目錄
一、前言
二、Elasticsearch9?語義檢索介紹
2.1 ES9 語義檢索核心特性
2.2 semantic_text 字段類型說明
2.3 ES9 語義檢索原理
2.4 ES9 語義檢索優勢與使用場景
三、 Elasticsearch9 搭建過程
3.1 環境說明
3.2 部署方式一
3.2.1 創建docker網絡
3.2.2 獲取es9鏡像
3.2.3 啟動 es容器
3.2.4 啟動kibana容器
3.2.5 創建es訪問賬戶和密碼
3.2.6 為kibana創建訪問es 的token令牌
3.2.6?生成訪問kibana的驗證碼
3.2.7 訪問kibana
3.3 部署方式二
3.3.1 初次啟動es容器
3.3.2 拷貝容器內部的文件
3.3.3 文件授權
3.3.4 移除鏡像
3.3.5 重啟es容器
3.3.6 修改es配置參數
3.3.7 啟動kibana容器
3.3.8?拷貝容器內的文件
3.3.9?文件目錄授權
3.3.10?創建kibana賬戶
3.3.11?修改容器外掛載目錄中的kibana.yml
3.3.12?重啟kibana容器
四、ES9 英文語義檢索操作過程
4.1 英文語義檢索操作案例
4.1.1 創建索引
4.1.2 索引添加數據
4.1.3 執行語義搜索
五、ES9 中文語義檢索操作過程
5.1 配置向量模型
5.1.1? 獲取向量模型和apikey
5.1.2 注冊推理API訪問入口
5.2 創建索引并增加數據
5.2.1 添加索引
5.2.2 增加幾條數據
5.3 語義檢索效果模擬
六、寫在文末
一、前言
語義檢索是指能夠理解查詢意圖和文檔含義的搜索技術,而不僅僅是關鍵詞匹配。它通過自然語言處理(NLP)和機器學習技術理解查詢和文檔的語義上下文。ES9(Elasticsearch 9)是 Elasticsearch 搜索引擎的一個重要版本,它在語義檢索(Semantic Search)方面引入了多項重要改進,使搜索更加智能化和語義化。本文將詳細介紹 Elasticsearch 9 的語義檢索特性、工作原理,并通過實際測試示例展示如何使用這些新功能。?
二、Elasticsearch9?語義檢索介紹
Elasticsearch 9.0 在語義搜索領域帶來了重大升級,通過原生支持 semantic_text 字段類型、改進的查詢方式以及與向量搜索的深度整合,為用戶提供了更強大、更靈活的語義檢索能力。

2.1 ES9 語義檢索核心特性
ES9 語義檢索具有如下核心特性:
-
原生向量搜索支持
-
內置向量數據庫功能,無需額外插件
-
支持高效的近似最近鄰(ANN)搜索
-
與傳統的倒排索引無縫集成
-
-
改進文本嵌入集成
-
簡化了嵌入模型(如BERT、GPT等)的集成流程
-
支持實時嵌入計算和索引
-
提供預訓練模型的管理功能
-
-
混合檢索模式
-
結合關鍵詞搜索(BM25)和向量搜索的優勢
-
可配置的混合評分機制
-
支持結果重排序(reranking)
-
-
增強NLP處理
-
