一、關于產品
1.1 產品介紹
NVIDIA Nsight Deep Learning Designer 是一款面向 AI 推理開發者的可視化建模與優化工具。它支持基于 ONNX 格式的神經網絡模型編輯、結構可視化、性能分析與 TensorRT 引擎導出,幫助用戶更高效地設計、調優和部署高性能推理模型。該工具集成了 ONNX Runtime 和 TensorRT Profiler,能夠提供從模型結構到底層 GPU 推理過程的全面洞察,簡化深度學習推理工作流。
1.2 核心優勢
全流程可視化模型編輯 通過拖拽式圖形界面創建、編輯和優化 ONNX 格式模型,無需手寫代碼即可完成模型設計與調優。
深度性能剖析 內置 ONNX Runtime 和 TensorRT 推理性能分析功能,精準呈現 GPU 使用率、Tensor Core 利用率和各層執行時間,助力發現瓶頸并指導優化。
高效推理引擎導出 一鍵將優化后的 ONNX 模型導出為 TensorRT 引擎文件,支持多種精度(FP32、FP16、INT8、FP8),顯著提升部署性能。
多平臺支持與遠程調優 支持本地和遠程 GPU 設備,包括數據中心 GPU、RTX 桌面顯卡及 Jetson 嵌入式平臺,通過 SSH 無縫連接目標設備進行模型測試與分析。
與 NVIDIA 推理生態無縫集成 與 NVIDIA TensorRT、ONNX Runtime 及 NGC 平臺緊密集成,支持模型快速遷移與部署,降低工程成本。
二、前期準備
3.1 軟件安裝
https://developer.nvidia.com/nsight-dl-designer/getting-started#下載網址

如上點擊,需要登陸nvidia賬號下載,登錄成功后等待程序下載完成
安裝完成!
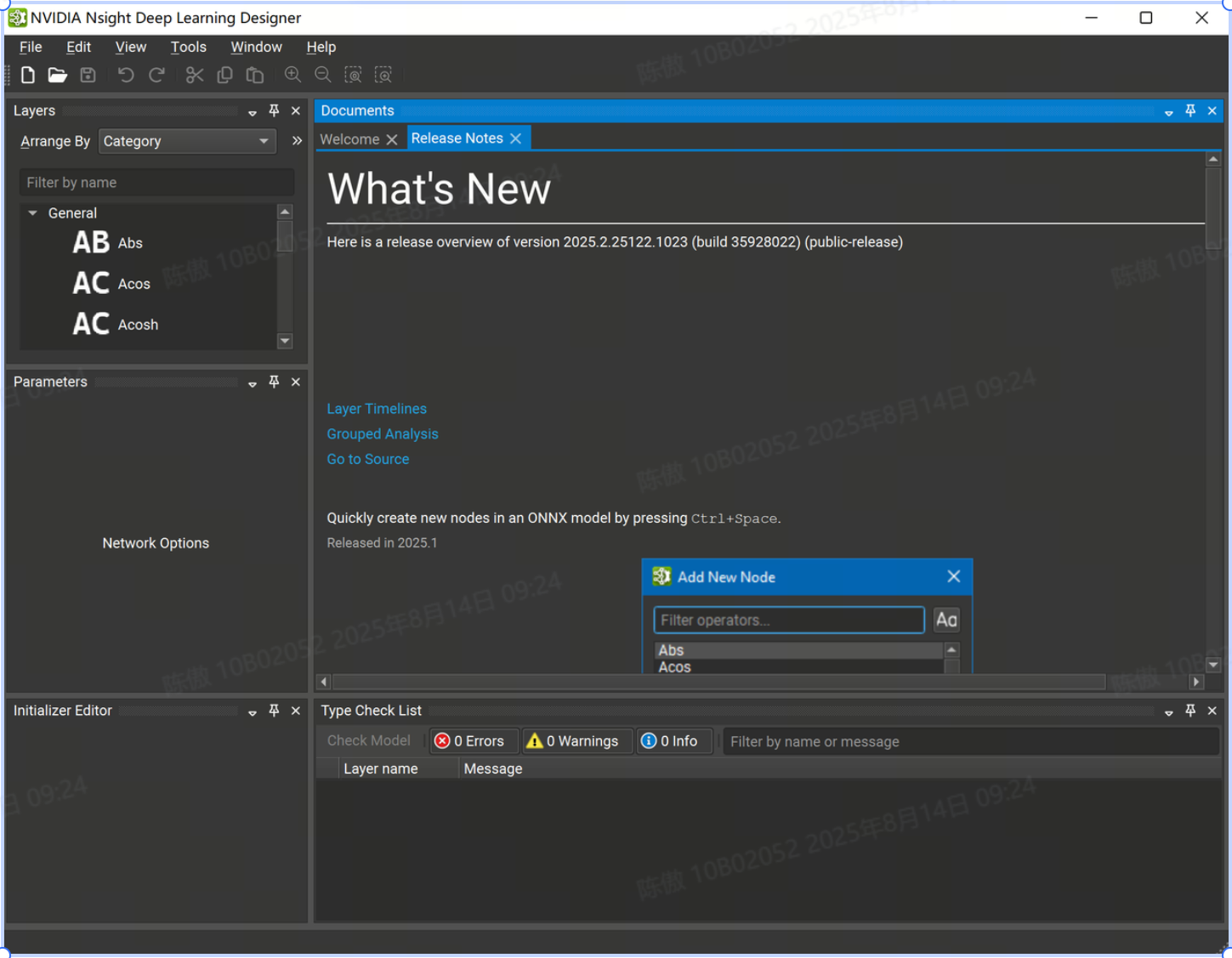
三、開始使用
創建新模型
Nsight Deep Learning Designer 既可以打開現有的 ONNX 模型,也可以從頭開始創建一個新模型。可以在 File > New File 下創建新模型。
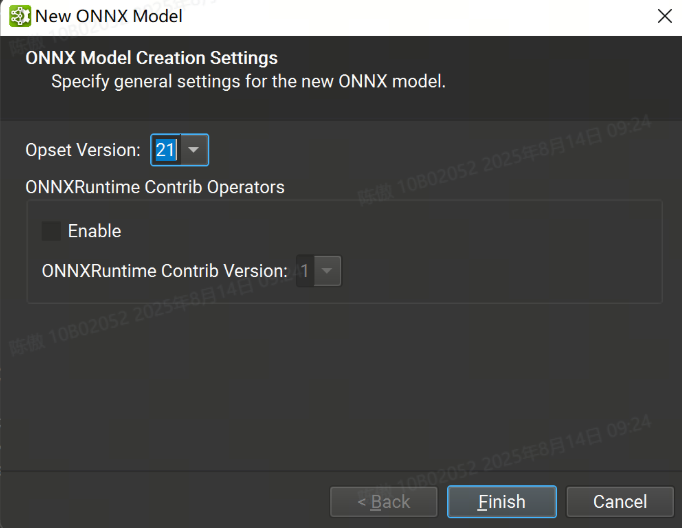
在此對話框中,可以選擇新模型所需的 ONNX Opset 版本。目前支持從版本 1 到版本 21 的所有 Opset。也可以導入 ONNXRuntime Contrib 運算符集。
Workspace
每個打開的 ONNX 模型都由工作區中的文檔選項卡表示。多個型號可以同時打開,并使用對接系統進行排列。工作區的中心元素是畫布,可以在其中通過放置層節點并在它們之間創建連接來創建和編輯模型圖。可以使用可停靠的工具窗口安排工作區。所有工具窗口都可以在 View > Windows 和 model canvas 上下文菜單下找到。可以查閱 Window (窗口) 菜單下的命令來保存、應用或重置布局。
默認工作區由 Layer Palette、Parameter 窗口、Initializer Editor 和 Type Checking 窗口組成。
首次加載模型時,畫布將顯示整個模型圖。可以使用 Ctrl + 鼠標滾輪進行放大和縮小,也可以通過右鍵單擊并拖動框來縮放區域。使用鼠標中鍵單擊并拖動可向任意方向平移視圖。通過單擊畫布右上角的齒輪圖標,然后選擇 Controls 選項卡,可以查看導航作的完整列表。
為了更輕松地在畫布中直觀地對齊節點,可以使用 View (查看) > Show Grid (顯示網格) 菜單作來啟用背景網格。 畫布中的節點可以通過其唯一名稱(如果 ONNX 模型中不存在,則自動生成)和它們的層類型來標識。
修改當前圖形或模型的編輯作會將文檔標記為已修改。只有在使用 File > Save 或 Ctrl + S 快捷鍵保存模型后,更改才會反映在磁盤上。 可以使用Ctrl + Z 和 Ctrl + Y 快捷鍵撤消和重做當前會話中的編輯操作。
布局
首次打開模型時,布局算法會自動將節點定位在畫布上。 通過 ONNX 模型將各個節點位置保留在配套配置文件中,以便在重新打開時恢復節點位置。 可以使用 View > Arrange Nodes 菜單作在任何模型上顯式運行布局算法。
導出 Canvas
可以使用 File > Export > Export Canvas As Image(將畫布導出為圖像)菜單作將整個模型畫布導出為單個圖像文件。背景顏色、網格顏色和狀態以及圖像保存位置可以從下圖的對話框中設置。支持的圖像格式為 PNG、JPEG 和 SVG。
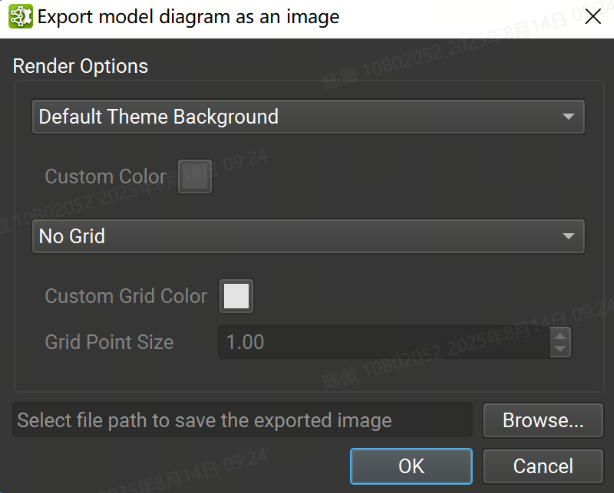
層Layers
Layer Palette 包含可從其導入的運算符集添加到模型的可用運算符列表。圖層可以按名稱、集合或類別進行排列。還可以對 Layer 調色板進行排序或篩選。要將新的圖層實例添加到畫布中,只需從調色板中拖放即可。
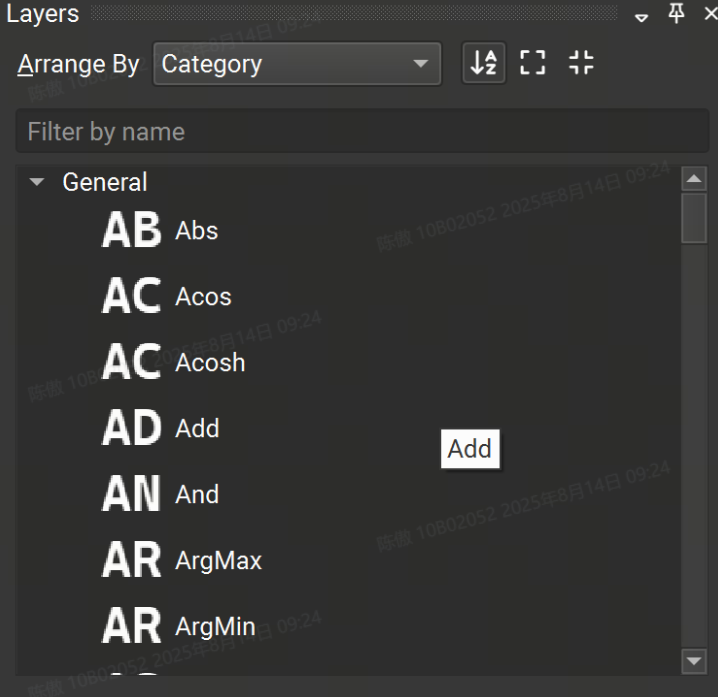
或者,將鼠標光標放在模型畫布中的任意位置,然后按“Control + 空格鍵”打開一個快速節點添加對話框,如下圖所示。在搜索框中輸入將過濾可用圖層列表,按“Enter”或雙擊列表條目會將所選圖層添加到鼠標光標下的畫布中。
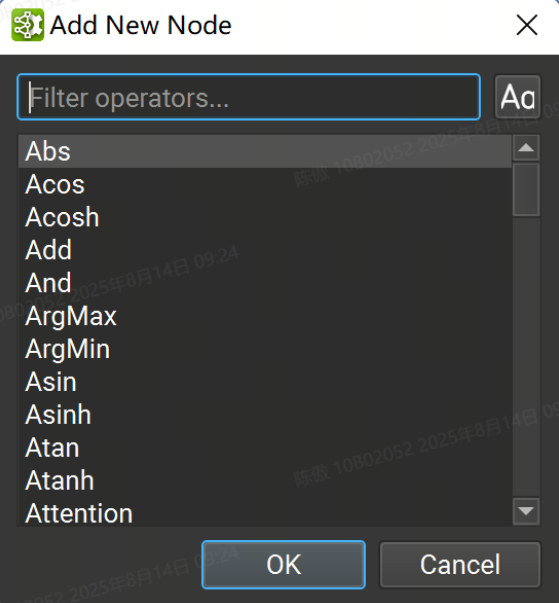
Layer Explorer 顯示模型中當前層的列表。模型層可以按層類型或名稱進行組織,并從“按名稱篩選”搜索框中按名稱進行篩選。圖層的排序順序可以在工具欄中切換。雙擊 Layer Explorer 中的圖層可跳轉到畫布中的圖層。
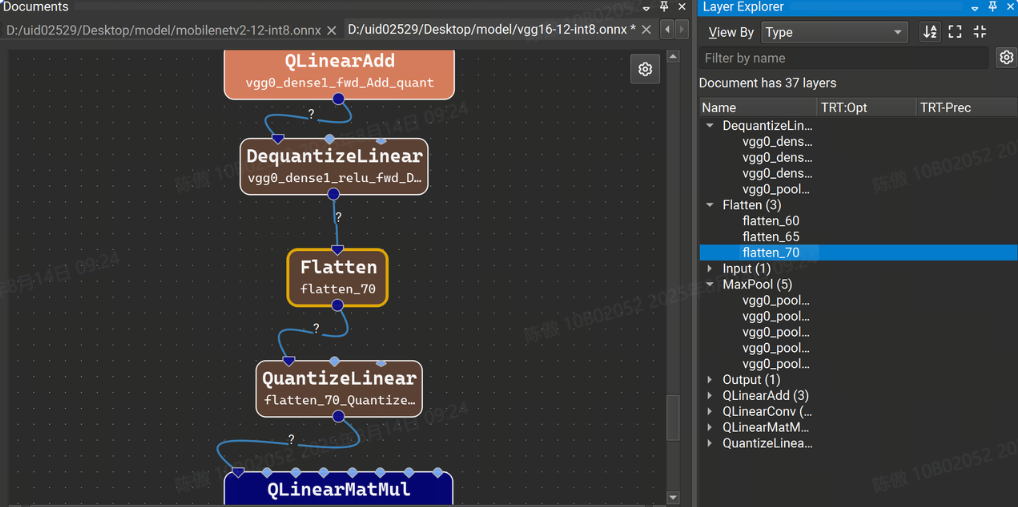
