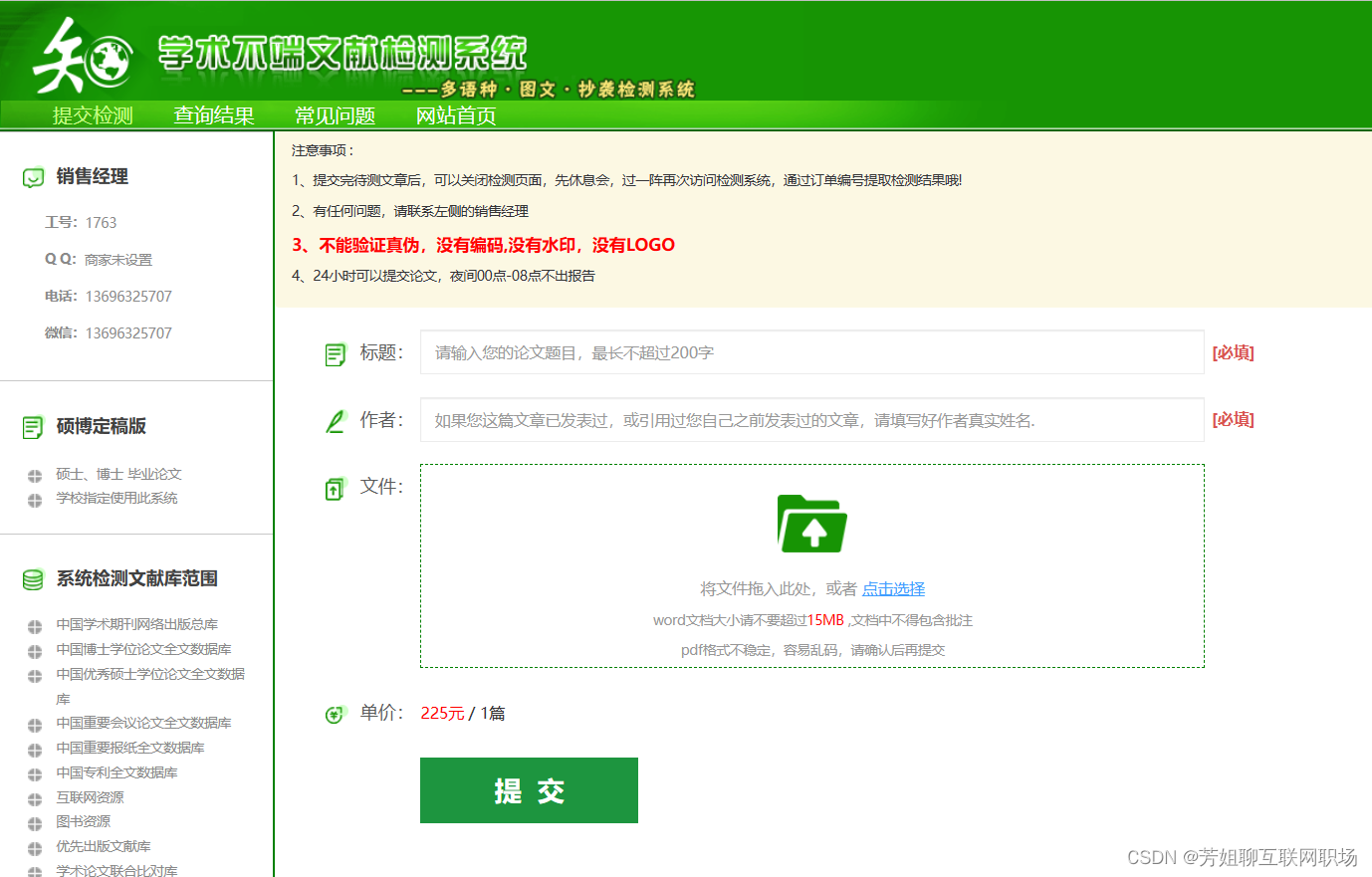
收藏模塊;用戶收藏的文件夾與文件:
任務欄屬性:文本名稱,作者名稱,文件大小,修改日期,
文件夾屬性:本文本查看,刪除文件,修改文本內容,并保存修改的內容,下載文本
網頁查重-(爬蟲):文本查重網頁版 爬取百度搜索結果頁全部鏈接內容


