1.簡介
Kubernetes的本質是一組服務器集群,它可以在集群的每個節點上運行特定的程序,來對節點中的容器進行管理。目的是實現資源管理的自動化,主要提供了如下的主要功能:
- 自我修復:一旦某一個容器崩潰,能夠在1秒中左右迅速啟動新的容器
- 彈性伸縮:可以根據需要,自動對集群中正在運行的容器數量進行調整
- 服務發現:服務可以通過自動發現的形式找到它所依賴的服務
- 負載均衡:如果一個服務起動了多個容器,能夠自動實現請求的負載均衡
- 版本回退:如果發現新發布的程序版本有問題,可以立即回退到原來的版本
- 存儲編排:可以根據容器自身的需求自動創建存儲卷
2.組件
一個kubernetes集群主要是由控制節點(Master)、工作節點(Node)構成,每個節點上都會安裝不同的組件。
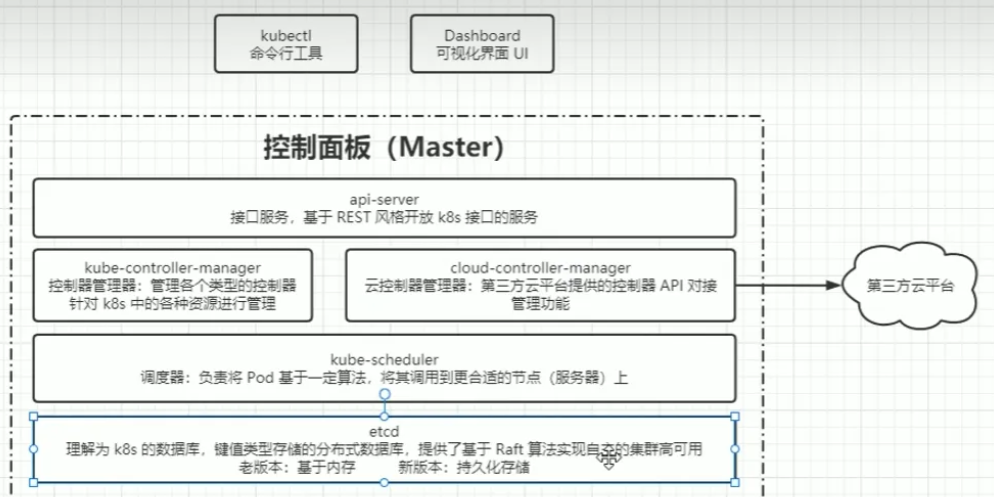
2.1Master
集群的控制平面,負責集群的決策 ( 管理 )
- ApiServer : 資源操作的唯一入口,接收用戶輸入的命令,提供認證、授權、API注冊和發現等機制
- Scheduler : 負責集群資源調度,按照預定的調度策略將Pod調度到相應的node節點上
- ControllerManager : 負責維護集群的狀態,比如程序部署安排、故障檢測、自動擴展、滾動更新等
- Etcd :負責存儲集群中各種資源對象的信息
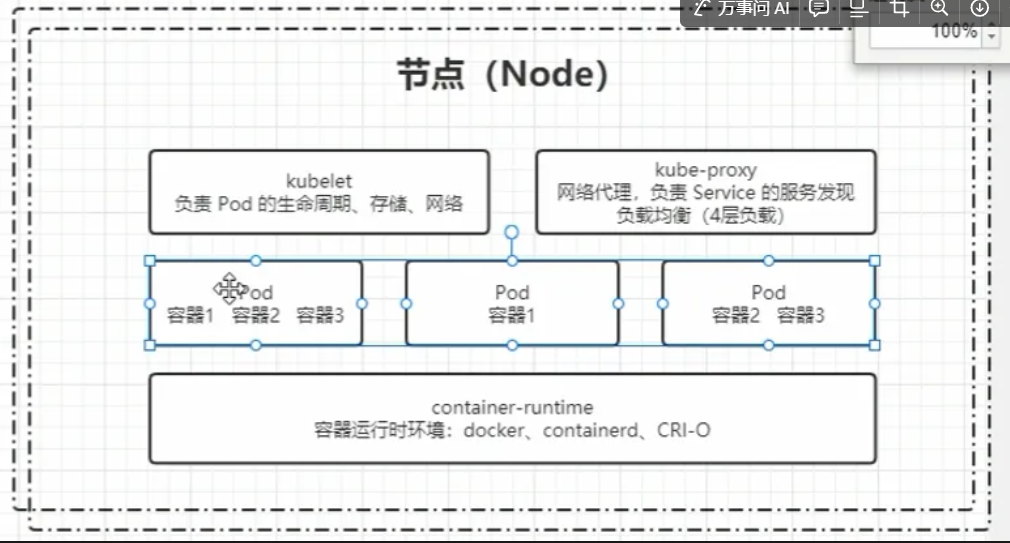
2.2Node
集群的數據平面,負責為容器提供運行環境 ( 干活 )
- Kubelet : 負責維護容器的生命周期,即通過控制docker,來創建、更新、銷毀容器
- KubeProxy : 負責提供集群內部的服務發現和負載均衡
- Docker : 負責節點上容器的各種操作
2.3案例
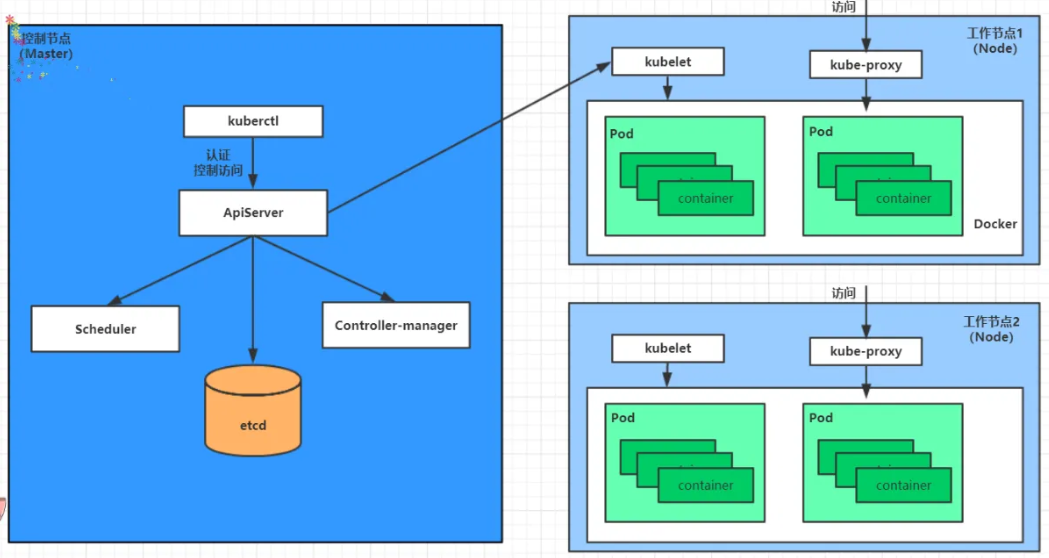
- 1.首先要明確,一旦kubernetes環境啟動之后,master和node都會將自身的信息存儲到etcd數據庫中
- 2.一個nginx服務的安裝請求會首先被發送到master節點的apiServer組件
- 3.apiServer組件會調用scheduler組件來決定到底應該把這個服務安裝到哪個node節點上,在此時,它會從etcd中讀取各個node節點的信息,然后按照一定的算法進行選擇,并將結果告知apiServer
- 4.apiServer調用controller-manager去調度Node節點安裝nginx服務
- 5.kubelet接收到指令后,會通知docker,然后由docker來啟動一個nginx的pod。pod是kubernetes的最小操作單元,容器必須跑在pod中至此,
- 6.一個nginx服務就運行了,如果需要訪問nginx,就需要通過kube-proxy來對pod產生訪問的代理,外界用戶就可以訪問集群中的nginx服務了
3.專業術語
3.1無狀態服務和有狀態服務
無狀態服務(stateless service):該服務運行的實例不會在本地存儲需要持久化的數據,并且多個實例對于同一個請求響應的結果是完全一致的。有狀態服務(stateful service):該服務運行的實例需要在本地存儲持久化數據,比如Mysql數據庫。
3.2對象規約和狀態
規約:“spec”是“規約”、“規格”的意思,spec是必需的,它描述了對象的期望狀態,即希望對象所具有的特征,當創建Kubernetes對象時,必須提供對象的規約,用來描述該對象的期望狀態,以及關于對象的一些基本信息(例如名稱)狀態:表示對象的實際狀態,該屬性由K8S自己維護,K8S會通過一系列的控制器對對應對象進行管理,讓對象的狀態與規約重合。
3.3資源對象
3.3.1集群級別
- Namespace:命名空間,即“資源對象組”
- Node:Node不是由K8S創建的,K8S只是管理Node上的資源。
- ClusterRole:是 Kubernetes 中用于定義集群范圍內權限的 RBAC (基于角色的訪問控制) 資源對象。它與 Role 類似,權限適用于整個集群,允許對集群級別的資源(如節點、持久卷等)和非資源端點(如/healthz)進行授權。
- ClusterRoleBinding:是 Kubernetes RBAC (基于角色的訪問控制) 機制中的關鍵資源,用于將 ClusterRole 的權限綁定到特定的用戶、組或服務賬戶。
3.3.2命名空間級別
- Pod:Pod指的是容器組,是K8S中的最小可部署單元,可能由單個容器或者幾個緊耦合在一起的容器組成,Pod內一定有一個Pause容器,用來Pod內容器進行網絡通信。
- RC(ReplicationController):用來確保容器應用的副本數始終保持在用戶定義的副本數,如果有容器異常退出,會自動創建新的Pod來替代,多的容器會自動回收
- RS(ReplicaSet):RS和RC沒有本質的不同,只是名字不一樣,并且RS支持集合式的seletor。
- Deployment:底層也是創建一個RS,同時支持RS的擴容和縮容功能,除此之外,還支持滾動升級/回滾,暫停與恢復功能。
- StatefulSet:具有穩定的持久化存儲,穩定的網絡標志,有序部署,有序擴展,有序刪除,由Headless Service和VolumeClaimTemplate組成。
- DaemonSet :為每一個Node上都運行一個容器副本,常用來部署一些集群的日志、監控或者其他系統管理應用。
- Job:一次性任務,運行完成后Pod銷毀,不會重新啟動新容器。
- CronJob:在Job的基礎上加上了定時功能
- Service :簡稱“svc”,節點間的通信應該用Service,Service就是把Pod暴露出來提供服務,Service才是真正的服務,定義了Pod邏輯集合和訪問Pod集合的策略。
- Ingress:是 Kubernetes 中管理外部訪問集群服務的 API 對象,它提供了 HTTP/HTTPS 路由規則,用于將外部請求路由到集群內部的服務。Ingress 相當于 Kubernetes 的"智能路由層"或"入口網關"。
- Volume:數據卷,共享Pod中容器使用的數據,用來放持久化的數據,比如數據庫數。
- ConfigMap:在 Kubernetes 中,ConfigMap 是一種用于管理和存儲配置數據的資源。它允許你將配置數據與應用程序代碼分離,從而使應用程序更加靈活和易于管理。ConfigMap 通常用于存儲非機密數據,例如配置文件、環境變量或命令行參數。
- Secret:在 Kubernetes 中,Secret 是一種用于存儲和管理敏感信息的資源。與 ConfigMap 類似,Secret 可以將配置信息與應用程序代碼分離,但 Secret 專門用于存儲機密數據,比如密碼、API 密鑰、證書等。Secret 中的數據默認會被編碼成 Base64 格式以防止意外泄漏,并且支持加密存儲。
- DownwardApi:在 Kubernetes 中,Downward API 是一種機制,用于將集群中的某些信息(如 Pod 的元數據和狀態信息)傳遞給容器。通過 Downward API,容器可以獲取運行時的上下文數據,例如 Pod 的名稱、命名空間、節點名稱、資源請求和限制等。這有助于容器在不直接調用 Kubernetes API 的情況下獲取相關信息,從而增強應用程序的自適應能力。
- Role:Role 是一種資源,用于在命名空間范圍內定義權限,以控制哪些用戶、服務賬戶或其他角色可以訪問特定資源。Role 通過定義規則(rules)來指定可以進行哪些操作,以及哪些資源可以被操作,從而實現基于角色的訪問控制(RBAC)。
- RoleBinding:在 Kubernetes 中,RoleBinding 是一種資源,用于將指定的 Role(或 ClusterRole)綁定到用戶、組或服務賬戶。通過 RoleBinding,可以授予特定主體(用戶、組或服務賬戶)在命名空間內的權限,從而實現基于角色的訪問控制(RBAC)。
- Horizontal Pod Autoscaler(HPA):Pod自動擴容策略,控制管理器每隔30S查詢metrics的資源使用情況。支持三種metrics類型,即預定義的metrics(以利用率的方式計算,比如CPU利用率)、自定義的Pod metrics(以原始值《raw value》的方式計算)、自定義的object metrics。支持兩種metrics查詢方式(Heapster和自定義的REST API),支持多種metrics
- Pod Template:Pod的模板定義,被包含在其他Kubernetes對象中(例如Deployment、StatefulSet、DaemonSet),控制器通過Pod Template信息創建Pod。
- LimitRange:可以對集群內Request和Limits的配置全局統一限制,相當于批量設置一個范圍內的Pod資源使用限制。
- PV:集群中的一塊網絡存儲資源,由管理員預先配置,或者使用 StorageClass 動態配置。它是集群級別的資源,獨立于Pod生命周期。
- PVC:是用戶對存儲的請求,它類似于Pod消耗節點資源的方式,PVC消耗PV資源。
3.3.3資源清單
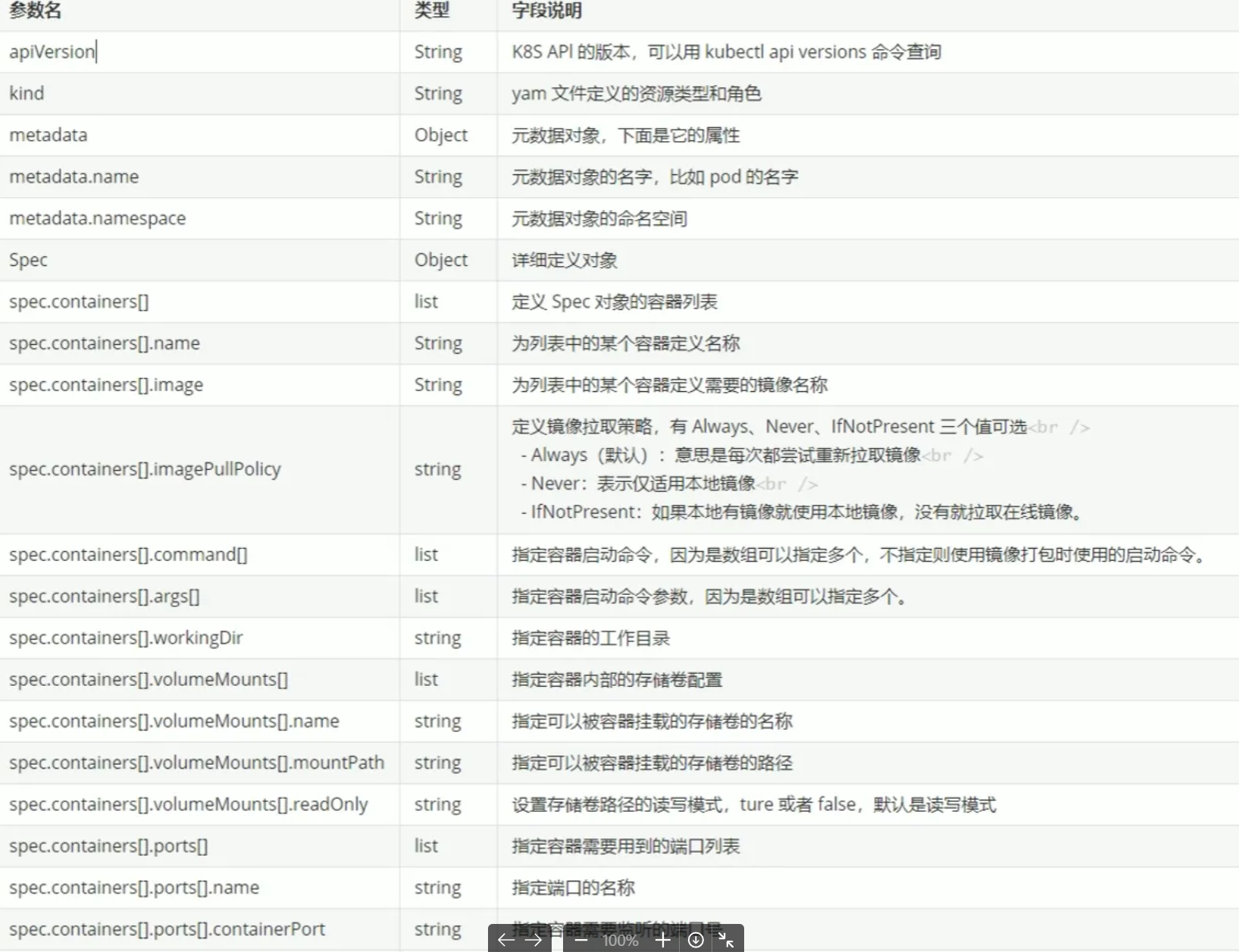
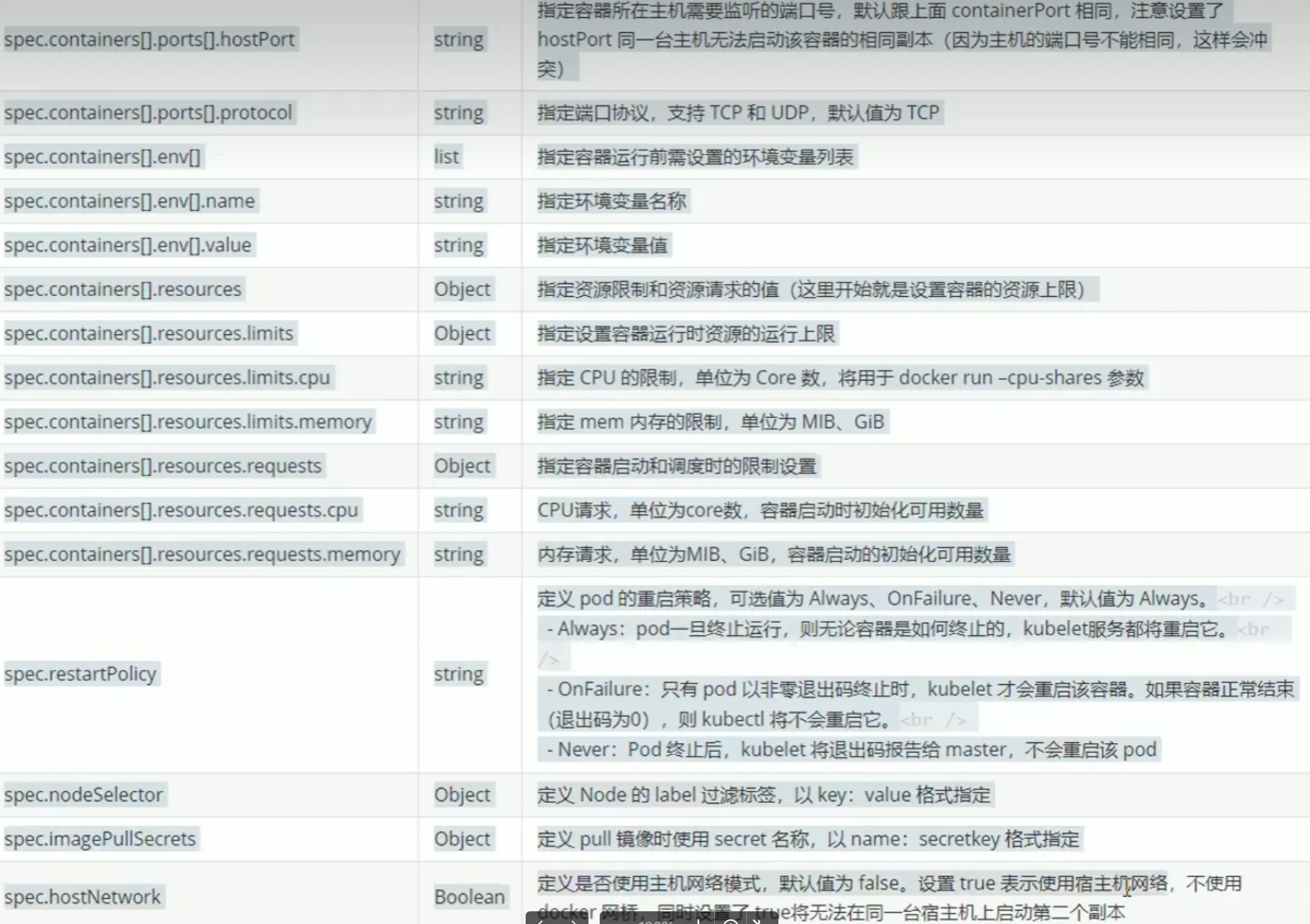
3.4多資源的yaml文件編寫
apiVersion: v1
kind: Namespace
metadata:name: dev
---
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: nginx-deployname: nginx-deploynamespace: dev
spec:replicas: 2revisionHistoryLimit: 10selector:matchLabels:app: nginx-deploystrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:labels:app: nginx-deployspec:containers:- image: nginx:latestimagePullPolicy: IfNotPresentname: nginxresources:limits:cpu: 200mmemory: 128Mirequests:cpu: 100mmemory: 128MirestartPolicy: Always
3.5Kubernetes API版本
Kubernetes API是Kubernetes最強大的部分,它為你的基礎設施和應用程序提供可預測、可擴展的API。也就是說KubernetesAPI就是K8S中各個組件之間通信使用的API,而yaml中的apiVersion指的就是這些接口的版本。常用的如下:
- alpha:該軟件可能包含錯誤,啟用一個功能可能會導致bug,隨時可能會丟棄對該功能的支持,恕不另行通知
- beta:軟件經過很好的測試。啟用功能被認為是安全的 默認情況下功能是開啟的 細節可能會改變,但功能在后續不會被刪除
- stable:穩定版,該版本名稱命名方式:vX這里X是一個整數 穩定版本,放心使用 將出現在后續發布的軟件版本中,例如:v1
4.資源管理
在Kubernetes中,所有內容都被抽象為資源,用戶需要通過操作資源來管理kubernetes。Kubernetes的本質上就是一個集群系統,用戶可以在集群中部署各種服務,所謂的部署服務,其實就是在Kubernetes集群中運行一個個的容器,并將指定的程序跑在容器中。Kubernetes的最小管理單元是pod而不是容器,所以只能將容器放在Pod中,而Kubernetes一般也不會直接管理Pod,而是通過Pod控制器來管理Pod的。如何考慮訪問Pod中服務,Kubernetes提供了Service資源實現這個功能。當然,如果Pod中程序的數據需要持久化,Kubernetes還提供了各種存儲系統。
4.1命令式對象管理
直接使用 kubectl 命令操作集群,無需編寫配置文件,適合快速執行一次性任務。
# 創建資源
kubectl run nginx --image=nginx
kubectl create deployment nginx --image=nginx# 更新資源
kubectl scale deployment nginx --replicas=3
kubectl annotate pod nginx description='my annotation'# 刪除資源
kubectl delete deployment nginx
4.2命令式對象配置
用配置文件定義對象,通過命令明確指定操作(create/replace/delete),每個文件通常包含單個對象定義。
# 創建資源
kubectl create -f nginx.yaml# 更新資源(完全替換)
kubectl replace -f nginx.yaml# 刪除資源
kubectl delete -f nginx.yaml
4.3聲明式對象配置
使用配置文件定義期望狀態,讓 Kubernetes 決定如何達到該狀態,使用 apply 操作,使用目錄管理多個相關文件。
# 應用配置(創建或更新)
kubectl apply -f configs/# 查看差異
kubectl diff -f configs/# 刪除資源(通過文件)
kubectl delete -f configs/
4.4聲明式對象配置和命令式對象配置
聲明式對象配置,保留歷史版本信息(可通過 kubectl rollout 查看),有差異對比,而命令式都沒有。
4.5Kubectl