Layer Explorer 的高級過濾選項可通過單擊 Filter by name 文本框旁邊的齒輪圖標來訪問。高級篩選選項允許按層類型和分配給層的任何屬性(例如 TensorRT 層精度)進行篩選。帶有活動高級過濾器數量的紅色徽章顯示在齒輪上。
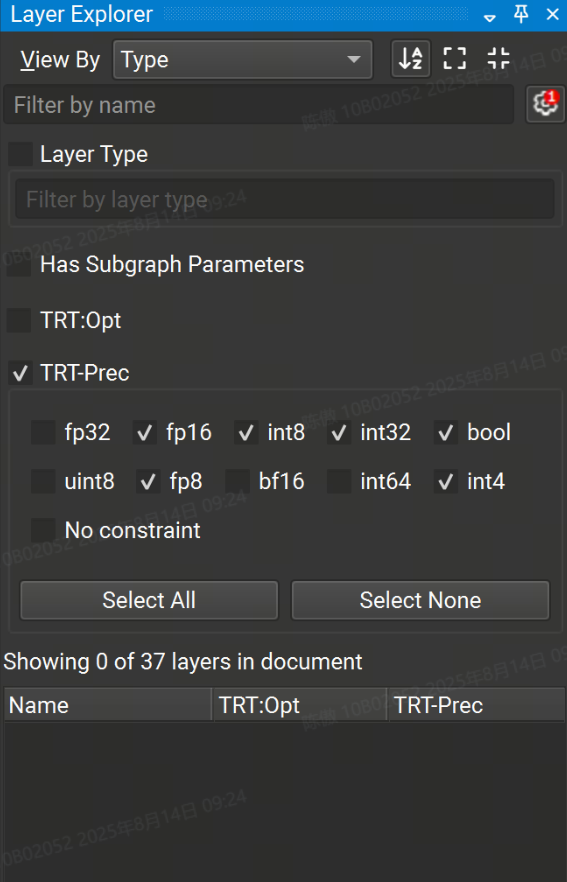
默認情況下,常量節點在 Model Canvas 和 Layer Explorer 中處于隱藏狀態。要顯示常量節點, View > Show All Constants。要在打開新模型時不再默認隱藏常量, Tools > Options,然后在 Model Canvas 頁面下,將 Hide Constant Layers 設置為 No。
參數
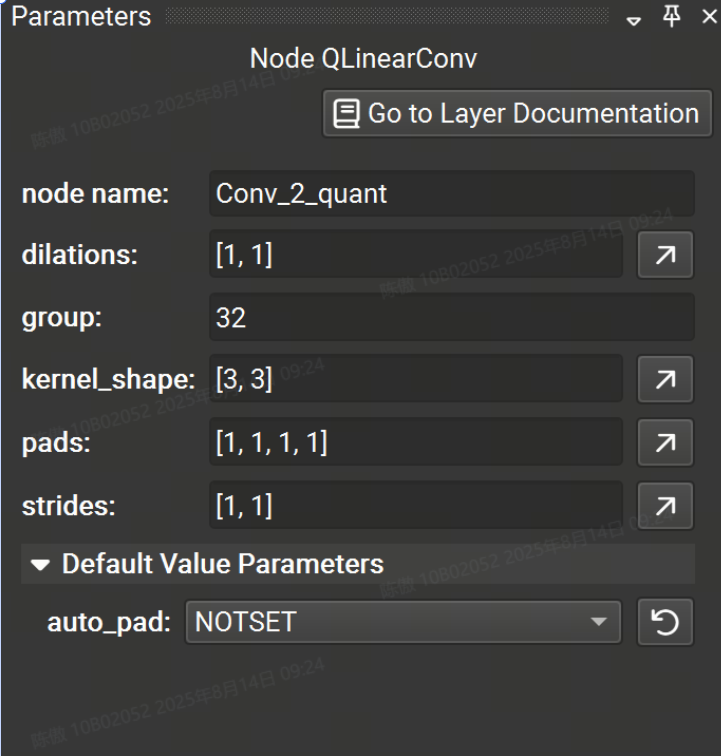
parameter 工具窗口允許對任何節點的參數進行交互式修改。從畫布中選擇一個節點,將列出該運算符的可用參數。節點名稱也可以編輯,但它在整個圖形中必須是唯一的。
具有未指定值的參數將獲得 Opset 中指定的默認值,并顯示在參數編輯器的可折疊的 Default Value Parameters 部分中。 修改參數時,該參數將移出 default value 部分。要將參數恢復為默認值,單擊圓形箭頭圖標,當鼠標懸停在字段上時,該圖標位于參數輸入字段的右側。
Tensor/List 值應采用以下格式:并且可以嵌套多維張量 。字符串值必須用單引號括起來, 可以使用將單引號嵌入到字符串文本中。 要獲得更高級的張量或列表編輯功能,使用 Tensor Editor,方法是單擊任何張量/列表類型參數最右側的向上箭頭按鈕。[1, 2, 3, 4][[1, 2], [3, 4]]'Some text'\'It\'s alive!'
如果當前未選擇任何層,則會顯示模型信息,例如導入的 ONNX opset 版本。 可以一次選擇多個圖層,以便進行批量參數編輯。僅顯示所選節點共有的參數。
編輯模型
將運算符拖放到畫布中會創建該運算符類型的新實例,并使用自動生成的名稱。所有實例都必須具有可編輯的唯一名稱;名稱應為有效的 C90 標識符。運算符由畫布上的矩形節點表示。此節點顯示運算符的名稱和類型,如果類型檢查器報告了任何問題,則顯示一個圖標。
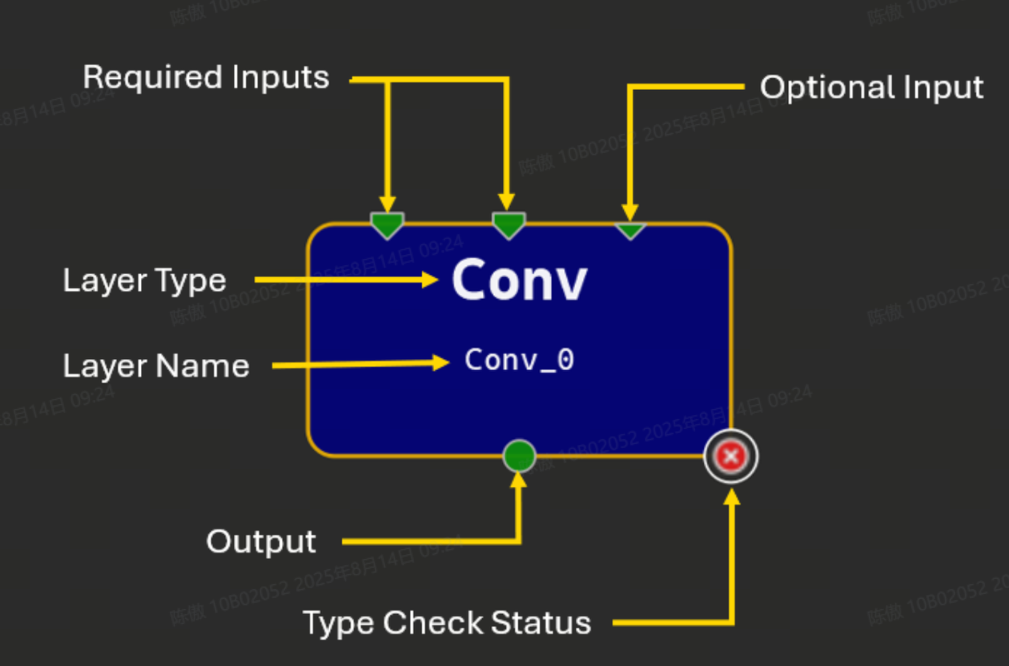
節點圖示符表示使用終端的運算符的輸入和輸出。節點頂部的三角形表示輸入,節點底部的圓圈表示輸出。大多數輸入端子需要連接才能使模型有效,但可選的輸入端子不是必需的。可選輸入在字形上用較小的三角形表示。多條鏈路可以從單個輸出端子開始,但只能將一條鏈路連接到給定的輸入端子。未連接的終端為綠色,帶鏈接的終端為深藍色,連接到初始值設定項的輸入終端為淺藍色。
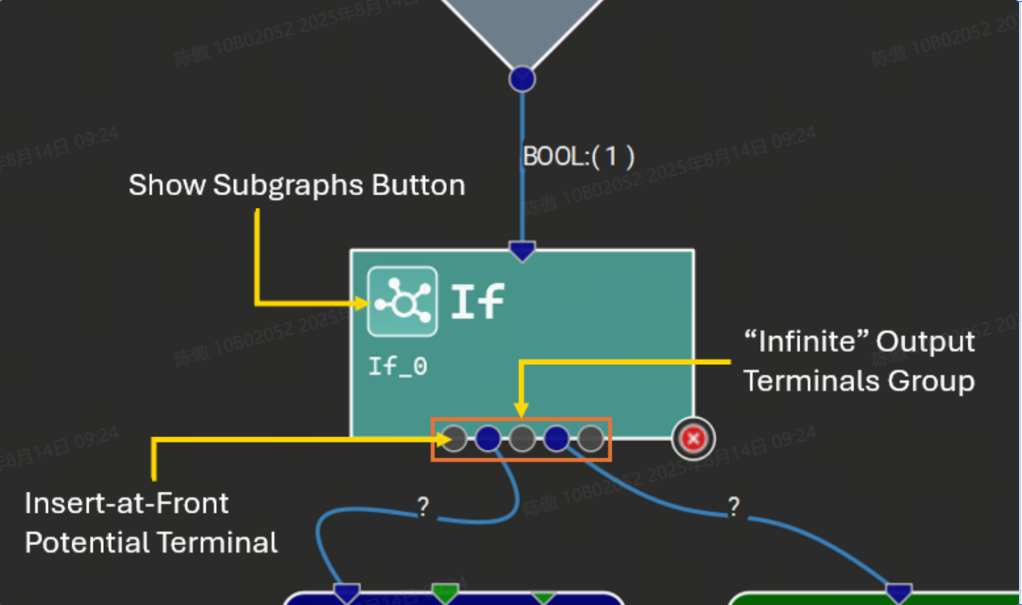
某些運算符接受給定參數的可變數量的輸入張量,或者為給定的輸出名稱生成可變數量的輸出張量。Nsight Deep Learning Designer 通過特殊的 “無限” 終端來表示這些。在連接到無限端子時,每個連接的端子之間將出現更多的灰色端子,代表潛在的新連接點。下圖顯示了一個具有可變輸出數量的運算符示例,以及子圖。
初始值設定項
初始化器在 ONNX 中用于表示常量張量值,例如權重。它們可以直接用作輸入,而無需引入額外的 Constant 運算符。單個初始值設定項可以由圖中的多個運算符使用。初始值設定項值可以直接嵌入到 ONNX 模型中,也可以從外部二進制文件引用。 每個初始值設定項都由模型中的唯一名稱標識。
初始值設定項編輯器工具窗口允許用戶查看和編輯已打開的 ONNX 模型的初始值設定項。
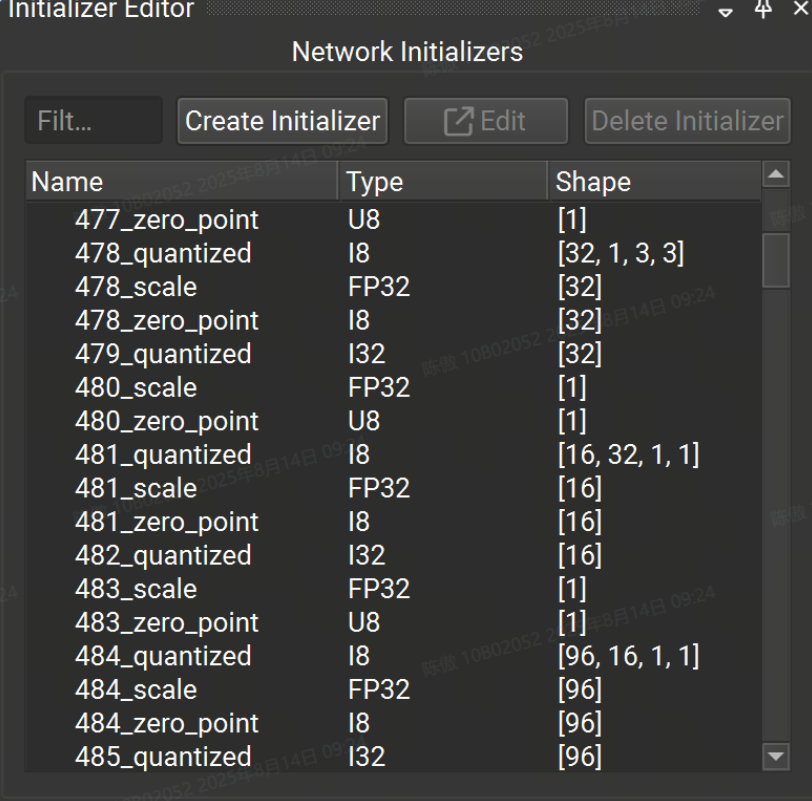
初始值設定項編輯器分為兩部分:上半部分用于查看、創建、編輯和刪除模型中的任何初始值設定項,下半部分用于查看和連接當前所選節點的初始值設定項。如果當前未選擇任何節點,則下半部分將被隱藏。
網絡初始值設定項列表可以按名稱進行篩選。所選的初始值設定項可以是:
-
從模型中刪除,這也將斷開它們與當前使用它的任何節點的連接。
-
使用張量編輯器進行編輯。
可以使用創建初始值設定項按鈕打開對話框,從頭開始創建初始值設定項。
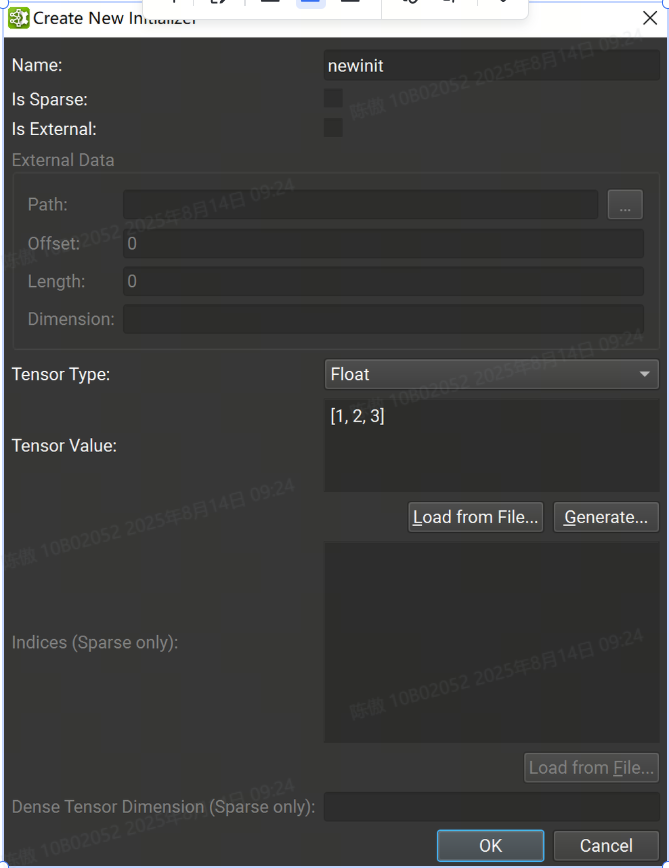
從那里,可以提供初始值設定項信息,例如名稱、張量類型和張量值。字符串值必須用單引號括起來。可以從 Numpy 文件加載 Tensor 值。請注意,在加載之前,數據類型必須與 Numpy 文件中的數據類型匹配。[1, 2, 3, 4][[1, 2], [3, 4]]'Some text'\'It\'s alive!'
也可以使用隨機或歸零數據生成初始值設定項以用于占位符目的。從 Create New Initializer 對話框中選擇張量類型,然后按 Generate... 按鈕。目前并非所有張量類型都支持隨機生成;如果沒有可用的生成支持,則該按鈕將被禁用。
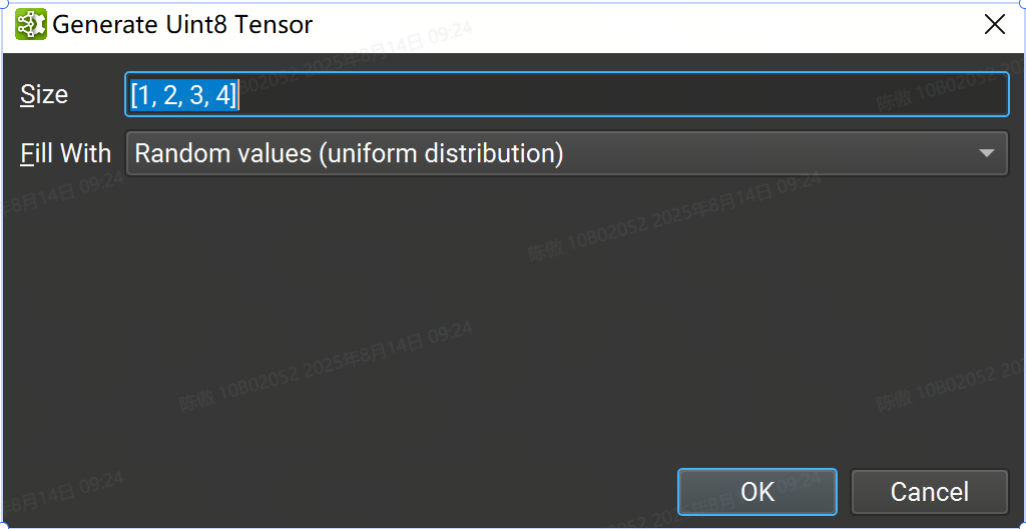
在 format 中輸入張量的大小,然后選擇 fill 方法:[1, 2, 3, 4]
-
隨機值(標準正態分布)使用標準正態分布(均值 = 0,方差 = 1)。可用于使用多個字節進行存儲的浮點類型。
-
零值將生成的張量的每個元素設置為零。適用于所有類型。
-
隨機正值 (uniform distribution) 使用類型支持的所有正值的均勻分布。排除零。可用于至少使用一個字節進行存儲的所有整數類型。
-
隨機負值 (uniform distribution) 使用類型支持的所有負值的均勻分布。排除零。可用于至少使用一個字節進行存儲的有符號整數類型。
