pandas 是基于python語言的數據分析處理庫,使用廣泛。本文主要參考pandas的官方入門指導,并結合自己入門使用的一些常用操作進行說明。
pandas通常和numpy結合使用,一般通過如下語句導入numpy和pandas庫。
import numpy as np
import pandas as pd
一. pandas 數據結構
pandas提供兩類基本數據結構,即series和dataframe。
1.1 series
series 是一維帶標簽的數組,可以存放整形, 字符串, python object 等類型。
可以通過如下方式傳入一個列表來創建series:
In [3]: s = pd.Series([1, 3, 5, np.nan, 6, 8])In [4]: s
Out[4]:
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
1.2 dataframe
有行和列的二維數據結構。
DataFrame 可以傳入數組創建,也可以傳入字典進行創建。
In [5]: dates = pd.date_range("20130101", periods=6)In [6]: dates
Out[6]:
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04','2013-01-05', '2013-01-06'],dtype='datetime64[ns]', freq='D')In [7]: df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD"))In [8]: df
Out[8]: A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.524988
通過字典的方式創建,字典的keys 即為DataFrame的列標簽,字典的值即為DataFrame的值。
In [9]: df2 = pd.DataFrame(...: {...: "A": 1.0,...: "B": pd.Timestamp("20130102"),...: "C": pd.Series(1, index=list(range(4)), dtype="float32"),...: "D": np.array([3] * 4, dtype="int32"),...: "E": pd.Categorical(["test", "train", "test", "train"]),...: "F": "foo",...: }...: )...: In [10]: df2
Out[10]: A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
DataFrame 的每一列數據的格式相同,可以通過dtypes 方法獲取
In [11]: df2.dtypes
Out[11]:
A float64
B datetime64[s]
C float32
D int32
E category
F object
dtype: object
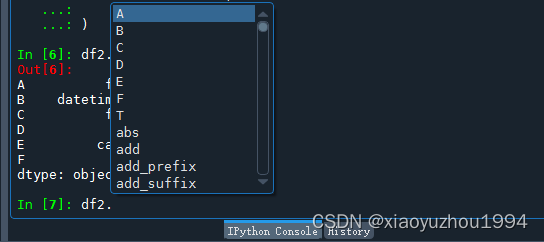
使用IPython,可以通過tab獲取DataFrame的列名稱以及公共屬性。
二. 數據查看
2.1 head 和tail方法,查看頭部和尾部的行數據
In [13]: df.head()
Out[13]: A B C D
2013-01-01 0.469112 -0.282863 )


![[C#] 使用HttpClient請求https地址報錯的解決方案](http://pic.xiahunao.cn/[C#] 使用HttpClient請求https地址報錯的解決方案)


)

,拿走就用~)



)






】212. 單詞搜索 II)