Kubectl是Kubernetes集群的命令行工具,通過它能夠對集群本身進行管理,并能夠在集群上進行容器化應用的安裝部署,kubectl命令語法如下:
kubectl [command] [type] [name] [flags]
- comand:指定要對資源執行的操作,例如create、get、delete
- type:指定資源類型,比如deployment、pod、service
- name:指定資源的名稱,名稱大小寫敏感
- flags:指定額外的可選參數
4.6Kubectl可以在node節點上運行
Kubectl的運行是需要進行配置的,它的配置文件是$HOME/.kube,如果想要在node節點運行此命令,需要將master上的.kube文件復制到node節點上,即在master節點上執行下面操作:
find / -name .kube
scp -r 192.168.126.201:/root/.kube/ /root
scp -r 192.168.126.201:/etc/kubernetes/admin.conf /etc/kubernetes/admin.conf
5.資源管理
5.1Namespace(ns)
Namespace是Kubernetes系統中的一種非常重要資源,它的主要作用是用來實現多套環境的資源隔離或者多租戶的資源隔離。默認情況下,Kubernetes集群中所有的pod都是可以互相訪問的,但是實際中,可能不想讓兩個pod之間相互的訪問,那此時就可以將兩個pod劃分到不同的namespace中,Kubernetes通過將集群內部的資源分配到不同的namespace中,可以形成邏輯上的組,以方便不同的組的資源進行隔離使用和管理。可以同通過Kubernetes的授權機制,講不同的namespace交給不同的租戶進行管理,這樣就實現了多租戶的資源隔離,此時還能結合kubernetes的資源配額機制,限定不同租戶能占用的資源,例如CPU使用量、內存使用量等等,實現多租戶可用資源的管理。
常用命令如下:
- 查看所有命令空間:`kubectl get ns`/`kubectl get namespace`
- 查看指定的命名空間:`kubectl get ns <命名空間名稱>`
- 指定輸出格式查看命名控件:`kubectl get ns <命令空間名稱> -o yaml/wide/json`
- 查看命名空間詳情:`kubectl describe ns <命名空間名稱>`
- 創建:`kubectl create ns <創建命名空間的名稱>`
- 刪除:`kubectl delete ns dev`
ymal創建格式
apiVersion: v1
kind: Namespace
metadata:name: dev
5.2Pod
Pod是kubernetes集群進行管理的最小單元,程序要運行必須部署在容器中,而容器必須存在于Pod中。Pod可以認為是容器的封裝,一個Pod中可以存在一個或者多個容器。kubernetes在集群啟動之后,集群中的各個組件也都是以Pod方式運行的。Kubernetes 通過 CRI(Container Runtime Interface) 與容器運行時交互,而不是直接調用 Docker CLI。
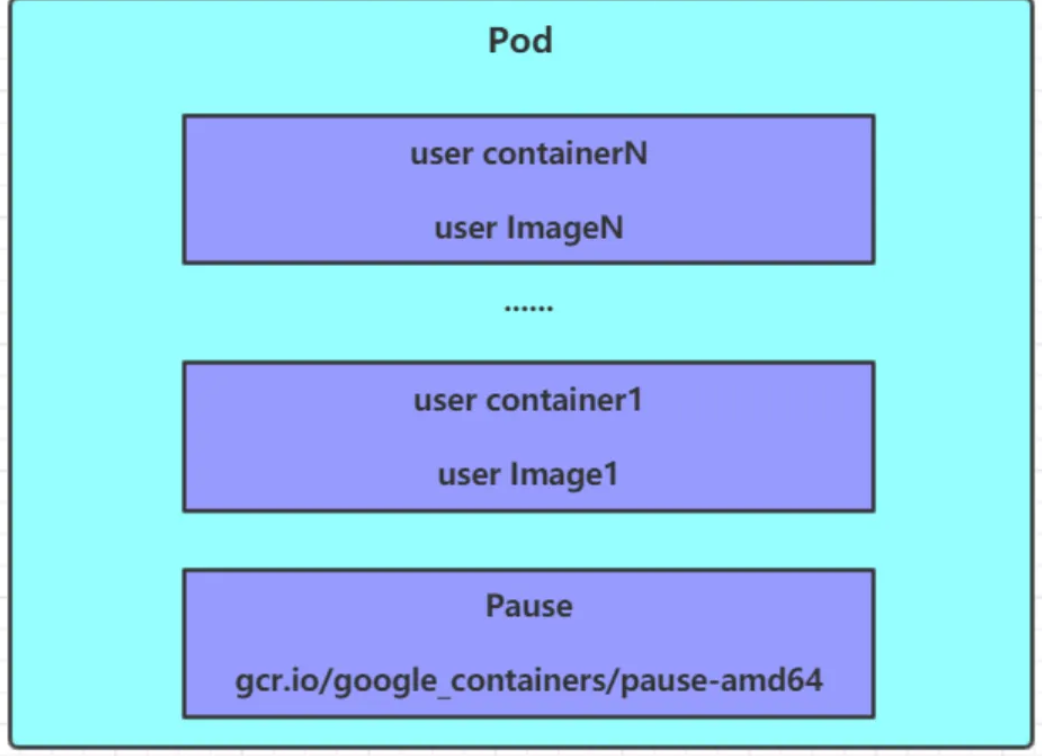
5.2.1常見命令
- 查看命名空間中的pod:kubectl get pods -n <命名空間名稱>
- 查看pod的詳細信息:kubectl describe pod <pod命名空間> -n <命名空間名稱>
- 查看所有命名空間的pod:kubectl get pod --all-namespaces
- 刪除指定pod:kubectl delete pod <pod命名空間> -n <命名空間名稱>
- 進入指定pod:kubectl exec -it <pod命名空間> -n <命名空間名稱> -c <容器名稱> — /bin/bash或者/bin/sh
== yaml創建格式==
apiVersion: v1
kind: Pod
metadata:name: nginxnamespace: devlabels:type: appversion: 1.0.0
spec:containers:- name: nginx-demoimage: nginx:latestimagePullPolicy: IfNotPresentcommand:- nginx- -g- 'daemon off;'workingDir: /usr/share/nginx/htmlports:- name: httpcontainerPort: 80protocol: TCPenv:- name: JVM_OPTSvalue: '-Xms128m -Xmx128m'restartPolicy: OnFailure
5.2.2生命周期
- 調度:kube-scheduler 選擇一個合適的節點。
- 拉取鏡像:kubelet 下載容器鏡像。
- 運行 Init 容器(如果配置)。
- 運行主容器:
- 執行 postStart 鉤子(如果配置)。
- 啟動 startupProbe → livenessProbe/readinessProbe。
- 標記為 Running。
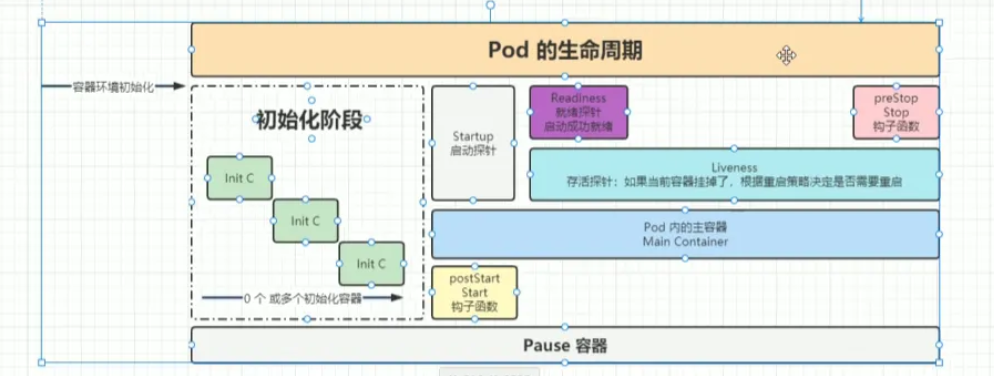
5.3探針
Kubernetes 中的探針(Probes)是一種用于監控容器健康狀況的機制,通過定期檢測容器的狀態來決定是否采取相應操作(如重啟容器、停止流量路由等)。Kubernetes 提供了三種類型的探針,每種探針有不同的作用場景和觸發行為。
5.3.1啟動探針(startup probe)
- 作用:檢測容器是否已經成功啟動。如果配置了啟動探針,其他探針(如就緒和存活探針)會等到啟動探針成功后再開始運行。
- 適用場景:啟動時間較長的應用(如 Java 應用或傳統服務),避免在啟動過程中被其他探針誤殺。
5.3.2就緒探針(Readiness Probe)
- 作用:檢測容器是否已準備好接收流量。如果探測失敗,容器會從 Service 的負載均衡池中移除,直到探測成功。
- 適用場景:應用需要完成初始化(如加載配置、連接數據庫)后才能提供服務。
5.3.3存活探針(Liveness Probe)
- 作用:檢測容器是否仍在正常運行。如果探測失敗,kubelet 會重啟容器。
- 適用場景:檢測死鎖、長時間阻塞等不可恢復的問題。
5.3.4探針的檢測方式
- Exec:在容器內執行命令,返回值為 0 表示成功。
livenessProbe:exec:command: ["cat", "/tmp/healthy"]
- HTTP GET:向容器的指定端口和路徑發送 HTTP 請求,狀態碼為 2xx/3xx 表示成功。
readinessProbe:httpGet:path: /healthport: 8080
- TCP Socket:嘗試與容器的指定端口建立 TCP 連接,連接成功即通過。
livenessProbe:tcpSocket:port: 3306
5.4Label
Label是Kubernetes系統中的一個重要概念。它的作用就是在資源上添加標識,用來對它們進行區分和選擇。
5.4.1Label的特點
- 一個Label會以key/value鍵值對的形式附加到各種對象上,如Node、Pod、Service等等
- 一個資源對象可以定義任意數量的Label ,同一個Label也可以被添加到任意數量的資源對象
- Label通常在資源對象定義時確定,當然也可以在對象創建后動態添加或者刪除
5.4.2Label Selector
標簽定義完畢之后,還要考慮標簽的選擇,Label Selector的作用就是用于標簽的選擇。Label Selector分為兩種。
- 基于等式的Label Selector
- name = slave:選擇所有包含Label中key=“name”且value=”slave“的對象
- env !=production :選擇所有包括Label中key=env且value不等于production的對象
- 基于集合的Label Selector
- name in (master,slave):選擇所有包含Label中key=”name“且value=”master“或”slave“的對象
- name not in (frontend):選擇所有包含Label中的key=”name”且value不等于”fronted“的對象
標簽的選擇條件可以使用多個,此時將多個Label Selector進行組合,使用, 進行分割即可,例如:name=slave,env!=production
5.4.3常用命令
- 為pod資源打標簽:kubectl label pod <pod名稱> <標簽名=標簽值> -n <命名空間名稱>
- 覆蓋標簽:kubectl label pod <pod名稱> <現有標簽名稱=新的標簽值> -n <命名空間名稱> --overwrite
- 查看并篩選標簽:kubectl get pods -n <命名空間名稱> -l
- 刪除標簽:kubectl label 資源類型 <資源對象名稱> -n <命名空間名稱> 標簽名-
== yaml配置方式 ==
apiVersion: v1
kind: Pod
metadata:name: nginxnamespace: devlabels:version: "3.0" env: "test"
spec:containers:- image: nginx:latestname: podports:- name: nginx-portcontainerPort: 80protocol: TCP
5.5Pod控制器
Pod是kubernetes的最小管理單元,在Kubernetes中,按照Pod的創建方式分為自主式Pod(Kubernetes直接通過命令創建的Pod)、控制器創建的Pod(kubernetes通過控制器創建的pod,這種pod刪除后還會重建),常見的如下:
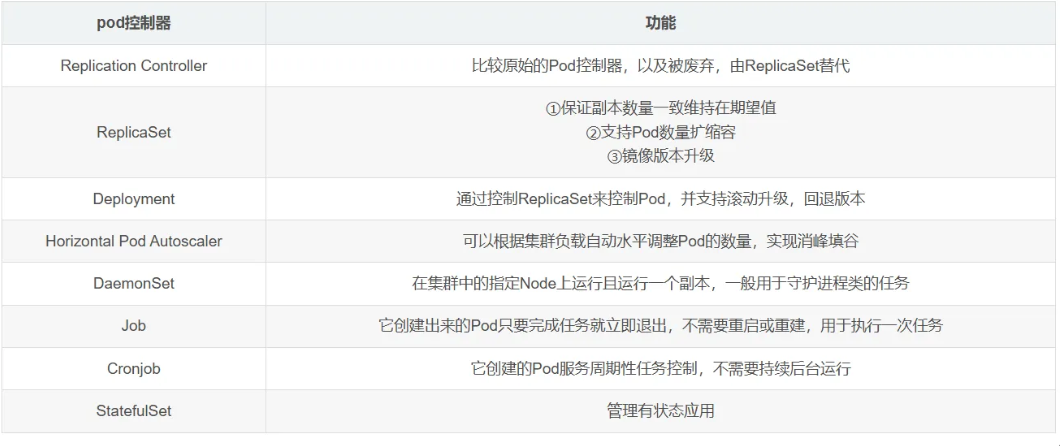
5.5.1Deployment(deploy)
為了更好的管理服務編排,Kubernetes引入了Deployment控制器。值得一提的是,Deployment控制器并不是直接管理pod,而是通過管理ReplicaSet來間接管理Pod,Deployment可以控制ReplicaSet的創建、升級、回滾等操作,從而管理Pod的數量和版本。即Deployment管理ReplicaSet,ReplicaSet管理Pod。相比之下,Deployment比ReplicaSet功能更加強大,能夠支持服務發布的停止、繼續、滾動更新、回滾和水平擴縮容等功能,使得服務編排更加方便和靈活。
5.5.1.1控制流程
- 獲取實際狀態: Deployment 控制器從 Etcd 中獲取所有攜帶了指定標簽的 Pod,并統計它們的數量
- 獲取期望狀態: 通過 Deployment 對象的 Replicas 字段,獲取期望的 Pod 數量
- 對比狀態: 對比實際狀態和期望狀態的數量。如果它們不一致,就需要進行調諧,確定是創建新的 Pod 還是刪除現有的 Pod
一個 Kubernetes 對象的主要編排邏輯,實際上是在第三步的“對比”階段完成的。這個操作,通常被叫作調諧(Reconcile)。這個調諧的過程,則被稱作“Reconcile Loop”(調諧循環)或者“Sync Loop”(同步循環)。
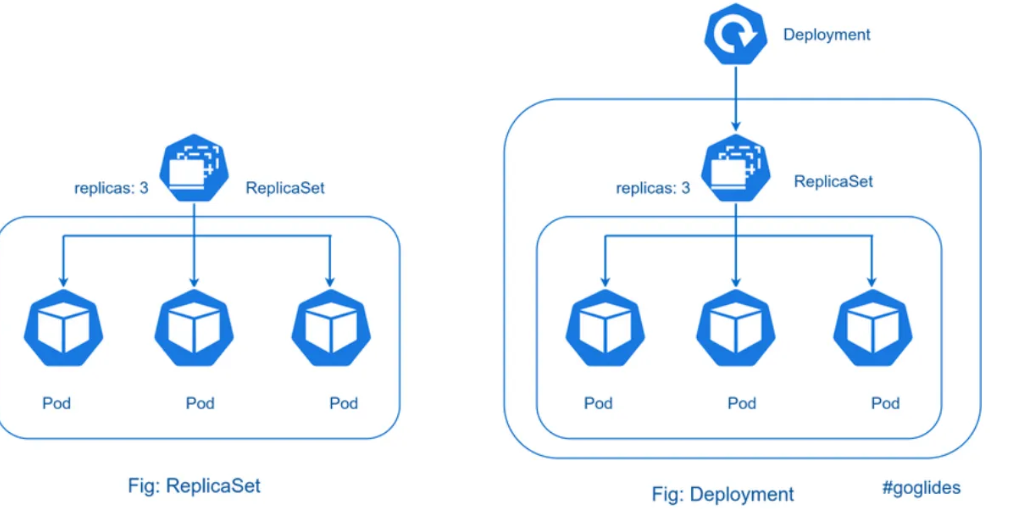
5.5.1.2創建Deployment(聲明式創建)
yaml文件如下:
apiVersion: apps/v1 # 版本號
kind: Deployment # 類型
metadata: # 元數據name: nginx-deploy # deployment控制器名稱namespace: test # 所屬命名空間labels: # 標簽列表plmType: nginx # 定義標簽的鍵值對
spec: # 詳情描述replicas: 2 # 期望的副本數量,默認為1revisionHistoryLimit: 3 # 保留歷史版本paused: false # 暫停部署,默認是falseprogressDeadlineSeconds: 600 # 部署超時時間(s),默認是600,超過這個時間就會變為失敗strategy: # 更新時替換舊pod的策略type: RollingUpdate # 滾動更新策略rollingUpdate: # 滾動更新maxSurge: 30% # 最大額外可以存在的副本數,可以為百分比,也可以為整數maxUnavailable: 30% # 最大不可用狀態的 Pod 的最大值,可以為百分比,也可以為整數selector: # 選擇器,通過它指定該控制器管理哪些podmatchLabels: # Labels匹配規則plmType: nginxtemplate: # 模板,當副本數量不足時,會根據下面的模板創建pod副本metadata:labels:plmType: nginx #Pod 標簽spec:containers:- name: nginximage: nginx:1.17.1ports:- containerPort: 80
然后執行如下命令:
kubectl apply -f deploy1.yaml
5.5.1.3創建Deployment的yaml模板
apiVersion: apps/v1 # 版本號
kind: Deployment # 類型
