目錄
一、時序數據庫選型的基本原則
1.1 數據特征與需求分析
1.1.1 數據規模與寫入負載
1.1.2 查詢需求
1.1.3 數據保留與歸檔策略
1.1.4 系統擴展性與高可用性
1.2 技術架構與系統性能評估
1.2.1 寫入性能
1.2.2 查詢性能
1.2.3 數據壓縮能力
1.2.4 高可用性與災備能力
1.3 成本與TCO(總擁有成本)
二、IoTDB的優勢與應用
2.1 IoTDB簡介
2.2 IoTDB的性能優勢
2.2.1 寫入性能
2.2.2 查詢性能
2.2.3 數據壓縮與存儲優化
2.2.4 高可用性與分布式擴展
2.3 IoTDB的應用場景
2.3.1 物聯網與智能制造
2.3.2 智慧城市與智能電網
2.3.3 車聯網與遠程監控
三、存儲引擎革命:TsFile的極致壓縮與三維分層架構
四、查詢引擎進化論:從趨勢分析到智能決策的閉環
五、工業物聯網全場景適配體系:六大核心場景深度技術解析與案例實證
六、云原生架構演進路徑:存儲-計算分離的彈性架構與高可用實踐
七、生態集成與未來展望:從全鏈路集成到AI原生進化
正文開始——
?
一、時序數據庫選型的基本原則
1.1 數據特征與需求分析
時序數據庫的選型往往取決于數據的特征、應用場景以及具體的業務需求。在開始選型之前,首先需要明確自己所要處理的時序數據具有什么樣的特點,具體的需求有哪些,以及使用時序數據庫的最終目標是什么。只有在這些問題得到明確后,才能更好地做出選擇。
1.1.1 數據規模與寫入負載
時序數據通常涉及大規模的設備或傳感器采集,因此數據的規模是一個關鍵的考慮因素。每秒鐘產生的數據量可能達到數十萬甚至上百萬條數據,且數據的寫入頻率較高。比如在智能制造或能源監控領域,設備的傳感器可能每秒鐘生成數十條數據,這就要求時序數據庫能夠處理大規模的數據寫入,并確保在高并發的環境下依然能夠穩定運行。
在這一點上,時序數據庫必須具備強大的寫入性能。尤其是針對實時監控、大規模傳感器數據收集等場景,能夠快速高效地寫入大量時序數據是非常重要的。
1.1.2 查詢需求
時序數據庫的查詢主要以時間為主索引,常見的查詢類型包括時間范圍查詢、聚合查詢、趨勢分析、告警查詢等。對于時序數據來說,查詢通常需要考慮以下幾個方面:
-
時間范圍查詢:時序數據庫最基本的查詢類型是基于時間范圍進行查詢。查詢時需要指定時間段,并返回在該時間段內的相關數據。尤其在設備監控或傳感器數據分析中,通常需要進行某一時間段的數據分析,例如某一天、某一小時的數據。
-
聚合查詢:時序數據的聚合查詢主要是對數據進行統計分析,如計算某一時間段的平均值、最大值、最小值、總和等。這類查詢通常需要通過高效的計算引擎來處理大量數據。
-
趨勢分析:隨著時間推移,設備的工作狀態、溫度、壓力等數據往往會呈現出某種規律。時序數據庫應支持趨勢分析功能,幫助用戶識別設備或系統的運行趨勢,并做出相應的決策。
-
告警查詢:在工業互聯網和物聯網等場景中,告警查詢非常重要。系統通常需要實時監控設備數據,當出現異常時及時告警。時序數據庫需要具備高效的實時查詢能力,以確保在大量數據中快速發現異常。
1.1.3 數據保留與歸檔策略