內置更先進的文本分詞和分析器
-
改進的同義詞和語義擴展功能
-
更好的多語言支持
-
-
查詢方式擴展
-
原生 semantic 查詢:專為語義搜索設計的簡潔查詢語法
-
match 查詢支持:現在 match 查詢也可用于 semantic_text 字段,提供更熟悉的查詢體驗
-
knn 查詢支持:可直接對 semantic_text 字段執行近似最近鄰搜索
-
sparse_vector 查詢:支持稀疏向量搜索技術
-
2.2 semantic_text 字段類型說明
ES 9 引入了 semantic_text 字段類型,這是一種專為語義搜索設計的字段類型,能夠自動處理文本的向量化表示。與傳統的 text 字段不同,semantic_text 字段在索引時會自動通過配置的推理模型將文本轉換為向量表示,而無需用戶手動處理向量轉換過程。其關鍵優勢如下:
-
開箱即用:
-
只需配置推理端點,無需手動管理向量轉換過程
-
-
透明處理:
-
自動處理文本擴展和向量化,對用戶完全透明
-
-
混合搜索:
-
可與傳統關鍵詞搜索(BM25)結合使用,提升搜索結果相關性
-
2.3 ES9 語義檢索原理
ES9 語義搜索基于文本擴展(text expansion)技術,其核心工作流程如下:
-
數據存儲向量化:將寫入索引的數據進行向量化存儲
-
查詢擴展:將用戶查詢輸入通過推理模型擴展為包含相關術語的擴展查詢
-
向量轉換:將擴展后的查詢轉換為向量表示(密集或稀疏向量)
-
相似度計算:計算查詢向量與文檔向量的相似度
-
結果排序:根據相似度得分對結果進行排序
與傳統基于關鍵詞搜索相比,語義搜索能夠理解查詢的意圖和上下文,而不僅是匹配字面詞匯。例如,搜索"自新媒體運營"可以匹配到包含與新媒體語義相近的的文檔,即使文檔中沒有出現新媒體這個詞。
2.4 ES9 語義檢索優勢與使用場景
語義檢索在實際應用中是獨具優勢的,具體來說:
-
更精準的搜索結果:理解用戶查詢的真實意圖
-
自然語言查詢:支持問答式搜索和復雜查詢
-
推薦系統:基于內容相似性的推薦
-
跨語言搜索:不同語言間的語義匹配
ES9的語義檢索功能特別適用于需要理解內容語義的場景,如知識庫搜索、電子商務產品搜索、內容推薦系統等。結合大模型,可以讓語義檢索發揮更強的作用。
三、 Elasticsearch9 搭建過程
為了后面使用和驗證Elasticsearch9的語義檢索特性,需要搭建Es9,接下來介紹2種基于docker安裝Elasticsearch9的方式。
3.1 環境說明
請提前準備下面的環境
- 云服務器或虛擬機,至少2C4G;
- docker環境,版本不要太低;
3.2 部署方式一
3.2.1 創建docker網絡
使用下面的命令創建一個docker 網絡
docker network create elastic
3.2.2 獲取es9鏡像
使用下面的命令拉取es9鏡像
docker pull elasticsearch:9.0.1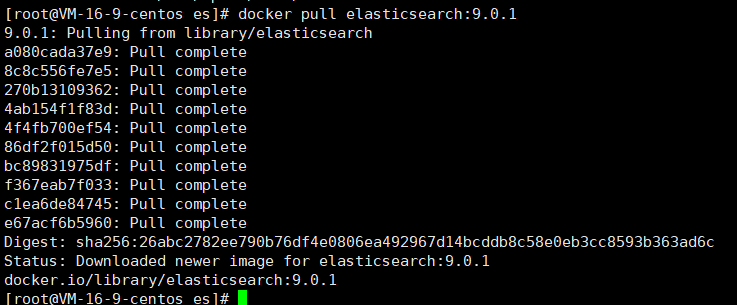
