一·代碼
import torch
print(torch.__version__) # 驗證安裝的開發環境是否正確'''
MNIST 包含 70,000 張手寫數字圖像;60,000 張用于訓練,10,000 張用于測試。
圖像是灰度的,28x28 像素的,并且居中的,以減少預處理和加快運行。
'''import torch
from torch import nn # 導入神經網絡模塊from torchvision import datasets # 封裝了很多與圖像相關的模型、及數據集
from torchvision.transforms import ToTensor # 數據轉換、張量,將其他類型的數據轉換為 tensor 張量,numpy array, dataframe'''下載訓練數據集(包含訓練圖片 + 標簽)'''
training_data = datasets.MNIST( # 跳轉到函數內部源代碼,pycharm 按 Ctrl + 鼠標點擊root="data", # 表示下載的手寫數字,到哪個路徑,.60000train=True, # 表示下載后的數據集,里的,訓練集download=True, # 如果你之前已經下載過了,就不用再下載transform=ToTensor() # 張量,圖片是不能直接傳入神經網絡模型
) # 對于 pytorch 來說能夠識別的數據一般是 tensor 張量'''下載測試數據集(包含訓練圖片 + 標簽)'''
test_data = datasets.MNIST(root="data",train=False,download=True,transform=ToTensor() # Tensor 是在深度學習中被使用廣泛的數據類型,它為深度學習框架(如 PyTorch、TensorFlow)緊密集成,方便進行神經網絡的訓練和推理。
) # 允許 CPU 和 GPU 運行,Tensor 可以在 GPU 上運行,這在深度學習應用中可以顯著提升計算速度。print(len(training_data))# '''展示手寫數字圖片,把訓練數據集中的前 59000 張圖片展示一下'''
#
# from matplotlib import pyplot as plt
#
# figure = plt.figure()
# for i in range(9):
# img, label = training_data[i + 59000] # 提取第 59000 張圖片
# figure.add_subplot(3, 3, i + 1) # 圖像窗口中創建多個小窗口、小窗口用于展示圖片
# plt.title(label)
# plt.axis("off") # plt.show() 才顯示矢量
# plt.imshow(img.squeeze(), cmap="gray") # plt.imshow() 函數來將數組(data)中的數據顯示為圖像,并在圖形窗口中顯示圖像
# a = img.squeeze() # img.squeeze() 從張量 img 中去掉維度為 1 的,如果該維度的大小不為 1 則張量不會改變。cmap="gray" 表示使用灰度色彩映射來顯示圖像,這意味著圖像將以灰度模式顯示
# plt.show()
# '''創建數據DataLoader(數據加載器)
# batch_size:將數據集分成多份,每一份為batch_size個數據。
# 優點:可以減少內存的使用,提高訓練速度。
# '''
from torch.utils.data import DataLoader # 數據管理工具,打包數據
