本文較長,建議點贊收藏,以免遺失。更多AI大模型應用開發學習視頻及資料,盡在聚客AI學院。
不知道你們有沒有遇到過,在我們一些實際落地的AI項目中,雖然前期“Demo 很驚艷,但上線后卻無人問津”。你們有沒有想過問題究竟在哪?今天我將從企業級 AI 應用的真實場景切入,并通過一個Demo構建,探討 AI 在數據層的真正需求,以及企業應如何構建合適的數據底座來支撐真實的 AI 應用。如果對你有所幫助,記得告訴身邊有需要的人。
一、超預期的真實業務需求
研究表明,許多AI項目在演示階段效果驚艷,但上線后卻無人問津。核心問題在于真實業務場景的復雜性遠超預期——用戶需求往往融合多維度要素,而非簡單的單點查詢。例如:
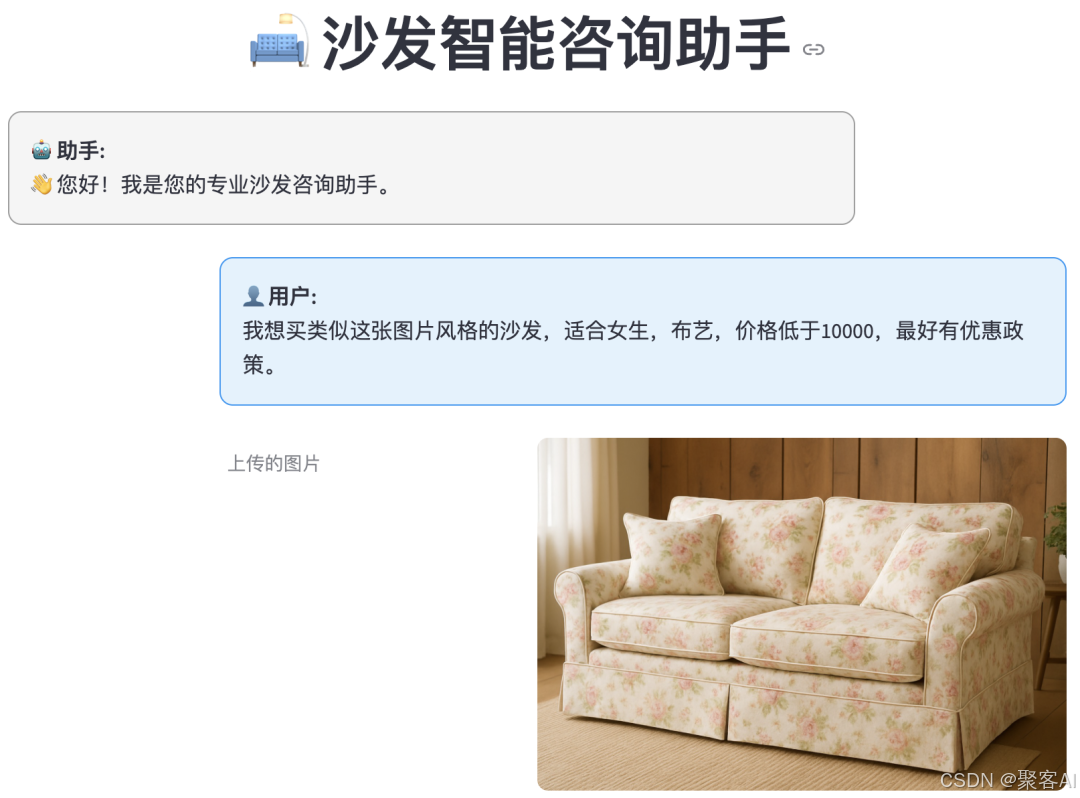
用戶可能請求:“找到類似這張圖片的布藝沙發,價格低于8000元,適合女性使用,且朝陽區附近有銷售點。”
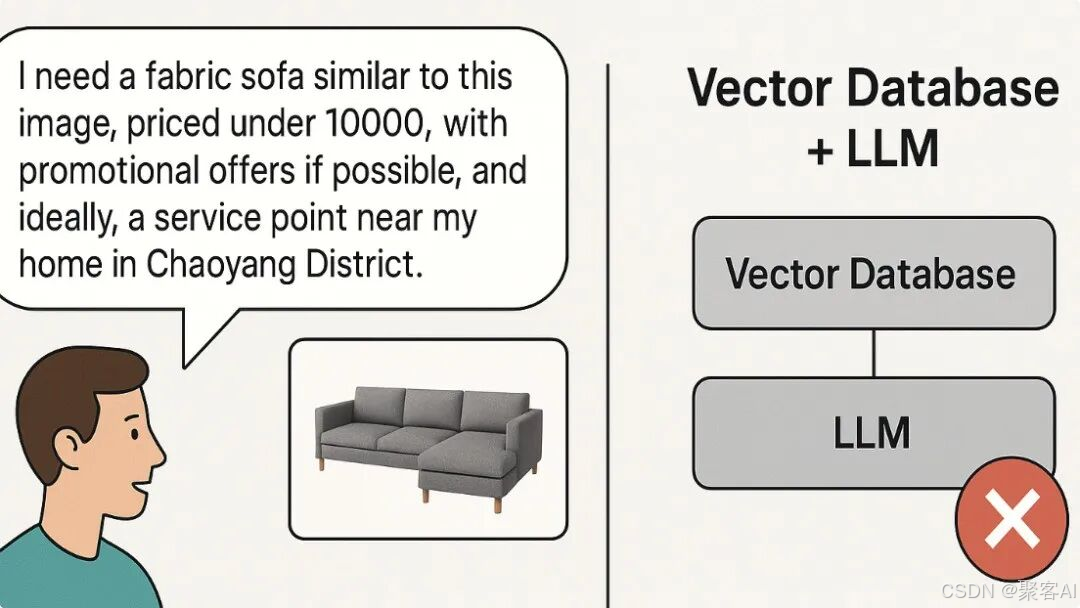