3.2.3 啟動 es容器
使用下面的命令啟動一個es容器
-
注意,如果你的服務器內存不足,建議啟動容器的時候在參數中限制一下容器占用的內存大小
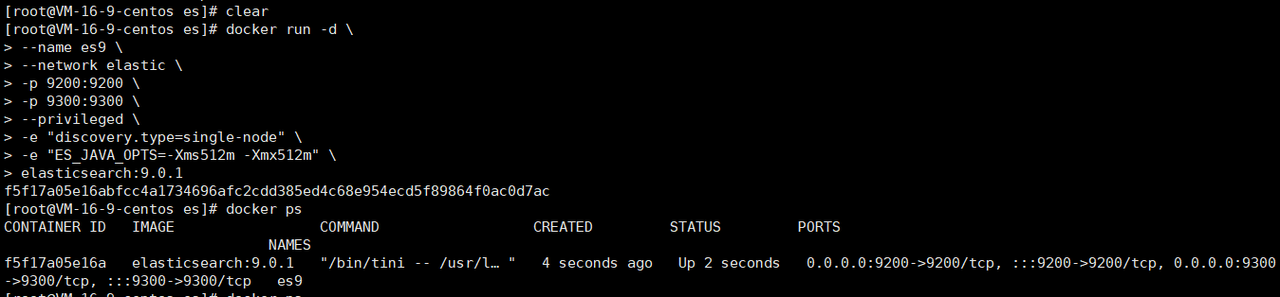
docker run -d \
--name es9 \
--network elastic \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:9.0.1容器啟動成功后,使用docker ps 命令檢查一下
3.2.4 啟動kibana容器
為了后續操作es索引數據方便,這里使用es的可視化操作工具kibana,下面使用下面的命令啟動kibana容器
docker run -d \
--name kibana_09 \
--network elastic \
-p 5601:5601 \
--privileged \
kibana:9.0.1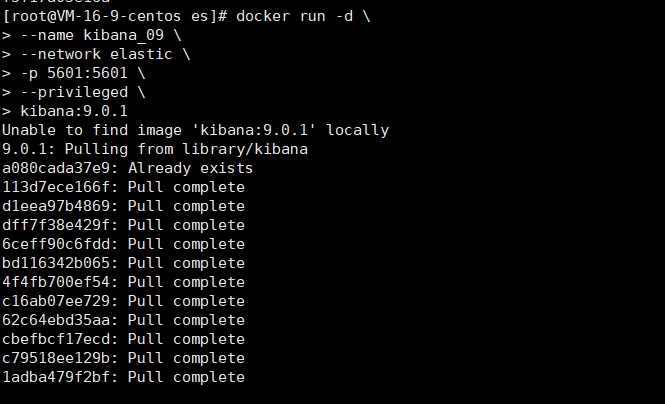
使用docker ps命令檢查是否啟動成功

3.2.5 創建es訪問賬戶和密碼
為了確保es的數據安全,默認情況下,es開啟了數據安全訪問測試,在yml配置文件中可以看到
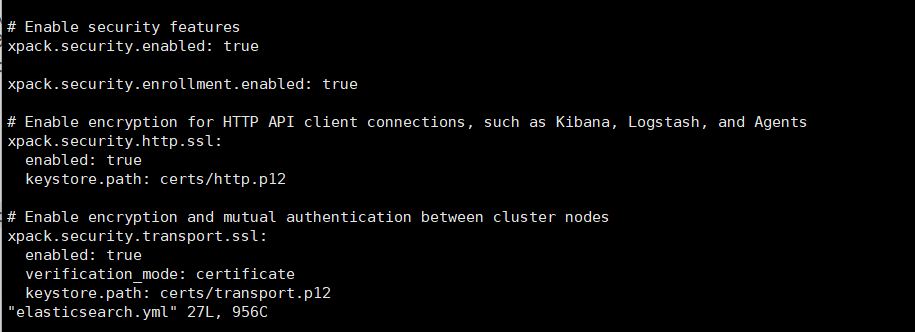
使用下面的命令創建一個賬戶和密碼,輸入命令之后,在最后會隨機生成一個密碼,注意妥善保管
docker exec -it es9 /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic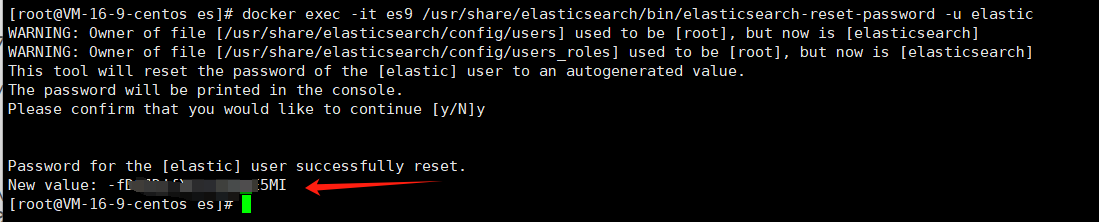
3.2.6 為kibana創建訪問es 的token令牌
還記得在使用kibana操作es的時候,在kibana中需要設置連接es的IP,端口等信息,在這里需要為kibana設置一個訪問的token令牌,參考下面的命令
docker exec -it es9 /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana執行之后稍等一會,就會生成一長串token字符串,后續在kibana訪問的時候會用到,請注意妥善保管

3.2.6?生成訪問kibana的驗證碼
這么做的目的還是為了訪問數據的安全考慮,執行下面的命令,生成驗證碼
docker exec kibana_09 /usr/share/kibana/bin/kibana-verification-code
3.2.7 訪問kibana
輸入 IP:5601 ,訪問kibana控制臺
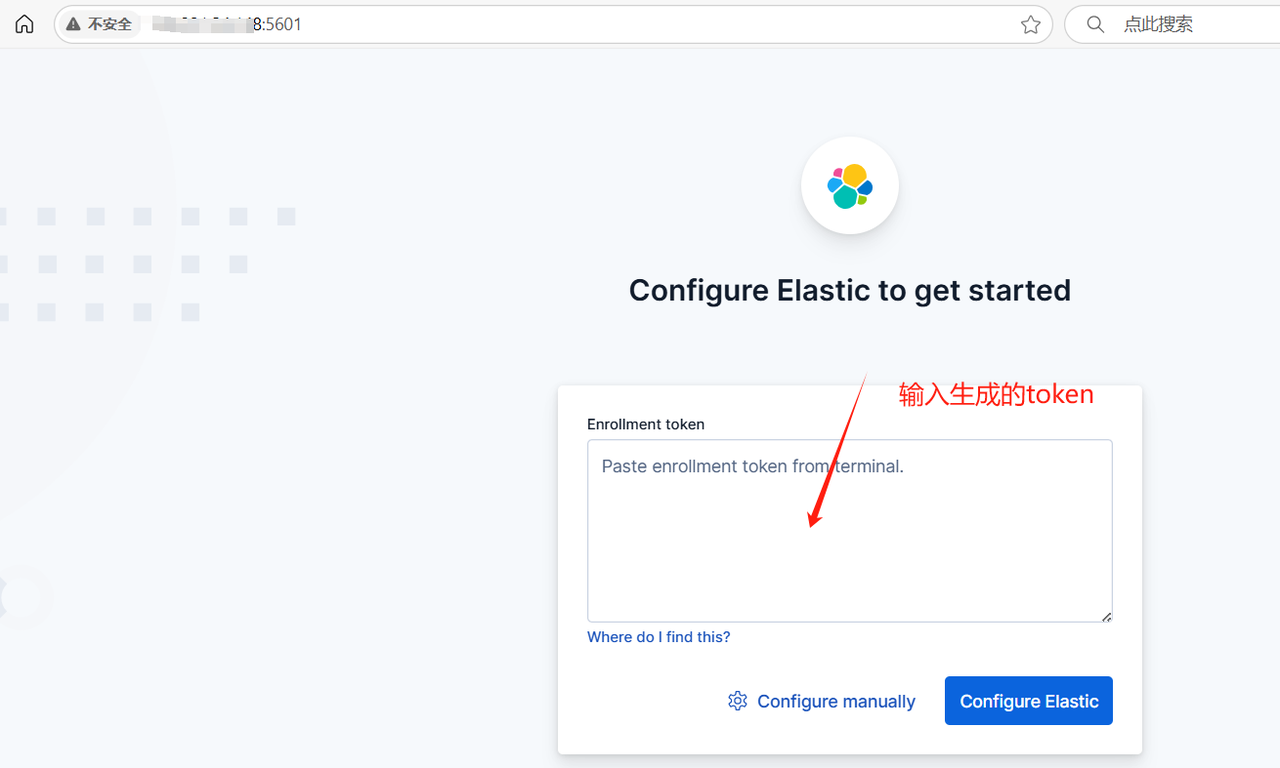
將前面生成的token粘貼到輸入框,跳轉到下面的界面后,再將生成的驗證碼輸入進去
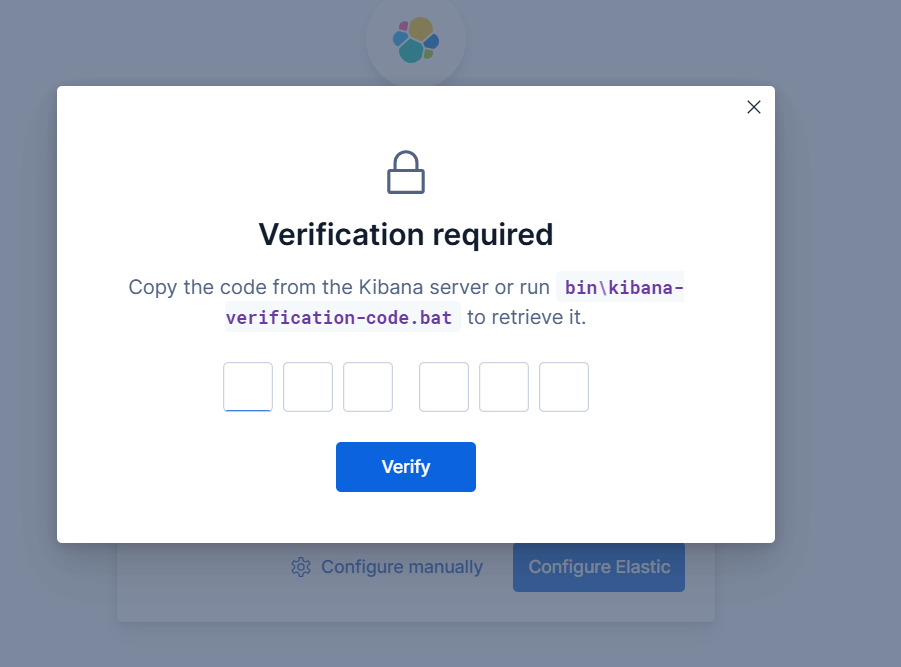
驗證成功后,跳轉到下面的頁面進行初始化相關的設置