metadata: # 元數據name: string # deployment控制器名稱 namespace: string # 所屬命名空間 labels: # 標簽列表key: value # 定義標簽的鍵值對annotations: # 自定義注解列表key: value # 定義注解的鍵值對
spec: # 詳情描述replicas: int # 期望的副本數量,默認為1revisionHistoryLimit: 3 # 保留歷史版本paused: false # 暫停部署,默認是falseprogressDeadlineSeconds: 600 # 部署超時時間(s),默認是600,超過這個時間就會變為失敗strategy: # 更新時替換舊pod的策略type: RollingUpdate # 滾動更新策略# RollingUpdate 以滾動更新的方式更新pod,并可以通過設置maxSurge、maxUnavailable來控制滾動更新的過程# Recreate 所有現有的pod都會在創建新的pod之前被終止rollingUpdate: # 滾動更新maxSurge: 30% # 最大額外可以存在的副本數,可以為百分比,也可以為整數maxUnavailable: 30% # 最大不可用狀態的 Pod 的最大值,可以為百分比,也可以為整數selector: # 選擇器,通過它指定該控制器管理哪些podmatchLabels: # Labels匹配規則app: nginx-podmatchExpressions: # Expressions匹配規則- {key: app, operator: In, values: [nginx-pod]}template: # 模板,當副本數量不足時,會根據下面的模板創建pod副本metadata:labels: app: nginx-pod #Pod 標簽spec:containers:- name: nginximage: nginx:1.17.1ports:- containerPort: 80
5.5.1.4查看創建的Deploy
[root@master ~]# kubectl get deployment -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
deployment-nginx 2/2 2 2 6s
- NAME 列出了集群中 Deployment 的名稱
- READY 顯示應用程序的可用的副本數。顯示的模式是 就緒個數/期望個數
- UP-TO-DATE 當前處于最新版本的 Pod 的個數,所謂最新版本指的是 Pod 的 Spec 部分與 Deployment 里 Pod 模板里定義的完全一致
- AVAILABLE 當前可用的pod的數量,既是running狀態又是最新版本,并且處于ready狀態。AVAILABLE 字段,描述的才是用戶所期望的最終狀態
- AGE 顯示應用程序運行的時間
創建deployment同時也會自動創建出對應的ReplicaSet,ReplicaSet的名稱被格式化[Deployment名稱]-[隨機字符串]其中的隨機字符串是使用 pod-template-hash 隨機生成的。Deployment 控制器將 pod-template-hash 標簽添加到 Deployment 所創建或收留的每個 ReplicaSet。此標簽可確保 Deployment 的子ReplicaSets 不重疊,從而避免子ReplicaSets創建的pod與其它pod混淆。
[root@master k8s]# kubectl get pods -n test --show-labels -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
nginx-deploy-dcdf74b56-v8dxr 1/1 Running 0 10m 10.42.0.50 master <none> <none> plmType=nginx,pod-template-hash=dcdf74b56
nginx-deploy-dcdf74b56-v7qpr 1/1 Running 0 10m 10.42.0.49 master <none> <none> plmType=nginx,pod-template-hash=dcdf74b56
[root@master k8s]# kubectl get rs -n test --show-labels -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR LABELS
nginx-deploy-dcdf74b56 2 2 2 10m nginx nginx:1.17.1 plmType=nginx,pod-template-hash=dcdf74b56 plmType=nginx,pod-template-hash=dcdf74b56
[root@master k8s]# kubectl get pods -n test --show-labels -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
nginx-deploy-dcdf74b56-v8dxr 1/1 Running 0 10m 10.42.0.50 master <none> <none> plmType=nginx,pod-template-hash=dcdf74b56
nginx-deploy-dcdf74b56-v7qpr 1/1 Running 0 10m 10.42.0.49 master <none> <none> plmType=nginx,pod-template-hash=dcdf74b56
5.5.1.5水平擴縮容
水平擴縮容非常容易實現,deployment只需要修改它所控制的ReplicaSet的pod副本個數就可以了
- 使用edit命令,修改yaml文件中spec中的replicas為5
[root@k8s-master ~]# kubectl get deploy -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
deployment-nginx 2/2 2 2 17h
[root@k8s-master ~]# kubectl edit deploy deployment-nginx -n dev
deployment.apps/deployment-nginx edited
[root@k8s-master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
deployment-nginx-587fdd789f-j6pgk 1/1 Running 0 23s
deployment-nginx-587fdd789f-lffcm 1/1 Running 0 23s
deployment-nginx-587fdd789f-nzppf 1/1 Running 1 17h
deployment-nginx-587fdd789f-r6z6t 1/1 Running 0 23s
deployment-nginx-587fdd789f-zwsdt 1/1 Running 1 17h
- 使用scale命令
[root@k8s-master ~]# kubectl scale deploy deployment-nginx --replicas=3 -n dev
deployment.apps/deployment-nginx scaled
[root@k8s-master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
deployment-nginx-587fdd789f-lffcm 1/1 Running 0 2m24s
deployment-nginx-587fdd789f-nzppf 1/1 Running 1 17h
deployment-nginx-587fdd789f-zwsdt 1/1 Running 1 17h
scale和edit的區別
scale命令適合臨時調整,僅調整副本數,不會影響 Pod 模板,不涉及 YAML 文件。下次 kubectl apply 時可能會被覆蓋(如果 YAML 里定義的 replicas 不同)。但是edit修改的是 Deployment 的聲明式配置(存儲在 etcd 中)。會持久化修改,即使重啟集群或重新 apply 也不會丟失。
5.5.1.6滾動更新
僅當 Deployment Pod 模板(即 .spec.template)發生改變時,例如模板的標簽或容器鏡像被更新,才會觸發Deployment 上線。 其他更新(如對 Deployment 執行擴縮容的操作)不會觸發上線動作,當你修改 Deployment 的副本數量(spec.replicas)時,只是調整 Pod 的數量,而不涉及 Pod 模板的變更。這不會觸發新的 Pod 模板創建,也不會引發滾動更新。例如,你把 replicas 從 3 調整到 5,Kubernetes 只會再創建兩個 Pod 來滿足新的副本數量要求,而不會重新創建已有的 Pod。
例如修改鏡像后,Kubernetes 就會立刻觸發滾動更新 的過程。通過 kubectl rollout status 指令查看 deployment-nginx 的狀態變化:kubectl rollout status deploy deployment-nginx -n dev。
[root@master ~]# kubectl describe deployment deployment-nginx -n dev
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal ScalingReplicaSet 10m deployment-controller Scaled up replica set deployment-nginx-dcbd8844d to 2Normal ScalingReplicaSet 7m9s deployment-controller Scaled up replica set deployment-nginx-dcbd8844d to 5Normal ScalingReplicaSet 3m56s deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 3Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set deployment-nginx-9588fc68c to 1Normal ScalingReplicaSet 18s deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 2Normal ScalingReplicaSet 18s deployment-controller Scaled up replica set deployment-nginx-9588fc68c to 2Normal ScalingReplicaSet 17s deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 1Normal ScalingReplicaSet 17s deployment-controller Scaled up replica set deployment-nginx-9588fc68c to 3Normal ScalingReplicaSet 16s deployment-controller Scaled down replica set deployment-nginx-dcbd8844d to 0
可以看到,首先,當你修改了 Deployment 里的 Pod 定義之后,Deployment Controller 會使用這個修改后的 Pod 模板,創建一個新的 ReplicaSet(hash=9588fc68c),這個新的 ReplicaSet 的初始 Pod 副本數是:0。然后在 Age=19 s 的位置,Deployment Controller 開始將這個新的 ReplicaSet 所控制的 Pod 副本數從 0 個變成 1 個,即水平擴展出一個副本。緊接著,在 Age=18 s 的位置,Deployment Controller 又將舊的 ReplicaSet(hash=dcbd8844d)所控制的舊 Pod 副本數減少一個,即水平收縮成一個副本。如此交替進行,新 ReplicaSet 管理的 Pod 副本數,從 0 個變成 1 個,再變成 2 個,最后變成 3 個。而舊的 ReplicaSet 管理的 Pod 副本數則從 3 個變成 2 個,再變成 1 個,最后變成 0 個。這樣,就完成了這一組 Pod 的版本升級過程。像這樣,將一個集群中正在運行的多個 Pod 版本,交替地逐一升級的過程,就是 滾動更新 。
5.5.1.7rollout
kubectl rollout status 顯示當前升級狀態
kubectl rollout history 顯示升級歷史記錄
kubectl rollout pause 暫停版本升級過程
kubectl rollout resume 繼續已經暫停的版本升級過程
kubectl rollout restart 重啟版本升級過程
kubectl rollout undo 回滾到上一級版本,可以使用 --to-revision回滾到指定版本
默認情況下 Deployment 的所有上線記錄都保留在系統中,以便可以隨時回滾 。假設你在更新 Deployment 時犯了一個拼寫錯誤,將鏡像名稱命名設置為
nginx:1.161而不是nginx:1.61.1,此上線進程會出現停滯,可以通過檢查上線狀態來驗證
