文章摘要
本文基于 VMware 虛擬機環境,詳細講解 Redis 高可用架構的核心組件與部署流程,涵蓋三大核心模塊:Redis 主從復制(實現數據備份與讀寫分離)、Redis 哨兵(基于主從復制實現故障自動轉移,保障服務高可用)、Redis Cluster 集群(去中心化架構,實現數據分片與橫向擴展)。
一、redis主從復制
Redis 主從復制是 Redis 高可用架構的基礎,通過將主節點(Master)的數據同步到從節點(Slave),實現數據備份(避免單點數據丟失)和讀寫分離(主節點寫、從節點讀,減輕主節點壓力)。
1. 原理
Redis主從復制是將主節點數據同步到從節點的機制,核心流程分三步:
- 建立連接:從節點通過
REPLICAOF指定主節點,發起連接并完成認證。 - 數據同步:
- 首次同步或主節點重啟時,觸發全量復制:主節點生成RDB快照發給從節點,同時緩存期間的寫命令,隨后將緩存命令發送給從節點。
- 從節點斷線重連后,若條件滿足(主節點未變、偏移量在積壓緩沖區范圍內),觸發部分復制:僅同步斷線期間的增量數據。
- 命令傳播:同步完成后,主節點實時將新寫命令發給從節點,保持數據一致。
核心作用:實現數據備份、讀寫分離,是高可用架構的基礎。
2. 配置主從同步
環境說明:
| 主機名 | ip | 作用 |
|---|---|---|
| redis-master | 192.168.2.10/24 | master |
| redis-slave1 | 192.168.2.11/24 | slave1 |
| redis-slave2 | 192.168.2.12/24 | slave2 |
(1)master上配置
#關閉防火墻以及SELinux
[root@master ~]# systemctl disable --now firewalld
[root@master ~]# getenforce
Disabled
#安裝redis并且啟動
[root@master ~]# yum install redis -y
[root@master ~]# systemctl start redis
#編輯配置文件
[root@master ~]# vim /etc/redis/redis.conf
bind 0.0.0.0
protected-mode no
daemonize no #后臺運行[root@redis-master ~]# redis-cli -p 6379
#有效響應
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> info replication
role:master #當前角色為主
connected_slaves:0
master_failover_state:no-failover
master_replid:b765b9a92e508c2b912f56d2f496e34d1431818f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
(2)slave1配置
[root@slave1 ~]# systemctl disable --now firewalld
[root@slave1 ~]# setenforce 0
setenforce: SELinux is disabled
[root@slave1 ~]# yum install redis -y
[root@slave1 ~]# systemctl start redis
[root@slave1 ~]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master #可以看到此時從的角色也是主
connected_slaves:0
master_failover_state:no-failover
master_replid:be4ca2f5431d5ced9f6fec13fb45111d00a15fb2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> replicaof 192.168.2.10 6379 #臨時添加主
OK
127.0.0.1:6379> info replication
# Replication
role:slave #當前從的角色調整為slave
master_host:192.168.168.20
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:0
slave_repl_offset:0
master_link_down_since_seconds:-1
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:be4ca2f5431d5ced9f6fec13fb45111d00a15fb2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
#如果想要slave1永久成為192.168.2.10的從需要寫配置文件
[root@redis-slave1 ~]# vim /etc/redis/redis.conf
bind 0.0.0.0
protected-mode no
daemonize no
replicaof 192.168.2.10 6379
[root@redis-slave1 ~]# systemctl restart redis
(3)slave2配置
[root@slave2 ~]# setenforce 0
setenforce: SELinux is disabled
[root@slave2 ~]# systemctl restart redis
[root@slave2 ~]# yum install redis -y
[root@slave2 ~]# vim /etc/redis/redis.conf
bind 0.0.0.0
protected-mode no
daemonize no
replicaof 192.168.2.10 6379
[root@slave2 ~]# systemctl disable --now firewalld
(4)主從復制驗證
#主上查看
[root@master ~]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.2.11,port=6379,state=online,offset=472520,lag=0
slave1:ip=192.168.2.12,port=6379,state=online,offset=472520,lag=1
master_failover_state:no-failover
master_replid:8d6ad7deb54af3875d40da49acb6e57b0225f63b
master_replid2:d301ad130006c0539408fe1c69b9b2d677a7d479
master_repl_offset:472520
second_repl_offset:10827
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:99
repl_backlog_histlen:472422#主上可以寫入數據,從上只能讀數據
[root@master ~]# redis-cli
127.0.0.1:6379> set s 1
OK
127.0.0.1:6379> get s
"1"
#從上查看
127.0.0.1:6379> get s
"1"
127.0.0.1:6379> DEL s
(error) READONLY You can't write against a read only replica.
