【MATLAB第119期】基于MATLAB的KRR多輸入多輸出全局敏感性分析模型運用(無目標函數,考慮代理模型)
下一期研究SHAP的多輸入多輸出敏感性分析方法
一、SOBOL(無目標函數)
(1)針對簡單線性數據及非線性數據,用函數擬合得到公式,隨后思路與上面一致。
(2)無法擬合得到公式, 即復雜非線性函數,需要通過借用機器學習模型,作為訓練學習模型(黑箱子模型)
本文具體研究攻克第二種情況
有個前提(模型擬合性較好,對應數據較好)
即訓練學習模型, 訓練集和測試集擬合效果很棒。
如果擬合效果差,SOBOL分析結果一定存在較大誤差。
本文選用多輸入多輸出模型KRR,效果好且比BP穩定。
1.運行思路
A、設定KRR代理模型和變量上下限(6個變量,2個因變量,維度D=6)
(1).選用KRR模型作為代理模型*
代理模型講究運行效率快、精度高、模型簡單 ,適用于多輸入多輸出,與BP訓練效果進行對比
(2).數據設置:常用的案例數據 ,103*8 ,前6列代表輸入變量, 最后2列代表因變量。
(3).選用模型后,幾個點需要注意:
(1)數據固定,即訓練樣本/測試樣本固定, 所代表的模型評價才夠穩定。
(2)使用固定算子函數代碼(神經網絡代理模型是必要的) ,即開頭代碼為: rng default 或者rng(M)等 ,M根據實際測試效果確定。可固定輸出結果,保證運行結果一致。此一致代表此刻你打開的matlab, 在不關閉情況下每次運行結果一致。跟matlab版本有關,系統版本,以及電腦有關。
(3)最為關鍵的一點 ,變量的上下限不能超過案例數據的上下限,為了保證模型的普適性和有效性!!!
比如案例數據的訓練樣本中, X1-X6的最小值為:
[137 0 0 160 4.40000000000000 708]
