在實際的數據庫遷移工作中,異構庫之間的遷移常常被視為一項“高風險、高工作量、高復雜度”的挑戰任務。這不僅是一次數據庫切換,更是對系統穩定性、數據一致性、業務連續性和技術團隊耐力的全方位考驗。
為解決企業在異構數據庫遷移中的痛點,NineData 數據復制功能現已支持 SQL Server > MySQL 的結構、全量和增量同步鏈路,幫助企業以更低風險、更少投入、更短停機時間,完成數據庫系統的平滑遷移與實時同步。
1. SQL Server > MySQL 遷移有多難?
- 語法與結構不兼容: SQL Server 與 MySQL 在語法、數據類型、約束定義等方面存在諸多差異,手動遷移不僅耗時耗力,出錯率也高,遷移后的系統常因兼容性問題反復踩坑。
- 數據量大遷移緩慢: 企業數據庫通常有數千萬甚至上億條數據,全量導出導入耗時長、易中斷,不具備恢復機制,一旦失敗,遷移進度將被嚴重拖慢。
- 增量同步機制缺失: 傳統遷移方案多數無法處理實時變更,尤其是長周期運行場景中,源庫與目標庫的數據一致性難以保障。
- 業務中斷風險高: 很多企業業務系統依賴 SQL Server,無法接受長時間停機或遷移期間數據丟失。
2. NineData 如何解決這些痛點?
NineData 在數據復制引擎層面深度優化,專為異構數據庫之間的數據遷移與實時同步場景而設計:
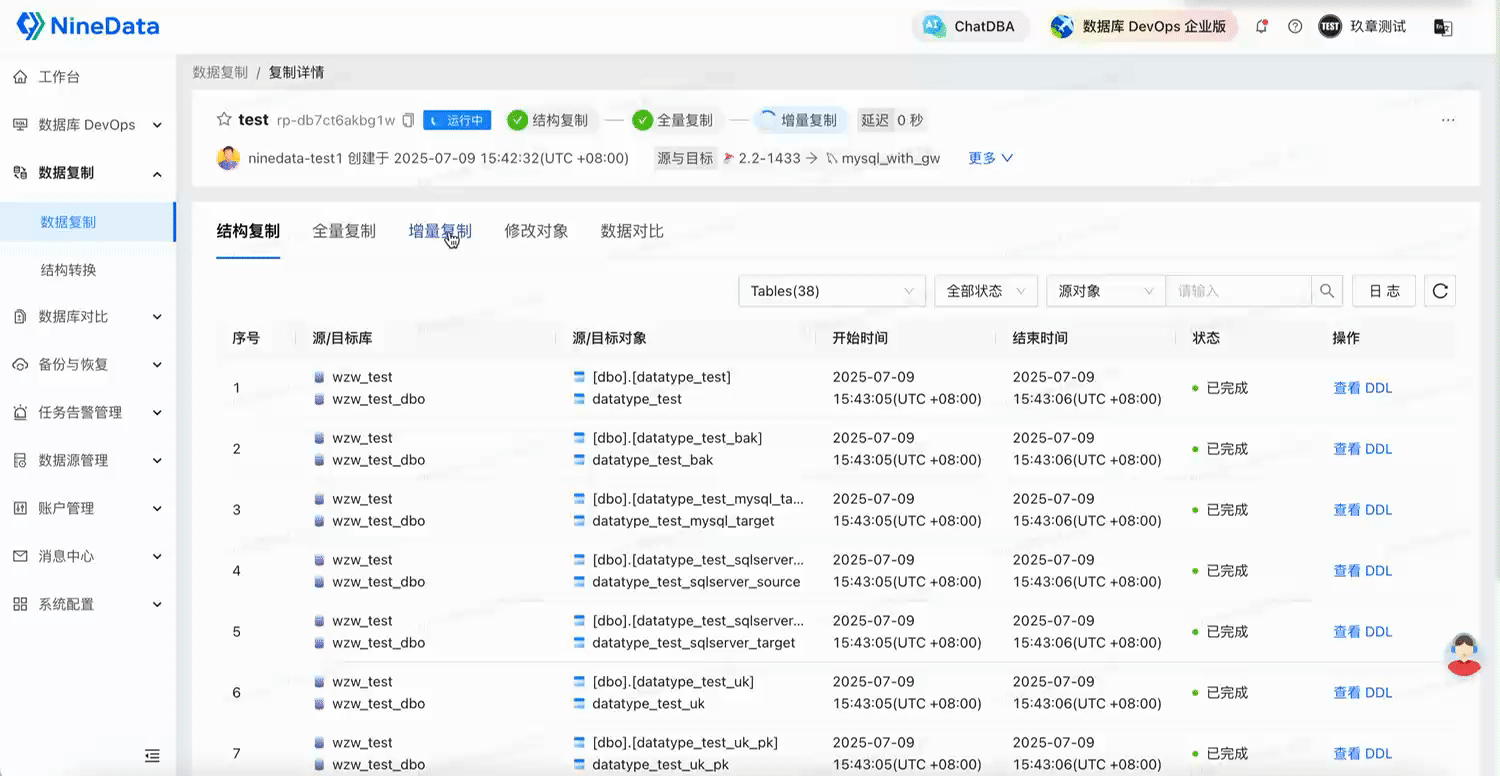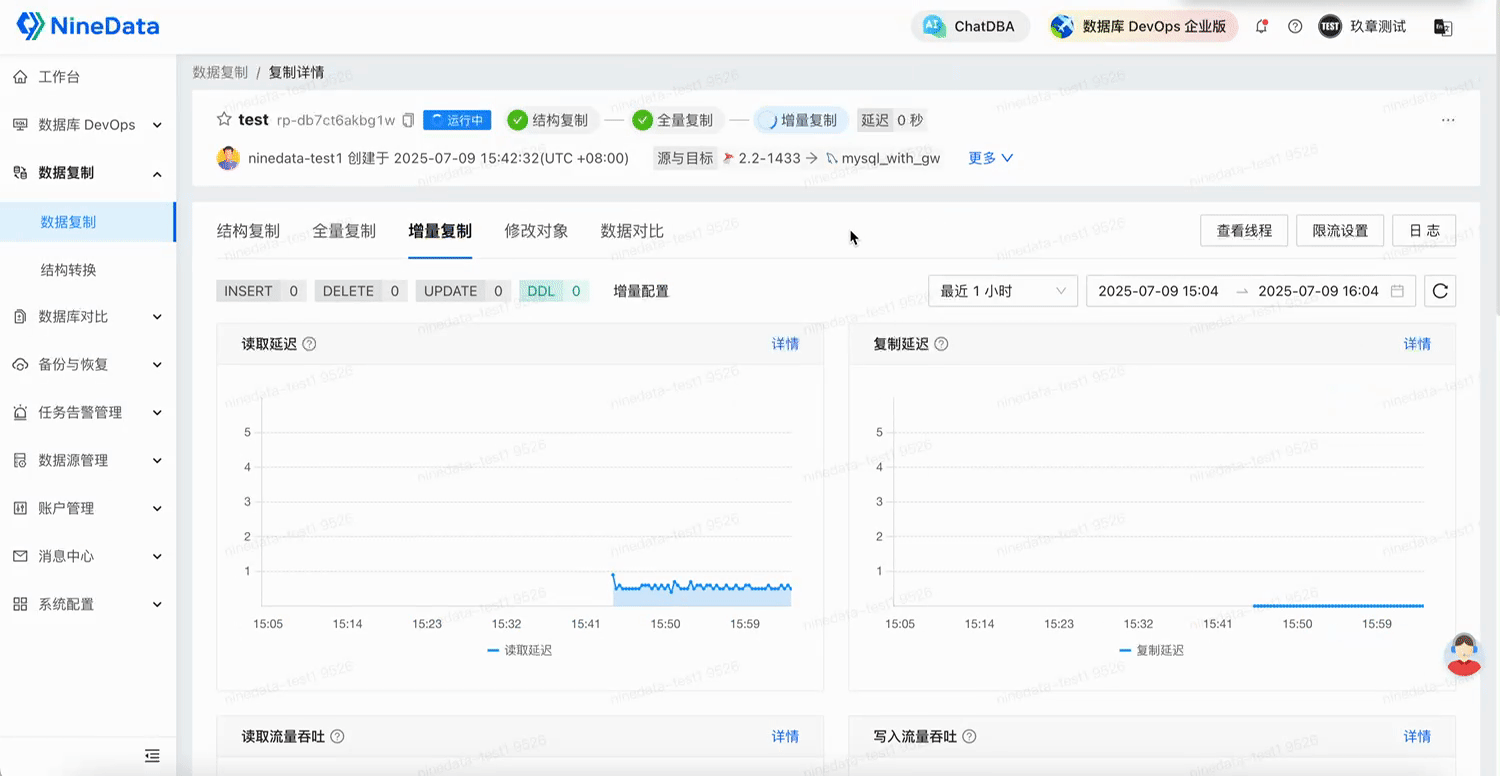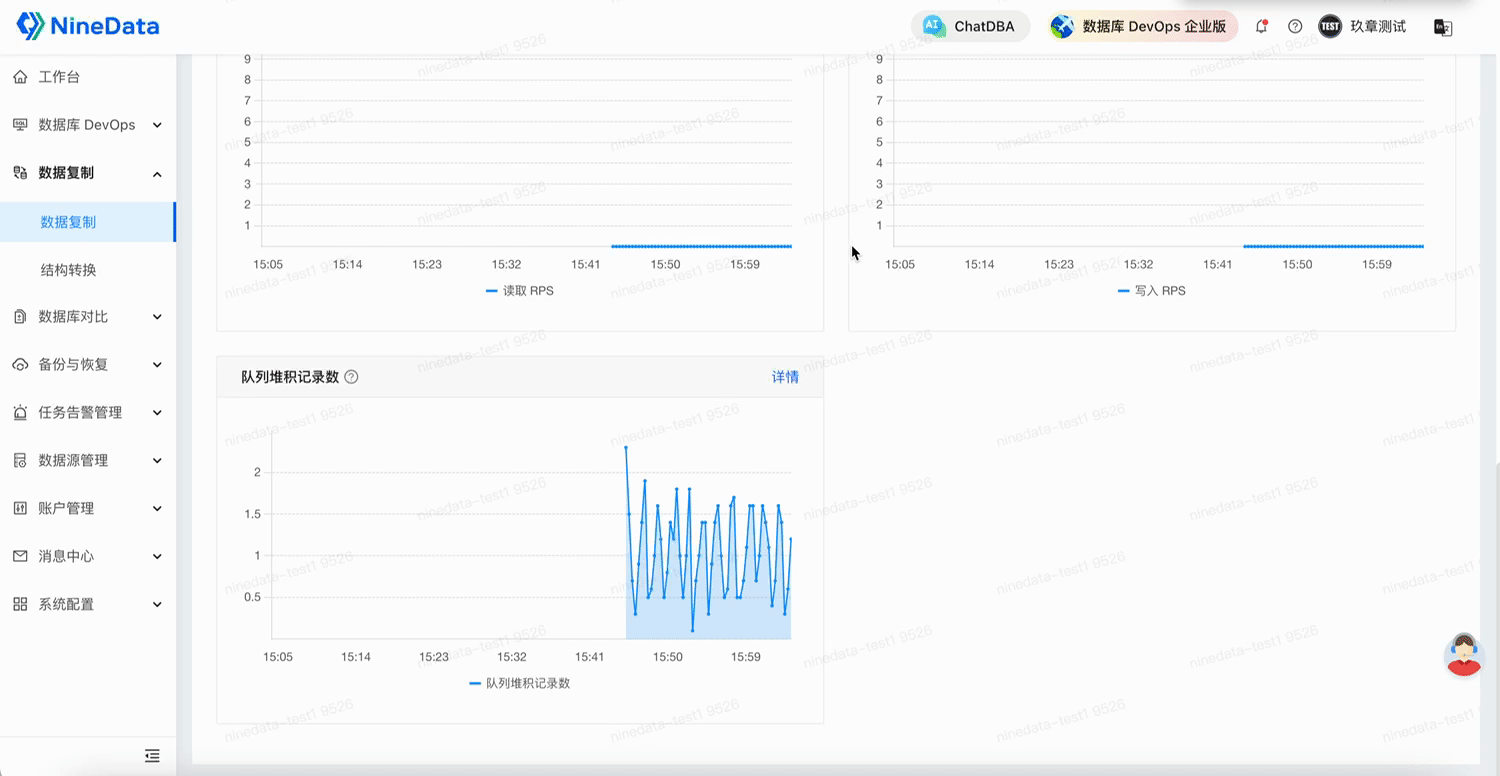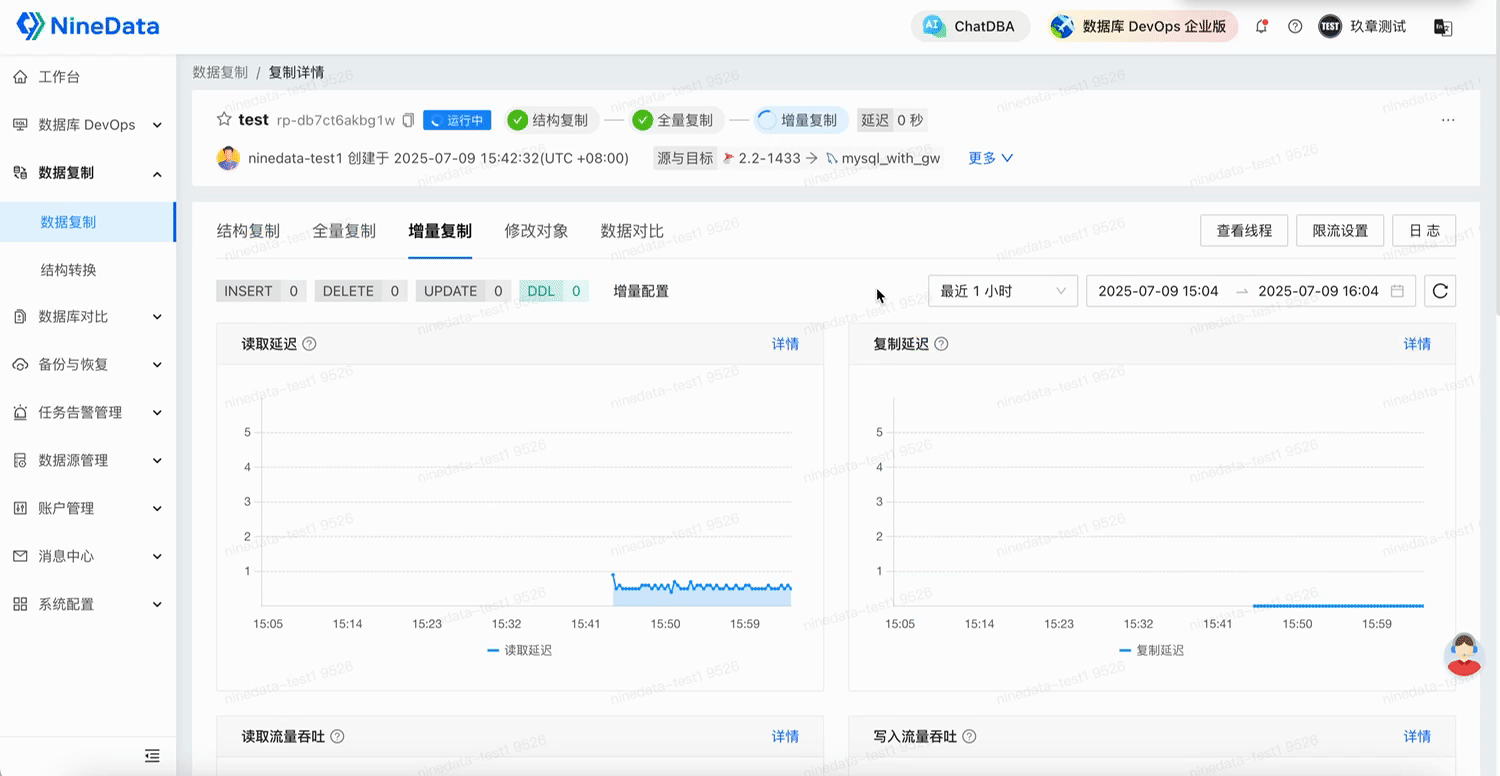
2.1 表結構復制:自動識別字段、索引、外鍵,遷移更輕松
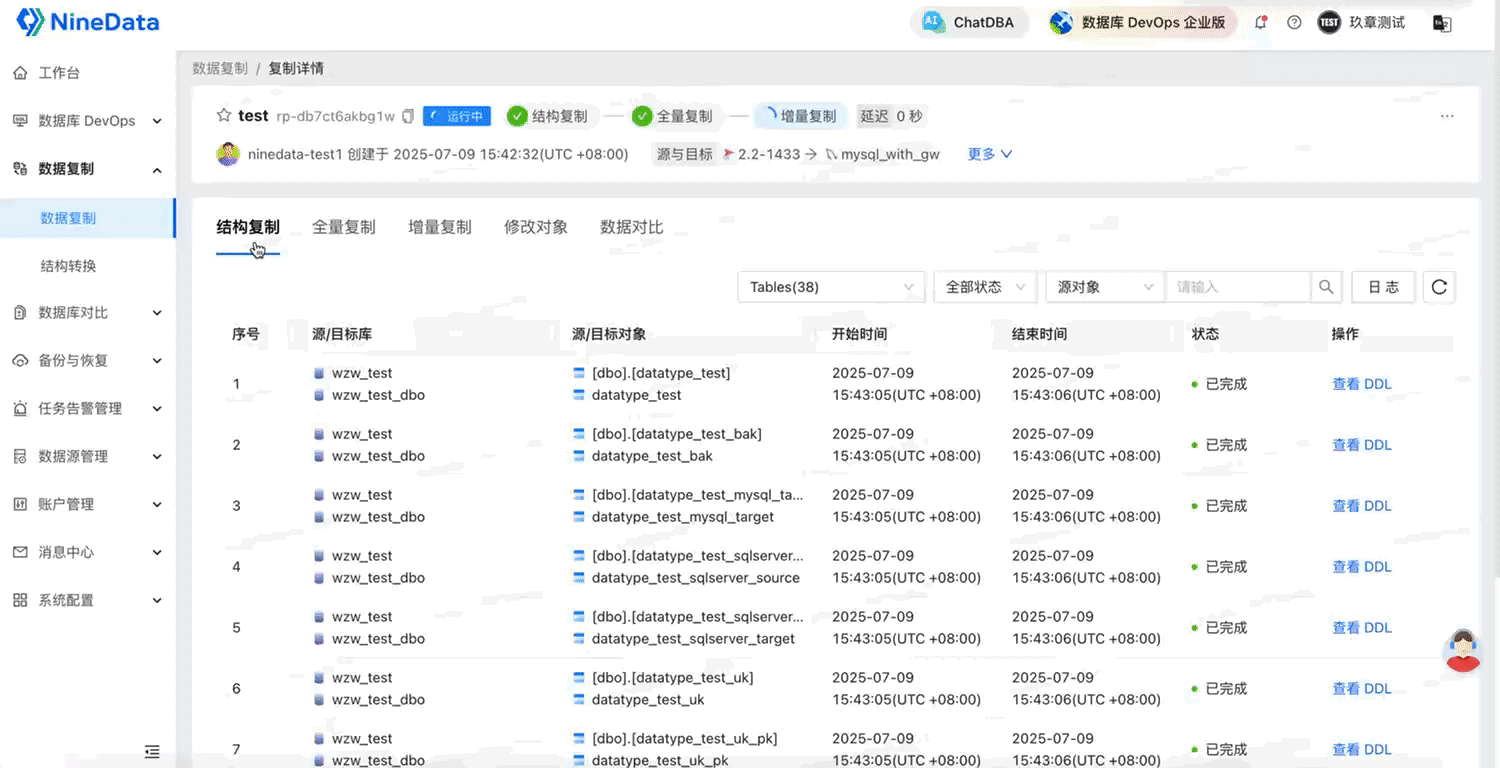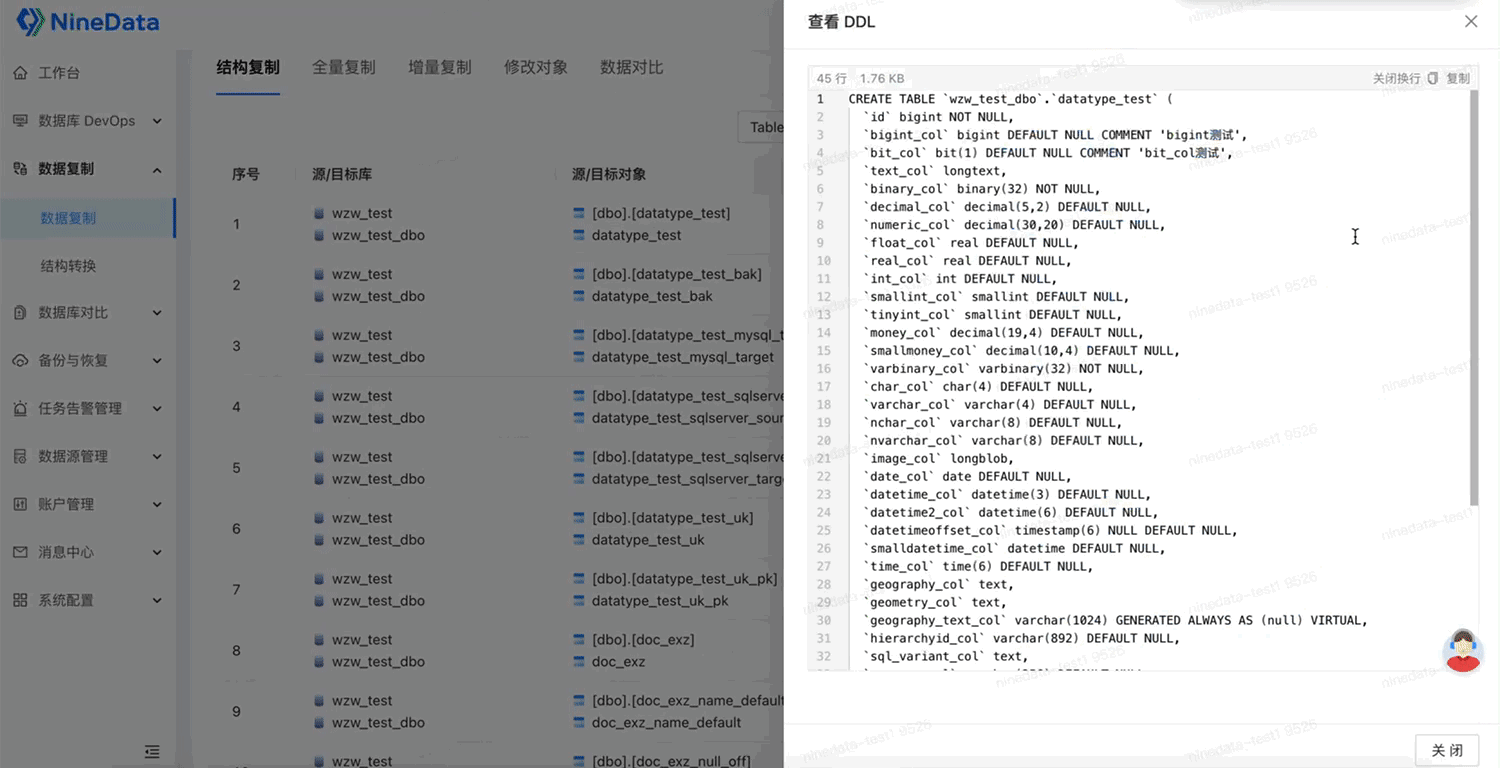