二、redis高可用(哨兵)
Redis 主從復制僅能實現數據備份,若主節點故障,需手動切換從節點為主節點,無法滿足高可用需求。哨兵(Sentinel) 通過分布式集群監控主從節點,實現故障自動檢測與轉移,確保服務不中斷。
1. 原理
Redis哨兵是基于主從復制的高可用機制,核心是通過分布式哨兵集群實現主節點故障的自動處理,關鍵流程如下:
-
哨兵集群部署:通常3-5個哨兵節點(奇數,避免投票平局),既監控主從節點,也互相監控,防止哨兵自身單點故障。
-
分層故障檢測:
- 單個哨兵定期給主節點發
PING,超時未響應則標記為“主觀下線”(可能誤判); - 該哨兵向其他哨兵發起投票,若超過
quorum(法定票數,如3個哨兵需2票)同意主節點下線,則標記為“客觀下線”(確認故障)。
- 單個哨兵定期給主節點發
-
自動故障轉移:
- 哨兵集群用Raft算法選一個“領頭哨兵”負責執行轉移;
- 從健康從節點中選新主:優先挑數據最完整(復制偏移量最大)、優先級高的從節點;
- 新主升級(
SLAVEOF NO ONE),其他從節點改同步新主,原主恢復后變從節點。
-
客戶端適配:客戶端通過哨兵的
SENTINEL get-master-addr-by-name命令獲取當前主節點地址,故障轉移后自動拿到新地址,無需手動改配置。
這套機制讓Redis在主節點故障時,能10-30秒內自動恢復服務,實現高可用。
2. 哨兵部署與實操
(1)前提條件:確保主從復制正常
哨兵依賴主從復制,需先確保主從節點正常運行并完成數據同步:
- 主節點(master)配置:默認配置即可(redis.conf),確保 port 6379 等基礎配置正確。
- 從節點(slave)配置:在 redis.conf 中添加(或通過命令臨時設置):
replicaof 192.168.2.10 6379
啟動主節點和從節點,通過 info replication 命令確認主從關系正常(主節點 role:master,從節點 role:slave)。
[root@master ~]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.2.11,port=6379,state=online,offset=473528,lag=1
slave1:ip=192.168.2.12,port=6379,state=online,offset=473528,lag=0
master_failover_state:no-failover
master_replid:6970a8c24b0da9d60549f73916e90b50128c40e8
master_replid2:8d6ad7deb54af3875d40da49acb6e57b0225f63b
master_repl_offset:473528
second_repl_offset:473515
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:454346
repl_backlog_histlen:19183(2) 哨兵配置文件(sentinel.conf)
每個哨兵節點需一份sentienl.conf配置文件,3 個哨兵節點(Master、Slave1、Slave2 各部署 1 個)的配置需一致。。核心配置項如下:
[root@master ~]#vim /etc/redis/sentinel.conf
port 26379 #監聽端口
daemonize no #后臺運行
pidfile /var/run/redis-sentinel.pid
logfile /var/log/redis/sentinel.log
#格式:sentinel monitor <主節點名稱> <主節點IP> <主節點端口> <quorum法定票數>
sentinel monitor mymaster 192.168.2.10 6379 2
#monitor:監控
#mymaster為監控對象起的服務名稱
#2表示只有2個或2個以上的哨兵認為主節點不可用的時候,才會把 master 設置為客觀下線狀態,然后進行 failover 操作。
# 若主節點超過30秒未響應哨兵的PING,哨兵會標記其為“主觀下線”
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1 #發生故障轉移后,同時開始同步新master數據的slave數量
sentinel failover-timeout mymaster 180000 #整個故障切換的超時時間為3分鐘
[root@master ~]# scp /etc/redis/sentinel.conf root@192.168.2.11:/etc/redis/
root@192.168.2.11's password:
sentinel.conf 100% 14KB 25.7MB/s 00:00
[root@master ~]# scp /etc/redis/sentinel.conf root@192.168.2.12:/etc/redis/
root@192.168.2.12's password:
sentinel.conf 100% 14KB 16.1MB/s 00:00
[root@master ~]# systemctl start redis-sentinel.service
(3)啟動哨兵(3 個節點均需執行)
systemctl start redis-sentinel
(4)驗證哨兵配置
[root@master ~]# redis-cli -p 26379
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
#主節點名稱、狀態、從節點數量、哨兵數量
master0:name=mymaster,status=ok,address=192.168.2.10:6379,slaves=2,sentinels=3
(5)故障轉移測試
模擬主節點(192.168.2.10)故障,驗證哨兵是否自動切換主節點:
[root@master ~]# redis-cli
127.0.0.1:6379> SHUTDOWN
not connected> exit
[root@master ~]# tail -5 /var/log/redis/sentinel.log
33602:X 07 Sep 2025 17:31:08.192 # +vote-for-leader ca35a05386937b45caa68d35c00a68f37aff1c3e 1
33602:X 07 Sep 2025 17:31:08.788 # +config-update-from sentinel ca35a05386937b45caa68d35c00a68f37aff1c3e 192.168.2.12 26379 @ mymaster 192.168.2.10 6379
33602:X 07 Sep 2025 17:31:08.788 # +switch-master mymaster 192.168.2.10 6379 192.168.2.11 6379
33602:X 07 Sep 2025 17:31:08.789 * +slave slave 192.168.2.12:6379 192.168.2.12 6379 @ mymaster 192.168.2.11 6379
33602:X 07 Sep 2025 17:31:08.789 * +slave slave 192.168.2.10:6379 192.168.2.10 6379 @ mymaster 192.168.2.11 6379
33602:X 07 Sep 2025 17:31:38.843 # +sdown slave 192.168.2.10:6379 192.168.2.10 6379 @ mymaster 192.168.2.11 6379
#可以看到主已經自動切換為slave1,從節點slave2已同步新主#從slave1上查看
[root@slave1 ~]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.2.12,port=6379,state=online,offset=118748,lag=1
master_failover_state:no-failover
master_replid:8276820d549a2bf011159dd785a500abce05a1ed
master_replid2:46ef1e258850bfd3b53b5b5ad3474728a2089638
master_repl_offset:118887
second_repl_offset:78970
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:118887
重啟原主節點(驗證是否自動變為從節點)
[root@master ~]# systemctl start redis
[root@master ~]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave #身份已經變為了slave1的從
master_host:192.168.2.11 #主為slave1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_read_repl_offset:162850
slave_repl_offset:162850
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8276820d549a2bf011159dd785a500abce05a1ed
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:162850
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:161146
repl_backlog_histlen:17053.總結
注意事項!!!!
