目錄
一,計算機是如何組成的
1.1,CPU中央處理單元
1.1.1,CPU的構成和屬性
1.1.2,如何判斷cpu的好壞
1.1.3,指令
1.1.4,CPU的緩存
1.2,操作系統
1.2.1,進程
1.2.2,PCB的核心屬性
1.2.3,內存分配-內存管理 和進程間通信
一,計算機是如何組成的
在馮諾依曼的體系中,計算機由CPU,存儲器,輸入設備和輸出設備組成
1.1,CPU中央處理單元
1.1.1,CPU的構成和屬性
門電路=>半加器=>全加器=>加法器=>ALU運算器=>差不多構成CPU
![]()
這是電腦是計算機的屬性:
AMD指的是生產CPU的廠商,記住主要的廠商是intel 和 amd,它們生產的區別是intel的針腳長在主板上,amd的針腳長在CPU上
7840H是指這是標壓處理器,通過H這個后綴進行判斷,其中還有U系列,不同的字符代表不同的性能和功耗級別,U表示的是低壓CPU
3.80GHz表示的是CPU的主頻,也就是指CPU一秒鐘可以執行多少條指令,執行的每個次數,又被稱為時鐘周期
1.1.2,如何判斷cpu的好壞
判斷CPU的好壞有很多指標,但最關注的只有兩點:主頻 和 核心數
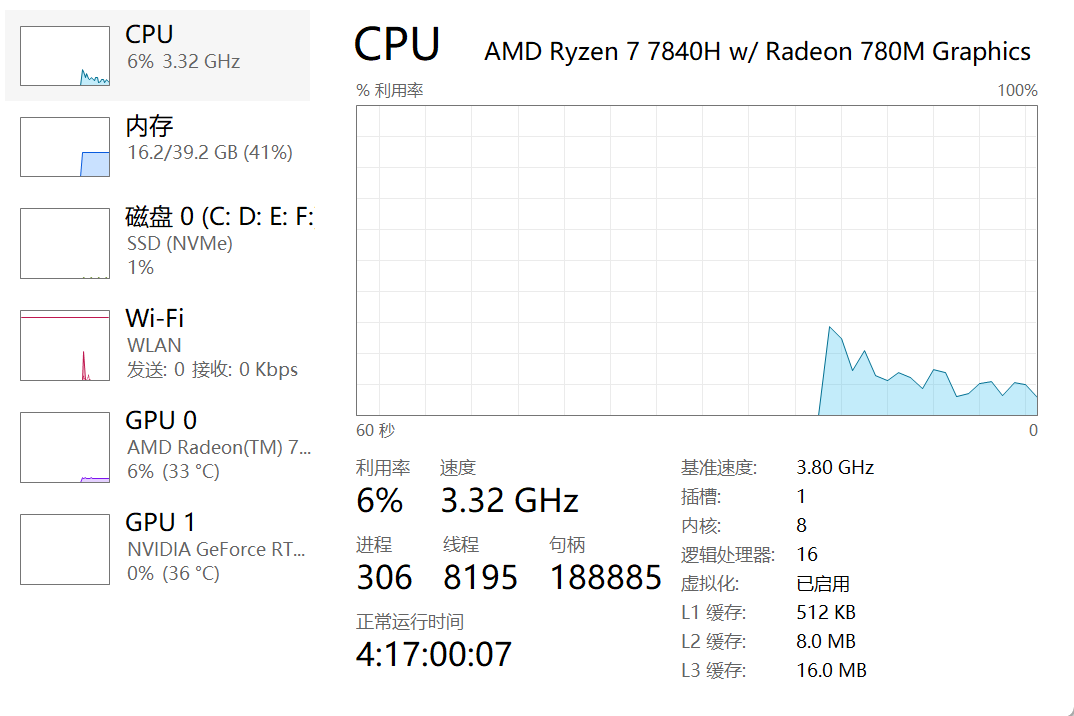
在打開任務管理器找到CPU的時候,可以看見CPU的數據:
其中3.32GHz和之前查看處理器的性能時的主頻不一樣,是因為cpu主頻都是在時刻改變的~~它會根據當前任務的負載程度,動態變化
3.32GHz就是指運行是當前的頻率,又被稱為睿頻
CPU的頻率是有上限的,不同的CPU上限不一樣,甚至有的CPU還可以超頻,給CPU吃更多的電,CPU就有更強的表現
內核指的就是CPU的核心數
其實最開始的時候cpu都是單個核心的(核心可以理解為一個能夠完成完整計算機功能的整體,是由很多的計算機單元構成的),提高集成程度,就提高cpu的速度
隨著時代的發展,隨著集成程度的提高,發現進一步提高,就越來越難了~~減小單個計算單元的體積,勢必就會增加工藝的難度~~當體積小到一定的程度的時候,經典力學就失效了,量子力學就接管了
于是一個核心不夠,就多個核心來湊

內核就是指cpu上焊上去的核心,現在的cpu有一個"超線程技術",可以讓一個核心頂兩個核心,就指的是內核下方的邏輯處理器
1.1.3,指令
指令(Instruction)是cpu上能夠執行的任務的最小單元,這些最小單元都是由二進制的方式來表示的機器語言(不同的cpu支持的指令/機器語言是不相同的)
簡單模擬cpu執行指令的過程:(這是簡化的版本,真實的X86或者arm的指令表要復雜很多)
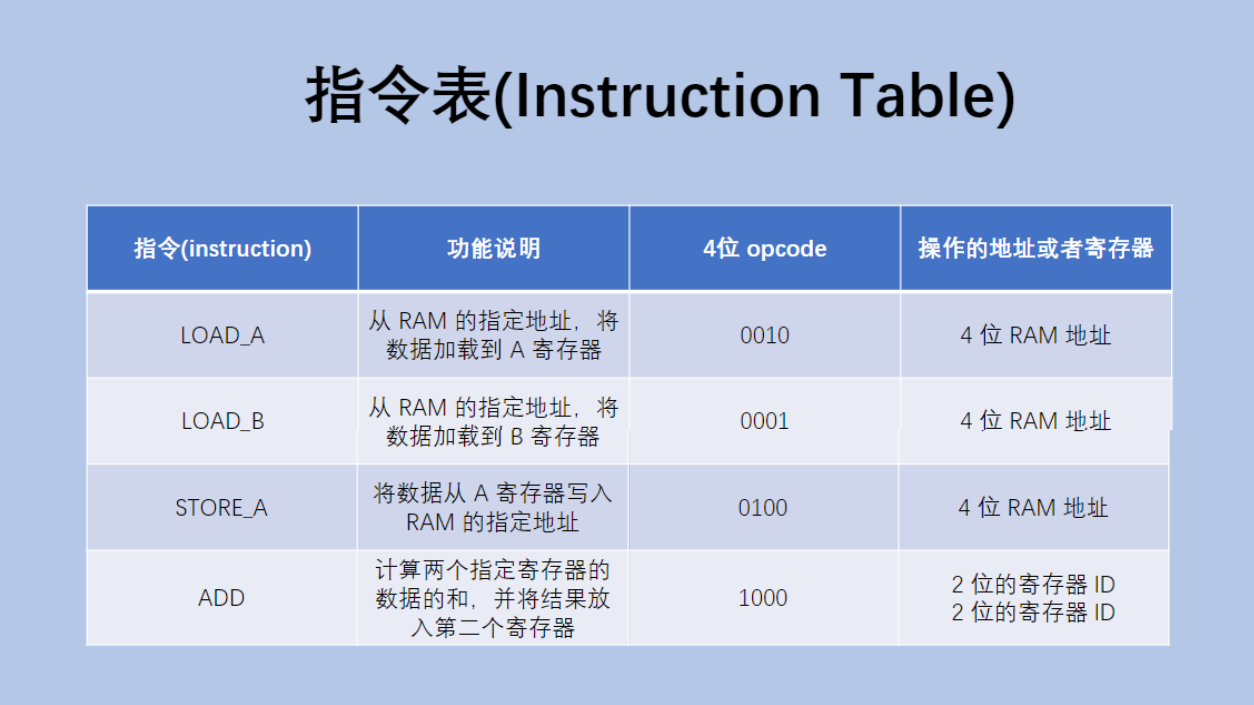
RAM:內存??