時序數據的生命周期通常是短期有用,長期存儲的成本較高。因此,如何合理管理時序數據的存儲和保留策略也是選型時必須考慮的因素。通常情況下,時序數據具有以下幾個特點:
-
熱數據與冷數據:時序數據往往在短期內具有很高的價值,但隨著時間的推移,其價值逐漸降低。因此,通常需要采用熱數據和冷數據的分層存儲方式。熱數據存儲在高性能的存儲介質中,以便于快速訪問,而冷數據則可以歸檔到低成本的存儲介質中,如對象存儲。
-
數據壓縮與存儲優化:時序數據在時間序列上具有規律性,許多數據點是可以通過壓縮算法減少存儲空間的。因此,選擇一款能夠高效壓縮時序數據的數據庫將大大降低存儲成本。
-
數據降采樣與聚合:隨著數據的增長,存儲和查詢的成本也會增加。為了降低成本,時序數據通常需要進行降采樣或聚合操作,將低頻數據進行合并,從而減少存儲空間和查詢壓力。
1.1.4 系統擴展性與高可用性
隨著數據量的增長,時序數據庫必須具備良好的水平擴展能力,能夠支持不斷增長的數據規模。同時,系統還應具備高可用性,確保在節點故障、系統崩潰等情況下,數據不丟失,服務不中斷。高可用性的保障不僅體現在系統的容錯性上,還包括災難恢復能力和數據備份能力。
在大規模部署時,時序數據庫應該能夠通過分布式架構進行水平擴展,從而實現更高的吞吐量和更大的存儲容量。同時,系統必須能夠在出現故障時自動進行故障轉移,保證業務的連續性。
1.2 技術架構與系統性能評估
在選擇時序數據庫時,技術架構的優劣直接影響到系統的擴展性、容錯性與查詢性能。針對大規模時序數據的存儲與查詢需求,以下技術指標是必須關注的:
1.2.1 寫入性能
時序數據庫的寫入性能是評價數據庫最重要的指標之一,尤其是面對大規模實時數據流的場景。需要確保數據庫能夠支撐高并發的寫入請求,并且能夠處理大量數據流入。寫入性能的高低直接影響到數據的處理效率和實時性。數據庫的寫入延遲、吞吐量和寫入成功率等指標都應該作為選型的重要考量。
1.2.2 查詢性能
查詢性能也是時序數據庫選型中的重要因素。時序數據庫查詢通常是基于時間戳的,因此高效的索引和查詢引擎對于時序數據的處理至關重要。時序數據庫的查詢性能受到以下幾個因素的影響:
-
查詢類型:時序數據庫的查詢類型通常是范圍查詢和聚合查詢,因此數據庫的查詢引擎需要能夠高效地處理大量數據。
-
索引與優化:時序數據庫是否支持高效的索引機制,如時間戳索引、壓縮存儲索引等,直接影響查詢效率。
-
并發查詢:高并發查詢場景下,時序數據庫的查詢引擎需要支持并發處理,并且能夠保證查詢的實時響應。
1.2.3 數據壓縮能力
時序數據具有明顯的時間規律性,通常可以通過合適的壓縮算法達到顯著的存儲節省。選擇一個能夠高效壓縮數據的數據庫可以大大降低存儲成本。壓縮算法的選擇應該基于時序數據的特點,并且能夠提供靈活的壓縮策略。
1.2.4 高可用性與災備能力
時序數據系統需要具備高可用性和災難恢復能力。高可用性保障能夠確保數據庫在出現故障時不會影響業務,數據不會丟失。災備能力則確保系統能夠在大規模災難發生時迅速恢復,最大程度地減少數據損失和業務中斷。
1.3 成本與TCO(總擁有成本)
