一、堆排序 (借助樹)
1.利用完全二叉樹構建大頂堆
2.堆頂元素和堆底元素進行交換,堆底元素不再參與構建,剩余元素繼續構建大頂堆3.時間復雜度??O(nlogn)
1.完全二叉樹:按照從上到下,從左到右的順序進行排序

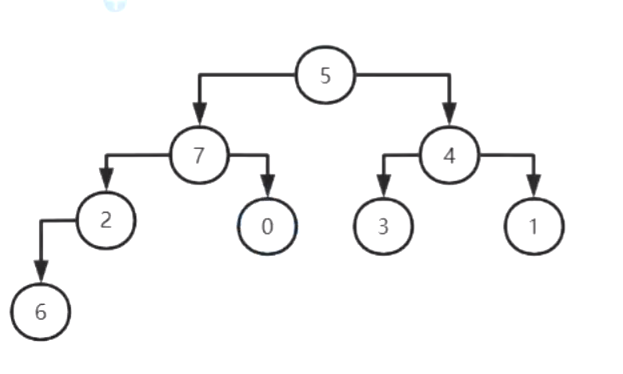
2.大頂堆: 任何一個節點值大于等于左右孩子,根節點一定是最大值
arr[i]的左孩子 arr[2i+1] ? ? ? ? ? 要求條件: arr[i]>= arr[2i+1]&&
?arr[i]的右孩子 arr[2i-2] ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?arr[i]>=arr[2i-2]
3.構建大頂堆:
第一大步:
1. 從后往前對每個數據依次進行檢測調整
2. 定義 parent 游標指向要檢測的節點
3. 定義 parent 的左孩子,判斷 child 是否為空(有孩子一定會有左孩子)
4. 如果 child 為空,則 parent 符合大頂堆
5. 如果 child 不為空,判斷 parent 有沒有右孩子,child 指向左右孩子的最大值。
6. 父子節點進行比較,如果父節點的值大,則符合大頂堆,繼續向前檢測。
7. 如果父節點的值小,則不符合大頂堆,父子節點進行交換。
8. parent 指向 child, child 指向左右孩子的最大值。直到 child 為空或者父節點的值大。
第二大步:
?1.只有堆頂變了,只維護堆頂就可以,做到堆頂最大
package com.pcby.demo;//堆排序
import java.util.Arrays;
/*1.利用完全二叉樹構建大頂堆* 2.堆頂元素和堆底元素進行交換,堆底元素不再參與構建,剩余元素繼續構建大頂堆*/public class HeapSort {public static void main(String[] args) {int[] arr= {5,7,4,2,0,3,1,6};sort(arr);System.out.println(Arrays.toString(arr));}// 排序public static void sort(int[] arr){// 第一大步for (int i = arr.length - 1; i >= 0; i--) {adjust(arr, i, arr.length);}// 第二大步for (int i = arr.length - 1; i >= 0; i--) {int temp = arr[0];arr[0] = arr[i];arr[i] = temp;adjust(arr, 0, i);}}// 維護public static void adjust(int[] arr, int parent, int length) {int child = 2 * parent + 1;while (child < length) {// 定義右孩子int rchild = child + 1;if (rchild < length && arr[rchild] > arr[child]) {child++;} // child 指向了左右孩子的最大值// 父子節點進行比較,父節點要大if (arr[parent] < arr[child]) {// 父子節點進行交換int temp = arr[parent];arr[parent] = arr[child];arr[child] = temp;// 父節點指向 child, child 指向左右孩子最大值parent = child;child = 2 * child + 1;} else {break;}}}
}每一步思路:
1. 定義數組并調用排序函數:
在 ?main ?方法中,定義一個數組 ?arr ,其元素為 ?{5,7,4,2,0,3,1,6} 。
調用 ?sort ?方法對數組進行堆排序。
輸出排序后的數組。
2. 排序方法(sort 方法):
第一大步(構建初始大頂堆):
從數組的最后一個元素開始,逐個向前調整,確保每個父節點都大于其子節點。
調用 ?adjust ?方法對每個元素進行調整。
第二大步(排序過程):
將堆頂元素(最大值)與堆底元素交換,使最大值位于數組末尾。
堆的大小減 1(通過調整 ?length ?參數實現),對剩余元素重新調整為大頂堆。
重復上述交換和調整過程,直到堆的大小為 1。
3. 調整堆結構(adjust 方法):
初始化父節點和左孩子節點的位置。
在循環中,檢查右孩子節點是否存在且是否大于左孩子節點,將 ?child ?指向左右孩子中較大的那個。
如果父節點小于當前 ?child ?節點,交換它們的位置。
更新父節點和孩子節點的位置,繼續調整子樹,直到父節點大于等于孩子節點或孩子節點超出堆的范圍。
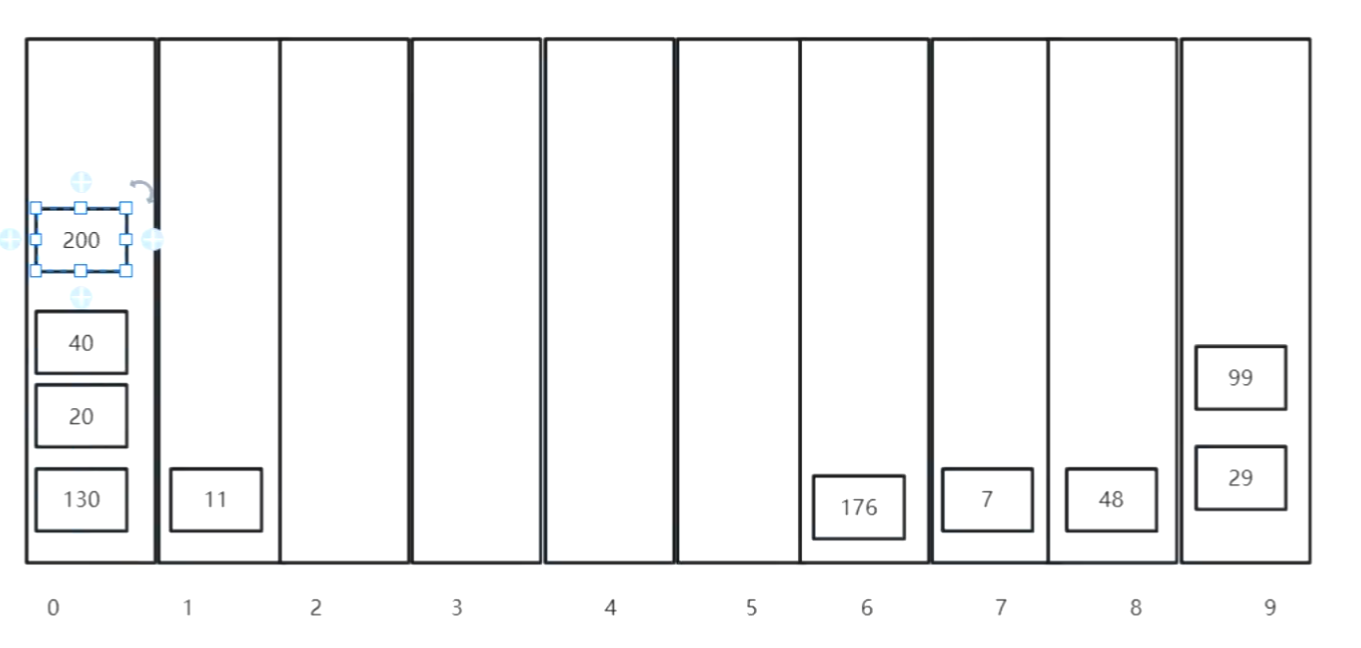
?二、基數排序(借助桶)
不能排負值,先排序個位,十位,百位
1.先建立0-9九個桶
2.看各個數字個位數都是多少,是多少放在哪個桶里
3.放好后從0號桶開始取數字,取出來,在排序十位,同理排序百位
package com.pcby.demo;import java.util.Arrays;public class Radix {public static void main(String[] args) {int[] arr = {5,14,20,125,362,61,94,4,12,1002,54,99,87,89};sort(arr);System.out.println(Arrays.toString(arr));}public static void sort(int[] arr) {// 找最大值int max = arr[0];for (int i = 0; i < arr.length; i++) {if (arr[i] > max) {max = arr[i];}}// 最大值的位數int len = (max + "").length();// 聲明 0-9 十個桶int[][] bucket = new int[10][arr.length];// 桶記錄工具int[] elementCount = new int[10];int n = 1;// 循環放入取出for (int num = 0; num < len; num++) {// 放入for (int i = 0; i < arr.length; i++) {// 放到哪個桶 余數int element = arr[i] / n % 10;int count = elementCount[element];bucket[element][count] = arr[i];// 桶記錄 +1elementCount[element]++;}// 取出int index = 0;for (int i = 0; i < elementCount.length; i++) {if (elementCount[i] > 0) {for (int j = 0; j < elementCount[i]; j++) {arr[index] = bucket[i][j];index++;}elementCount[i] = 0;}}n = n * 10;}}
}三、快速排序
待排序數組的第一個作為基準數;
定義游標 j 從后往前,找比基準數小的值,找到后停下;
定義游標 i 從前往后,找比基準數大的值,找到后停下;
i j 指向的數據交換 j 繼續找比基準數小的,i 繼續找比基準數大的,直到 i j 相遇 基準數和相遇位置交換,基準數到達正確位置;
以基準數為起始點,拆分成左右兩部分,重復上述所有,直到數據獨立
時間復雜度: O(n log n)
import java.util.Arrays;public class QuickSort {public static void main(String[] args) {int[] arr = {5, 7, 4, 2, 0, 3, 1, 6};sort(arr, 0, arr.length - 1);System.out.println(Arrays.toString(arr));}public static void sort(int[] arr, int left, int right) {if (left >= right) {return;}int base = arr[left];int j = right;int i = left;while (i != j) {while (arr[j] >= base && i != j) {j--;}while (arr[i] <= base && i != j) {i++;}int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}arr[left] = arr[i];arr[i] = base;sort(arr, left, i - 1);sort(arr, i + 1, right);}
