摘要
隨著能源問題日益突出,電力能耗數據分析對于提高能源利用效率、降低能源消耗具有重要意義。本文設計并實現了一個基于 Python Django 和 Spark 的電力能耗數據分析系統。系統采用前后端分離架構,前端使用 Django 框架實現用戶界面,后端使用 Spark 框架進行電力能耗數據的處理和分析。系統實現了數據采集、數據清洗、數據存儲、數據分析和數據可視化等功能,為電力能耗管理提供了有力的支持。實驗結果表明,該系統能夠高效地處理和分析大規模電力能耗數據,為能源管理決策提供科學依據。
1 引言
1.1 研究背景與意義
隨著全球經濟的快速發展,能源需求不斷增長,能源問題日益成為全球關注的焦點。電力作為現代社會最主要的能源之一,其消耗情況直接關系到能源利用效率和環境保護。因此,對電力能耗數據進行分析和管理,對于提高能源利用效率、降低能源消耗、實現可持續發展具有重要意義。
傳統的電力能耗數據分析方法存在處理速度慢、分析能力有限等問題,難以滿足大規模電力能耗數據的處理和分析需求。隨著大數據技術的快速發展,特別是 Apache Spark 等分布式計算框架的出現,為電力能耗數據分析提供了新的技術手段。Spark 具有高效、快速、靈活等特點,能夠處理大規模數據,并提供豐富的數據分析工具和算法。
本文設計并實現了一個基于 Python Django 和 Spark 的電力能耗數據分析系統,旨在利用大數據技術對電力能耗數據進行高效處理和分析,為能源管理決策提供科學依據。
1.2 國內外研究現狀
在國外,電力能耗數據分析系統的研究和應用已經相對成熟。許多發達國家都建立了完善的電力能耗數據采集和分析系統,用于監測和管理電力能耗情況。例如,美國的智能電網項目、歐盟的能源效率指令等,都強調了對電力能耗數據的采集和分析,以提高能源利用效率。
在國內,隨著大數據、人工智能等技術的快速發展,電力能耗數據分析系統的研究和應用也得到了越來越多的關注。許多電力企業和科研機構都開展了相關的研究和實踐工作,開發了一些電力能耗數據分析系統。例如,國家電網公司的智能電網數據平臺、南方電網公司的電力大數據分析系統等,都為電力能耗管理提供了有力的支持。
然而,目前國內的電力能耗數據分析系統還存在一些不足之處,如數據采集不全面、數據分析方法單一、數據可視化效果不佳等。因此,需要進一步加強電力能耗數據分析系統的研究和開發,提高系統的性能和功能。
1.3 研究內容與方法
本文的研究內容主要包括以下幾個方面:
- 電力能耗數據分析系統的需求分析,包括功能需求、性能需求和安全需求。
- 系統的總體設計,包括架構設計、功能模塊設計和數據庫設計。
- 系統的詳細設計與實現,包括數據采集模塊、數據清洗模塊、數據存儲模塊、數據分析模塊和數據可視化模塊的設計與實現。
- 系統的測試與優化,包括功能測試、性能測試和用戶體驗測試等。
- 系統的部署與應用,包括系統的部署環境、部署流程和應用效果等。
本文采用的研究方法主要包括以下幾種:
- 文獻研究法:通過查閱相關文獻,了解國內外電力能耗數據分析系統的研究現狀和發展趨勢,為系統的設計和實現提供理論支持。
- 需求分析法:通過問卷調查、用戶訪談等方式,了解電力企業和能源管理部門對電力能耗數據分析系統的需求和期望,為系統的功能設計提供依據。
- 系統設計法:采用面向對象的設計方法,對系統進行總體設計和詳細設計,確保系統的可擴展性和可維護性。
- 實驗研究法:通過實際測試和實驗,驗證系統的功能和性能,對系統進行優化和改進。
2 系統需求分析
2.1 功能需求
基于 Python Django 和 Spark 的電力能耗數據分析系統的功能需求主要包括以下幾個方面:
- 數據采集功能:支持從各種數據源采集電力能耗數據,包括電表、傳感器、SCADA 系統等。
- 數據清洗功能:對采集到的電力能耗數據進行清洗和預處理,去除噪聲數據和異常值。
- 數據存儲功能:將清洗后的電力能耗數據存儲到數據庫中,支持數據的高效存儲和查詢。
- 數據分析功能:對電力能耗數據進行分析,包括統計分析、趨勢分析、異常檢測、預測分析等。
- 數據可視化功能:將分析結果以圖表、報表等形式進行可視化展示,支持交互式查詢和分析。
- 用戶管理功能:支持用戶的注冊、登錄、權限管理等功能。
- 系統管理功能:支持系統參數配置、數據備份與恢復、日志管理等功能。
2.2 性能需求
基于 Python Django 和 Spark 的電力能耗數據分析系統的性能需求主要包括以下幾個方面:
- 數據處理能力:系統應能夠高效處理大規模電力能耗數據,支持每秒數千條數據的采集和處理。
- 數據分析速度:系統應能夠快速完成各種數據分析任務,響應時間應控制在合理范圍內。
- 系統可用性:系統應具有高可用性,保證 7×24 小時不間斷運行。
- 數據安全性:系統應保證電力能耗數據的安全性和完整性,防止數據泄露和篡改。
2.3 安全需求
基于 Python Django 和 Spark 的電力能耗數據分析系統的安全需求主要包括以下幾個方面:
- 用戶認證與授權:系統應支持用戶認證和授權機制,確保只有授權用戶才能訪問系統資源。
- 數據加密:系統應對敏感數據進行加密處理,確保數據在傳輸和存儲過程中的安全性。
- 訪問控制:系統應實現細粒度的訪問控制,限制用戶對系統資源的訪問權限。
- 安全審計:系統應記錄用戶的操作日志,支持安全審計和追蹤。
- 備份與恢復:系統應定期備份數據,確保在發生故障時能夠快速恢復數據。
3 系統總體設計
3.1 系統架構設計
基于 Python Django 和 Spark 的電力能耗數據分析系統采用分層架構設計,主要包括以下幾層:
- 數據采集層:負責從各種數據源采集電力能耗數據,并將數據傳輸到數據處理層。
- 數據處理層:負責對采集到的電力能耗數據進行清洗、轉換和預處理,將數據轉換為適合分析的格式。
- 數據分析層:負責對處理后的數據進行分析,包括統計分析、趨勢分析、異常檢測、預測分析等。
- 數據存儲層:負責存儲采集到的原始數據和分析結果,包括關系型數據庫和分布式文件系統。
- 應用服務層:負責提供系統的業務邏輯和服務接口,包括用戶管理、數據查詢、分析報告等。
- 前端展示層:負責提供用戶界面,包括 Web 界面和移動應用界面,使用戶能夠直觀地查看和分析電力能耗數據。
系統架構圖如下所示:
3.2 功能模塊設計
基于 Python Django 和 Spark 的電力能耗數據分析系統的功能模塊設計如下:
- 數據采集模塊:負責從各種數據源采集電力能耗數據,并將數據傳輸到數據處理層。該模塊包括數據采集器、數據傳輸和數據接收三個子模塊。
- 數據清洗模塊:負責對采集到的電力能耗數據進行清洗和預處理,去除噪聲數據和異常值。該模塊包括數據過濾、數據去重、數據填充和數據標準化四個子模塊。
- 數據存儲模塊:負責將清洗后的電力能耗數據存儲到數據庫中,支持數據的高效存儲和查詢。該模塊包括關系型數據庫存儲和分布式文件系統存儲兩個子模塊。
- 數據分析模塊:負責對電力能耗數據進行分析,包括統計分析、趨勢分析、異常檢測、預測分析等。該模塊包括數據統計、數據挖掘、機器學習和深度學習四個子模塊。
- 數據可視化模塊:負責將分析結果以圖表、報表等形式進行可視化展示,支持交互式查詢和分析。該模塊包括圖表生成、報表生成和地圖展示三個子模塊。
- 用戶管理模塊:負責用戶的注冊、登錄、權限管理等功能。該模塊包括用戶注冊、用戶登錄、用戶信息管理和權限管理四個子模塊。
- 系統管理模塊:負責系統參數配置、數據備份與恢復、日志管理等功能。該模塊包括系統配置、數據備份、數據恢復和日志管理四個子模塊。
3.3 數據庫設計
基于 Python Django 和 Spark 的電力能耗數據分析系統的數據庫設計主要包括以下幾個表:
- 用戶表(user):存儲系統用戶的基本信息,包括用戶 ID、用戶名、密碼、郵箱、角色等字段。
sql
CREATE TABLE `user` (`id` int(11) NOT NULL AUTO_INCREMENT,`username` varchar(50) NOT NULL COMMENT '用戶名',`password` varchar(100) NOT NULL COMMENT '密碼',`email` varchar(50) DEFAULT NULL COMMENT '郵箱',`role` int(11) NOT NULL DEFAULT '1' COMMENT '角色(1:普通用戶,2:管理員)',`status` int(11) NOT NULL DEFAULT '1' COMMENT '狀態(1:啟用,0:禁用)',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間',PRIMARY KEY (`id`),UNIQUE KEY `username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用戶表';