[root@master ~]# kubectl rollout status deploy deployment-nginx -n dev
Waiting for deployment "deployment-nginx" rollout to finish: 1 out of 3 new replicas have been updated...
查看所創建的 Pod,你會注意到新 ReplicaSet 所創建的 1 個 Pod 卡頓在鏡像拉取循環中
[root@master ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deployment-nginx-8545c8f6d8-gzbcq 0/1 ImagePullBackOff 0 80s
deployment-nginx-86b659b6c4-cc4x4 1/1 Running 0 25m
deployment-nginx-86b659b6c4-znhh6 1/1 Running 0 26m
查看ReplicaSet發現新版本的 ReplicaSet(hash=8545c8f6d8)的水平擴展已經停止。而且此時它已經創建了一個 Pod,但是它們都沒有進入 READY 狀態。這當然是因為這個 Pod 都拉取不到有效的鏡像。(nginx:1.161這個鏡像在docker hub中并不存在,因此滾動更新被觸發后會立即停止)。與此同時舊版本的 ReplicaSet(hash=86b659b6c4)的水平收縮,也自動停止了。此時已經有一個舊 Pod 被刪除,還剩下兩個舊 Pod
[root@master ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
deployment-nginx-8545c8f6d8 1 1 0 44s
deployment-nginx-86b659b6c4 2 2 2 25m
deployment-nginx-9588fc68c 0 0 0 74m
deployment-nginx-dcbd8844d 0 0 0 85m
Deployment 控制器自動停止有問題的上線過程,并停止對新的 ReplicaSet 擴容。 這行為取決于所指定的 rollingUpdate 參數(具體為 maxUnavailable)。 默認情況下,Kubernetes 將此值設置為 25%
[root@master ~]# kubectl describe deployment deployment-nginx -n dev
RollingUpdateStrategy: 1 max unavailable, 0 max surge
我們只需要執行一條
kubectl rollout undo命令,就能把整個 Deployment 回滾到上一個版本,讓這個舊 ReplicaSet(hash=86b659b6c4)再次擴展成 3 個 Pod,而讓新的 ReplicaSet(hash=8545c8f6d8)重新收縮到 0 個 Pod
[root@master ~]# kubectl rollout undo deployment deployment-nginx -n dev
deployment.apps/deployment-nginx rolled back
[root@master ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deployment-nginx-86b659b6c4-4gfn4 1/1 Running 0 24s
deployment-nginx-86b659b6c4-cc4x4 1/1 Running 0 30m
deployment-nginx-86b659b6c4-znhh6 1/1 Running 0 30m
[root@master ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
deployment-nginx-8545c8f6d8 0 0 0 6m32s
deployment-nginx-86b659b6c4 3 3 3 31m
deployment-nginx-9588fc68c 0 0 0 80m
deployment-nginx-dcbd8844d 0 0 0 91m
果我想回滾到更早之前的版本,可以通過
kubectl rollout history命令,查看每次 Deployment 變更對應的版本。由于我們在創建這個 Deployment 的時候,指定了--record參數,所以我們創建這些版本時執行的 kubectl 命令,都會被記錄下來。如果執行命令時沒有指定--record參數,那么 CHANGE-CAUSE 字段記錄值為<none>
[root@master ~]# kubectl rollout history deploy deployment-nginx -n dev
deployment.apps/deployment-nginx
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image deployment deployment-nginx nginx=nginx:1.17.1 --namespace=dev --record=true
4 kubectl set image deploy deployment-nginx nginx=nginx:1.161 --namespace=dev --record=true
5 kubectl apply --filename=nginx-deploy.yaml --record=true
你還可以通過這個
kubectl rollout history指令,看到每個版本對應的 Deployment 的 API 對象的細節
kubectl rollout history deploy deployment-nginx -n dev --revision=2
然后,我們就可以在
kubectl rollout undo命令行最后,加上要回滾到的指定版本的版本號,就可以回滾到指定版本了。直接使用--to-revision=2回滾到了2版本, 如果省略這個選項,就是回退到上個版本。
kubectl rollout undo deploy deployment-nginx -n dev --to-revision=2
其實deployment之所以可是實現版本的回滾,就是通過記錄歷史RS來實現的,一旦想回滾到哪個版本,只需要將當前版本pod數量降為0,然后將回滾版本的pod提升為目標數量就可以了。保留歷史記錄的本質是保留每次修改創建的RS控制器,而回滾的本質是切換到對應版本的RS控制器。deployment對象
spec.revisionHistoryLimit字段就是k8s為deployment保留的歷史版本個數,如果設置為0,那么就再也不能進行回滾操作了
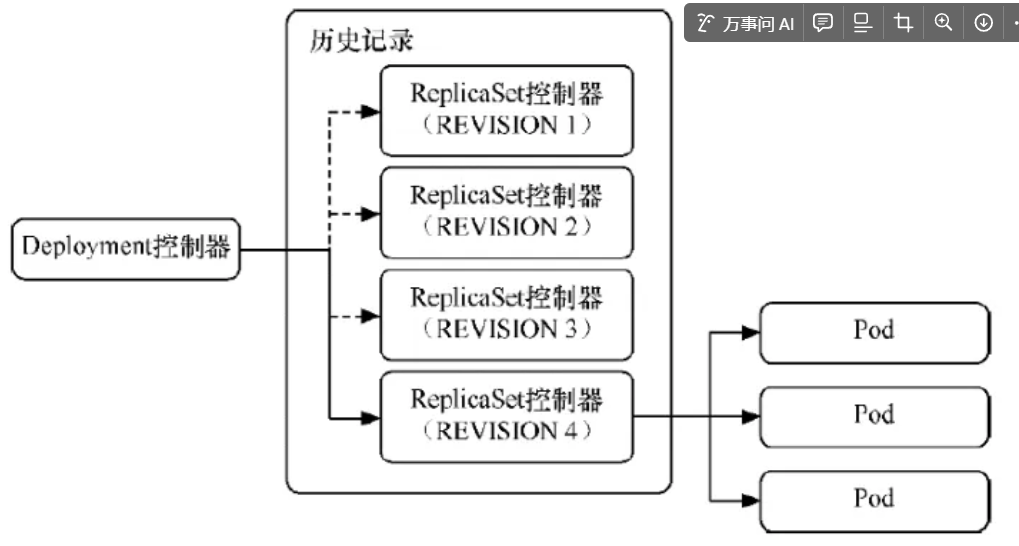
通過控制RS,比如創建新RS,舊RS就會把里面的pod副本數一個個轉移到新RS,達到滾動更新,滾動更新以后舊RS并沒有被刪除,而是被停用,如果想要用舊RS,達到回滾
更新的暫停與恢復
無論是直接更新還是滾動更新,都會一直更新到結束。但為了避免更新有問題,可以嘗試只更新一個pod,待這個pod驗證無誤后,再更新其它pod。Deployment控制器支持控制更新過程中的控制,如暫停(pause)或繼續(resume)更新操作
kubectl rollout pause deployment <deployment name> #暫停
kubectl rollout resume deployment <deployment name> #恢復
比如有一批新的Pod資源創建完成后立即暫停更新過程,此時,僅存在一部分新版本的應用,主體部分還是舊的版本。然后,再篩選一小部分的用戶請求路由到新版本的Pod應用,繼續觀察能否穩定地按期望的方式運行。確定沒問題之后再繼續完成余下的Pod資源滾動更新,否則立即回滾更新操作。這就是所謂的金絲雀發布。
例子
例如,對于一個剛剛創建的 Deployment,獲取 Deployment 信息:
[root@master ~]# kubectl get deploy -n dev -owide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-nginx 3/3 3 3 8s nginx nginx:1.8 app=nginx-deployment
[root@master ~]# kubectl get rs -n dev -owide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
deployment-nginx-86b659b6c4 3 3 3 14s nginx nginx:1.8 app=nginx-deployment,pod-template-hash=86b659b6c4
更新deployment的版本,并配置暫停deployment,升級完第一個pod后會立即暫停后續操作
kubectl set image deploy deployment-nginx nginx=nginx:1.17.4 -n dev && kubectl rollout pause deployment deployment-nginx -n dev
5.5.1.8刪除
刪除deployment,其下的RS和pod也將被刪除
[root@k8s-master ~]# kubectl delete deploy deployment-nginx -n dev
deployment.apps "deployment-nginx" deleted
如果某臺服務器宕機或關機,那么在該節點上的pod將變成了ternminating狀態,表示已經終止。另外還有新的pod在創建,所以控制器保證集群中的pod數量與配置中期望的pod數量保持一致
5.5.1.9部署策略
在Kubernetes中有幾種不同的方式發布應用,所以為了讓應用在升級期間依然平穩提供服務,選擇一個正確的發布策略就非常重要了。選擇正確的部署策略是要依賴于我們的業務需求的,下面我們列出了一些可能會使用到的策略:
重建(recreate):停止舊版本部署新版本滾動更新(rolling-update):一個接一個地以滾動更新方式發布新版本藍綠(blue/green):新版本與舊版本一起存在,然后切換流量金絲雀(canary):將新版本面向一部分用戶發布,然后繼續全量發布A/B測(a/b testing):以精確的方式(HTTP 頭、cookie、權重等)向部分用戶發布新版本。A/B測實際上是一種基于數據統計做出業務決策的技術。在 Kubernetes 中并不原生支持,需要額外的一些高級組件來完成改設置(比如Istio、Linkerd、Traefik、或者自定義 Nginx/Haproxy 等)。
5.5.2DaemonSet(ds)
DaemonSet的主要作用就是在Kubernetes集群里每一個節點中運行一個pod,當有新節點加入kubernetes集群中,該pod會自動在該節點上被創建出來。當節點從集群移除后,該節點的這個Pod也會被回收。所有和這個對象相關的 Pod都會被刪除。
5.5.3Job/CronJob
Job和CronJob,他們組合了Pod,實現了離線業務的處理。
在線業務 :比如Nginx、Nodejs、Mysql、Redis等等,一旦運行起來基本就不會停,也就是永遠在線。
離線業務:一般不直接服務于外部用戶,只對內部用戶有意義,比如日志分析、數據轉碼等等,雖然計算很大,但只會考慮一段時間,離線業務的特點是必定會退出,不會無期限地運行下去。離線業務分為兩種,一種是臨時任務,跑完就完事了。一種是定時任務,可以按時按點周期運行,不需要過多干預,對應到Kubernetes里,臨時任務就是API對象Job,定時任務就是API對象CronJob。
5.5.3.1Job
Job對象通常用于運行那些僅需要執行一次的任務,例如數據庫遷移、批處理腳本,Job的本質是確保一個或多個Pod健康地運行直至運行完畢。如定時腳本意外退出是沒辦法重新執行的,Job可以判斷這個腳本是不是正常退出,如果不是正常退出job會重新執行該腳本直到正常退出為止。并且還可以設置重試的次數。
創建:
apiVersion: batch/v1
kind: Job
metadata:name: pi
spec:template:spec:containers:- name: piimage: busyboxcommand: ["sh", "-c", "echo 'scale=5000; 4*a(1)' | bc -l "]restartPolicy: Never #重啟策略backoffLimit: 4 #失敗時重試次數,默認為6
?BusyBox是一個開源項目,提供了大約400個常見UNIX/Linux命令的精簡實現?。它被打包為單個二進制文件,適合資源受限的環境,如嵌入式設備和物聯網設備。BusyBox的特點是短小精悍,特別適合對尺寸敏感的系統。
我們可以看到這個 Job 創建的 Pod 進入了 Running 狀態,這意味著它正在計算 Pi 的值
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-mmjnd 1/1 Running 0 40s
跟其他控制器不同的是,Job 對象并不要求你定義一個
spec.selector來描述要控制哪些 Pod。在成功創建后,我們來查看一下這個 Job 對象
[root@master ~]# kubectl describe jobs pi
......
