需求
假如我有一個時間序列,例如是前113天的價格數據(訓練集),然后我希望借此預測后30天的數據(測試集),實際上這143天的價格數據都已經有了。這里為了簡單,每一天的數據只有一個價格維度(轉化成矩陣形式就是1列),但實際上每一天的數據也可以是多維的特征,轉化成矩陣就是多列。
預測思路
首先訓練模型去預測下一天數據的能力,訓練完后,我們使用歷史數據預測第114天的數據,預測后,我們暫時將第114天的數據看做真實數據,放入歷史數據中,再用它預測第115天的數據,依次類推,最終預測完后30天的數據。
本實現的關鍵點
1. 數據預處理:歸一化很重要,可以加速訓練過程并提高模型性能
2. 模型結構:LSTM + 全連接層的組合用于回歸預測
3. 訓練過程:使用MSE損失和Adam優化器
4. 預測方式:滾動預測,保持隱藏狀態的連續性
一、LSTM神經元結構
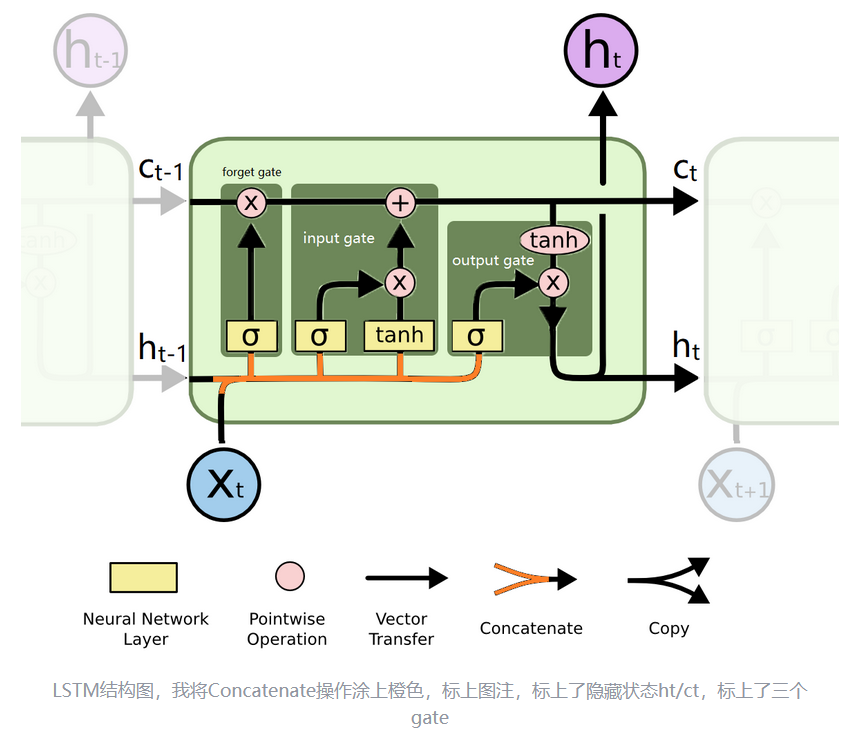
?

二、定義LSTM模型
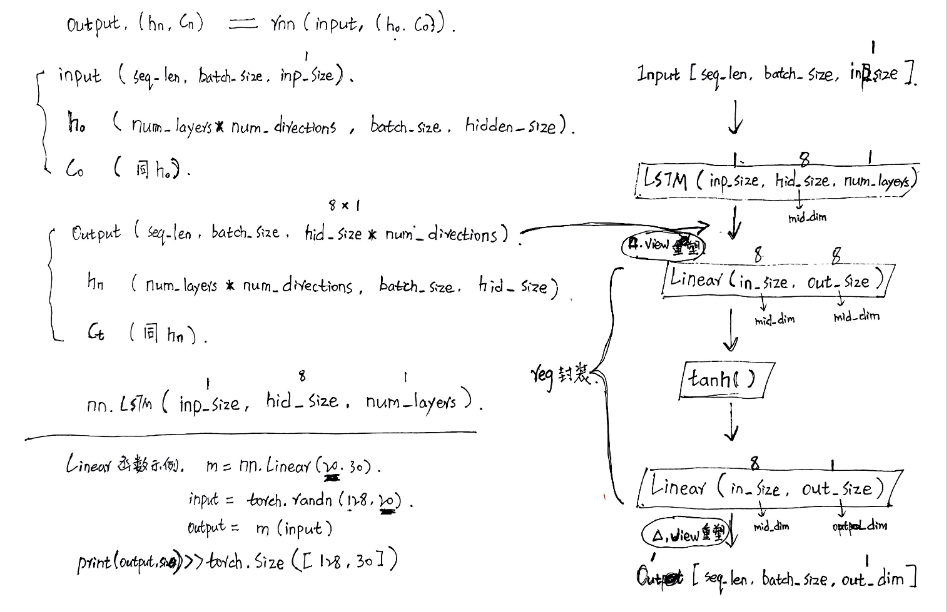
我們會使用torch.nn.LSTM()加載LSTM層。其LSTM的參數定義如下:

?注意:
- 對于雙向 LSTM,正向和反向分別是方向 0 和 1。當輸出層拆分時,以
batch_first=False:output.view(seq_len, batch, num_directions, hidden_size)為例。- 對于雙向 LSTM,h_n 與輸出的最后一個元素并不等價;前者包含最終的向前和向后隱藏狀態,而后者包含最終的向前隱藏狀態和初始的向后隱藏狀態。
batch_first參數對于非批處理的輸入會被忽略。proj_size應該小于hidden_size。
?torch.nn.LSTM中的proj_size參數到底是什么意思?
?
proj_size是 PyTorchtorch.nn.LSTM中的一個參數,用于指定將 LSTM 輸出的隱藏狀態(hidden state)映射到指定維度。當proj_size大于 0 時,LSTM 會通過一個可學習的投影矩陣將隱藏狀態投影到該維度,通常用于調整輸出特征的數量或適配特定任務需求。具體作用
在 LSTM 模型中,隱藏狀態
h的維度通常與輸入特征維度一致(即hidden_size)。通過引入proj_size參數,可以在 LSTM 輸出后通過線性變換進一步壓縮或擴展特征空間,例如:
- ?降維?:當
proj_size小于hidden_size時,通過投影矩陣將高維特征映射到低維空間,減少計算量或提取核心特征。- ?升維?:當
proj_size大于hidden_size時,可增加輸出特征的多樣性,適用于需要更多特征的情況。?注意事項
- 該參數默認值為 0,即不進行投影操作。
- 投影矩陣是可學習的,其維度由
proj_size和hidden_size共同決定。
最重要的參數就前三個,其他參數都可以默認。把網絡看成一個黑箱,我們在用是肯定是輸入一個向量,然后網絡處理后輸出一個向量,所以我們必須要告訴網絡輸入的向量是多少維,輸出的為多少維,因此前兩個參數就決定了輸入和輸出向量的維度。當然,hidden_size只是指定從LSTM輸出的向量的維度,并不是最后的維度,因為LSTM層之后可能還會接其他層,如全連接層(FC),因此hidden_size對應的維度也就是FC層的輸入維度。
LSTM網絡的輸入和輸出:
?