如果初始值設定項標記為外部,則必須提供磁盤上二進制文件的路徑。外部文件必須位于相對于模型存儲位置。因此,在處理僅內存中的模型(例如未保存的新模型)時,無法創建外部初始值設定項。偏移量是存儲數據開始的文件中的字節位置,長度是包含數據的字節數。外部初始值設定項張量數據不直接存儲在 ONNX 模型中。這可以減小模型文件的大小。
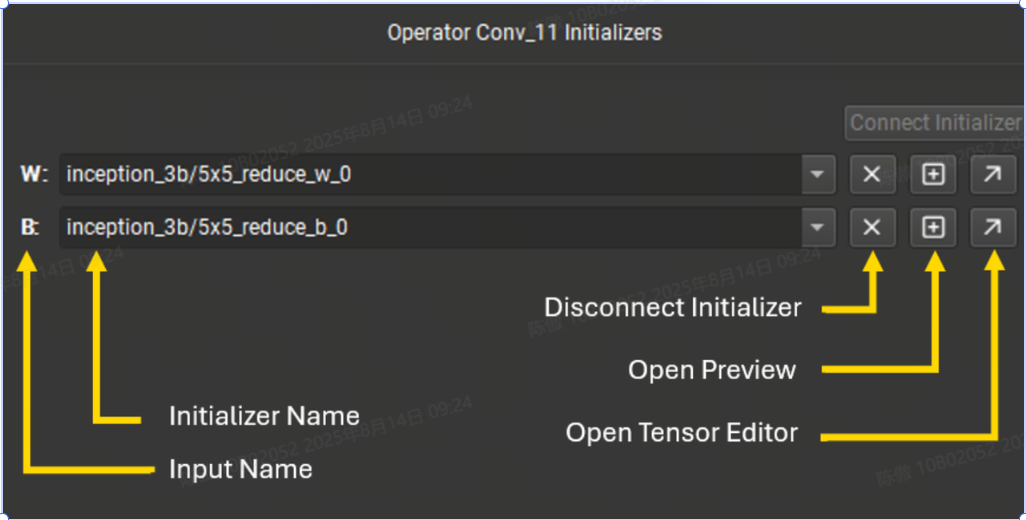
從畫布中選擇節點時,如果它有一個空閑終端,則啟用 連接初始值設定項 按鈕以允許將模型初始值設定項連接到該節點。 連接后,終端將在節點字形上變為黃色,表示它已連接到初始值設定項。將鏈接連接到它將斷開初始值設定項與節點輸入的連接。
初始值設定項編輯器的底部列出了當前所選節點的所有連接到初始值設定項的終端。可以使用下拉菜單切換終端使用的初始值設定項。下拉列表可按名稱過濾。 使用十字按鈕,可以斷開初始值設定項與終端的連接。加號按鈕打開張量值的預覽,對角線箭頭按鈕將打開張量編輯器。
子圖Subgraphs
一些 ONNX 控制流運算符,例如 Loop 和 If 將一個或多個子圖作為參數。子圖是與其父模型具有相同初始化器和導入操作集的ONNX圖形。
子圖的作用域由其父級決定,無論是運算符實例還是局部函數定義。作用域內的所有子圖都必須具有唯一的名稱。
可以使用Tools > Extract Model Subgraph命令將子圖導出到 Nsight 深度學習設計器中的獨立 ONNX 模型。在打開的對話框中,通過標識子圖的父類型(運算符或局部函數)、父作用域的名稱以及該作用域內的子圖名稱來選擇子圖。然后選擇用于保存提取的子圖的輸出路徑。
僅列出當前文檔中的運算符。要從另一個子圖或本地函數內的運算符導出子圖,必須從相應的子圖或本地函數文檔中打開 Tools > Extract Model Subgraph 向導。
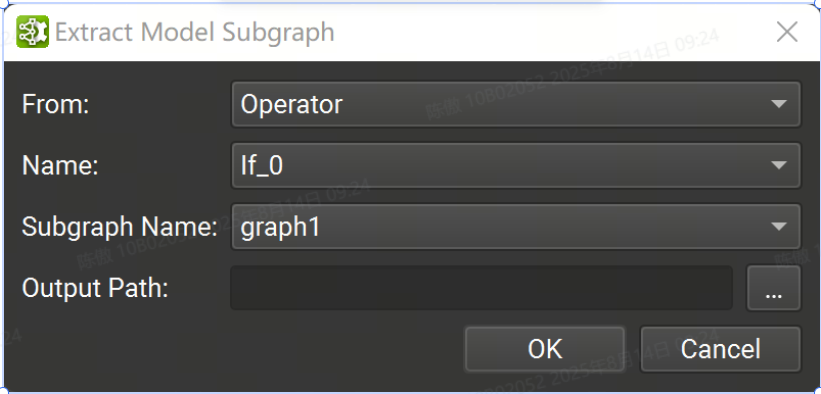
在創建對話框中,必須提供給定其范圍的唯一子圖名稱。可以啟用一些選項,以便在創建子圖后打開子圖,以及從運算符或局部函數子圖復制現有子圖。
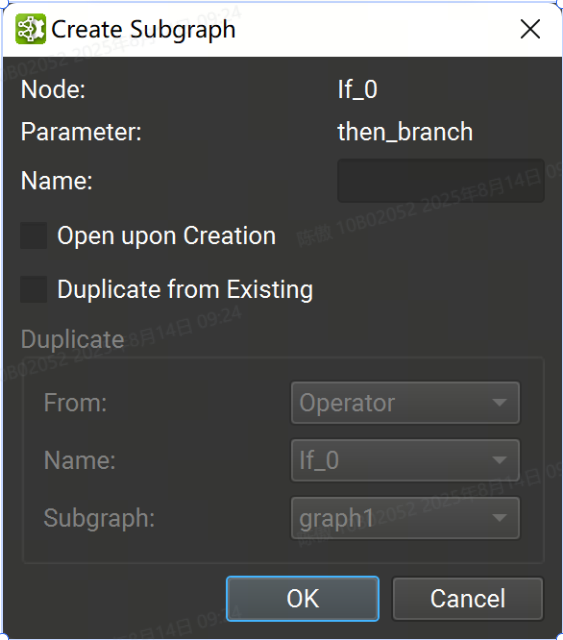
子圖可以在單獨的文檔選項卡中可視化。要打開子圖,請單擊運算符字形上的子圖按鈕,然后從菜單中選擇所需的子圖,或在參數編輯器工具窗口中單擊子圖的鏈接。
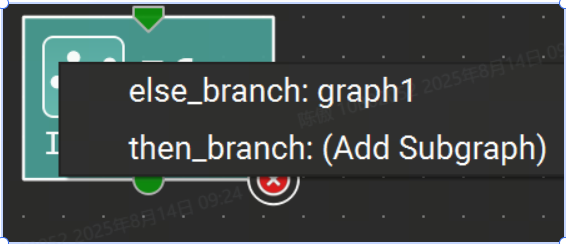
打開后,就像普通的 ONNX 模型一樣編輯子圖,模型初始值設定項在子圖中沒有模擬,因此無法編輯。使用主工具欄上的“Confirm Subgraph Edits”按鈕保留封閉文檔中子圖中的更改。此命令更新父文檔以反映對子圖的更改。否則,父文檔是只讀的,而其子圖則打開以供編輯。
本地函數
圖形組件通常在模型中重復。局部函數可用于表示這些重復模式。這通過將模式抽象為單個節點來創建模型的更高級別表示。
除了創建或刪除模型初始值設定項外,還可以像普通模型一樣編輯本地函數。必須使用主工具欄上的 Confirm Local Function Edits 按鈕來應用對本地函數所做的更改。應用后,本地函數定義將在模型中更新。
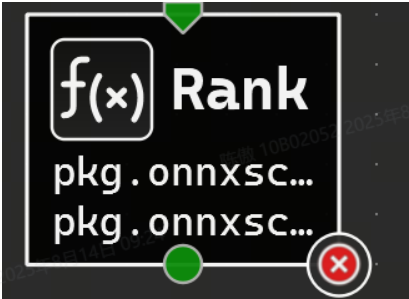
以使用 Model Local Functions (模型本地函數) 工具窗口管理本地函數。它列出了模型中當前定義的所有函數,該列表可以按名稱進行過濾。
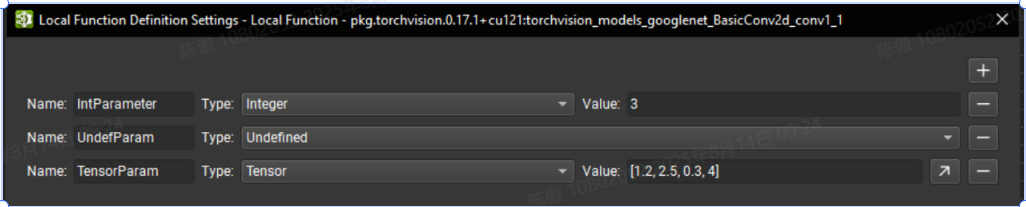
此外,還可以參數化局部函數。在 Nsight Deep Learning Designer 中編輯函數時,可以使用Tools > Local Function Settings action打開局部函數定義設置對話框。
在此對話框中,可以使用 + 按鈕定義新參數。必須提供唯一的名稱以及參數類型。undefined 類型的參數要求函數的每個實例在傳遞此參數的值時提供一種類型的信息。否則,必須為所有其他類型提供默認值。也可以通過單擊相應的 - 按鈕來刪除參數。
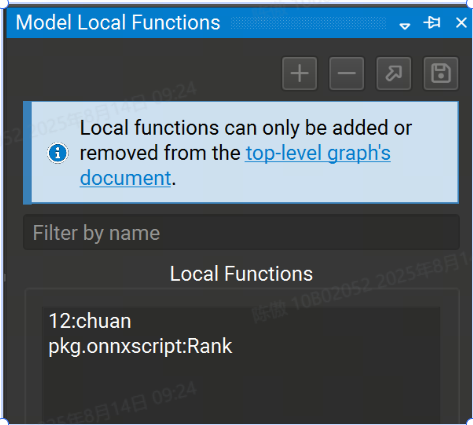
可以使用 Model Local Functions (模型本地函數) 工具窗口管理本地函數。它列出了模型中當前定義的所有函數,該列表可以按名稱進行過濾。可以使用箭頭和保存按鈕分別打開所選函數或將其提取到獨立的 ONNX 模型中。
+ 按鈕創建新的本地函數。提供函數名稱和域。- 按鈕從模型中刪除本地函數。該函數的所有實例都將轉換為自定義運算符。
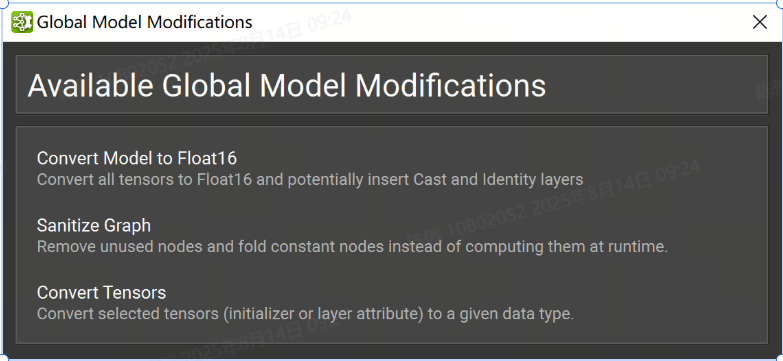
批量修改
在某些工作流中,可能需要修改 ONNX 模型的大部分或對每個節點執行特定修改。可以在Tools > Global Model Modification對話框下找到該工具。
模型轉為FP16
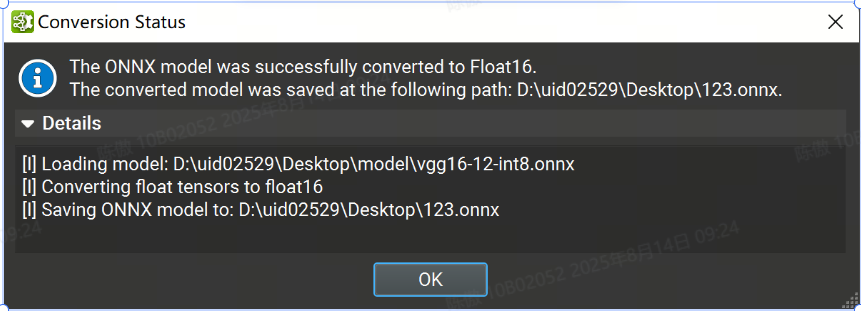
一種常見的模型優化技術是將模型權重轉換為半精度格式(例如 FP16)。這可以將模型大小減少一半,并提高某些 GPU 的性能,但可能會犧牲一些精度。
在tools > Global Model Modification對話框下,可以將 ONNX 模型轉換為使用 Float16。提供轉換后的模型的輸出路徑,然后單擊“完成”。執行轉換時會出現一個旋轉的輪子。該過程完成后,將出現一個對話框,并顯示轉換狀態,其中包含包含詳細日志的可展開部分。
Sanitize Graph