X1-X6的最大值為:
[374 193 260 240 19 1049.90000000000]
那么你的sobol序列生成的數據也只能在這個范圍,才能保證代理模型的有效性。
(4)生成樣本的數量當然以多為好, 但不能跟案例數據樣本數量差距太大,減少偶然性。
(5)代理模型效果
KRR:
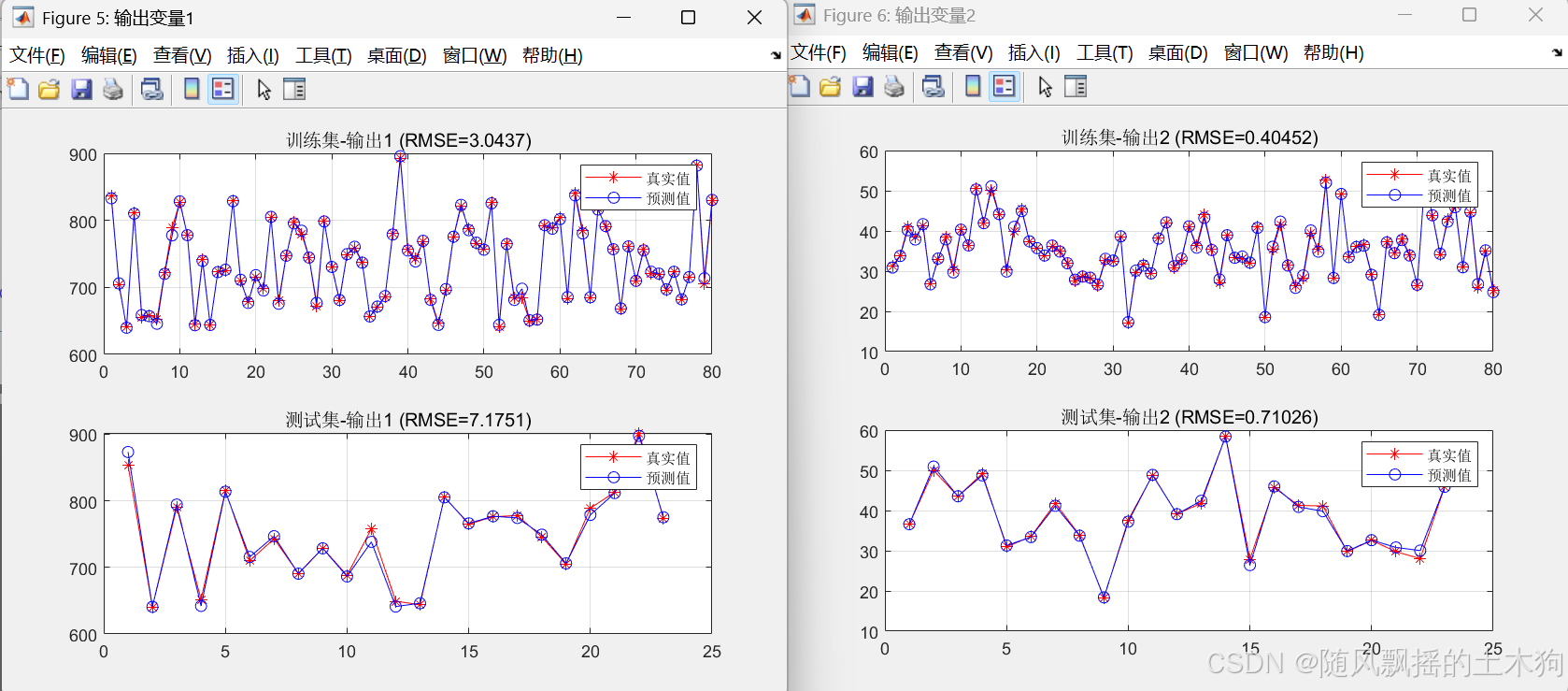
=== 輸出1評價指標 ===
訓練集: R2=0.9975, MAE=2.0306, MBE=-0.0019
測試集: R2=0.9887, MAE=4.5770, MBE=-0.7719
=== 輸出2評價指標 ===
訓練集: R2=0.9969, MAE=0.3082, MBE=-0.0001
測試集: R2=0.9937, MAE=0.4756, MBE=0.0310
BP:
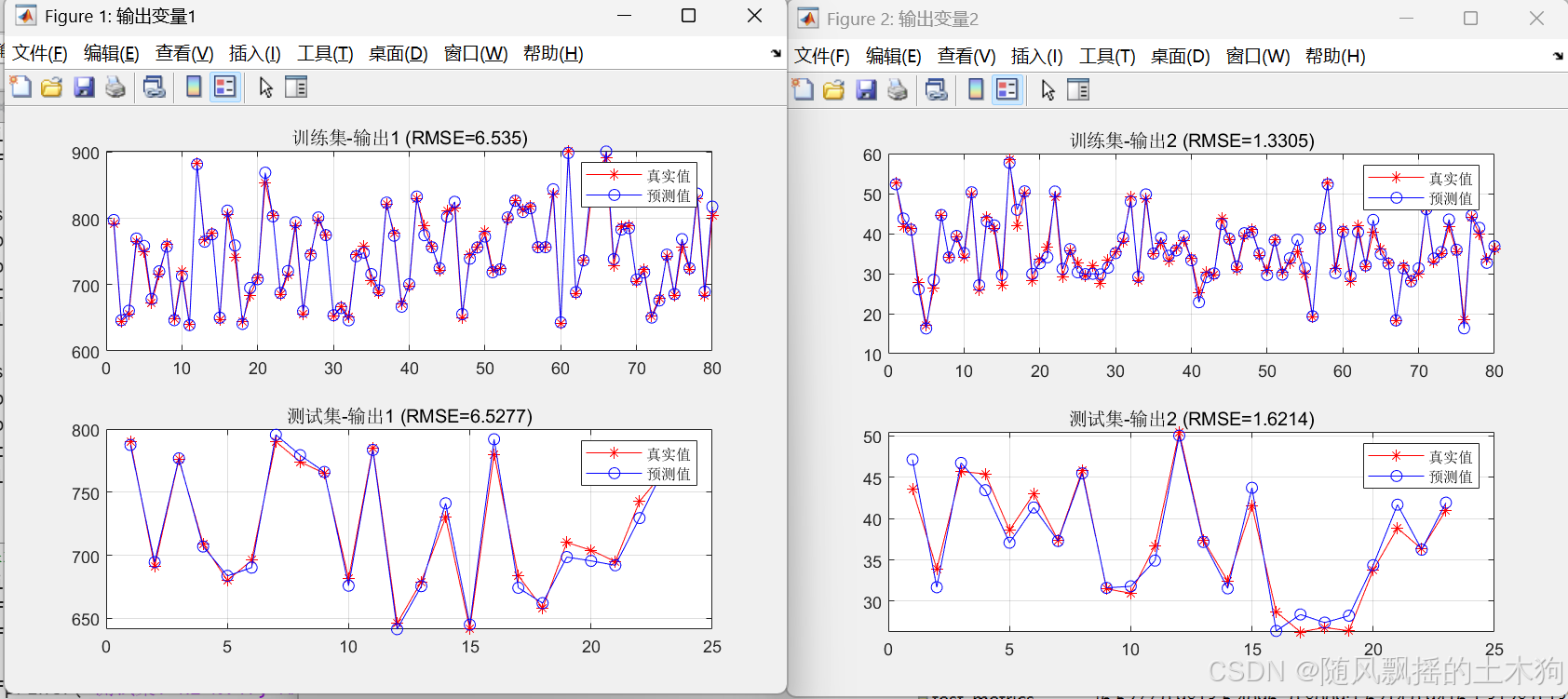
=== 輸出1評價指標 ===
訓練集: R2=0.9901, MAE=5.0527, MBE=1.4881
測試集: R2=0.9813, MAE=5.4096, MBE=-0.8009
=== 輸出2評價指標 ===
訓練集: R2=0.9728, MAE=1.0644, MBE=0.1991
測試集: R2=0.9416, MAE=1.3128, MBE=0.1372
%% 設定:給定參數個數和各個參數的范圍
D=6;% 6個參數
M=D*2;%
nPop=400;% 采樣點個數,跟訓練樣本數量大概一致
VarMin=[137 0 0 160 4.40000000000000 708];%各個參數下限