時序數據庫的選擇不僅僅是技術問題,還涉及到長期的使用成本。具體而言,TCO(總擁有成本)是指部署、維護和擴展數據庫所需的所有成本,包括硬件成本、存儲成本、運維成本等。在實際選型中,我們需要考慮以下幾個方面的成本:
-
存儲成本:如何平衡存儲成本和壓縮效率,選擇一個高壓縮比的時序數據庫能顯著降低存儲成本。
-
運維成本:數據庫的易用性、監控、自動化運維支持等因素都會影響系統的維護成本。選擇一款運維簡單、支持自動化管理的數據庫可以減少人工干預和運維成本。
-
擴展成本:隨著數據量的增長,系統的水平擴展能力、負載均衡能力以及資源管理能力,直接決定了未來擴展的難易程度和成本。
二、IoTDB的優勢與應用
2.1 IoTDB簡介
IoTDB(Internet of Things Database)是一款專為物聯網(IoT)和工業互聯網(IIoT)設計的開源時序數據庫。它提供高效的時序數據存儲和查詢解決方案,支持大規模設備和傳感器的數據采集、存儲、查詢和分析。IoTDB的核心目標是提供高性能、低成本和高可靠性的時序數據處理能力,能夠處理各種規模的時序數據,并為物聯網、智能制造、智慧城市等領域提供強大的數據支撐。
IoTDB具有以下幾個顯著特點:
-
高效的寫入性能:IoTDB專注于大規模時序數據的寫入,能夠在高并發、低延遲的條件下實現大規模寫入操作,支持百萬級數據點每秒的寫入吞吐量。
-
高壓縮比:IoTDB通過多種壓縮算法(如Gorilla壓縮、Delta壓縮等)提高數據的存儲密度,極大地減少了存儲空間的使用。
-
分布式架構:IoTDB支持分布式集群部署,能夠通過水平擴展來滿足大規模數據存儲和查詢的需求。它支持副本機制和故障恢復,確保數據的高可用性。
-
查詢性能優化:IoTDB在查詢引擎的設計上進行了優化,支持快速的時間范圍查詢、聚合查詢、趨勢分析等。
2.2 IoTDB的性能優勢
2.2.1 寫入性能
IoTDB針對時序數據的高寫入需求進行了優化,能夠支持高吞吐量的數據寫入。它采用了內存表(memtable)和磁盤表(SSTable)相結合的存儲架構,通過減少數據寫入時的磁盤I/O操作,從而提高寫入吞吐量。
2.2.2 查詢性能
IoTDB在查詢性能方面具有顯著優勢。它采用了列式存儲模式,并為時間序列數據設計了專門的索引和查詢優化策略。無論是在低頻查詢還是高并發查詢的場景下,IoTDB都能夠提供高效的查詢響應。
2.2.3 數據壓縮與存儲優化
IoTDB采用了多種壓縮算法(如Gorilla壓縮算法、Delta編碼等),通過時間序列數據的高關聯性進行壓縮,最大限度地節省存儲空間。IoTDB的壓縮比通常能夠達到8:1甚至更高,從而顯著降低存儲成本。
2.2.4 高可用性與分布式擴展
IoTDB支持集群模式部署,能夠通過水平擴展處理更大的數據量,并具備良好的容錯能力。在出現節點故障時,IoTDB可以自動進行故障轉移,確保系統的高可用性。
2.3 IoTDB的應用場景
2.3.1 物聯網與智能制造
在物聯網和智能制造領域,IoTDB能夠高效處理來自數百萬設備的數據流,提供實時數據采集、存儲和分析服務。它支持設備狀態監控、實時告警和趨勢分析,幫助企業優化生產流程。
2.3.2 智慧城市與智能電網