- 哨兵數量:至少 3 個(奇數),避免投票平局(如 3 個哨兵可容錯 1 個故障)。
- 配置一致性:所有哨兵的 sentinel monitor 配置需一致(主節點名稱、IP、端口、quorum 值相同)。
- 獨立部署:哨兵節點與主從節點盡量部署在不同機器,避免單點硬件故障導致整體不可用。
- 端口開放:確保主從節點端口(如 6379)和哨兵端口(如 26379)在防火墻中開放,允許節點間通信。
三、redis cluster(去中心化集群)
Redis 主從 + 哨兵雖能實現高可用,但無法解決 “單主節點性能瓶頸” 和 “數據容量上限” 問題。Redis Cluster 是去中心化架構,通過將數據分片(Sharding)到多個主節點,實現橫向擴展(擴容)與高可用。
1. 集群核心特性
- 數據分片:將 Redis 的 16384 個 Slot(哈希槽)均勻分配到多個主節點,每個主節點負責一部分 Slot;客戶端根據key的哈希值計算所屬 Slot,直接訪問對應主節點。
- 去中心化:無中心節點,每個節點都保存整個集群的拓撲信息,客戶端可連接任意節點訪問數據(自動重定向到目標節點)。
- 高可用:每個主節點對應至少 1 個從節點,主節點故障時,從節點自動升級為主節點(類似哨兵的故障轉移)。
2. 配置集群
按照如下示例,需要準備6臺服務器:
說明:條件有限,本次使用三臺服務器,每臺服務器上運行一主一從
| 主機說明 | 主機IP | 端口 |
|---|---|---|
| master1 | 192.168.2.10 | 6379 |
| slave1 | 192.168.2.10 | 6380 |
| master2 | 192.168.2.11 | 6379 |
| slave2 | 192.168.2.11 | 6380 |
| master3 | 192.168.2.12 | 6379 |
| slave3 | 192.168.2.12 | 6380 |
下·(1)單節點 Redis 實例配置(以 Master1 所在機器為例)
需為每臺機器配置 2 個 Redis 實例(6379 為主、6380 為從),步驟如下:
#修改如下配置
[root@master1 ~]# vim /etc/redis/redis.conf
port 6379 # 修改端口號
pidfile /var/run/redis_6379.pid # 修改pid文件名
dir /var/lib/redis # 持久化文件存放目錄
dbfilename dump_6379.rdb # 修改持久化文件名
bind 0.0.0.0 # 綁定地址
daemonize yes # 讓redis后臺運行
protected-mode no # 關閉保護模式
logfile /var/log/redis/redis_6379.log # 指定日志
cluster-enabled yes # 開啟集群功能
cluster-config-file nodes-6379.conf #設定節點配置文件名,不需要我們創建,由redis自己維護
cluster-node-timeout 10000 # 節點心跳失敗的超時時間,超過該時間(毫秒),集群自動進行主從切換
#啟動第一個redis實例
[root@master1 ~]# systemctl restart redis
[root@master1 ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=28535,fd=6))#在該主機上啟動另外一個6380端口的實例
[root@master1 ~]# cp /etc/redis/redis.conf /etc/redis/redis-6380.conf
[root@master1 ~]# vim /etc/redis/redis-6380.conf
bind 0.0.0.0
protected-mode no
port 6380
daemonize no
pidfile /var/run/redis_6380.pid
logfile /var/log/redis/redis_6380.log
dbfilename dump_6380.rdb
dir /var/lib/redis
cluster-enabled yes
cluster-config-file nodes-6380.conf
cluster-node-timeout 15000
[root@master1 ~]# redis-server /etc/redis/redis-6380.conf#使用命令啟動6380實例并將其放在后臺
[root@master1 ~]# redis-server /etc/redis/redis-6380.conf &
[1] 28610
#查看是否有兩個redis實例
[root@master1 ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:16379 0.0.0.0:* users:(("redis-server",pid=1841,fd=8))
tcp LISTEN 0 511 0.0.0.0:16380 0.0.0.0:* users:(("redis-server",pid=1876,fd=8))
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=1841,fd=6))
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=1876,fd=6))
(2)復制配置到其他節點(192.168.2.11、192.168.2.12)
將 Master1 的 2 個配置文件(redis.conf、redis-6380.conf)復制到 master2(192.168.2.11)和 master3(192.168.2.12),并啟動實例:
[root@master1 ~]# scp /etc/redis/redis* root@192.168.2.11:/etc/redis
[root@master1 ~]# scp /etc/redis/redis* root@192.168.2.12:/etc/redis