VarMax=[374 193 260 240 19 1049.90000000000];%各個參數上限
B、生成sobol序列樣本數據
1、 生成多組N*M(即N行12列)的樣本矩陣p。用自帶函數sobolset生成。
p= sobolset(M)
2、 篩選nPop*M(即400行12列)的樣本矩陣R。
for i=1:nPop% 選取前nPop行被上下限空間處理后的樣本r=p(i,:);r=VarMin+r.*(VarMax-VarMin);R=[R; r];
end
C、R樣本拆分變換(提高樣本豐富度)
1.將矩陣的前D列設置為矩陣A,后D列設置為B列,在我們的例子中就是矩陣m的前6列設置為矩陣A,后6列設置為矩陣B。
A=R(:,1:D);% 每行代表一組參數,其中每列代表每組參數的一個參數;行數就代表共有幾組參數
B=R(:,D+1:end);
2.構造nPopDD_out的矩陣ABi(i = 1,2,…,D),即用矩陣B中的第i列替換矩陣A的第i列,以本體為例:
AB = zeros(nPop, D, D_out) % 400*600*2
AB=
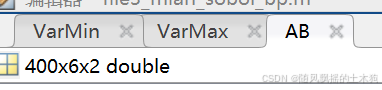
經過這三步我們構造了A、B、AB1、AB2這五個矩陣,這樣我們就有4 * nPop組輸入數據,因此我們將有4 * nPop的Y1、Y2值。將上述的數據帶入函數 ,這里詳細的計算過程就不描述了。根據輸入我們得出對應的Y1、Y2值矩陣。
D、計算所有樣本對應的Y值
for i=1:nPopYA(i)=myfun(A(i,:)); %A矩陣對應的YA值YB(i)=myfun(B(i,:));%B矩陣對應的YB值for j=1:DYAB(i,j)=myfun(AB(i,:,j));%YAB矩陣對應的YAB值end
