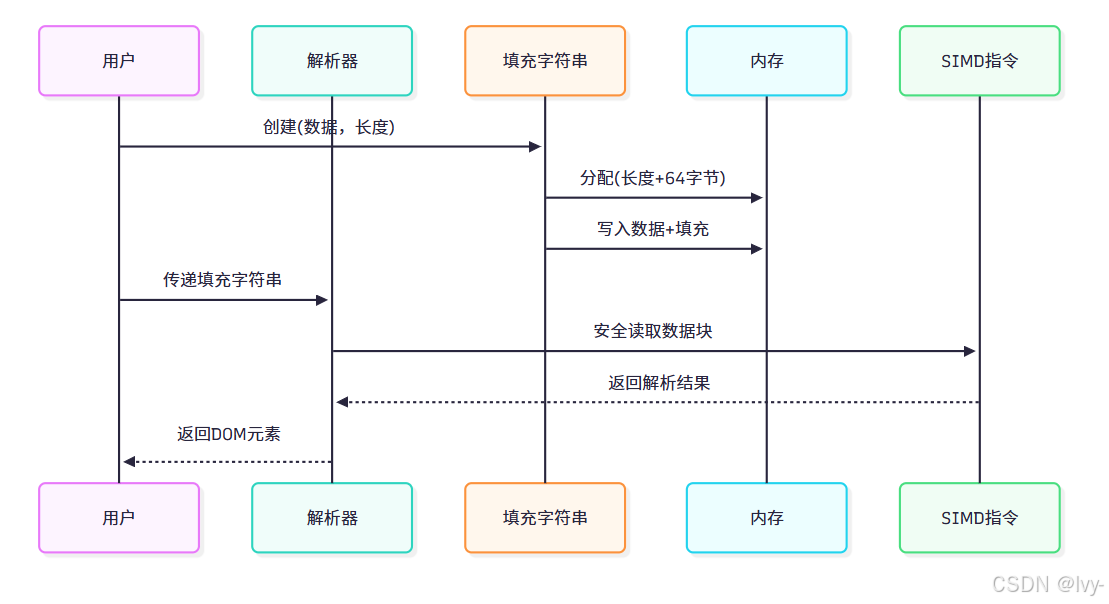
第二章:填充字符串
在第一章解析器中,我們學習了simdjson::dom::parser和simdjson::ondemand::parser作為可復用內存的JSON解析工具。
本章將深入解析JSON數據輸入的核心要求——“填充字符串”。
為何需要填充?
simdjson通過SIMD(單指令多數據)指令實現高性能解析。
這些指令要求以固定字節塊(如32或64字節)處理數據,可能越界訪問內存。
若JSON數據位于內存末尾且未預留空間,將導致段錯誤。
為此,simdjson要求輸入數據必須包含SIMDJSON_PADDING(默認為64字節)的填充空間。
// 來自include/simdjson/base.h
/*** JSON解析所需的填充字節數*/
constexpr size_t SIMDJSON_PADDING = 64;
例如:100字節的JSON數據需要至少164字節的緩沖區,前100字節存儲數據,后64字節為填充(通常置零)。
填充數據管理
simdjson提供兩種核心類型處理填充:
1. simdjson::padded_string
內存自主管理型,保證數據尾部包含填充空間。創建時會自動分配新緩沖區并復制數據。
#include <simdjson.h>int main() {// 從C風格字符串創建const char* json_cstr = "{\"name\":\"simdjson\"}";simdjson::padded_string s1(json_cstr, strlen(json_cstr));// 從std::string創建std::string json_std = "{\"count\":42}";simdjson::padded_string s2(json_std);// 使用_padded字面量(推薦)auto s3 = R"({"active":true})"_padded;// 數據訪問std::cout << "數據長度:" << s3.size() << std::endl; // 實際JSON長度return 0;
}
注意:
size()返回原始數據長度(不含填充)- 屬于移動語義類型,不可復制
_padded字面量簡化創建過程
2. simdjson::padded_string_view
非擁有型視圖,適用于已有填充緩沖區的情況。需開發者保證緩沖區有效性。
#include <simdjson.h>
#include <vector>int main() {// 手動創建填充緩沖區std::string source = "{\"value\":99}";std::vector<char> buffer(source.size() + SIMDJSON_PADDING, 0);memcpy(buffer.data(), source.data(), source.size());// 創建視圖simdjson::padded_string_view view(buffer.data(), source.size(), buffer.size());// 使用pad()工具處理std::stringstd::string dynamic_str = "{\"id\":123}";auto padded_view = simdjson::pad(dynamic_str); // 修改原字符串容量// 解析示例simdjson::dom::parser parser;auto doc = parser.parse(view);return 0;
}
注意:
pad()會修改原字符串,追加空格至滿足填充要求- 必須確保底層緩沖區在視圖使用期間有效
解析器集成
兩種類型均可直接用于解析方法:
// DOM解析示例
simdjson::dom::parser parser;
auto json = R"({"key":"value"})"_padded;
auto result = parser.parse(json);// On-Demand解析(強制要求填充)
