本文來自社區投稿,作者丁一超
書生大模型實戰營第5期已正式啟動,本期實戰營新增「論文分類打榜賽」,以幫助學員更好地掌握大模型技能。
本文將手把手帶領大家如何基于昇騰微調 InternLM 模型,輕松上手論文自動分類任務。從環境配置、數據準備,到 模型微調和推理部署,完整教程不藏私。即使你是模型微調新手,也能快速參與打榜實踐!
InternLM開源鏈接:
https://github.com/InternLM/InternLM
在線體驗鏈接:
https://chat.intern-ai.org.cn/
1.環境配置
創建云腦任務
登錄OpenI平臺并創建云腦任務(https://openi.pcl.ac.cn/)。
- 計算資源:昇騰NPU
- 資源規格:按下圖圈紅處選擇
- 鏡像:openmind_cann8
- 選擇模型:internlm2_5-7b-chat(找到【選擇模型】-【公開模型】,搜索框內輸入【internlm2_5】,在出來的列表里選擇【internlm2_5-7b-chat】)
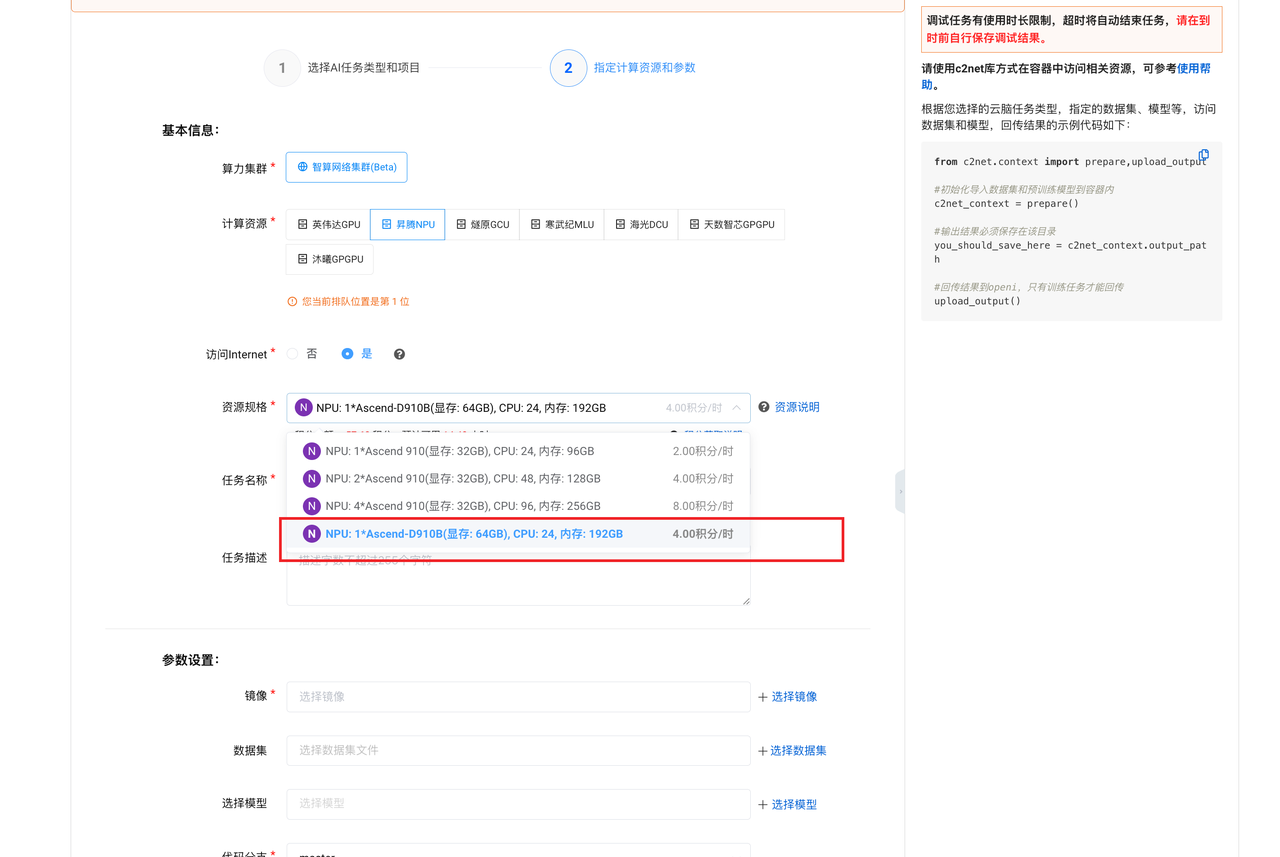
全部選擇完成后點【新建任務】即可完成云腦任務創建。因為需要拉取模型文件,所以這一步的時間會有點長,第一次加載整個過程有可能會需要 1-2 小時,后續再加載就快了。耐心等到任務狀態由【Waiting】變為【Running】即可,期間可以先學習其他內容。
當任務狀態變為【Runing】后,點【調試】就可以開始體驗操作了。

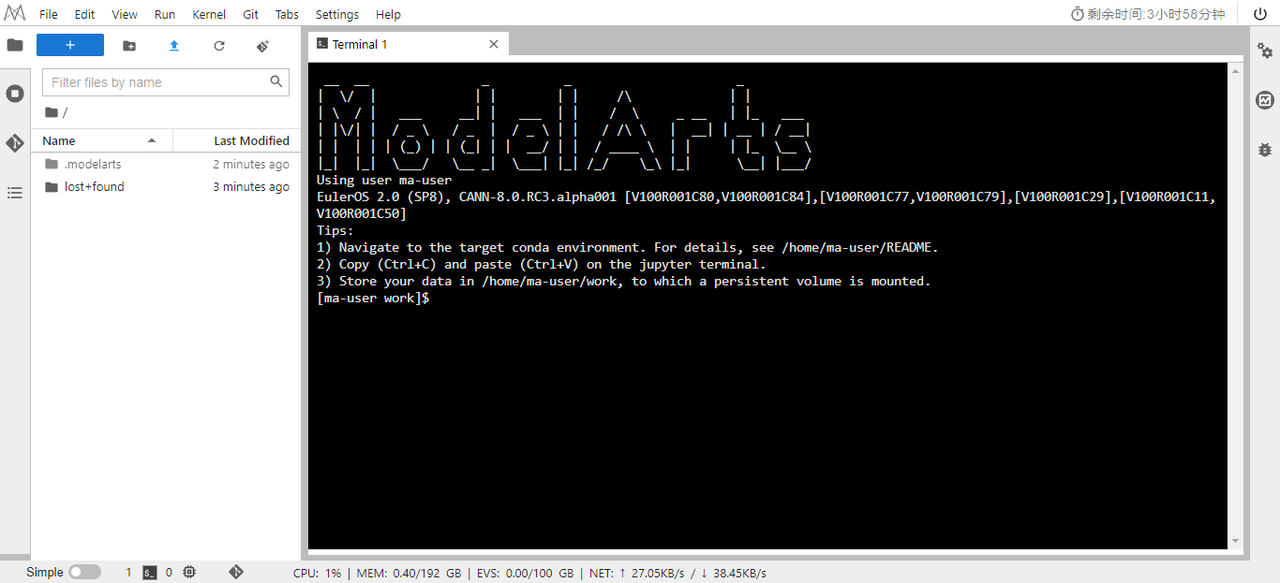
Tips:啟智社區的調試任務單次運行只能 4 小時,另外除了 /home/ma-user/work 目錄下的文件在環境結束后都會恢復。
創建 Conda 環境
conda create -n internlm python=3.10 -y
conda activate internlm
pip install torch==2.3.1 torch-npu==2.3.1 torchaudio==2.3.1 torchvision
Tips:因為啟智社區環境關機后 /home/ma-user/work 目錄外的文件會被還原,所以如果想后面繼續使用這個調試任務又不想多花一點時間重新配置環境的話,可以在創建 conda 環境的時候使用以下命令,關機后再開直接執行 conda activate 即可。
conda create -p /home/ma-user/work/anaconda/internlm python=3.10 -y
conda activate /home/ma-user/work/anaconda/internlm
克隆代碼倉
git clone https://github.moeyy.xyz/https://github.com/InternLM/lmdeploy
git clone https://github.moeyy.xyz/https://github.com/InternLM/xtuner.git
安裝 LMDeploy
cd lmdeploy
pip install -r requirements_ascend.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
LMDEPLOY_TARGET_DEVICE=ascend pip3 install -v --no-build-isolation -e .