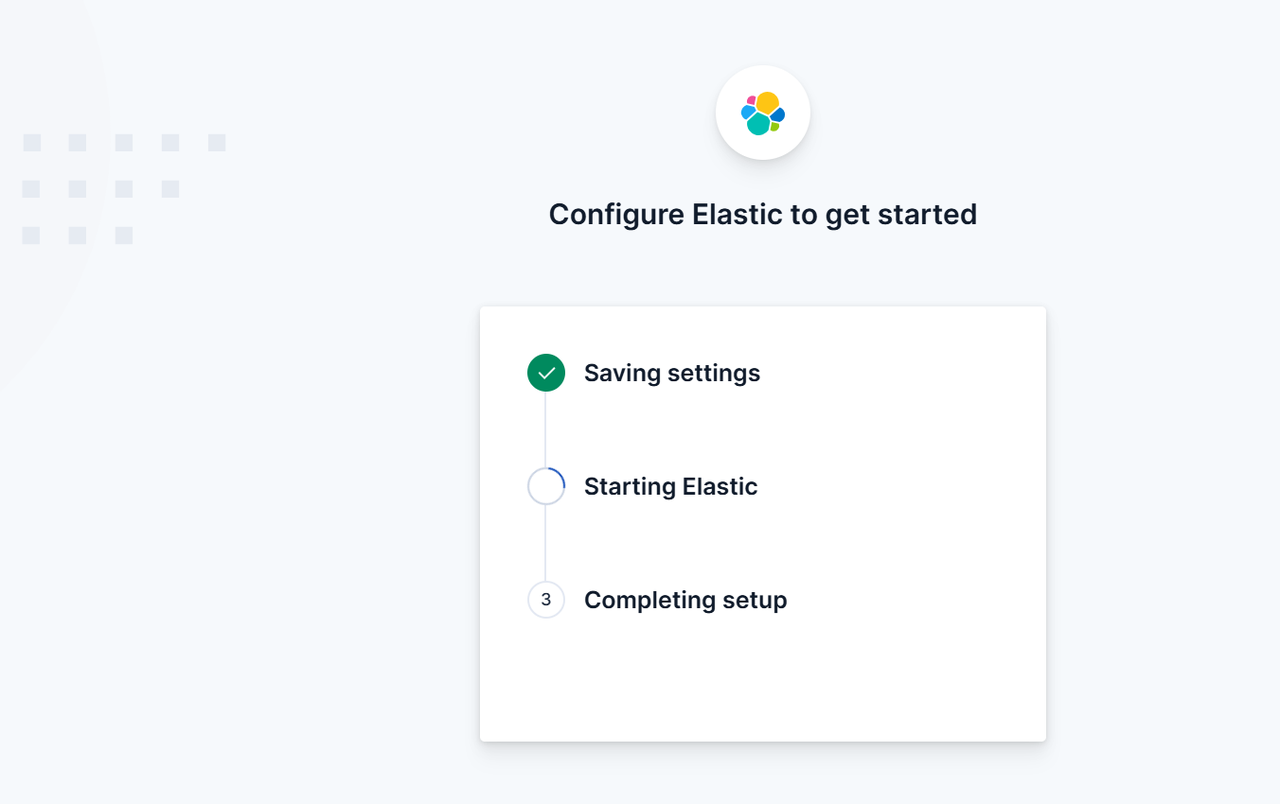
初始化完成后跳轉到下面的登錄界面,輸入前面設置的賬戶和密碼進行登錄
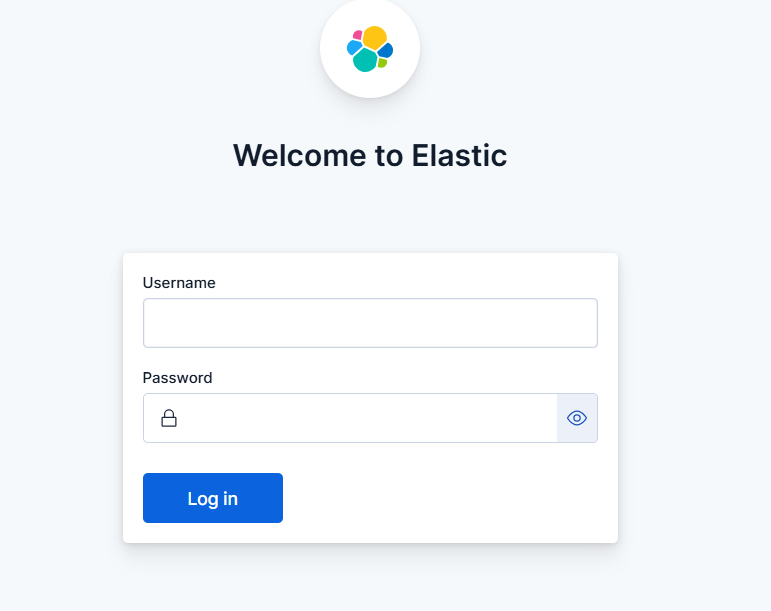
登錄成功后,就來到下面熟悉的界面了
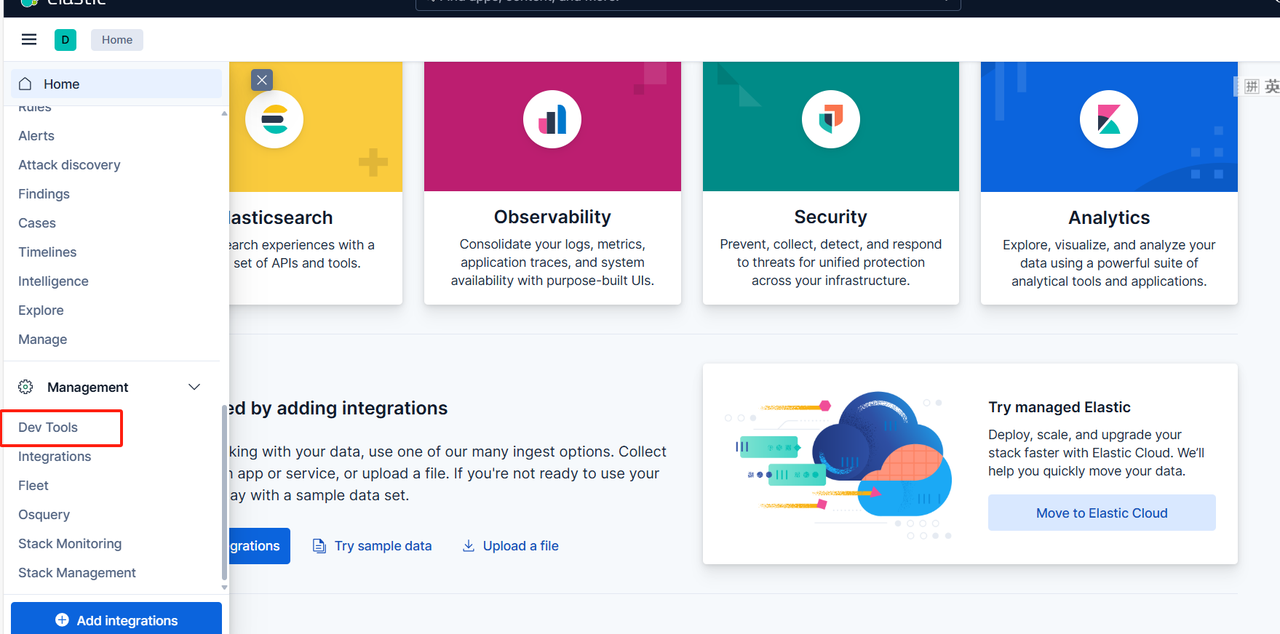
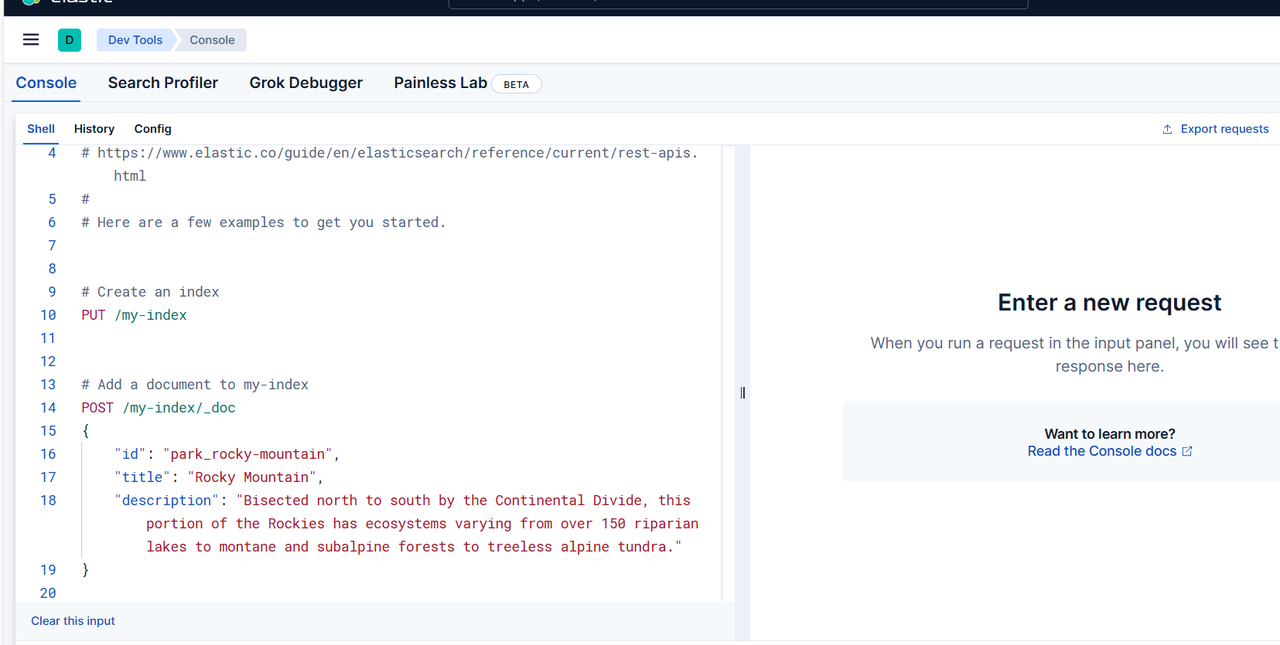
點擊左側的Dev Tools菜單,就到了熟悉的界面,在這個界面就可以操作ES相關的命令了
3.3 部署方式二
下面介紹第二種部署方式
3.3.1 初次啟動es容器
使用下面的命令啟動容器
docker run -d \
--name es9 \
--network elastic \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:9.0.1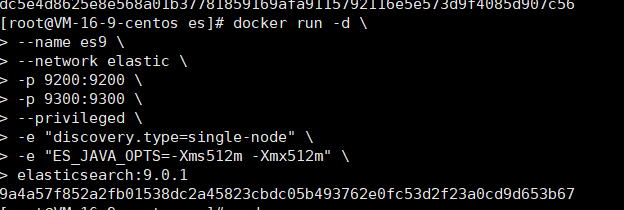
3.3.2 拷貝容器內部的文件
將容器內部的文件拷貝出來后面使用
docker cp es9:/usr/share/elasticsearch/data /usr/local/soft/es
docker cp es9:/usr/share/elasticsearch/plugins /usr/local/soft/es
docker cp es9:/usr/share/elasticsearch/config /usr/local/soft/es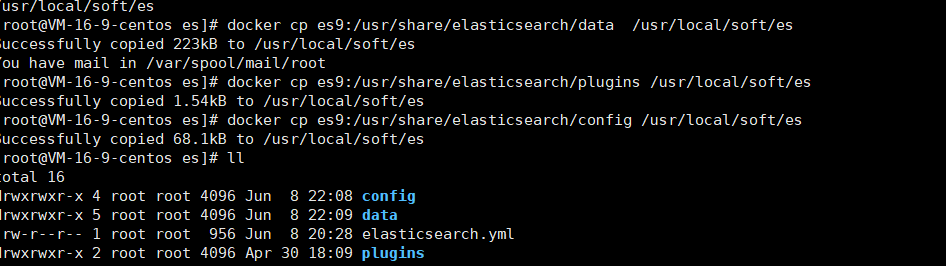
3.3.3 文件授權
后續會用到
chmod 777 -R config/ data/ plugins/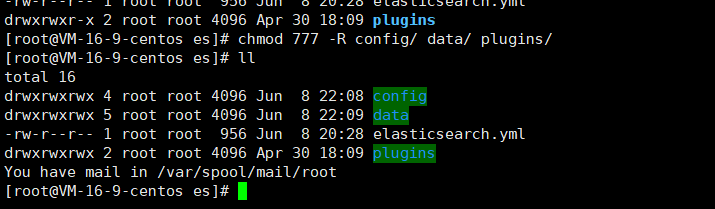
3.3.4 移除鏡像
使用下面的命令移除鏡像
docker stop es9 && docker rm es9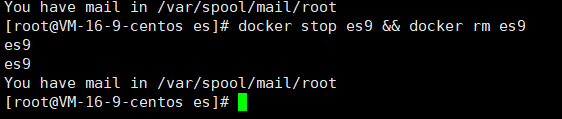
3.3.5 重啟es容器
執行下面的命令重啟es
docker run -d \
--name es9 \
--network elastic \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-v /usr/local/soft/es/data:/usr/share/elasticsearch/data \
-v /usr/local/soft/es/plugins:/usr/share/elasticsearch/plugins \
-v /usr/local/soft/es/config:/usr/share/elasticsearch/config \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:9.0.1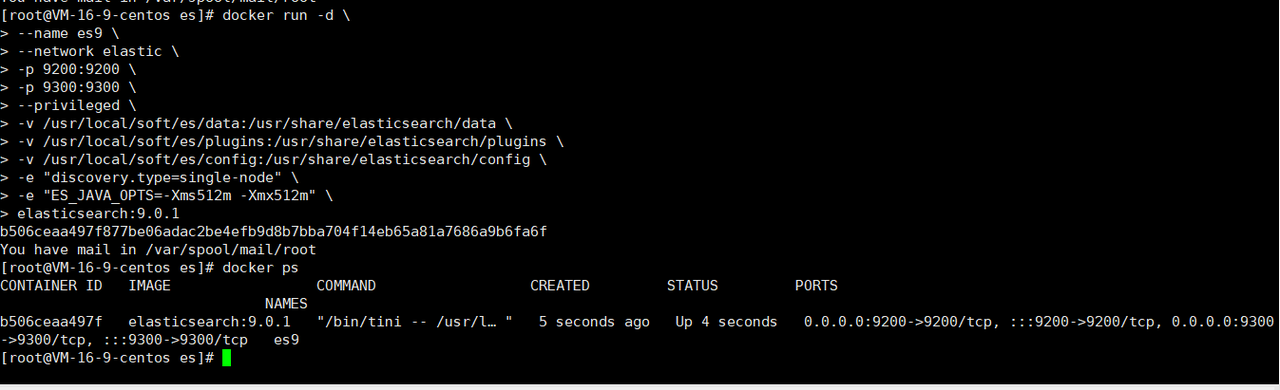