train_dataloader = DataLoader(training_data, batch_size=64)#64張圖片為一個包,1、損失函數2、GPU一次性接受的圖片個數
test_dataloader = DataLoader(test_data, batch_size=64)
for X, y in test_dataloader:#X是表示打包好的每一個數據包print(f"Shape of X [N, C, H, W]: {X.shape}")#print(f"Shape of y: {y.shape} {y.dtype}")break# 判斷當前設備是否支持GPU,其中mps是蘋果m系列芯片的GPU。 '''#返回cuda, mps. CPU m1 , m2 菜顯CPU+GPU RTX3060,
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")#字符串的格式化。 CUDA驅動軟件的功能: pytorch能夠去執行cuda的命令, cuda通過GPU指令集去控制GPU
# #神經網絡的模型也需傳入到GPU,1個batchsize的數據集也需要傳入到GPU,才可以進行訓練。''' 定義神經網絡 類的繼承這種方式'''
class NeuralNetwork(nn.Module):#通過調用類的形式來使用神經網絡,神經網絡的模型,nn.moduledef __init__(self):#python基礎關于類,self類自己本身super().__init__()#繼承的父類初始化self.flatten = nn.Flatten()#展開,創建一個展開對象flattenself.hidden1 = nn.Linear(28*28, 128)#第1個參數:有多少個神經元傳入進來,第2個參數:有多少個數據傳出去前一層神經元的個數,當前本self.hidden2 = nn.Linear(128, 256)#為什么你要用128self.out = nn.Linear(256, 10)#輸出必需和標簽的類別相同,輸入必須是上一層的神經元個數def forward(self, x): #前向傳播,你得告訴它 數據的流向。是神經網絡層連接起來,函數名稱不能改。當你調用forward函數的時候,傳入進來的x = self.flatten(x) #圖像進行展開x = self.hidden1(x)x = torch.relu(x) #激活函數,torch使用的relu函數 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return xmodel = NeuralNetwork().to(device)
print(model)# 訓練函數
def train(dataloader, model, loss_fn, optimizer):model.train()batch_size_num = 1for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)loss = loss_fn(pred, y)# 反向傳播optimizer.zero_grad()loss.backward()optimizer.step()loss_value = loss.item()if batch_size_num % 100 == 0:print(f"loss: {loss_value}?f [number: {batch_size_num}]")batch_size_num += 1# 測試函數(示例,可補充完整測試指標計算等邏輯)