simdjson::ondemand::parser ondemand_parser;
auto doc = ondemand_parser.iterate(json);
內存模型
類型對比指南
| 特性 | padded_string | padded_string_view |
|---|---|---|
| 內存所有權 | 自主管理 | 依賴外部緩沖區 |
| 填充保證 | 自動創建 | 需預先存在 |
| 適用場景 | 新數據創建 | 已有緩沖區復用 |
| 性能影響 | 可能內存拷貝 | 零拷貝 |
| 易用性 | 高(推薦新手) | 中(需內存管理經驗) |
核心要點
- 安全第一:SIMD指令越界訪問可能引發段錯誤,填充是必須的
- 性能權衡:padded_string簡化開發但可能
內存拷貝,padded_string_view適合高性能場景 - 生命周期管理:解析結果依賴原始緩沖區,需確保數據持續有效
- 工具鏈整合:
_padded字面量和pad()函數提升開發效率
掌握填充字符串機制是使用simdjson的關鍵下一步,我們將在第三章文檔結構中學習如何訪問解析后的數據。
下一章:文檔結構
第三章:文檔(Document)
在前幾章中,我們學習了用于解析 JSON 的核心工具:解析器(Parser),以及如何通過填充字符串(Padded String)格式準備 JSON 數據以實現安全快速處理。
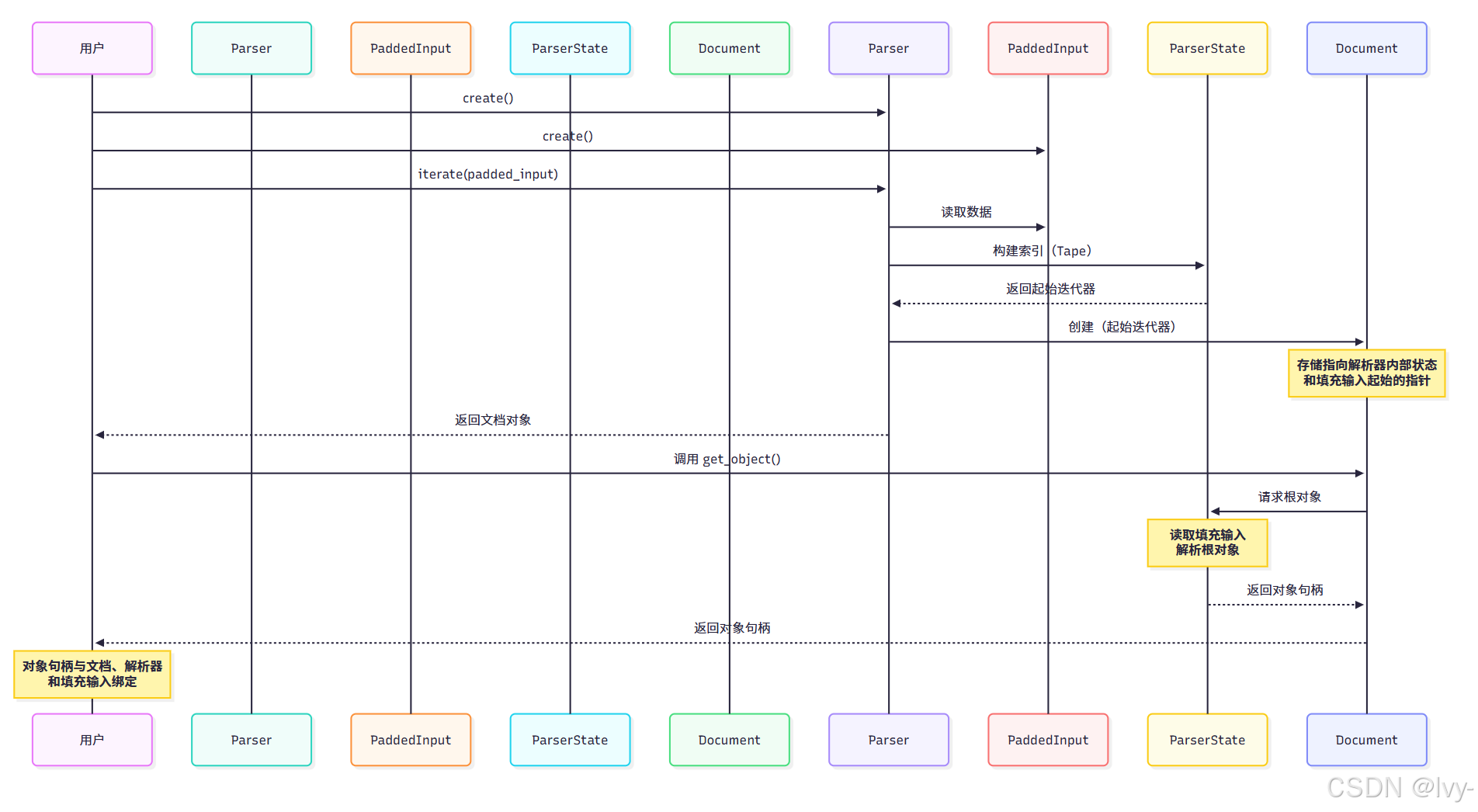
現在我們已經準備好解析器并將 JSON 數據放入填充字符串中,執行解析操作會得到什么?在按需(On-Demand)API 中,這就是 simdjson::ondemand::document 的用武之地。
可以將 document 對象視為初始解析步驟(iterate 調用)的結果。
這是探索所提供 JSON 數據的入口點。
什么是按需模式中的文檔?
與可能立即在內存中構建完整 JSON 文檔樹結構的傳統 JSON 解析器不同,simdjson 按需 API 采用了不同的方法。
當調用 parser.iterate(padded_string) 時,我們得到的是 simdjson::ondemand::document 對象。
這個
document并非整個 JSON 的完全解析表示,而更像是定位在 JSON 數據起始位置的智能迭代器或游標。它持有導航 JSON 結構和按需解析值所需的必要信息。
-
想象你的 JSON 數據是裝滿嵌套在盒子和袋子里的物品的大型寶箱。
document不是寶箱內所有內容的描述,而是打開寶箱的鑰匙和指示第一個主容器(JSON 根值)位置的地圖。 -
我們使用這張地圖(
document的方法)找到第一個容器,然后通過進一步指令打開它并發現內部物品,僅在需要時挖掘寶物。
這種"按需挖掘"的特性使得按需 API 內存效率極高,尤其適用于只需少量數據的大型 JSON 文件。
獲取第一個文檔
讓我們回顧前幾章的簡單示例,重點觀察獲得的 document 對象:
#include <simdjson.h>
#include <iostream>int main() {// 1. 創建解析器實例(我們的工具)simdjson::ondemand::parser parser;// 2. 準備填充字符串格式的 JSON 數據(我們的原材料)// 按需模式需要填充輸入simdjson::padded_string json_data = R"({"message": "hello world", "status": true})"_padded;// 3. 使用解析器"遍歷"填充數據// 返回需要檢查錯誤的結果對象simdjson::simdjson_result<simdjson::ondemand::document> result = parser.iterate(json_data);// 4. 檢查遍歷步驟是否成功if (result.error()) {std::cerr << "解析初始化失敗: " << result.error() << std::endl;return EXIT_FAILURE;}// 5. 從結果中獲取文檔對象simdjson::ondemand::document doc = std::move(result.value()); // 使用 std::move 提高效率std::cout << "成功獲取文檔對象!" << std::endl;// 現在'doc'是我們進入 JSON 的入口// 實際上還未真正*解析*內容,只是設置了迭代器return EXIT_SUCCESS;
