文章目錄
- 一、排序的相關概念
- 二、排序類型
- 三、排序算法實現
- 插入排序
- 1.直接插入排序
- 2.希爾排序
- 選擇排序
- 3.簡單選擇排序
- 4.堆排序
- 交換排序
- 5.冒泡排序
- 6.快速排序
- 遞歸實現
- 非遞歸實現
- 7.歸并排序
- 遞歸實現
- 非遞歸實現
- 8.計數排序
- 四、總結
一、排序的相關概念
排序:根據數據中關鍵字的大小,來進行升序或者降序排列。比如按照英文字母順序排序,按照商品價格或者銷量來排序等。
穩定性:如果存在兩個或多個相同的數據,若經過排序后,它們的相對次序保持不變,則稱這種排序算法是穩定的;否則就是不穩定的。
內部排序:數據元素全部放在內存中的排序。
外部排序:數據元素太多,不能同時放在內存中,根據排序過程的要求不能在內外存之間移動數據的排序。
本篇介紹的是內部排序。
二、排序類型

三、排序算法實現
可用各種排序算法跑這個OJ—>排序OJ鏈接
插入排序
1.直接插入排序
基本思想:將待排序的元素逐個插入到一個已經排好序的有序序列中,直到所有元素插入完為止,得到一個新的有序序列 。
初始序列是無序的,怎么將待排元素插入有序序列呢?
第一個元素本身可以看做一個有序序列,所以從第二個元素開始,從后往前遍歷比較,插入前面已經排好的有序序列中。將大于該元素的所有元素位置向后挪動一位,在比較的過程中邊比較邊挪動。
以升序為例

可以發現,假設待排序的序列長度為n,插入排序需要進行n-1趟。
時間復雜度:O(N2)。趟數為n-1,每趟待排序元素需要在前面的有序序列中從后往前比較挪動數據。
最好情況:O(N);有序,判斷一次直接break出來,總共n-1趟,每趟不用挪動數據,量級為。
最壞情況:O(N2);逆序,每趟都頭插,次數1+2+3+…N-1,所以時間復雜度量級是。
元素集合越接近有序,直接插入排序算法的效率越高。
空間復雜度:O(1)。 沒有使用額外空間。
穩定性:穩定。 如果是大于等于某個位置的元素,則在其后面插入,相對位置不變。
//插入排序 穩定 時間復雜度O(N^2) 空間復雜度O(1)
void InsertSort(int* a, int n)
{for (int i = 1; i < n; i++){int end = i - 1;//有序序列的末尾位置int x = a[i];//待排序元素//將x插入到[0, end]區間中,并保持有序while (end >= 0){if (x < a[end]){a[end + 1] = a[end];//往后挪一個位置end--;}else{break;}}//while循環結束有兩種情況://1.end = -1也即x比前面所有數都小;//2.x >= a[end] 這兩種都是在end后面插入a[end + 1] = x;}
}
2.希爾排序
希爾排序法又稱縮小增量法。是對插入排序的優化方案,效率比直接插入排序要高。
基本思想:將待排序列以間隔gap劃分為gap個不同的組,對同組內的元素進行直接插入排序,然后縮小gap,重復上述分組和排序,直到gap=1,也就是直接插入排序,就會得到一個有序序列。
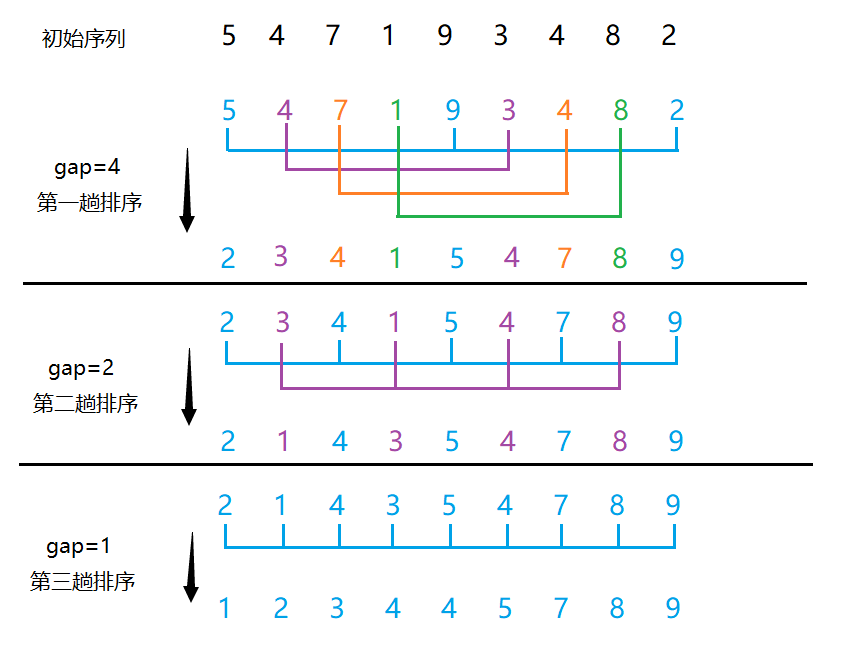
gap取多少合適?
