
1、 機器學習中特征的理解
def:?特征選擇和降維
特征選擇:原有特征選擇出子集?,不改變原來的特征空間
降維:將原有的特征重組成為包含信息更多的特征,?改變了原有的特征空間降維的主要方法
????????Principal?Component Analysis?(主成分分析)
????????Singular Value?Decomposition?(奇異值分解)
特征選擇的方法
????????Filter?方法?:卡方檢驗、信息增益、相關系數
????????Wrapper?方法?:其主要思想是:將子集的選擇看作是一個搜索尋優問題?,生成不同的組合?,對組合進行評價?,再與其他的組合進行比較。這樣就將子集的選擇看作是一個是一個優化問題?,這里有很多的優化算法可以解決?,尤其是一些啟發式的優化算法?,如??GA,?PSO,?DE?,ABC?等?,詳見“優化算法?—— ?人工蜂群算法 ?(ABC)”,“優化算法 ?—— ?粒子群算法 ?(PSO)”。
????????Embedded?方法?:其主要思想是?:在模型既定的情況下學習出對提高模型準確性最好的屬性。這句話并不是很好理解?,其實是講在確定模型的過程中?,挑選出那些對模型的訓練有重要意義的屬性。
????????主要方法?:正則化。?嶺回歸就是在基本線性回歸的過程中加入了正則項。
2、機器學習中?,有哪些特征工程方法?
數據和特征決定了機器學習的上限,?而?模型和算法只是逼近這個上限而 已
(1)計算每—?個特征與相應變量的相關性:?工?程上常用 的手?段有計算皮?爾遜系數和互信息系數,?皮?爾遜系數只能衡量線性相關性而?互信息系數能夠很好地度量各種相關性,但是計算相對復雜—?些,好在很多toolkit里?邊都包含了這個工?具(如??sklearn的MINE)?,得到相關性之后就可以排序選擇特征了;
(2)構建單個特征的模型?,通過模型的準確性為特征排序?,借此來選擇特征;
(3)通過L1正則項來選擇特征:?L1正則方?法具有稀疏解的特性,?因此天然具備特征選擇的特性?,但是要注意,L1沒有選到的特征不代表不重要,原因是兩個具有高?相關性的特征可能只保留了—?個,如果要確定哪個特征重要應再通過L2正則方?法交叉檢驗*;
(4)訓練能夠對特征打分的預選模型:RandomForest和Logistic?Regression等都能對模型的特征打分,通過打分獲得相關性后再訓練最終模型;
(5)通過特征組合后再來選擇特征?:如對用 戶id和用 戶特征最組合來獲得較大 的特征集再來選擇特征?,這種做法在推薦系統和廣?告系統中比?較常見 ,這也是所謂億級甚至 十?億級特征的主要來源?,原因是用?戶數據比?較稀疏?,組合特征能夠同時兼顧全局模型和個性化模型?,這個問題有機會可以展開講。
(6)通過深度學習來進行?特征選擇:?目 前這種手?段正在隨著深度學習的流行而?成為—?種手?段?,尤其是在計算機視覺領域?,原因是深度學習具有自 動學習特征的能力?,這也是深度學習又 叫unsupervised?feature
????????learning的原因。從深度學習模型中選擇某—?神經層的特征后就可以用 來進行?最終目 標模型的訓練了。
3、機器學習中的正負樣本
????????在分類問題中?,這個問題相對好理解—?點,?比?如人?臉識別中的例子 ,正樣本很好理解?,就是人?臉的圖片?,
????????負樣本的選取就與問題場景相關?,具體而 言 ,如果你要進行?教室中學生 的人?臉識別?,那么負樣本就是教室的窗子 、墻等等?,也就是?說?,不能是與你要研究的問題毫不相關的亂七八?糟的場景圖片 ,這樣的負樣本并沒有意義。負樣本可以根據背景生?成,
????????有時候不需要尋找額外的負樣本。—?般3000-10000的正樣本需要5,000,000-100,000,000的負樣本來學習,在互金?領域—?般在入?模前將正負比?例通過采樣的方?法調整到3)1-5:1。
區別:所謂線性分類器即用 —?個超平面?將正負樣本分離開?,表達式為 ??y?=wx????。這里?強調的是平面?。
????????而非?線性的分類界面?沒有這個限制,可以是曲面?,多個超平面 的組合等。典型的線性分類器有感知機,LDA,邏輯斯特回歸,?SVM(線性核);
????????典型的非?線性分類器有樸素貝 葉斯(有文?章說這個本質是線性的,http://dataunion.org/12344.html),kNN,決策樹,?SVM(?非?線性核)
優缺點:?1.線性分類器判別簡單、易實現、且需要的計算量和存儲量小?。
????????為解決比?較復雜的線性不可分樣本分類問題?,提出非?線性判別函數。超曲面?,?非線性判別函數計算復雜,
????????實際應用 上受到較大 的限制。在線性分類器的基礎上,?用 分段線性分類器可以實現復雜的分類面 。解決問題比?較簡便的方?法是采用 多個線性分界面?將它們分段連接,?用 分段線性判別劃分去逼近分界的超曲面?。
????????如果—?個問題是非?線性問題并且它的類邊界不能夠用 線性超平面?估計得很好?,那么非?線性分類器通常會比線性分類器表現得更精準。如果—?個問題是線性的?,那么最好使用 簡單的線性分類器來處理。
5、如何解決過擬合問題
解釋過擬合:
????????模型在訓練集表現好?,在真實數據表現不好,?即模型的泛化能力 不夠。從另外—?個方 面?來講,模型在達到經驗損失最小 的時候?,模型復雜度較高?,結構風 險沒有達到最優。
解決:
????????學習方?法上:?限制機器的學習?,使機器學習特征時學得不那么徹底,?因此這樣就可以降低機器學到局部特征和錯誤特征的幾?率?,使得識別正確率得到優化.
????????數據上?:要防止?過擬合?,做好特征的選取。訓練數據的選取也是很關鍵的,?良好的訓練數據本身的局部特征應盡可能少,?噪聲也盡可能小 .
6、L1和L2正則的區別,如何選擇L1和L2正則
L0正則化的值是模型參數中非?零參數的個數。
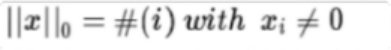
????????也就是如果我們使用 L0范數?,即希望w的大?部分元素都是0.?(?w是稀疏的)所以可以用 于ML中做稀疏編碼,特征選擇。通過最小?化L0范數?,來尋找最少最優的稀疏特征項。但不幸的是,?L0范數的最優化問題是—?個NP?hard問題,?而?且理論上有證明,?L1范數是L0范數的最優凸近似,?因此通常使用 L1范數來代替。
L1正則化表示各個參數絕對值之和。
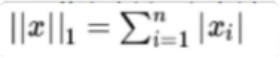
????????L1范數的解通常是稀疏性的?,傾向于選擇數目 較少的—?些非?常大?的值或者數目 較多的insignificant的小值。
????????L2正則化標識各個參數的平方 的和的開方?值。

????????L2范數越小 ,可以使得w的每個元素都很小 ,接近于0?,但L1范數不同的是他不會讓它等于0而?是接近于0.




)





)



)

)