?輸入:input,(h_0, c_0)



?輸出:output,(h_n, c_n)
output:對于未批處理的輸入,形狀為 (L,D?Hout) 的張量,當 batch_first=False 時為 (L,N,D?Hout),當 batch_first=True 時為 (N,L,D?Hout),包含來自 LSTM 最后層的輸出特征 (h_t),對于每個 t。如果輸入了 torch.nn.utils.rnn.PackedSequence,輸出也將是一個打包序列。當 bidirectional=True 時,輸出將包含序列中每個時間步的正向和反向隱藏狀態的拼接。


?LSTM參數這部分詳細學習可以跳轉到:
https://zhuanlan.zhihu.com/p/510072883
LSTM — PyTorch 2.7 documentation
?LSTM的輸入和輸出為:output,(h_n,c_n) = lstm (x, [ht_1, ct_1]),
其中x就是我們喂給網絡的數據,它的shape要求如下:x:[seq_length, batch_size, input_size]
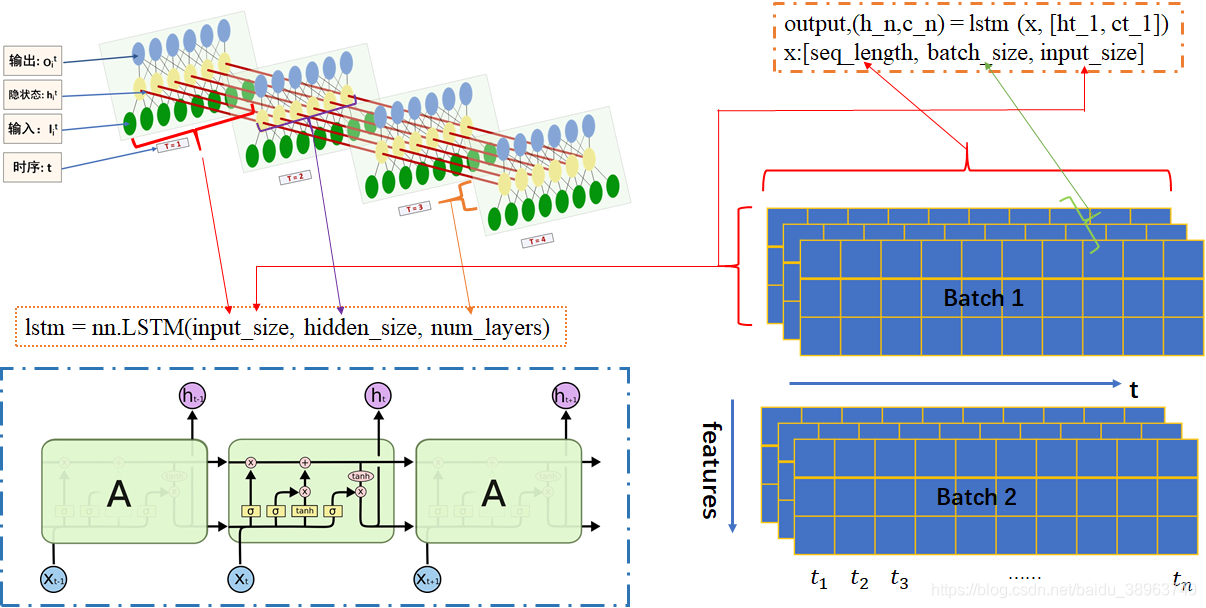
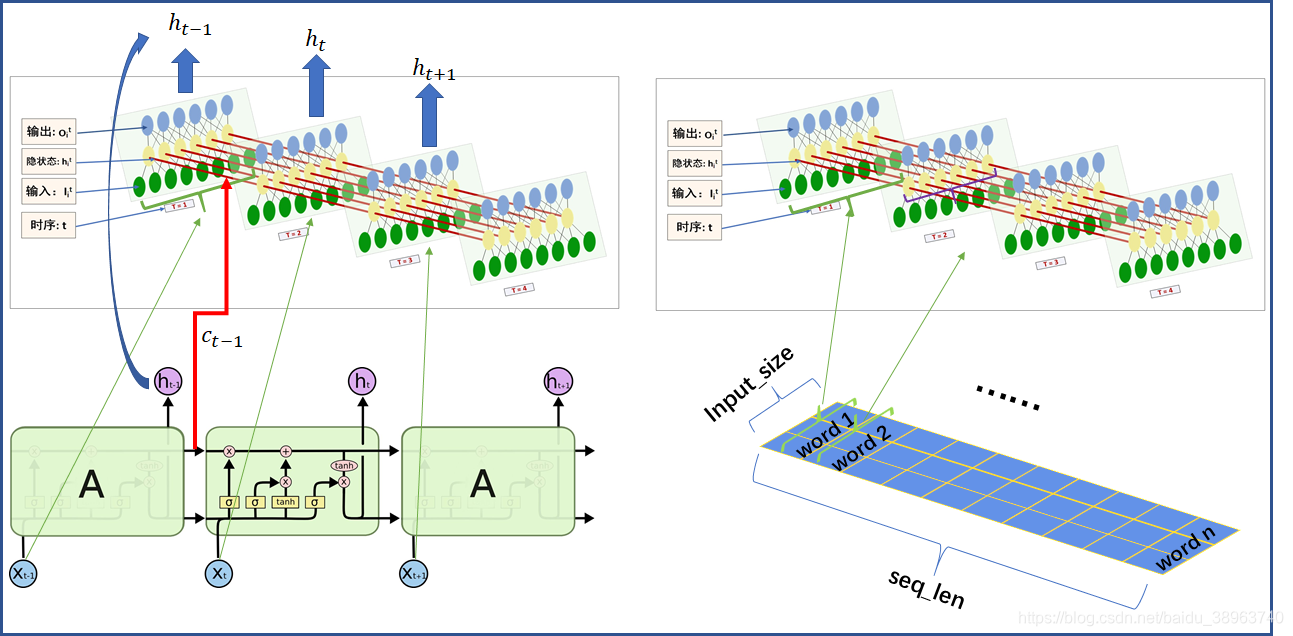 ?圖片地址:pytorch中LSTM參數詳解(一張圖幫你更好的理解每一個參數)_torch lstm參數圖解-CSDN博客?
?圖片地址:pytorch中LSTM參數詳解(一張圖幫你更好的理解每一個參數)_torch lstm參數圖解-CSDN博客?
input(seq_len, batch_size, input_size)
參數有:
? ? seq_len:序列長度,在NLP中就是句子長度,一般都會用pad_sequence補齊長度
? ? batch_size:每次喂給網絡的數據條數,在NLP中就是一次喂給網絡多少個句子
? ? input_size:輸入的特征維度,和前面定義網絡結構的input_size參數一致##
那么輸入此LSTM的 input() == (seq_len, batch_size, input_size)
在我們的LSTM時間序列預測任務中:
seq_len:時間序列的長度,在這里使用前113天的價格數據進行訓練,則 seq_len == 113。
batch_size:同一批次中要處理的樣本數,它決定了每次輸入網絡的數據批次大小,直接影響訓練效率和內存占用。(這里的樣本好像指的是序列的個數,即一個seq就是一個樣本)
input_size:輸入數據的特征維度,在這里只有價格一個維度,則 input_size?== 1。##
如果是自然語言處理 (NLP) ,那么:
seq_len:將對應句子的長度
batch_size:同個批次中輸入的句子數量
input_size: 句子中用來表示每個單詞(中文分詞)的矢量維度##
請注意,雖然通常情況下input張量的第一個維度是批次大小batch size,但是PyTorch建議我們輸入循環網絡的時候張量的第一個維度是序列長度seq_len,而第二個維度才是批次大小batch_size。(其實就是LSTM參數中batch_fist==False)
為了進行時間序列預測,我們在LSTM后面接上兩層全連接層(1層亦可),同時改變最終輸出張量的維度,我們只需要預測價格這一個值,因此最終的out_dim 為1。在LSTM后方的全連接層也可以看做是一個回歸操作 regression。
在LSTM后面接上兩層全連接層,為何是兩層: 理論上足夠寬,并且至少存在一層具有任何一種“擠壓”性質的激活函數的兩層全連接層就能擬合任何連續函數。最先提出這個理論證明的是 Barron et al., 1993,使用了UAT (Universal Approximation Theorem),指出了可以在compact domain擬合任意多項式函數。”
實際上對于過于復雜的連續函數,這個「足夠寬」不容易滿足。并且擬合訓練數據并讓神經網絡具備足夠的泛化性的前提是:良好的訓練方法(比如批次訓練數據滿足 獨立同分布 (i.i.d.),良好的損失函數,滿足Lipschitz連續 etc.)