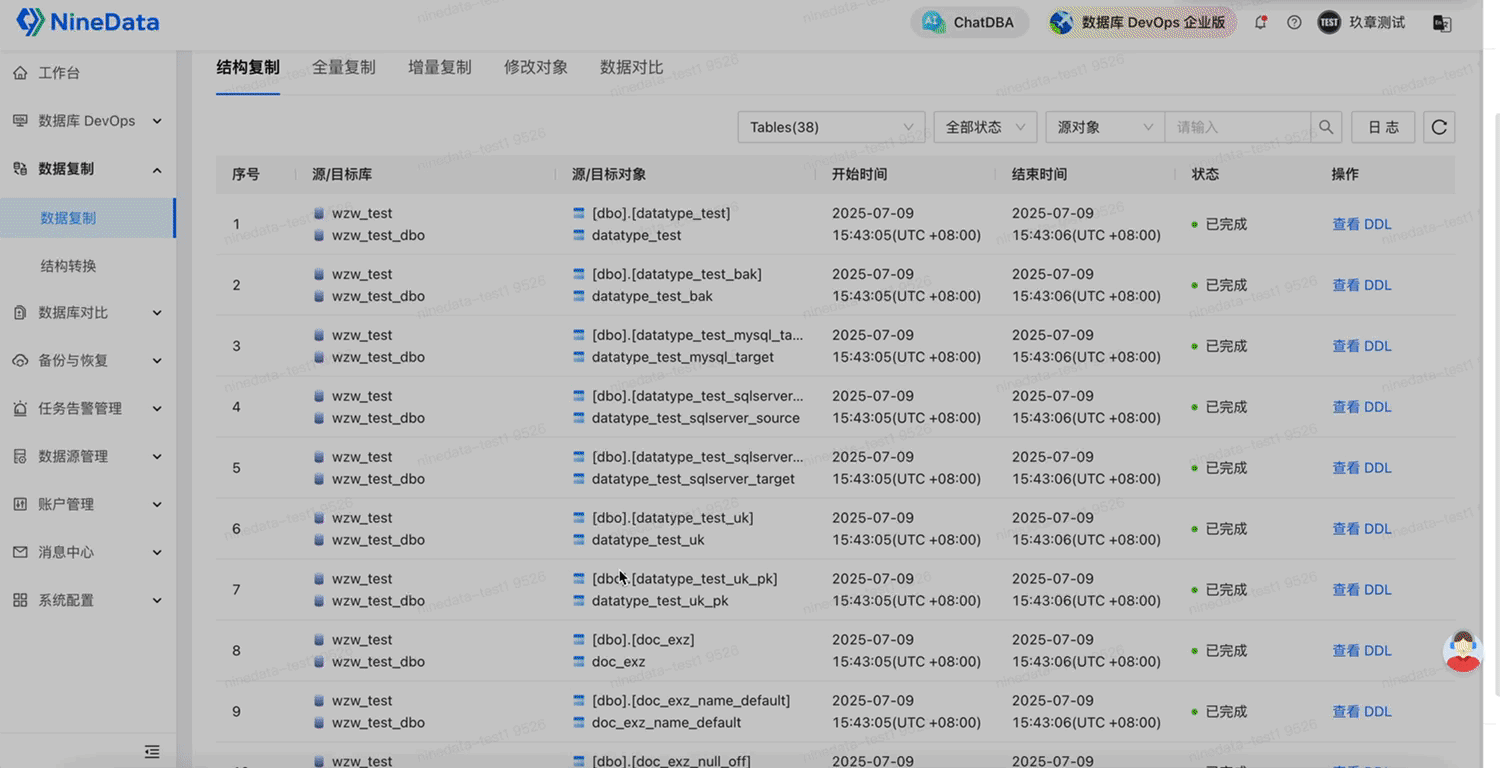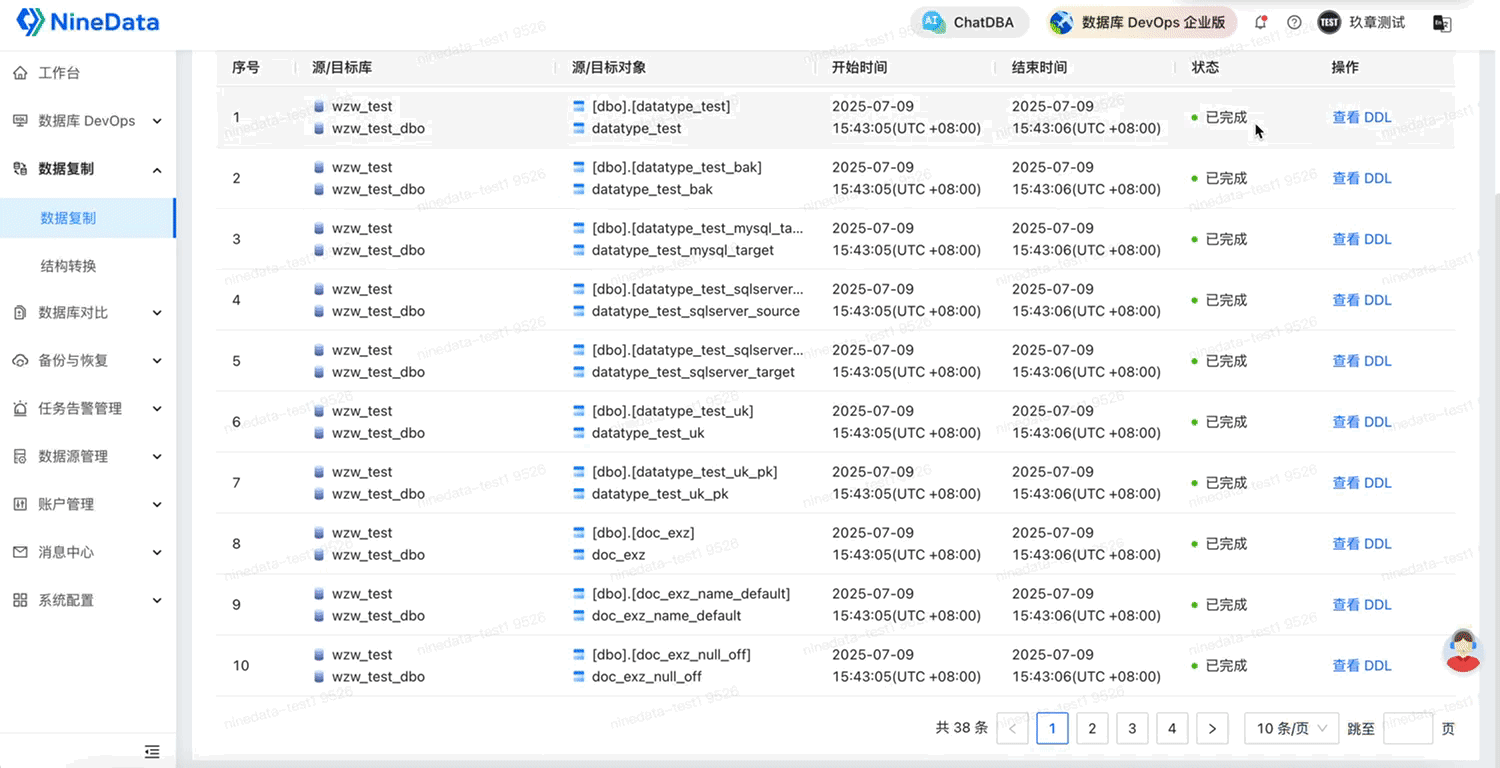
NineData 當前支持的結構復制,聚焦在最關鍵的對象類型:表。并不僅僅是建表語句的搬運,而是:
- 自動識別表字段、主鍵、唯一鍵、普通索引、外鍵等結構信息。
- 自動完成字段類型的映射與轉換。
- 支持表名、字段名的映射。
- 避免手動建表、手動改字段,遷移過程更加結構化、自動化。
2.2 全量復制穩定高效,超大表/字段無壓力