- 數據源表(data_source):存儲電力能耗數據的數據源信息,包括數據源 ID、數據源名稱、數據源類型、數據源地址等字段。
sql
CREATE TABLE `data_source` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(50) NOT NULL COMMENT '數據源名稱',`type` varchar(20) NOT NULL COMMENT '數據源類型(電表、傳感器、SCADA等)',`address` varchar(100) NOT NULL COMMENT '數據源地址',`description` varchar(255) DEFAULT NULL COMMENT '數據源描述',`status` int(11) NOT NULL DEFAULT '1' COMMENT '狀態(1:啟用,0:禁用)',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='數據源表';
- 電力設備表(power_device):存儲電力設備的基本信息,包括設備 ID、設備名稱、設備類型、所屬部門、安裝位置等字段。
sql
CREATE TABLE `power_device` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(50) NOT NULL COMMENT '設備名稱',`type` varchar(20) NOT NULL COMMENT '設備類型(變壓器、電機、空調等)',`department` varchar(50) DEFAULT NULL COMMENT '所屬部門',`location` varchar(100) DEFAULT NULL COMMENT '安裝位置',`description` varchar(255) DEFAULT NULL COMMENT '設備描述',`status` int(11) NOT NULL DEFAULT '1' COMMENT '狀態(1:啟用,0:禁用)',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='電力設備表';
- 電力能耗數據表(power_consumption):存儲電力能耗的詳細數據,包括數據 ID、設備 ID、數據源 ID、采集時間、能耗值等字段。
sql
CREATE TABLE `power_consumption` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`device_id` int(11) NOT NULL COMMENT '設備ID',`source_id` int(11) NOT NULL COMMENT '數據源ID',`collect_time` datetime NOT NULL COMMENT '采集時間',`power_value` decimal(10,2) NOT NULL COMMENT '能耗值(kWh)',`voltage` decimal(10,2) DEFAULT NULL COMMENT '電壓(V)',`current` decimal(10,2) DEFAULT NULL COMMENT '電流(A)',`power_factor` decimal(10,2) DEFAULT NULL COMMENT '功率因數',`frequency` decimal(10,2) DEFAULT NULL COMMENT '頻率(Hz)',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',PRIMARY KEY (`id`),KEY `idx_device_id` (`device_id`),KEY `idx_collect_time` (`collect_time`),FOREIGN KEY (`device_id`) REFERENCES `power_device` (`id`),FOREIGN KEY (`source_id`) REFERENCES `data_source` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='電力能耗數據表';
- 異常記錄表(abnormal_record):存儲電力能耗數據中的異常記錄,包括記錄 ID、設備 ID、異常類型、異常時間、異常描述等字段。
sql
CREATE TABLE `abnormal_record` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`device_id` int(11) NOT NULL COMMENT '設備ID',`abnormal_type` varchar(50) NOT NULL COMMENT '異常類型(過載、欠壓、波動等)',`abnormal_time` datetime NOT NULL COMMENT '異常時間',`abnormal_value` decimal(10,2) NOT NULL COMMENT '異常值',`normal_range` varchar(100) NOT NULL COMMENT '正常范圍',`description` varchar(255) DEFAULT NULL COMMENT '異常描述',`status` int(11) NOT NULL DEFAULT '1' COMMENT '狀態(1:未處理,2:已處理)',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間',PRIMARY KEY (`id`),KEY `idx_device_id` (`device_id`),KEY `idx_abnormal_time` (`abnormal_time`),FOREIGN KEY (`device_id`) REFERENCES `power_device` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='異常記錄表';
- 預測結果表(prediction_result):存儲電力能耗預測的結果,包括結果 ID、設備 ID、預測時間、預測值、預測方法等字段。
sql
CREATE TABLE `prediction_result` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`device_id` int(11) NOT NULL COMMENT '設備ID',`predict_time` datetime NOT NULL COMMENT '預測時間',`predict_value` decimal(10,2) NOT NULL COMMENT '預測值(kWh)',`method` varchar(50) NOT NULL COMMENT '預測方法',`confidence` decimal(10,2) DEFAULT NULL COMMENT '置信度',`description` varchar(255) DEFAULT NULL COMMENT '預測描述',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',PRIMARY KEY (`id`),KEY `idx_device_id` (`device_id`),KEY `idx_predict_time` (`predict_time`),FOREIGN KEY (`device_id`) REFERENCES `power_device` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='預測結果表';