#在master1和master2上分別啟動6379和6380端口服務
systemctl restart redis 6379
redis-server /etc/redis/redis-6380.conf & 6380
#查看端口,確保服務啟動
[root@master2 ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:16380 0.0.0.0:* users:(("redis-server",pid=1885,fd=8))
tcp LISTEN 0 511 0.0.0.0:16379 0.0.0.0:* users:(("redis-server",pid=1848,fd=8))
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=1885,fd=6))
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=1848,fd=6))
啟動好全部 Redis 服務器后,接下來就是如何把這 6 個服務器按預先規劃的結構來組合成集群了。在做接下來的操作之前,一定要先確保所有 Redis 實例都已經成功啟動,并且對應實例的節點配置文件都已經成功生成。
#使用如下命令在所有主機上都可以看到所有實例生成的rdb文件和nodes文件
ls /var/lib/redis/
dump_6380.rdb dump.rdb nodes-6379.conf nodes-6380.conf
注意:如果沒看到dump_6380.rdb,前面無錯誤的話,是因為還沒有數據,屬于正常現象
準備工作做完就可以開始創建集群了
創建集群命令格式:
redis-cli --cluster create --cluster-replicas 副本數 主機IP:端口號 主機IP:端口號
#create 創建集群
#`節點總數 ÷ (replicas + 1)` 得到的就是master的數量。節點列表中的前n個就是master,其它節點都是slave節點,隨機分配到不同master。(Redis 的分配原則是:盡量保證每個主數據庫運行在不同的IP地址,每個從庫和主庫不在一個IP地址上。)
(3)創建 Redis Cluster 集群
所有實例啟動后,通過redis-cli --cluster create命令創建集群,指定 “每個主節點對應 1 個從節點”:
# 前3個為候選主節點,后3個為候選從節點
[root@master1 ~]# redis-cli --cluster create --cluster-replicas 1 192.168.2.10:6379 192.168.2.11:6379 192.168.2.12:6379 192.168.2.10:6380 192.168.2.11:6380 192.168.2.12:6380
# 命令解釋:
# --cluster-replicas 1:每個主節點分配1個從節點
# Redis會自動分配主從關系(原則:從節點與主節點不在同一IP,避免單點故障)
# 執行后會提示“是否接受該配置”,輸入yes確認#查看集群狀態
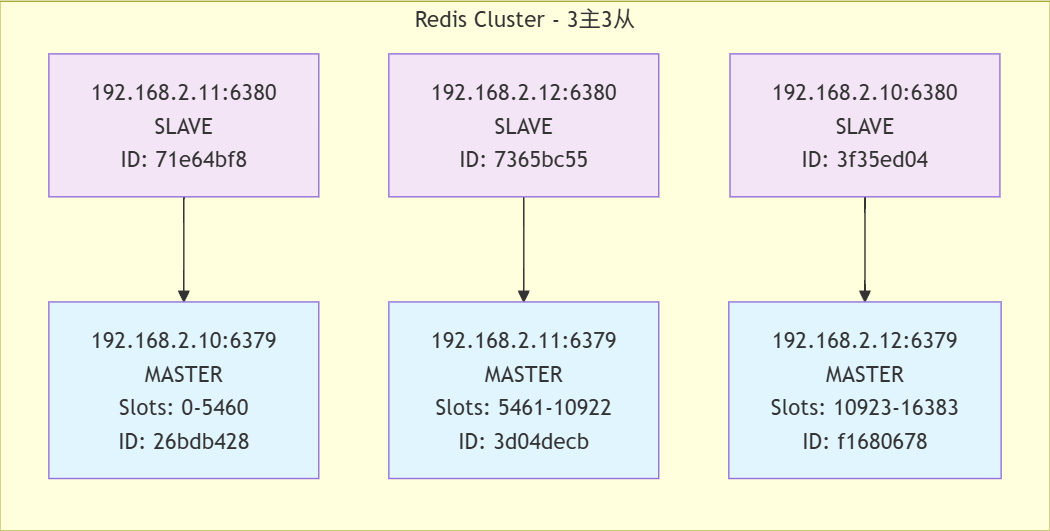
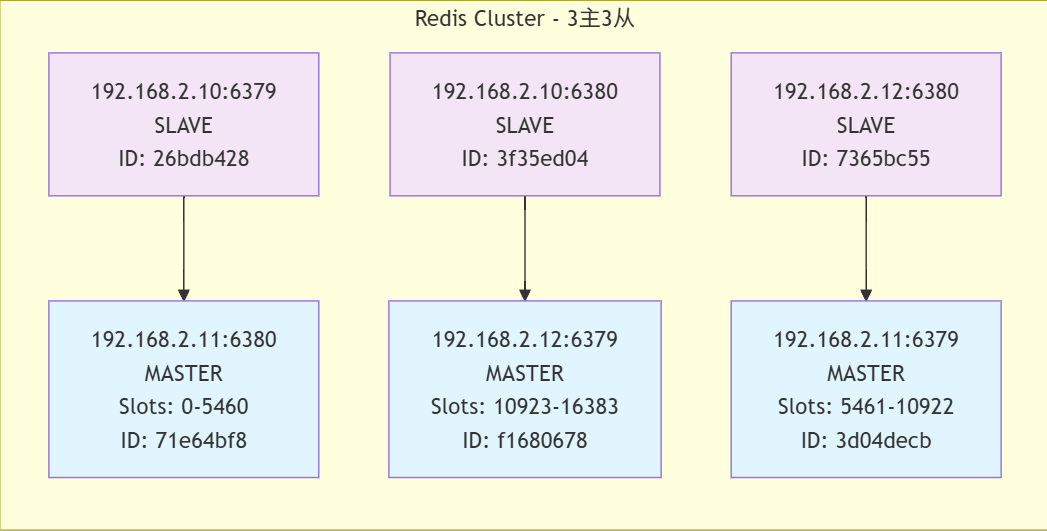
[root@master1 ~]# redis-cli -p 6379 cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757319959184 3 connected
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,master - 0 1757319958000 1 connected 0-5460
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757319959000 2 connected
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757319958000 3 connected 10923-16383
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 slave 26bdb428b70a027af429bfd3fe040a79987bfb3c 0 1757319958000 1 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757319957172 2 connected 5461-10922
通過拓撲圖可以更加清晰的看出結構
(4)集群功能驗證(數據分片與重定向)
通過-c參數啟用集群模式連接 Redis,驗證數據自動分片與重定向:
#加上-c表示啟用集群模式
[root@master1 ~]# redis-cli -p 6379 -c
127.0.0.1:6379> set a 9527
-> Redirected to slot [15495] located at 192.168.2.12:6379
OK
192.168.2.12:6379> set b WuYanZu
-> Redirected to slot [3300] located at 192.168.2.10:6379
OK
192.168.2.10:6379> set c hellokitty
-> Redirected to slot [7365] located at 192.168.2.11:6379
OK
192.168.2.11:6379> get a
-> Redirected to slot [15495] located at 192.168.2.12:6379
"9527"
192.168.2.12:6379> get b
-> Redirected to slot [3300] located at 192.168.2.10:6379
"WuYanZu"