在tools > Global Model Modification對話框下的“清理圖形”批量修改作可以通過執行恒定折疊和刪除未使用的節點來幫助減小 ONNX 模型的大小。
要執行圖形清理,請在對話框中提供清理模型的輸出路徑,然后單擊“finish”。該過程完成后,將顯示一個對話框,其中包含包含詳細日志的可展開部分的狀態。
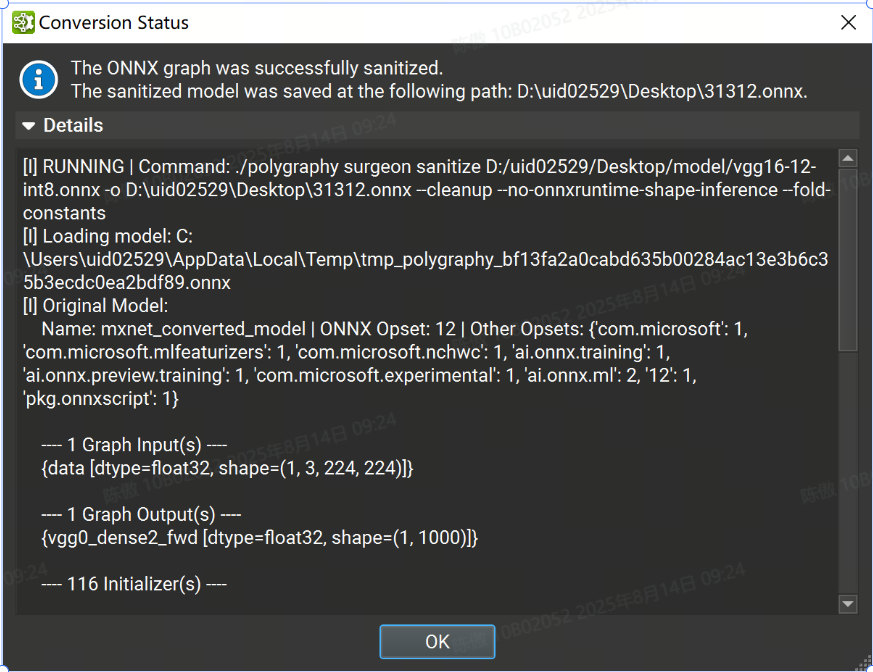
自定義選項
-
Set fold size threshold: 設定每個張量最大折疊尺寸閾值(以字節為單位),在此閾值之內的張量將進行常量折疊處理。任何生成的張量尺寸超過此閾值的節點將不會被折疊掉。
-
Number of constant folding passes: 設置恒定的折疊次數。計算張量形狀的子圖可能無法在單次折疊中達到要求。如果未指定,會自動計算所需的折疊次數。
轉換Tensor
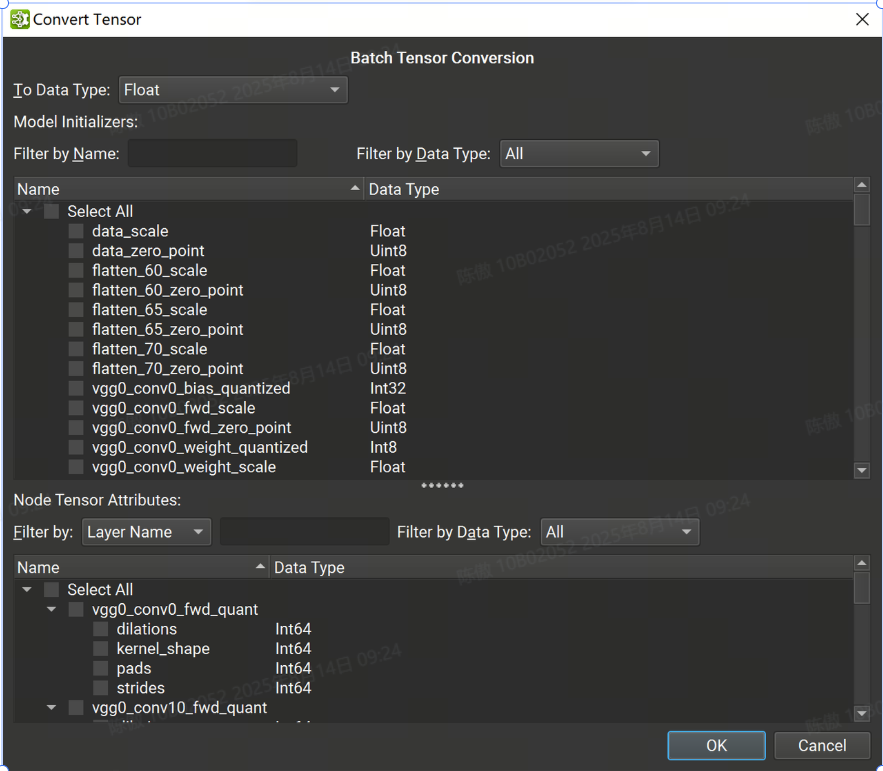
批量張量轉換對話框分為兩個面板:頂部列出所有模型初始值設定項,而底部包含所有張量或基于列表的節點屬性。初始值設定項可以按名稱和數據類型進行過濾,而節點的張量或列表可以按節點或張量名稱和數據類型進行過濾。
可以使用對話框頂部的組合框選擇節點張量、列表和初始值設定項的組合以轉換為單個目標數據類型。選擇所有必要的張量后。
根據源轉化和目標轉化數據類型,可能會發生數據精度丟失和/或截斷。撤消批量轉換會將之前轉換的所有張量恢復為其原始數據類型和值。
用戶工具
當用戶工作流程需要處理超出全局模型修改系統提供的范圍時,可以使用自定義用戶工具。用戶工具是一種將 ONNX 模型的自定義處理作為設計器設計工作流程的一部分的方法。
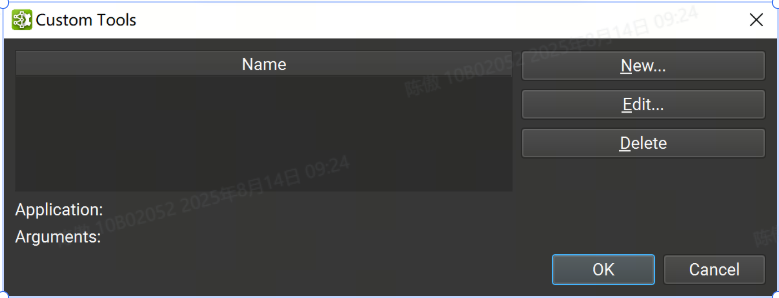
自定義工具可以通過 Tools > Custom Tools下可訪問的對話框進行管理。該對話框包含用戶定義的自定義工具列表。從列表中選擇一個工具將在底部顯示其應用程序路徑和參數。 可以使用對話框右側的相應按鈕刪除或編輯選定的自定義工具。
可以使用“new”按鈕創建新的自定義工具,這將打開一個新的對話框窗口,其中必須提供工具信息:
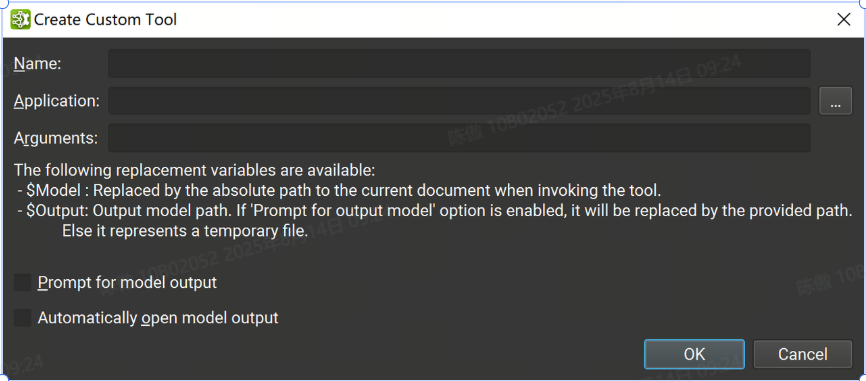
-
Name: 用于標識工具的唯一名稱
-
Application: 啟動該工具的可執行進程的應用程序路徑
-
Arguments: 要傳遞給應用程序的可選參數。有兩個特殊的替換參數可用:
$Model: 在啟動工具時被當前 ONNX 文檔絕對路徑替換。
$Output:“提示輸入模型輸出”選項會提示輸入此路徑。如果禁用該選項,則這是臨時文件的路徑。
-
Prompt for model output: 如果打開,則在調用該工具時將打開一個對話框,詢問將用于替換參數的路徑。
-
Automatically open model output: 如果打開,當工具成功完成并且如果參數列表中設置了變量時,將自動打開輸出文檔
請注意,要運行 Python 腳本,應用程序路徑應指向 Python 解釋器,并且提供的第一個參數應是 Python 腳本的路徑。
自定義用戶工具可以在 Tools > User 子菜單下找到,從該菜單中選擇一個工具將調用它,給定當前關注的 ONNX 模型。將打開一個對話框窗口,并提供運行過程的當前狀態以及標準輸出和錯誤日志。可以使用“取消”按鈕取消自定義工具進程,這將導致進程被終止。 根據是否為工具設置了自動打開模型輸出選項,當工具成功退出時,將打開輸出模型(如果有)。
活動平臺設置
活動可以在 Linux、Windows 或 NVIDIA L4T 上本地運行,也可以在 Linux 和 NVIDIA L4T 目標計算機上遠程運行。對于在本地運行的活動,主機和目標計算機是相同的。(主機平臺指運行Nsight設計器的計算機,目標平臺指運行活動的計算機)
連接管理
在 Nsight 設計器中啟動活動時,活動窗口的頂部用于選擇將在哪臺目標計算機上執行活動。支持本地和遠程目標。 默認情況下,將選擇在運行主機應用程序的平臺上執行。
點擊 Profile Model 可以調出 Session Settings
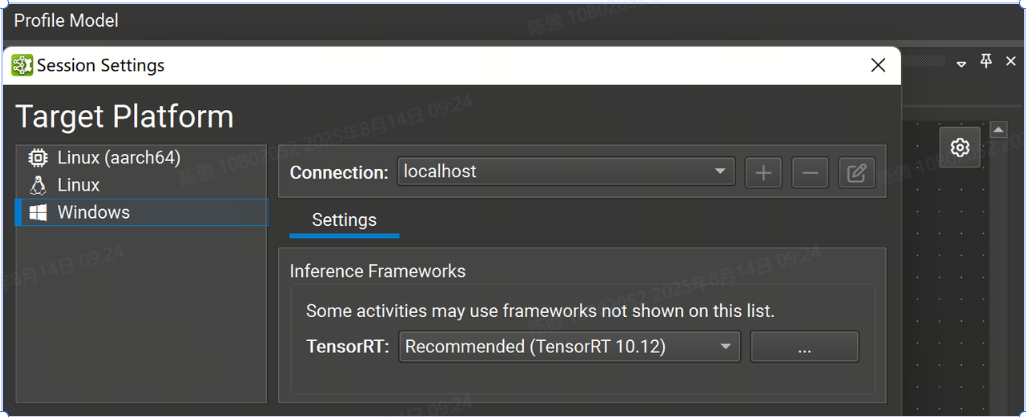
目前,Nsight 支持以下平臺:
-
Windows x86_64:僅限本地。
-
Linux x86_64:本地和遠程。
-
NVIDIA L4T arm64:本地和遠程。
使用遠程目標時,必須從頂部下拉列表中選擇或創建連接。要創建新連接,選擇 + 并輸入遠程連接詳細信息。使用本地平臺時,將選擇 localhost 作為默認主機,無需進一步的連接設置。
遠程連接
可以在“連接”對話框中將支持 SSH 的遠程目標配置為目標。要配置遠程設備,需要選擇支持 SSH 的目標平臺,然后按 + 按鈕。將顯示以下配置對話框。
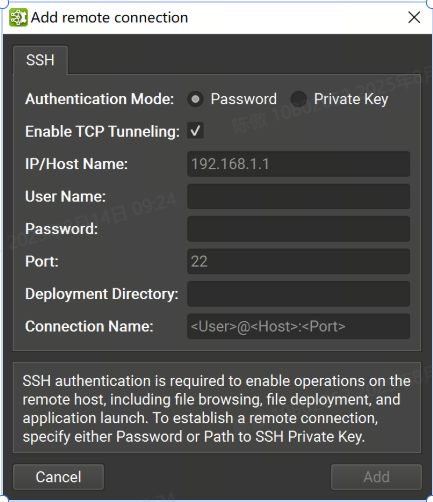
支持密碼和私鑰認證方式。在此對話框中,選擇身份驗證方法并輸入以下信息:
-
密碼
-
IP/Host Name:目標設備的 IP 地址或主機名。
-
User Name: SSH 連接的用戶名。
-
Password: SSH 連接的用戶密碼。
-
Port: SSH 連接的端口。(默認值為 22)。
-
Deployment Directory:在目標設備上用于部署支持文件的目錄。指定的用戶必須具有對此位置的寫入權限。支持相對路徑。
-
Connection Name:將顯示在 Connection (連接) 對話框中的遠程連接的名稱。如果未設置,它將默認為 。
<User>@<Host>:<Port>
-
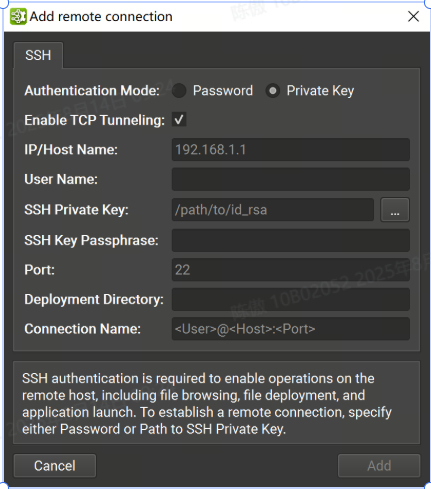