gap初始值一般取n / 2,每趟排序完gap / 2,直到gap=1,即直接插入排序,此時序列接近有序,直接插入效率O(N)。gap也可以每次 ÷ 3,只要保證gap最后一次能取到1。
排升序,gap越大,大的數更快到后面,小的數更快到前面,但是越不接近有序;gap越小,越接近有序,gap=1時,就是直接插入排序。
時間復雜度:平均為O(N1.3)。希爾排序的時間復雜度至今還沒有精確的分析結果,經過大量的實驗推出,n在某個特定范圍內,希爾排序的比較和移動次數約為N1.3。
空間復雜度:O(1)。 沒有使用額外空間。
穩定性:不穩定。 希爾排序是分組排序的,且每個組內的數據不連續,無法保證相同數據的相對位置不被改變。比如上圖中紫色4和橙色4在第一趟排序后,相對位置就發生了變化,所以希爾排序是不穩定排序。
//希爾排序 不穩定 效率比直接插入排序高
void ShellSort(int* a, int n)
{//gap > 1 預排序//gap == 1 直接插入排序int gap = n;while (gap > 1){//gap = gap / 3 + 1;//也可以,除3后別忘了+1,否則gap為2時除3結果為0gap /= 2;for (int i = gap; i < n; i++){int end = i - gap;int tmp = a[i];//將x插入到[0, end]區間中,保持有序while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];//往后挪一個位置,方便x插入end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
選擇排序
3.簡單選擇排序
基本思想:每次從剩下的待排序列中標記最小(最大)值的下標位置,遍歷完后存放到未排序列的起始位置(也是已排好的序列的下一個位置),直到全部待排序的數據排完。
實際上,我們每趟可以選出兩個值,一個最大值,一個最小值,然后分別與序列的起始和末尾元素交換。這樣排序的趟數可以減少一半,但比較和交換的次數會×2,整體效率沒有太大變化。

時間復雜度:O(N2)。一共選擇n趟,每趟與n-1個數進行比較;如果是每次同時選出最大值和最小值,一共需要n/2趟,每趟比較2×(n-1)次,量級都是O(N2)。
選擇排序沒有最好情況和最壞情況,不管有序還是逆序,都需要進行O(N2)次比較。所以選擇排序的性能很差。因為不管是有序還是逆序,選擇排序的效率都是最差的O(N2)。
空間復雜度:O(1)。 沒有使用額外空間。
穩定性:不穩定。 因為每次是將待排序列的起始位置與序列中最小值(或最大值)進行交換,只保證了最小值的穩定性,但起始位置的穩定性可能會被破壞。(如果同時找出最大值并交換,例如圖中一樣,最小值表示的元素的穩定性也可能會被破壞,比如上圖中第二趟排序4的相對位置就發生了變化)
//選擇排序 不穩定 時間復雜度O(N^2) 空間復雜度O(1)
void SelectSort(int* a, int n)
{int l = 0, r = n - 1;while (l < r){int minPos = l, maxPos = l;//標記最小值和最大值的下標for (int i = l + 1; i <= r; i++){if (a[i] < a[minPos])minPos = i;if (a[i] > a[maxPos])maxPos = i;}//C語言沒有庫函數,交換函數需要自己寫Swap(&a[l], &a[minPos]);//如果最大值maxPos與左邊界l重合,在l與minPos交換后,最大值轉移到了minPos位置if (l == maxPos)maxPos = minPos;Swap(&a[r], &a[maxPos]);l++;r--;}
}
4.堆排序