192.168.2.10:6379> get c
-> Redirected to slot [7365] located at 192.168.2.11:6379
"hellokitty"
由此我們可以看出
這個 Redis 集群表現出以下關鍵特性:
- 數據分片:數據均勻分布在多個節點
- 一致性哈希:鍵到節點的映射穩定且一致
- 透明訪問:客戶端無需知道數據具體位置
- 高可用性:所有節點正常運行,數據可訪問
- 高性能:快速的重定向和響應
3. 集群故障轉移測試
(1)模擬 Master1(192.168.2.10:6379)故障,驗證從節點是否自動升級為主節點:
[root@master1 ~]# redis-cli -p 6379
127.0.0.1:6379> SHUTDOWN
not connected> exit
[root@master1 ~]# redis-cli -p 6380
127.0.0.1:6380> cluster nodes
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757321186609 2 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757321187616 2 connected 5461-10922
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757321186000 7 connected 0-5460
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 master,fail - 1757321174513 1757321172000 1 disconnected
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 myself,slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757321185000 3 connected
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757321184594 3 connected 10923-16383
可以看到192.168.2.10:6379變為了fail,而他的從192.168.2.11:6380變為了現在的主,如圖:
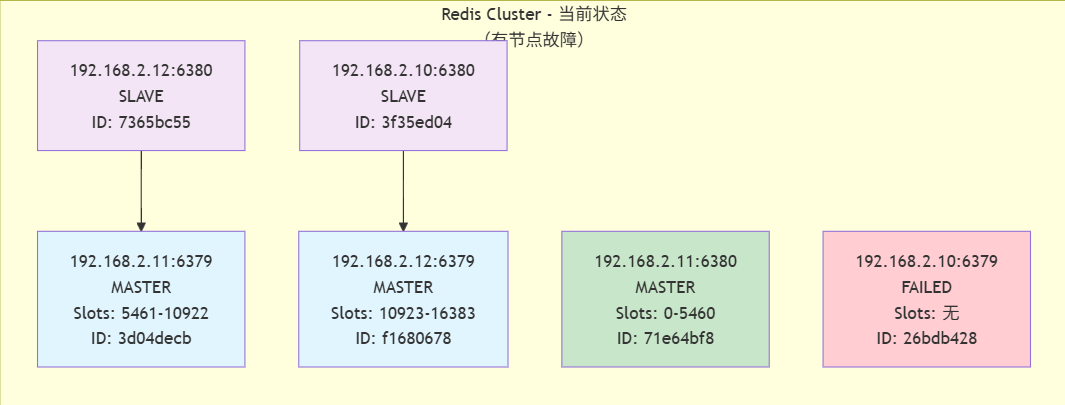
集群狀態分析
-
故障情況
故障節點: 192.168.2.10:6379 (原主節點,負責slots 0-5460)
故障時間: 1757321174513 (Unix時間戳,約2025年9月8日) -
故障轉移
新的主節點: 192.168.2.11:6380 (原為192.168.2.10:6379的從節點)
接管slot范圍: 0-5460
故障轉移成功: 集群自動完成了主從切換 -
當前集群結構
- 正常工作的主節點: 3個
192.168.2.11:6379 (slots 5461-10922)
192.168.2.12:6379 (slots 10923-16383)
192.168.2.11:6380 (slots 0-5460,故障轉移后晉升) - 從節點: 2個
192.168.2.12:6380 (復制192.168.2.11:6379)
192.168.2.10:6380 (復制192.168.2.12:6379)
- 正常工作的主節點: 3個
(2)再次啟動master1,可以發現master1變成了從
[root@master1 ~]# systemctl start redis
[root@master1 ~]# redis-cli -p 6379
127.0.0.1:6379> cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757321484000 3 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757321484923 2 connected 5461-10922
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757321485929 7 connected 0-5460
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757321484000 3 connected 10923-16383
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757321484000 7 connected
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757321484000 2 connected
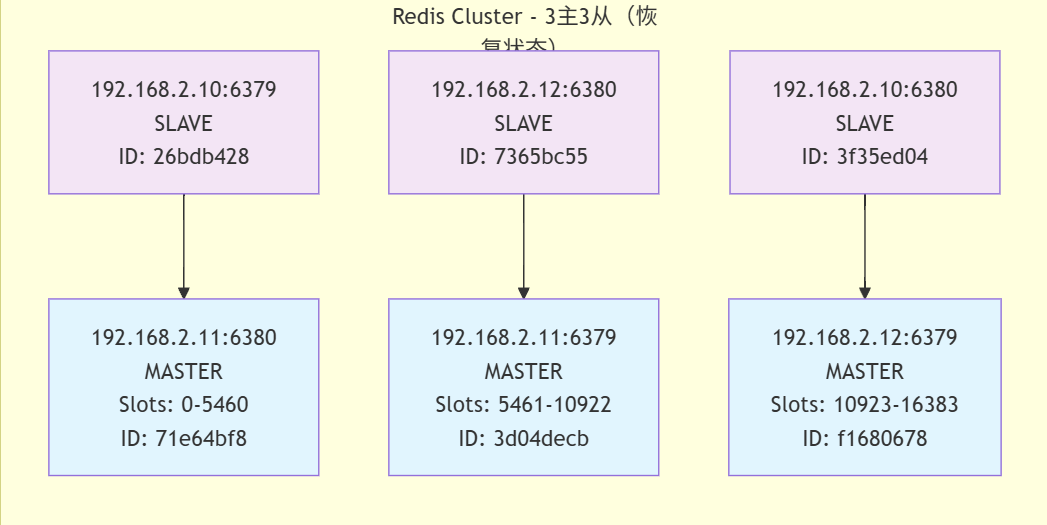
集群狀態分析
-
恢復后的集群結構
主節點: 3個
192.168.2.11:6380 (slots 0-5460) - 原從節點晉升
192.168.2.11:6379 (slots 5461-10922) - 保持不變
192.168.2.12:6379 (slots 10923-16383) - 保持不變
從節點: 3個
192.168.2.10:6379 (復制192.168.2.11:6380) - 原故障主節點恢復為從節點
192.168.2.12:6380 (復制192.168.2.11:6379) - 保持不變
192.168.2.10:6380 (復制192.168.2.12:6379) - 保持不變 -
故障恢復過程
原故障節點192.168.2.10:6379已恢復
但它沒有恢復為主節點,而是作為從節點加入了集群
它現在復制的是192.168.2.11:6380(故障轉移期間晉升的節點)
集群保持了3主3從的完整結構
注意:如果所有某段插槽的主從節點都宕機了,Redis 服務是否還能繼續?