-
私鑰
-
IP/Host Name:目標設備的 IP 地址或主機名。
-
User Name: SSH 連接的用戶名。
-
SSH Private Key:用于向 SSH 服務器進行身份驗證的私鑰。
-
SSH Key Passphrase:私鑰的密碼。
-
Port: SSH 連接的端口。(默認值為 22)。
-
Deployment Directory:在目標設備上用于部署支持文件的目錄。指定的用戶必須具有對此位置的寫入權限。支持相對路徑。
-
Connection Name:將顯示在 Connection (連接) 對話框中的遠程連接的名稱。如果未設置,它將默認為 。
<User>@<Host>:<Port>
-
遠程啟動 Activity 后,如有必要,所需的二進制文件和庫將復制到遠程計算機上的 Deployment Directory。
在 Linux 和 NVIDIA L4T 主機平臺上,Nsight Deep Learning Designer 支持在目標計算機上進行 SSH 遠程分析,這些計算機無法通過 ProxyJump 和 ProxyCommand SSH選項 從運行 UI 的計算機直接尋址。 這些選項可用于指定要連接的中間主機或要運行的實際命令,以獲取連接到目標主機上的 SSH 服務器的套接字,并且可以添加到 SSH 配置文件中。
請注意,對于這兩個選項,Nsight Deep Learning Designer 都會運行外部命令,并且不會實施任何機制,以使用在連接對話框中輸入的憑證向中間主機進行身份驗證。這些憑證將僅用于對計算機鏈中的最終目標進行身份驗證。
使用 ProxyJump 選項時,Nsight Deep Learning Designer 使用 OpenSSH 客戶端建立與中間主機的連接。這意味著,為了使用 ProxyJump 或 ProxyCommand,必須在主機上安裝支持這些選項的 OpenSSH 版本。
在這種情況下,向中間主機進行身份驗證的常見方法是使用 SSH 代理并使其保存用于身份驗證的私鑰。
由于使用了 OpenSSH SSH 客戶端,因此還可以使用 SSH askpass 機制以交互方式處理這些身份驗證。
部署工作流程
在開始活動之前,Nsight 深度學習設計器將檢查目標機器上是否存在所有必要的依賴項;對于遠程目標,Nsight 深度學習設計器將查看提供的Deployment Directory。對話框顯示活動的依賴項列表和驗證進度。如果某些依賴項丟失或不是最新的,則對話框中的它們條目將顯示一個警告圖標,并且 Nsight 深度學習設計器將開始在目標上部署它們。
在目標計算機上部署所有依賴項后,Nsight Deep Learning Designer 將繼續啟動活動。后續啟動將更快,因為 Nsight 深度學習設計器不會重新部署依賴項,只要它們仍然符合活動要求。
Nsight 深度學習設計器將目標計算機下載的依賴項和輔助二進制文件存儲在主機上,并將時序緩存和一些其他驗證緩存存儲在目標計算機上的本地緩存目錄中。默認情況下,本地緩存目錄存儲在 Windows 上的HOME\AppData\ Local 中,在 Linux 上存儲在 $HOME/.config 中。可以通過設置NV_DLD_CACHE_DIR環境變量來更改此目錄。
使用 TensorRT
Nsight 深度學習設計器可以將 ONNX 模型導出到 TensorRT 引擎,并可選擇對其進行分析。生成的引擎文件與其他 TensorRT 10.10 應用程序完全兼容。
筆記:
-
使用 Nsight 創建的 TensorRT 引擎特定于創建它們的 TensorRT 版本和創建它們的 GPU。有關詳細信息,請參閱 TensorRT 文檔。
-
Nsight 器在構建 TensorRT 網絡時使用時序緩存。如果可能,將從緩存中加載常用層的戰術計時。
-
引擎構建和分析階段依賴于推理算法的準確時序,用于引擎優化和性能報告。為獲得最佳效果,請勿將其他 GPU 工作與 TensorRT 活動并行運行,因為這會扭曲結果。
-
導出和分析活動都可以從“welcone”頁面訪問的“Start Activity”對話框啟動。
Dynamic Shapes and TensorRT
TensorRT 在處理動態輸入大小時需要優化配置文件。靜態確定的輸入大小不需要其他信息,但每個動態輸入大小都需要優化配置文件詳細信息。如果未以這種方式完全指定輸入,TensorRT 將失敗并出現錯誤,例如 .['batch', 3, 544, 960]['W', 'H']input_name: dynamic input is missing dimensions in profile 0
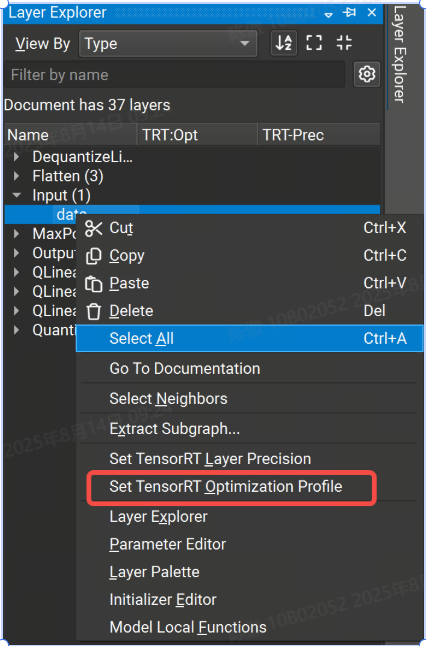
Nsight 提供了在主機 GUI 中定義優化配置文件的方法:
-
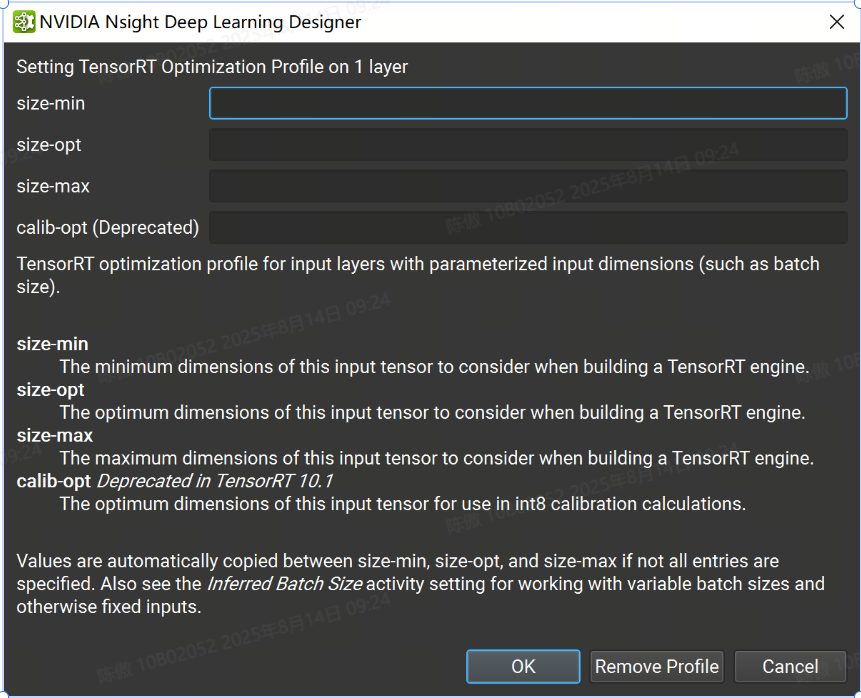
可以通過 TensorRT 優化配置文件屬性設置各個層的優化配置文件。右鍵單擊畫布或圖層資源管理器中的輸入圖層,然后選擇 Set TensorRT Optimization Profile 上下文菜單項。這將打開一個對話框,您可以在其中定義輸入的最小、最大和最佳大小。可選的 and 字段用于定義輸入的最小和最大大小。請注意,優化配置文件只能應用于頂級圖的輸入,而不能應用于子圖或局部函數。
為 TensorRT 指定層精度
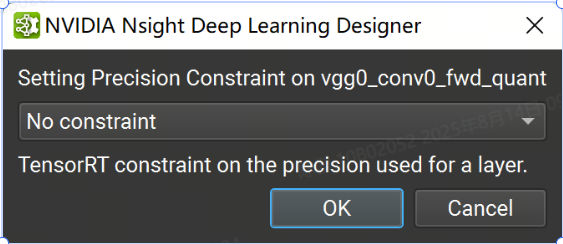