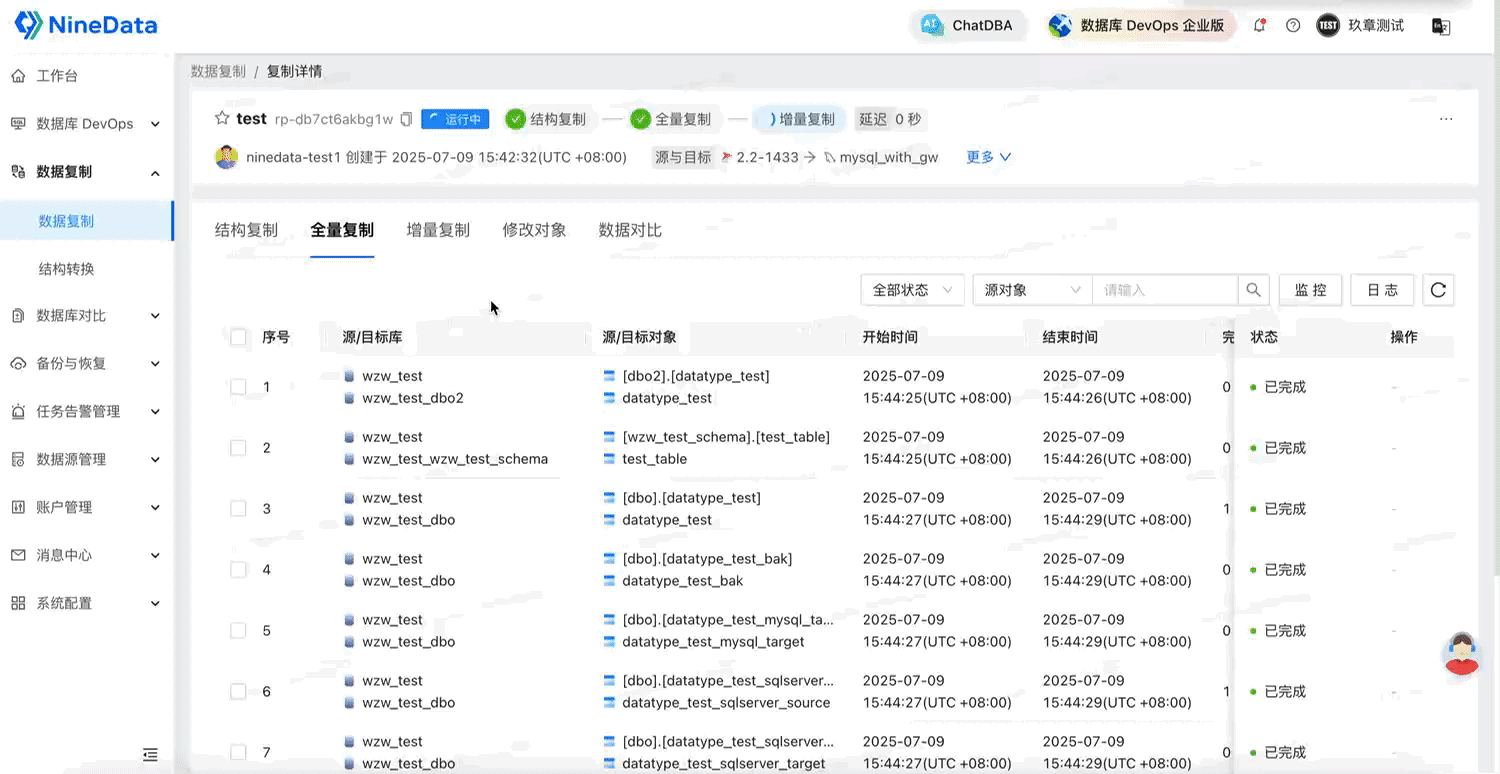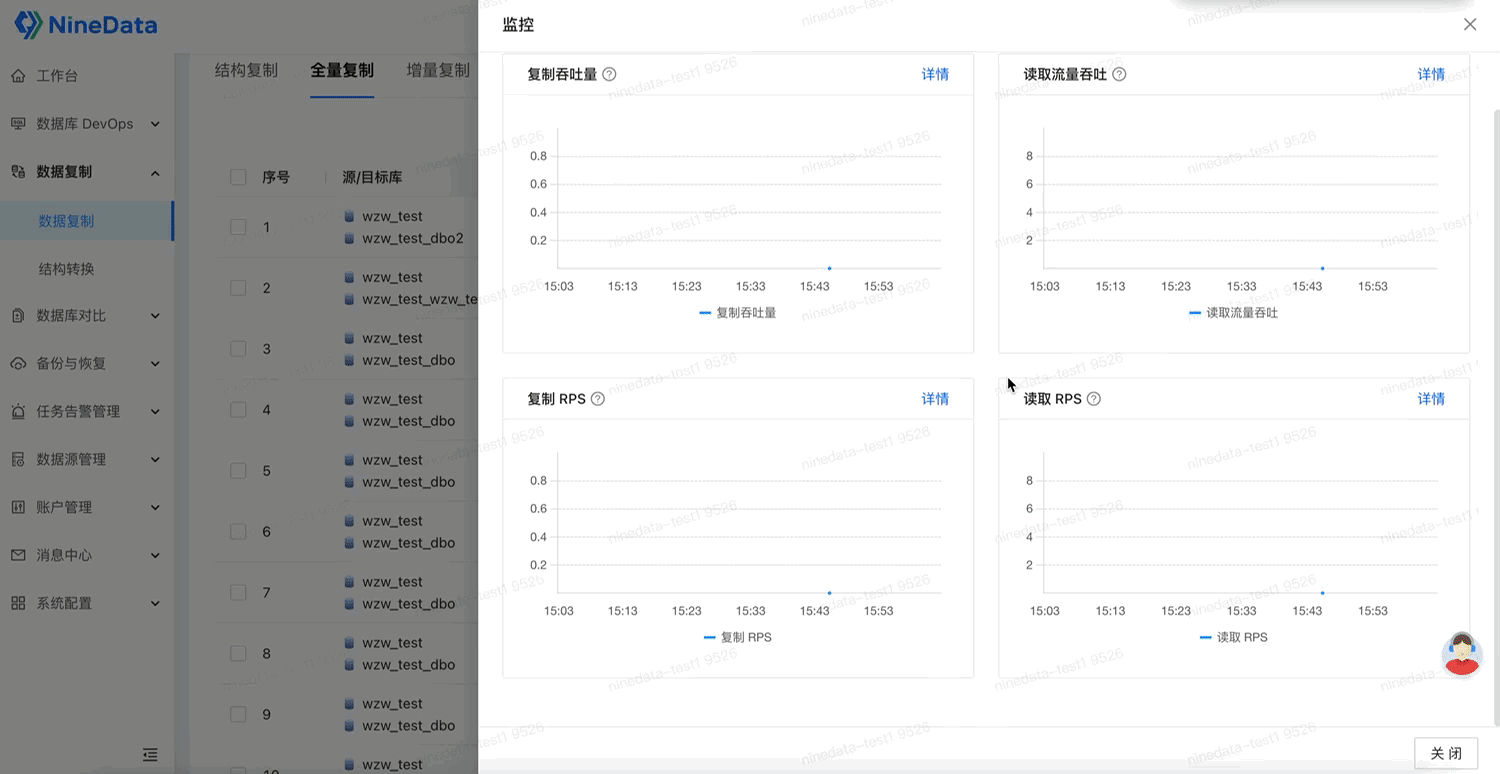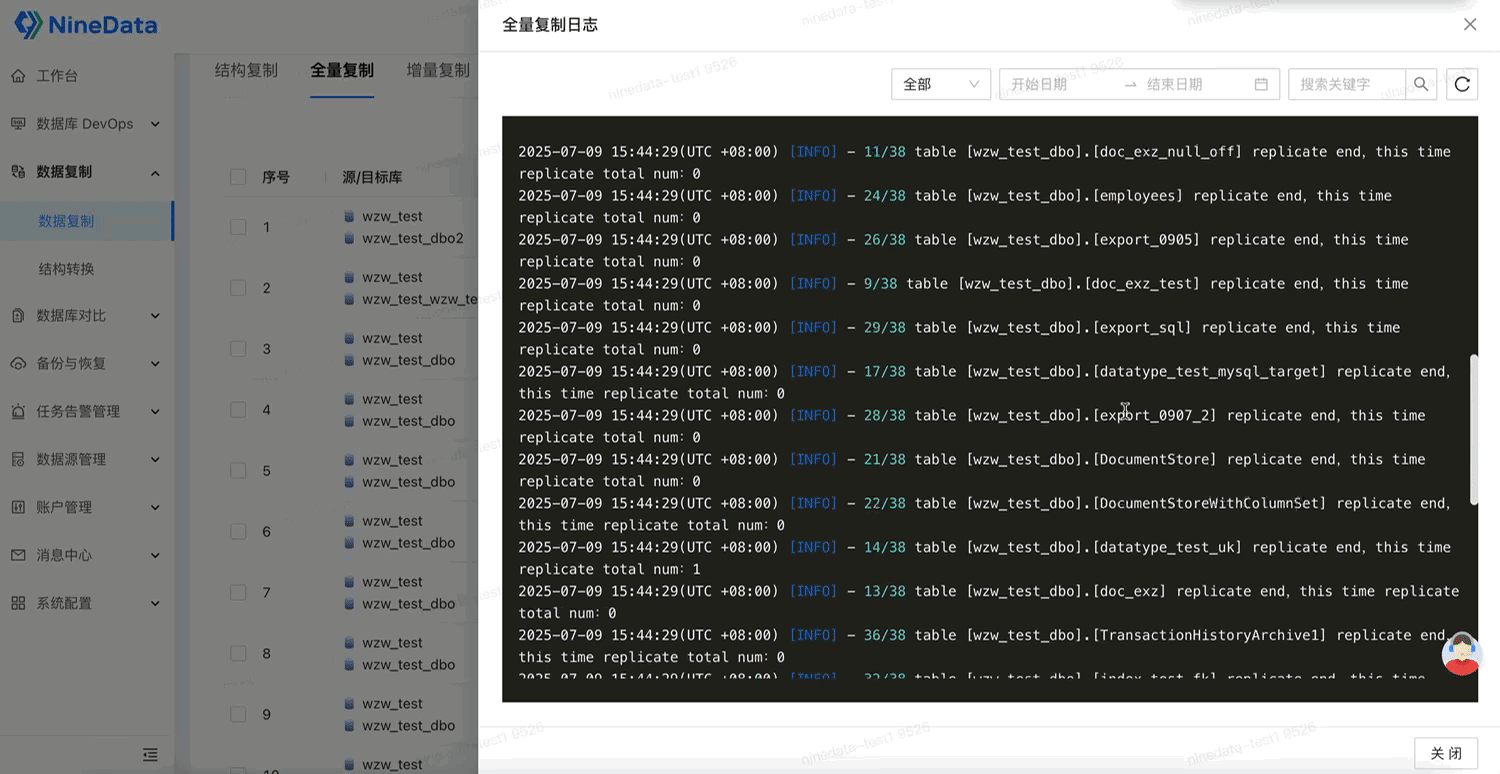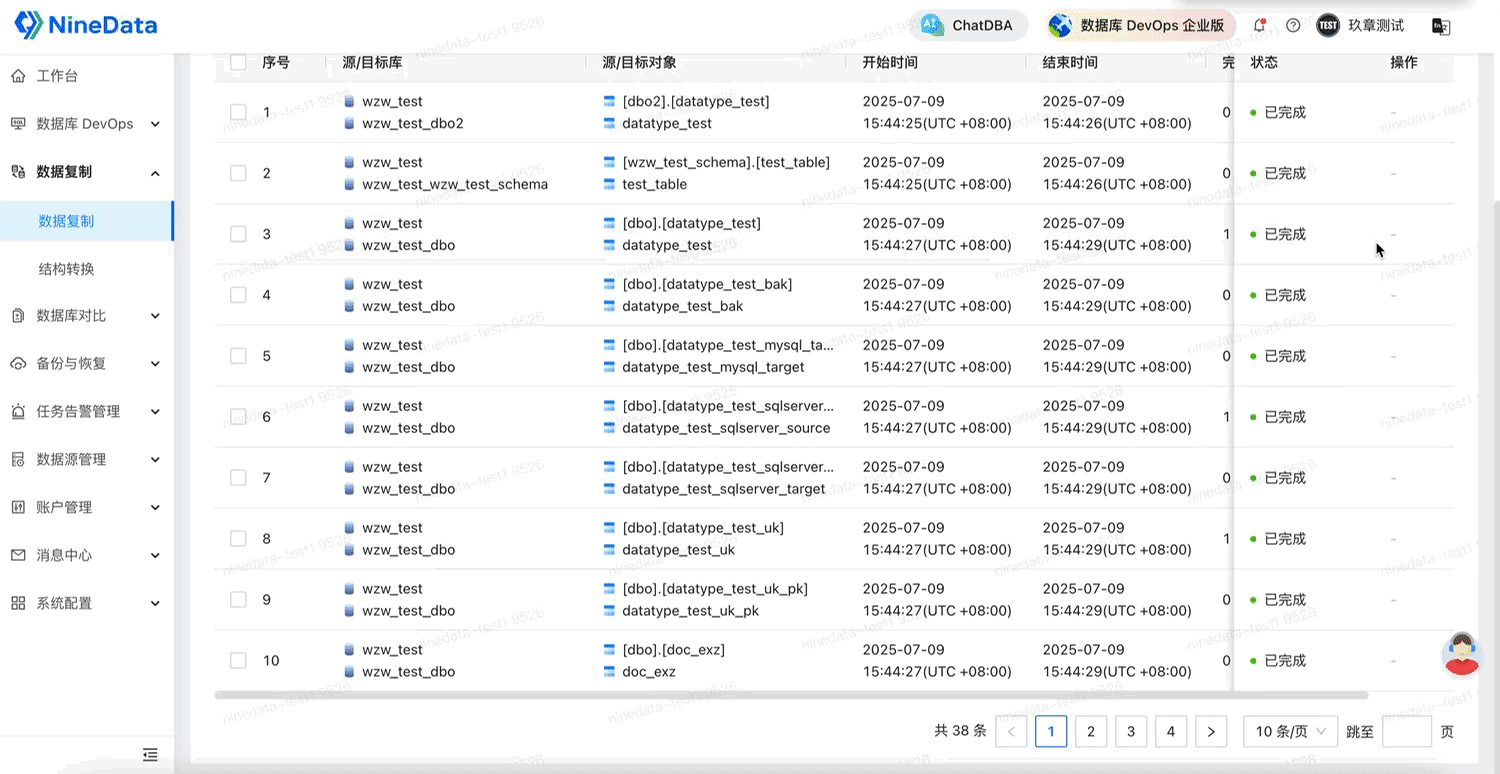
在全量復制場景中,NineData 經過實際測試驗證,具備以下能力:
- 支持億級大表遷移:單表數據超 1 億條記錄,復制過程穩定,性能表現優異;
- 支持超大字段遷移:單行數據記錄超過 20MB 無異常;
- 全面支持所有主流數據類型:數值、日期時間、字符串、二進制、空間類型等均驗證通過;