安裝 Transformers4.48.0
pip install transformers==4.48.0
安裝 deepspeed 及 mpi4py
pip install deepspeed==0.16.2
conda install mpi4py
安裝 XTuner
cd ../xtuner/
# 刪除requirements/runtime.txt中的第一行bitsandbytes==0.45.0
# 刪除requirements.txt文件中的-r requirements/deepspeed.txt 這一行
pip install -e '.[all]'
將模型導入到容器內
這一步建議第一次創建好云腦任務啟動完成就執行好,以免后面模型如果有更新,可能會出現只有部分文件同步到容器中的情況。
# 導入包
from c2net.context import prepare, upload_output
# 初始化導入數據集和預訓練模型到容器內
c2net_context = prepare()
如果遇到沒有成功加載模型的話,可以看下 notebook 用的 kernel 是不是【MindSpore】。
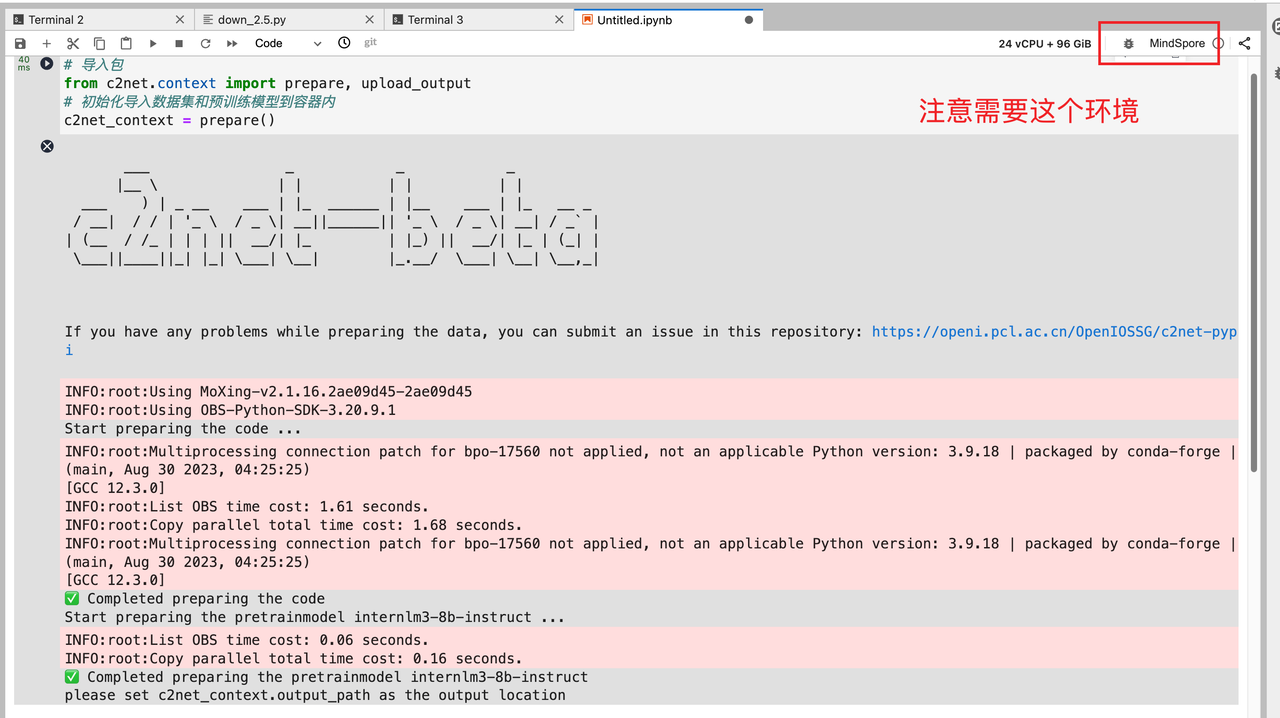
模型導入到容器內會存放在該路徑下:/home/ma-user/work/pretrainmodel
驗證 XTuner
因為 XTuner 暫時沒有 internlm3 的配置文件,不過可以使用 internlm2.5 的配置文件修改一下也是能夠使用的。
xtuner list-cfg |grep internlm2_5
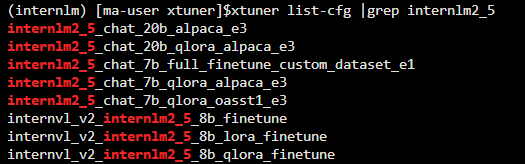
復制配置文件
找到 internlm2_5_chat_7b_qlora_alpaca_e3,然后復制到 config/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py
mkdir config
xtuner copy-cfg internlm2_5_chat_7b_qlora_alpaca_e3 ./config
2.準備訓練數據
數據獲取
modelscope download --dataset JimmyMa99/smartflow-arxiv-dataset --local_dir ./datasets/smartflow-arxiv-dataset
數據集轉換
關于數據詳情可參考這篇文章的數據部分。
https://blog.csdn.net/2402_82411485/article/details/148402132?spm=1001.2014.3001.5501
原本的數據是 swift 版本,因此需要創建一個數據集轉換腳本 convert_to_alpaca.py
touch convert_to_alpaca.py
數據集轉換腳本 convert_to_alpaca.py 代碼如下:
import json
import os
import argparsedef convert_to_alpaca_format(input_file, output_file):"""將 Swift 格式的數據轉換為 Alpaca 格式輸入格式:{"system": "你是個優秀的論文分類師","conversation": [{"human": "Based on the title...","assistant": "D"}]}輸出格式 (Alpaca):{"instruction": "根據論文的標題、作者和摘要,確定該論文的科學類別。","input": "Based on the title...","output": "D"}"""print(f"轉換數據: {input_file} -> {output_file}")converted_data = []with open(input_file, "r", encoding="utf-8") as f:for line in f:try:data = json.loads(line.strip())# 檢查數據結構if "system" not in data or "conversation" not in data:print(f"警告: 數據缺少必要字段: {data}")continue# 從 system 提取指令instruction = data.get("system", "")if not instruction:instruction = "根據論文的標題、作者和摘要,確定該論文的科學類別。"# 處理對話for turn in data["conversation"]:if "human" in turn and "assistant" in turn:# 創建新的 Alpaca 格式數據new_data = {"instruction": instruction,"input": turn["human"],"output": turn["assistant"],}converted_data.append(new_data)except json.JSONDecodeError:print(f"警告: 無法解析JSON行: {line}")except Exception as e:print(f"處理行時發生錯誤: {str(e)}")# 寫入輸出文件with open(output_file, "w", encoding="utf-8") as f:for item in converted_data:f.write(json.dumps(item, ensure_ascii=False) + "\n")print(f"轉換完成! 共轉換 {len(converted_data)} 條數據")if __name__ == "__main__":parser = argparse.ArgumentParser(description="轉換數據到Alpaca格式")parser.add_argument("--input",type=str,required=True,help="輸入文件路徑 (swift_formatted_sft_train_data.jsonl)",)parser.add_argument("--output", type=str, required=True, help="輸出文件路徑")args = parser.parse_args()convert_to_alpaca_format(args.input, args.output)
執行代碼轉換:
python convert_to_alpaca.py --input datasets/smartflow-arxiv-dataset/swift_formatted_sft_train_data.jsonl --output datasets/sftdata.jsonl
3.模型訓練
鏈接模型地址
ln -s /home/ma-user/work/pretrainmodel/internlm2_5-7b-chat ./
修改 config 文件 internlm2_5_chat_7b_qlora_alpaca_e3.py
# 第34行修改為模型地址
pretrained_model_name_or_path = "internlm2_5-7b-chat"# 第38行修改為數據集地址
- alpaca_en_path = "tatsu-lab/alpaca"