堆排序在數據結構——堆中已經詳細講過了,這里可能講的沒有那么細致。想詳細了解堆的具體原理和使用可以看看這篇博客。
堆排序是利用數據結構堆(Heap)的特性所設計的一種算法,是選擇排序的一種。它是通過堆來選擇數據。
基本思想: 依次將將堆頂的數據與堆尾的數據交換,然后向下調整成堆,重復上述步驟直到數據完全有序。比如一個大根堆,我們取出堆頂元素(最大數)與最后一個數交換,交換后的最大數不看作在堆里面,那么堆頂元素的左右子樹仍滿足堆的性質,堆的結構并沒有被破壞,然后堆頂元素向下調整成堆,即可選出第二大的數,以此類推到最后一個元素,就可以成功實現堆排序了。
升序:建大堆
降序:建小堆
時間復雜度:O(N*logN)。向下調整建堆的時間復雜度為O(N)(過程在數據結構堆篇),堆頂元素一共進行n-1次交換,每次交換后向下調整為O(logN),所以最大量級是O(N*logN)。
堆排序也沒有最好情況和最壞情況,堆排序不受初始序列順序的影響,有序或者逆序時間復雜度都是O(N*logN)。
空間復雜度:O(1)。 沒有使用額外空間。
穩定性:不穩定。 建堆時數據的相對順序就可能被改變,在選數時堆頂與堆尾數據交換也可能導致穩定性被破壞。
//C語言沒有庫函數,交換函數需要自己寫
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}
//堆排序向下調整(排升序建大堆)
void AdjustDown(int* a, int n, int parent)
{int child = 2 * parent + 1;//先賦值左孩子while (child < n){//右孩子存在且右孩子比左孩子更大if (child + 1 < n && a[child + 1] > a[child]){child++;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = 2 * parent + 1;}else{break;}}
}//堆排序 不穩定 時間復雜度O(N*logN)
void HeapSort(int* a, int n)
{//倒著調整,從最后一個非葉子結點開始向下調整建堆 效率O(N)for (int i = (n - 2) / 2; i >= 0; i--){AdjustDown(a, n, i);}//O(N*logN)int end = n - 1;//堆的有效長度while (end > 0){Swap(&a[0], &a[end]);//堆頂與堆尾元素交換AdjustDown(a, end, 0);//堆頂再向下調整,范圍[1,end]end--;}
}
交換排序
5.冒泡排序
基本思想:從前往后遍歷序列,每相鄰兩個數比較大小,前一個比后一個大就交換,直到將最大元素交換到末尾位置,繼續從前往后遍歷,重復上述操作,直到所有元素有序。
冒泡排序和選擇排序一樣都非常容易理解,也不上圖演示了(畫圖太費時間),一切都在代碼中。
時間復雜度:O(N2)。一共n趟,每趟比較交換次數遞減,總共比較1+2+3+…+n-1次,量級為O(N2)。
最好情況:O(N) ;有序情況下只用進行一趟比較(flag標記),就退出循環。
最壞情況:O(N2);每趟都進行交換。
空間復雜度:O(1)。 沒有使用額外空間。
穩定性:穩定。 前后兩個元素相同則不用交換,相對位置沒有改變。
//冒泡(交換)排序 穩定 時間復雜度O(N^2)
void BubbleSort(int* a, int n)
{for (int i = 0; i < n; i++){bool flag = false;//判斷是否交換過for (int j = 0; j < n - 1 - i; j++){if (a[j] > a[j + 1]){Swap(&a[j], &a[j + 1]);flag = true;}}if (flag == false)//一趟下來沒有交換說明已經有序{break;}}
