Task07:第三章 預訓練語言模型PLM
(這是筆者自己的學習記錄,僅供參考,原始學習鏈接,愿 LLM 越來越好?)
本篇介紹3種很典的decoder-only的PLM(GPT、LlaMA、GLM)。目前火🔥的LLM基本都是用解碼器的架構
什么是Decoder-Only的PLM?
就是Transformer的decoder層堆疊,或者在此基礎上改進而來的。
對NLG,生成任務比較牛,這也是為什么用來做LLM生成文本。
GPT
GPT-123如何一步步超越BERT
= Generative Pre-Training Language Model 生成式預訓練語言模型
1. 歷程:
- 2018年OpenAI就已經發了GPT,但是那時候性能還不行,比BERT差。
- –>通過增大數據集、參數,(認為的“體量即正義”)讓模型能力得到了突破【
涌現能力:不知怎的當年的小黑變身了】 - –> 2020年 GPT-3 就BOOM💣了
2. GPT-123的對比
主打一個越來越大,最終 GPT-3 達到了百億級別參數量和百GB級別的語料規模。(這里對數量級有個認知就差不多了)
| 模型 | Decoder Layer | Hidden Size | 注意力頭數 | 注意力維度 | 總參數量 | 預訓練語料 |
|---|---|---|---|---|---|---|
| GPT-1 | 12 | 3072 | 12 | 768 | 0.12B | 5GB |
| GPT-2 | 48 | 6400 | 25 | 1600 | 1.5B | 40GB |
| GPT-3 | 96 | 49152 | 96 | 12288 | 175B | 570GB |
GPT-2比1的變化:
規模變大 + 嘗試 zero-shot(這種方式GPT-3都不太行,2的效果肯定一般)
GPT-3比2的變化:
規模瘋狂大 + few-shot(這個不是預訓練+微調 范式了)
注:GPT-3 要在1024張 A100(80GB顯存)顯卡上分布式 訓1個月(顯卡要千張,時間要幾十天)
chatGPT:
模型:GPT-3
方法:預訓練+指令微調+RLHF(人類反饋強化學習)
什么是zero-shot?什么是few-shot?
零樣本學習:就是預訓練訓完PLM就用來做任務了,不再進行微調;
少樣本學習:是零樣本學習和微調的偏0的折中,一般在prompt里面給3-5個例子(讓PLM稍微知道我說的任務是怎么個回事)。
如:
zero-shot:請你判斷‘這真是一個絕佳的機會’的情感是正向還是負向,如果是正向,輸出1;否則輸出0few-shot:請你判斷‘這真是一個絕佳的機會’的情感是正向還是負向,如果是正向,輸出1;否則輸出0。你可以參考以下示例來判斷:‘你的表現非常好’——1;‘太糟糕了’——0;‘真是一個好主意’——1。
GPT的預訓練任務CLM
CLM = Casual Language Modeling 因果語言建模
(ps:這里原文寫的是模型model,但我覺得這是一個任務,所以我喜歡把它理解成是modeling建模)
什么是CLM?
可以看出是N-gram的拓展。
前面所有token 預測 下一個token,補全。
一直重復這個訓練過程,模型漸漸就能預判了。
(比之前其他PLM的預訓練任務MLM掩碼的、NLP下一句,更直接)
input: 今天天氣
output: 今天天氣很input: 今天天氣很
output:今天天氣很好
GPT模型架構
- 位置編碼:
GPT 沿用transformer典的Sinusoidal(三角函數絕對位置編碼)BERT用的可訓練的全連接層 - 注意力:
和tran的不一樣了,因為前面無encoder了,反而變得類encoder了。只有一次掩碼自注意。 - 歸一化:
采用pre-norm,很典的 - FNN:
用的2個一維卷積核而不是tran的線性矩陣
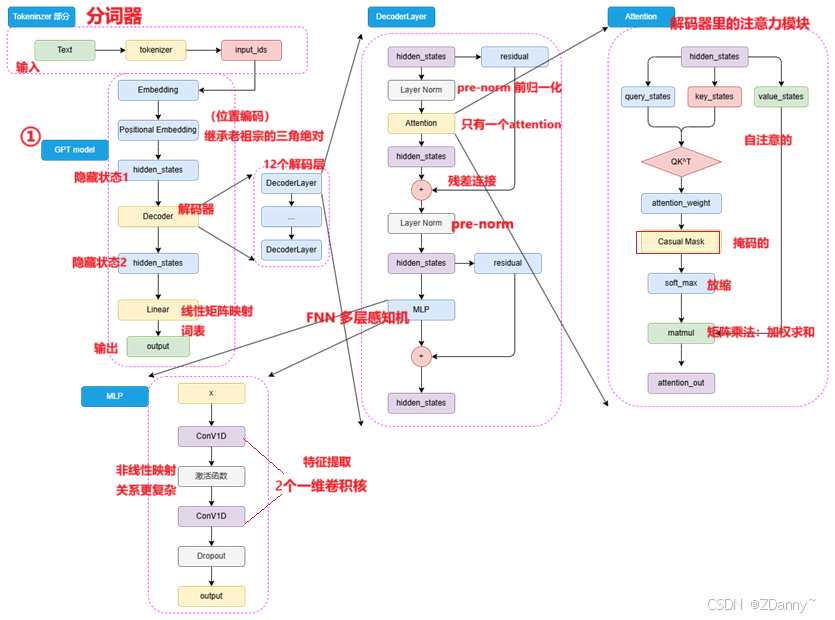
卷積核咋用的?