當使用默認設置運行時,TensorRT 將使用自動調整從啟用的策略中選擇每一層的數據類型精度,以最大限度地提高性能。但是,可以通過使用 Nsight 深度學習設計器中的 TensorRT 層精度屬性在每層的基礎上強制執行精度約束。可用的浮點精度選項包括:fp32、fp16、bf16 和 fp8。整數選項是 int64、int32、int8、int4、uint8 和 bool。如果未為圖層分配精度,TensorRT 將使用自動調整為該圖層選擇最佳精度。請注意,除了指定精度約束外,還必須在活動設置中將鍵入模式設置為“遵守精度約束”或“首選精度約束”。
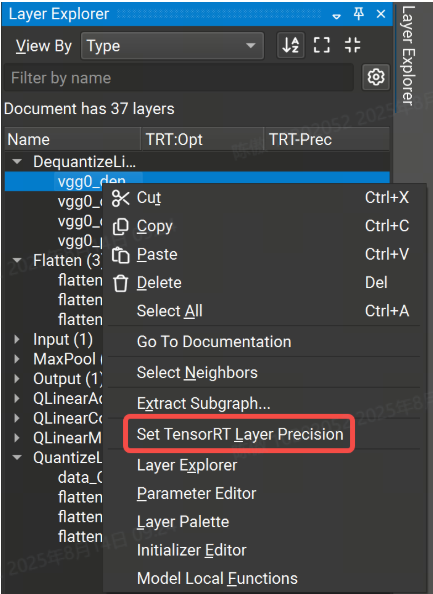
可以在 Nsight 深度學習設計器中設置層精度約束,方法是右鍵單擊“層資源管理器”中的選定行或模型畫布中的節點,然后選擇“設置層精度”上下文菜單項,然后在出現的對話框中選擇精度選項。要清除精度約束,請為選定層選擇“無約束”選項。
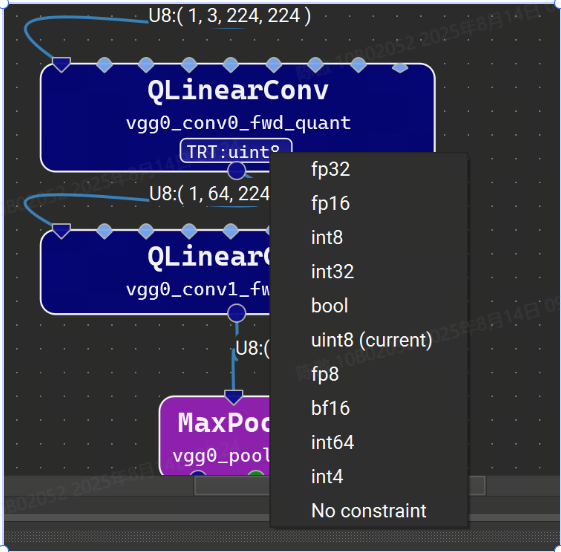
具有精度約束的圖層將具有顯示在圖層資源管理器的 TRT-Prec 列中的約束值,并且圖層字形上將顯示具有所選精度的小徽章。單擊此標志將顯示用于更改或刪除約束的選項的快速菜單。
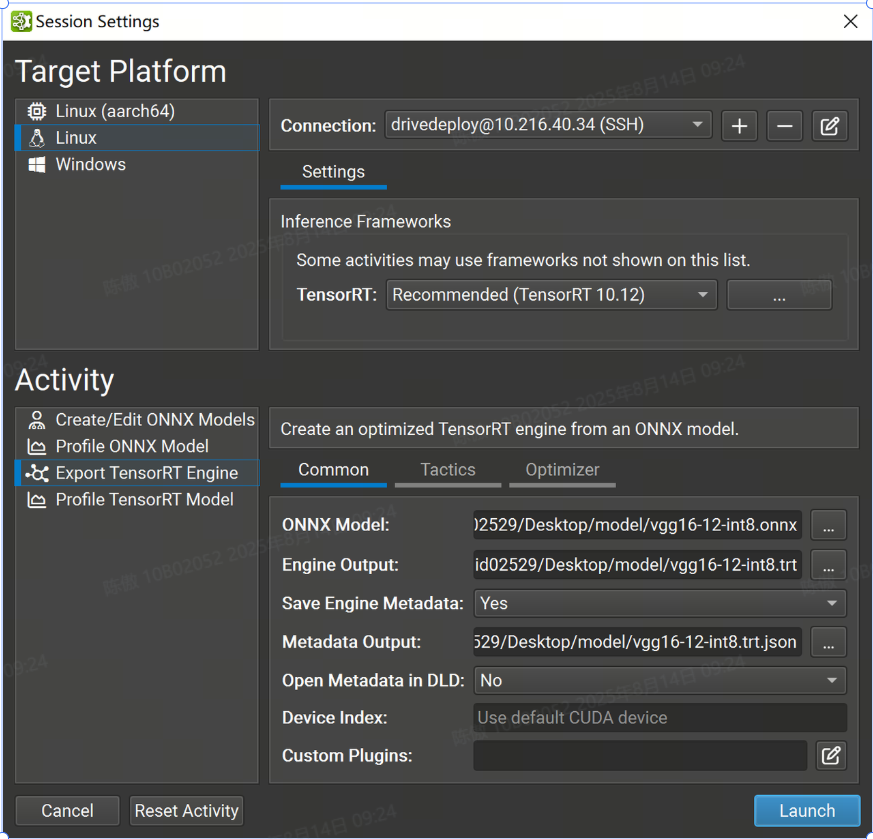
導出 TensorRT 引擎
要導出 TensorRT 引擎,請打開要導出的 ONNX 模型,然后使用 File > Export > TensorRT Engine 菜單項。ONNX 模型也可以從“開始活動”對話框中導出,而無需事先打開它們。
常用設置
-
TensorRT:下拉選擇要使用的TensorRT版本,也可以選擇在目標系統上使用系統安裝的 TensorRT,或指定自定義路徑。如果指定自定義路徑,則它必須是從目標計算機上的部署目錄到 TensorRT 共享庫位置的相對路徑。
-
ONNX 模型:導出的模型的本地路徑。如有必要,它將被復制到目標系統。
-
Engine Output :要保存導出的 TensorRT 引擎的本地目標。如有必要,將從目標系統復制它。該活動根據 ONNX 模型文件名建議此參數的默認名稱。
-
Save Engine Metadata :控制存儲在 TensorRT 引擎中的元數據量。當設置為 YES 時,-level 元數據(完整信息)將存儲在引擎中。將此選項設置為 No 將刪除所有圖層信息。
-
Metadata Output:是可選的。如果為該參數提供了本地路徑,則 Nsight 將在導出后創建一個 TensorRT 類的實例,并從目標系統復制其輸出。如果此參數留空,則不會創建任何元數據文件。該活動根據 ONNX 模型文件名建議此參數的默認名稱。
-
在DLD中打開Metadata:控制導出后是否在Nsight中打開元數據文件作為模型進行可視化。僅當生成元數據文件時,此選項才可用。
-
設備索引選項:控制在多 GPU 系統上使用的 CUDA 設備。設備零表示默認的 CUDA 設備,設備按調用中的順序排列。如果此設置留空,則 Nsight 深度學習設計器將使用第一個 CUDA 設備。
-
自定義插件:允許在引擎構建期間將路徑傳遞到可選的自定義TensorRT插件以加載。提供的路徑必須相對于所選目標系統。插件必須與選定的 TensorRT 版本兼容。
戰術設置
本部分中的大多數設置都與 TensorRT 的枚舉密切相關。BuilderFlags
FP32 張量格式和策略始終可用于 TensorRT。如果 TensorRT 會導致整體運行時間縮短或不存在較低精度的實現,則仍可能選擇更高精度的層格式。
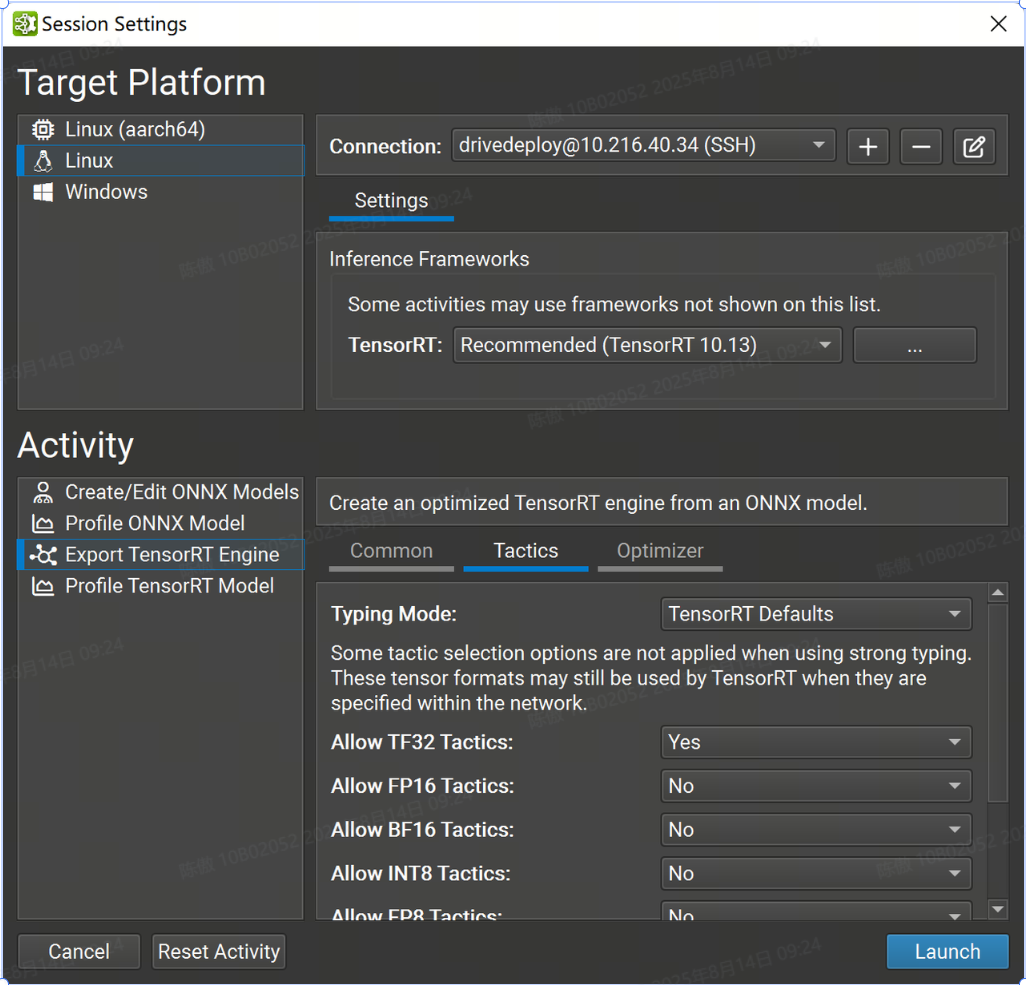
-
Typing Mode 設置控制 TensorRT 的類型系統:
-
TensorRT Defaults 指示 TensorRT 的優化器使用自動調整來確定張量類型。此選項生成最快的引擎,但當模型精度要求層以比 TensorRT 選擇的更高的精度運行時,可能會導致精度損失。在此模式下,層精度約束將被忽略。
-
Strongly Typed 指示 TensorRT 的優化器使用 ONNX 運算符類型規范中的規則確定張量類型。類型不是自動調整的,可能會導致引擎比 TensorRT 選擇張量類型的引擎慢,但較小的內核替代方案集可以縮短引擎構建時間。在此模式下,層精度約束和 FP16、BF16、INT8 和 FP8 策略設置將被忽略。
-
Obey Precision Constraints 使用 TensorRT 自動調整,其中尚未使用 Nsight 深度學習設計器設置層精度約束。如果特定精度約束不存在層實現,則引擎構建將失敗。
-
Prefer Precision Constraints 選項類似于 Obey Precision Constraints,但如果無法觀察到層精度約束或導致網絡變慢,TensorRT 將發出警告消息,而不是無法構建引擎。
-
-
Allow TF32 Tactics 允許 TensorRT 的優化器選擇 TensorFloat-32 精度。此格式需要 NVIDIA Ampere GPU 架構或更新版本。
-
Allow FP16 允許 TensorRT 的優化器選擇 IEEE 754 半精度。
-
Allow BF16 Tactics 允許 TensorRT 的優化器選擇 Bfloat16 精度。此格式需要 NVIDIA Ampere GPU 架構或更新版本。
-
Allow INT8 Tactics 允許 TensorRT 的優化器使用量化的 8 位整數精度。建議使用顯式量化網絡,但如果網絡被隱式量化且未提供校準緩存,則 Nsight 深度學習設計器將分配占位符動態范圍(類似于 )。
trtexec -
