數據庫中的引擎
常用的引擎有InnoDB、MyIsam、Memory三種。
MyIsam:組織形式分為三種:
frm文件存儲表結構、MyData文件存儲表中的數據、MyIndex文件存儲表的索引數據。是分開存儲的。
Memory:基于內存的,訪問速度快,但是后面可能用的都是Redis。
重點來說說InnoDB存儲引擎吧:
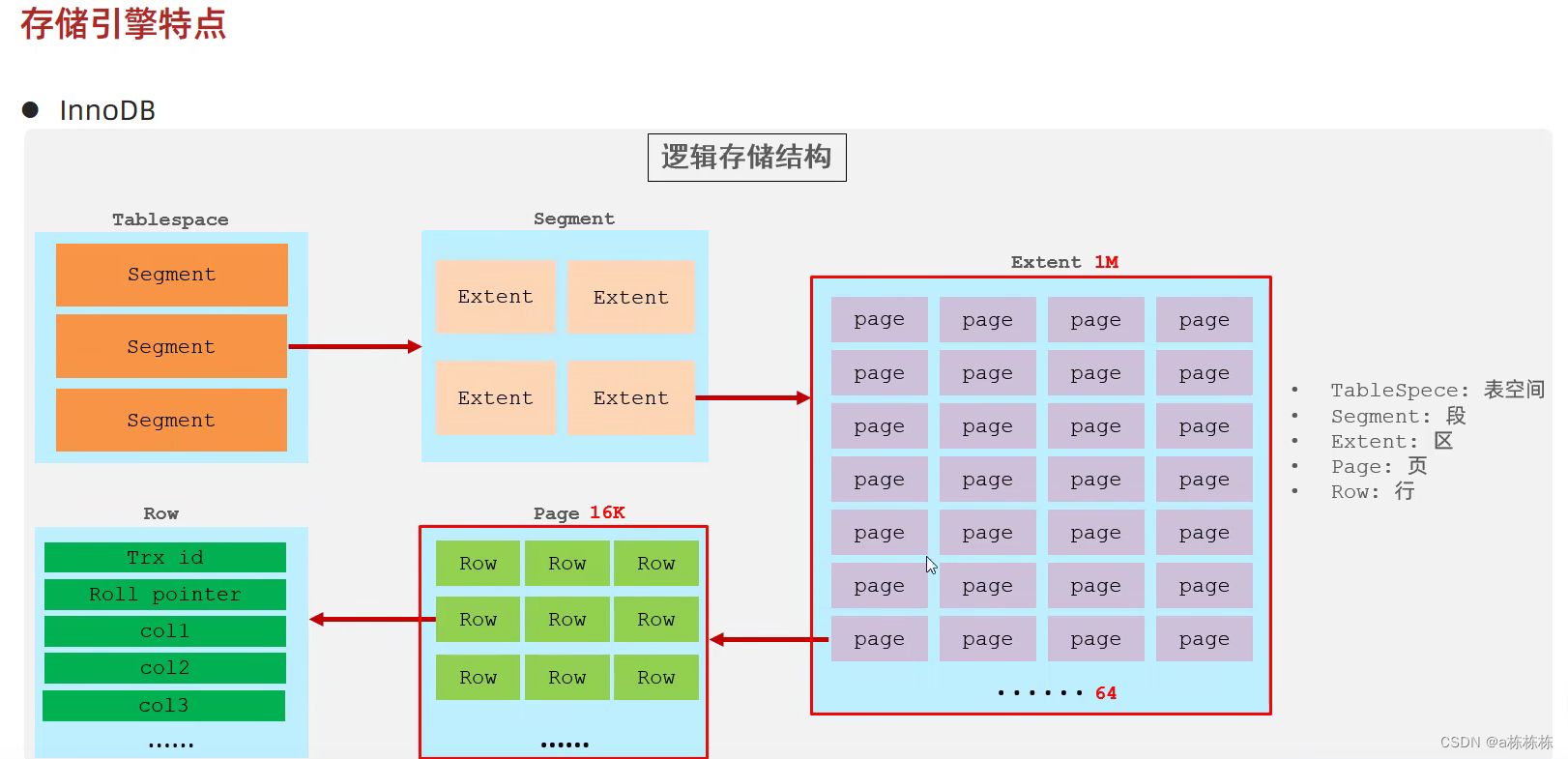
MySQL默認的存儲引擎,DML操作支持事務。一個ibd文件對應一張表嘛。它在一個TableSpace的表空間這樣一個邏輯結構中,按大小分為段、區、頁這樣的。一個段有四個區,一個區有連續64隔數據頁,這個數據頁就是InnoDB下最基本的數據單位嘛,然后數據頁的大小是16K,數據頁里面才是你存的這種行記錄,它都是往數據頁里面放的。
InnoDB有三個特點嘛:支持外鍵、還有事務、還有行級鎖,這是它的幾個特點。
它也是一個組織索引表,這一塊就跟索引掛鉤了嘛,它每個節點就是一個數據頁。然后根據組織形式又能分為聚集索引和二級索引嘛,根據不同的這種索引,字段進行組織,排放。
它不僅存放表結構、數據。還會存放該表對應的索引信息。
索引
一種用于提高數據庫查詢性能的有序的數據結構。通過它呢,數據庫引擎可以快速定位到存儲表中的特定數據,而不必逐行遍歷整個表。
聚集索引和二級索引
在InnoDB存儲引擎中,根據索引的存儲形式,分為聚集索引(指針)和二級索引(二級指針)
索引結構中,葉子結點存放的是整行的行數據。必須有,且只有一個。
索引結構中,葉子結點存放的是對應的主鍵。可以有多個。除了聚集索引以外的索引都是二級索引
B+樹和B樹的結點:
B+樹非葉子節點只存儲key,不存儲值,直到葉子節點才存儲值,非葉子節點主要起到索引作用,葉子節點包含了所有插入的元素。
B樹每個結點即存值又存key,我們知道,一個數據頁大小是16K固定的嘛,如果又存節點又存Key,就會導致每個節點存儲的key的個數少,進而導致樹的層數很深。這也是不用B樹去存儲索引的原因。
不用Hash存儲索引的原因:
不用Hash,因為我們數據庫查詢經常會涉及到范圍查詢嘛,而Hash索引只能做到精確查找,不能進行范圍查找,同時Hash不能對數據進行排序操作。
聚集索引選取規則
如果存在主鍵,主鍵就是聚集索引。
如果沒有設置主鍵,默認第一個唯一索引就是聚集索引。
如果又沒有主鍵,又沒有唯一索引,那么InnoDB會自動生成一個rowid作為隱藏的聚集索引。
對于葉子節點:聚集索引存放的是一行的全部信息,而二級索引存放的是主鍵值,通常會涉及到回表查詢嘛。(然后通過主鍵值,再回表)
