案例:鳶尾花數據集的聚類
一.聚類簡介
神經網絡能夠從輸入數據中自動提取有意義的特征,而競爭學習規則使得單層神經網絡能夠根據相似度將輸入樣本進行聚類,每個聚類由一個輸出神經元代表并作為該類別的“原型”,從而實現對輸入模式的無監督分類與結構發現。
二.案例研究(Iris植物聚類)
i.問題陳述:
針對無法明確將數據集劃分為三種鳶尾花類別的問題,設定目標為構建一個能夠自主學習并完成聚類任務的智能無監督人工神經網絡(ANN),選用競爭型神經網絡(Competitive ANN)作為模型,并采用競爭學習(Competitive Learning)算法,使網絡能夠根據輸入特征自動發現數據的內在類別結構并完成分類。
ii.數據集描述:
本實驗數據集包含 150 個樣本,分屬 Setosa、Versicolor 和 Virginica 三種鳶尾花類別,每個樣本由 4 個連續型特征描述,分別為萼片長度(4.3–7.9 cm)、萼片寬度(2.0–4.4 cm)、花瓣長度(1.0–6.9 cm)和花瓣寬度(0.1–2.5 cm),這些特征在數值范圍和單位上存在差異,因此在模型訓練前需進行歸一化處理,以確保特征在聚類中的貢獻均衡。
iii.測試理解問題:
本任務屬于聚類應用,數據集規模為 150 個樣本在 3 個類別上的共 450 條特征記錄,每個樣本包含 4 個變量(萼片長度、萼片寬度、花瓣長度、花瓣寬度),目標是將其劃分為 Setosa、Versicolor 和 Virginica 三類,通過無監督聚類方法發現不同鳶尾花品種在特征空間中的分布規律與相似性結構。
三、核心概念與流程
1.數據準備
? ? ? i.數據歸一化
歐幾里得距離對特征數值范圍非常敏感,如果某個特征的取值范圍較大,就會在距離計算中占據主導地位,掩蓋其他特征的作用;同時,不同特征可能存在不同的單位和量綱(如 cm、kg、秒),直接比較不公平。通過歸一化,可以將所有特征轉換到同一尺度(通常是 0 到 1 的比例數據),使它們在相似度計算中權重均衡,并加快模型的訓練收斂速度。
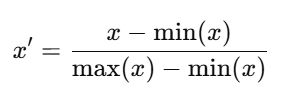
? ? ? ii.數據劃分(DATA PREPARATION)
在實驗中,將 150 個樣本隨機劃分為訓練集和測試集,例如可分為訓練集 100 個、測試集 50 個,或按 70:30、80:20 等比例進行分配,以便用于模型訓練和效果評估。
2.網絡結構(Iris 示例)
在該競爭學習網絡中,輸入層神經元數量等于特征數,即 4 個節點分別對應萼片長度、萼片寬度、花瓣長度和花瓣寬度;輸出層神經元數量等于期望的聚類簇數,本例設置為 3 個神經元分別代表三種鳶尾花類別;權重矩陣的維度為 4×3,即每個輸出神經元都關聯一個 4 維權重向量,用于表征該類別在特征空間中的“原型”位置,并在訓練過程中不斷調整以貼近該簇樣本的特征分布。
3.初始化
訓練初期將網絡權重初始化為較小的隨機值(如在 [0,1] 區間或依據輸入特征范圍生成),并在訓練過程中定期記錄權重變化,例如比較初始權重、迭代 100 次后的權重以及 2000 次后的權重,以觀察網絡收斂過程和權重逐步貼近各類別特征分布的趨勢。
4.激活與匹配(找 Winner)
使用 歐氏距離(Euclidean distance) 作為匹配準則:對每個輸出單元 j計算, 選擇距離最小者作為勝出神經元(BMU)。
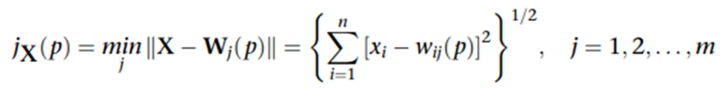
5.權重更新
對勝出神經元的權重按下式更新:
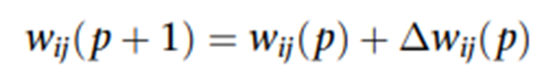
?
α是學習率,控制更新幅度;Λj(p)是鄰域函數;
6.重復訓練直至收斂
由于無監督學習中沒有可直接監控的標簽誤差,本例采用歐氏距離準則或“權重變化不再顯著”作為收斂判據,即當權重向量在多次迭代后變化幅度極小即可視為收斂。
7.簇標注(Labelling 輸出神經元)
在無監督聚類中,輸出單元本身沒有預設類標簽,因此常用的方法是在訓練完成后利用帶標簽的測試集進行“投票”標注,即統計每個輸出單元在測試集中最常贏得的真實類別,將該單元標記為該類別,從而實現輸出神經元與具體類別的對應關系。
)


