- 支持字符集、時區、中文、表情等特殊字符內容同步;
- 索引完整性同步:單列、多列主鍵/唯一鍵,普通索引等均已驗證支持。
2.3 增量復制:CDC 實時捕獲,數據同步秒級延遲
NineData 基于 SQL Server 的 CDC(Change Data Capture)機制,全面支持:
- DML 操作同步:INSERT、UPDATE、DELETE 全覆蓋;
- DDL 兼容性測試中:常見 CREATE、ALTER、TRUNCATE 等操作已部分支持(個別指令仍在修復中,如 TRUNCATE、RENAME);
- 復雜數據類型與大事務同步:已驗證支持含復雜結構的數據更新,以及單事務 10 萬行級別變更;
- 斷點續傳與容災能力:測試通過,遷移過程具備斷點恢復機制,避免單點失敗帶來數據不一致風險;
- 支持全字符集、表情、特殊字符、跨時區等場景下的增量同步。
2.4 數據對比校驗:確保遷移后目標庫數據 100% 一致
NineData 提供內置數據比對機制,自動對源庫與目標庫數據進行一致性校驗:
- 精確對比每一條記錄。
- 自動識別字段精度差異、缺失記錄、值不一致等問題。
- 生成可視化比對報告,支持差異數據導出與修復。
- 適配大表、高并發下的安全比對,確保數據質量和準確性。
3. 企業應用場景舉例
- 替換高昂授權成本的 SQL Server,切換至開源 MySQL 方案。
- 實現 SQL Server 數據同步至 MySQL 數據倉庫用于分析查詢。
- 推動企業 IT 架構朝異構、多源系統演進,實現技術棧多樣化與靈活部署。
4. 總結
通過此次 SQL Server > MySQL 復制鏈路的上線,NineData 不僅擴展了異構數據庫支持邊界,更為企業提供了一套 “零腳本、低停機、可控風險” 的標準化遷移路徑。




)




--文件管理系統 ubuntu22.04)
)