卷積核就是一個滑動的窗口,可以和輸入點積計算,提取局部特征
x = [1, 2, 3, 4, 5, 6] #輸入序列
w = [0.2, 0.5, 0.3] #一個大小為 3 的一維卷積核#就是每次取輸入的3個數一起看,如:
輸出第一個位置:0.2×1 + 0.5×2 + 0.3×3 = 2.6
輸出第二個位置:0.2×2 + 0.5×3 + 0.3×4 = 3.6y = [2.6, 3.6, 4.6, 5.6]
卷積核的數值很有講究的,可以看出這個核的偏好
這個也有些抽象
- w = [0.2, 0.5, 0.3] 說明每次取輸入序列的3個數中更關注中間的=幫助模型理解一個詞與前后詞之間的平衡關系
- w = [0.1, 0.8, 0.1] =強調中間詞(當前 token),但也考慮前后詞

序列長度:詞的個數
10個詞128維詞向量,矩陣形狀:(10,128)
256個卷積核,nn.Conv1d(in_channels=128, out_channels=256, kernel_size=3)
in_channels=128 :填的是輸入一個詞向量的維度
out_channels=256:說明用了256個一維卷積核
kernel_size=3:說明卷積核大小是3,三個數字
ps:(這里還有一點問題)
NLP一行是一個token, DL中一行是一維詞向量
LLaMA
模型系列(開源但還要到它官網去申請)
參數:從幾億 7B 到幾十、幾百億
數據:從 1T → 15T
上下文長度:2K → 8K
架構的優化:tokenizer+大詞表、分組查詢注意力機制GQA
LLaMA-123 一路走來
Meta的(前臉書Facebook的)
| 版本 | 發布時間 | 參數規模 | 訓練語料規模 | 上下文長度 | 核心改進 |
|---|---|---|---|---|---|
| LLaMA-1 | 2023年2月 | 7B / 13B / 30B / 65B | >1T tokens | 2048 | 2048 張 "GPT-3" 訓21天 |