}
代碼解析:
parser.iterate(json_data)是關鍵函數調用,接收包含 JSON 的填充字符串- 返回
simdjson::simdjson_result<simdjson::ondemand::document>,這是 simdjson 處理潛在錯誤的方式 - 檢查
result.error()確保文檔迭代器設置成功,此步驟包括快速掃描 JSON 的基本結構有效性并構建內部索引(有時稱為"tape") - 成功時通過
std::move(result.value())獲取simdjson::ondemand::document對象
獲得 doc 對象后,我們即可開始用它訪問 JSON 數據。
探索文檔根節點
document 對象表示 JSON 結構的根節點。JSON 文檔的根可以是任意有效 JSON 值:對象 {}、數組 []、字符串 "abc"、數值 123、布爾值 true 或 null。
document 提供以下方法判斷根值類型:
doc.type():返回根 JSON 值的類型(如json_type::object,json_type::array等)doc.get_object():嘗試以 JSON 對象形式訪問根節點doc.get_array():嘗試以 JSON 數組形式訪問根節點doc.get_string(),doc.get_int64(),doc.get_double(),doc.get_bool(),doc.is_null():嘗試以標量值形式訪問根節點
當調用這些 get_...() 方法時,simdjson 才會真正執行根節點的解析。讓我們擴展示例來檢查類型并訪問根對象:
#include <simdjson.h>
#include <iostream>int main() {simdjson::ondemand::parser parser;simdjson::padded_string json_data = R"({"message": "hello world", "status": true})"_padded;simdjson::simdjson_result<simdjson::ondemand::document> result = parser.iterate(json_data);if (result.error()) {std::cerr << "解析初始化失敗: " << result.error() << std::endl;return EXIT_FAILURE;}simdjson::ondemand::document doc = std::move(result.value());// 6. 檢查文檔根節點類型simdjson::simdjson_result<simdjson::ondemand::json_type> root_type_result = doc.type();if (root_type_result.error()) {std::cerr << "獲取根類型錯誤: " << root_type_result.error() << std::endl;return EXIT_FAILURE;}simdjson::ondemand::json_type root_type = root_type_result.value();if (root_type == simdjson::ondemand::json_type::object) {std::cout << "根節點是 JSON 對象。" << std::endl;// 7. 