回表查詢
先介紹一下聚集索引和二級索引的區別;
就是我們查詢條件一般是通過二級索引,這樣拿到了主鍵值,再拿到該主鍵值,再進行一次回表查詢。
覆蓋索引
查詢使用了索引,同時返回的列,不需要回表查詢,即一次查詢就能全部找到了。如select id,name from a where name = jack ,這里id是主鍵值,name是二級索引,通過二級索引查到了id,也就是主鍵值,不需要回表查詢,所以叫做覆蓋索引。因此盡量不要使用select *,因為這樣往往會做到回表查詢,影響查詢性能。
索引失效的場景
用到復合(聯合)索引的時候,違反最左前綴法則
【查詢的時候必須從索引的最左列開始,如果跳過了中間某一列,則跳過之后的索引都失效】
當查詢條件有范圍查詢的時候,其右邊的條件,如where id > 1 and xxx 【and后面的索引都會失效】
在索引列上進行運算操作
以%開頭的模糊查詢
隱式類型轉換(如表中數據是字符串類型,而你給他一個int類型,即不加單引號,索引會失效)
索引設計原則
①數據量大,且查詢比較頻繁的表建立索引,如果一個表全是增刪改的操作,就沒必要加索引了
②常作為查詢條件where、order by、group by操作的字段建立索引,如果一次查詢條件的字段為多個,也可以考慮設置聯合索引,但記住它們的順序不能改變,要遵守最左配對原則
③選擇區分度高的列作為索引,像性別男女就沒必要。
④如果是字符串類型的字段,且長度較長,可以針對字段的特點,建立前綴索引。
⑤盡量使用聯合索引,減少單列索引,查詢時,聯合索引很多時候可以覆蓋索引,避免回表,提高查詢效率。
⑥控制索引的數量,索引越多,維護索引結構的代價也越大,會影響增刪改的效率
事務
對于單獨的DQL(數據查詢語句)我們一般不會說去考慮事務,如果是設計到DDL、DML比如insert、update、delete,為了保證操作的原子性,即同時成功或同時失敗。因為事務是一個不可分割的單元嘛,并且如果有的成功執行,有的沒成功,那就會造成很大的問題,也因此引入了事務的機制。
四大特性:
原子性:保證一個事務中的多條操作語句,要不同時成功,要不同時失敗。不會處于中間狀態。
一致性:事務執行的結果是使數據庫從一個狀態變到另一個一致性狀態。
隔離性:涉及到不同的隔離機制,數據庫中有四種隔離機制,讀未提交、讀已提交、可重復讀、串行化。使得每個事務都獨立執行嘛。
持久性:因為數據最終是要落盤的,持久化保存數據嘛。
)





)