- 分析報告表(analysis_report):存儲電力能耗分析的報告,包括報告 ID、報告名稱、報告類型、生成時間、報告內容等字段。
sql
CREATE TABLE `analysis_report` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(100) NOT NULL COMMENT '報告名稱',`type` varchar(50) NOT NULL COMMENT '報告類型(日報、周報、月報、年報等)',`start_time` datetime NOT NULL COMMENT '開始時間',`end_time` datetime NOT NULL COMMENT '結束時間',`content` text NOT NULL COMMENT '報告內容',`user_id` int(11) NOT NULL COMMENT '生成用戶ID',`status` int(11) NOT NULL DEFAULT '1' COMMENT '狀態(1:正常,0:已刪除)',`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間',`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間',PRIMARY KEY (`id`),KEY `idx_user_id` (`user_id`),FOREIGN KEY (`user_id`) REFERENCES `user` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='分析報告表';
4 系統詳細設計與實現
4.1 數據采集模塊設計與實現
數據采集模塊是電力能耗數據分析系統的基礎,負責從各種數據源采集電力能耗數據。本系統采用分布式采集架構,支持多種數據源的接入,包括電表、傳感器、SCADA 系統等。
數據采集模塊的核心代碼如下:
python
運行
import threading
import time
import logging
import pymysql
from kafka import KafkaProducerclass DataCollector:def __init__(self, config):self.config = configself.logger = logging.getLogger('data_collector')self.producer = KafkaProducer(bootstrap_servers=config['kafka_servers'],value_serializer=lambda x: x.encode('utf-8'))self.running = Falseself.threads = []def start(self):"""啟動數據采集服務"""self.running = Trueself.logger.info('數據采集服務已啟動')# 獲取所有數據源data_sources = self.get_data_sources()# 為每個數據源創建一個采集線程for source in data_sources:thread = threading.Thread(target=self.collect_data, args=(source,))thread.daemon = Truethread.start()self.threads.append(thread)self.logger.info(f'已啟動數據源 {source["name"]} 的采集線程')def stop(self):"""停止數據采集服務"""self.running = Falseself.logger.info('數據采集服務已停止')# 等待所有線程結束for thread in self.threads:thread.join(timeout=5)# 關閉Kafka生產者self.producer.close()def get_data_sources(self):"""獲取所有數據源"""try:conn = pymysql.connect(host=self.config['db_host'],port=self.config['db_port'],user=self.config['db_user'],password=self.config['db_password'],database=self.config['db_name'])with conn.cursor(pymysql.cursors.DictCursor) as cursor:sql = "SELECT * FROM data_source WHERE status = 1"cursor.execute(sql)return cursor.fetchall()except Exception as e:self.logger.error(f'獲取數據源失敗: {str(e)}')return []finally:if conn:conn.close()def collect_data(self, source):"""從指定數據源采集數據"""source_id = source['id']source_type = source['type']source_address = source['address']# 根據數據源類型選擇相應的采集器if source_type == 'meter':collector = MeterDataCollector(source_address)elif source_type == 'sensor':collector = SensorDataCollector(source_address)elif source_type == 'scada':collector = ScadaDataCollector(source_address)else:self.logger.error(f'不支持的數據源類型: {source_type}')returnwhile self.running:try:# 采集數據data = collector.collect()if data:# 處理采集到的數據processed_data = self.process_data(data, source_id)# 發送數據到Kafkaself.send_to_kafka(processed_data)self.logger.info(f'從數據源 {source["name"]} 采集到 {len(data)} 條數據')else:self.logger.warning(f'從數據源 {source["name"]} 采集到的數據為空')# 休眠一段時間后再次采集time.sleep(self.config['collect_interval'])except Exception as e:self.logger.error(f'從數據源 {source["name"]} 采集數據失敗: {str(e)}')time.sleep(self.config['collect_interval'])def process_data(self, data, source_id):"""處理采集到的數據"""processed_data = []for item in data:# 添加數據源ID和采集時間item['source_id'] = source_iditem['collect_time'] = time.strftime('%Y-%m-%d %H:%M:%S')# 數據格式驗證if 'device_id' not in item or 'power_value' not in item:self.logger.warning(f'數據格式不正確: {item}')continueprocessed_data.append(item)return processed_datadef send_to_kafka(self, data):"""發送數據到Kafka"""try:for item in data:self.producer.send(self.config['kafka_topic'], str(item))self.producer.flush()except Exception as e:self.logger.error(f'發送數據到Kafka失敗: {str(e)}')