3.3.6 修改es配置參數
在掛載目錄中修改yml配置,調整下面的參數,調整完畢后注意重啟es容器
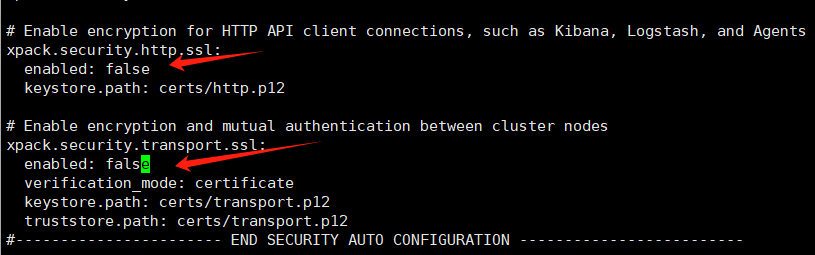
3.3.7 啟動kibana容器
使用下面的命令啟動kibana容器
docker run -d \
--name kibana \
--network elastic \
-p 5601:5601 \
--privileged \
-e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \
kibana:9.0.1
3.3.8?拷貝容器內的文件
將容器內的文件拷貝出來
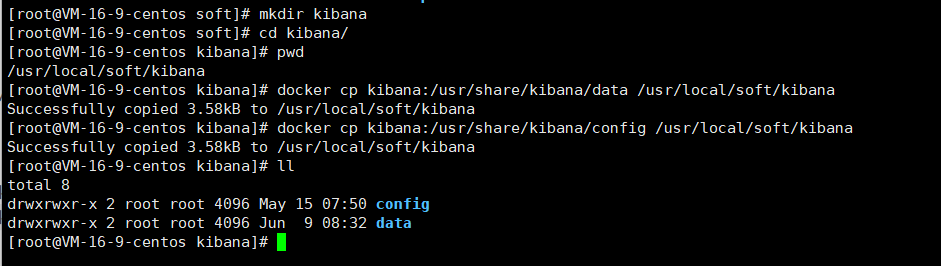
3.3.9?文件目錄授權
為確保后續訪問權限,給文件做下授權
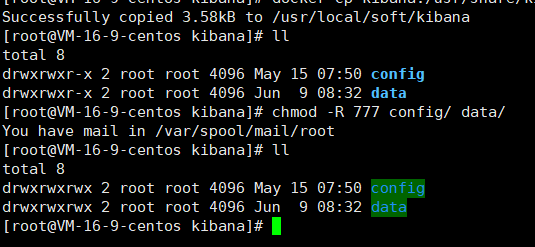
然后移除容器
docker stop kibana && docker rm kibana
3.3.10?創建kibana賬戶
創建為kibana創建新賬戶,用于訪問elasticsearch,容器內 /usr/share/elasticsearch/bin 目錄下
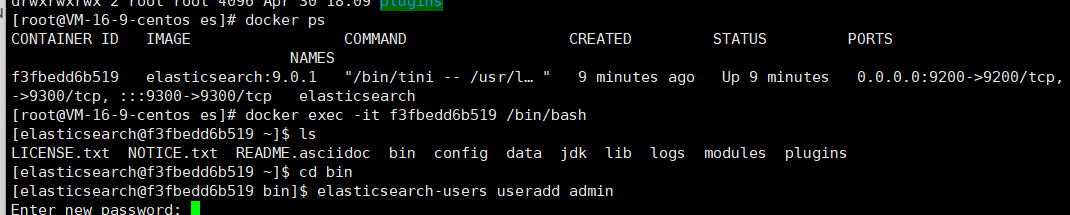
對賬戶授權(123456)

3.3.11?修改容器外掛載目錄中的kibana.yml
在yml中新增下面的配置
xpack.screenshotting.browser.chromium.disableSandbox: true
elasticsearch.username: admin
elasticsearch.password: 123456
3.3.12?重啟kibana容器
使用下面的命令重啟容器
docker run -d \
--name kibana \
--network elastic \
-p 5601:5601 \
--privileged \
-v /usr/local/soft/kibana/data:/usr/share/kibana/data \
-v /usr/local/soft/kibana/config:/usr/share/kibana/config \
-e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \
kibana:9.0.1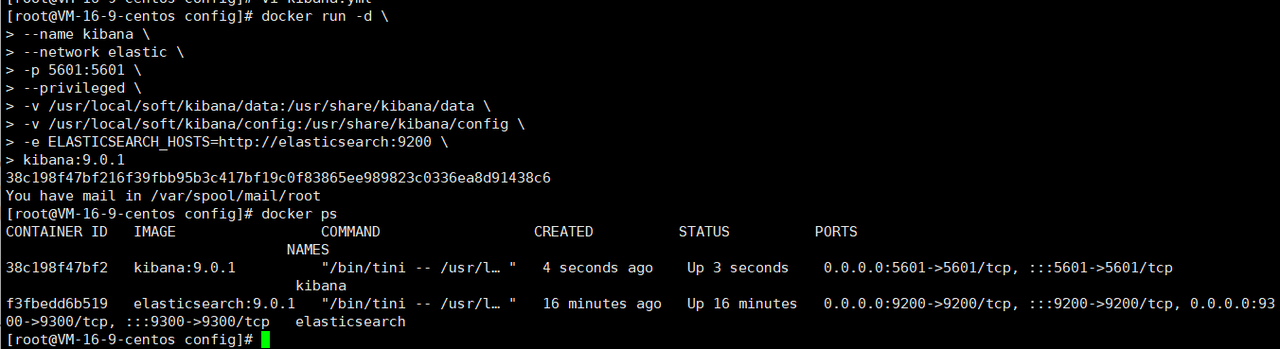
四、ES9 英文語義檢索操作過程
Elasticsearch 提供了開箱即用的 ELSER(Elastic Learned Sparse Encoder)模型,適合英文語義搜索。對于中文,可以使用阿里云的稀疏向量模型。
4.1 英文語義檢索操作案例
4.1.1 創建索引
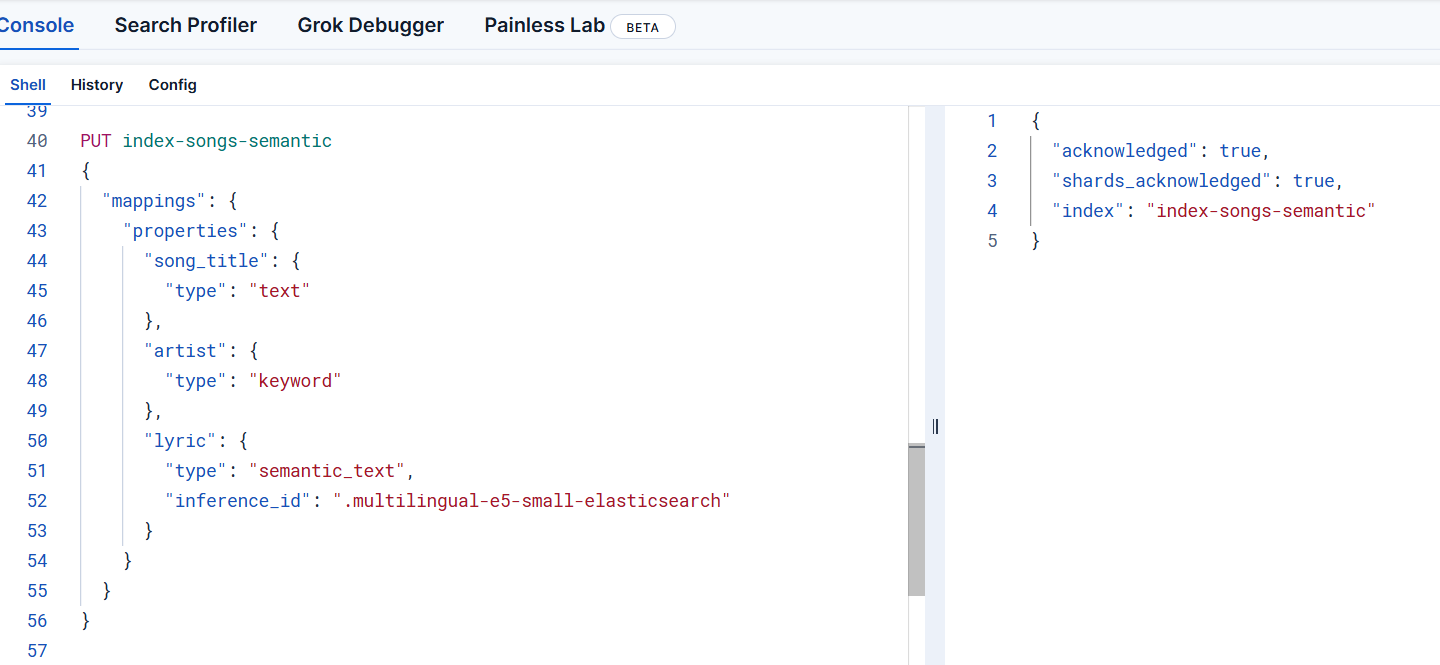