def test(dataloader, model, loss_fn):passloss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 執行訓練
train(train_dataloader, model, loss_fn, optimizer)
class NeuralNetwork(nn.Module):#通過調用類的形式來使用神經網絡,神經網絡的模型,nn.moduledef __init__(self):#python基礎關于類,self類自己本身init初始化代碼,
''' 定義神經網絡 類的繼承這種方式'''
class NeuralNetwork(nn.Module):#通過調用類的形式來使用神經網絡,神經網絡的模型,nn.moduledef __init__(self):#python基礎關于類,self類自己本身super().__init__()#繼承的父類初始化self.flatten = nn.Flatten()#展開,創建一個展開對象flattenself.hidden1 = nn.Linear(28*28, 128)#第1個參數:有多少個神經元傳入進來,第2個參數:有多少個數據傳出去前一層神經元的個數,當前本self.hidden2 = nn.Linear(128, 256)#為什么你要用128self.out = nn.Linear(256, 10)#輸出必需和標簽的類別相同,輸入必須是上一層的神經元個數def forward(self, x): #前向傳播,你得告訴它 數據的流向。是神經網絡層連接起來,函數名稱不能改。當你調用forward函數的時候,傳入進來的x = self.flatten(x) #圖像進行展開x = self.hidden1(x)x = torch.relu(x) #激活函數,torch使用的relu函數 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x
def __init__(self):#python基礎關于類,self類自己本身super().__init__()#繼承的父類初始化self.flatten = nn.Flatten()#展開,創建一個展開對象flattenself.hidden1 = nn.Linear(28*28, 128)#第1個參數:有多少個神經元傳入進來,第2個參數:有多少個數據傳出去前一層神經元的個數,當前本self.hidden2 = nn.Linear(128, 256)#為什么你要用128self.out = nn.Linear(256, 10)#輸出必需和標簽的類別相同,輸入必須是上一層的神經元個數這里是對象層沒有開始操作
def forward(self, x): #前向傳播,你得告訴它 數據的流向。是神經網絡層連接起來,函數名稱不能改。當你調用forward函數的時候,傳入進來的x = self.flatten(x) #圖像進行展開x = self.hidden1(x)x = torch.relu(x) #激活函數,torch使用的relu函數 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x這個是開始操作數據的