4.2 數據分析模塊設計與實現
數據分析模塊是電力能耗數據分析系統的核心,負責對采集到的電力能耗數據進行分析和挖掘。本系統采用 Spark 框架進行數據分析,支持多種分析算法和模型。
數據分析模塊的核心代碼如下:
python
運行
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation import RegressionEvaluator
import logging
import jsonclass PowerAnalysis:def __init__(self, config):self.config = configself.logger = logging.getLogger('power_analysis')self.spark = SparkSession.builder \.appName("PowerAnalysis") \.config("spark.sql.shuffle.partitions", "10") \.getOrCreate()def analyze_daily_consumption(self, start_date, end_date):"""分析每日電力能耗"""try:# 讀取數據df = self.read_power_data(start_date, end_date)# 按日期分組統計總能耗daily_df = df.groupBy(to_date("collect_time").alias("date")) \.agg(sum("power_value").alias("total_power")) \.orderBy("date")return daily_df.toPandas()except Exception as e:self.logger.error(f'分析每日電力能耗失敗: {str(e)}')return Nonedef analyze_device_consumption(self, device_id, start_date, end_date):"""分析特定設備的電力能耗"""try:# 讀取數據df = self.read_power_data(start_date, end_date)# 篩選特定設備的數據device_df = df.filter(col("device_id") == device_id)# 按小時統計能耗hourly_df = device_df.groupBy(hour("collect_time").alias("hour")) \.agg(avg("power_value").alias("avg_power")) \.orderBy("hour")return hourly_df.toPandas()except Exception as e:self.logger.error(f'分析特定設備的電力能耗失敗: {str(e)}')return Nonedef detect_abnormal(self, device_id, start_date, end_date):"""檢測電力能耗異常"""try:# 讀取數據df = self.read_power_data(start_date, end_date)# 篩選特定設備的數據device_df = df.filter(col("device_id") == device_id)# 計算統計指標stats = device_df.select(avg("power_value").alias("mean"),stddev("power_value").alias("std")).collect()[0]mean = stats["mean"]std = stats["std"]# 定義異常閾值upper_threshold = mean + 3 * stdlower_threshold = mean - 3 * std# 檢測異常abnormal_df = device_df.filter((col("power_value") > upper_threshold) | (col("power_value") < lower_threshold))return abnormal_df.toPandas()except Exception as e:self.logger.error(f'檢測電力能耗異常失敗: {str(e)}')return Nonedef predict_consumption(self, device_id, days=7):"""預測未來電力能耗"""try:# 獲取歷史數據end_date = datetime.now().strftime('%Y-%m-%d')start_date = (datetime.now() - timedelta(days=30)).strftime('%Y-%m-%d')df = self.read_power_data(start_date, end_date)# 篩選特定設備的數據device_df = df.filter(col("device_id") == device_id)# 按天統計總能耗daily_df = device_df.groupBy(to_date("collect_time").alias("date")) \.agg(sum("power_value").alias("total_power")) \.orderBy("date")# 準備特征daily_df = daily_df.withColumn("day_of_week", dayofweek("date"))daily_df = daily_df.withColumn("day_of_month", dayofmonth("date"))# 轉換為向量格式assembler = VectorAssembler(inputCols=["day_of_week", "day_of_month"],outputCol="features")data = assembler.transform(daily_df).select("features", "total_power")# 劃分訓練集和測試集train_data, test_data = data.randomSplit([0.8, 0.2])# 訓練線性回歸模型lr = LinearRegression(featuresCol="features", labelCol="total_power")model = lr.fit(train_data)# 評估模型predictions = model.transform(test_data)evaluator = RegressionEvaluator(labelCol="total_power", predictionCol="prediction", metricName="rmse")rmse = evaluator.evaluate(predictions)self.logger.info(f"模型評估結果: RMSE = {rmse}")# 生成未來日期future_dates = []for i in range(1, days+1):future_date = (datetime.now() + timedelta(days=i)).strftime('%Y-%m-%d')future_dates.append({"date": future_date,"day_of_week": datetime.strptime(future_date, '%Y-%m-%d').isoweekday(),"day_of_month": datetime.strptime(future_date, '%Y-%m-%d').day})# 創建未來數據的DataFramefuture_df = self.spark.createDataFrame(future_dates)# 