+ alpaca_en_path = "datasets/sftdata.jsonl"# 第110行-121行替換為下面這段
alpaca_en = dict(type=process_hf_dataset,dataset=dict(type=load_dataset, path='json', data_files=alpaca_en_path),tokenizer=tokenizer,max_length=max_length,dataset_map_fn=alpaca_map_fn,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length,use_varlen_attn=use_varlen_attn,
)
在 NPU 上微調還需要修改以下兩段代碼:
# 代碼頭引入庫的部分
- from transformers import (AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig)
+ from transformers import (AutoModelForCausalLM, AutoTokenizer)#######################################################################
# PART 2 Model & Tokenizer #
######################################################################## 第86行左右刪除
- quantization_config=dict(
- type=BitsAndBytesConfig,
- load_in_4bit=True,
- load_in_8bit=False,
- llm_int8_threshold=6.0,
- llm_int8_has_fp16_weight=False,
- bnb_4bit_compute_dtype=torch.float16,
- bnb_4bit_use_double_quant=True,
- bnb_4bit_quant_type='nf4')
啟動微調訓練
xtuner train config/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py --deepspeed deepspeed_zero1
模型格式轉換
xtuner convert pth_to_hf ./config/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py ${pth_file} ./hf #pth_file位置填寫訓練后保存的權重地址,取最后一個iter開頭的文件夾即可,一般在work_dir目錄下
模型合并
xtuner convert merge ./internlm2_5-7b-chat ./hf ./merged --max-shard-size 2GB --device npu
如果模型使用的不是 InternLM2.5 而是 InternLM3-8B 的話,模型合并完畢后看一下 merged 目錄下有沒有一個 modeling_internlm3.py。如果沒有的話需要手動復制到合并后的目錄下。
cp -r ./internlm3-8b-instruct/modeling_internlm3.py ./merged
4.模型評測
可參考這篇文章中的模型評測部分
https://blog.csdn.net/2402_82411485/article/details/148402132?spm=1001.2014.3001.5501
5.提交模型完成評測
前置條件
