什么是感興趣區域(ROI)?
在計算機視覺中,**感興趣區域(ROI)**指的是圖像中包含我們想要分析、處理或識別的目標或特征的特定子集。就像我們在閱讀一本書時會聚焦于某個重要的段落,計算機視覺系統在處理圖像時,也會將注意力集中到圖像中對任務最有價值的區域,而非整個圖像。
使用ROI的主要目的是提高效率和減少計算負擔。通過僅處理ROI,我們可以:
- 加速處理速度:減少需要處理的數據量。
- 提高精度:通過排除背景噪聲和無關信息,更精確地識別和分析目標。
- 節省內存:只需加載和存儲圖像的特定部分。
ROI的類型和表示方法
ROI可以有多種形狀和表示方式,最常見的是:
- 矩形(Bounding Box):這是最常用、最簡單的ROI形式,通過左上角和右下角的坐標(或左上角坐標和寬度、高度)來定義。這在目標檢測任務中非常普遍。
- 多邊形(Polygon):當目標形狀不規則時,多邊形ROI可以更精確地圈定目標,如在分割或某些特殊檢測任務中。
- 圓形(Circle):常用于檢測圓形物體,如螺栓、圓形標志等。
- 掩模(Mask):一個二進制圖像,與原圖大小相同,其中ROI區域的像素值為1(或255),其余區域為0。這在**實例分割(Instance Segmentation)**中尤為重要,因為它能精確到像素級別地分割出目標。
ROI在計算機視覺中的核心應用
ROI在計算機視覺的多個子領域扮演著至關重要的角色:
目標檢測 (Object Detection)
目標檢測的任務是識別圖像中所有感興趣的物體,并用**邊界框(Bounding Box)**標記出它們的位置。在這里,ROI是核心概念。
- R-CNN (Region-based Convolutional Neural Networks) 系列算法(如R-CNN, Fast R-CNN, Faster R-CNN)是典型的基于ROI的方法。這些算法首先通過**區域提議網絡(Region Proposal Network, RPN)**在圖像中生成大量的潛在ROI,然后對這些ROI進行分類和邊界框回歸,以確定它們是否包含目標。
- **無提議(Proposal-free)**的算法,如YOLO(You Only Look Once)和SSD(Single Shot Detector),雖然不明確生成ROI,但它們在特征圖上劃分網格,每個網格負責預測其所包含的目標,這種思想在本質上也是對圖像區域進行局部關注。
圖像分割 (Image Segmentation)
圖像分割將圖像中的每個像素都分類。在實例分割中,ROI的作用尤為明顯。
- Mask R-CNN 是實例分割領域的代表性算法。它在Faster R-CNN的基礎上,增加了一個用于預測**掩模(Mask)**的分支。對于每個檢測到的ROI,該網絡不僅預測其類別和位置,還生成一個像素級別的掩模,精確地分割出目標。
人臉識別與分析 (Face Recognition and Analysis)
在人臉識別系統中,第一步通常是人臉檢測,即在圖像中定位人臉的位置并用一個矩形框(ROI)將其框起來。
- 一旦確定了人臉ROI,后續的步驟,如面部對齊(Face Alignment)、特征提取和身份識別,都只在ROI內部進行,極大地簡化了計算,并提高了識別的準確性。
- 同樣,在情感分析和年齡、性別識別等任務中,也都是先定位人臉ROI,再進行后續的分析。
視頻監控與跟蹤 (Video Surveillance and Tracking)
在視頻監控中,ROI可以用于行人檢測、車輛跟蹤和異常行為分析。
- 通過在視頻流中持續追蹤某個目標的ROI,可以實現穩定、高效的目標跟蹤。例如,一旦檢測到一個移動的車輛,系統就會在每一幀中只在車輛的ROI附近進行搜索,而不是掃描整個畫面。
ROI的提取和選擇
提取ROI的方法多種多樣,這取決于具體的應用和算法:
- 傳統方法:
- 滑動窗口(Sliding Window):在圖像上以固定步長移動一個窗口,每個窗口都作為一個潛在的ROI。這種方法計算量大,效率低。
- 基于輪廓或邊緣檢測:通過Canny、Sobel等算子提取圖像中的邊緣,再根據邊緣信息尋找封閉區域作為ROI。
- 基于深度學習的方法:
- 區域提議網絡 (RPN):這是目前主流的方法,它能在訓練中學習如何有效地生成高質量的ROI,大大優于傳統的滑動窗口方法。
- 注意力機制 (Attention Mechanism):在一些最新的網絡架構中,注意力機制可以讓網絡自動“關注”到圖像中重要的區域,這本質上也是一種動態的ROI選擇。
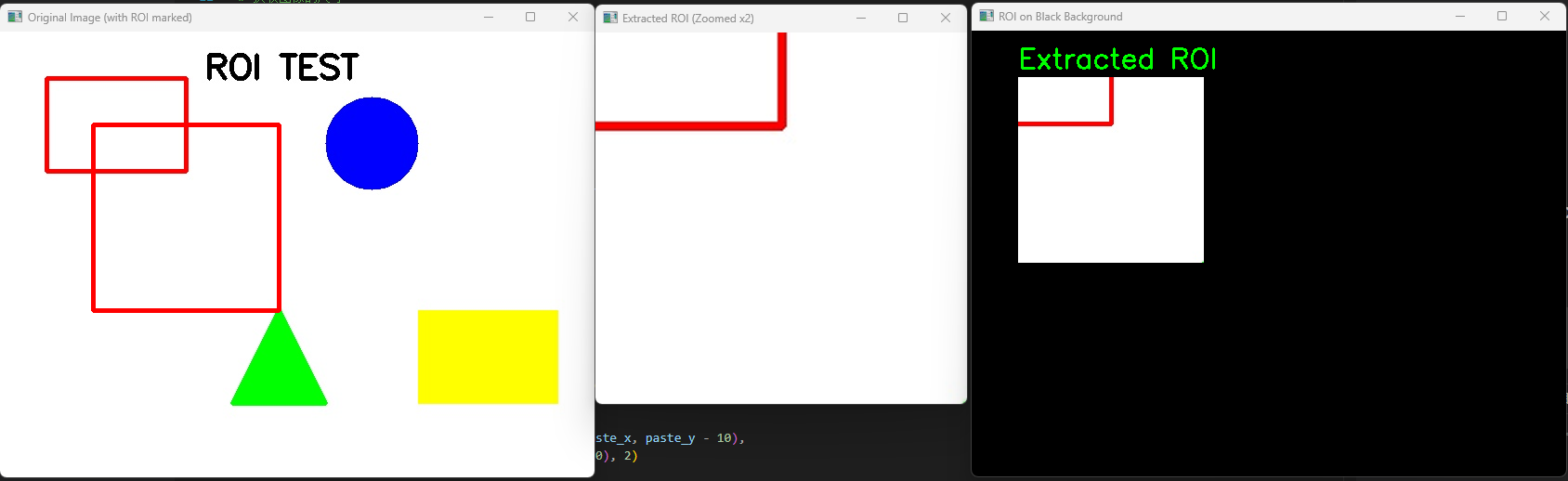
opencv實現ROI
import cv2
import numpy as np# 1. 讀取圖像
image = cv2.imread('test.jpg')# 檢查圖像是否成功讀取
if image is None:print("錯誤:無法讀取圖像。請檢查文件路徑是否正確。")exit()# 獲取圖像的尺寸
height, width = image.shape[:2]
print(f"原始圖像尺寸:寬 {width},高 {height}")# 2. 定義ROI的坐標
x_start, y_start = 100, 100
x_end, y_end = 300, 300# 3. 裁剪ROI
roi = image[y_start:y_end, x_start:x_end]
roi_height, roi_width = roi.shape[:2]
print(f"裁剪的ROI尺寸:寬 {roi_width},高 {roi_height}")# 4. 在原圖上畫出ROI區域的紅色矩形框
image_with_roi = image.copy()
cv2.rectangle(image_with_roi, (x_start, y_start), (x_end, y_end), (0, 0, 255), 3)# 5. 創建一個全黑的背景圖像,用于放置ROI
black_background = np.zeros(image.shape, dtype=np.uint8)# 將ROI粘貼到背景圖像上 (偏移 50,50)
paste_x, paste_y = 50, 50
black_background[paste_y : paste_y + roi_height, paste_x : paste_x + roi_width] = roi# 在粘貼的ROI旁邊加文字說明
cv2.putText(black_background, "Extracted ROI", (paste_x, paste_y - 10),cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)# 6. 放大ROI圖像,方便觀察細節
roi_zoomed = cv2.resize(roi, (roi_width * 2, roi_height * 2), interpolation=cv2.INTER_CUBIC)# 7. 顯示結果
cv2.imshow('Original Image (with ROI marked)', image_with_roi)
cv2.imshow('Extracted ROI (Zoomed x2)', roi_zoomed)
cv2.imshow('ROI on Black Background', black_background)# 等待按鍵,然后關閉所有窗口
cv2.waitKey(0)
cv2.destroyAllWindows()
執行效果:




)


![[數據結構——lesson2.順序表]](http://pic.xiahunao.cn/[數據結構——lesson2.順序表])

:多容器管理與集群部署實踐)


:原理、實現與避坑指南】)






)