轉換為向量格式future_data = assembler.transform(future_df).select("features", "date")# 預測未來能耗predictions = model.transform(future_data)return predictions.select("date", "prediction").toPandas()except Exception as e:self.logger.error(f'預測未來電力能耗失敗: {str(e)}')return Nonedef read_power_data(self, start_date, end_date):"""讀取電力能耗數據"""try:# 從HDFS讀取數據df = self.spark.read \.format("parquet") \.load(self.config['data_path'])# 篩選指定日期范圍內的數據df = df.filter((col("collect_time") >= start_date) & (col("collect_time") <= end_date))return dfexcept Exception as e:self.logger.error(f'讀取電力能耗數據失敗: {str(e)}')return None
4.3 數據可視化模塊設計與實現
數據可視化模塊是電力能耗數據分析系統的重要組成部分,負責將分析結果以直觀的圖表和報表形式展示給用戶。本系統采用 Django 框架實現 Web 界面,并使用 ECharts 進行數據可視化。
數據可視化模塊的核心代碼如下:
python
運行
from django.shortcuts import render
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
import json
import pandas as pd
from .models import PowerConsumption, PowerDevice, AbnormalRecord, PredictionResult
from .analysis import PowerAnalysis
from datetime import datetime, timedelta@csrf_exempt
def index(request):"""系統首頁"""return render(request, 'power_analysis/index.html')def device_list(request):"""設備列表頁面"""devices = PowerDevice.objects.all()return render(request, 'power_analysis/device_list.html', {'devices': devices})def device_detail(request, device_id):"""設備詳情頁面"""device = PowerDevice.objects.get(id=device_id)# 獲取今日能耗today = datetime.now().strftime('%Y-%m-%d')today_data = PowerConsumption.objects.filter(device_id=device_id, collect_time__startswith=today).order_by('collect_time')# 轉換為DataFramedf = pd.DataFrame(list(today_data.values()))# 準備圖表數據time_labels = []power_values = []if not df.empty:df['collect_time'] = pd.to_datetime(df['collect_time'])df.set_index('collect_time', inplace=True)# 按小時重采樣hourly_data = df['power_value'].resample('H').sum()time_labels = hourly_data.index.strftime('%H:%M').tolist()power_values = hourly_data.tolist()# 獲取最近異常recent_abnormal = AbnormalRecord.objects.filter(device_id=device_id, status=1).order_by('-abnormal_time')[:5]# 獲取預測數據prediction_data = PredictionResult.objects.filter(device_id=device_id,predict_time__gte=datetime.now()).order_by('predict_time')[:7]prediction_dates = []prediction_values = []for item in prediction_data:prediction_dates.append(item.predict_time.strftime('%Y-%m-%d'))prediction_values.append(float(item.predict_value))return render(request, 'power_analysis/device_detail.html', {'device': device,'time_labels': json.dumps(time_labels),'power_values': json.dumps(power_values),'abnormal_records': recent_abnormal,'prediction_dates': json.dumps(prediction_dates),'prediction_values': json.dumps(prediction_values)})def daily_analysis(request):"""每日能耗分析頁面"""# 獲取最近7天的日期end_date = datetime.now()start_date = end_date - timedelta(days=7)dates = []for i in range(7):date = (start_date + timedelta(days=i)).strftime('%Y-%m-%d')dates.append(date)# 獲取每日總能耗daily_data = []for date in dates:total_power = PowerConsumption.objects.filter(collect_time__startswith=date).aggregate(total=Sum('power_value'))['total'] or 0daily_data.append({'date': date,'total_power': round(total_power, 2)})# 準備圖表數據date_labels = [item['date'] for item in daily_data]power_values = [item['total_power'] for item in daily_data]return render(request, 'power_analysis/daily_analysis.html', {'date_labels': json.dumps(date_labels),'power_values': json.dumps(power_values)})def abnormal_analysis(request):"""異常分析頁面"""# 獲取所有異常記錄abnormal_records = AbnormalRecord.objects.all().order_by('-abnormal_time')return render(request, 'power_analysis/abnormal_analysis.html', {'abnormal_records': abnormal_records})def