代碼示例:
reg = nn.Sequential(
? ? nn.Linear(mid_dim, mid_dim),? ?# 全連接層,將LSTM輸出映射到mid_dim維度
? ? nn.Tanh(),? # 激活函數,將輸出映射到[-1, 1]之間
? ? nn.Linear(mid_dim, out_dim),???# 全連接層,將LSTM輸出映射到out_dim維度
)? # regression回歸##
linear_input = output_of_LSTM? # LSTM的輸出作為回歸層的輸入
[seq_len, batch_size, mid_dim]= linear_input.shape
linear_input = linear_input.view(seq_len * batch_size, mid_dim)??# 將輸出重塑為2D
output = reg(linear_input)?# 通過回歸層
output = output.view(seq_len, batch_size, out_dim)?# 重塑回原始形狀
?看不懂上面代碼示例的話,請跳轉到API文檔:
Linear — PyTorch 2.7 documentation
Tanh — PyTorch 2.7 documentation
Tensor Views — PyTorch 2.7 documentation
?定義LSTM模型的完整代碼如下:
class RegLSTM(nn.Module):def __init__(self, inp_dim, out_dim, mid_dim, mid_layers):"""初始化LSTM回歸模型參數:inp_dim: 輸入維度out_dim: 輸出維度mid_dim: LSTM隱藏層維度mid_layers: LSTM層數"""super(RegLSTM, self).__init__()# LSTM層,輸入維度為inp_dim,隱藏狀態維度為mid_dim,層數為mid_layersself.rnn = nn.LSTM(inp_dim, mid_dim, mid_layers) # 回歸層,將LSTM輸出映射到預測值self.reg = nn.Sequential(nn.Linear(mid_dim, mid_dim), # 全連接層,將LSTM輸出映射到mid_dim維度nn.Tanh(), # 激活函數,將輸出映射到[-1, 1]之間nn.Linear(mid_dim, out_dim), # 全連接層,將LSTM輸出映射到out_dim維度) def forward(self, x):"""前向傳播參數:self.rnnx: 輸入數據,形狀為 [seq_len, batch_size, inp_dim]返回:輸出預測,形狀為 [seq_len, batch_size, out_dim]"""# 獲取LSTM輸出,y形狀為 [seq_len, batch_size, mid_dim]y = self.rnn(x)[0] # y, (h, c) = self.rnn(x) # 獲取輸出的形狀seq_len, batch_size, hid_dim = y.shape# 將輸出重塑為2D,便于全連接層處理y = y.view(-1, hid_dim) # 通過回歸層y = self.reg(y) # 重塑回原始形狀y = y.view(seq_len, batch_size, -1) return ydef output_y_hc(self, x, hc):"""帶隱藏狀態的前向傳播,用于預測時保持狀態連續性參數:x: 輸入數據hc: 上一步的隱藏狀態和單元狀態元組 (h, c)返回:y: 輸出預測hc: 更新后的隱藏狀態和單元狀態"""# 傳遞隱藏狀態和單元狀態y, hc = self.rnn(x, hc)# 與forward相同的處理步驟seq_len, batch_size, hid_dim = y.size() # 獲取輸出y的形狀y = y.view(-1, hid_dim) # 將輸出y重塑為2D,便于全連接層處理y = self.reg(y) # 通過回歸層y = y.view(seq_len, batch_size, -1) # 重塑回原始形狀return y, hc# 示例:LSTM的輸入輸出維度
print("LSTM輸入格式: [seq_len, batch_size, feature_dim]")
print("示例: 5個時間步,3個樣本,每個樣本10個特征 -> [5, 3, 10]")
forward方法中LSTM層的輸入與輸出(帶批處理、batch_first=False、proj_size=0)
一、輸入格式:input,(h0, C0)
1、input為(seq_len,batch_size,input_size)格式的tensor,seq_len即為time_step
2、h0為(num_layers * num_directions, batch_size, hidden_size)格式的tensor,隱藏狀態的初始狀態。(num_directions指lstm單向還是雙向;如果設置了投影維度則應為proj_size)
3、C0為(num_layers * num_directions, batch_size, hidden_size)格式的tensor,細胞初始狀態
二、輸出格式:output,(ht,Ct)
1、output為(seq_len, batch_size, num_directions*hidden_size)格式的tensor,包含輸出特征h_t(源于LSTM每個t的最后一層)
2、ht為(num_layers * num_directions, batch_size, hidden_size)格式的tensor,
3、Ct為(num_layers * num_directions, batch_size, hidden_size)格式的tensor,
###
?代碼示例(以NLP為例):
rnn = nn.LSTM(10, 20, 2) # 一個單詞向量長度為10,隱藏層節點數為20,LSTM有2層
input = torch.randn(5, 3, 10) # 輸入數據由3個句子組成,每個句子由5個單詞組成,單詞向量長度為10
h0 = torch.randn(2, 3, 20) # 2:LSTM層數*方向? 3:batch? 20: 隱藏層節點數
c0 = torch.randn(2, 3, 20) # 同上
output, (hn, cn) = rnn(input, (h0, c0))print(output.shape, hn.shape, cn.shape)?
>>> torch.Size([5, 3, 20])? ?torch.Size([2, 3, 20])? ?torch.Size([2, 3, 20])
?總結一下:
在LSTM內部,有h和c,可以理解為hidden和cell。模型中定義了兩個函數forward()和output_y_hc,可以理解為forward()函數在訓練后預測時,會扔掉h和c,每次預測都用同一個h和c(可能是訓練時最后一次的h和c,可能是隨機的),output_y_hc()會一直返回h和c,從而下一次預測可以把h和c在帶進去,一直用最新的h和c。
模型構造函數接受四個參數:inp_dim, out_dim, mid_dim, mid_layers,其中inp_dim, mid_dim, mid_layers是nn.LSTM()構造時傳入的3個參數,輸入維度是inp_dim,在這里是1,輸出維度是mid_dim,這里可以自己定義。后面再跟兩個全連接層,第一個全連接層是mid_dim to mid_dim,第二個全連接層是mid_dim to out_dim,也就是說,模型最后的輸出維度是out_dim,在本問題中,我們希望預測的是每天的價格,所以out_dim也是1。
REGLSTM這個類里面定義的成員函數output_y_hc,有什么作用?
我們需要保存LSTM的隱藏狀態(hidden state),用于恢復序列中斷后的計算。舉例子,我有完整的序列 seq12345:
- 我輸入seq12345 到LSTM后,我能得到6,即seq123456。
- 我也可以先輸入 seq123 以及默認的隱藏狀態hc,得到4和新的hc,然后我把seq234和新的hc輸入,可以得到5和新的hc,我接著把 seq345 以及 hc一起輸入到LSTM,我也能得到6,即seq123456。
(hc 指 h和c,是兩個張量,本文開頭的LSTM結構圖注明了何為 h與c)
三、數據預處理
3.1 數據預處理函數
在模型訓練之前,需要對訓練集的train_x和train_y都要進行歸一化。
train_x, train_x_minmax = minmaxscaler(train_x)? ?#返回歸一化后的數據、最大和最小值
train_y, train_y_minmax = minmaxscaler(train_y)
前后過程:
劃分數據集 --> 對訓練集的x和y進行歸一化 --> 模型訓練 --> 保存模型?