Pod Template:Labels: controller-uid=500d112e-df22-43f4-a6e0-49efc462f15bjob-name=pi
......
可以看到,這個 Job 對象在創建后,它的 Pod 模板,被自動加上了一個
controller-uid=< 一個隨機字符串 >這樣的 Label。而這個 Job 對象本身,則被自動加上了這個 Label 對應的 Selector,從而保證了 Job 與它所管理的 Pod 之間的匹配關系。而 Job Controller 之所以要使用這種攜帶了 UID 的 Label,就是為了避免不同 Job 對象所管理的 Pod 發生重合。像這種離線job可能要執行多次,若是pod的標簽一樣,會出現錯誤選擇的問題我們可以看到很快 Pod 變成了 Completed 狀態,這是因為容器的任務執行完成正常退出了,我們可以查看對應的日志
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-mmjnd 0/1 Completed 0 48s
[root@master ~]# kubectl logs pi-8xv5b
3.141592653589793238462643383279...
但是如果執行任務的 Pod 因為某種原因一直沒有結束怎么辦呢?同樣我們可以在 Job 對象中通過設置字段
spec.activeDeadlineSeconds來限制任務運行的最長時間,比如:
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:name: pi
spec:activeDeadlineSeconds: 10template:spec:containers:- name: piimage: busyboxcommand: ["sh", "-c", "echo 'scale=5000; 4*a(1)' | bc -l "]restartPolicy: Never #重啟策略backoffLimit: 4 #失敗時重試次數,默認為6
EOF
那么當我們的任務 Pod 運行超過了 10s 后,這個 Job 的所有 Pod 都會被終止,并且 Pod 的終止原因會變成 DeadlineExceeded
如果這個離線作業失敗了要怎么辦?比如,我們在例子中定義了restartPolicy=Never,那么離線作業失敗后 Job Controller 就會不斷地嘗試創建一個新 Pod。這也是我們需要在 Pod 模板中定義restartPolicy=Never的原因,離線計算的 Pod 永遠都不應該被重啟,所以想讓任務進行就只能創新的Pod。如果你定義的restartPolicy=OnFailure,那么離線作業失敗后,Job Controller 就不會去嘗試創建新的 Pod。但是,它會不斷地嘗試重啟 Pod 里的容器。
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:name: job-failed-demo
spec:template:spec:containers:- name: test-jobimage: busyboxcommand: ["echo123", "test failed job!"]restartPolicy: OnFailure
EOF重啟策略改為 OnFailure,則當 Job 任務執行失敗后不會創建新的 Pod 出來,只會不斷重啟 Pod
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
job-failed-demo-9hsfx 0/1 RunContainerError 1 (21s ago) 33s
并行
在 Job 對象中,負責并行控制的參數有兩個:
spec.parallelism:它定義的是一個 Job 在任意時間最多可以啟動多少個 Pod 同時運行
spec.completions:它定義的是 Job 至少要完成的 Pod 數目,即 Job 的最小完成數現在,我在之前計算 Pi 值的 Job 里,添加這兩個參數,這樣我們就指定了這個 Job 最大的并行數是 2,而最小的完成數是 4
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:name: pi
spec:parallelism: 2completions: 4template:spec:containers:- name: piimage: busyboxcommand: ["sh", "-c", "echo 'scale=5000; 4*a(1)' | bc -l "]restartPolicy: NeverbackoffLimit: 4
EOF查看這個job,COMPLETIONS 定義的最小完成數
[root@master ~]# kubectl get job
NAME COMPLETIONS DURATION AGE
pi 0/4 79s 79s
我們可以看到,這個 Job 首先創建了兩個并行運行的 Pod 來計算 Pi
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-8f766 1/1 Running 0 19s
pi-lzdbh 1/1 Running 0 19s
而在這兩個 Pod 相繼完成計算后。每當有一個 Pod 完成計算進入 Completed 狀態時,就會有一個新的 Pod 被自動創建出來
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-8f766 0/1 Completed 0 59s
pi-9rkfc 0/1 ContainerCreating 0 1s
pi-hzwmb 0/1 ContainerCreating 0 3s
pi-lzdbh 0/1 Completed 0 59s
當所有的 Pod 均已經成功退出,這個 Job 也就執行完了,所以你會看到它的 COMPLETIONS 字段的值變成了 4/4
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-8f766 0/1 Completed 0 107s
pi-9rkfc 0/1 Completed 0 49s
pi-hzwmb 0/1 Completed 0 51s
pi-lzdbh 0/1 Completed 0 107s
[root@master ~]# kubectl get job
NAME COMPLETIONS DURATION AGE
pi 4/4 104s 110sJob Controller 控制的對象,直接就是 Pod。Job Controller在控制循環中進行調諧操作,根據實際運行的、已經退出的和設置的允許并行的和最少完成的這兩個參數共同計算出在這個周期里應該創建或者刪除的 Pod 數目,然后調用 Kubernetes API 來執行這個操作。以上面計算 Pi 值的這個例子為例,當 Job 一開始創建出來時,實際處于 Running 狀態的 Pod 數目 = 0,已經成功退出的 Pod 數目 = 0,而用戶定義的 completions,也就是最終用戶需要的 Pod 數目 = 4。所以在這個時刻,需要創建的 Pod 數目 = 最終需要的 Pod 數目 - 實際在 Running 狀態 Pod 數目 - 已經成功退出的 Pod 數目 = 4 - 0 - 0= 4。也就是說,Job Controller 需要創建 4 個 Pod 來糾正這個不一致狀態。可是,我們又定義了這個 Job 的 parallelism=2。也就是說,我們規定了每次并發創建的 Pod 個數不能超過 2 個。所以,Job Controller 會對前面的計算結果做一個修正,修正后的期望創建的 Pod 數目應該是:2 個。這時候,Job Controller 就會并發地向 kube-apiserver 發起兩個創建 Pod 的請求。類似地,如果在這次調諧周期里,Job Controller 發現實際在 Running 狀態的 Pod 數目,比 parallelism 還大,那么它就會刪除一些 Pod,使兩者相等。
5.5.3.2
CronJob和Job的關系,正如同Deployment和ReplicaSet的關系一樣,CronJob是一個專門用來管理Job對象的控制器,只不過,他創建和刪除Job的依據是schedule字段定義的,schedule字段是一個標準的unix Cron格式的表達式。一個 CronJob 對象其實就對應linux系統中 crontab 文件中的一行,它根據配置的時間格式周期性地運行一個Job,格式和 crontab 也是一樣的:分 時 日 月 周 要運行的命令
yaml文件
apiVersion: batch/v1beta1
kind: CronJob
metadata:name: cronjob-demo
spec:schedule: "*/1 * * * *"jobTemplate: #CronJob 是一個 Job 對象的控制器spec:template:spec:restartPolicy: OnFailurecontainers:- name: busyboximage: busyboxargs:- "bin/sh"- "-c"- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
spec.successfulJobsHistoryLimit(默認為3) 和 spec.failedJobsHistoryLimit(默認為1),表示歷史限制,是可選的字段,指定可以保留多少完成和失敗的 Job。然而,當運行一個 CronJob 時,Job 可以很快就堆積很多,所以一般推薦設置這兩個字段的值。如果設置限制的值為 0,那么相關類型的 Job 完成后將不會被保留
稍微等一會兒查看可以發現多了幾個 Job 資源對象,這個就是因為上面我們設置的 CronJob 資源對象,每1分鐘執行一個新的 Job
[root@master ~]# kubectl get job
NAME COMPLETIONS DURATION AGE
cronjob-demo-28651212 1/1 7s 84s
cronjob-demo-28651213 0/1 24s 24s
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
cronjob-demo-28651212-pg529 0/1 Completed 0 91s
cronjob-demo-28651213-469cp 0/1 ContainerCreating 0 31s
由于定時任務的特殊性,很可能某個 Job 還沒有執行完,另外一個新 Job 就產生了。這時候,你可以通過
spec.concurrencyPolicy字段來定義具體的處理策略。比如:concurrencyPolicy=Allow這也是默認情況,這意味著這些 Job 可以同時存在;concurrencyPolicy=Forbid這意味著不會創建新的 Pod,該創建周期被跳過;concurrencyPolicy=Replace這意味著新產生的 Job 會替換舊的、沒有執行完的 Job。而如果某一次 Job 創建失敗,這次創建就會被標記為“miss”。當在指定的時間窗口內,miss 的數目達到 100 時,那么 CronJob 會停止再創建這個 Job。這個時間窗口,可以由spec.startingDeadlineSeconds字段指定。比如startingDeadlineSeconds=200,意味著在過去 200 s 里,如果 miss 的數目達到了 100 次,那么這個 Job 就不會被創建執行了。
5.5.4StatefulSet(sts)
Deployment和RelicaSet是為無狀態服務而設計的,一個應用的所有Pod是完全一樣的。所以它們互相之間沒有順序,也無所謂在哪臺宿主機上。需要的時候,Deployment就可以通過Pod模板創建新的Pod,不需要的時候,可以任意殺掉。因此對Pod的啟動順序,集群要求,點對點TCP連接也沒有任意的要求。為此Kubernetes引入了StatefulSet這種資源對象來支持這種復雜的功能,StatefulSet類似于ReplicaSet,但是它可以處理Pod的啟動順序,為保留每個Pod的狀態設置唯一標識,具有以下幾個功能特性:
穩定的持久化存儲:即Pod死亡重新調度后還是能訪問到相同的持久化數據,數據不會丟失,基于PVC來實現(公用一個存儲卷,Pod死亡后,StatefulSet會維持副本數重新創建Pod,仍會使用到上個Pod使用到的存儲卷)穩定的網絡標志:即Pod重新調度后其PodName和HostName不變,很多服務會以PodName或HostName為連接對象,為防止新的Pod名稱發生改變,需要重新寫入,基于Headless Service實現有序部署,有序擴展:即Pod是有順序的,在部署或者擴展的時候要依據定義的順序依次進行,當前的Pod必須都是Running(運行)和Ready(就緒)狀態,下一個Pod才能運行。有序收縮,有序刪除:即從N-1到0,比如先起mysql,再起nginx。停先停nginx,再停mysql
創建用的yaml
apiVersion: v1
kind: Service
metadata:name: nginxlabels:app: nginx
spec:ports:- port: 80name: webclusterIP: Noneselector:app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:serviceName: "nginx"replicas: 3 # 默認值是 1selector:matchLabels:app: nginx # 必須匹配 .spec.template.metadata.labelstemplate:metadata:labels:app: nginx # 必須匹配 .spec.selector.matchLabelsspec:containers:- name: nginximage: nginx:latestports:- containerPort: 80name: web