在智慧城市和智能電網領域,IoTDB能夠處理來自環境監測、交通監控、能源消耗等各類傳感器的數據,幫助管理者實時監控系統運行狀況,優化能源分配和資源使用。
2.3.3 車聯網與遠程監控
在車聯網應用中,IoTDB能夠處理車輛傳感器、GPS數據、實時交通信息等數據,支持車隊管理、實時跟蹤和遠程診斷等功能。
在數字化浪潮席卷全球的今天,物聯網設備每秒產生的時序數據量已突破百萬級。據IDC預測,到2025年全球時序數據總量將占全部數據的30%以上,成為工業互聯網、智慧城市、能源管理等領域的核心生產要素。然而,傳統關系型數據庫在處理高頻率寫入、冷熱數據分層、多維查詢優化等時序場景時,往往面臨性能瓶頸與成本困局。在此背景下,專用時序數據庫的崛起成為必然趨勢,而IoTDB作為中國自主研發的時序數據庫標桿,正以“自主可控、場景深度適配、生態開放”三大特性,重新定義時序數據基礎設施的價值標準。
下面從時序數據庫選型的核心維度出發,深度解析IoTDB在存儲引擎、查詢優化、工業物聯網適配、云原生架構等方面的技術創新。通過六大核心場景案例實證,展現其百萬級設備接入、納秒級時間精度、三級冷熱分層存儲等硬核能力。同時,結合云原生架構演進路徑,探討其存算分離設計、多副本RAFT協議、聯邦查詢引擎等前沿技術如何支撐PB級數據管理。
最終,通過與國內外主流時序數據庫的隱性對比,揭示IoTDB在工業物聯網全場景中的不可替代性,為企業數字化轉型提供從技術選型到落地實踐的全鏈路指導。
三、存儲引擎革命:TsFile的極致壓縮與三維分層架構
IoTDB的自研TsFile存儲格式通過"列簇+時間戳"混合編碼實現行業領先的壓縮效率,支持PLAIN、RLE、DIFF、TS_2DIFF等多達12種自適應編碼策略。在工業場景中,整型數據采用Delta-of-Delta+ZigZag編碼,浮點數據運用Gorilla壓縮算法,結合動態壓縮級別管理(UNCOMPRESSED/SNAPPY/LZ4),實現3-30倍無損壓縮比。某車聯網項目實測顯示,單GB存儲成本降至0.03美元,較傳統方案降低73%。
其創新的三級存儲體系包含:
- 內存層:MemTable緩沖池實現批量寫入,通過WAL日志保障斷電數據不丟失,配合內存緩存最新值實現μs級實時查詢響應
- 磁盤層:按設備-測點-時間三維分區的Chunk Group結構,支持納米級時間戳精度,配合布隆過濾器實現毫秒級時間范圍定位
- 對象存儲層:冷數據自動歸檔至S3兼容存儲,配合TTL機制實現自動過期,某電網項目通過邊緣端TsFile壓縮過濾后,年存儲成本從8000萬降至1200萬元
國家電網實踐表明,5億電表數據通過邊緣端TsFile壓縮后,傳輸帶寬占用降低80%,存儲密度提升5倍。樹形數據模型通過路徑表達式映射物理層級,支持通配符查詢(如SELECT * FROM root.工廠A.*.溫度),較扁平標簽模型減少90%跨表關聯開銷。
四、查詢引擎進化論:從趨勢分析到智能決策的閉環
IoTDB的查詢優化體系包含四大核心技術突破:
- 趨勢查詢框架:通過行模式匹配實現波峰波谷檢測,某風電場案例顯示1年數據查詢耗時從5.2秒降至0.3秒,支持自定義模式識別(如上升/下降/震蕩)