寄存器:cpu上的存儲數據的單元,cpu上能直接存的數據比較少,這些寄存器主要是為了支持cpu完成一些運算,保存中間結果的,它的空間雖然有限,但是訪問速度是極快的,比內存訪問速度要快上3-4個數量級
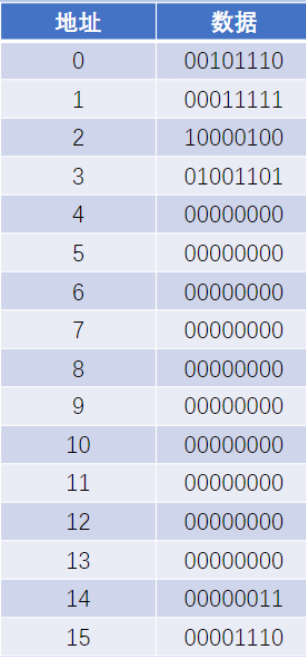 這一段指令? 其實就是內存中的一段數據的單元~~我們寫好的代碼,最終想要運行,都是需要讓操作系統,先把寫好并編譯好的指令加載到內存中,然后cpu才能執行的? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?假定,從0號地址開始執行程序,cpu就會先從0號地址這里讀取數據,到cpu寄存器里,并對這個指令??進行解析=>查詢指令表,看這個指令要干嘛? ? ? ? 0010? 1110,前4位對應的是opcode,0010即指LOAD_A 要完成的工作,從內存中,讀取數據到A寄存器中,后4位是參數,是內存地址,轉換為十進制,1110就是14? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?那么這里就是指將14地址內存的數據讀取到A寄存器當中? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 默認情況下,cpu執行內存中的指令是''順序執行''的,除非遇到跳轉類的指令? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?后面的LOAD_B和STORE_A執行也是同理了? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?ADD指令中,1000 01 00,1000指執行ADD,01和00分別指向不同的寄存器,其中寄存器的編號都是在指令表里提前要約定好的,將兩個寄存器里面的內容相加,結果保存到第二個操作數的寄存器中
這一段指令? 其實就是內存中的一段數據的單元~~我們寫好的代碼,最終想要運行,都是需要讓操作系統,先把寫好并編譯好的指令加載到內存中,然后cpu才能執行的? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?假定,從0號地址開始執行程序,cpu就會先從0號地址這里讀取數據,到cpu寄存器里,并對這個指令??進行解析=>查詢指令表,看這個指令要干嘛? ? ? ? 0010? 1110,前4位對應的是opcode,0010即指LOAD_A 要完成的工作,從內存中,讀取數據到A寄存器中,后4位是參數,是內存地址,轉換為十進制,1110就是14? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?那么這里就是指將14地址內存的數據讀取到A寄存器當中? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 默認情況下,cpu執行內存中的指令是''順序執行''的,除非遇到跳轉類的指令? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?后面的LOAD_B和STORE_A執行也是同理了? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?ADD指令中,1000 01 00,1000指執行ADD,01和00分別指向不同的寄存器,其中寄存器的編號都是在指令表里提前要約定好的,將兩個寄存器里面的內容相加,結果保存到第二個操作數的寄存器中