目前為止書接上回網絡搭建任務二就完成了
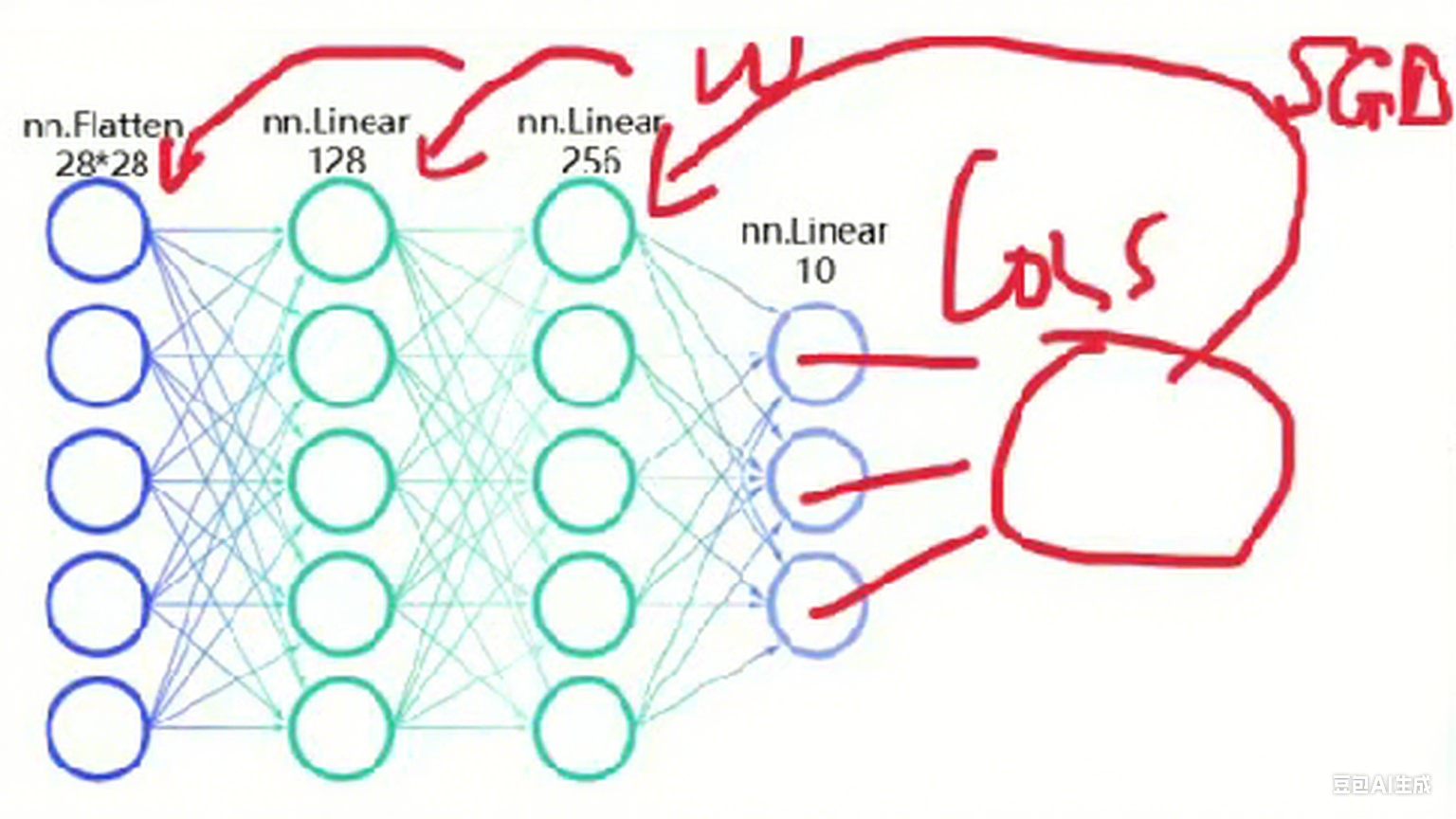
這樣的網絡搭建就完成了
訓練的方法就是構建一個損失函數來方向更新w權重,以及反向更新用什么方法來反向更新
loss_fn = nn.CrossEntropyLoss()
# #L1Loss: L1損失,也稱為平均絕對誤差(Mean Absolute Error, MAE)。它計算預測值與真實值之間的絕對差值的平均值。
# NLLLoss: 負對數似然損失(Negative Log Likelihood Loss)。它用于多分類問題,通常與LogSoftmax輸出層配合使用。
# NLLLoss2d: 這是NLLLoss的一個特殊版本,用于處理2D圖像數據。在最新版本的PyTorch中,這個損失函數可能已經被整合到NLL
# PoissonNLLLoss: 泊松負對數似然損失,用于泊松回歸問題。
# GaussianNLLLoss: 高斯負對數似然損失,用于高斯分布(正態分布)的回歸問題。
# KLDivLoss: Kullback-Leibler散度損失,用于度量兩個概率分布之間的差異。
# #MSELoss: 均方誤差損失(Mean Squared Error Loss),計算預測值與真實值之間差值的平方的平均值。
# #BCELoss: 二元交叉熵損失(Binary Cross Entropy Loss),用于二分類問題。
# BCEWithLogitsLoss: 結合了Sigmoid激活函數和二元交叉熵損失的損失函數,用于提高數值穩定性。
# HingeEmbeddingLoss: 鉸鏈嵌入損失,用于學習非線性嵌入或半監督學習。
# MultiLabelMarginLoss: 多標簽邊際損失,用于多標簽分類問題。
# SmoothL1Loss: 平滑L1損失,是L1損失和L2損失(MSE)的結合,旨在避免梯度爆炸問題。
# HuberLoss: Huber損失,與SmoothL1Loss類似,但有一個可調的參數來控制L1和L2損失之間的平衡。
# SoftMarginLoss: 軟邊際損失,用于二分類問題,可以看作是Hinge損失的一種軟化版本。
# CrossEntropyLoss: 交叉熵損失,用于多分類問題。它結合了LogSoftmax和NLLLoss的功能。
# MultiLabelSoftMarginLoss: 多標簽軟邊際損失,用于多標簽二分類問題。
# CosineEmbeddingLoss: 余弦嵌入損失,用于學習非線性嵌入,通過余弦相似度來度量樣本之間的相似性。
# MarginRankingLoss: 邊際排序損失,用于排序問題,如學習到排序的嵌入空間。
# MultiMarginLoss: 多邊際損失,用于多分類問題,旨在優化分類邊界的邊際。
# TripletMarginLoss: 三元組邊際損失,用于學習嵌入空間中的距離度量,通常用于人臉識別或圖像檢索等任務。
# TripletMarginWithDistanceLoss: 這是TripletMarginLoss的一個變體,允許使用自定義的距離函數。
# CTCLoss: 連接時序分類損失(Connectionist Temporal Classification Loss),用于序列到序列的學習問題
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)優化算法,這里的model是前面定義的類