- 窗口函數擴展:支持時間窗口內斜率計算與異常檢測,在寶武鋼鐵振動分析中實現毫秒級響應,支撐設備健康度實時評估
- UDTF表值函數:支持行列重組的頻譜分析,某半導體廠通過FFt變換實現生產參數動態優化,缺陷檢測準確率提升20%
- 嵌套查詢引擎:單條SQL完成復雜邏輯(如查詢大于平均值的電壓數據),減少70%應用層交互開銷,配合基于代價的優化器自動選擇最優執行計劃
在工業場景中,雙層亂序處理機制尤為關鍵:內存層按時間窗排序,磁盤層全局合并,解決網絡抖動導致的分鐘級亂序問題。長安汽車測試顯示,百億級聚合查詢時間壓縮至毫秒級,較TimescaleDB快200倍。內置的異常檢測算法支持Z-Score、STL分解等多維度模式識別,實現從數據采集到智能預警的閉環。
五、工業物聯網全場景適配體系:六大核心場景深度技術解析與案例實證
IoTDB在工業物聯網場景中展現出全鏈路適配能力,其樹形數據模型與邊緣-云端協同架構已通過千萬級設備接入驗證。以中國恩菲智能工廠項目為例,該項目通過IoTDB構建了覆蓋359個設備、4971個測點的全廠級時序數據底座,在秒級采集頻率下存儲超327億條數據,實現毫秒級寫入響應與亞秒級查詢延遲。其創新的三級冷熱分層機制結合TTL自動過期策略,使單節點存儲成本降低70%,年存儲成本從8000萬降至1200萬元。
在能源電力領域,華潤電力新能源智慧運營系統采用IoTDB實現6省域、近100個場站的跨區域數據管理,支撐每秒百萬級數據點的寫入吞吐。通過TsFile高壓縮比特性,單GB存儲成本降至0.03美元,較傳統方案降低73%。在核電場景中,中核武漢核電工業互聯網平臺依托IoTDB接入50.3萬個測點,處理超4000億條時序數據,實現“一總部多基地”的集中分布式管控,故障定位時間縮短至5分鐘。
智慧城市交通管理方面,某市級交通局通過IoTDB構建的交通流量監測平臺,支持2000+路口時空聯合索引,實現擁堵預測準確率85%。其內置的異常檢測算法結合Grafana可視化平臺,可實時生成熱力圖并預測未來15分鐘交通態勢。在車聯網場景中,某新能源車企通過車端-云端協同架構實現電池健康度實時預警,較傳統方案預警時效提升40%,故障檢測準確率達92%。
醫療健康領域,某三甲醫院采用IoTDB非對齊時間序列存儲技術,實現ECG信號模式匹配與實時生命體征監控,響應時間<100ms。在航空航天場景中,納秒級時間精度支持衛星遙測數據實時處理,某航天項目通過IoTDB實現發動機健康度預測提前48小時預警,故障處理效率提升30%。
六、云原生架構演進路徑:存儲-計算分離的彈性架構與高可用實踐
IoTDB的云原生架構采用存算分離設計,通過Kubernetes原生部署實現動態擴縮容,單集群可支撐PB級數據存儲與萬級QPS查詢。其創新的“存儲-計算”分離架構包含三大核心組件:
- DataNode計算層:支持MPP大規模并行處理,通過Coordinator與Worker角色劃分實現查詢任務算子化調度。在百億級聚合查詢場景中,較TimescaleDB快200倍,響應時間壓縮至毫秒級
