最近項目需要優化一下目標檢測網絡,在這個過程中發現還是得增加對框架底層的掌握才可行。于是準備對pytorch的一些基本概念做一些再理解。參考PyTorch的wiki,對自己的學習過程做個記錄。
Tensors 是一種特殊的數據結構,與數組和矩陣非常相似。在PyTorch中,我們使用張量對模型的輸入、輸出以及模型參數進行編碼。
張量類似于 NumPy 的 ndarray,不同之處在于張量可以在 GPU 或其他硬件加速器上運行。事實上,張量和 NumPy 數組通常可以共享相同的底層內存,從而無需復制數據。張量還針對自動求導進行了優化。如果你熟悉 ndarray,那么使用張量 API 會得心應手。如果不熟悉,也別擔心,跟著學就行!
import torch
import numpy as np
一、怎么初始化 Tensors
張量可以通過多種方式初始化。
1.直接從數據中獲取
張量可以直接從數據創建。數據類型會自動推斷。
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)
2.從NumPy數組
張量可以從NumPy數組創建:
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
3.從另一個張量:
新的張量將保留參數張量的屬性(形狀、數據類型),除非被顯式覆蓋。
x_ones = torch.ones_like(x_data) # retains the properties of x_data
print(f"Ones Tensor: \n {x_ones} \n")x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data
print(f"Random Tensor: \n {x_rand} \n")
4.使用隨機值或常數值:
shape 是張量維度的元組。在以下函數中,它決定了輸出張量的維度。
shape = (2,3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")
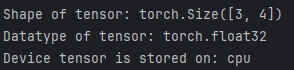
二、張量的屬性
張量屬性描述了它們的形狀、數據類型以及存儲它們的設備。
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")
三、張量運算
這里全面介紹了1200多種張量運算,包括算術運算、線性代數、矩陣操作(轉置、索引、切片)、采樣等等。
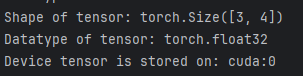
這些操作中的每一項都可以在CPU和加速器(如CUDA、MPS、MTIA或XPU)上運行。
默認情況下,張量是在CPU上創建的。我們需要使用.to方法(在檢查加速器可用性之后)顯式地將張量移動到加速器上。wiki提醒,跨設備復制大張量在時間和內存方面的開銷可能很大!
# We move our tensor to the current accelerator if available
if torch.accelerator.is_available():tensor = tensor.to(torch.accelerator.current_accelerator())
嘗試列表中的一些操作。如果你熟悉NumPy API,那么使用Tensor API對你來說將輕而易舉。
標準的類似numpy的索引和切片操作:
tensor = torch.ones(4, 4)
print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
tensor[:,1] = 0
print(tensor)
拼接張量 你可以使用 torch.cat 沿著給定維度拼接一系列張量。另請參閱 torch.stack,這是另一個與 torch.cat 略有不同的張量拼接操作符
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)
算術運算
# This computes the matrix multiplication between two tensors. y1, y2, y3 will have the same value
# ``tensor.T`` returns the transpose of a tensor
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)y3 = torch.rand_like(y1)
torch.matmul(tensor, tensor.T, out=y3)# This computes the element-wise product. z1, z2, z3 will have the same value
z1 = tensor * tensor
z2 = tensor.mul(tensor)z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
單元素張量 如果你有一個單元素張量,例如通過將張量的所有值聚合為一個值,你可以使用 item() 將其轉換為Python數值:
agg = tensor.sum()
agg_item = agg.item()
print(agg_item, type(agg_item))
原地操作將結果存儲到操作數中的操作稱為原地操作。它們以 _ 后綴表示。例如:x.copy_(y)、x.t_() 會改變 x。
print(f"{tensor} \n")
tensor.add_(5)
print(tensor)
就地操作節省了一些內存,但在計算導數時可能會出現問題,因為會立即丟失歷史信息。因此,不建議使用它們。節省了一些內存,但在計算導數時可能會出現問題,因為會立即丟失歷史信息。因此,不建議使用它們。
四、與NumPy的橋接
CPU 上的張量和 NumPy 數組可以共享它們的底層內存位置,改變其中一個也會改變另一個。
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy()
print(f"n: {n}")
張量的變化會反映在NumPy數組中。
t.add_(1)
print(f"t: {t}")
print(f"n: {n}")
NumPy數組轉換為張量
n = np.ones(5)
t = torch.from_numpy(n)
NumPy數組中的變化會反映在張量中。
張量轉換為NumPy數組
這是YOLO12推理時,將后端可視化的操作。將Tensor格式的檢測結果,從gpu取到cpu上,轉為numpy數組。

再使用opencv的函數進行檢測結果可視化(檢測框繪制和標簽繪制)。
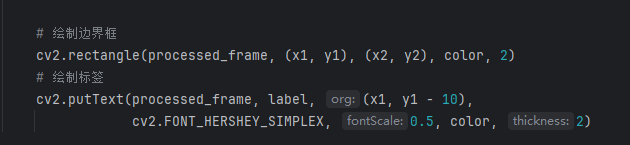
最終的結果如下圖:

0->b 講解)
)





)


![[激光原理與應用-225]:機械 - 3D圖與2D圖各自的作用](http://pic.xiahunao.cn/[激光原理與應用-225]:機械 - 3D圖與2D圖各自的作用)
)
![UVa12345 Dynamic len(set(a[L:R]))](http://pic.xiahunao.cn/UVa12345 Dynamic len(set(a[L:R])))
![[Ubuntu] VNC連接Linux云服務器 | 實現GNOME圖形化](http://pic.xiahunao.cn/[Ubuntu] VNC連接Linux云服務器 | 實現GNOME圖形化)

![[激光原理與應用-241]:設計 - 266n皮秒深紫外激光器,哪些因素影響激光器紫外光的輸出功率?](http://pic.xiahunao.cn/[激光原理與應用-241]:設計 - 266n皮秒深紫外激光器,哪些因素影響激光器紫外光的輸出功率?)