執行下面的命令創建一個索引
PUT index-songs-semantic
{"mappings": {"properties": {"song_title": {"type": "text"},"artist": {"type": "keyword"},"lyric": {"type": "semantic_text","inference_id": ".multilingual-e5-small-elasticsearch" }}}
}看到右側的執行成功說明索引已創建
如果后續待檢索的文檔中有中文,可以使用阿里云的大模型,參考下面的命令設置
- 需要提前配置好與阿里云向量模型的授權,后文中會有說明
PUT alibaba_sparse
{"mappings": {"properties": {"content": {"type": "semantic_text","inference_id": "alibabacloud_ai_search_sparse"}}}
}4.1.2 索引添加數據
為上述創建的索引增加幾條數據
POST index-songs-semantic/_doc/1
{"song_title": "...Baby One More Time","artist": "Britney Spears","lyric": "When I'm with you, I lose my mind, give me a sign"
}POST index-songs-semantic/_doc/2
{"song_title": "Crazy","artist": "Britney Spears","lyric": "You drive me crazy, I just can't sleep, I'm so excited, I'm in too deep"
}POST index-songs-semantic/_doc/3
{"song_title": "We wil rock you","artist": "Britney Spears","lyric": "Shouting in the street, gonna take on the world someday"
}依次點擊將3條數據添加進去
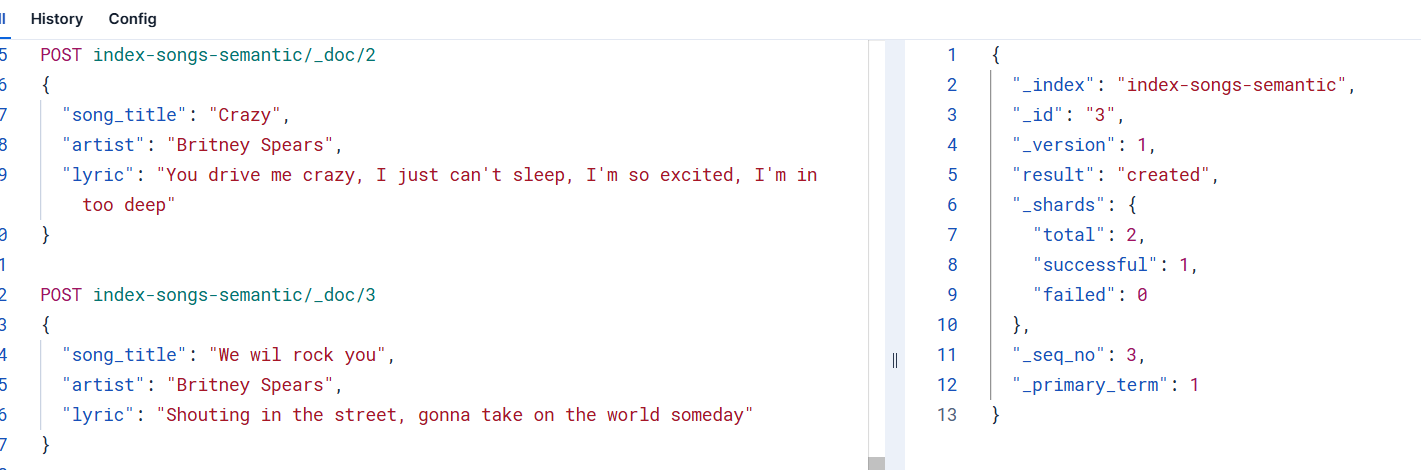
注意,如果在為索引添加數據過程中出現403的license錯誤,請執行下面的命令
POST /_license/start_trial?acknowledge=true請注意,acknowledge=true 參數是必需的,因為它確認了你理解此許可證將在30天后到期。此外,每個主要版本只能激活一次試用期。如果您的集群已經激活過試用期,則需要等到新的主要版本發布或者通過官方渠道申請延長試用期。
4.1.3 執行語義搜索
使用 semantic 查詢:
-
簡單來說,語義搜索就是,你輸入一個與文檔中的意思差不多的文本,能夠給你搜索出來
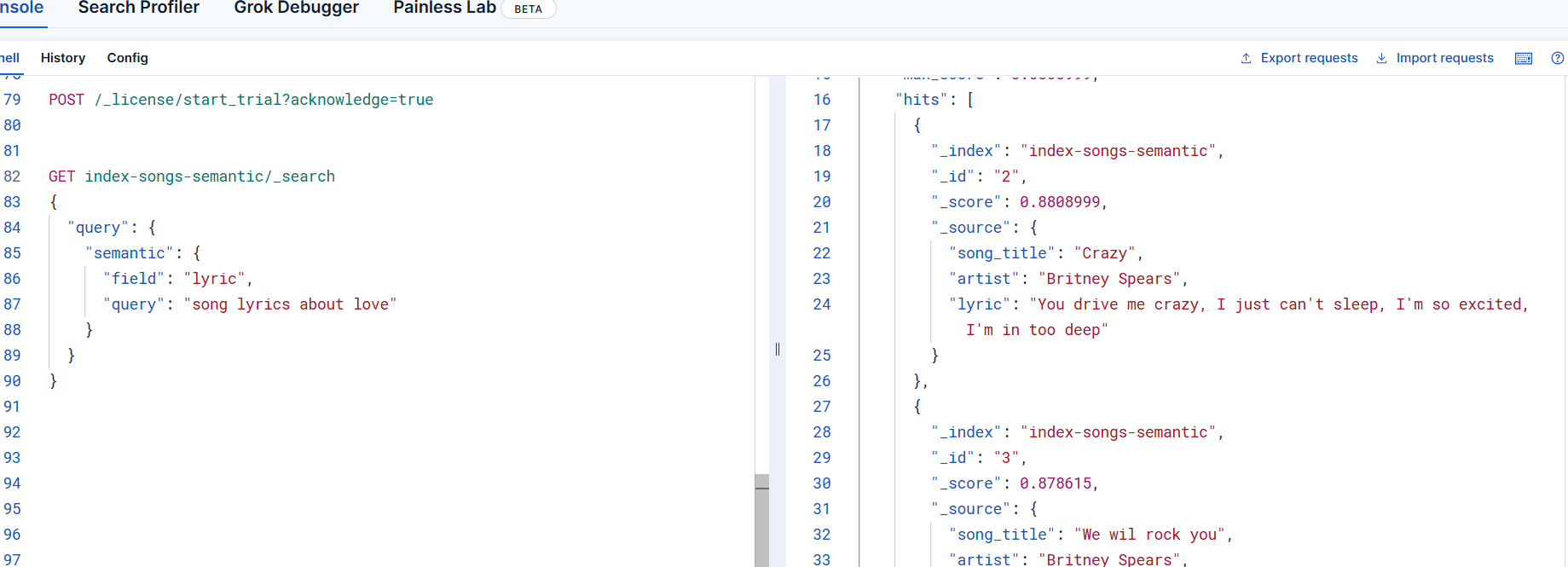