答:當發生某段插槽的主從都宕機后,如果在 redis.conf 配置文件中的 cluster-require-full-coverage 參數的值為 yes ,那么整個集群都掛掉;如果參數的值為 no ,那么該段插槽數據全都不能使用,也無法存儲,其他段可以正常運行。
4.集群擴容(添加主從節點)
當集群容量不足時,可添加新的主從節點并重新分片。我們向現有集群中添加兩個節點,這兩個節點做一主一從。主節點的端口號為 6381,從節點的端口號為 6382。
(1)添加新實例配置
# 1. 創建6381(主)和6382(從)的配置文件
[root@master1 ~]# cp /etc/redis/redis.conf /etc/redis/redis-6381.conf
[root@master1 ~]# cp /etc/redis/redis.conf /etc/redis/redis-6382.conf
# 2. 修改6381配置(主節點)
[root@master1 ~]# sed -n 's/6379/6381/gp' /etc/redis/redis-6381.conf # 將所有6379替換為6381
# Accept connections on the specified port, default is 6381 (IANA #815344).
port 6381
# tls-port 6381
pidfile /var/run/redis_6381.pid
logfile /var/log/redis/redis_6381.log
dbfilename dump_6381.rdb
cluster-config-file nodes-6381.conf
# cluster-announce-tls-port 6381
[root@master1 ~]# sed -i 's/6379/6381/g' /etc/redis/redis-6381.conf
修改6382配置(從節點)
[root@master1 ~]# sed -i 's/6379/6382/g' /etc/redis/redis-6382.conf
[root@master1 ~]# redis-server /etc/redis/redis-6381.conf
[root@master1 ~]# redis-server /etc/redis/redis-6382.conf
# 5. 驗證新實例啟動
[root@master1 ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:16379 0.0.0.0:* users:(("redis-server",pid=1981,fd=8))
tcp LISTEN 0 511 0.0.0.0:16381 0.0.0.0:* users:(("redis-server",pid=2046,fd=8))
tcp LISTEN 0 511 0.0.0.0:16380 0.0.0.0:* users:(("redis-server",pid=1876,fd=8))
tcp LISTEN 0 511 0.0.0.0:16382 0.0.0.0:* users:(("redis-server",pid=2052,fd=8))
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=1981,fd=6))
tcp LISTEN 0 511 0.0.0.0:6381 0.0.0.0:* users:(("redis-server",pid=2046,fd=6))
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=1876,fd=6))
tcp LISTEN 0 511 0.0.0.0:6382 0.0.0.0:* users:(("redis-server",pid=2052,fd=6))
添加節點到集群的語法格式為:
redis-cli --cluster add-node new_host:new_port existing_host:existing_port--cluster-slave--cluster-master-id <arg>
add-node命令用于添加節點到集群中,參數說明如下:
- new_host:被添加節點的主機地址
- new_port:被添加節點的端口號
- existing_host:目前集群中已經存在的任一主機地址
- existing_port:目前集群中已經存在的任一端口地址
- –cluster-slave:用于添加從(Slave)節點
- –cluster-master-id:指定主(Master)節點的ID(唯一標識)字符串
(2)將新實例加入集群
## 1. 添加6381為主節點(關聯到現有集群)
# 192.168.2.10:6381:新主節點
# 192.168.2.10:6379:現有集群中的任意節點(用于定位集群)
[root@master1 ~]# redis-cli --cluster add-node 192.168.2.10:6381 192.168.2.10:6379
>>> Adding node 192.168.2.10:6381 to cluster 192.168.2.10:6379
>>> Performing Cluster Check (using node 192.168.2.10:6379)
S: 26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379slots: (0 slots) slavereplicates 71e64bf81ae2d0e667b3321911a04ba730926640
S: 3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380slots: (0 slots) slavereplicates f16806788448f2dd7b7d2cb64104a3a6c783a2a6
M: 3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379slots:[5461-10922] (5462 slots) master1 additional replica(s)
M: 71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380slots:[0-5460] (5461 slots) master1 additional replica(s)
M: f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379slots:[10923-16383] (5461 slots) master1 additional replica(s)
S: 7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380slots: (0 slots) slavereplicates 3d04decb42d25b78266ce19ebc3e9dac67932330
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.2.10:6381 to make it join the cluster.