或更復雜的業務場景:“篩選北京地區近三個月購買過家居產品的客戶,優先向庫存量大的SKU發放涉及配送問題的優惠券。”
這類請求需同時處理圖像匹配、價格過濾、地理位置約束、用戶畫像分析等多模態數據。傳統RAG或Agent方案常因數據孤島和檢索維度單一而失效,根源在于企業數據割裂:結構化數據(價格、庫存)與非結構化數據(文本、圖像)分離存儲,導致混合檢索效率低下。
??二、問題剖析:數據孤島與檢索天花板??
企業AI應用的核心瓶頸是數據的割裂性:
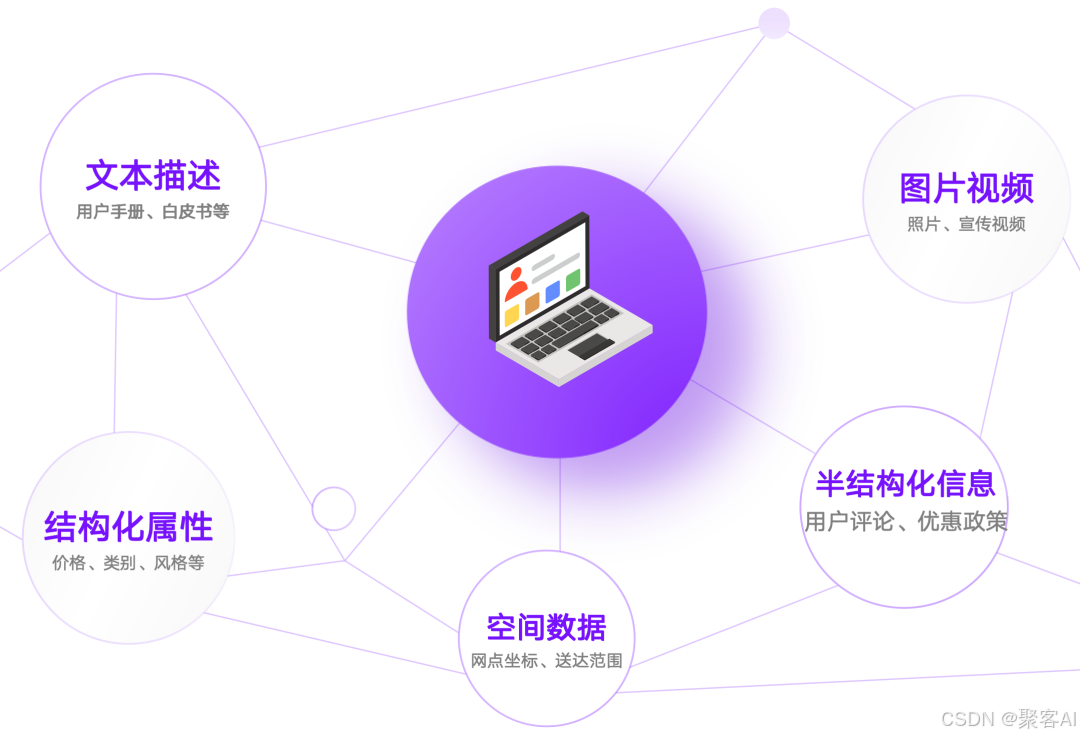
??數據多樣性常態??:產品信息包含圖片、參數、評價等多模態內容;交易數據涉及金額、時間、地點;用戶數據涵蓋行為、畫像等。

??查詢復雜性必然??:真實場景需融合語義相似度、數值區間、空間位置等多條件檢索。例如:圖像匹配+庫存狀態+用戶偏好,或關鍵詞搜索+時間范圍+關聯推薦。
??傳統方案局限??:
- 向量數據庫擅長文本相似度,但難以關聯結構化數據(如價格區間)。
- 多系統拼接(SQL+向量API)導致低效和一致性風險。
??解決方案:融合AI數據層架構??
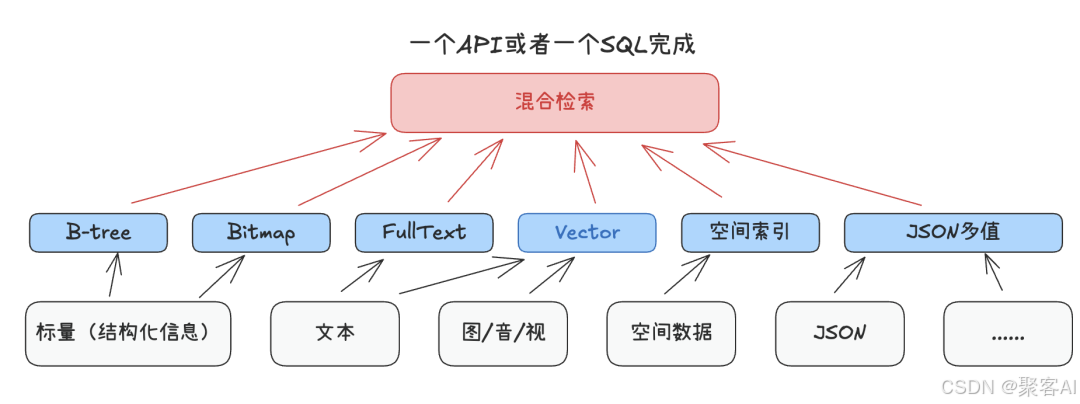
為破解上述問題,??一體化AI數據底座??成為關鍵技術方向。其核心是通過統一存儲和檢索引擎,支持多模態數據(文本、圖像、結構化字段)的混合負載:
統一數據層優勢??:
- 多模態融合:圖像、文本向量與JSON/空間數據統一存儲。
- 混合檢索:單條SQL實現語義相似度、屬性過濾、空間查詢。
- 架構簡化:減少跨系統同步,提升實時性與一致性。
??三、實戰:構建多模態混合檢索Agent??
以下Demo展示基于真實場景的實現:
??場景設計??
用戶多輪對話示例:
“推薦類似圖片的布藝沙發,價格<10000元,有優惠政策。”
“產品維護手冊詳情?”
“再買一款相似但更大的沙發。”??技術選型??