1.1.4,CPU的緩存
當時的計算機,在cpu執行指令的時候,要經歷從內存中讀取數據的操作,這個設定,就是馮諾依曼體系的精髓? ?最初設計該結構,就是為了把"執行"和"存儲"分開,這么做主要是為了"解耦合"來降低硬件設計的成本? 且當年的cpu執行指令的速度和存儲器取指令的速度是差不多的,配合很好
隨著硬件技術的發展,cpu越來越快,內存讀取數據提升不明顯,內存逐漸跟不上cpu的節奏了
于是出現緩存,通過臨時存儲經常訪問的數據,提高數據檢索速度和應用程序性能
1.2,操作系統
像windows10,windows11,linux,mac os,android,ios都是操作系統,這些操作系統,本質上都是用來搞管理的軟件
操作系統的功能主要是兩點:
1.對下管理所有的硬件設備
2.對上要給軟件提供一個穩定的運行環境
對于第一點,操作系統畢竟是一個軟件,不可能認識市面上的所有的硬件設備
但是操作系統知道,市面的硬件設備就這么幾個大的類別,每個大類別下面的硬件設備大概有哪些功能
硬件廠商就需要在開發硬件的時候,同時開發一個驅動程序,專屬于這個硬件設備,讓操作系統通過這個驅動程序完成對硬件設備的控制,也就是指操作系統統一管理各種不同的硬件設備給軟件提供統一的api
注:由于JVM已經把系統api封裝了,完成同樣的功能,就直接調用jvm的api即可,不需要學習系統原裝的,(天然跨大平臺)在windows上能跑,換成linux等其他的也能夠跑
1.2.1,進程
進程是操作系統提供的一種"軟件資源"
如今我們使用的系統,都屬于是"多任務操作系統",也就是同一時刻,可以同時運行多個任務
電腦上每一個正在運行的程序,就可以稱為是"任務",也叫做"進程"
與之對應的,就是"單任務操作系統",同一時刻,只能運行一個程序
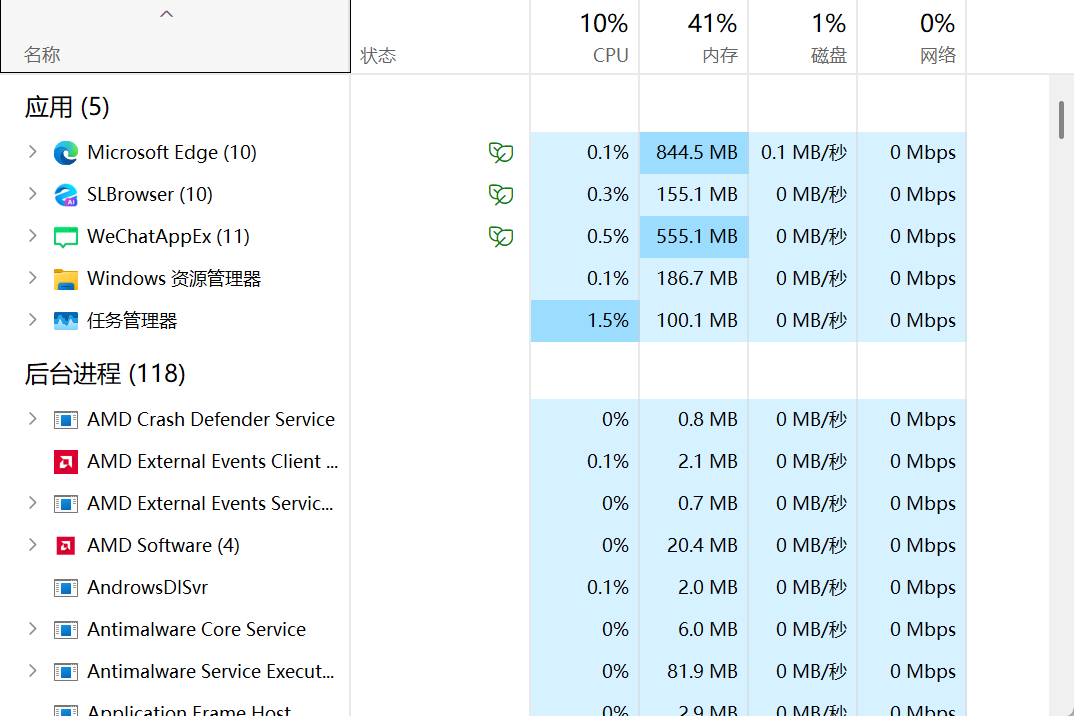
每個任務在執行過程中,都需要消耗一定的硬件資源
換而言之,計算機中的每個進程,在運行的時候,都需要給他分配一定的系統資源
因此,進程是系統分配資源的基本單位
操作系統的進程管理:
1.先描述(使用類/結構體這樣的方式,把實體屬性給列出來)
操作系統,一般都是C/C++實現的,因此可以使用結構體
表示進程信息的結構體,稱為PCB(進程控制塊,Process Control Block)
2.再組織(使用一定的數據結構,把一些結構體/對象 串到一起)
當我們看到任務管理器中的這些進程的時候,意味著系統內部就在遍歷鏈表,并且打印每個節點的關鍵信息
如果運行一個新的程序,于是系統中就會多一個進程,多的這個進程就需要構造出一個新的pcb,并且添加到鏈表上
如果某個運行中的程序退出了,就需要把對應進程的pcb從鏈表中刪除掉,并且銷毀對應的pcb資源