end
[YA YB YAB1 YAB2 ]組合起來
依次各列數據代表YA YB YAB1 YAB2 值
E、一階影響指數S值、總效應指數ST值計算
1.計算公式:

var方差函數為matlab自帶
2.一階影響指數S值
VarX=zeros(D,1);% S的分子
S=zeros(D,1);
VarY=var([YA;YB],1);% S的分母。 計算基于給定的樣本總體的方差(EXCEL var.p())
for i=1:Dfor j=1:nPopVarX(i)=VarX(i)+YB(j)*(YAB(j,i)-YA(j));endVarX(i)=1/nPop*VarX(i);S(i)=VarX(i)/VarY; %一階影響指數
end
3.總效應指數ST值
for i = 1:Dfor k = 1:D_outsum_term = 0;for j = 1:nPopsum_term = sum_term + (YA(j, k) - AB(j, i, k))^2;endST0(i, k) = (1/(2*nPop)) * sum_term / VarY(k);end
end
4.SOBOL模型分析
(1) KRR
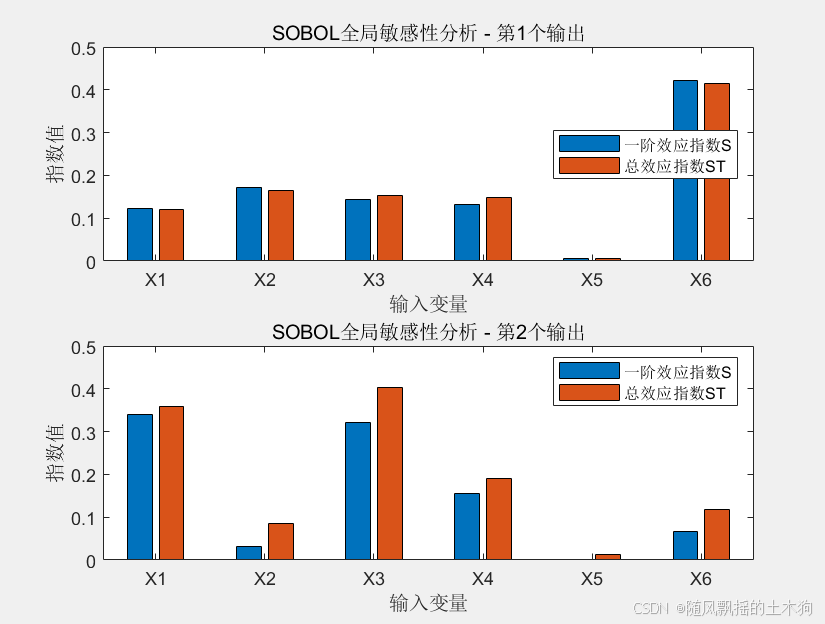
(2)BP
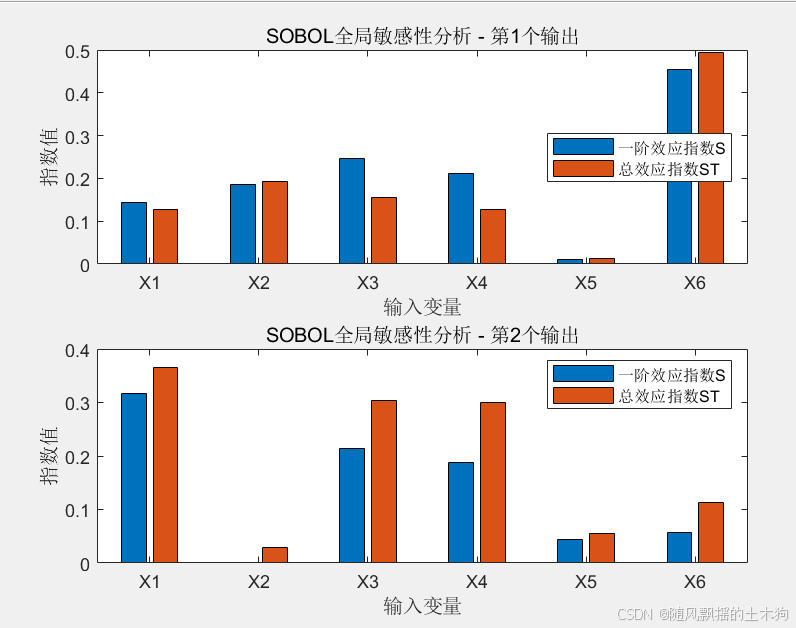
KRR和BP結果有一些出入,可見代理模型的重要性,
三、代碼獲取
1.閱讀首頁置頂文章
2.關注CSDN
3.根據自動回復消息,回復“119期”以及相應指令,即可獲取對應下載方式。


)







詳解:相對定位 絕對定位 固定定位)




)