model = NeuralNetwork().to(device)
print(model)下面的是優化器的一些函數
from . import swa_utils as swa_utils
from . import lr_scheduler as lr_scheduler
from .adadelta import Adadelta as Adadelta
from .adagrad import Adagrad as Adagrad
from .adam import Adam as Adam
from .adamax import Adamax as Adamax
from .adamw import AdamW as AdamW
from .asgd import ASGD as ASGD
from .lbfgs import LBFGS as LBFGS
from .nadam import NAdam as NAdam
from .optimizer import Optimizer as Optimizer
from .radam import RAdam as RAdam
from .rmsprop import RMSprop as RMSprop
from .rprop import Rprop as Rprop
from .sgd import SGD as SGD
from .sparse_adam import SparseAdam as SparseAdam
這個就是輸出的結果進行損失函數反向更新通過SGD的方法來更新權重
train(train_dataloader, model, loss_fn, optimizer)#訓練1次完整的數據,多輪訓練,
test(test_dataloader, model, loss_fn)這個里開始訓練然后就是調取前面的函數
# 訓練函數
def train(dataloader, model, loss_fn, optimizer):model.train()batch_size_num = 1for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)loss = loss_fn(pred, y)# 反向傳播optimizer.zero_grad()loss.backward()optimizer.step()loss_value = loss.item()if batch_size_num % 100 == 0:print(f"loss: {loss_value}?f [number: {batch_size_num}]")batch_size_num += 1pred = model.forward(X)執行上面的代碼
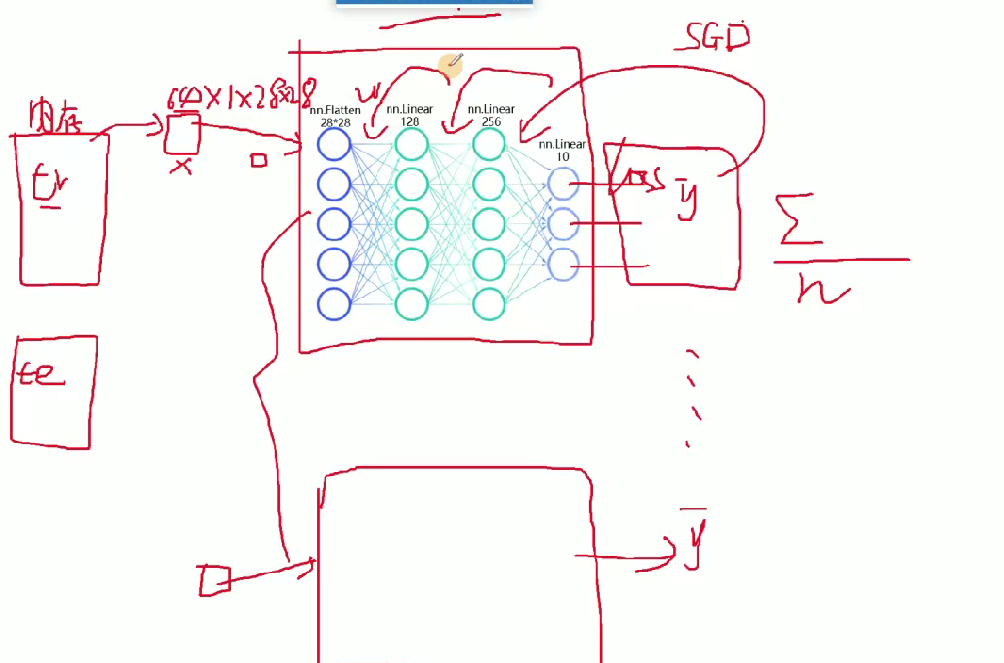