此次的表述是一個簡化版本,事實上組織方式更加復雜(不是一個鏈表,是更加復雜的鏈式結構)
進一步了解進程,就要去了解PCB
1.2.2,PCB的核心屬性
pid:進程的身份標識,此處通過一個簡單的不重復的整數來進行區分的。
系統會保證,同一個機器上,同一時刻,每個進程的pid都是唯一的~~
內存指針:描述了進程使用內存資源的詳細情況,進程運行過程中,需要消耗一些系統資源的,其中內存就是一種重要的資源,只要從系統中申請,系統分配一塊內存,才能使用,每個進程都必須使用自己申請到的內存.內存指針,就是用來描述說你這個進程,都能使用哪些內存,一個進程跑起來的時候,需要有指令也需要有數據(指令和數據都是要加載到內存中的),進程也需要知道,哪里存的是指令,哪里存的是數據
文件描述符表:描述了進程所涉及的硬盤相關的資源,我們的進程經常要訪問硬盤,而操作系統,對于硬盤這樣的硬件設備,進行了封裝=>文件,不管是哪種盤,都是統一進行的抽象,都是按照"文件"的方式來操作的
一個進程想要操作文件,就需要"打開文件",就是讓你的進程在文件描述符表中分配一個表項(構造一個結構體)表示這個文件的相關信息
正因為進程是系統分配資源的基本單位,所以內存,硬盤就會在PCB中有所體現
過渡:
在任務管理器,可以看到進程消耗了cpu的資源
cpu就像一個舞臺,而要執行的指令,就是演員,而指令是進程來執行,演員也就是進程
一個cpu可能有一個核心,也可能有多個核心~~
每個核心都是一個舞臺,演員需要登上舞臺,才能夠進行表演,但同一時刻,一個舞臺上,只能有一個演員
假如一個電腦上有16個邏輯核心,而系統上的進程,遠遠不止16個,不夠分怎么辦
所以,這里就涉及到一個非常關鍵的概念~分時復用(并發)
當cpu核心只有一個時,先執行進程1的代碼(進程1,登臺表演),執行一會后,讓進程1下來,進程2上,進程2執行一會后,進程3上,以此類推
只有切換速度足夠快,人是感知不到這個切換的過程的,在人眼中,多個任務/進程,就是"同時執行"的,而當進程太多,cpu負擔太重,就會出現"卡頓"
隨著多核cpu出現,同時執行的進程就變得更加復雜了
如有4個舞臺,同時就可以有四個不同的進程,在各自的舞臺上進行執行,此時,微觀上,這幾個進程也是"同時執行的",而不是靠快速切換模擬的"同時執行",被稱為并行執行
與之對應的,前面的并發執行,仍然存在,每個核心仍然要分時復用,仍然要快速切換
所以當前現代的計算機的執行過程,往往都是并發+并行同時存在的,而對于兩個進程是并行執行還是并發執行就都是看系統的調度的
因此,往往就把"并行"和"并發"統稱為"并發"
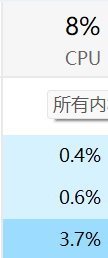 所以此次cpu的百分數,就是指你的進程在cpu舞臺上消耗的時間的百分比? ? ? ? ? ? ? ? ? ? ? 如果有一個進程,把cpu吃到了100%,意味著其他進程都沒有執行的時間了,很可能就會造成系統卡頓,于是就要用到進程的調度,分時復用,并發執行
所以此次cpu的百分數,就是指你的進程在cpu舞臺上消耗的時間的百分比? ? ? ? ? ? ? ? ? ? ? 如果有一個進程,把cpu吃到了100%,意味著其他進程都沒有執行的時間了,很可能就會造成系統卡頓,于是就要用到進程的調度,分時復用,并發執行