[OK] New node added correctly.# 2. 獲取6381的節點ID(用于指定從節點關聯)
[root@master1 ~]# redis-cli -p 6381
127.0.0.1:6381> cluster nodes
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757322589884 7 connected 0-5460
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757322590086 2 connected
65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381@16381 myself,master - 0 1757322588000 0 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757322590891 2 connected 5461-10922
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757322589000 3 connected
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757322589000 7 connected
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757322588000 3 connected 10923-16383
127.0.0.1:6381> exit
# --cluster-slave:標記為從節點
# --cluster-master-id:指定主節點ID(6381的ID)
[root@master1 ~]# redis-cli --cluster add-node 192.168.2.10:6382 192.168.2.10:6379 --cluster-slave --cluster-master-id 65314ae3be4d4e58b0f2272108d98c878e8a3ca4
>>> Adding node 192.168.2.10:6382 to cluster 192.168.2.10:6379
>>> Performing Cluster Check (using node 192.168.2.10:6379)
S: 26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379slots: (0 slots) slavereplicates 71e64bf81ae2d0e667b3321911a04ba730926640
S: 3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380slots: (0 slots) slavereplicates f16806788448f2dd7b7d2cb64104a3a6c783a2a6
M: 3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379slots:[5461-10922] (5462 slots) master1 additional replica(s)
M: 71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380slots:[0-5460] (5461 slots) master1 additional replica(s)
M: f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379slots:[10923-16383] (5461 slots) master1 additional replica(s)
M: 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381slots: (0 slots) master
S: 7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380slots: (0 slots) slavereplicates 3d04decb42d25b78266ce19ebc3e9dac67932330
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.2.10:6382 to make it join the cluster.
Waiting for the cluster to join>>> Configure node as replica of 192.168.2.10:6381.
[OK] New node added correctly.
(3)重新分片(分配 Slot 給新主節點)
新主節點默認無 Slot,需從現有主節點遷移 Slot(本例遷移 612 個 Slot 給 6381):
由于集群中增加了新節點,需要對現有數據重新進行分片操作。重新分片的語法如下:
redis-cli --cluster reshard host:port--cluster-from <arg>--cluster-to <arg>--cluster-slots <arg>--cluster-yes--cluster-timeout <arg>--cluster-pipeline <arg>--cluster-replace
reshard命令用于重新分片,參數說明如下:
- host:集群中已經存在的任意主機地址
- port:集群中已經存在的任意主機對應的端口號
- –cluster-from:表示slot目前所在的master節點node ID(不能寫slaveID,都必須寫master唯一標識),多個ID用逗號分隔
- –cluster-to:表示需要分配節點的node ID(不能寫slaveID,都必須寫master唯一標識)
- –cluster-slot:分配的slot數量
- –cluster-yes:指定遷移時的確認輸入
- –cluster-timeout:設置migrate命令的超時時間
- –cluster-pipeline:定義cluster getkeysinslot命令一次取出的key數量,不傳的話使用默認值為10
- –cluster-replace:是否直接replace到目標節點
1.查看現有主節點ID(確定從哪個主節點遷移Slot)
[root@master1 ~]# redis-cli -p 6379
127.0.0.1:6379> cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757323378295 3 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757323378000 2 connected 5461-10922
d092030167c5dd384922569cffcdc1768230f73a 192.168.2.10:6382@16382 slave 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 0 1757323381000 0 connected
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757323381000 7 connected 0-5460
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757323381313 3 connected 10923-16383
65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381@16381 master - 0 1757323380307 0 connected
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757323378000 7 connected
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757323379000 2 connected
127.0.0.1:6379> exit
2. 執行重新分片
[root@master1 ~]# redis-cli --cluster reshard 192.168.2.10:6379 \
> --cluster-from f16806788448f2dd7b7d2cb64104a3a6c783a2a6 \ #master3的ID
> --cluster-to 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 \ #6381的ID
> --cluster-slots 612 \ #分配的slot數量
> --cluster-yes \
> --cluster-timeout 5000 \
> --cluster-pipeline 10 \
> --cluster-replace
驗證分片結果
[root@master1 ~]# redis-cli -p 6379
127.0.0.1:6379> cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757324010041 3 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757324007023 2 connected 5461-10922
d092030167c5dd384922569cffcdc1768230f73a 192.168.2.10:6382@16382 slave 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 0 1757324009000 8 connected
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757324010041 7 connected 0-5460
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757324008029 3 connected 11535-16383
65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381@16381 master - 0 1757324009035 8 connected 10923-11534
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757324008000 7 connected
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d、
拓撲圖
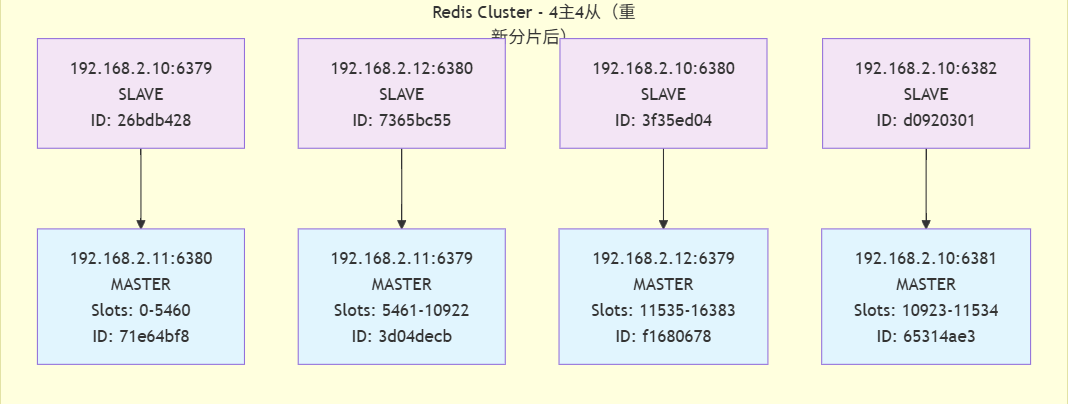
集群狀態分析
- 重新分片結果
重新分片操作已成功完成,現在集群有4個主節點,每個都負責一部分slot:
-
192.168.2.11:6380: 負責 slots 0-5460 (共5461個slot)
-
192.168.2.11:6379: 負責 slots 5461-10922 (共5462個slot)
-
192.168.2.10:6381: 負責 slots 10923-11534 (共612個slot)
-
192.168.2.12:6379: 負責 slots 11535-16383 (共4849個slot)
- Slot分配變化
-
原192.168.2.12:6379節點負責的slot范圍從10923-16383縮減為11535-16383
-
新節點192.168.2.10:6381獲得了10923-11534范圍的slot(共612個slot)
- 當前集群結構
-
主節點: 4個,分布在3臺服務器上
-
192.168.2.11: 2個主節點 (6379和6380)
-
192.168.2.12: 1個主節點 (6379)
-
192.168.2.10: 1個主節點 (6381)
-
-
從節點: 4個,提供高可用性
-
每個主節點都有對應的從節點
-
從節點分布在不同的服務器上,確保容錯
-
5. 集群縮容
縮容與擴容相反,需先將待刪除節點的 Slot 遷移到其他主節點,再刪除節點(避免數據丟失):
# 1. 查看待刪除節點的Slot分布(確保Slot已遷移完畢)
[root@master1 ~]# redis-cli --cluster check 192.168.2.10:6379
192.168.2.11:6379 (3d04decb...) -> 1 keys | 5462 slots | 1 slaves.