def forward(self, x): #前向傳播,你得告訴它 數據的流向。是神經網絡層連接起來,函數名稱不能改。當你調用forward函數的時候,傳入進來的x = self.flatten(x) #圖像進行展開x = self.hidden1(x)x = torch.relu(x) #激活函數,torch使用的relu函數 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x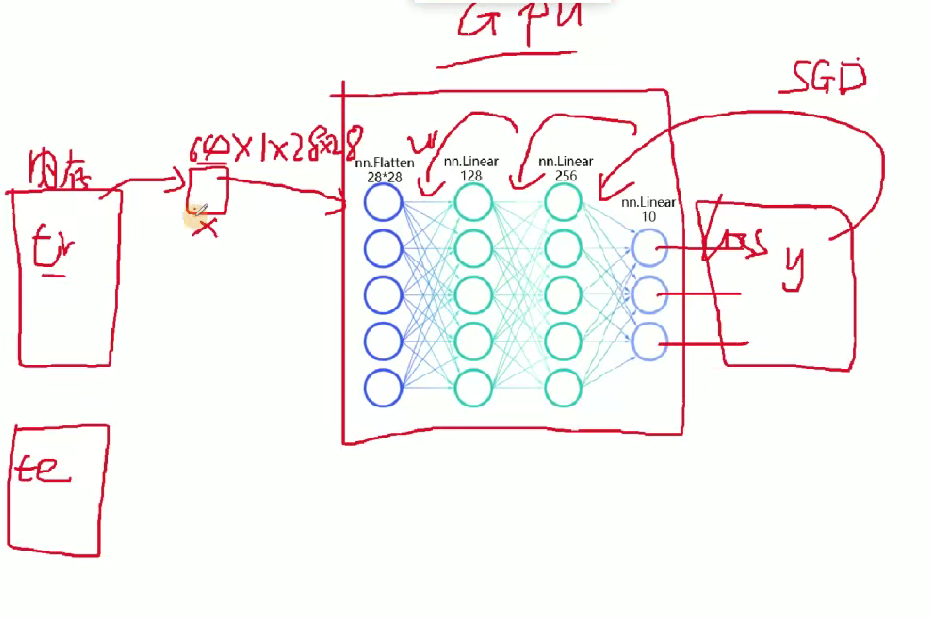
計算機會自動搭建64個這樣的網絡,然后64張圖片分別進行前向傳播得到輸出預測結果,然后在計算損失值,然后和loss比較求和平均更新w的權重
這里使用交叉熵損失函數
loss = loss_fn(pred, y)這里進行權重更新
optimizer.zero_grad() # 梯度值清零
loss.backward() # 反向傳播計算得到每個參數的梯度值w
optimizer.step() # 根據梯度更新網絡w參數
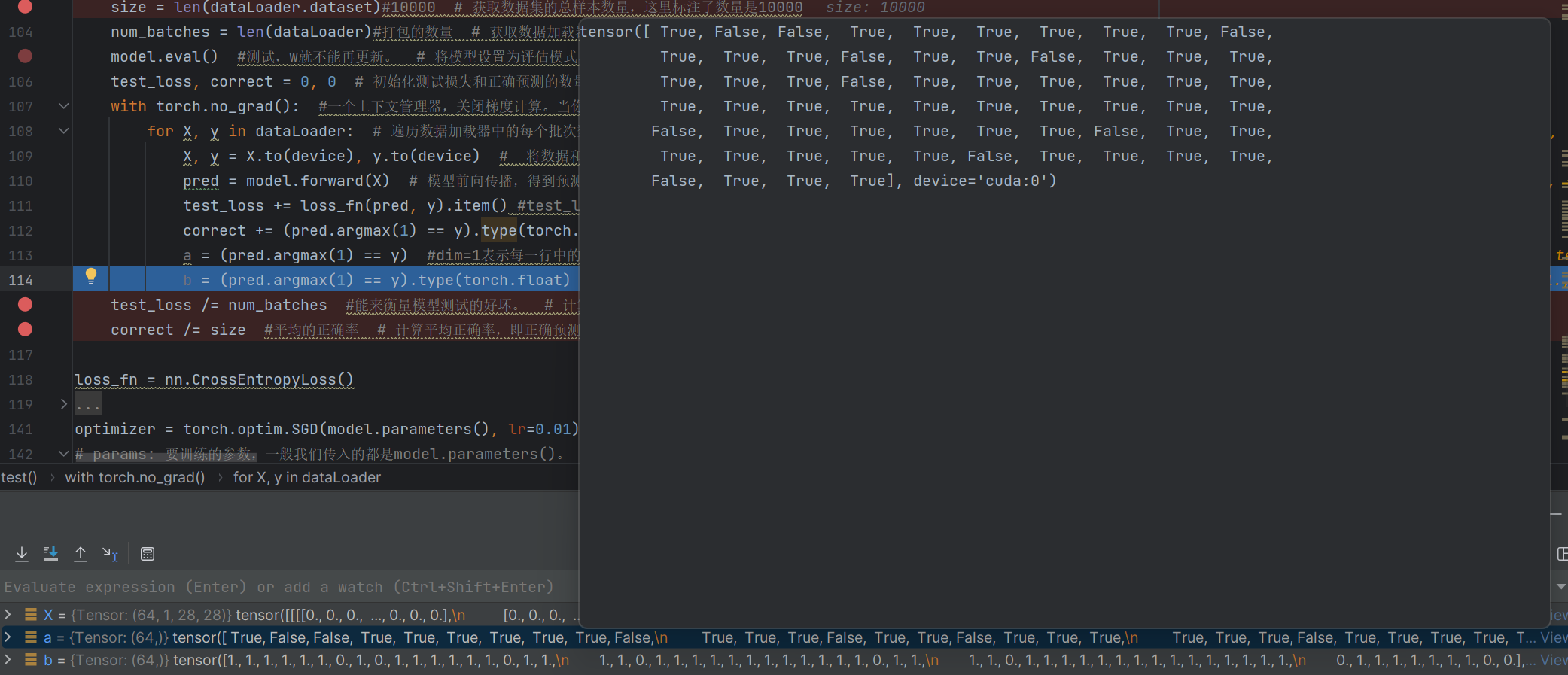
def test(dataLoader, model, loss_fn): # dataLoader: <torch.utils.data.dataloader.DataLoader object at 0x00000260size = len(dataLoader.dataset)#10000 # 獲取數據集的總樣本數量,這里標注了數量是10000num_batches = len(dataLoader)#打包的數量 # 獲取數據加載器的批次數,即打包后的數量model.eval() #測試,w就不能再更新。 # 將模型設置為評估模式,此時模型參數不會被更新test_loss, correct = 0, 0 # 初始化測試損失和正確預測的數量with torch.no_grad(): #一個上下文管理器,關閉梯度計算。當你確認不會調用Tensor.backward()的時候。這可以減少計算所用內存 # 關閉梯度計算,減少內存使用,因為測試階段不需要反向傳播for X, y in dataLoader: # 遍歷數據加載器中的每個批次數據X, y = X.to(device), y.to(device) # 將數據和標簽移動到指定設備(CPU或GPU)pred = model.forward(X) # 模型前向傳播,得到預測結果test_loss += loss_fn(pred, y).item() #test_loss是會自動累加每一個批次的損失值 # 累加每個批次的損失值,item()將張量轉換為Python數值correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 累加正確預測的數量,先比較預測和真實標簽,轉換為浮點型后求和再轉換為Python數值a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值對應的索引號,dim=0表示每一列中的最大值對應的索引號 # 記錄預測與真實標簽是否匹配的布爾值,解釋了argmax參數dim=1的含義b = (pred.argmax(1) == y).type(torch.float) # 將上述布爾值轉換為浮點型張量test_loss /= num_batches #能來衡量模型測試的好壞。 # 計算平均每個批次的測試損失,用于衡量模型測試表現correct /= size #平均的正確率 # 計算平均正確率,即正確預測數占總樣本數的比例