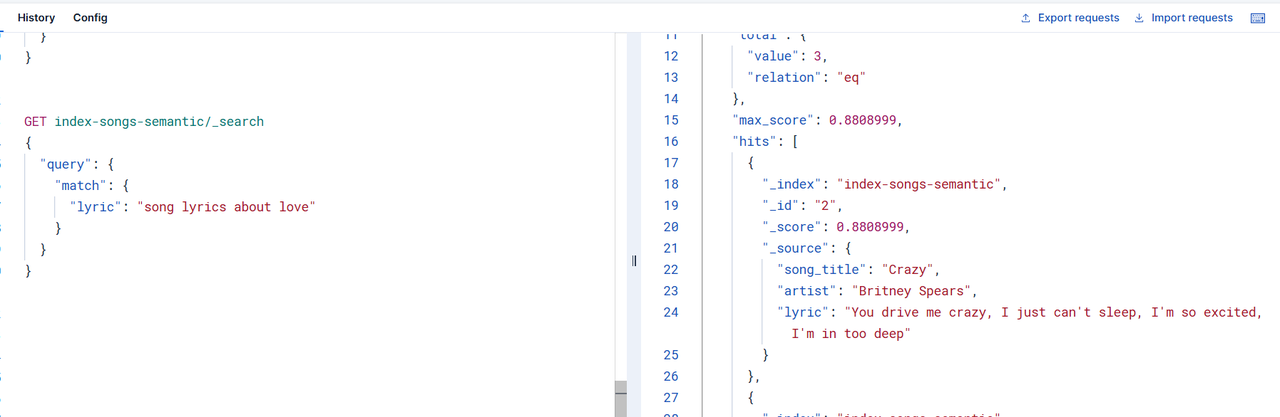
GET index-songs-semantic/_search
{"query": {"semantic": {"field": "lyric","query": "song lyrics about love"}}
}使用上面的語句在kibana中執行,可以看到,能夠按照評分高低將符合條件的文檔檢索出來
match 查詢(9.0新特性):
- 簡單來說,使用es9的語義檢索功能,像之前那樣使用es的查詢語法即可
五、ES9 中文語義檢索操作過程
接下來通過案例操作演示下ES9的中文語義檢索完整的操作過程。
5.1 配置向量模型
在文章開頭談到ES9的語義檢索原理時,其中一個非常重要的點就是數據存儲在es的時候,其內部有一個數據向量化的過程,即向量化后的數據才能在后續的檢索中,借助語義檢索查出來,因此在這里,我們先選擇阿里云的文本向量大模型,結合es9一起來完成對于中文語義檢索的過程。
5.1.1? 獲取向量模型和apikey
進入阿里云平臺獲取文本向量模型,并獲取apikey,平臺訪問入口:智能開放搜索 OpenSearch 控制臺
1)找到文本向量模型
如下,在服務廣場找到下面的文本向量化模型,后續將會使用這個模型
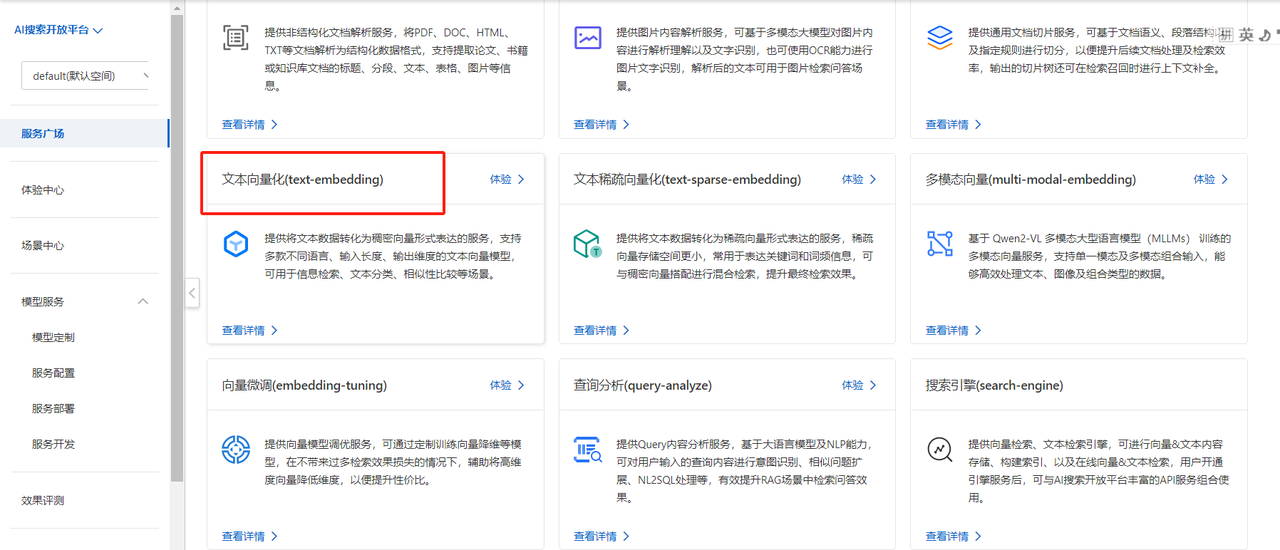
點擊查看詳情,可以看到里面提供針對實際業務中多種場景下的具體服務信息,在后文的配置中使用哪一個,只需要拷貝對應的服務ID即可。

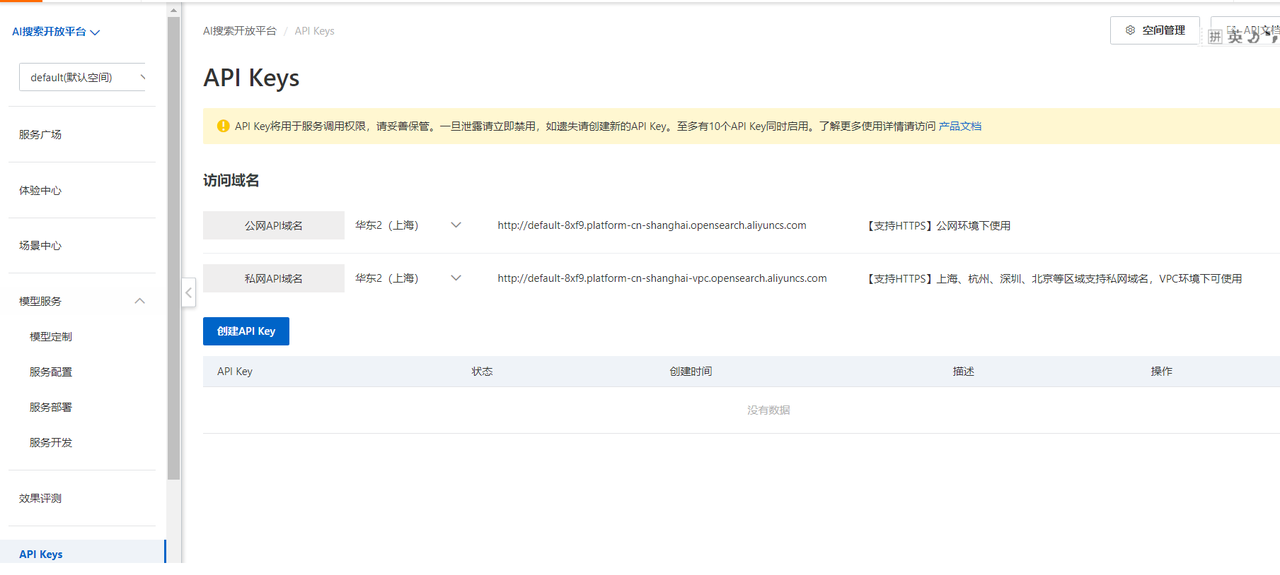
2)創建apikey
初次進來需要手動創建一個apikey
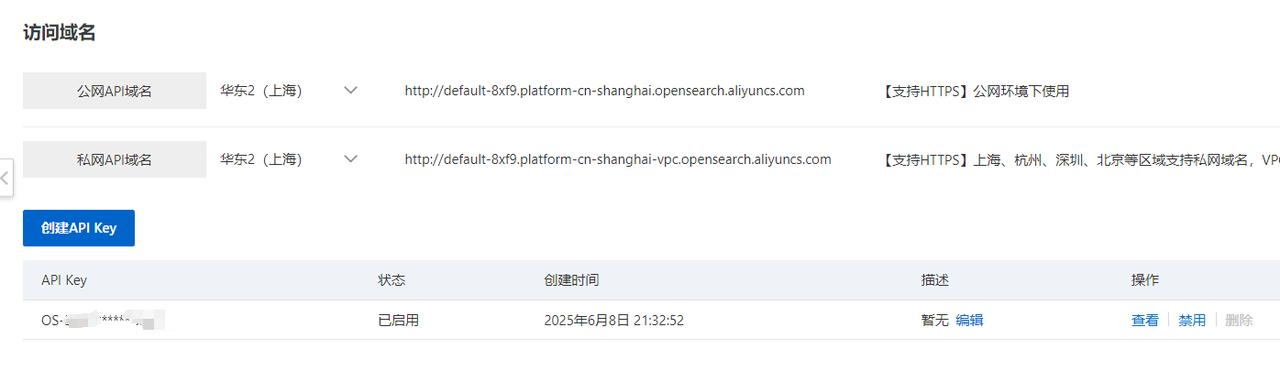
5.1.2 注冊推理API訪問入口
如何才能讓后續寫入es的索引數據與AI大模型進行聯動呢?首先需要通過es的API進行服務注冊,即打通ES與AI大模型交互,在kibana中執行下面的命令
PUT _inference/text_embedding/text_embedding_v1
{"service":"alibabacloud-ai-search","service_settings":{"api_key":"你的apikey","service_id":"ops-text-embedding-001","host":"default-8xf9.platform-cn-shanghai.opensearch.aliyuncs.com","workspace":"default"}
}看到下面的界面創建成功

5.2 創建索引并增加數據
5.2.1 添加索引
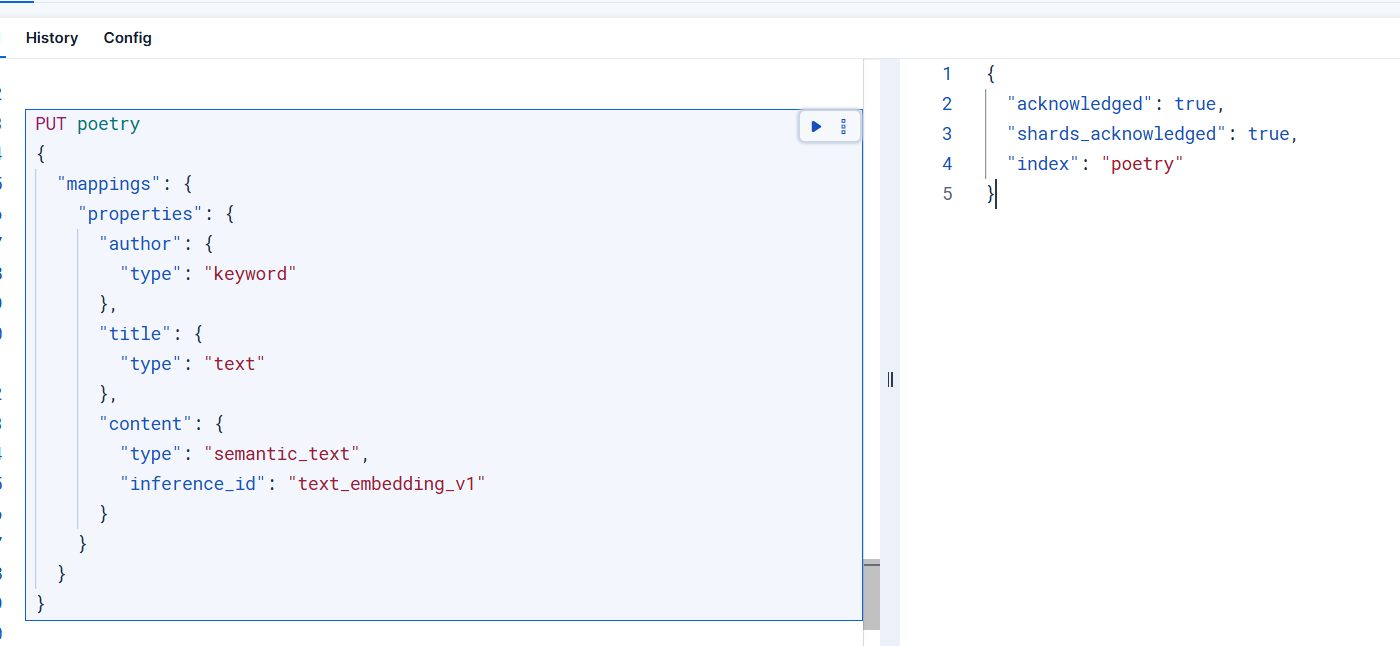
使用下面的語句創建一個索引
PUT poetry