#? #? #? #?
在模型預測過程,需要對測試集的test_x進行歸一化,對predict_y進行反歸一化。
test_x = preminmaxscaler(test_x, train_x_minmax[0], train_x_minmax[1])? #返回歸一化后的值
predict_y = unminmaxscaler(predict_y, train_x_minmax[0], train_y_minmax[1])
前后過程:
使用定長的timestep序列數據作為輸入來預測下一個數據點--> 對測試集的test_x進行歸一化 -->?獲取最后一個時間步的預測值test_y[-1].item()? -->? 對預測值predict_y進行反歸一化? --> 將預測結果加入數據集當作真實數據并進行下一步數據點的預測
數據先預處理一下。若直接對全部數據進行歸一化處理是不正確的,歸一化的時候不應該把測試用的數據也包括進去。對于訓練集的x和y我們分別都歸一化處理。之后在預測的時候,對于輸入的x,我們要用訓練集x的最大和最小值進行歸一化處理,對于預測得到的y,我們要用訓練集y的最大和最小值進行反歸一化。所以我們要保存著訓練集中x和y的最大值與最小值。
為了提高神經網絡的訓練效果,我們需要對數據進行歸一化處理。下面定義三個函數:
1. `minmaxscaler`: 將數據歸一化到[0,1]區間
2. `preminmaxscaler`: 使用已知的最小值最大值對新數據進行歸一化
3. `unminmaxscaler`: 將歸一化的數據反歸一化回原始范圍
def minmaxscaler(data):"""將數據歸一化到[0,1]區間參數:data: 輸入數據返回:scaled_data: 歸一化后的數據(min_val, max_val): 用于反歸一化的最小值和最大值"""min_val = np.min(data)max_val = np.max(data)scaled_data = (data - min_val) / (max_val - min_val)return scaled_data, (min_val, max_val)def preminmaxscaler(data, min_val, max_val):"""使用已知的最小值和最大值對數據進行歸一化參數:data: 輸入數據min_val: 最小值max_val: 最大值返回:scaled_data: 歸一化后的數據"""scaled_data = (data - min_val) / (max_val - min_val)return scaled_datadef unminmaxscaler(data, min_val, max_val):"""將歸一化的數據反歸一化參數:data: 歸一化的數據min_val: 原始數據的最小值max_val: 原始數據的最大值返回:原始數據"""return data * (max_val - min_val) + min_val# 測試歸一化函數
test_data = np.array([1, 5, 10, 15, 20])
normalized_data, (min_val, max_val) = minmaxscaler(test_data)
print("原始數據:", test_data)
print("歸一化數據:", normalized_data)
print("反歸一化數據:", unminmaxscaler(normalized_data, min_val, max_val))
?輸出結果:
preminmaxscaler是在預測的時候,我們用訓練集的最大最小值去做歸一化。
unminmaxscaler就是反歸一化。
3.2?準備數據集
- 經過嘗試,LSTM對輸入的時間序列長度似乎沒有要求,也就是說我可以輸入100天的歷史數據進行訓練,我也可以輸入50天的歷史數據進行訓練。之后在訓練完進行預測的時候,我也可以輸入任意天數的歷史數據預測未來的數據。
- 由于數據較少,我們只設置1個batch,也就是一次就把所有訓練數據輸入進去,然后迭代多個epoch進行訓練。
- 我們使用113天的歷史數據訓練模型,預測后30天的數據。
# 加載數據 - 時間序列數據(144天的價格歷史數據)bchain = np.array([112., 118., 132., 129., 121., 135., 148., 148., 136., 119., 104.,118., 115., 126., 141., 135., 125., 149., 170., 170., 158., 133.,114., 140., 145., 150., 178., 163., 172., 178., 199., 199., 184.,162., 146., 166., 171., 180., 193., 181., 183., 218., 230., 242.,209., 191., 172., 194., 196., 196., 236., 235., 229., 243., 264.,272., 