192.168.2.11:6380 (71e64bf8...) -> 1 keys | 5461 slots | 1 slaves.
192.168.2.12:6379 (f1680678...) -> 1 keys | 4849 slots | 1 slaves.
192.168.2.10:6381 (65314ae3...) -> 0 keys | 612 slots | 1 slaves.
[OK] 3 keys in 4 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.2.10:6379)
S: 26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379slots: (0 slots) slavereplicates 71e64bf81ae2d0e667b3321911a04ba730926640
S: 3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380slots: (0 slots) slavereplicates f16806788448f2dd7b7d2cb64104a3a6c783a2a6
M: 3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379slots:[5461-10922] (5462 slots) master1 additional replica(s)
S: d092030167c5dd384922569cffcdc1768230f73a 192.168.2.10:6382slots: (0 slots) slavereplicates 65314ae3be4d4e58b0f2272108d98c878e8a3ca4
M: 71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380slots:[0-5460] (5461 slots) master1 additional replica(s)
M: f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379slots:[11535-16383] (4849 slots) master1 additional replica(s)
M: 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381slots:[10923-11534] (612 slots) master1 additional replica(s)
S: 7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380slots: (0 slots) slavereplicates 3d04decb42d25b78266ce19ebc3e9dac67932330
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@master1 ~]# redis-cli --cluster reshard 192.168.2.10:6379 \
> --cluster-from 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 \
> --cluster-to f16806788448f2dd7b7d2cb64104a3a6c783a2a6 \
> --cluster-slots 612
#省略輸出
刪除節點的語法格式為:
redis-cli --cluster del-node host:port node_id
del-node命令用于從集群中刪除節點,參數說明如下:
- host:集群中已經存在的主機地址
- port:集群中已經存在的主機對應的端口號
- node_id:要刪除的節點ID
- 先刪除從節點,如果先刪除主節點,從會故障轉移
1. 刪除從節點(先刪從,再刪主)
[root@master1 ~]# redis-cli --cluster del-node 192.168.2.10:6382 d092030167c5dd384922569cffcdc1768230f73a
>>> Removing node d092030167c5dd384922569cffcdc1768230f73a from cluster 192.168.2.10:6382
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
2. 刪除主節點(需確保無Slot)
[root@master1 ~]# redis-cli --cluster del-node 192.168.2.10:6381 65314ae3be4d4e58b0f2272108d98c878e8a3ca4
>>> Removing node 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 from cluster 192.168.2.10:6381
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
[root@master1 ~]# redis-cli -p 6379 cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757325635000 9 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757325636000 2 connected 5461-10922
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757325637567 7 connected 0-5460
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757325634000 9 connected 10923-16383
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757325636000 7 connected
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757325636562 2 connected
集群拓撲分析
- 主從關系
-
主節點1 (192.168.2.11:6380) → 從節點 (192.168.2.10:6379)
-
主節點2 (192.168.2.11:6379) → 從節點 (192.168.2.12:6380)
-
主節點3 (192.168.2.12:6379) → 從節點 (192.168.2.10:6380)
- 數據分片
-
節點1 (192.168.2.11:6380): 負責 slots 0-5460
-
節點2 (192.168.2.11:6379): 負責 slots 5461-10922
-
節點3 (192.168.2.12:6379): 負責 slots 10923-16383
- 物理服務器分布
-
192.168.2.10: 運行2個從節點 (6379, 6380)
-
192.168.2.11: 運行2個主節點 (6379, 6380)
-
x192.168.2.12: 運行1個主節點 (6379) 和1個從節點 (6380)
四、總結
- 主從復制:
- 主節點專門負責寫數據,從節點會跟著主節點同步數據,還能幫著處理讀請求。這樣一來,主節點的數據有備份(從節點存了一樣的),讀請求多的時候也不用都擠著主節點,能分散壓力。缺點是單主故障系統就完蛋了,也不能漂移IP。
- 哨兵:
在主從復制的基礎上工作,專門盯著主節點。要是主節點壞了,不用人手動操作,哨兵會自動挑個數據最全、最靠譜的從節點,讓它變成新的主節點,10-30 秒就能恢復服務,不用等著停業。可以解決主節點故障,也可以漂移IP,缺點是寫操作無法擴展。
- Cluster:
適合業務變大的情況,是多主多從的模式。把所有數據分成好多小塊,每個主節點管一塊,每個主節點再配個從節點備份數據。要是哪個主節點壞了,它的從節點能頂上;業務再變大,還能加新的主從節點(擴容),解決了單個主節點扛不動大業務的問題。它同時解決了主從復制(單點故障、容量瓶頸)和哨兵(寫操作無法擴展)的缺點,是支撐大規模、高并發需求的終極方案。


















)