with torch.no_grad(): #一個上下文管理器上下文管理器,能自動檢測當前打開的文件,在反向傳播計算的過程中會產生大量的臨時數據,不要的話就清理掉了
a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值對應的索引號,dim=0表示每一列中的最大值對應的索引號 # 記錄預測與真實標簽是否匹配的布爾值,解釋了argmax參數dim=1的含義
b = (pred.argmax(1) == y).type(torch.float) # 將上述布爾值轉換為浮點型張量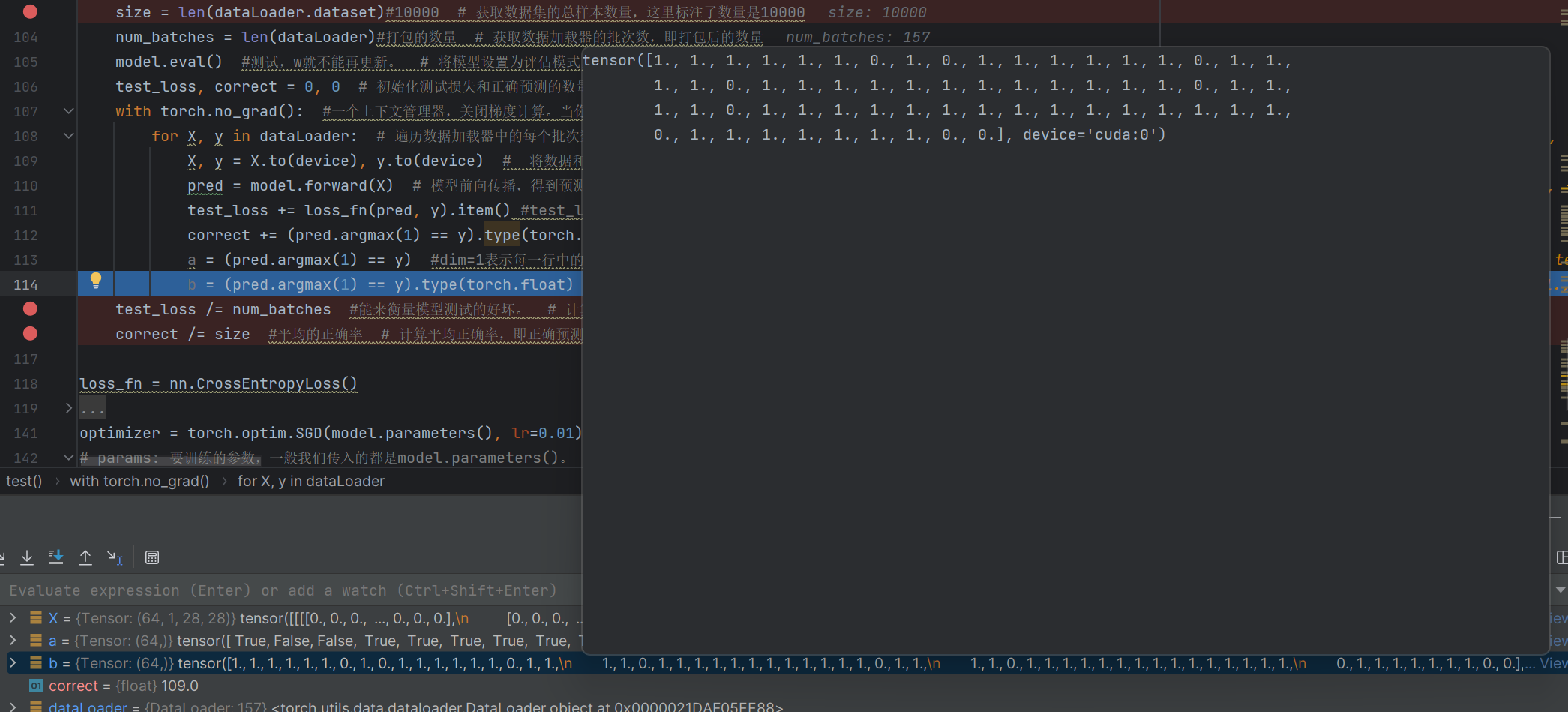
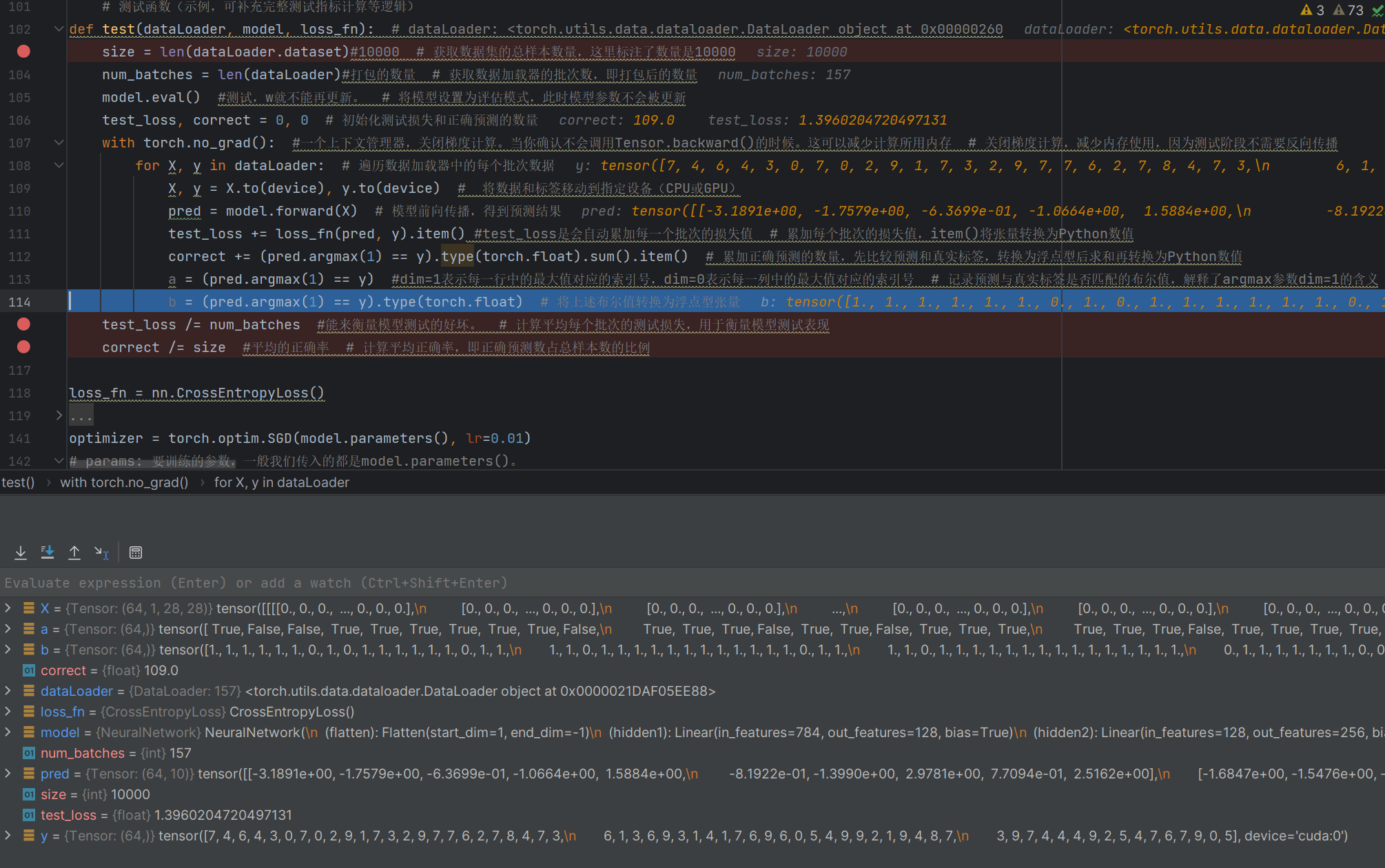
這里的correct是判斷出了對了109個
# 定義訓練的輪數(epoch),即整個訓練數據集會被模型學習多少遍
# 這里設置為 10,注釋里也提出了疑問“到底選擇多少呢?”,實際需根據數據集、模型等情況調整
epochs = 10 #到底選擇多少呢?# 循環執行多輪訓練,輪數由上面定義的 epochs 決定
for t in range(epochs):# 打印當前輪次信息,t 從 0 開始,所以用 t+1 展示人類習慣的“第 1 輪、第 2 輪”等print(f"Epoch {t+1}\n-------------------------------")# 調用訓練函數,將訓練數據加載器、模型、損失函數、優化器傳入,執行一輪訓練# 注釋里說明“10 次訓練”,對應 epochs 為 10 時會循環調用訓練 10 次train(train_dataloader, model, loss_fn, optimizer)#10次訓練# 當所有輪次的訓練都完成后,打印 “Done!” 提示訓練結束
print("Done!")
# 調用測試函數,傳入測試數據加載器、模型、損失函數,對訓練好的模型進行測試評估
test(test_dataloader, model, loss_fn)后面
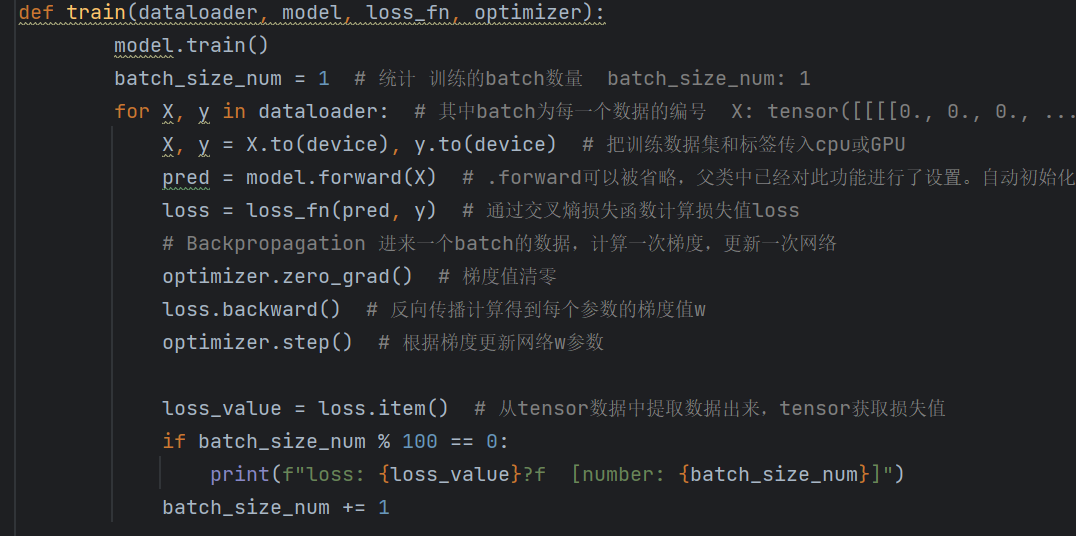
if batch_size_num % 100 == 0:print(f"loss: {loss_value}?f [number: {batch_size_num}]")這里100批次來計算損失函數
二.改進
原本的代碼進行的運算太慢了需要改進
# 計劃分析 sigmoid 函數和 relu 函數,這里拼寫可能有誤,正確一般是 sigmoid
###分析sigmiod, relu
# 計劃分析隨機梯度下降(sgd)優化器和 Adam 優化器
### sgd, Adam 優化器
- 批量梯度下降法(Batch Gradient Descent)BGD
使用全樣本數據計算梯度,例如一個 batch_size=64,計算出 64 個梯度值
好處:收斂次數少。壞處:每次迭代需要用到所有數據,占用內存大耗時大。 - 隨機梯度下降法(Stochastic Gradient Descent)
從 64 個樣本中隨機抽出一組,訓練后按梯度更新一次
優點:速度快。缺點:可能陷入局部最優,搜索起來比較盲目,并不是每次都朝著最優的方向 - 小批量梯度下降法(Mini-batch Gradient Descent)
將訓練數據集分成小批量用于計算模型誤差和更新模型參數。是批量梯度下降法和隨機梯度下降法的結合。 - 自適應矩估計 (Adaptive Moment Estimation) Adam