{"mappings": {"properties": {"author": {"type": "keyword"},"title": {"type": "text"},"content": {"type": "semantic_text","inference_id": "text_embedding_v1" }}}
}
5.2.2 增加幾條數據
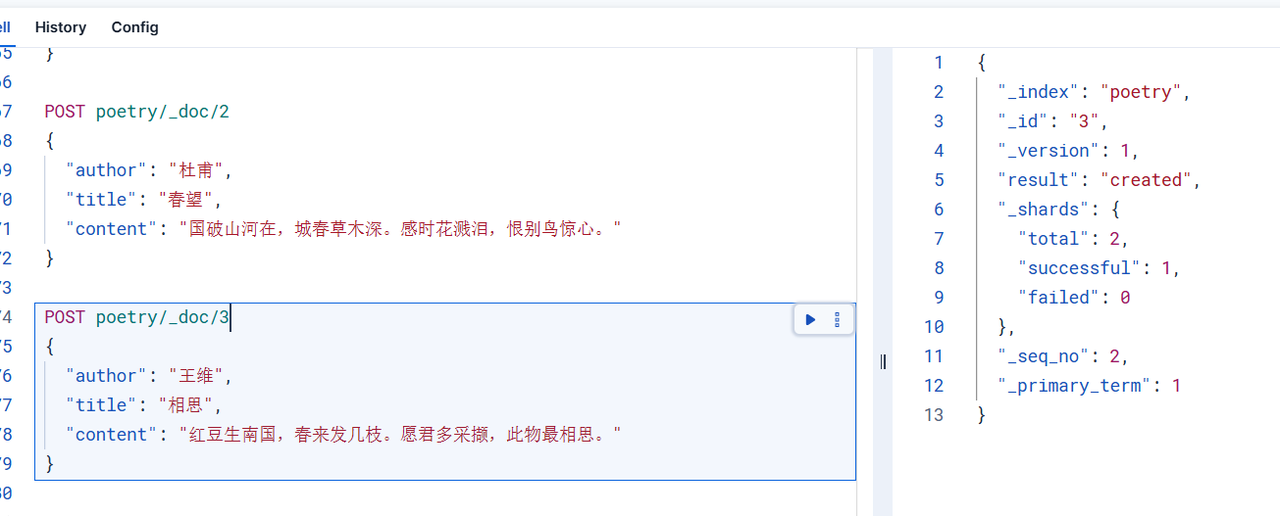
使用下面的語句增加幾條數據
POST poetry/_doc/1
{"author": "杜甫","title": "春望","content": "國破山河在,城春草木深。感時花濺淚,恨別鳥驚心。"
}POST poetry/_doc/2
{"author": "李白","title": "靜夜思","content": "床前明月光,疑是地上霜。舉頭望明月,低頭思故鄉。"
}POST poetry/_doc/3
{"author": "王維","title": "相思","content": "紅豆生南國,春來發幾枝。愿君多采擷,此物最相思。"
}
es的語義檢索在數據進行存儲的時候,看到的是為索引增加了一些數據,其實底層還增加了數據向量化的操作過程
5.3 語義檢索效果模擬
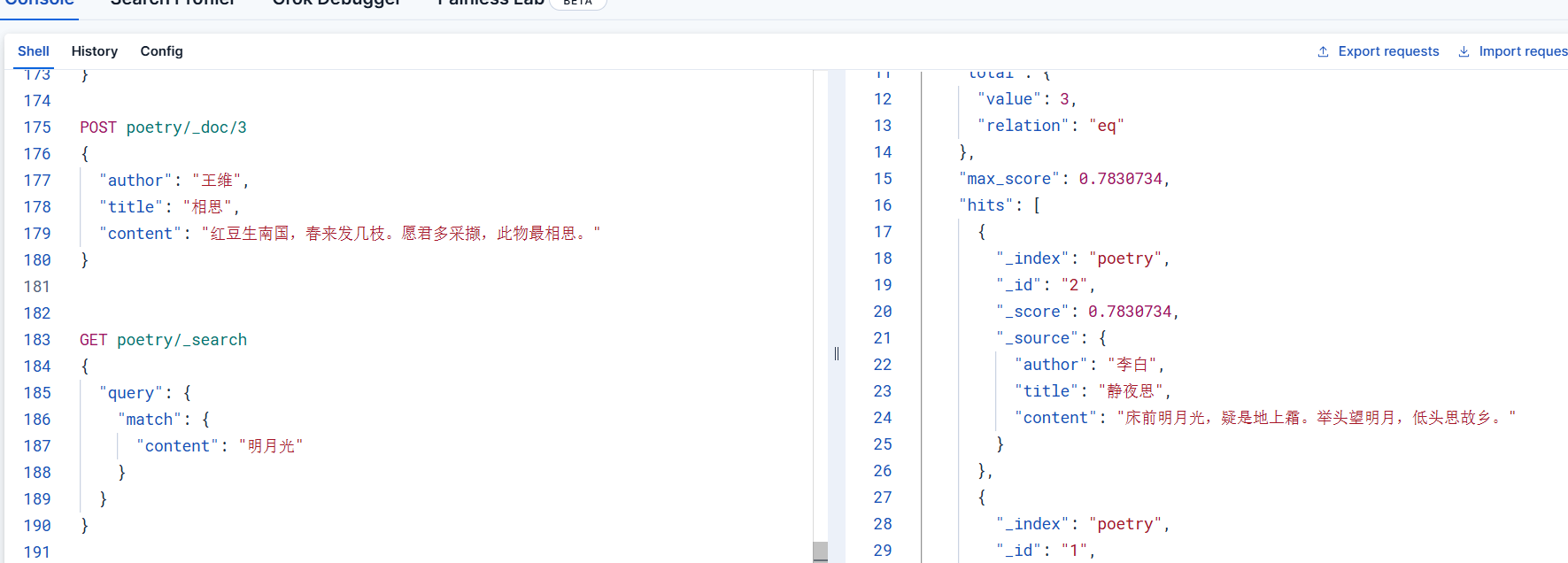
通過上一步操作之后,數據不僅存儲到索引,而且也被向量化了,實際在進行檢索的時候,仍然是使用es常規的檢索語法即可,首先進行正常的檢索,我們使用關鍵字檢索
GET poetry/_search
{"query": {"match": {"content": "明月光"}}
}通過檢索的結果,可以看到能夠按照預期將相似度最高的排在最前面
然后在使用下面的語句,這一句是根據文檔中的第一條數據推斷出來的近似語句
- 細心的同學可以發現,這里直接使用了es大家熟悉的match語法
GET poetry/_search
{"query": {"match": {"content": "描述家國大義詩句有哪些"}}
}點擊查詢之后,神奇的現象出現了,能夠正確的將語義最相似的第一條詩句返回
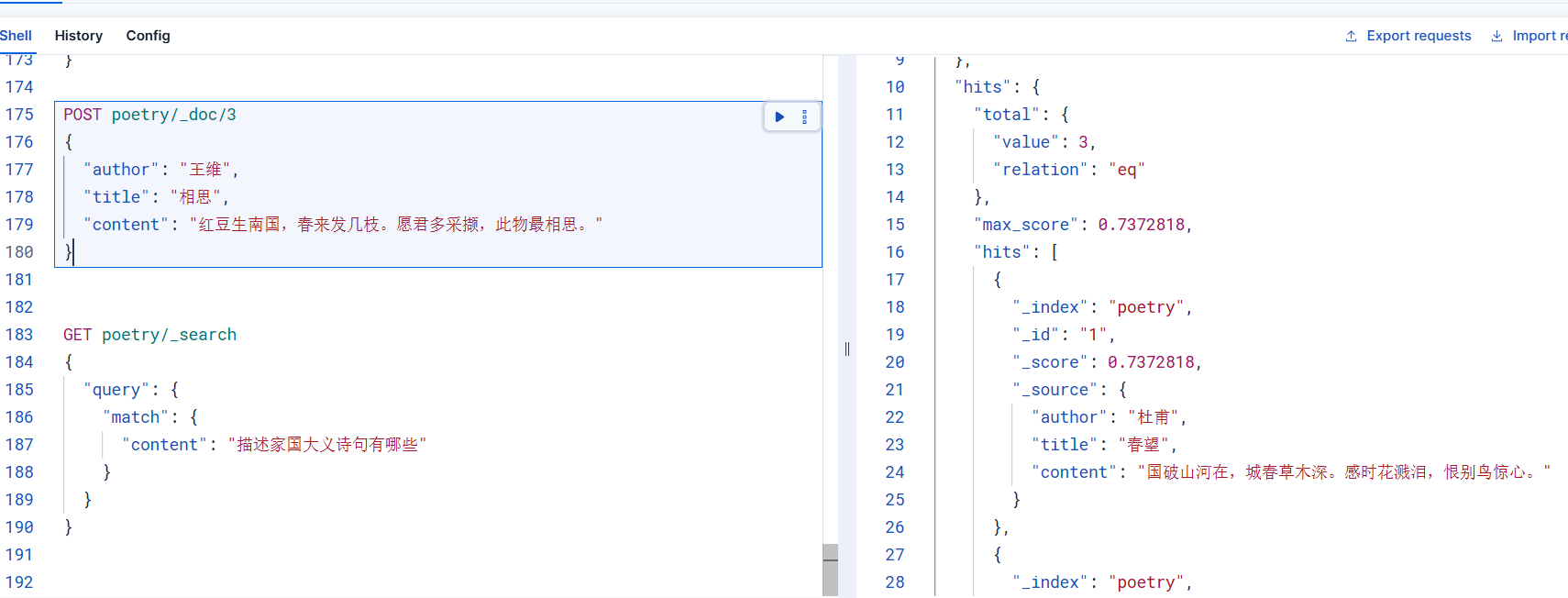
更近一步,使用es進行多條件查詢時候,語義檢索仍然有效,比如在下面的組合條件查詢中,我們限定了兩個條件,通過查詢結果來看,語義檢索仍然可以得到正確的返回結果
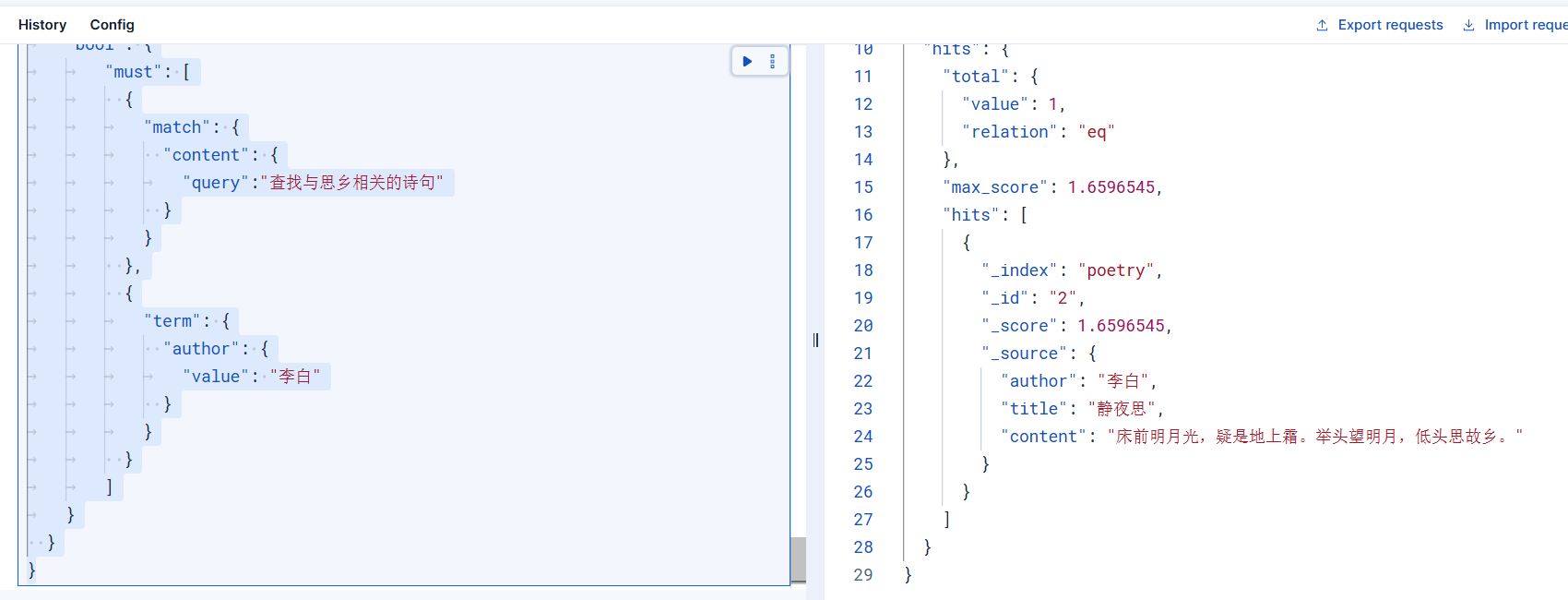
POST poetry/_search
{"size": 20,"query": {"bool": {"must": [{"match": {"content": {"query":"查找與思鄉相關的詩句"}}},{"term": {"author": {"value": "李白"}}}]}}
}檢索結果如下
六、寫在文末
本文通過較大的篇幅詳細介紹了es9的語義檢索功能,搭配向量大模型,可以在實際業務中發揮很重要的作用,有興趣的同學可以基于此繼續深入研究,本篇到此結束,感謝觀看。










)