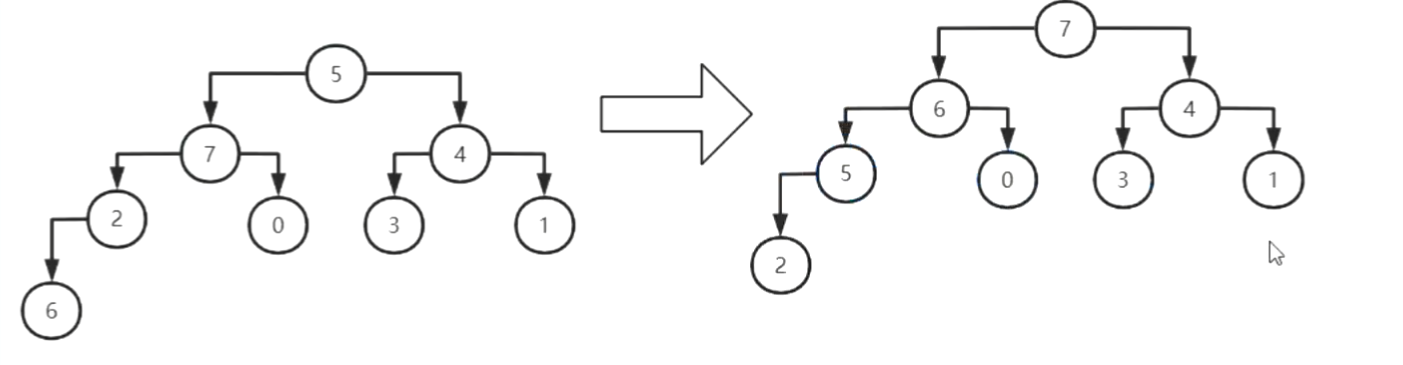
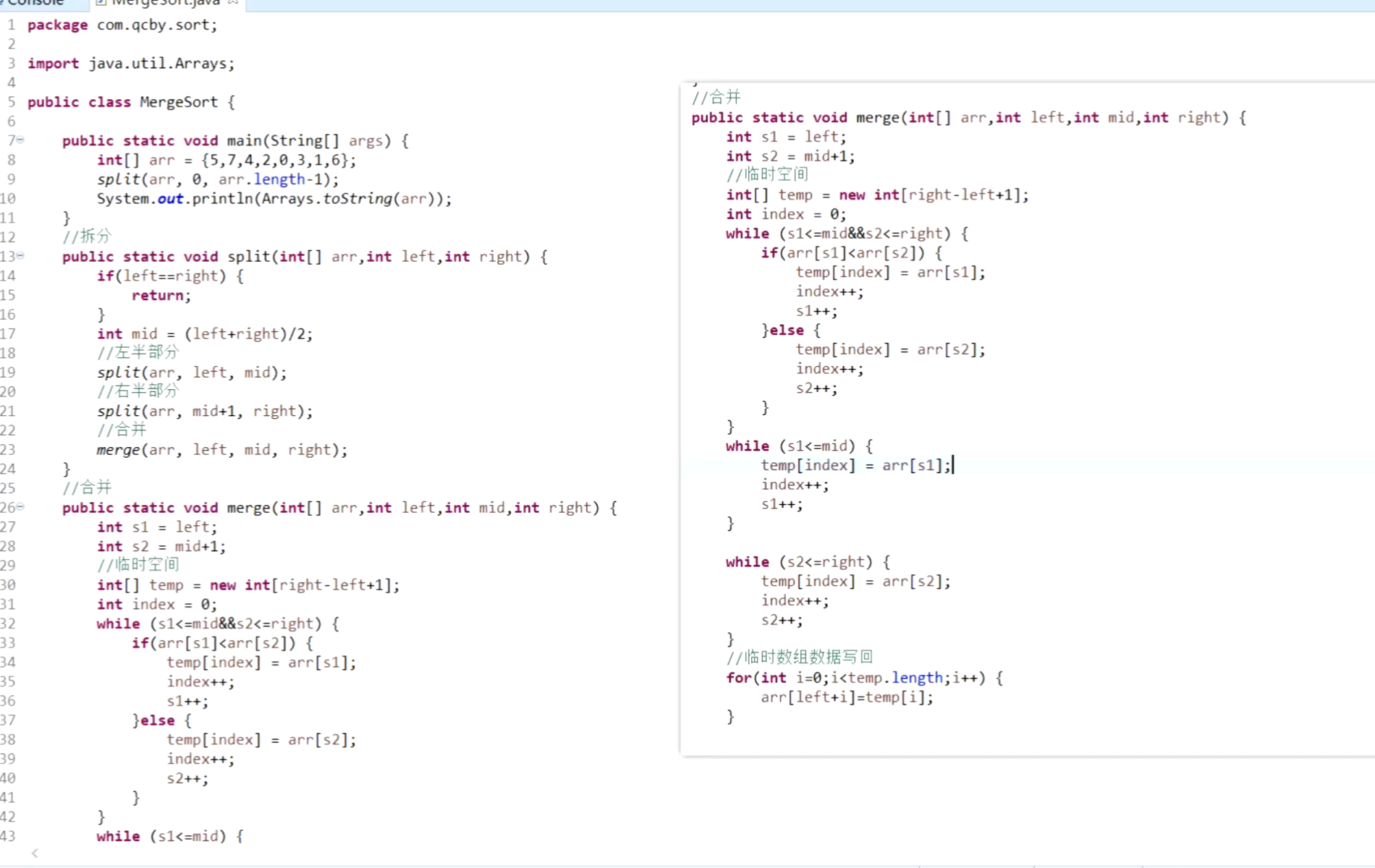
}四、歸并排序
即將數組不斷拆分為小數組,對小數組進行排序后再合并成大數組。先拆分再合并,在合并的過程中通過臨時空間進行排序。
空間復雜度:O(n)
?
package com.qcbj.sort;
import java.util.Arrays;public class MergeSort {public static void main(String[] args) {int[] arr = {5, 7, 4, 2, 0, 3, 1, 6};split(arr, 0, arr.length - 1);System.out.println(Arrays.toString(arr));}public static void split(int[] arr, int left, int right) {if (left == right) {return;}int mid = (left + right) / 2;split(arr, left, mid);split(arr, mid + 1, right);merge(arr, left, mid, right);}public static void merge(int[] arr, int left, int mid, int right) {int s1 = left;int s2 = mid + 1;int[] temp = new int[right - left + 1];int index = 0;while (s1 <= mid && s2 <= right) {if (arr[s1] <= arr[s2]) {temp[index] = arr[s1];index++;s1++;} else {temp[index] = arr[s2];index++;s2++;}}while (s1 <= mid) {temp[index] = arr[s1];index++;s1++;}while (s2 <= right) {temp[index] = arr[s2];index++;s2++;}for (int i = 0; i < temp.length; i++) {arr[left + i] = temp[i];}}
}?












的學習)



)


FatFs文件系統(SPI驅動W25Qxx))