- 動量梯度下降(Momentum Gradient Descent)
- AdaGrad
- RMSprop
- AdamW
- Adadelta
下面就是一些優化器函數
from . import swa_utils as swa_utils
from . import lr_scheduler as lr_scheduler
from .adadelta import Adadelta as Adadelta
from .adagrad import Adagrad as Adagrad
from .adam import Adam as Adam
from .adamax import Adamax as Adamax
from .adamw import AdamW as AdamW
from .asgd import ASGD as ASGD
from .lbfgs import LBFGS as LBFGS
from .nadam import NAdam as NAdam
from .optimizer import Optimizer as Optimizer
from .radam import RAdam as RAdam
from .rmsprop import RMSprop as RMSprop
from .rprop import Rprop as Rprop
from .sgd import SGD as SGD
from .sparse_adam import SparseAdam as SparseAdam
但也會有限制這個限制就是步長
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)下一步就是優化激活函數
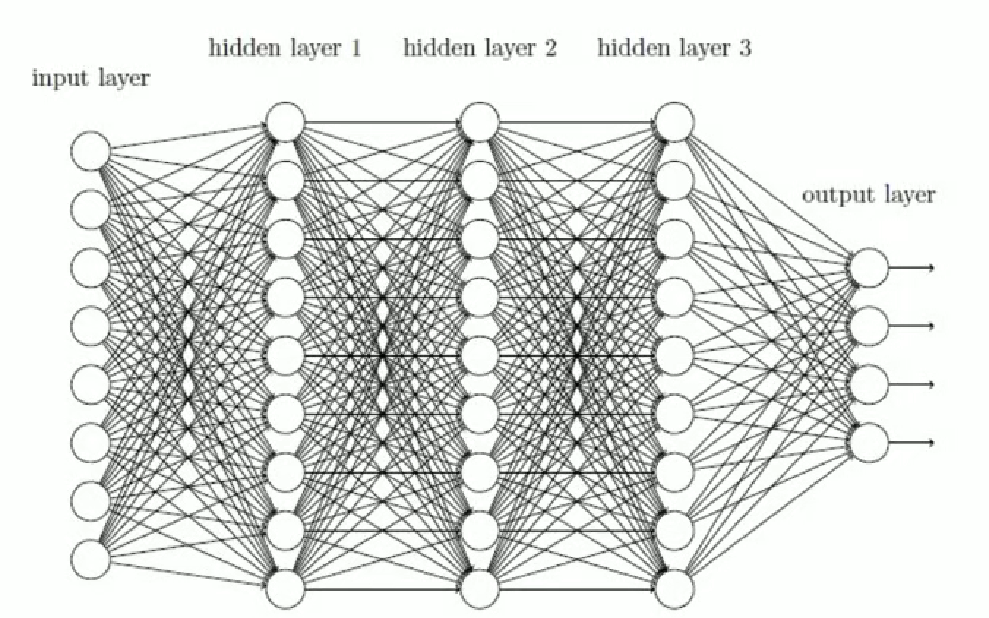

梯度消失
如果連乘的因子大部分小于 1,最后乘積的結果可能趨于 0,也就是梯度消失,后面的網絡層的參數不發生變化.
梯度爆炸
如果連乘的因子大部分大于 1,最后乘積可能趨于無窮,這就是梯度爆炸
造成原因:
梯度反向傳播中的連乘效應。對于更普遍的梯度消失問題,可以考慮下方
案解決:
用 ReLU、tanh、P - ReLU、R - ReLU、Maxout 等替代 sigmoid 函數。
ReLU

需要多層隱含層,才會奏效
def forward(self, x): #前向傳播,你得告訴它 數據的流向。是神經網絡層連接起來,函數名稱不能改。當你調用forward函數的時候,傳入進來的x = self.flatten(x) #圖像進行展開x = self.hidden1(x)x = torch.relu(x) #激活函數,torch使用的relu函數 relu,tanhx = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x



網絡編程:TCP 機制與 HTTP 協議)
![[element-plus] el-table在行單擊時獲取行的index](http://pic.xiahunao.cn/[element-plus] el-table在行單擊時獲取行的index)

——查詢構建、Text2SQL、查詢重構與分發)
)






:plt.imshow() - 繪制矩陣與圖像的強大工具)

)

)