}
6.快速排序
快速排序整體的綜合性能和使用場景都是比較好的,這也是大多數人使用快排的原因。
快速排序算法應該算是排序算法中的重點了。
快速排序是一種二叉樹結構的交換排序方法。
基本思想:任取待排序的序列中的某元素作為key值,按照key值將待排序集合分割成兩個子序列,左子序列中所有元素均小于key,右子序列中所有元素均大于key,然后最左右子序列重復該過程,直到所有元素有序。
快速排序的過程與二叉樹的前序遍歷相似,因此可以采用遞歸的方式。但在某些極端情況下可能會出現棧溢出,因此有時也會使用非遞歸的形式實現。
遞歸實現
快速排序的細節問題有很多,區間問題、key值的選取、交換細節等等,這些細節不注意很容易會造成超時(無限循環)、排序出錯等問題。因此也衍生了很多版本:hoare版本、挖坑法、前后指針版本等,還有一些優化key值選取的方法例如“三數取中法”,這些代碼有些地方不是那么容易理解,并且冗長,有的版本在排序OJ會跑不過。
上述所有版本這里不再總結,其他博主有更詳細的介紹。下面介紹一種AcWing上大佬總結的快排模板,非常厲害,代碼簡潔易懂,在排序OJ也能跑過。
思路:
我們選取一個
key值,使用雙指針i和j分別從區間左右兩邊往中間走,將>=key的數換到右區間,將<=key的數換到左邊界,當i>=j時,j(或i)的左邊區間都<=key,右邊區間都>=key,然后再遞歸左區間和右區間按照此方法排序。
void QuickSort(int* a, int l, int r)
{//遞歸的終止情況if (l >= r) return;//最好不選左右端點作key,否則有序或逆序情況下效率很差int key = a[(l + r) / 2];int i = l - 1, j = r + 1;while (i < j){while (a[++i] < key);//左邊找大while (a[--j] > key);//右邊找小if (i < j)Swap(&a[i], &a[j]);}QuickSort(a, l, j);QuickSort(a, j + 1 , r);
}
下面需要證明兩個問題:無限循環和無限遞歸的邊界問題。

key的取值會影響后面遞歸的區間,下面四種寫法都是正確的。
上面代碼是右邊第一種寫法。

我們先分析遞歸區間的取法:

再來分析key的取法
雖然下面這兩種區間劃分都可以,但具體哪種要看key的取法:

這四種寫法取一種即可
但建議寫左邊兩種,因為key取到邊界的話,有序或逆序情況下效率很差。
 總結:
總結:
1.key取
a[l]或者a[(l+r)/2]遞歸區間為QuickSort(a,l,j)和QuickSort(a,j+1,r);
2.key取a[r]或者a[(l+r+1)/2]遞歸區間為QuickSort(a,l,i-1)和QuickSort(a,i,r);
3.key不建議取邊界,最好從中間選取,否則有序或者逆序情況下,效率很差。
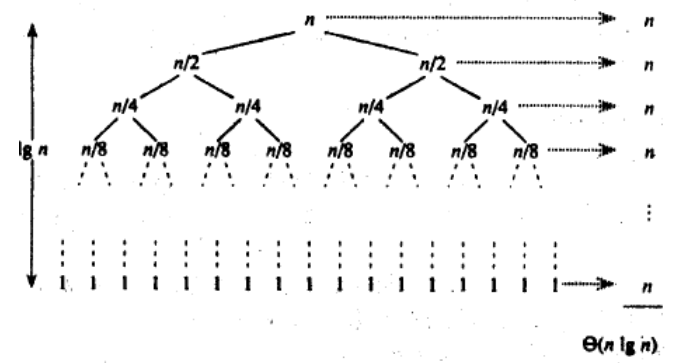
時間復雜度:O(N*logN)。時間復雜度=每層的操作次數×樹的深度=nlogn
最好情況:O(N*logN) ;有序,只判斷不進行交換。
最壞情況:O(N2);并非逆序,每次劃分,key都是最小(最大)的。
空間復雜度:O(logN)。 遞歸的棧幀開銷。
穩定性:不穩定。 快排前后交換數據會導致相對位置 發生改變。
非遞歸實現
快排的遞歸過程是將大區間劃分為兩個小區間,這兩個小區間再分別劃分成兩個更小區間,直到遞歸到邊界條件,結束然后回退到上一層。
所以快排的非遞歸可以借助隊列或者棧的方式來實現。
隊列的話可以參考二叉樹的層序遍歷。
思路:先取隊頭區間排序處理,再將隊頭的左右子區間入隊,再取隊頭區間,再將左右區間入隊,重復直到隊列為空。