以對象形式訪問根節點simdjson::simdjson_result<simdjson::ondemand::object> obj_result = doc.get_object();if (obj_result.error()) {std::cerr << "獲取根對象錯誤: " << obj_result.error() << std::endl;return EXIT_FAILURE;}simdjson::ondemand::object root_object = obj_result.value();std::cout << "成功訪問根對象。" << std::endl;// 后續章節將學習如何使用此'root_object'// 訪問"message"和"status"等字段} else {std::cout << "根節點不是對象,類型代碼: " << int(root_type) << std::endl;}// 重要提示:'doc'對象、解析器和 json_data 必須保持有效// 只要仍在使用從'doc'派生的任何數據return EXIT_SUCCESS;
}
源碼安裝庫文件:
git clone https://github.com/simdjson/simdjson.git
cd simdjson
mkdir build && cd build
cmake ..
make -j
sudo make install
編譯:
g++ -std=c++17 -o simdjson_test/test_simdjson simdjson_test/test_simdjson.cpp -lsimdjson
輸出結果:

此示例展示了如何獲取文檔、檢查類型并以預期類型(本例為 object)訪問根節點。獲得的 simdjson::ondemand::object 是導航對象內部的入口點,我們將在第五章詳細講解。
注意:即使檢查類型和訪問根值也會返回 simdjson_result。在按需 API 中,驗證和解析是漸進式進行的,在導航或提取數據的任何步驟都可能因 JSON 結構或值無效而產生錯誤。錯誤處理至關重要,后續將有專門章節講解(錯誤處理)。
文檔與依賴關系
必須牢記:simdjson::ondemand::document 對象并非已解析數據的獨立副本,而是原始填充 JSON 字符串的視圖,依賴解析器的內部狀態(如 tape/索引)。
這意味著:
- 只要仍在使用從文檔獲得的任何
object、array、value或string_view實例,simdjson::ondemand::parser對象必須保持存活且未被修改 - 包含 JSON 數據的原始
simdjson::padded_string(或padded_string_view指向的緩沖區)必須保持有效且未被修改 - 每個解析器對象同一時間只能激活一個文檔對象。若再次調用
parser.iterate(),新文檔將使舊文檔失效
實現原理(簡化版)
調用 parser.iterate(padded_string) 時,解析器會進行初始化工作,主要包括識別大括號、中括號、逗號和引號等結構元素,并構建內部索引(“tape”)。此階段不會完全解析字符串、數值或數組/對象的內容。
返回的 simdjson::ondemand::document 對象本質上是包裝了解析器內部狀態(特別是 json_iterator)和填充輸入字符串起始位置的指針。
當調用 doc.get_object() 或 doc.type() 等方法時,document 對象使用存儲的指針與解析器狀態及原始 JSON 數據進行交互。它利用索引快速跳轉到 JSON 的相關部分,并執行滿足請求所需的最小解析(例如確認根節點是’{',并為對象字段設置迭代器)。
字符串的實際數據(std::string_view)和導航的結構(object、array、value)都是與原始填充字符串和解析器狀態綁定的臨時視圖。
dom::document 與 ondemand::document 對比(簡注)