237., 211., 180., 201., 204., 188., 235., 227., 234., 264.,302., 293., 259., 229., 203., 229., 242., 233., 267., 269., 270.,315., 364., 347., 312., 274., 237., 278., 284., 277., 317., 313.,318., 374., 413., 405., 355., 306., 271., 306., 315., 301., 356.,348., 355., 422., 465., 467., 404., 347., 305., 336., 340., 318.,362., 348., 363., 435., 491., 505., 404., 359., 310., 337., 360.,342., 406., 396., 420., 472., 548., 559., 463., 407., 362., 405.,417., 391., 419., 461., 472., 535., 622., 606., 508., 461., 390.,432.], dtype=np.float32)bchain = bchain[:, np.newaxis] # 轉為列向量,形狀變為(144, 1)# 查看數據形狀print("數據形狀:", bchain.shape)print("前10個數據點:", bchain[:10].flatten())# 繪制原始數據plt.figure(figsize=(12, 6))plt.plot(bchain, 'b-')plt.title('原始時間序列數據')plt.xlabel('時間步')plt.ylabel('值')plt.grid(True)plt.show()?輸出結果: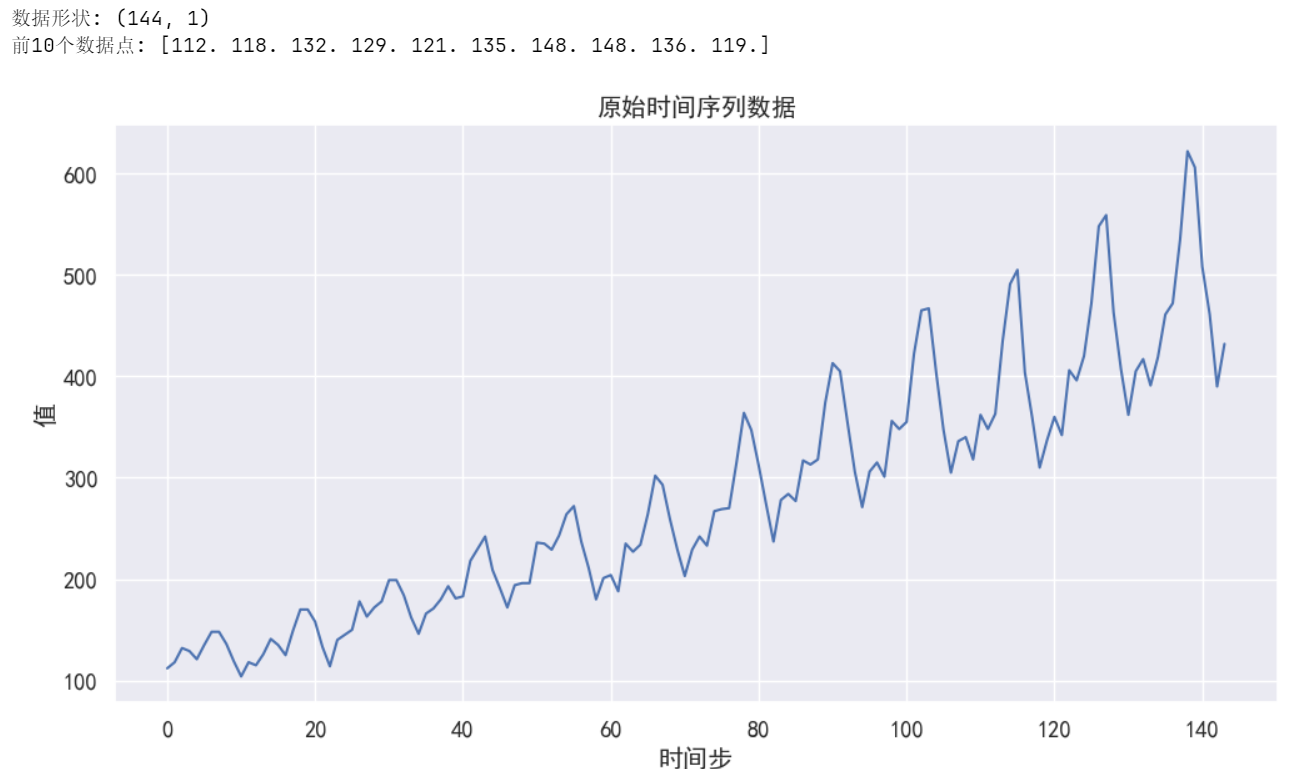
# 設置模型參數
inp_dim = 1 # 輸入維度
out_dim = 1 # 輸出維度
mid_dim = 8 # LSTM隱藏層維度
mid_layers = 1 # LSTM層數# 準備輸入和目標數據
# data_x是從第一個到倒數第二個數據點,data_y是從第二個到最后一個數據點
# 這里我們預測下一個時間步的值
data_x = bchain[:-1, :] # 形狀: (143, 1)
data_y = bchain[+1:, :] # 形狀: (143, 1)# 查看輸入和輸出的形狀
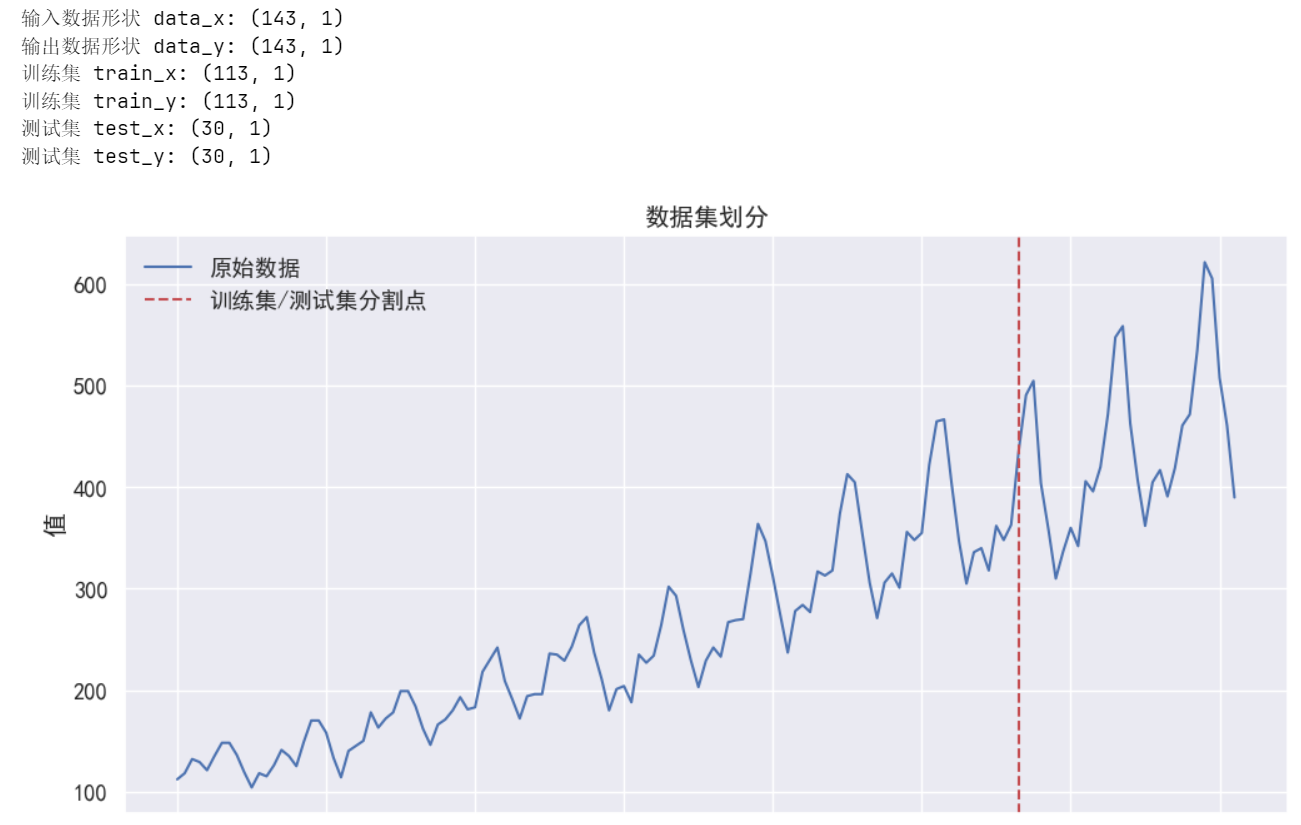
print("輸入數據形狀 data_x:", data_x.shape)
print("輸出數據形狀 data_y:", data_y.shape)# 劃分訓練集(前113個數據點)
train_size = 113
train_x = data_x[:train_size, :] # 形狀: (113, 1)
train_y = data_y[:train_size, :] # 形狀: (113, 1)
test_x = data_x[train_size:, :] # 形狀: (30, 1)
test_y = data_y[train_size:, :] # 形狀: (30, 1)print("訓練集 train_x:", train_x.shape)
print("訓練集 train_y:", train_y.shape)
print("測試集 test_x:", test_x.shape)
print("測試集 test_y:", test_y.shape)# 數據歸一化處理
train_x, train_x_minmax = minmaxscaler(train_x)
train_y, train_y_minmax = minmaxscaler(train_y)# 可視化數據集劃分
plt.figure(figsize=(12, 6))
plt.plot(range(len(data_x)), data_x, 'b-', label='原始數據')
plt.axvline(x=train_size, color='r', linestyle='--', label='訓練集/測試集分割點')
plt.title('數據集劃分')
plt.xlabel('時間步')
plt.ylabel('值')
plt.legend()
plt.grid(True)
plt.show()??輸出結果:
方法1:只輸入一條歷史序列進行訓練:
最簡單的訓練模式,我們把113天的歷史數據一次性輸入到模型中進行訓練。113天的歷史序列長這樣:[112., 118., 132., 129. …… 362., 348., 363.]
那這就是輸入模型的x。那么輸入模型的y是什么樣呢?由于我們希望的是預測后一天的數據,所以我們每次都取后一天的數據,同樣構成一個113天的序列,序列長這樣:[118., 132., 129., 121. …… 348., 363., 435.]