下面介紹快排非遞歸采用棧的實現方法。類似二叉樹的前序遍歷。
思路:每次取棧頂區間進行快排的單趟排序,然后將該區間的左右子區間入棧,再取棧頂區間處理,重復直到棧空。
//非遞歸快排
void QuickSortNonRe(int* a, int left, int right)
{ST st;STInit(&st);STPush(&st, left);//左端點入棧STPush(&st, right);//右端點入棧while (!STEmpty(&st)){//注意順序,和入棧順序相反int r = STTop(&st);STPop(&st);int l = STTop(&st);STPop(&st);//單趟排序int key = a[(l + r) / 2];int i = l - 1, j = r + 1;while (i < j){while (a[++i] < key);//左邊找大while (a[--j] > key);//右邊找小if (i < j)Swap(&a[i], &a[j]);}//分為[l, j]和[j + 1, r]區間if (l < j)//l == j 說明該區間只有一個值,無需入棧{STPush(&st, l);STPush(&st, j);}if (j + 1 < r){STPush(&st, j + 1);STPush(&st, r);}}STDestroy(&st);
}
7.歸并排序
遞歸實現
歸并排序的遞歸實現屬于分治算法,分治算法都有三步:
1.分成子問題;
2.遞歸處理子問題;
3.子問題合并。
歸并排序是不斷將區間分解成子區間,一分二,二分四…,直到每個區間只有一個元素,然后開始向上合并有序區間,分而治之。實現過程與二叉樹的后序遍歷類似,先遞歸再合并處理元素。

時間復雜度:O(N*logN)。與快排一樣,時間復雜度=每層的操作次數×樹的深度=nlogn
歸并排序不受初始數據順序的影響,不管有序還是無序,時間復雜度都是O(N*logN)。因為每次都遞歸到最小區間開始合并區間。
空間復雜度:O(N)。 需要額外開辟數組空間。
穩定性:穩定。 歸并過程左右區間有兩個數相同時,先從左區間取數據。
//歸并排序 穩定 時間復雜度O(N*logN) 空間復雜度O(N)
void Merge(int* a, int l, int r, int* tmp)//tmp臨時存放合并好的數據
{//遞歸的終止情況if (l >= r)return;//第一步:分成子問題int mid = (l + r) / 2;//第二步:遞歸處理子問題Merge(a, l, mid, tmp);Merge(a, mid + 1, r, tmp);//第三步:合并子問題;將[l, mid]和[mid + 1, r]區間歸并int i = l, j = mid + 1;int k = 0;while (i <= mid && j <= r){if (a[i] <= a[j])//可見穩定性tmp[k++] = a[i++];elsetmp[k++] = a[j++];}//左區間剩余while (i <= mid)tmp[k++] = a[i++];//右區間剩余while (j <= r)tmp[k++] = a[j++];//將歸并好的tmp數組的內容交給數組a的[l,r]區間memcpy(a + l, tmp, sizeof(int) * k);// k == r - l + 1//i = l, k = 0;//while (i <= r)// a[i++] = tmp[k++];
}//歸并排序
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (NULL == tmp){perror("malloc");return;}Merge(a, 0, n - 1, tmp);free(tmp);
}