prediction_analysis(request):"""預測分析頁面"""# 獲取所有設備devices = PowerDevice.objects.all()# 獲取預測數據prediction_data = []for device in devices:device_prediction = PredictionResult.objects.filter(device_id=device.id,predict_time__gte=datetime.now()).order_by('predict_time')[:7]dates = []values = []for item in device_prediction:dates.append(item.predict_time.strftime('%Y-%m-%d'))values.append(float(item.predict_value))prediction_data.append({'device_id': device.id,'device_name': device.name,'dates': dates,'values': values})return render(request, 'power_analysis/prediction_analysis.html', {'devices': devices,'prediction_data': json.dumps(prediction_data)})def api_get_device_data(request, device_id):"""獲取設備數據API"""# 獲取參數start_date = request.GET.get('start_date')end_date = request.GET.get('end_date')if not start_date or not end_date:return JsonResponse({'error': '缺少日期參數'}, status=400)# 調用分析服務analysis = PowerAnalysis()# 按小時分析hourly_data = analysis.analyze_device_consumption(device_id, start_date, end_date)if hourly_data is None:return JsonResponse({'error': '獲取數據失敗'}, status=500)# 轉換為JSONhourly_json = hourly_data.to_dict('records')# 異常檢測abnormal_data = analysis.detect_abnormal(device_id, start_date, end_date)if abnormal_data is None:return JsonResponse({'error': '獲取數據失敗'}, status=500)abnormal_json = abnormal_data.to_dict('records')return JsonResponse({'hourly_data': hourly_json,'abnormal_data': abnormal_json})
5 系統測試與優化
5.1 系統測試
為了驗證基于 Python Django 和 Spark 的電力能耗數據分析系統的功能和性能,進行了以下測試:
- 功能測試:對系統的各項功能進行測試,包括數據采集、數據清洗、數據分析、數據可視化等功能,確保功能正常運行。
- 性能測試:使用 JMeter 工具對系統的性能進行測試,模擬大量用戶并發訪問,測試系統的響應時間、吞吐量等性能指標。
- 安全測試:對系統的安全性進行測試,包括用戶認證、權限管理、數據加密等方面,確保系統的安全性。
- 兼容性測試:對系統在不同瀏覽器、不同操作系統上的兼容性進行測試,確保系統在各種環境下都能正常運行。
5.2 系統優化
在系統測試過程中,發現了一些性能瓶頸和問題,進行了以下優化:
- 數據處理優化:對 Spark 作業進行優化,調整分區數、緩存策略等,提高數據處理效率。
- 數據庫優化:對 MySQL 數據庫進行索引優化、查詢優化,提高數據庫的查詢性能。
- 緩存優化:使用 Redis 緩存熱門數據,減少數據庫訪問壓力。
- 前端優化:對前端頁面進行優化,壓縮 CSS 和 JavaScript 文件,優化圖片資源,提高頁面加載速度。
- 分布式部署:將系統部署到多臺服務器上,實現負載均衡,提高系統的并發處理能力。
6 結論與展望
6.1 研究成果總結
本論文設計并實現了一個基于 Python Django 和 Spark 的電力能耗數據分析系統。系統采用分層架構設計,包括數據采集層、數據處理層、數據分析層、數據存儲層、應用服務層和前端展示層。系統實現了數據采集、數據清洗、數據存儲、數據分析和數據可視化等功能,為電力能耗管理提供了有力的支持。
實驗結果表明,該系統能夠高效地處理和分析大規模電力能耗數據,為能源管理決策提供科學依據。系統具有良好的可擴展性和可維護性,能夠滿足不同規模電力企業的需求。
6.2 研究不足與展望
本論文的研究工作雖然取得了一定的成果,但仍存在一些不足之處:
- 系統的預測模型還可以進一步優化,提高預測的準確性和可靠性。
- 系統的異常檢測算法還可以進一步改進,提高異常檢測的靈敏度和特異性。
- 系統的用戶界面還可以進一步優化,提高用戶體驗。
- 系統的實時數據分析能力還可以進一步加強,支持更實時的電力能耗監控和預警。
未來的研究工作將主要集中在以下幾個方面:
- 引入深度學習算法,優化電力能耗預測模型,提高預測的準確性和可靠性。
- 研究更加高效的異常檢測算法,提高異常檢測的靈敏度和特異性。
- 優化系統的用戶界面,提高用戶體驗,支持更多的交互功能。
- 加強系統的實時數據分析能力,支持更實時的電力能耗監控和預警。
- 研究電力能耗數據的隱私保護技術,確保用戶數據的安全性和隱私性。
通過以上研究工作的開展,相信基于 Python Django 和 Spark 的電力能耗數據分析系統將能夠更好地滿足電力企業和能源管理部門的需求,為提高能源利用效率、降低能源消耗做出更大的貢獻。
參考文獻
??? 博主介紹:碩士研究生,專注于信息化技術領域開發與管理,會使用java、標準c/c++等開發語言,以及畢業項目實戰?
?????? 從事基于java BS架構、CS架構、c/c++ 編程工作近16年,擁有近12年的管理工作經驗,擁有較豐富的技術架構思想、較扎實的技術功底和資深的項目管理經驗。
?????? 先后擔任過技術總監、部門經理、項目經理、開發組長、java高級工程師及c++工程師等職位,在工業互聯網、國家標識解析體系、物聯網、分布式集群架構、大數據通道處理、接口開發、遠程教育、辦公OA、財務軟件(工資、記賬、決策、分析、報表統計等方面)、企業內部管理軟件(ERP、CRM等)、arggis地圖等信息化建設領域有較豐富的實戰工作經驗;擁有BS分布式架構集群、數據庫負載集群架構、大數據存儲集群架構,以及高并發分布式集群架構的設計、開發和部署實戰經驗;擁有大并發訪問、大數據存儲、即時消息等瓶頸解決方案和實戰經驗。
?????? 擁有產品研發和發明專利申請相關工作經驗,完成發明專利構思、設計、編寫、申請等工作,并獲得發明專利1枚。
-----------------------------------------------------------------------------------
????? 大家在畢設選題、項目升級、論文寫作,就業畢業等相關問題都可以給我留言咨詢,非常樂意幫助更多的人或加w 908925859。
相關博客地址:
csdn專業技術博客:https://blog.csdn.net/mr_lili_1986?type=blog
Iteye博客:??????? https://www.iteye.com/blog/user/mr-lili-1986-163-com
門戶:http://www.petsqi.cn
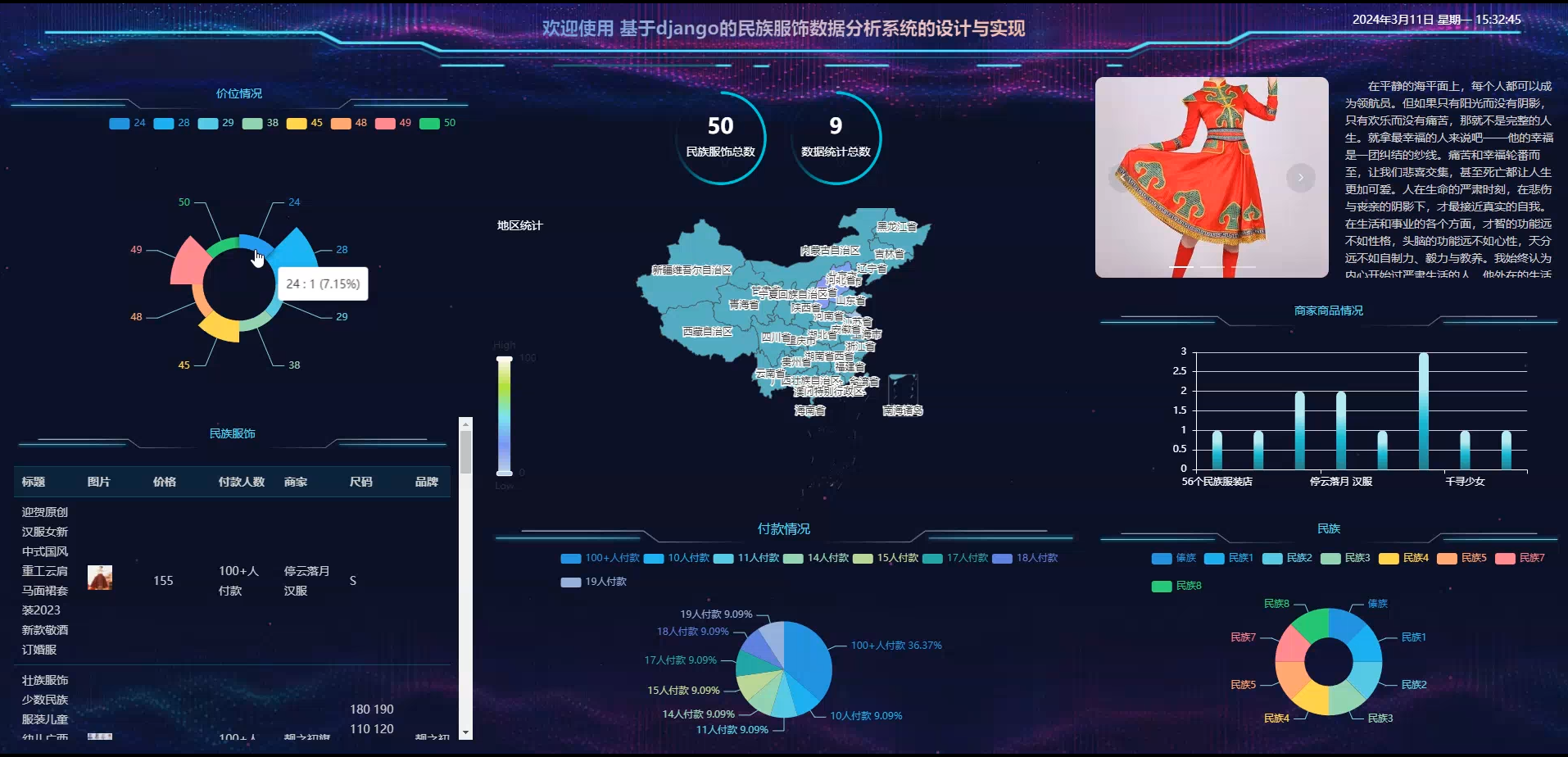
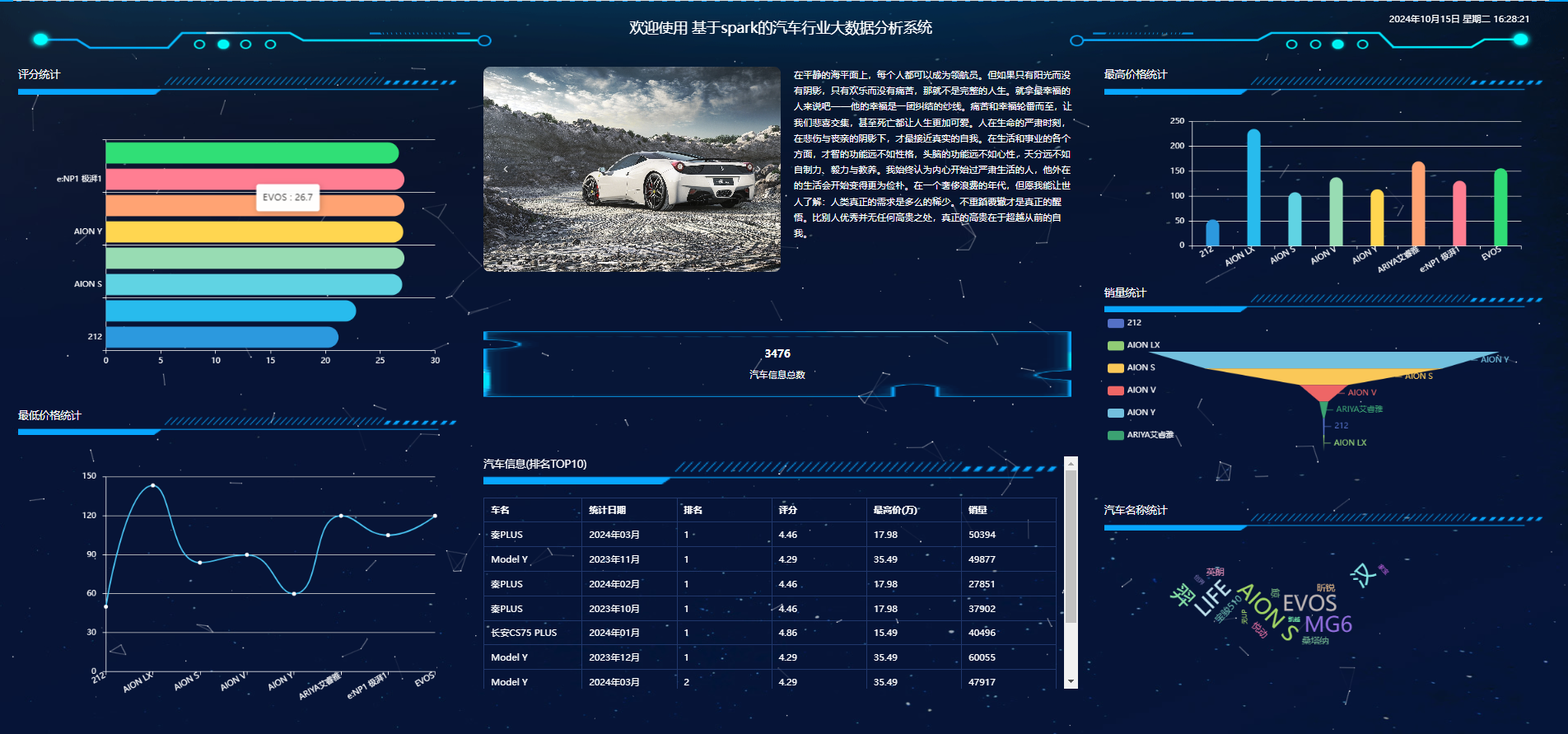
七、其他案例:?