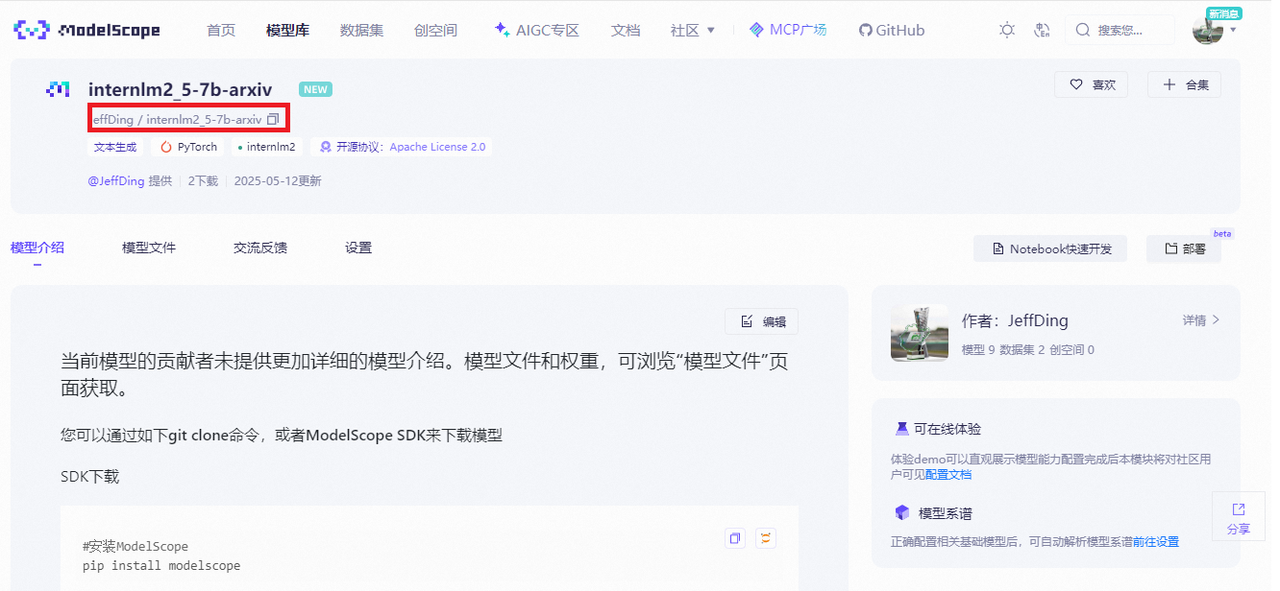
獲取 hub_model_id,如下圖圈紅部分
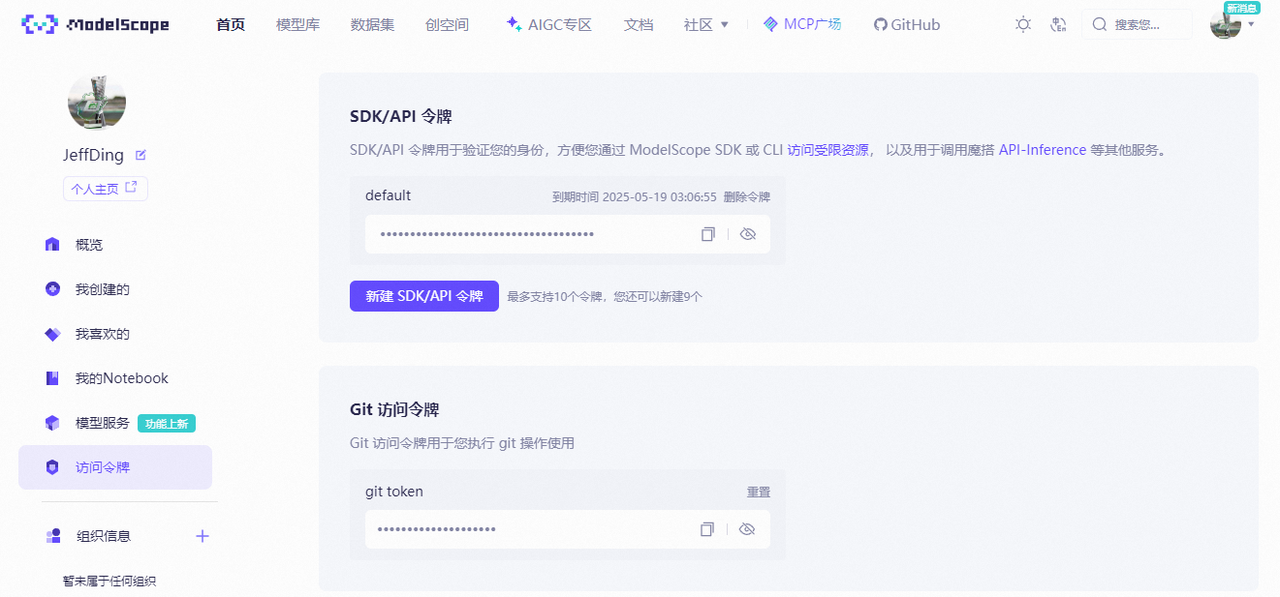
hub_token 獲取:【賬號設置】-【訪問令牌】復制SDK/API令牌即可
上傳模型到魔搭
因為 OpenI 環境無法安裝 git-lfs,所以只能使用 modelscope 庫進行模型的上傳
創建一個上傳的 python 腳本 upload.py
cd ~/work
touch upload.py
代碼腳本如下:
from modelscope.hub.api import HubApi
from modelscope.hub.constants import Licenses, ModelVisibilityYOUR_ACCESS_TOKEN = '你的ACCESS_TOKEN' #需要手動修改,獲取地址https://www.modelscope.cn/my/myaccesstoken
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)owner_name = '你的用戶名' #需要手動修改
model_name = '模型名稱' #需要手動修改
model_id = f"{owner_name}/{model_name}"api.create_model(model_id,visibility=ModelVisibility.PUBLIC,license=Licenses.APACHE_V2,chinese_name="模型中文名" #需要手動修改,寫英文的也沒事
)api.upload_folder(repo_id=f"{owner_name}/{model_name}", #前面獲取的hub_model_idfolder_path='xtuner/merged', #合并以后的模型目錄commit_message='upload model folder to repo', #commit信息隨便填
)
執行上傳腳本
cd ~/work
python upload.py
將上傳至魔搭的模型提交至比賽評測平臺
填寫下方表單即可完成提交
https://aicarrier.feishu.cn/share/base/form/shrcn0JkjbZKMeMPw04uHCWc5Pg
6.參賽獎勵
在以下時間點,排行榜位列前 10 的選手將獲得相應獎勵:
- 6 月 10 日 20:00:前 10 名獲得 InternStudio 平臺 1688 算力點
- 6 月 17 日 20:00:前 10 名獲得 InternStudio 平臺 999 算力點
- 6 月 24 日 20:00:前 10 名獲得 InternStudio 平臺 666 算力點
- 6 月 30 日 20:00:前 10 名額外獲得 官方證書
注:算力有效期僅第五期實戰營內有效

6 月 6 日榜單部分截圖
訪問下方鏈接可查看全部榜單內容
https://aicarrier.feishu.cn/share/base/dashboard/shrcnqpXY6Uy9FodNF3It75GSNe?iframeFrom=docx&ccm_open=iframe
本文主要介紹了如何基于昇騰硬件微調 InternLM 模型,并應用于論文分類任務,涵蓋了從環境配置、數據準備到模型訓練與評測的完整流程,希望對大家參加賽事有所幫助。
















)

![[特殊字符] Harmony OS Next里的Web組件:網頁加載的全流程掌控手冊](http://pic.xiahunao.cn/[特殊字符] Harmony OS Next里的Web組件:網頁加載的全流程掌控手冊)