- ??融合數據層??:OceanBase(支持向量、JSON、空間數據類型)。
- ??開發框架??:LangGraph(靈活工作流編排)。
- ??模型??:國內多模態嵌入模型。
??方案設計??
核心流程:
- ??條件抽取??:LLM解析用戶請求,生成結構化過濾條件(材質、價格、圖像向量)。

- ??混合檢索SQL??:單語句融合向量相似度、屬性過濾和空間查詢:
SELECT cosine_distance(image_vector, [圖片向量]) AS img_similarity, cosine_distance(description_vector, [文本向量]) AS text_similarity, ...
FROM products
WHERE style='布藝' AND price<=10000
ORDER BY img_similarity ASC LIMIT 3; 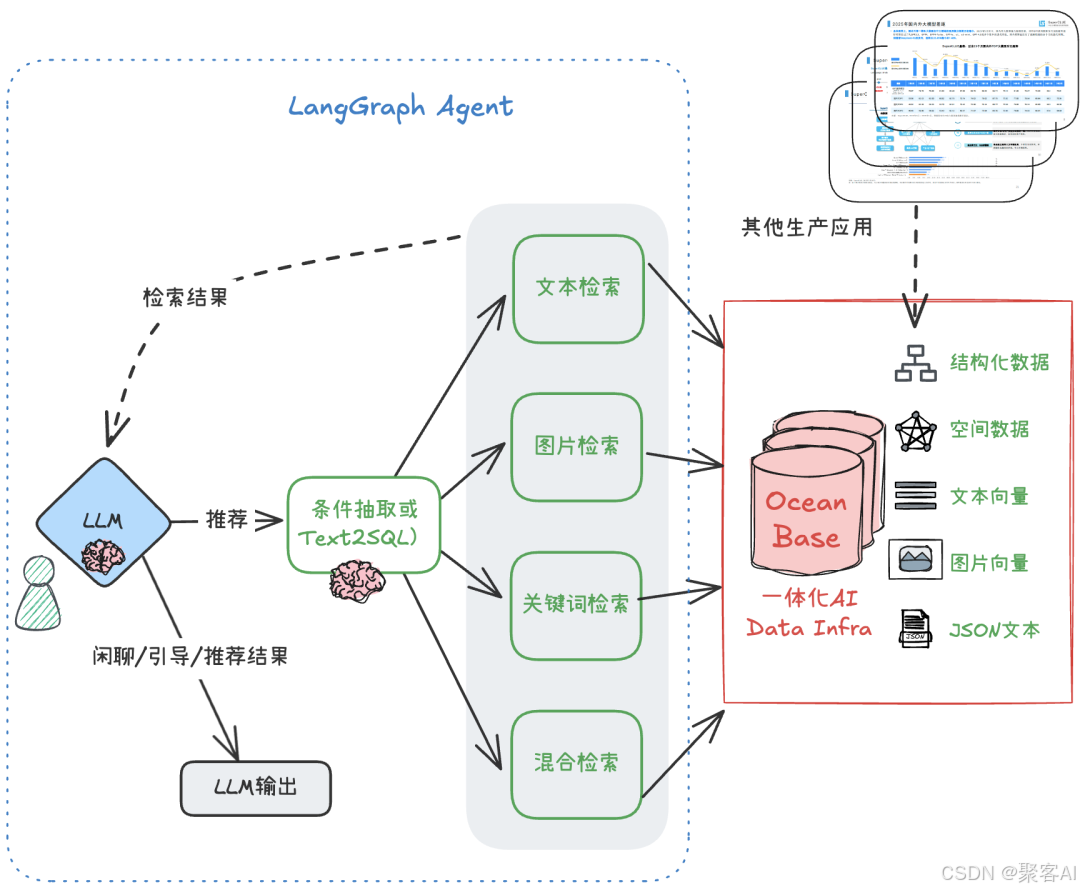
- ??工作流整合??:LangGraph協調意圖識別、檢索與結果生成。
??測試效果??