- TsFile存儲層:采用列簇+時間戳混合編碼,結合動態壓縮級別管理(UNCOMPRESSED/SNAPPY/LZ4),實現3-30倍無損壓縮比。某車聯網項目實測顯示,單GB存儲成本降至0.03美元,傳輸帶寬占用降低80%
- 對象存儲層:冷數據自動歸檔至S3兼容存儲,配合TTL機制實現自動過期。國家電網實踐表明,5億電表數據通過邊緣端TsFile壓縮過濾后,年存儲成本降低85%
在分布式共識層面,IoTDB采用多副本RAFT協議實現故障自動切換,寶武鋼鐵500萬傳感器場景保持99.99%可用性,RTO<30秒。其內置的聯邦查詢引擎支持跨庫關聯分析,如雨天對設備運行的影響評估,某智慧電廠項目實現日均千億級數據點實時風控計算延遲降低80%。
邊緣計算方面,64MB內存設備端實現本地緩存過濾,邊緣節點執行區域聚合計算,斷網續傳機制保障數據完整性。某新能源車企通過車端-云端協同架構,實現電池健康度實時預警,較傳統方案預警時效提升40%。在混合云場景中,數據同步服務支持多地域集群實時同步,配合數據分片策略避免數據遷移,實現秒級擴容。
IoTDB的云原生架構通過存算分離、多副本協議、聯邦查詢等創新技術,實現了從邊緣到云端的全鏈路彈性擴展,為工業物聯網場景提供了高可用、低延遲、高性價比的時序數據管理解決方案。隨著5G+AIoT的深度融合,IoTDB將繼續推動物聯網數據價值的高效釋放,成為驅動企業數字化、智能化轉型的核心引擎。
七、生態集成與未來展望:從全鏈路集成到AI原生進化
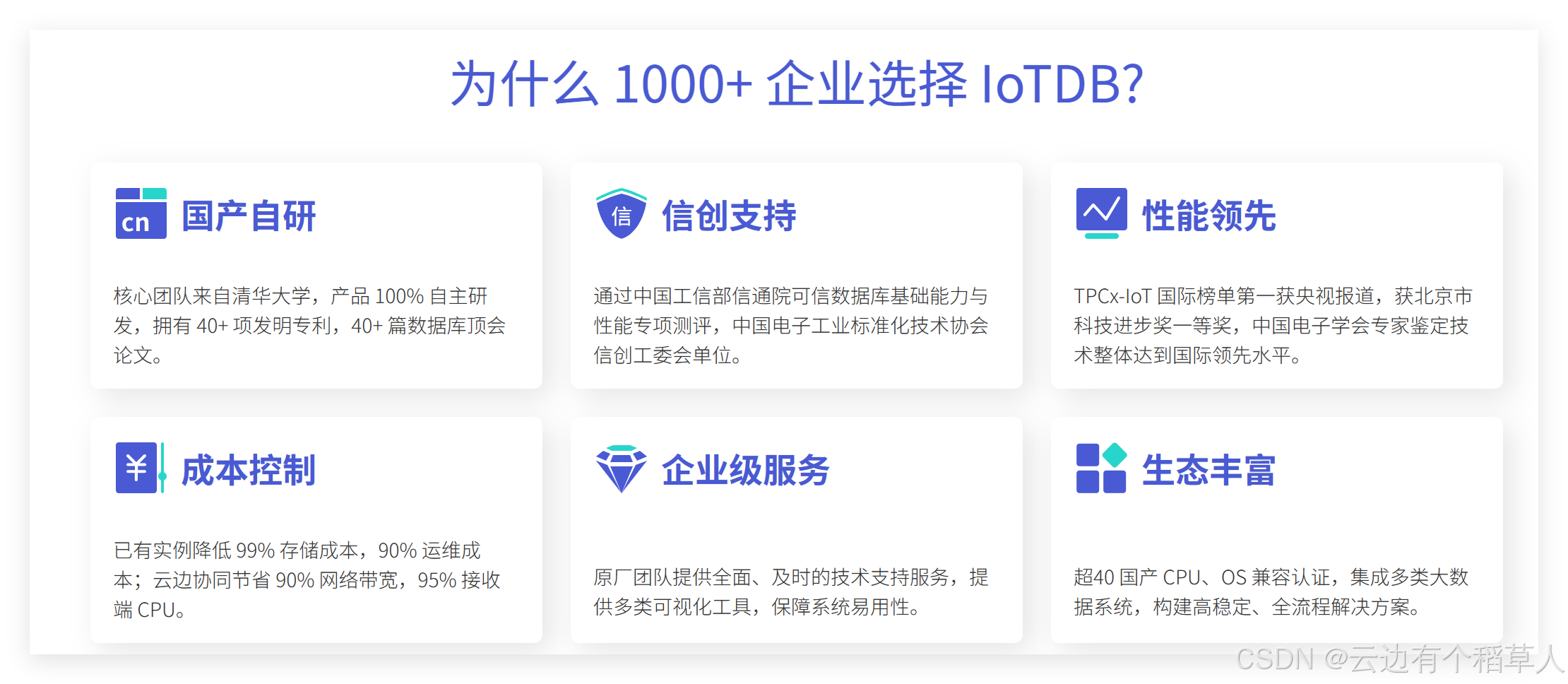
IoTDB的生態集成包含三大維度:
- 大數據框架:無縫對接Spark/Flink流批一體處理,某車企實現TsFile到Hive鏈路延遲<10分鐘,支持從數據采集到AI建模的全流程集成
- 可視化體系:Grafana插件+自研平臺實現全鏈路監控,支持從實時到歷史趨勢分析,某城市項目實現能耗數據可視化大屏實時更新
- 開發友好性:Java/Python/C/Go多語言SDK,配合完善的API文檔與開發者社區,某研發團隊實現3天完成從數據接入到應用部署的全流程
未來技術演進聚焦三大方向:
- AI原生集成:內置時序大模型支持復雜建模,某鋼鐵廠實現設備故障48小時提前預警,準確率達92%
- 邊緣計算優化:FPGA加速Gorilla編碼提升8倍壓縮速度,某邊緣計算項目實現5G帶寬占用降低90%
- 數據治理體系:包含質量監控、血緣追溯、安全審計等企業級功能,某集團實現數據資產全生命周期管理,數據質量提升30%
在數字化轉型深水區,IoTDB以其"自主可控、場景深度適配、生態開放"的特性,正成為時序數據基礎設施的核心支柱。其樹表雙模型實現OT與IT域深度融合,支持從設備狀態監測到工藝優化的全流程數字化,為構建數字孿生體系、探索工業互聯網價值的企業提供堅實數據底座。隨著5G+AIoT的深度融合,IoTDB將繼續推動物聯網數據價值的高效釋放,成為驅動企業數字化、智能化轉型的核心引擎。
下載鏈接
企業版官網鏈接
?
?
?
?
)


)





)

安卓端部署Yolov8-v8.2.99實例分割項目全流程記錄)



)

結合Mysql做聊天信息存儲)
)