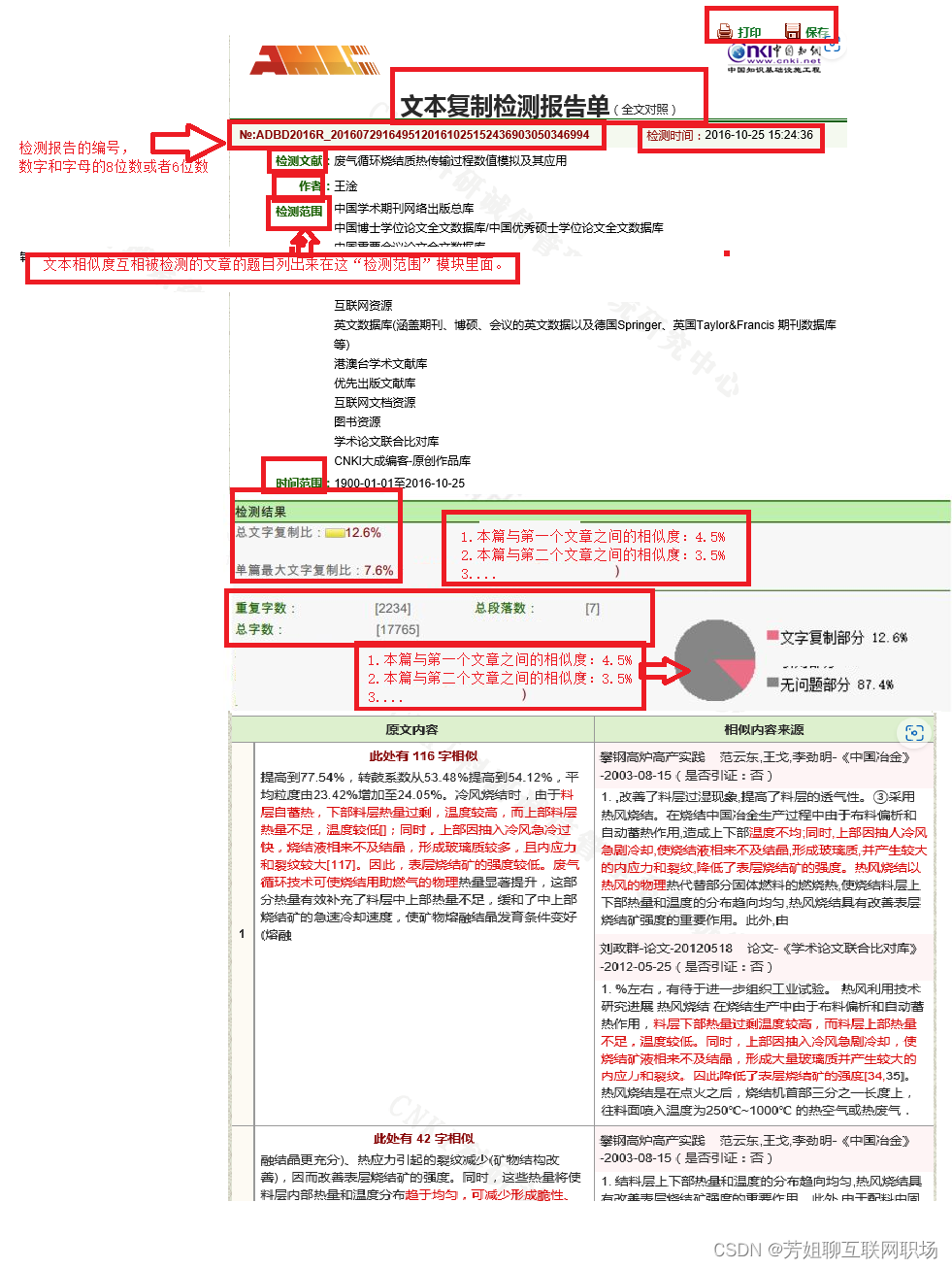
文本相似度的檢測報告的pdf格式

檢測報告的形成:pdf格式
檢測報告內容是:1.可以打印,2.保存本地;
- 檢測報告編號:數字和字母組成,6位數;
- 文本題目,作者,檢測范圍(互相被檢測的文本題目)
- 檢測時間,時間范圍(有效時間用戶自己輸入的)
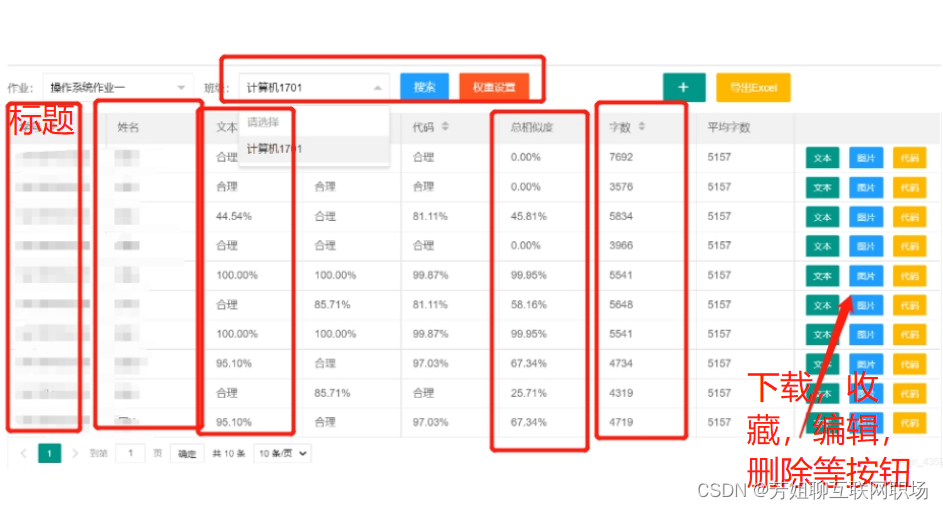
- 檢測結果
- 總文本總數相似度:12.6%
- 本篇與第一個文章之間的相似度: 4.5%
- 本篇與第二個文章之間的相似度: 3.5%
- .................
- 統計出各個文本之間相似度的統計圖,
- 原文內容與相似度來源的文本之間的對比列出,
以下圖片參考:
檢測報告的任務欄屬性:文本名稱,作者名,文件大小,報告生成時間,報告下載按鈕,報告搜索框(按照文本名與作者),總文本相似度,報告刪除按鈕,
檢測報告(pdf格式)以下的圖片一比一還原,
檢測報告內容是:1.可以打印,2.保存本地;
- 檢測報告編號:數字和字母組成,6位數;
- 文本題目,作者,檢測范圍(互相被檢測的文本題目)
- 檢測時間,時間范圍(有效時間用戶自己輸入的)
- 檢測結果
- 總文本總數相似度:12.6%
- 本篇與第一個文章之間的相似度: 4.5%
- 本篇與第二個文章之間的相似度: 3.5%
- .................
- 統計出各個文本之間相似度的統計圖,
- 原文內容與相似度來源的文本之間的對比列出,
以下圖片參考:
檢測報告的任務欄屬性:文本名稱,作者名,文件大小,報告生成時間,報告下載按鈕,報告搜索框(按照文本名與作者),總文本相似度,報告刪除按鈕,
檢測報告(pdf格式)以下的圖片一比一還原,
8用戶信息:看到個人的基本信息,上傳個人圖
需要源代碼或者二次開發的,請聯系



SPI數據的傳輸)
)
)





)

![[HUBUCTF 2022 新生賽]ezsql](http://pic.xiahunao.cn/[HUBUCTF 2022 新生賽]ezsql)






)