這就是輸入模型的y。可以看到y就是x后移了1天。這里我認為,如果我們想預測后兩天你的數據,那么我們的y就可以是x后移2天。
我們構造好了輸入數據的x和y,現在要把它們整理成模型希望的數據格式。LSTM希望的輸入數據是3維,[seq_len, batch_size, inp_dim]:
seq_len是時間步,也就是每個序列的長度。
batch_size是序列個數,也就是我們希望同時處理多少個序列。
inp_dim是輸入數據的特征維度,也就是對于每個時間序列,每一天的數據維數。
對于本問題,我們輸入的是一個113天的歷史序列,因此batch_size是1。每一天都只有一個價格數據,因此inp_dim也是1。而seq_len就是113。
對于y,y也是一個113天的序列,維度是1,數據格式也是[113, 1, 1]。只不過對應的seq_len具體的值往后移了一位。
# 設置設備(GPU或CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 第一種操作,直接把batch_x batch_y這一個序列扔進去# 準備訓練數據,添加batch維度
# LSTM輸入格式: [seq_len, batch_size, feature_dim]
batch_x = train_x[:, np.newaxis, :] # 形狀: [113, 1, 1],表示113個時間步,1個樣本,每個樣本1個特征
batch_y = train_y[:, np.newaxis, :] # 形狀: [113, 1, 1]
batch_x = torch.tensor(batch_x, dtype=torch.float32, device=device)
batch_y = torch.tensor(batch_y, dtype=torch.float32, device=device)print("訓練輸入 batch_x 形狀:", batch_x.shape)
print("訓練目標 batch_y 形狀:", batch_y.shape)?輸出:

?注意:了解np.newaxis的作用、用法
【Numpy】基礎學習:一文了解np.newaxis的作用、用法-CSDN博客
【Python】np.newaxis()函數用法詳解_np.newaxis函數-CSDN博客?Constants — NumPy v1.24 Manual【Python】np.newaxis()函數用法詳解_np.newaxis函數-CSDN博客
方法2:輸入多條短的歷史序列進行訓練:
我們也可以將使用類似于滑動窗口的方法,從原始數據里選取多段相同長度的序列,作為一條條的歷史序列x,當然也要搭配y序列(就是把x序列右移一步)。
我們選定歷史序列長度為40,一共選了25個序列,代碼如下:
# 設置設備(GPU或CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 將訓練數據轉換為張量
train_x_tensor = torch.tensor(train_x, dtype=torch.float32, device=device)
train_y_tensor = torch.tensor(train_y, dtype=torch.float32, device=device)# 使用滑動窗口構造多條序列,窗口長度為40,步長為3
window_len = 40
batch_x = [] # 存儲輸入序列
batch_y = [] # 存儲目標序列for end in range(len(train_x_tensor), window_len, -3):# 添加一段歷史序列到batch_xbatch_x.append(train_x_tensor[end-window_len:end])# 添加對應的目標序列到batch_ybatch_y.append(train_y_tensor[end-window_len:end])# 檢查構造的序列數量
print(f"構造的序列數量: {len(batch_x)}")# 使用pad_sequence將數據整理成LSTM希望的格式
# 將多條序列整理成 [seq_len, batch_size, feature_dim] 格式
from torch.nn.utils.rnn import pad_sequence
batch_x = pad_sequence(batch_x) # 形狀變為 [40, batch_size, 1]
batch_y = pad_sequence(batch_y) # 形狀變為 [40, batch_size, 1]print(f"batch_x的形狀: {batch_x.shape}") # [40, num_sequences, 1]
print(f"batch_y的形狀: {batch_y.shape}") # [40, num_sequences, 1]?輸出:
?
注意:因為pytorch要求timestep必須定長,基本上網上搜到的其他所有pytorch的lstm入門教程都是定長的timestep,如果遇到的案例中使用的是不定長的timestep,需借助pad_sequence成定長的timestep來訓練。(但是我整個實驗流程都是用的定長的timestep,可忽略這一點)
如果同一批次里面訓練序列長度不統一,直接在末尾補0的操作不優雅,我們需要借助torch 自帶的工具 pad_sequence的協助,放入pad_sequence 的序列必須從長到短放置,隨著反向傳播的進行,PyTorch 會逐步忽略完成梯度計算的短序列。具體解釋請看PyTorch官網。
?注意:了解torch.pad_sequence的作用、用法
pad_sequence_padsequence-CSDN博客
pytorch中的pad_sequence、pack_padded_sequence和pad_packed_sequence函數_pytorch pad-CSDN博客
「構建用于訓練的序列」:
要避免輸入相同起始裁剪位點的序列用于訓練。只有序列的起始裁剪位點都不一樣,在RNN內才不會重復訓練,這一點很重要。
batch_var_x.append(var_x[j:])? # 不同的起始裁剪位點,正確的裁剪方法
batch_var_x.append(var_x[:j])? # 相同的起始裁剪位點,完全錯誤的裁剪方法
我們通過pad_sequence將數據整理成LSTM希望的格式。
比如我們本來有3條歷史序列,分別是[1, 2, 3,4],[ 5, 6,7, 8],[9,10,11,12],但是我們將它們整理成的格式為:
原本是:? ? ? ? ? ? ? ?整理成:
[ [1,? 2,? ?3,? ?4],? ? ? ? ? ? ? ? [ [[1],? [5],? [9]],
? [5,? 6,? ?7,? ?8],? ? ? ? ? ? ? ? ? [[2],? [6],? [10]],
? [9, 10, 11, 12] ]? ? ? ? ? ? ? ? [[3],? [7],? [11]],??????????????????????????????????????????[[4],? [8],? [12]]?]
這樣,每一列是一個序列,一共有3個歷史序列。每一行是一個時間步,這樣整理數據,模型就能一行一行的處理,從而同時處理3個序列。
對于訓練用的x和y,我們都整理成一樣的格式。只不過在一般的情境中,x的維度要高一點,比如每一天(也就是一個時間步),一共有n個特征數據表示,也就是說x的維度是n,也就是說在定義LSTM的時候,input_size是n。假如我們有m個序列,每個序列有z個時間步,最后的x要整理成[z, m, n]。
四、模型訓練
4.1 初始化模型、損失函數和優化器
有了訓練用的x和y,我們就可以將其輸入到模型進行訓練。在模型訓練之前需要初始化模型,并設置損失函數和優化器。(保存模型結構圖這一步驟不是必要的,只是為了方便可視化)
# 初始化模型
model = RegLSTM(inp_dim, out_dim, mid_dim, mid_layers).to(device)
print(model)# 保存模型結構圖
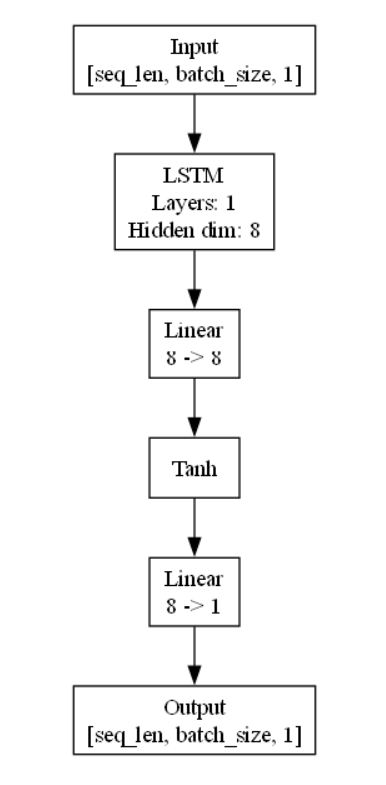
try:from graphviz import Digraphdef save_model_structure(model, inp_dim, mid_dim, mid_layers, out_dim, filename='model_structure'):dot = Digraph(comment='LSTM時間序列預測模型')# 添加輸入節點dot.node('input', f'Input\n[seq_len, batch_size, {inp_dim}]', shape='box')# 添加LSTM節點dot.node('lstm', f'LSTM\nLayers: {mid_layers}\nHidden dim: {mid_dim}', shape='box')# 添加回歸網絡節點dot.node('reg1', f'Linear\n{mid_dim} -> {mid_dim}', shape='box')dot.node('tanh', 'Tanh', shape='box')dot.node('reg2', f'Linear\n{mid_dim} -> {out_dim}', shape='box')# 添加輸出節點dot.node('output', f'Output\n[seq_len, batch_size, {out_dim}]', shape='box')# 添加邊dot.edge('input', 'lstm')dot.edge('lstm', 'reg1')dot.edge('reg1', 'tanh')dot.edge('tanh', 'reg2')dot.edge('reg2', 'output')# 保存為圖像dot.render(filename, format='png', cleanup=True)print(f'模型結構圖已保存為: {filename}.png')save_model_structure(model, inp_dim, mid_dim, mid_layers, out_dim, './model_structure_tutorial')# 顯示模型結構圖from IPython.display import Imagedisplay(Image(filename='./model_structure_tutorial.png'))except ImportError:print("無法保存模型結構圖。請安裝graphviz庫: pip install graphviz")print("并確保已安裝Graphviz軟件: https://graphviz.org/download/")# 設置損失函數和優化器
loss_fn = nn.MSELoss() # 均方誤差損失函數
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2) # Adam優化器輸出結果:

?下面的草稿是分析整個模型的結構是怎么來的:
4.2 訓練模型
有了訓練用的x和y,我們就可以將其輸入到模型進行訓練。我們將訓練800個epoch,每10個epoch打印一次損失值,代碼如下:
# 訓練模型
print("訓練開始...")