| LLaMA-2 | 2023年7月 | 7B / 13B / 34B / 70B | >2T tokens | 4096 | 引入 GQA(Grouped-Query Attention),推理更高效 |
| LLaMA-3 | 2024年4月 | 8B / 70B /400B | >15T tokens | 8K | 優化tokenizer:詞表擴展至 128K,編碼效率更高 |
LLaMA的架構
下面是LlaMA3的結構,和GPT挺像,但是有些地方有差異,這里不展開了。
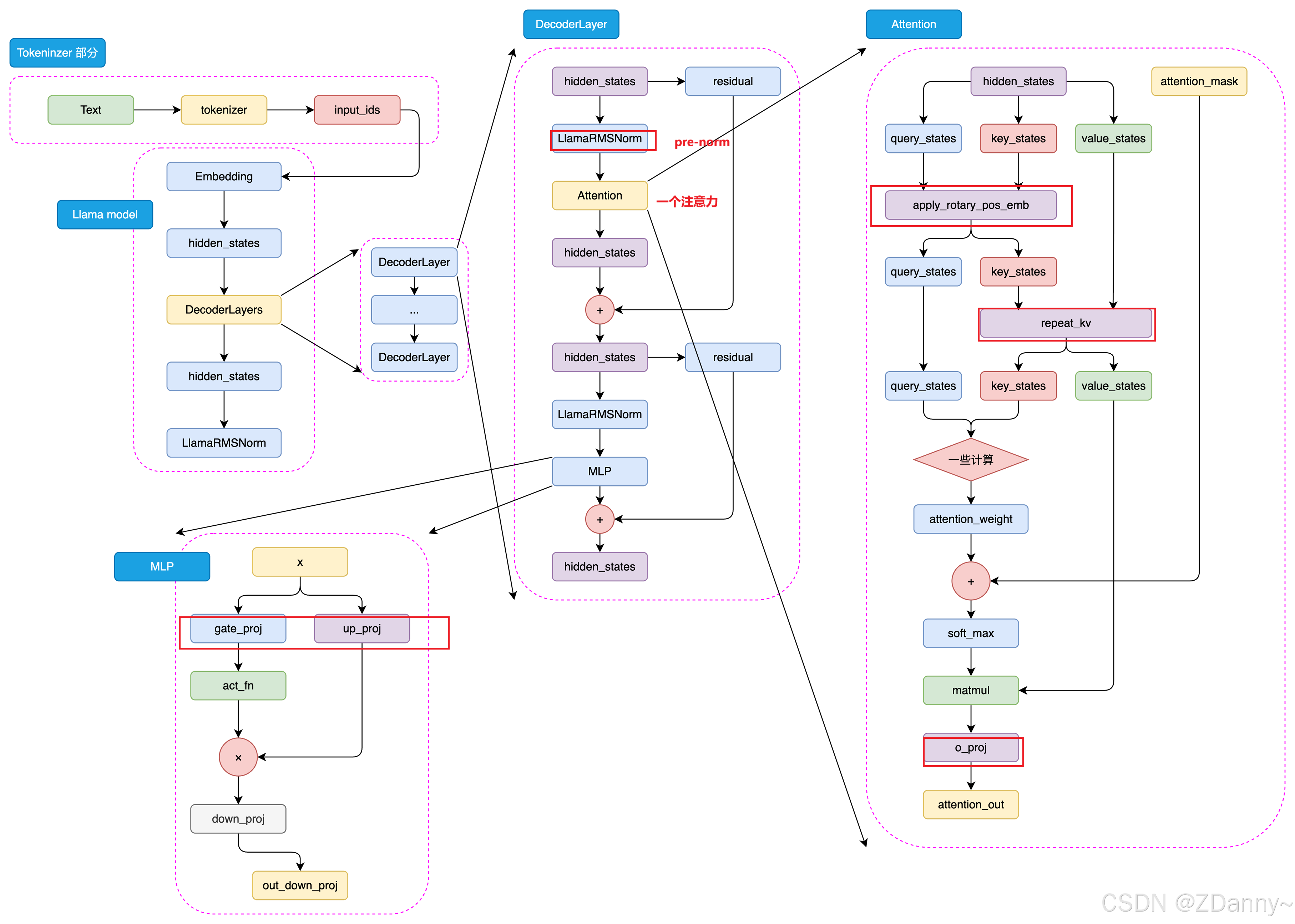
GLM
智譜的,清華計算機的,2023年國內首個開源中文LLM。
GLM也是一個任務名稱
GLM系列
看下來發現:
數據直接用T級別的
對架構、訓練策略等有一些改變
| 模型 | 時間 | 上下文長度 | 語料規模 | 架構/特點 | 關鍵能力 |
|---|---|---|---|---|---|
| ChatGLM-6B | 2023年3月 | 2k | 1T 中文語料 | 參考 ChatGPT 思路,SFT + RLHF | 中文 LLM 起點 |
| ChatGLM2-6B | 2023年6月 | 32k | - | LLaMA 架構 + MQA 注意力機制 | - |
| ChatGLM3-6B | 2023年10月 | - | - | 架構無大改,多樣化訓練數據集 + 訓練策略 支持函數調用 & 代碼解釋器 | 語義、數學、推理、代碼、知識達到當時 SOTA;可用于 Agent開發 |
| GLM-4 系列 | 2024年1月 | 128k | - | - | 新一代基座 |
| GLM-4-9B | 2024年1月 | 8k | 1T 多語言語料 | 與 GLM-4 方法一致 | 在同規模上超越 LLaMA3-8B |
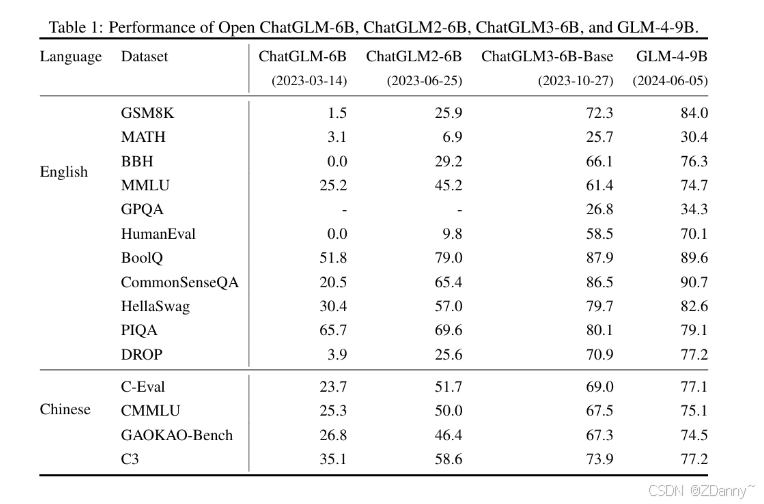
GLM用的預訓練任務
GLM既是模型名字,又是這個模型用的預訓練任務的名字
GLM=general language model 通用語言模型任務
GLM任務是怎么做的呢?