- 用戶輸入與Agent處理過程:
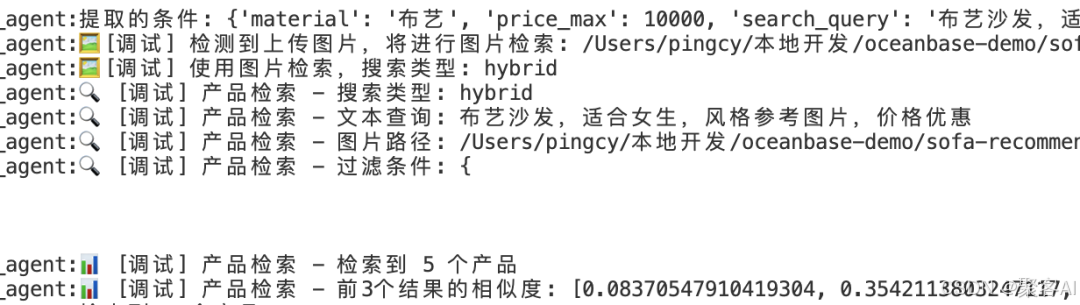
- 輸出結果:精準匹配圖像、價格與位置條件的產品推薦:

?ps:完整的示例代碼我已為大家準備好了,建議朋友們都跑一下,能更好幫助各位加速企業AI項目落地。粉絲朋友自取:《【實戰代碼】OceanBase 多模態產品推薦系統》?
四、擴展:兼容傳統RAG場景??
融合數據層不替代傳統方案,而是無縫集成:
- ??知識庫RAG兼容性??:存儲產品手冊向量,關聯結構化數據檢索:
SELECT chunk_content, cosine_distance(chunk_vector, ?) AS similarity
FROM products_docs
WHERE product_id=? AND similarity<=0.8