Allow FP8 Tactics 允許 TensorRT 的優化器使用量化的 8 位浮點精度。此設置與 INT8 設置互斥,通常僅對于具有插件生成的可選 FP8 張量的網絡才需要。
-
Examine Weights for Sparsity 指示 TensorRT 的優化器檢查權重并在權重具有合適的稀疏度時使用優化函數。
-
Allow cuDNN 和 cuBLAS Tactics 允許 TensorRT 使用 cuDNN 和 cuBLAS 庫進行層實現。禁用此設置后,將僅考慮內部 TensorRT 內核。啟用此設置將導致 cuDNN 下載到目標。
-
Native Instance Norm 指示 TensorRT 使用自己的實例規范化實現,而不是使用 cuDNN 的基于插件的實現。禁用此設置將導致 cuDNN 下載到目標。
優化器設置
此頁面中的設置主要控制 TensorRT 界面。
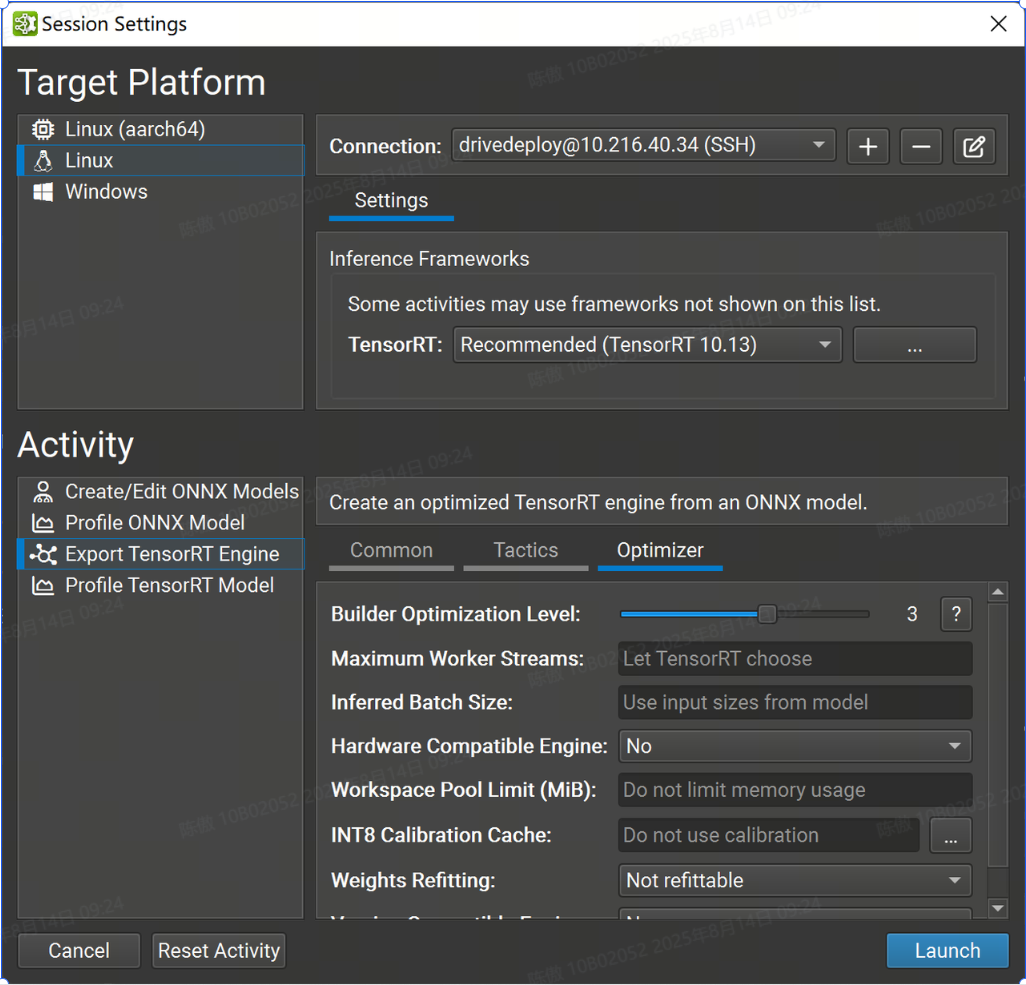
-
Builder Optimization Level 選項控制引擎構建時間和推理時間之間的權衡。更高的優化級別允許優化器花費更多時間搜索優化機會,這可能會在運行時獲得更好的性能。
-
Maximum Worker Streams 控制多流推理。如果模型包含可以并行運行的運算符,TensorRT 可以在輔助流上執行它們。此設置的值定義了在構建時要提供給 TensorRT 的最大流數。如果此設置留空,TensorRT 將使用內部啟發式方法來選擇適當的數字。將此值設置為零以禁用流并行性。
-
Inferred Batch Size 選項允許隱式指定 TensorRT 優化配置文件
-
Hardware Compatible Engine 選項可創建一個 TensorRT 引擎,該引擎適用于所有支持 TensorRT 的具有 Ampere 架構或更高版本的獨立 GPU。使用此功能可能會對性能產生影響,因為它會排除對后續 GPU 架構的優化。
-
Workspace Pool Limit (MiB) 選項控制 TensorRT 使用的工作區內存池的大小。該值應以 mibibytes 為單位指定;一個 MiB 是 2(20)字節。將此值設置得太小可能會阻止 TensorRT 找到層的有效實現。將此值留空(默認值)將消除限制并允許 TensorRT 使用 GPU 上所有可用的全局內存。
-
INT8 Calibration Cache 選項允許您為隱式量化 INT8 網絡指定校準緩存文件。將此值留空(默認值)將禁用校準。校準緩存既不需要,也不用于顯式量化網絡或不使用 INT8 策略的網絡。
-
Weights Refitting 選項控制權重是否存儲在生成的 TensorRT 模型中,以及是否可以在推理時更改權重。不可調整選項是 TensorRT 的默認值。它嵌入了可能無法重新安裝的重物。Refittable(包括權重)選項對應于 TensorRT 的標志;它嵌入了砝碼并允許重新安裝所有砝碼。Refitable (Weights stripped) 選項對應于 TensorRT 的標志。此選項僅嵌入具有性能敏感優化的權重;所有其他重量都被省略并可重新調整。應用程序應在推理時將原始權重重新調整到引擎中。
kREFITkSTRIP_PLAN -
Version Compatible Engine 選項創建了一個 TensorRT 引擎,可用于對更高版本的 TensorRT 進行推理。有關詳細信息,請參閱 TensorRT 文檔。
分析
Nsight支持使用 TensorRT 或 ONNX Runtime 作為推理框架對網絡進行分析。GPU 性能指標僅在使用 TensorRT 進行分析時可用。
要分析,請打開要分析的 ONNX 模型,然后使用 Profile Model 工具欄按鈕或 Tools > Profile Model 菜單項。也可以從 Start Activity 對話框中分析 ONNX 模型,而無需事先打開它們。
當以NVIDIA L4T平臺為目標時,用戶(本地或遠程)需要是 Debug 組的成員才能進行分析。
使用 ONNX 運行時進行分析
要使用 ONNX 運行時分析模型,請打開要分析的 ONNX 模型,然后使用 Tools > Profile Model 菜單項。ONNX 模型也可以從 Start Activity 對話框(可通過“歡迎頁面訪問”)進行分析,而無需事先打開它們。

Nsight Deep Learning Designer 的 ONNX Runtime 分析器基于 ONNXRuntime 測試二進制文件。ONNX 運行時分析的選項如下:
-
ONNX Model 參數是要分析的模型的本地路徑。如有必要,模型文件將被復制到目標系統。
-
Iterations 控制收集數據時執行的推理迭代次數。隨著采樣的數據點增加,增加此值會減少計算中值推理傳遞時的噪聲,但相應地會增加分析模型所需的時間。
-
Execution Provider 選項定義 ONNX 運行時探查器在推理期間將使用的后端。所有目標平臺都支持 CPU 和 CUDA 提供程序。Windows 目標還支持 DirectML 提供程序。
-
Enable Model Optimization 選項控制探查器是否應在運行推理之前首先應用圖形級轉換來優化模型。如果啟用,探查器將應用最高級別的優化,如 ONNX 運行時中的圖形優化中所述。
-
Generate Random Input(s) Data 控制分析器是否應為模型的輸入生成隨機數據,而無需在模型中嵌入數據或從外部文件引用數據。自由尺寸被視為 1。如果關閉,則必須提供輸入數據文件夾。
-