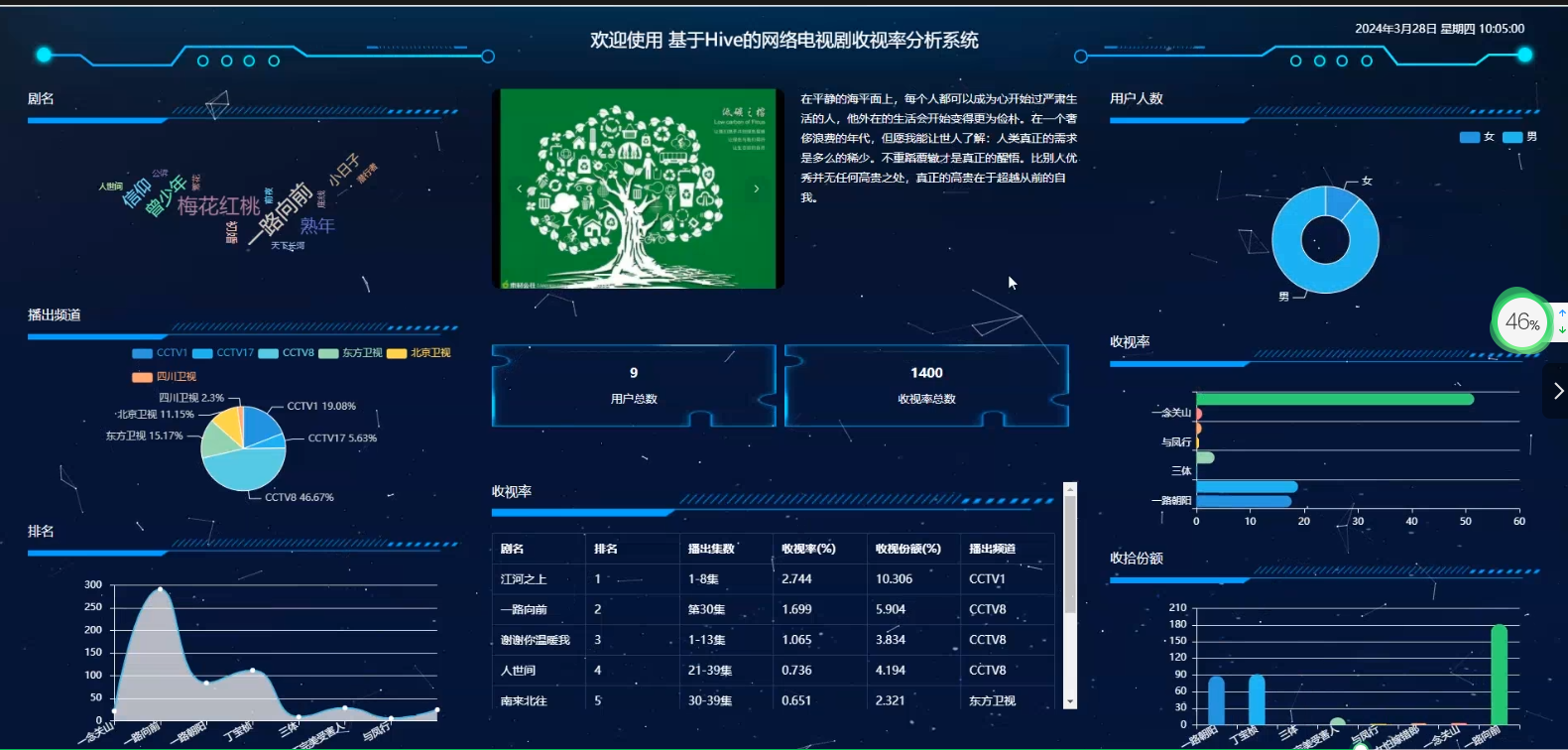

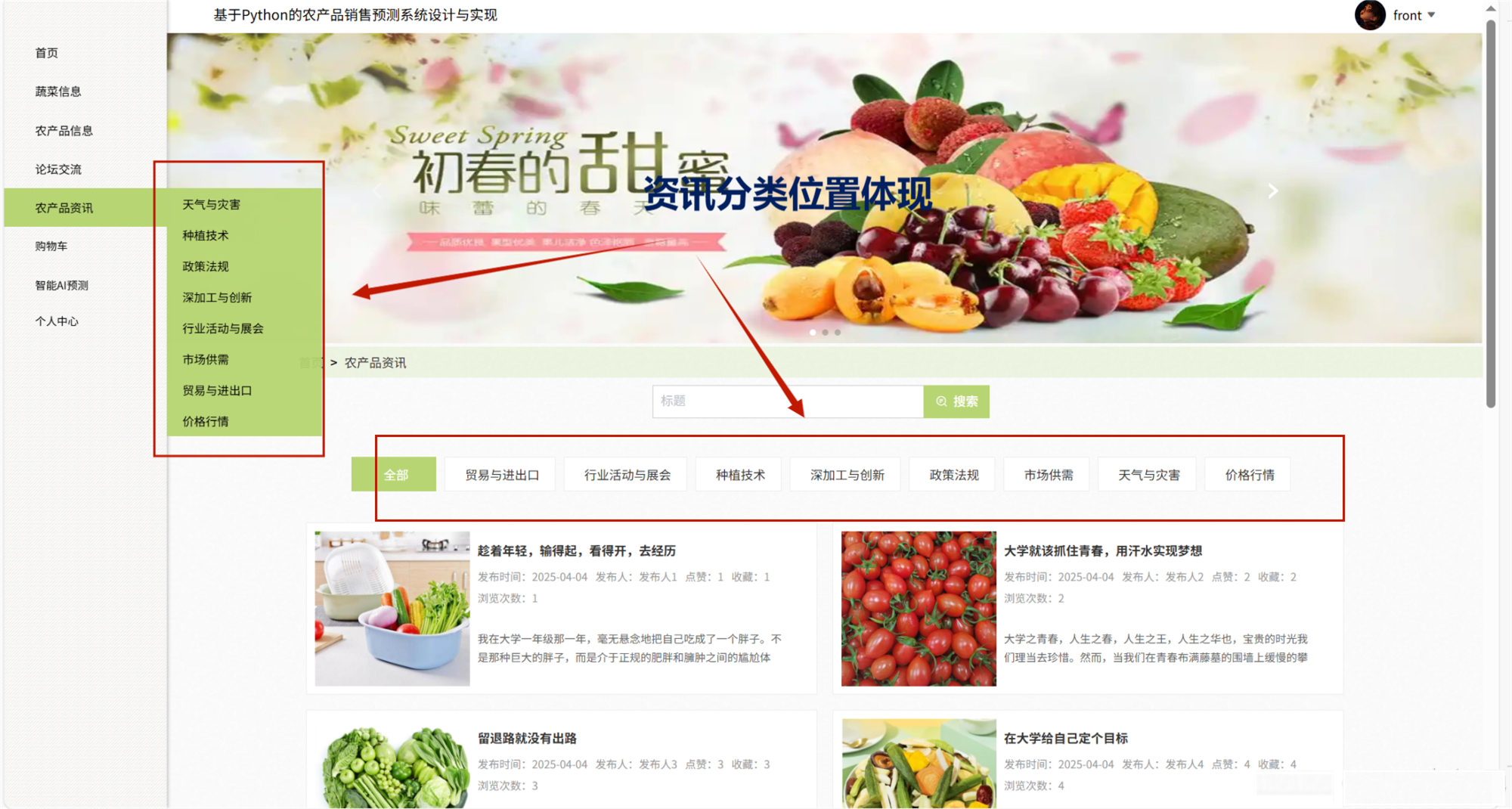