非遞歸實現
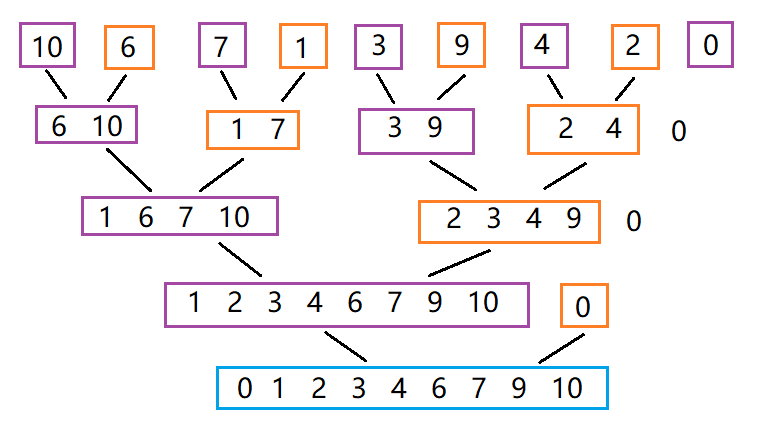
歸并排序的非遞歸是可以直接從最小區間開始合并的,所以省去了遞歸劃分子區間的過程,使用一個gap值來實現區間的跨度,gap從1開始每循環一次乘2,;區間的跨度從1到2,再到4…以2的指數增長。如果數據個數不滿足2n個,則左右區間可能會發生越界,這就是需要處理的細節問題。
修正區間邊界:(左區間的左端點一定不會越界,不用考慮)當左區間的右端點越界,或者右區間的左端點越界,則后面的元素(有序)不再合并,等待下一輪。
否則如果右區間的右端點越界,則使右端點=n-1,進行修正。
//非遞歸
void MergeSortNonRe(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (NULL == tmp){perror("malloc");return;}int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){int left1 = i, right1 = i + gap - 1;int left2 = i + gap, right2 = i + 2 * gap - 1;if (right1 >= n || left2 >= n)//不再歸并{break;}if (right2 >= n)//第二區間右端點越界{right2 = n - 1;}//合并子區間int k = i;while (left1 <= right1 && left2 <= right2){if (a[left1] <= a[left2])tmp[k++] = a[left1++];elsetmp[k++] = a[left2++];}while (left1 <= right1)tmp[k++] = a[left1++];while (left2 <= right2)tmp[k++] = a[left2++];//合并一次,拷貝一次memcpy(a + i, tmp + i, sizeof(int) * (right2 - i));}gap *= 2;}free(tmp);
}
8.計數排序
前面七種排序算法都屬于比較排序,而計數排序是一種非比較排序。并不是通過兩個數相比來進行排序的。
計數排序本質就是用數組存儲一個映射關系把它的位置保存起來,然后再遍歷原先的數組從位置數組中把它拿出來進行排序。
基本思想:統計相同元素出現次數,然后根據統計的結果將序列回收到原來的序列中。
遍歷一邊序列,元素每出現一次,就將以該元素為下標的數組的值+1,類似哈希表。
但是,如果序列中只有幾個數,但這幾個數并不算很小,例如{100, 100,101};我們就需要開辟101個空間來存儲,會造成空間的大量浪費。所以對此可以進行優化,利用序列中最大值和最小值的差值來開辟空間。這樣只需開辟2個整型空間即可。
時間復雜度:O(N+range)。只需要遍歷幾遍數組。
歸并排序不受初始數據順序的影響,不管有序還是無序,時間復雜度都是O(N*logN)。因為每次都遞歸到最小區間開始合并區間。
空間復雜度:O(range)。 需要額外開辟空間。range=最大值-最小值+1
穩定性:不穩定。 沒有進行數據交換,本質上是修改了原始數據。
計數排序在數據范圍集中時,效率很高,但是適用范圍及場景有限。
//計數排序 時間復雜度O(N+range) 空間復雜度O(range)
void CountSort(int* a, int n)