losses = [] # 記錄損失值,用于繪圖epochs = 801
for e in range(epochs):# 前向傳播out = model(batch_x) # 將輸入數據batch_x傳遞給模型,得到預測輸出out# 計算損失loss = loss_fn(out, batch_y) # 計算預測輸出out與真實輸出batch_y之間的損失losses.append(loss.item()) # 將損失值添加到losses列表中# 反向傳播和優化optimizer.zero_grad() # 清空梯度loss.backward() # 計算梯度optimizer.step() # 更新參數# 每10個epoch打印一次損失if e % 10 == 0:print('Epoch: {:4}, Loss: {:.5f}'.format(e, loss.item()))# 保存模型
torch.save(model.state_dict(), './net.pth')
print("模型已保存至: './net.pth'")# 繪制損失曲線
plt.figure(figsize=(10, 5))
plt.plot(losses)
plt.title('訓練損失曲線')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.yscale('log') # 使用對數尺度更容易觀察損失下降
plt.grid(True)
plt.show()
?輸出:
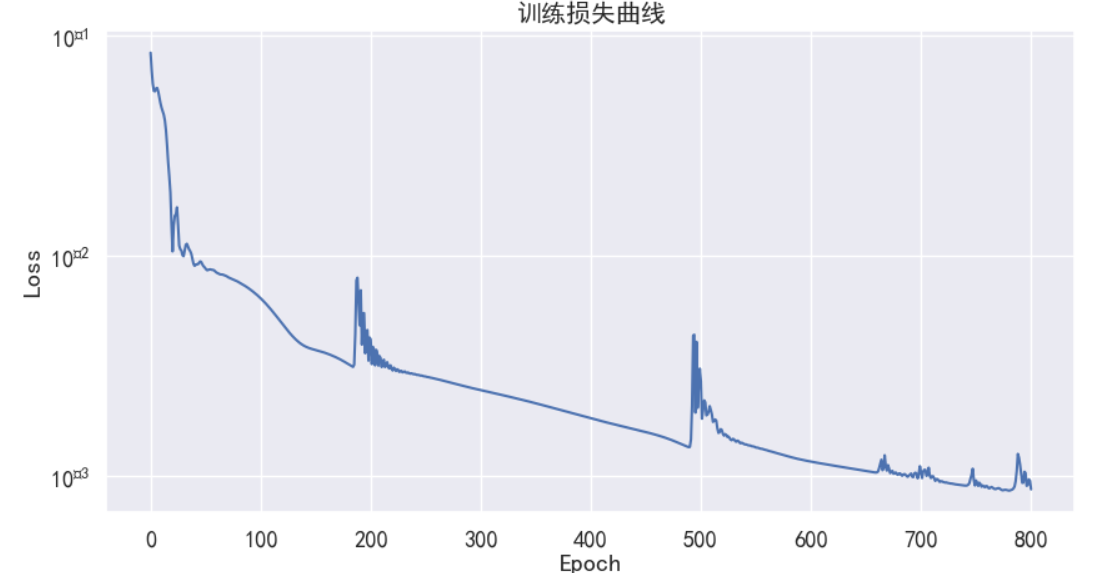
4.3 模型預測
預測的時候,我們還是要輸入一個序列x,得到一個輸出序列y。由于在訓練時輸出序列是輸入序列右移一步,因此對于得到的y,其最后一個值就是我們預測的下一天的數據。
對于輸入的序列x,序列長度任意,我在嘗試的時候發現序列長度長一點和短一點(甚至序列長度是1),預測的效果好像沒有差別,這可能證明LSTM的預測效果并不好。我也不太清楚。
現在使用訓練好的模型對測試集進行預測:
# 模型預測
print("開始預測...")
new_data_x = data_x.copy()
new_data_x[train_size:] = 0 # 清除訓練集之后的數據,用于存放預測結果test_len = 40 # 使用前40個數據點來預測下一個eval_size = 1 # 評估批量大小
# 初始化LSTM隱藏狀態和單元狀態為零
zero_ten = torch.zeros((mid_layers, eval_size, mid_dim), dtype=torch.float32, device=device)# 循環預測訓練集之后的數據
for i in range(train_size, len(new_data_x)):# 獲取前test_len個數據點作為輸入test_x = new_data_x[i-test_len:i, np.newaxis, :]# 歸一化test_x = preminmaxscaler(test_x, train_x_minmax[0], train_x_minmax[1])batch_test_x = torch.tensor(test_x, dtype=torch.float32, device=device)# 如果是第一個預測點,使用初始隱藏狀態# 否則,使用上一次預測的隱藏狀態繼續預測if i == train_size:test_y, hc = model.output_y_hc(batch_test_x, (zero_ten, zero_ten))else:# 僅使用最近的兩個時間步來更新狀態test_y, hc = model.output_y_hc(batch_test_x[-2:], hc)# 獲取完整的預測結果test_y = model(batch_test_x)# 獲取最后一個時間步的預測值predict_y = test_y[-1].item()# 反歸一化predict_y = unminmaxscaler(predict_y, train_x_minmax[0], train_y_minmax[1])# 保存預測結果new_data_x[i] = predict_yprint(f"預測時間步 {i}, 預測值: {predict_y:.2f}, 真實值: {data_x[i, 0]:.2f}")# 計算測試集的均方誤差