擴縮容
# 使用scale命令
kubectl scale statefulSet web --replicas=5
# 使用patch命令
kubectl patch sts web -p '{"spec":{"replicas":3}}'
kubectl patch命令用于更新資源的字段。這個命令可以用來修改Kubernetes集群中的對象而不需要提供完整的資源規格。如果只是簡單調整副本數,使用 scale 更直觀方便。如果需要同時修改多個配置或自動化場景,patch 更靈活
級聯刪除
默認刪除statefulset時會級聯刪除pod,如果不想刪除pod,可以使用如下命令
[root@k8s-master statefulset]# kubectl delete sts web --cascade=false
statefulset.apps "web" deleted
[root@k8s-master statefulset]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 79m
web-1 1/1 Running 0 79m
web-2 0/1 ImagePullBackOff 0 46m
5.5.5HPA
HPA(Horiaontal Pod Autoscaling)他可以根據當前Pod資源(如CPU,磁盤,內存),進行副本數的動態擴容和縮容,以便減輕各個Pod的壓力,當Pod負載達到一定的閾值后,會根據擴縮容的策略生成更多新的Pod來分擔壓力,當Pod的使用比較空閑時,在穩定空閑一段時候后,還回自動減少Pod的副本數量。
5.5.5.1安裝Metrics-server
在新版的K8S中,系統資源的采集均使用Metrics-Server服務,可以通過Metrics-Server服務采集節點和Pod的內存、磁盤、CPU和網絡的使用率等信息。說的具體點:新版K8S資源使用情況的度量(如容器的 CPU 和內存使用)可以通過 Metrics API 獲取。
- 1.下載并解壓Metrics-Server
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.7/components.yaml
- 2.修改鏡像地址

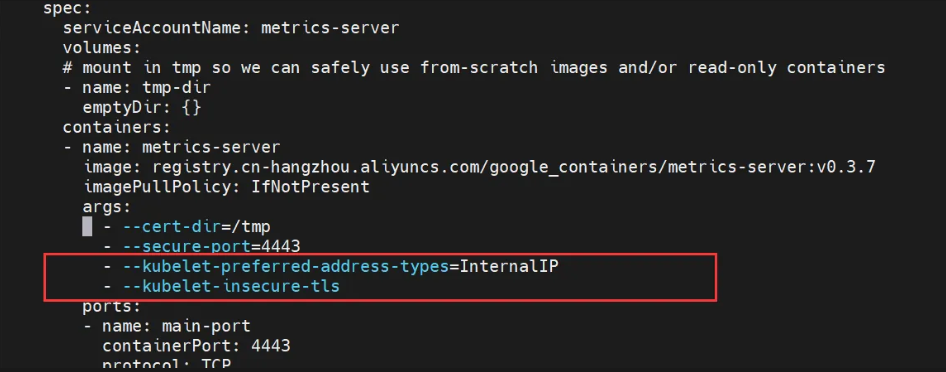
- 3.安裝Metrics-Server
kubectl apply -f components.yaml
- 4.查看node信息
[root@k8s-master metrics-server]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 187m 4% 4765Mi 61%
k8s-node1 109m 2% 3306Mi 42%
k8s-node2 90m 2% 3112Mi 40%
如果其中一個節點顯示為unknow,有可能是該節點沒有關閉防火墻(開放端口),關閉防火墻(開放端口)后,metrics-service需要一段時間才能檢測到CPU信息。
5.5.5.2HPA的使用
- 1.創建Deployment
[root@k8s-master metrics-server]# vi php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: php-apache
spec:selector:matchLabels:run: php-apachereplicas: 1template:metadata:labels:run: php-apachespec:containers:- name: php-apacheimage: "registry.cn-shenzhen.aliyuncs.com/cookcodeblog/hpa-example:latest"ports:- containerPort: 80resources:limits:cpu: 500mrequests:cpu: 200m
---
apiVersion: v1
kind: Service
metadata:name: php-apachelabels:run: php-apache
spec:ports:- port: 80selector:run: php-apache
- 2.創建php-apache并驗證
[root@k8s-master metrics-server]# kubectl apply -f php-apache.yaml
[root@k8s-master metrics-server]# kubectl get deploy,svc php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/php-apache 1/1 1 1 2m26sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/php-apache ClusterIP 10.100.133.191 <none> 80/TCP 2m26s
[root@k8s-master metrics-server]# kubectl get pod -l run=php-apache -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
php-apache-5b58575b9d-bc56q 1/1 Running 0 3m6s 10.244.1.38 k8s-node1 <none> <none>
- 3.創建HPA
[root@k8s-master metrics-server]# kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
horizontalpodautoscaler.autoscaling/php-apache autoscaled
注:為deployment php-apache 創建HPA,其中最小副本數為1,最大副本數為10,保持該deployment的所有Pod的平均CPU使用率不超過50%。在本例中,deployment的pod的resources.request.cpu為200m (200 milli-cores vCPU),所以HPA將保持所有Pod的平均CPU使用率不超過100m。
- 4.通過kubectl top pods查看pod的CPU使用情況。
[root@k8s-master metrics-server]# kubectl get hpa php-apache
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 17s
- 5.模擬增加負載
打開一個新的Terminal,創建一個臨時的pod
load-generator,并在該pod中向php-apache服務發起不間斷循環請求,模擬增加php-apache的負載(CPU使用率)。
[root@k8s-master metrics-server]# kubectl run -i --tty load-generator --rm --image=busybox --restart=Never – /bin/sh -c “while sleep 0.01; do wget -q -O- http://php-apache; done”
If you don’t see a command prompt, try pressing enter.
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!
- 模擬壓力測試幾分鐘后,觀察HPA:
```bash
[root@k8s-master metrics-server]# kubectl get hpa php-apache
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 75%/50% 1 10 5 10m
可以看到TARGETS(CPU使用率)的acutal值已升高到75% (超過了期望值50%),副本數REPLICAS也從1自動擴容到了5。
注:如果Kubernetes集群worker節點的CPU資源已經不足,HPA自動擴容會失敗,新擴容的pod會一直處在Pending狀態。通過kubectl describe命令查看pod詳細信息時,會看到“Insufficient cpu"的錯誤信息。
注:也就是HPA通過自動擴容到5個副本,來分攤了負載,使得所有Pod的平均CPU使用率保持在目標值內
- 6.模擬減少負載
在運行
load-generator的Terminal,按下Ctrl+C來終止進程。
等待幾分鐘后,觀察HPA:
[root@k8s-master metrics-server]# kubectl get hpa php-apache
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 22m
注:Kuberntes為了保證縮容時業務不中斷,和防止頻繁伸縮導致系統抖動,scaledown一次后需要等待一段時間才能再次scaledown,也叫伸縮冷卻(cooldown)。默認伸縮冷卻時間為5分鐘。
通過
kubectl describe hpa php-apache查看HPA自動伸縮的事件,可以看到“horizontal-pod-autoscaler New size: 1; reason: All metrics below target”的事件。
5.6Service
“Service”簡寫“svc”,Pod不能直接提供給外網訪問,而是應該使用Service,Service就是把Pod暴露出來提供服務,可以說Service是一個應用服務的抽象,定義了Pod邏輯集合和訪問這個Pod集合的策略,Service代理Pod集合,對外表現為一個訪問入口,訪問該入口的請求將經過負責均衡,轉發到后端Pod中的容器。
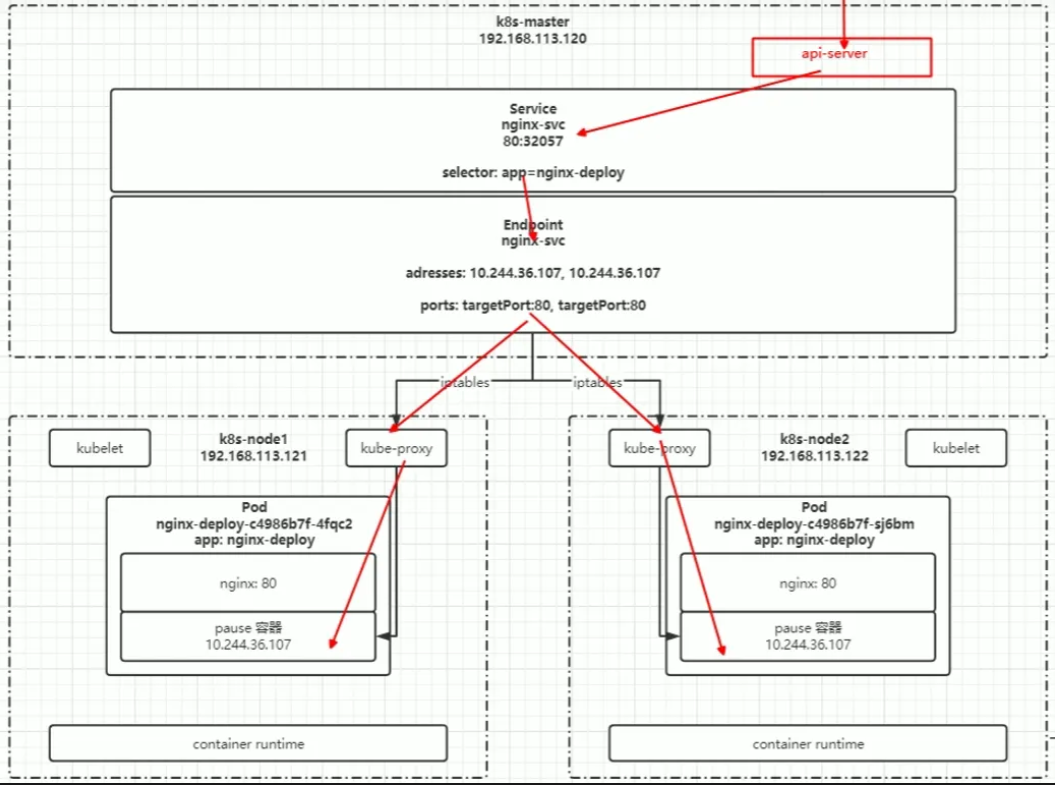
在Kubernetes中,當我們使用kubectl命令的時候,master節點上的api-server會接收到kubectl命令,然后分配給對應的service,讓service去調用endpoint,endpoint中存儲著node節點的ip和端口,然后endpoint通過kube-proxy去調用pod中容器。
5.6.1創建
apiVersion: v1 # api版本
kind: Service
metadata:namespace: dev # 命名空間name: nginx-svc # 對象名稱labels:app: nginx # Service本身的標簽
spec:selector:app: nginx-deploy # 所有匹配到這些標簽的Pod都可以通過該Service進行訪問ports:- port: 80 # Service自己的端口,在使用內網Ip訪問時使用targetPort: 80 # 目標Pod的端口protocol: TCP # 端口綁定的協議,支持TCP,UDP,SCTP,默認為TCPname: web # 為端口起個名字type: NodePort # 隨機起一個端口,映射到Ports中的端口,該端口是直接綁定在Node上的,且集群中的每一個node都會綁定這個端口,也可以用于將服務暴露給外部使用,但是這種方式實際環境不推薦,效率較低,而且Service是四層負載。
5.6.2查看svc和刪除svc
[root@k8s-master services]# kubectl get svc -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc NodePort 10.101.91.104 <none> 80:30718/TCP 7s[root@k8s-master services]# kubectl delete -f nginx-service.yaml
service "nginx-svc" deleted
5.6.3創建一個 NodePort 類型的 Service,并手動指定一個外部服務的 IP 和端口作為后端(Endpoints)
普通的Service通過Label Selector對后端Endpoint列表進行了一次抽象,如果后端Endpoint不是由Pod副本提供,則Service還可以抽象定義為任意其他服務,將一個Kubernetes集群外的已知服務定義為Kubernetes內的一個Service,供集群內其他應用訪問,常見的應用場景。
apiVersion: v1 # api版本
kind: Service
metadata:namespace: dev # 命名空間name: nginx-svc-external # 對象名稱labels:app: nginx # Service本身的標簽
spec:ports:- port: 80 # Service自己的端口,在使用內網Ip訪問時使用targetPort: 80 # 目標Pod的端口name: webtype: NodePort
---
apiVersion: v1
kind: Endpoints
metadata:labels:app: nginxname: nginx-svc-externalnamespace: dev
subsets:- addresses:- ip: 172.29.201.237ports:- port: 8099name: webprotocol: TCP
#創建資源kubectl create -f nginx-svc-external-ip.yaml#查看svc,ep