Input Data Folder 選項控制探查器應在何處查找模型輸入的數據。生成隨機輸入(Generate Random Input(s)必須關閉數據才能定義數據文件夾。它應該指向一個目錄,其中包含一個文件,每個模型輸入都有一個 ONNX TensorProto。Protobuf 文件需要命名為其相應模型的輸入,例如:。如有必要,輸入數據將被復制到目標系統。
input_0.pb -
Output Profile 參數是要保存探查器報告的本地目標。如有必要,將從目標系統復制它。該活動根據 ONNX 模型文件名建議此參數的默認名稱。
使用 TensorRT 進行分析
要使用 TensorRT 分析模型,請打開要分析的 ONNX 模型,然后使用工具>分析模型菜單項。ONNX 模型也可以從“開始活動”對話框(可通過“歡迎頁面訪問”)進行分析,而無需事先打開它們。
使用動態輸入大小分析 ONNX 模型需要 TensorRT 優化配置文件。分析器在生成隨機輸入數據時使用輸入最佳大小。
選擇版本
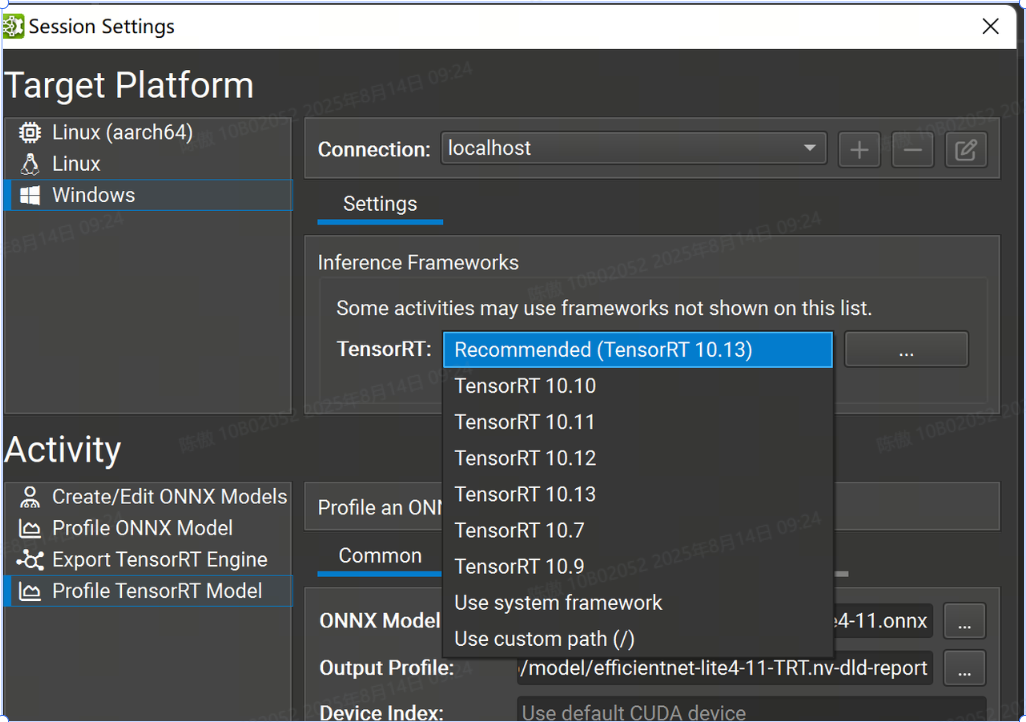
Nsight 支持多個次要版本的 TensorRT 10 進行分析。選擇要使用的 TensorRT 版本。有選定的 TensorRT 版本可供自動下載和部署(以及推薦版本)。您也可以選擇在目標系統上使用系統安裝的 TensorRT,或指定自定義路徑。如果您指定自定義路徑,則它必須是從目標計算機上的部署目錄到 TensorRT 共享庫位置的相對路徑。
常用設置
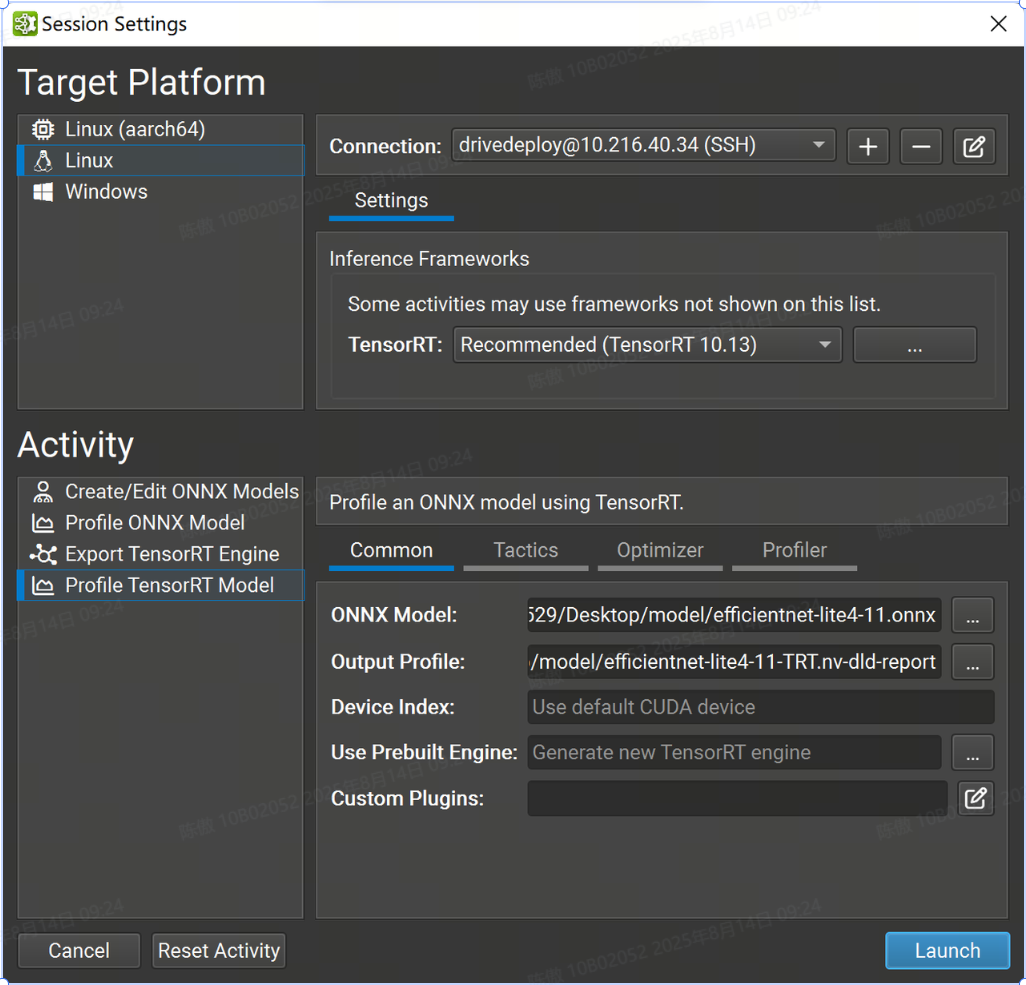
-
ONNX Model 參數是要分析的模型的本地路徑。如有必要,它將被復制到目標系統。
-
Output Profile 參數是要保存探查器報告的本地目標。如有必要,將從目標系統復制它。該活動根據 ONNX 模型文件名建議此參數的默認名稱。
-
Device Index 控制在多 GPU 系統上使用的 CUDA 設備。設備 0 表示默認的 CUDA 設備,設備按調用中的順序排列。如果此設置留空,則 Nsight 深度學習設計器將使用第一個 CUDA 設備.
-
Use Prebuilt Engine 選項允許您從 導出 TensorRT 引擎 活動或其他工作流(例如而不是構建新引擎)分析預先存在的 TensorRT 引擎。引擎文件必須是從正在分析的 ONNX 模型構建的,必須具有分析詳細性,并且如果可能,將在推理之前自動重新擬合。在分析預構建引擎時,將忽略“戰術”和“優化器”頁面中的設置。該引擎被視為可信的,任何嵌入式主機代碼(如 TensorRT 版本兼容性或插件嵌入選項)都將根據需要反序列化和執行。
-
Custom Plugins 參數允許在引擎構建期間將路徑傳遞到可選的自定義TensorRT插件以加載。提供的路徑必須相對于所選目標系統。插件必須與 TensorRT 10.10 兼容.
分析器設置
此頁面中的設置控制 Nsight 分析器的行為,而不是 TensorRT。
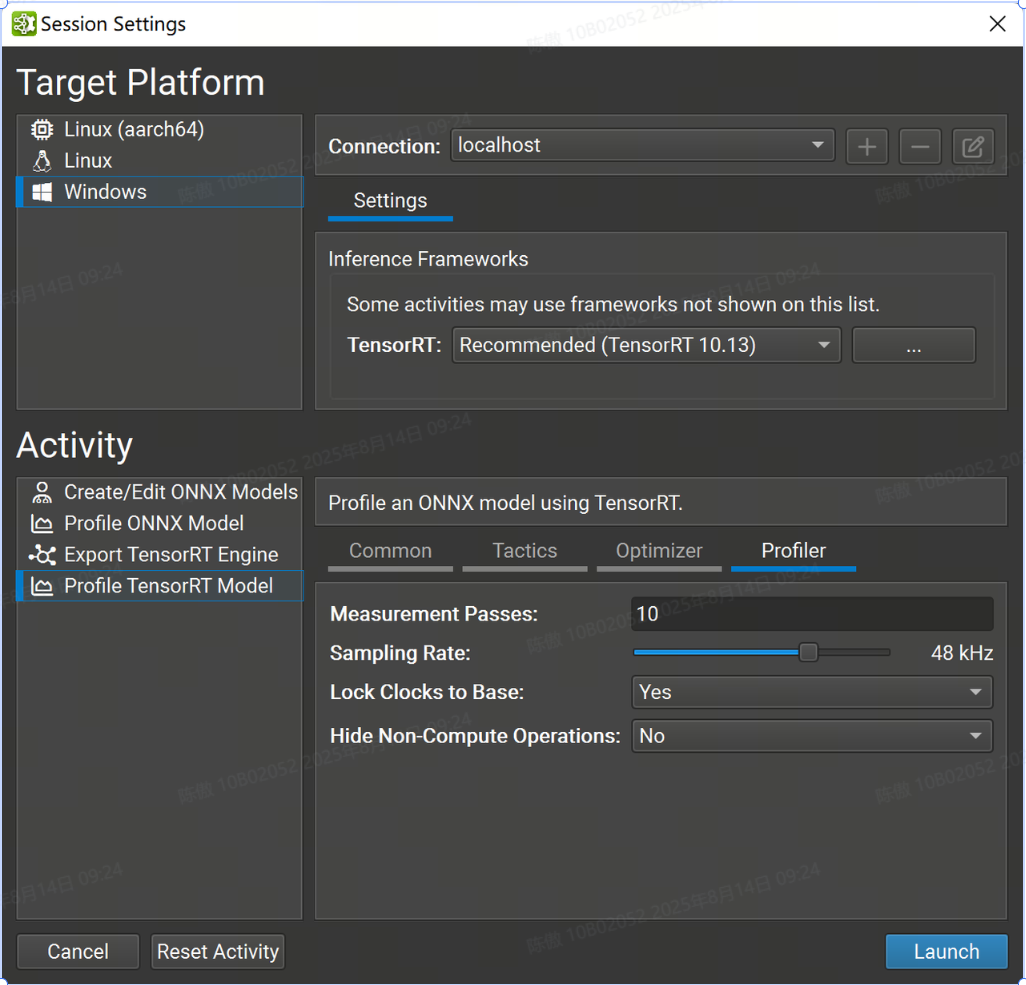
-
Measurement Passes 選項控制收集數據時執行的推理迭代次數。隨著采樣的數據點增加,增加此值會減少計算中值推理傳遞時的噪聲,但相應地會增加分析模型所需的時間。
-
Sampling Rate 選項控制 GPU 性能計數器收集的頻率。增加此值會為分析報告收集更多數據,但可能會溢出大型模型上的收集緩沖區。
-
Lock Clocks to Base 選項控制是否將 GPU 時鐘鎖定到其基本值,從而在分析期間禁用時鐘提升。鎖定時鐘提高了測量一致性,但代價是推理性能下降。
-
Hide Non-Compute Operations 控制是否在測量循環和生成的分析器報告中包括性能分析器開銷,例如主機/設備內存副本。
在對模型設計進行增量更改時,應將時鐘鎖定為基本值。各個層時序值將反映 GPU 的一致性能狀態,并在模型的各個版本之間進行有意義的比較。在實際配置中測量端到端性能時,應解鎖時鐘,隱藏非計算操作,并將 Measurement Passes 值設置為較大的數字(通常 200 個就足夠了)。增加通過計數可確保 GPU 保持活動狀態足夠長的時間以達到其最大時鐘速率。從分析作中省略非計算作會進一步使 GPU 飽和,因為 SM作不會與內存副本交錯。
從命令行進行分析
Nsight 包括一個輕量級命令行 TensorRT 分析器,適用于非交互式用例。從 Nsight 設計器 GUI 進行交互式分析后,可以將其復制到遠程目標的部署目錄。ndld-prof
可以使用該選項查看分析器接受的命令行參數的完整詳細信息。使用命令行分析器時,支持“Profile TensorRT Model”活動界面中的所有選項。--help
使用命令行探查器時,無需保存完整的分析報告。探查器將在 stdout 上顯示性能會審信息。
分析報告
Nsight 使用通用報告格式來存儲來自 ONNX Runtime 和 TensorRT 的分析數據。可以使用 “file">“ open file”命令重新打開現有分析報告。分析 TensorRT 模型 和分析 ONNX 模型 活動將在分析運行成功后自動打開新的分析器報告。
分析報告描述了所選推理框架執行的 ONNX 模型的執行,該框架通常指網絡的運行時優化版本。ONNX 模型中的節點組可以融合到單個優化層中,而其他節點可能會在優化過程中完全刪除。
分析報告有四個主要部分, 包括 ONNX Runtime 和 TensorRT 分析器之間的任何差異。
)







)





--PromptPilot (助手)答問之1)
 using `TU/lmr/m/n‘ instead)
ZLG CAN卡驅動封裝應用)
 算法超參數 多項式時間 樸素貝葉斯分類算法)