在第一章中,我們簡要展示了使用 dom::parser::parse 返回 dom::element 的 DOM 示例。雖然 simdjson 在內部確實有 dom::document 類型(simdjson::dom::parser 持有該類型),但 DOM API 中主要面向用戶的結果通常是表示完全解析樹節點的 dom::element。
相比之下,simdjson::ondemand::document 是按需 API 中的核心用戶對象,是 iterate 調用的直接結果,也是惰性導航的起點。
它不持有完整的解析樹,而是迭代解析過程的句柄。
對于使用按需模式(推薦方式)的初學者,初始階段主要交互對象是 simdjson::ondemand::parser、simdjson::padded_string(或 padded_string_view)和 simdjson::ondemand::document。
流程圖:
🎢初始階段的on-demand 模式
simdjson 庫在初始階段聚焦于 simdjson::ondemand::parser、simdjson::padded_string 和 simdjson::ondemand::document 的設計,主要基于性能優化、內存安全性和接口簡潔性的綜合考量:
-
性能導向的解析器設計
ondemand::parser采用 SIMD 指令集加速 JSON 解析,直接操作原始數據而非預解析為 DOM 樹。這種延遲加載(lazy parsing)策略避免一次性解析整個文檔,僅當訪問特定字段時才處理對應數據,極大減少內存占用和初始化開銷。 -
內存安全的數據容器
padded_string或padded_string_view為 JSON 數據添加尾部填充(padding),確保 SIMD 指令能安全讀取超出實際數據末尾的緩沖區。這種設計消除了邊界檢查開銷,同時防止內存越界訪問。 -
按需文檔模型
ondemand::document作為輕量級視圖,提供對 JSON 數據的惰性訪問。它不持有數據所有權,而是基于解析器的內部狀態動態生成字段值,避免了傳統 DOM 模型的全量內存分配。
交互流程
解析流程通常遵循以下模式:
- 創建
parser實例并復用(避免重復分配資源) - 加載 JSON 數據到
padded_string(或直接映射為padded_string_view) - 通過
parser.iterate()生成document視圖 - 在
document上執行具體字段訪問
simdjson::ondemand::parser parser;
auto json = simdjson::padded_string::load("data.json");
auto doc = parser.iterate(json);
std::string_view title = doc["title"];
與其他組件的對比
-
與 DOM API 的區別
傳統 DOM 解析(如simdjson::document)需完整解析整個 JSON 到內存樹,而 on-demand 模式將解析延遲到字段訪問時,更適合流式處理或大型文件。 -
與 SAX 模型的差異
SAX 需要實現回調函數處理事件,on-demand 則提供更直觀的鍵值訪問接口,同時保留相似的性能特性。
這種設計使初始階段既能保持高性能,又能通過簡潔的接口降低使用復雜度,符合現代 C++ 庫零開銷抽象的原則。
總結
simdjson::ondemand::document 是 parser.iterate() 的返回對象,代表按需 API 中 JSON 數據的根節點。
- 關鍵特性在于它并非完全解析的樹結構,而是允許按需解析 JSON 值的迭代器。
我們使用 document 對象作為導航 JSON 數據的起點,通常通過檢查其類型并調用 get_object() 或 get_array() 等方法來開始遍歷結構。
請牢記依賴關系:文檔對象、創建它的解析器以及原始填充字符串數據必須保持有效且在作用域內,才能安全使用從文檔獲得的任何數據。
現在我們已經掌握如何獲取和訪問 JSON 文檔根節點,下一步是理解單個 JSON 值(如字符串、數值或嵌套對象/數組)的表示和訪問方式,這將是下一章數值(Value)的主題。
下一章:數值(Value)










)