kubectl get svc,ep#使用busybox容器檢測,沒有的可以創建
kubectl run -it --image busybox:1.28.4 dns-test -- /bin/sh#已存在使用該指令進入pod
kubectl exec -it dns-test -- sh#進入pod內使用wget命令檢測,其中nginx-svc-external為服務的名稱,支持跨namespace訪問,訪問方式為<serviceName>.<namespace>
wget http://nginx-svc-external
5.6.4將集群內部對 nginx-svc-external-domain 的訪問映射到外部域名 www.wssnail.com
apiVersion: v1
kind: Service #類型
metadata: #元數據name: nginx-svc-external-domain #service的名稱namespace: devlabels:app: nginx-svc-external-domain #自身的標簽
spec:type: ExternalNameexternalName: www.wssnail.com
總結下來,之所以將IP或者域名配置成service的原因在于,當外部服務遷移到集群內時,只需給Service添加Selector,業務代碼無需修改。也就是通過服務發現來訪問。
什么是服務發現?服務發現是分布式系統中的一個核心概念,指的是讓應用程序或服務能夠自動發現并訪問它所依賴的其他服務,而無需硬編碼 IP 地址或主機名。在 Kubernetes 中,服務發現主要由 Service 和 DNS 機制來實現。也就是可以直接通過“http://服務名稱”可以直接訪問pod
5.6.5常用的類型
5.6.5.1ClusterIP
僅限集群內部訪問,不暴露到外網,自動分配一個虛擬 IP(VIP),生命周期內固定,通過 DNS 名稱(如 my-service.default.svc.cluster.local)訪問。
apiVersion: v1
kind: Service
metadata:name: my-service
spec:type: ClusterIP # 可省略,默認就是 ClusterIPselector:app: my-appports:- port: 80 # Service 暴露的端口targetPort: 8080 # Pod 的端口
5.6.5.2NodePort
在 ClusterIP 基礎上,額外在每個 Node 上綁定一個靜態端口(30000-32767),可以通過 NodeIP:NodePort 從集群外部訪問。
apiVersion: v1
kind: Service
metadata:name: my-service
spec:type: NodePortselector:app: my-appports:- port: 80 # Service 端口(集群內訪問)targetPort: 8080 # Pod 端口nodePort: 31000 # 手動指定 Node 端口(默認隨機)
5.6.5.3LoadBalancer
自動請求云廠商(AWS/GCP/Azure)的負載均衡器。分配一個公網 IP,并自動配置負載均衡規則
。底層仍然是 NodePort + ClusterIP,但由云廠商管理流量。本地集群(如裸金屬)默認不支持 LoadBalancer,需安裝 MetalLB 等解決方案。
apiVersion: v1
kind: Service
metadata:name: my-webapp
spec:type: LoadBalancer # 關鍵配置selector:app: nginxports:- port: 80 # 負載均衡器監聽的端口(外部訪問用)targetPort: 80 # Pod 容器的端口protocol: TCPexternalTrafficPolicy: Local # 可選,保留客戶端真實 IP
5.6.5.4ExternalName
不代理 Pod,而是返回一個 CNAME 記錄(DNS 重定向)。將 Service 名稱映射到外部域名(如 my-service → api.example.com)。
apiVersion: v1
kind: Service
metadata:name: my-external-service
spec:type: ExternalNameexternalName: api.example.com # 解析到這個域名
5.6.5.5 Headless Service(無頭服務)
沒有 ClusterIP,直接返回 Pod IP 列表,適用于需要直接訪問 Pod 的場景(如 StatefulSet),DNS 查詢會返回所有 Pod 的 IP(而不是負載均衡),適用場景為數據庫集群(如 MySQL、MongoDB 副本集)。
apiVersion: v1
kind: Service
metadata:name: my-headless-service
spec:clusterIP: None # 關鍵配置!selector:app: my-appports:- port: 80targetPort: 8080
5.7Ingress
Ingress 是 Kubernetes 中用于管理外部訪問集群服務的 API 對象,主要提供 HTTP/HTTPS 路由、基于域名的虛擬主機、SSL/TLS 終止等功能。與 LoadBalancer 相比,Ingress 更專注于 應用層(L7)流量管理,且能通過單一入口暴露多個服務。Ingress 規則需要由 Ingress Controller 實現,它是一個實際運行在集群中的代理服務(如 Nginx、Traefik)。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: my-ingressannotations:nginx.ingress.kubernetes.io/rewrite-target: / # 注解(依賴 Ingress Controller)
spec:tls:- hosts:- example.comsecretName: tls-secret # 引用存儲證書的 Secretrules:- host: example.com # 域名http:paths:- path: /app1 # 路徑pathType: Prefixbackend:service:name: app1-service # 后端 Serviceport:number: 80- path: /app2pathType: Prefixbackend:service:name: app2-serviceport:number: 8080
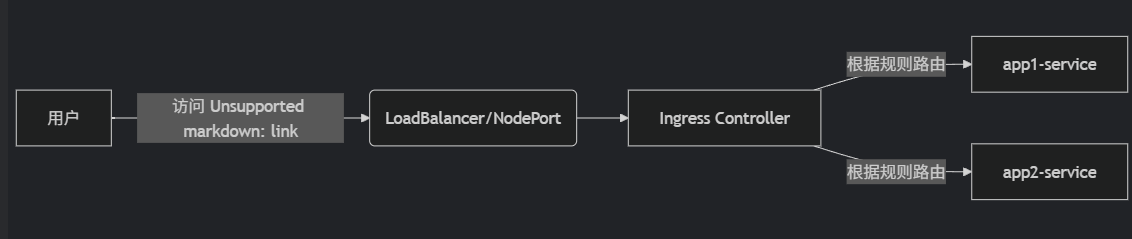
6.配置
6.1ConfigMap
存儲非敏感的配置數據(如環境變量、配置文件)。以鍵值對(key-value)形式存儲。可通過環境變量或文件掛載到 Pod。
apiVersion: v1
kind: ConfigMap
metadata:name: my-config
data:APP_COLOR: "blue"APP_ENV: "prod"config.json: | # 多行文本(如配置文件){"logLevel": "debug"}
作為環境變量使用
apiVersion: v1
kind: Pod
metadata:name: my-pod
spec:containers:- name: my-containerimage: nginxenv:- name: APP_COLOR # 環境變量名valueFrom:configMapKeyRef:name: my-config # ConfigMap 名稱key: APP_COLOR # 鍵名
掛載為文件
spec:containers:- name: my-containerimage: nginxvolumeMounts:- name: config-volume # 卷名稱mountPath: /etc/config # 掛載路徑volumes:- name: config-volumeconfigMap:name: my-config # ConfigMap 名稱items:- key: config.json # 鍵名path: app-config.json # 掛載后的文件名
6.2Secret
存儲敏感數據(如密碼、TLS 證書、API 密鑰)。數據以 Base64 編碼(非加密,需配合 RBAC 和網絡策略保護)。支持掛載為文件或環境變量。
6.2.1創建Secret
apiVersion: v1
kind: Secret
metadata:name: my-secret
type: Opaque # 通用類型
data:DB_USER: YWRtaW4= # admin(Base64 編碼)DB_PASSWORD: MTIzNDU2 # 123456
作為環境變量
env:- name: DB_PASSWORDvalueFrom:secretKeyRef:name: my-secretkey: DB_PASSWORD
作為文件
volumes:- name: secret-volumesecret:secretName: my-secretitems:- key: ssl.crtpath: tls.crt # 掛載為 /etc/secret/tls.crt
7.存儲
7.1Volumn
Volume 的生命周期與 Pod 綁定,但可以超越單個容器的生命周期,解決了容器內數據持久化的問題。通過spec.volumes定義,spec.containers.volumeMounts掛載。
7.1.1EmptyDir
EmptyDir是最基礎的Volumn類型,一個EmptyDir就是一個空目錄,EmptyDir是在Pod被分配到Node時創建的,它的初始內容為空,并且必須指定宿主機上對應的目錄文件,因為kubernets會自動分配一個目錄,當Pod銷毀,EmptyDir中的數據也會被永久刪除。常用在臨時空間,例如用于某些應用程序運行時所需的臨時目錄,且無須永久保留。
apiVersion: v1
kind: Pod
metadata:name: empty-dir-podnamespace: dev
spec:containers:- name: nginximage: nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80volumeMounts:- name: logs-volumemountPath: /var/log/nginx- name: busyboximage: busybox:latestimagePullPolicy: IfNotPresentcommand: ["/bin/sh","-c","tail -f /logs/access.log"]volumeMounts:- name: logs-volumemountPath: /logsvolumes:- name: logs-volumeemptyDir: {}
7.1.2HostPath
EmptyDir中的數據不會被數據化,它會隨著Pod的結束而銷毀,如果想簡單的將數據持久化到主機中,可以選擇HostPath,HostPath就是將Node主機中一個實際目錄掛在到Pod中,以供容器使用,這樣的設計可以保證Pod銷毀了,但是數據一句依舊存在于Node主機中。例子如下(但是需要注意的是這兩個容器使用了一個HostPath,所以都能讀取到對方的掛載文件):
apiVersion: v1
kind: Pod
metadata:name: host-path-podnamespace: dev
spec:containers:- name: nginximage: nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80volumeMounts:- name: logs-volumemountPath: /var/log/nginx- name: busyboximage: busybox:latestimagePullPolicy: IfNotPresentcommand: ["/bin/sh","-c","tail -f /logs/access.log"]volumeMounts:- name: logs-volumemountPath: /logsvolumes:- name: logs-volumehostPath:path: /root/logstype: DirectoryOrCreate # 目錄存在就使用,不存在就先創建后使用
spec.volumes.hostPath.type的取值:
DirectoryOrCreate 目錄存在就使用,不存在就先創建后使用
Directory 目錄必須存在
FileOrCreate 文件存在就使用,不存在就先創建后使用
File 文件必須存在
Socket unix套接字必須存在
CharDevice 字符設備必須存在
BlockDevice 塊設備必須存在
7.1.3NFS
HostPath可以解決數據持久化的問題,但是一旦Node節點故障了,Pod如果轉移到了別的節點,就會出現問題,此時需要準備單獨的網絡存儲系統,比如常見的是NFS、CIFS,NFS是一個網絡文件存儲系統,可以搭建一臺NFS服務器,然后將Pod中的存儲直接連接到NFS系統,這樣的話,無論Pod在節點上怎么轉移,只要Node跟NFS的對接沒問題,數據就可以成功訪問了。
NFS代表網絡文件系統(Network File System),它是一種用于在計算機系統之間共享文件和目錄的協議,NFS被廣泛用于Unix和Linux操作系統種,它允許遠程計算機像訪問本地文件一樣訪問和操作遠程文件,從而方便了多臺計算機之間的文件共享和協作。