{//第一遍,找出最大值和最小值int maxVal = a[0], minVal = a[0];for (int i = 1; i < n; i++){if (a[i] > maxVal)maxVal = a[i];if (a[i] < minVal)minVal = a[i];}//開辟數組空間int range = maxVal - minVal + 1;//calloc自動初始化為0int* count = (int*)calloc(sizeof(int), range);if (NULL == count){perror("malloc");return;}//第二遍,計數for (int i = 0; i < n; i++)count[a[i] - minVal]++;//排序int i = 0;for (int x = minVal; x <= maxVal; x++){while (count[x - minVal]-- > 0)a[i++] = x;}free(count);
}
四、總結
對這八種算法進行性能測試,隨機生成10萬個數據,統計排序所消耗時間如下:
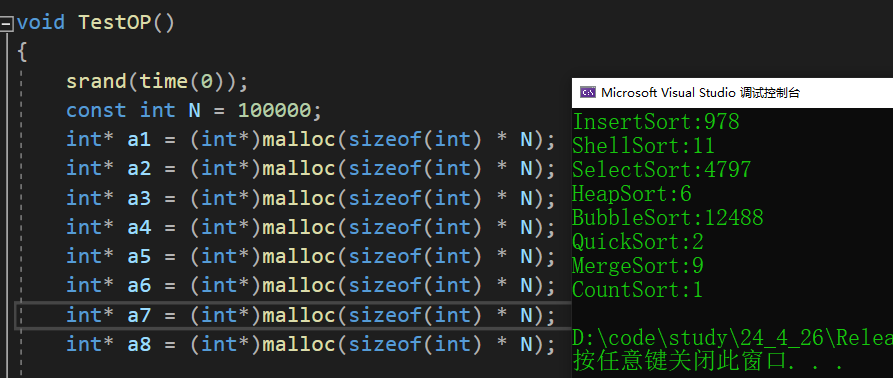 可以看出,三種基本排序:插入排序、選擇排序、冒泡排序所花費的時間明顯更多。它們的時間效率都是O(N2),但是它們的效率卻有明顯差別。
可以看出,三種基本排序:插入排序、選擇排序、冒泡排序所花費的時間明顯更多。它們的時間效率都是O(N2),但是它們的效率卻有明顯差別。
插入排序最快;選擇排序掃描一遍數組,只需要換兩次位置;而冒泡排序需要不斷交換相鄰的元素。因此,選擇排序在大型數據集中的性能比冒泡排序更好。
剩下五種排序算法跟它們不是一個量級,數據量太小看不出明顯差別,我們單獨用100萬個數據來測試這五種排序算法的性能。
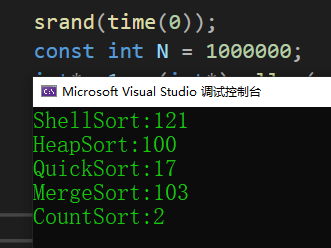
計數排序最快,但是計數排序的使用場景也有限,本質是拿空間換時間,而且當空間效率O(range)>O(nlog(n))的時候其效率反而不如基于比較的排序;所以計數排序不歸在常見的排序算法中。
剩下四種常見算法中,希爾排序、堆排序、歸并排序是相差不大的;快速排序是比較突出的,要比其余算法(除了計數排序)都快,快速排序整體的綜合性能和使用場景都是比較好的。
排序算法復雜度及穩定度分析
| 排序方法 | 時間復雜度 | 空間復雜度 | 穩定性 | |||
| 平均情況 | 最好情況 | 最壞情況 | ||||
| 插入排序 | 插入排序 | O(n2) | O(n) | O(n2) | O(1) | 穩定 |
| 希爾排序 | 平均 O(n1.3) | O(1) | 不穩定 | |||
| 選擇排序 | 選擇排序 | O(n2) | O(n2) | O(n2) | O(1) | 不穩定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不穩定 | |
| 交換排序 | 冒泡排序 | O(n2) | O(n) | O(n2) | O(1) | 穩定 |
| 快速排序 | O(nlogn) | O(nlogn) | O(n2) | O(nlogn) | 不穩定 | |
| 歸并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 穩定 | |
| 計數排序 | O(n+range) | O(n+range) | O(n+range) | O(range) | 不穩定 | |
快速排序:一般情況時排序速度最塊,但是不穩定,當有序時,反而不好;
歸并排序:效率非常不錯,在數據規模較大的情況下,比希爾排序和堆排序要好;
堆排序:適合Tok-K問題;例:找出一千萬個數中最小的前一百個數;
算法的時間復雜度與初始序列初態無關的算法有:選擇排序、堆排序、歸并排序。
完整代碼:八大排序算法

PyLammps 教程)
![[JAVASE] 類和對象(二)](http://pic.xiahunao.cn/[JAVASE] 類和對象(二))
pixabay免費可商用的圖片、視頻、插畫、矢量圖、音樂)









)


)