=CLM(因果)+MLM(掩碼)的結合,
ps:感覺也是為啥它是G,general,可能就是因為融合了兩種學習語言的任務。掩碼讓你會用詞,因果讓你會表達,這也是人可以用來學習語言的抽象任務吧。
一個序列進行隨機位置的幾個token掩碼,然后讓模型預測被遮蔽的部分+這個序列的下一token。
GLM任務的效果?
使用時間:GLM在預訓練模型時代比較火,只第一代用,后來GLM團隊自己也還是回到了傳統的CLM任務。
效果:對增強模型理解能力比較好
【模型性能與通體了BERT(encoder-only)的性能對比】
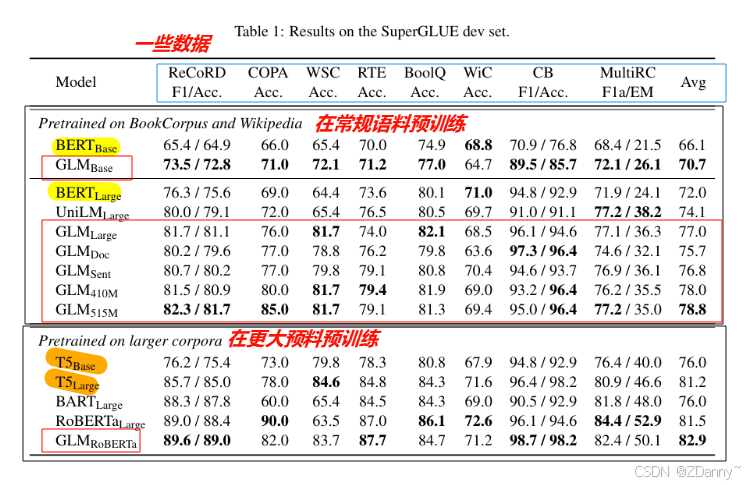
GLM的模型架構
和GPT架構很像(咱就是說,畢竟大佬,所以咱也得respect一下)
差異點一:用Post-Norm = 后歸一化
如下公式很直觀了
LayerOutput = LayerNorm(x + Sublayer(x))
post-norm和pre-norm的區別?
這兩個是有順序差別的歸一化方法。
計算差別: (在計算殘差鏈接的時候,)
- post歸一化顧名思義,殘差計算之后再歸一化。
- pre歸一化就是先進行歸一化,再殘差連接。
效果差別:
- post歸一化對參數整體的正則化效果更好,模型的魯棒性更好(泛化能力更強,在面對不同場景的時候)。
- pre自然的是有一部分參數加載參數正則化之后,所以可以防止模型梯度失控(消失或者爆炸)
二者如何選擇?
- 對很大的模型,一般默認覺得pre會好一點(防梯度失控)
- 但GLM里提出說post可以避免LLM數值錯誤,可能就是post就讓參數整體進到歸一化里,所以比較不割裂吧 。
差異點二:減少輸出參數量
做法:MLP --> 單個線性層
作用:輸出層參數量少了,參數都在模型本身
ps:
- 輸出層參數量少了有什么用?
輸出層參數并不是模型掌握的知識,他是最終生成文本的數字表示。所以量少了轉成文本就簡單了- 參數都在模型本身有什么用?
模型的參數就是模型學到的能力的數字抽象,輸入進來的內容經過和這些參數的計算,就可以運用到模型能力
(這里可能涉及到大模型參數的可解釋性問題,大家可以再去看看別的資料講解)
差異點三:激活函數換成GeLUs
- 傳統的激活函數——ReLU,就是保留正的數(傳播),負的為0
- GLM的激活函數——GeLUs,在0附近做軟過渡,非線性映射(更柔)
可能后期出一個激活函數的合集吧,大家想看也可以評論區催更



(LeetCode 每日一題) 3025. 人員站位的方案數 I (排序))
圖片裁剪)
)
)


)