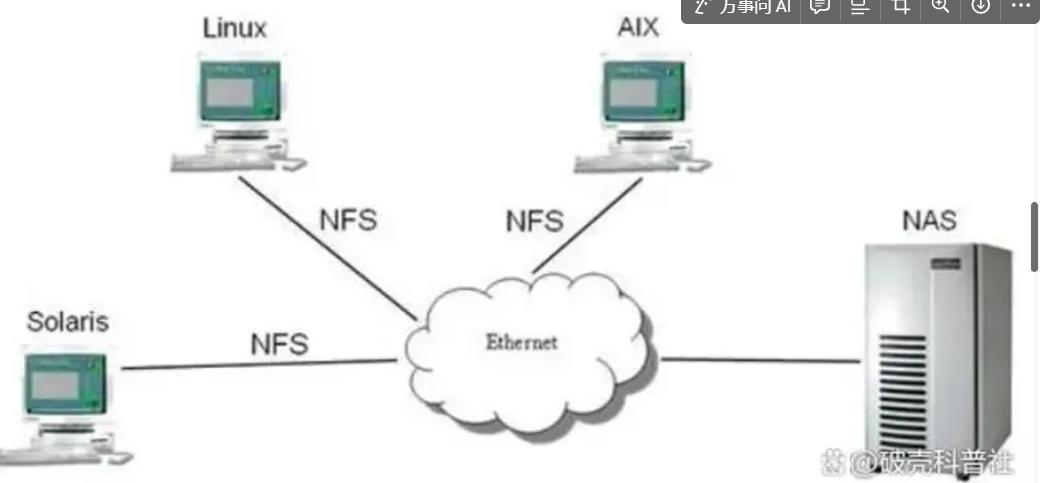
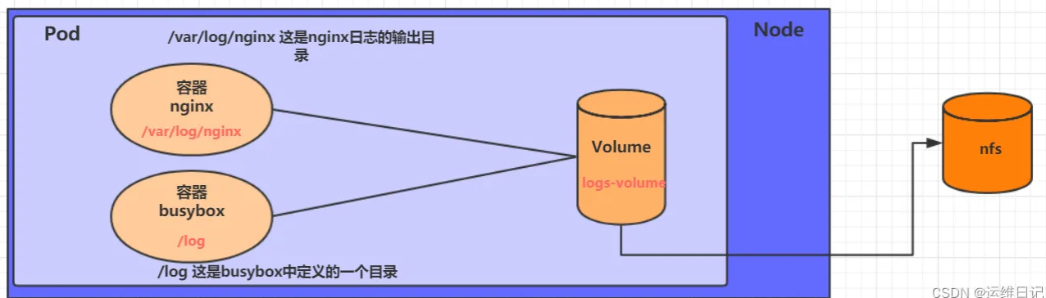
例子如下:
- 1.首先要準備nfs的服務器,這里為了簡單,直接是master節點做nfs服務器
# 在nfs上安裝nfs服務
[root@nfs ~]# yum install nfs-utils -y# 準備一個共享目錄
[root@nfs ~]# mkdir /root/data/nfs -pv# 將共享目錄以讀寫權限暴露給192.168.126.0/24網段中的所有主機
[root@nfs ~]# vim /etc/exports
[root@nfs ~]# more /etc/exports
/root/data/nfs 192.168.126.0/24(rw,no_root_squash)# 啟動nfs服務
[root@nfs ~]# systemctl restart nfs
- 2.接下來,要在的每個node節點上都安裝下nfs,這樣的目的是為了node節點可以驅動nfs設備
# 在node上安裝nfs服務,注意不需要啟動
[root@k8s-master01 ~]# yum install nfs-utils -y
- 3.接下來,就可以編寫pod的配置文件了,創建volume-nfs.yaml
apiVersion: v1
kind: Pod
metadata:name: volume-nfsnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1ports:- containerPort: 80volumeMounts:- name: logs-volumemountPath: /var/log/nginx- name: busyboximage: busybox:1.30command: ["/bin/sh","-c","tail -f /logs/access.log"] volumeMounts:- name: logs-volumemountPath: /logsvolumes:- name: logs-volumenfs:server: 192.168.126.201 #nfs服務器地址path: /root/data/nfs #共享文件路徑
- 4.最后,運行下pod,觀察結果
# 創建pod
[root@k8s-master01 ~]# kubectl create -f volume-nfs.yaml
pod/volume-nfs created# 查看pod
[root@k8s-master01 ~]# kubectl get pods volume-nfs -n dev
NAME READY STATUS RESTARTS AGE
volume-nfs 2/2 Running 0 2m9s# 查看nfs服務器上的共享目錄,發現已經有文件了
[root@k8s-master01 ~]# ls /root/data/
access.log error.log
7.2PV和PVC
我剛剛在想有了HostPath和NFS,為什么還用PV和PVC,AI給我一個解答,我覺得是正確的。開發/運維分離,開發者只需聲明"我需要5GB可讀寫存儲",運維者決定實際使用NFS、云存儲還是本地SSD。
7.2.1PV
Persistent Volume,系統資源)是持久化卷的意思,是對底層的共享存儲的一種抽象。一般情況下PV由kubernetes管理員進行創建和配置,它與底層具體的共享存儲技術有關,并通過插件完成與共享存儲的對接。創建yaml如下:
apiVersion: v1
kind: PersistentVolume
metadata:name: pv2
spec:nfs: # 存儲類型,與底層真正存儲對應capacity: # 存儲能力,目前只支持存儲空間的設置storage: 2GiaccessModes: # 訪問模式,ReadWriteOnce(RWO):讀寫權限,但是只能被單個節點掛載,ReadOnlyMany(ROX): 只讀權限,可以被多個節點掛載,ReadWriteMany(RWX):讀寫權限,可以被多個節點掛載storageClassName: # 存儲類別,PV可以通過storageClassName參數指定一個存儲類別。具有特定類別的PV只能與請求了該類別的PVC進行綁定。未設定類別的PV則只能與不請求任何類別的PVC進行綁定。persistentVolumeReclaimPolicy: # 當PV不再被使用了之后,對其的處理方式。目前支持三種策略,需要注意的是,底層不同的存儲類型可能支持的回收策略不同。Retain (保留) 保留數據,需要管理員手工清理數據,Recycle(回收) 清除 PV 中的數據,效果相當于執行 rm -rf /thevolume/*,Delete (刪除) 與 PV 相連的后端存儲完成 volume 的刪除操作,當然這常見于云服務商的存儲服務。
例子如下:
apiVersion: v1
kind: PersistentVolume
metadata:name: pv3
spec:capacity: storage: 3GiaccessModes:- ReadWriteManypersistentVolumeReclaimPolicy: Retainnfs:path: /root/data/pv3server: 192.168.5.6
7.2.2PVC
PVC(Persistent Volume Claim,命名空間級別資源)是持久卷聲明的意思,是用戶對于存儲需求的一種聲明。換句話說,PVC其實就是用戶向Kubernetes系統發出的一種資源需求申請。創建yaml如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvcnamespace: dev
spec:accessModes: # 訪問模式selector: # 采用標簽對PV選擇storageClassName: # 存儲類別resources: # 請求空間requests:storage: 5Gi
參數描述
- 訪問模式:用于描述用戶應用對存儲資源的訪問資源
- 選擇條件:通過Label Selector的設置,可使PVC對于系統中已存在的PV進行篩選
- 存儲類別:PVC定義時可以設定需要的后端存儲的類別,只有設置了該class的pv才能被系統選出
- 資源請求:描述對存儲資源的請求
例子
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc1namespace: dev
spec:accessModes: - ReadWriteManyresources:requests:storage: 1Gi
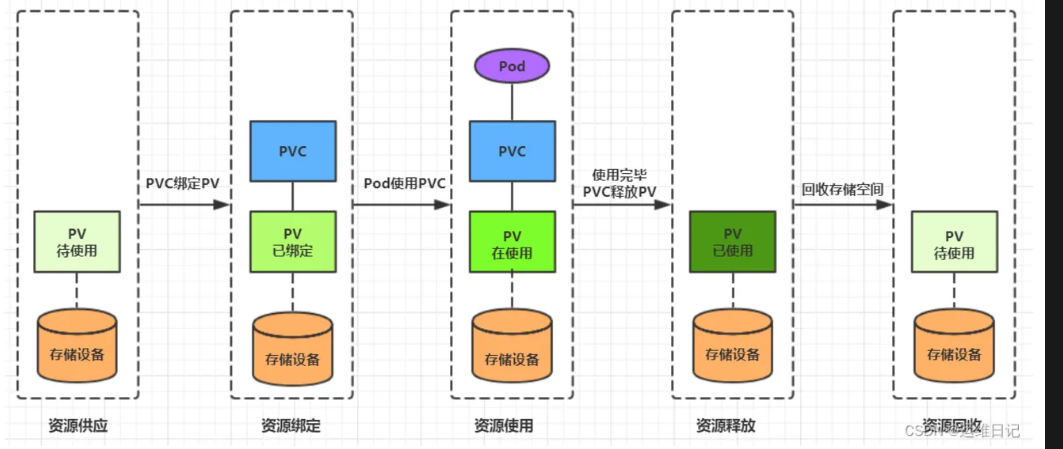
7.2.3生命周期
PVC和PV是一一對應的,在用戶定義好PVC之后,系統將根據PVC對存儲資源的請求在已存在的PV中選擇一個滿足條件的,如果找不到PVC會無限期處于Pending狀態,直到系統管理員創建一個符合其要求的PV,PV一旦綁定到某個PVC上,就會被這個PVC獨占,不能再與其他PVC綁定了。用戶可以在Pod中向Volume一樣使用PVC。
當存儲資源使用完畢后,用戶可以刪除PVC,與該PVC綁定的PV將會被標記為已釋放,但還不能立即與其他PVC進行綁定,通過之前PVC寫入的數據可能還留在存儲設備上,只有在清除之后PV才能再次被使用。
對于PV,管理員可以設定回收策略,用于設置與之綁定的PVC釋放資源之后如何處理遺留數據的問題。只有PV的存儲空間完成回收,才能供新的PVC綁定和使用。
8原生組件介紹
8.1執行流程
─────────────────────────────────────────────────────Kubernetes 控制平面流程
─────────────────────────────────────────────────────+─────────────+ +───────────────+│ 用戶/工具 │ │ Cloud Provider││ (kubectl/UI)│ │ API │+──────┬──────+ +───────┬───────+│ ││ 1. 創建/更新資源請求 │├──────────────────────┘▼+───────────────+ 2. 驗證/存儲 +──────+│ kube-apiserver │?──────────────────?│ etcd │+──────┬───────┬─+ 集群狀態 +──────+│ ││ │ 3. 資源變更通知(kube-scheduler 只關心未調度的 Pod,它的核心職責是決定 Pod 應該運行在哪個節點上。kube-controller-manager 包含多個控制器,每個控制器監聽不同的資源,確保集群狀態符合用戶聲明的期望狀態.)│ ├──────────────────────┐│ │ │▼ ▼ ▼+─────────────+ +─────────────────+ +──────────────────+│ kube-scheduler │ │ kube-controller- │ │ cloud-controller- │+──────┬───────+ │ manager │ │ manager ││ +────────┬────────+ +────────┬────────+│ │ ││ 4. 分配節點 │ 5. 確保期望狀態 │ 6. 云資源操作▼ ▼ ▼+─────────────+ +─────────────+ +─────────────+│ 工作節點 │ │ 工作節點 │ │ 云基礎設施 ││ (kubelet) │ │ (kubelet) │ │ (VM/負載均衡)│+─────────────+ +─────────────+ +─────────────+
8.2CoreDNS
負責為整個k8s集群提供 DNS 服務,屬于DNS插件。基于dns的接口去實現集群內部的dns內部域名解析的一種能力。k8s集群創建后,會在kube-system名稱空間下默認生成兩個coredns的pod,所有pod的域名請求會以負載均衡的方式向這兩個coredns的pod進行域名解析。
8.2.1Pod的請求鏈路分析
Pod 網絡棧 → kube-proxy → CoreDNS Pod。
在 Kubernetes 環境中,當 CoreDNS 成功解析一個域名后,請求不會繼續傳遞到操作系統 /etc/resolv.conf 中配置的上游 DNS 服務器。這是由 Kubernetes DNS 解析的層級機制和 CoreDNS 的工作邏輯決定的。在 Kubernetes 環境中,CoreDNS 不會緩存 /etc/resolv.conf 中配置的上游 DNS 服務器地址,但會根據配置動態讀取和使用這些上游 DNS。
9.K3S
9.1關閉防火墻
systemctl disable firewalld --now
9.2安裝Docker源
# 安裝docker倉庫源
yum -y install wget && wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
# 安裝docker
yum install -y docker-ce-20.10.12-3.el7 docker-ce-cli-20.10.12-3.el7 containerd.io
# 設置docker服務自啟動并啟動服務
systemctl enable docker --now
# 設置docker鏡像源
mkdir /etc/docker
cat > /etc/docker/daemon.json << EOF
{"exec-opts": ["native.cgroupdriver=systemd"],"registry-mirrors": ["https://atomhub.openatom.cn","https://registry.dockermirror.com"]
}
EOF
# 重啟docker
systemctl daemon-reload && systemctl restart docker
9.3安裝K3S主節點
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn INSTALL_K3S_VERSION=v1.29.0+k3s1 sh -s server --docker
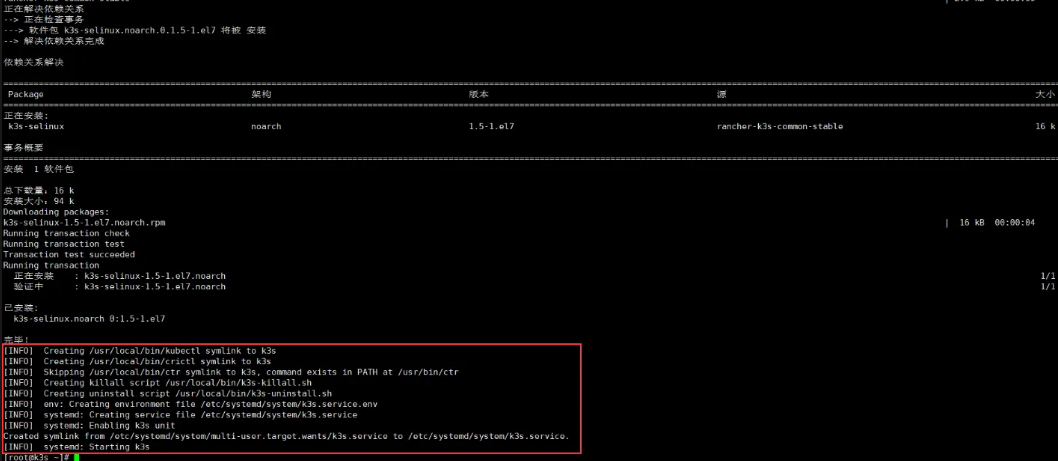
# 相關命令
systemctl status k3s # 查看服務狀態
systemctl stop k3s # 停止服務
systemctl start k3s # 啟動服務
systemctl restart k3s # 重新啟動服務
k3s-uninstall.sh # 卸載服務
# 配置ip
vi /etc/rancher/k3s/k3s.yaml
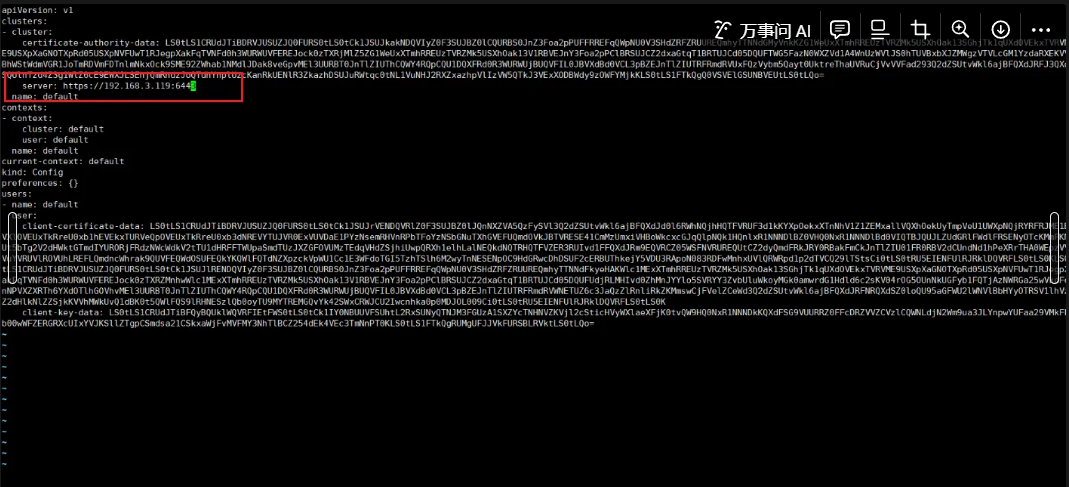
# 配置環境變量
vi /etc/profile
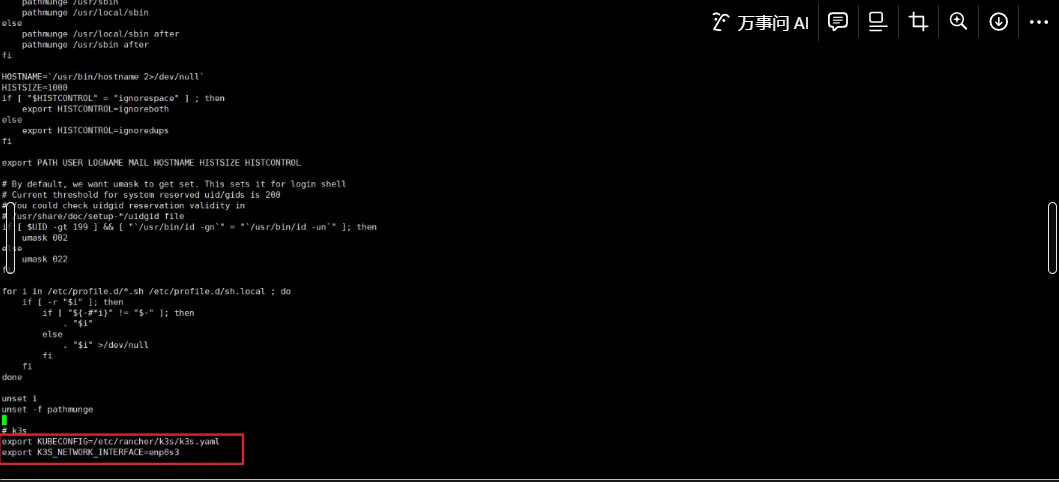
# 查看集群是否正常
watch kubectl get node -o wide

9.4安裝K3S Node節點
注意關閉防火墻
- 查看主節點token
cat /var/lib/rancher/k3s/server/node-token

- 添加node節點
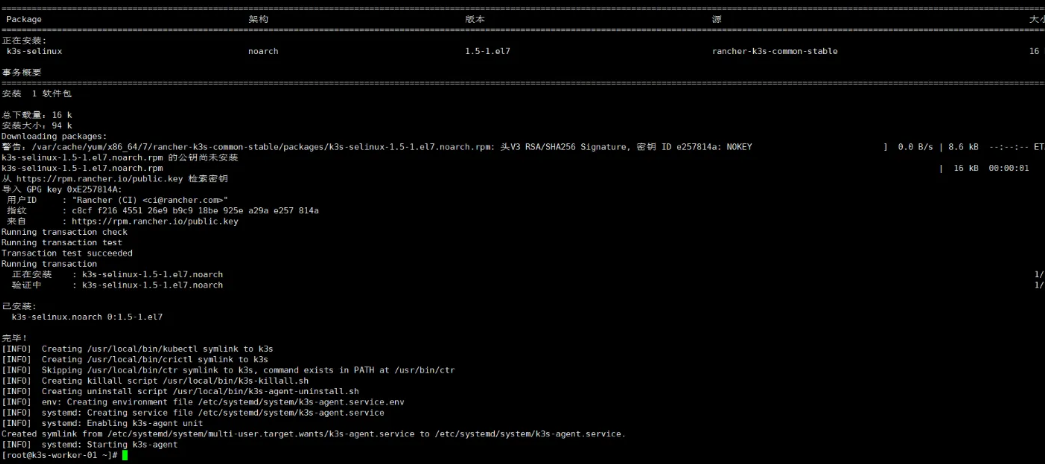
)
)



)
![華為OD-2024年E卷-通過軟盤拷貝文件[200分] -- python](http://pic.xiahunao.cn/華為OD-2024年E卷-通過軟盤拷貝文件[200分] -- python)