test_predictions = new_data_x[train_size:]
test_actual = data_x[train_size:]
mse = np.mean((test_predictions - test_actual) ** 2)
print(f"測試集均方誤差 (MSE): {mse:.2f}")
- new_data_x中,前113天是歷史數據,后30天是我們要預測的,因此其值都設置為0。
- 我們每次輸入40天的數據,并希望預測得到下一天,這樣依次將114天、115天直到最后一天的數據預測出來。
- test_x是我們每次輸入的40天的歷史序列,將其整理成[40, 1, 1]的格式,并進行歸一化,然后輸入模型。
- 得到的test_y也是一個40天的序列,最后一個值就是我們預測的下一天的值。使用反歸一化將其還原,就是預測的下一天的值。我們將其添加到new_data_x的相應位置中。
- hc就是模型的隱狀態,這樣不斷返回模型隱狀態,再輸入到模型中,應該是效果會比較好。這個我不太清楚。
4.4 可視化預測效果對比
# 可視化結果
plt.figure(figsize=(12, 6))
plt.plot(new_data_x, 'r', label='預測值')
plt.plot(data_x, 'b', label='真實值', alpha=0.3)
plt.axvline(x=train_size, color='g', linestyle='--', label='訓練/測試分界線')
plt.legend(loc='best')
plt.title('LSTM時間序列預測結果')
plt.xlabel('時間步')
plt.ylabel('值')
plt.grid(True)
plt.savefig('prediction_result.png')
plt.show()
print("預測結果已保存至: 'prediction_result.png'")# 放大查看測試集部分
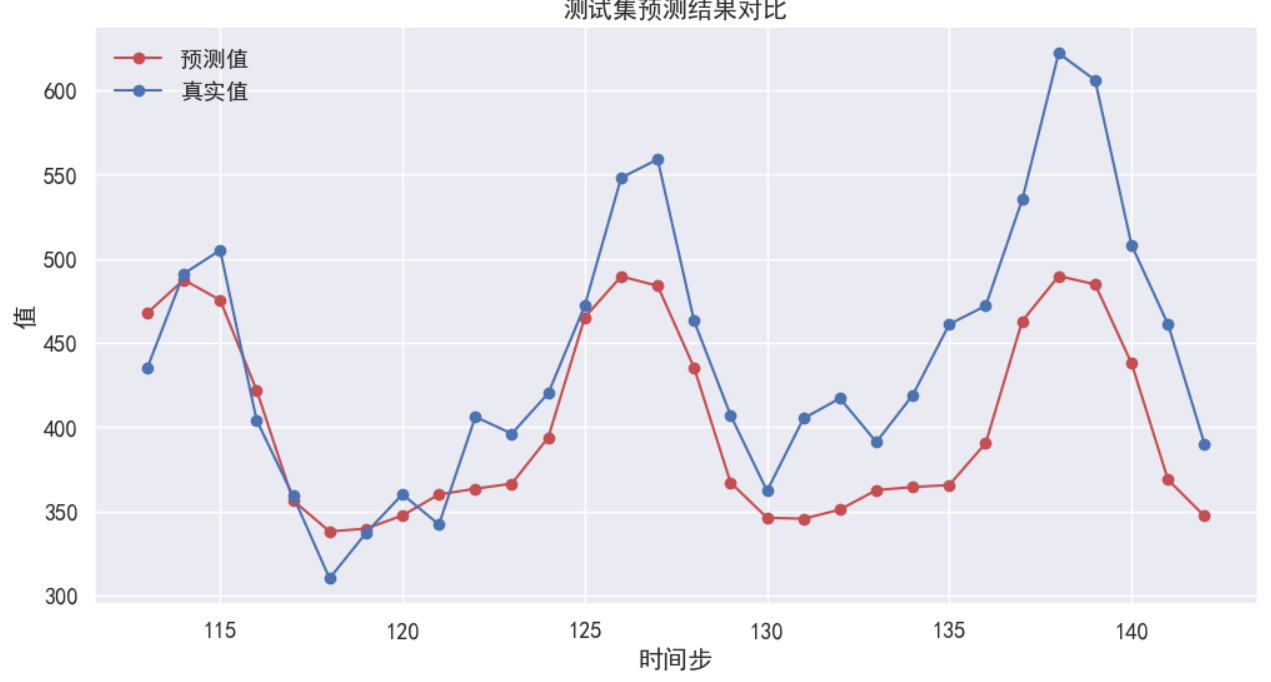
plt.figure(figsize=(12, 6))
plt.plot(range(train_size, len(data_x)), new_data_x[train_size:], 'r-o', label='預測值')
plt.plot(range(train_size, len(data_x)), data_x[train_size:], 'b-o', label='真實值')
plt.title('測試集預測結果對比')
plt.xlabel('時間步')
plt.ylabel('值')
plt.legend(loc='best')
plt.grid(True)
plt.show()
?數據結果: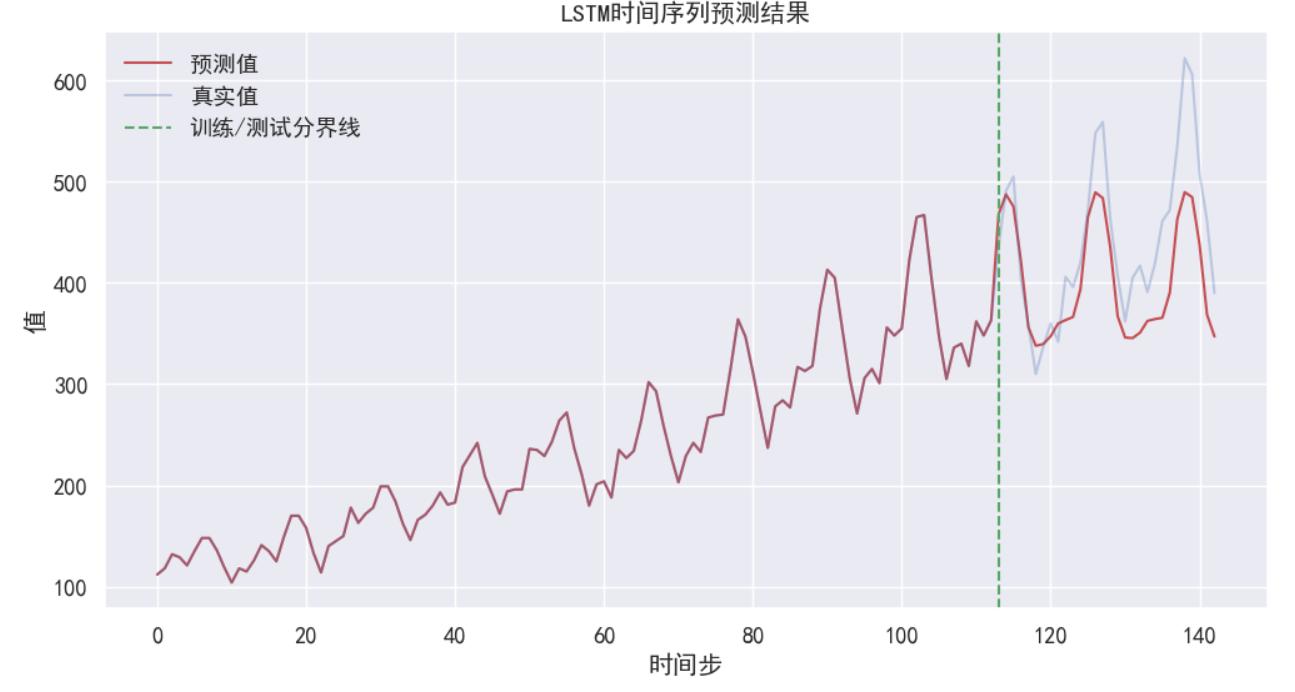
進一步改進方向
1. 調整網絡結構(層數、隱藏單元數)
2. 嘗試不同的窗口大小
3. 添加更多特征
4. 使用更復雜的損失函數
5. 應用正則化技術防止過擬合
參考文章:
使用LSTM進行簡單時間序列預測(入門全流程,包括如何整理輸入數據)_lstm 時間序列-CSDN博客
https://zhuanlan.zhihu.com/p/94757947
https://zhuanlan.zhihu.com/p/94757947
LSTM詳解-CSDN博客
https://zhuanlan.zhihu.com/p/36455374
)

深入講解教程)





—語言模型+讀取長序列數據(2))

)

的語法結構以及外部暴露)





)
)