ORDER BY similarity ASC LIMIT 3; 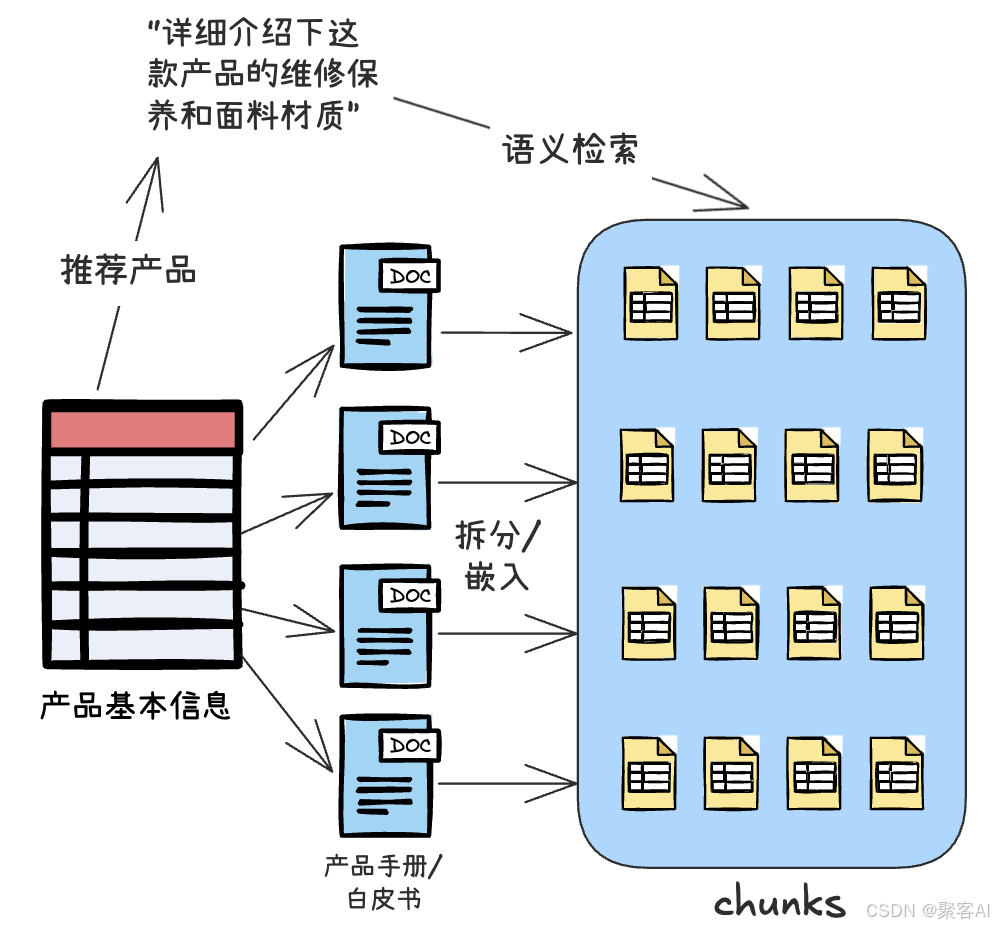
- ??低代碼平臺支持??:OceanBase PowerRAG簡化開發(預覽版):
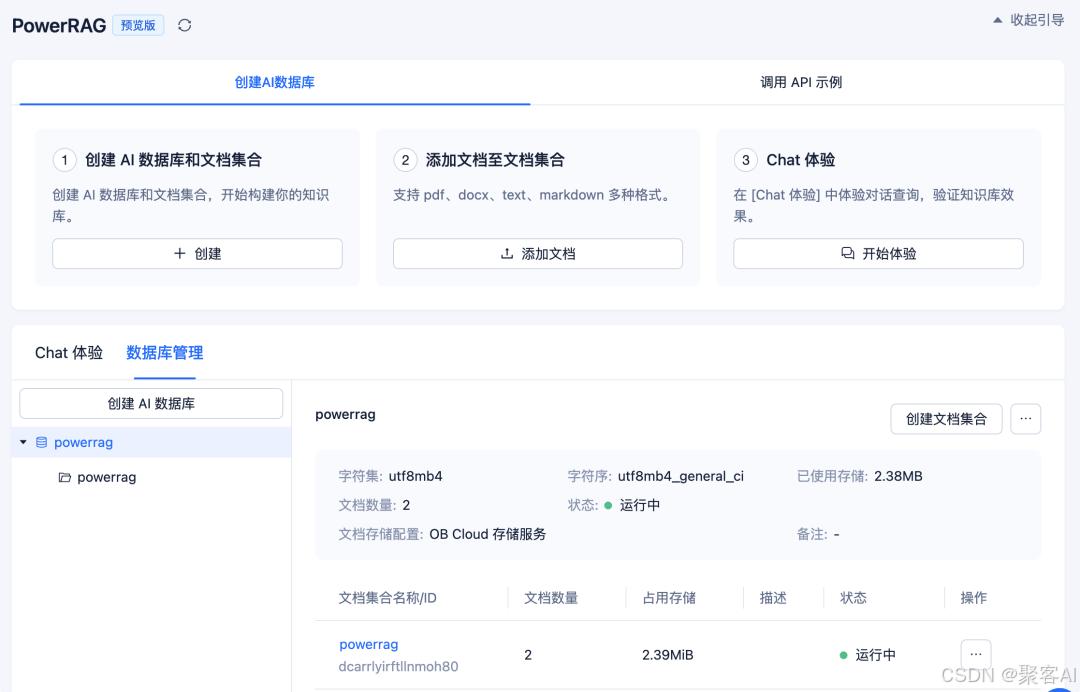
筆者總結:?
融合AI數據層(如OceanBase)通過四大優勢推動企業AI落地:
- ??架構極簡??:統一SQL接口替代多系統粘合,降低開發復雜度。
- ??檢索高效??:多模態混合檢索提升相關性(語義+精確過濾)。
- ??實時一致??:事務保障避免數據延遲風險。
- ??企業級擴展??:高可用、分布式架構支撐海量數據。
傳統數據庫廠商正借此實現AI時代轉型——一體化數據底座不僅是技術優化,更是釋放AI商業潛力的核心引擎。好了,今天的分享就到這里,點個小紅心,我們下期見。

)



|入門的開始:Linux基本指令(2))