對此,PCB中就需要提供一些屬性,來支持系統對這些進程的調度:
狀態:描述某個進程是否能夠去cpu上執行
狀態中重要是就緒狀態和阻塞狀態
就緒狀態:隨時準備好去cpu上執行,操作系統打聲招呼就可以上了
阻塞狀態:這個進程,當前不方便去cpu上執行,不應該去調度他(比如,進程在等待IO,來自控制臺的輸入輸出)
優先級:對于多個進程等待系統調度,調度的先后關系,先調度誰,后調度誰,誰長,誰短,都是可以進行調配的(系統的api可以設置)
記賬信息:針對每個進程,占據了多少cpu時間,進行一個統計。會根據這個統計結果來進一步的調整調度的策略~~
因此就需要在下一個輪次進行調整,確保每個進程都不至于出現完全撈不著CPU的情況的
上下文:進程從cpu離開之前,需要保存現場,把當前cpu中各種寄存器的狀態,都記錄到內存中
等到下一次進程回到cpu執行的時候,此時就可以把保存的這些寄存器的值恢復回去,進程就會沿著上次執行到的位置,繼續往后執行
就相當于存檔和讀檔
結合前面指令執行,知道每個進程在運行過程中,就會有很多的中間結果,在CPU的寄存器中
例:3和14相加,先使用寄存器保存3和14,再使用寄存器,保存17
然而執行完3加14后,進程就被調度出了cpu
操作系統調度進程,過程可以認為是隨機的,任何一個進程,代碼執行到任何一條指令的時候都可能被調度出cpu,因此,就需要在進程調度出cpu之前,把當前寄存器中的這些信息,給單獨保存到一個地方(存檔)
在進程調度回cpu的時候,繼續之前的進度來執行,在該進程下次再去cpu執行的時候,再把這些寄存器的信息給恢復過來(讀檔)
"保存上下文":就是把cpu的關鍵寄存器中的數據,保存到內存中(PCB的上下文屬性中)
"恢復上下文":就是把內存中的關鍵寄存器中的數據,加載到cou對應的寄存器中
1.2.3,內存分配-內存管理 和進程間通信
內存管理的核心結論:每個進程的內存,都是彼此獨立的,互不干擾的
通常情況下,進程A不能直接訪問進程B的內存,為了系統的穩定性,如果某個進程代碼出現bug,出錯影響的范圍,只是影響到自己的這個進程,不會影響到其他進程,這種情況,也稱為"進程獨立性"
進程間通信:
雖然有進程的獨立性,但是有時候也需要,多個進程相互配合,完成某個工作
進程間通信與進程的"獨立性"并不沖突,系統提供一些公共的空間(多個進程都能訪問到的),讓兩個進程借助公共空間來交互數據
上述只是進程的序幕,實際上,在JAVA中不太鼓勵"多進程編程"
線程 更加重要了,詳細看線程單獨的文章




![Shell 中 ()、(())、[]、{} 的用法詳解](http://pic.xiahunao.cn/Shell 中 ()、(())、[]、{} 的用法詳解)
:Vue3 提示框proxy.$modal.msgSuccess()提示文本換行解決方案)
![[Sync_ai_vid] 唇形同步推理流程 | Whisper架構](http://pic.xiahunao.cn/[Sync_ai_vid] 唇形同步推理流程 | Whisper架構)



)
)