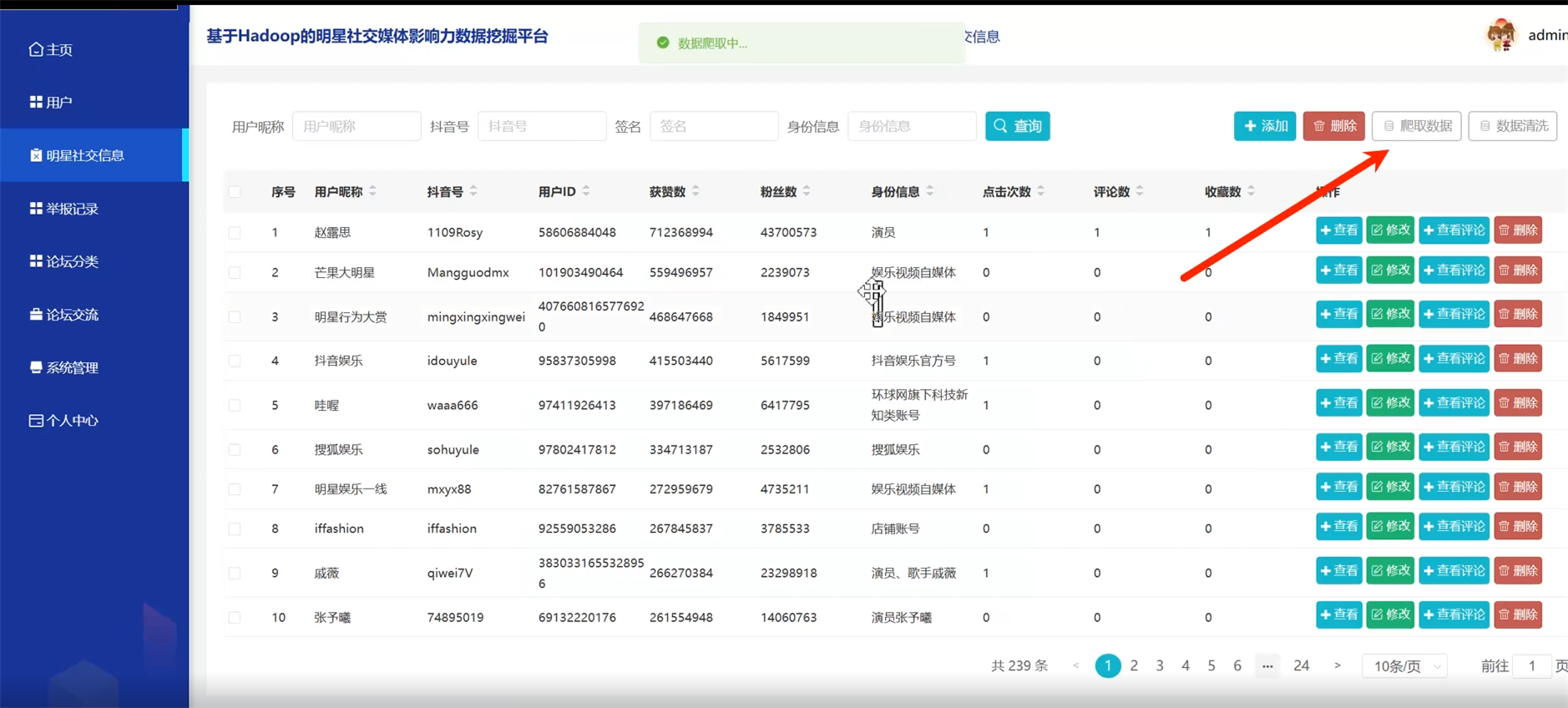
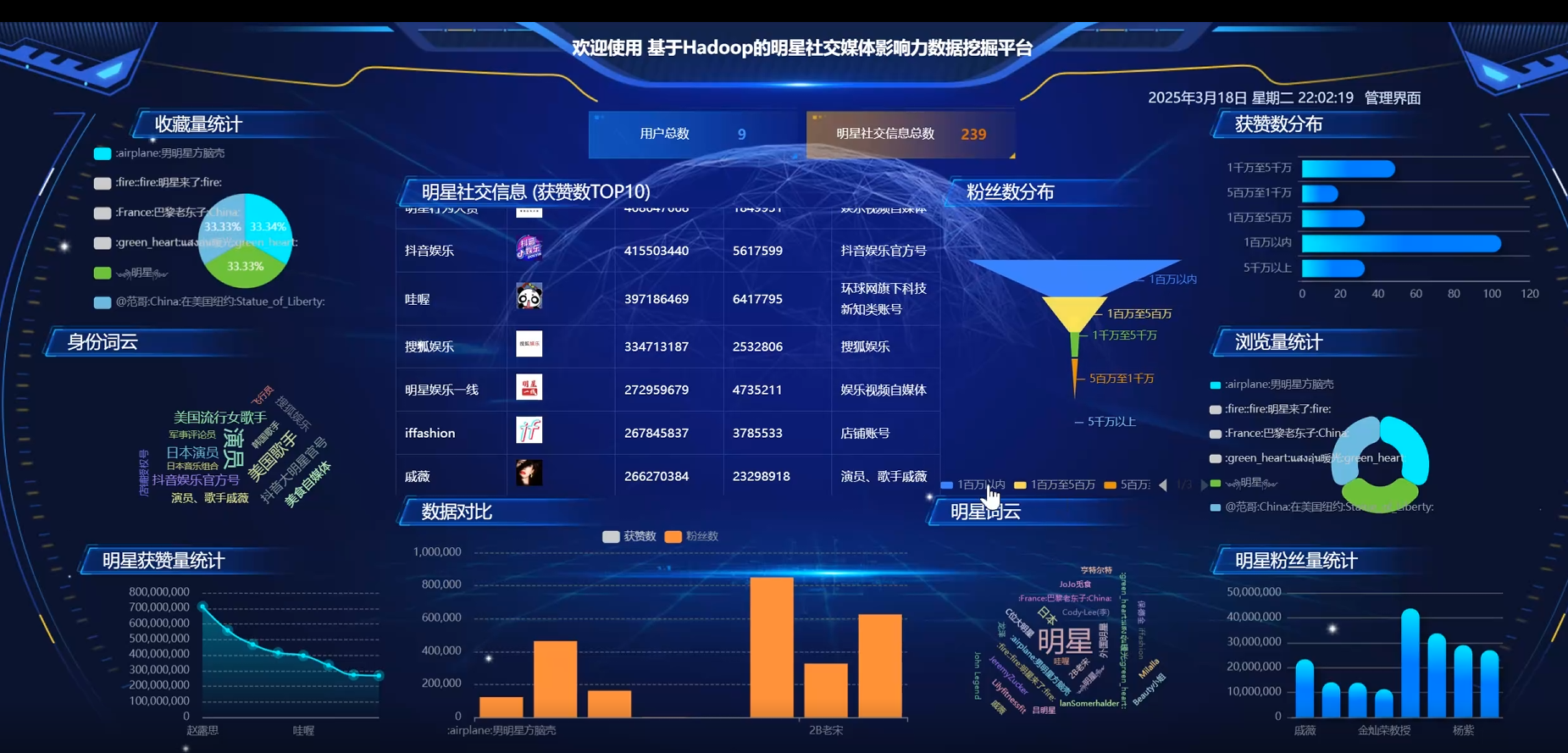


?
??
?

)






)











