文本分類
- 傳統機器學習方法
- 文本表示
- 向量空間模型
- 特征選擇
- 文檔頻率
- 互信息
- 信息增益(IG)
- 分類器設計
- 貝葉斯理論:
- 線性判別函數
- 文本分類性能評估
- P-R曲線
- ROC曲線
將文本文檔或句子分類為預定義的類或類別, 有單標簽多類別文本分類和多標簽多類別文本分類。

傳統機器學習方法
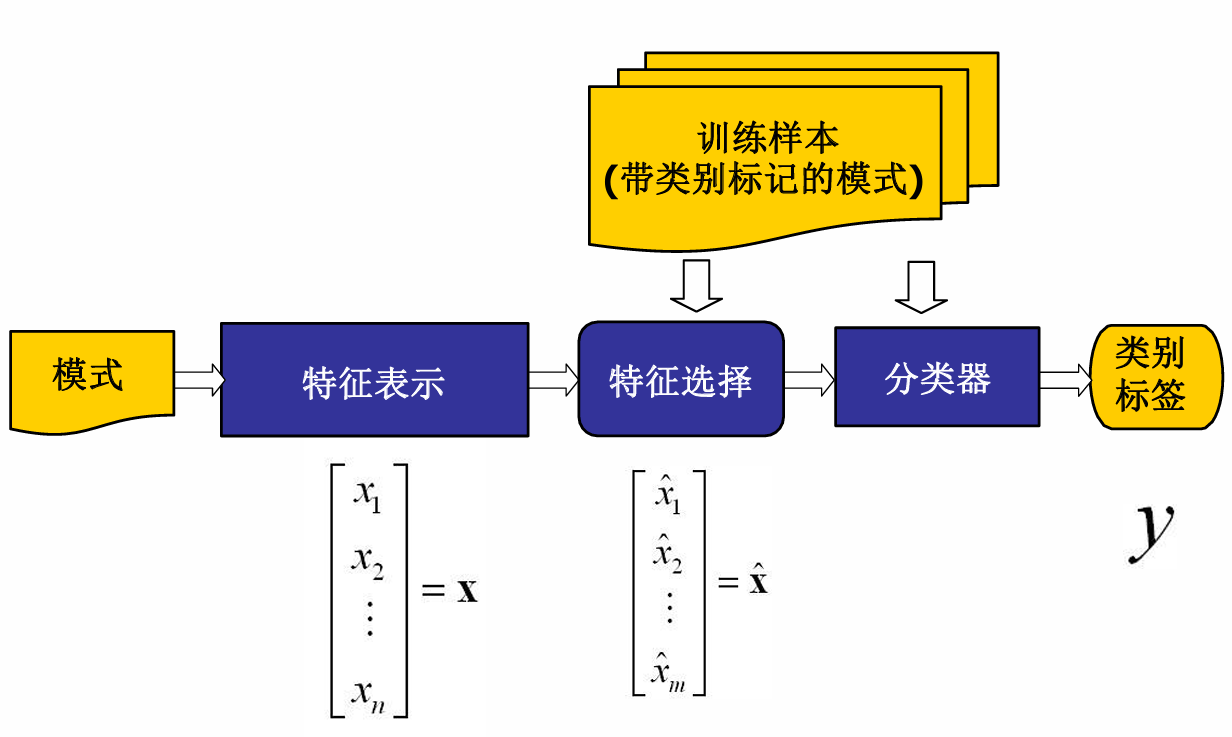
文本表示
計算機進行文本理解,必須知道文本長什么樣,文本的形式化表示是反映文本內容和區分不同文本的有效途徑。
向量空間模型
向量空間模型(vector space model, VSM)由G. Salton 等人于1960s末期在信息檢索領域提出,核心是將文本視為特征項的集合。特征項是VSM中最小的語言單元,可以是字、詞、短語等。文本則表示為特征項的集合 ( 𝑡 1 , 𝑡 2 , … , 𝑡 𝑛 ) (𝑡_1,𝑡_2,…,𝑡_𝑛) (t1?,t2?,…,tn?)
詞語(詞組或短語):若詞語作為特征項,那么特征項的集合可視為一個詞表。詞表可從語料中統計獲得,可看作一個詞袋,向量空間模型被稱為詞袋模型(bag-of-words, BOW)

特征項權重:每個特征項在文本中的重要性不盡相同,用𝑤表示特征項𝑡的權重,相應地,文本可以表示為 ( 𝑡 1 : 𝑤 1 , 𝑡 2 : 𝑤 2 , … , 𝑡 𝑛 : 𝑤 𝑛 ) (𝑡_1:𝑤_1,𝑡_2:𝑤_2,…,𝑡_𝑛:𝑤_𝑛) (t1?:w1?,t2?:w2?,…,tn?:wn?)或 ( 𝑤 1 , 𝑤 2 , … , 𝑤 𝑛 ) (𝑤_1,𝑤_2,…,𝑤_𝑛) (w1?,w2?,…,wn?)
如何計算特征項的權重?
- 布爾變量(是否出現)
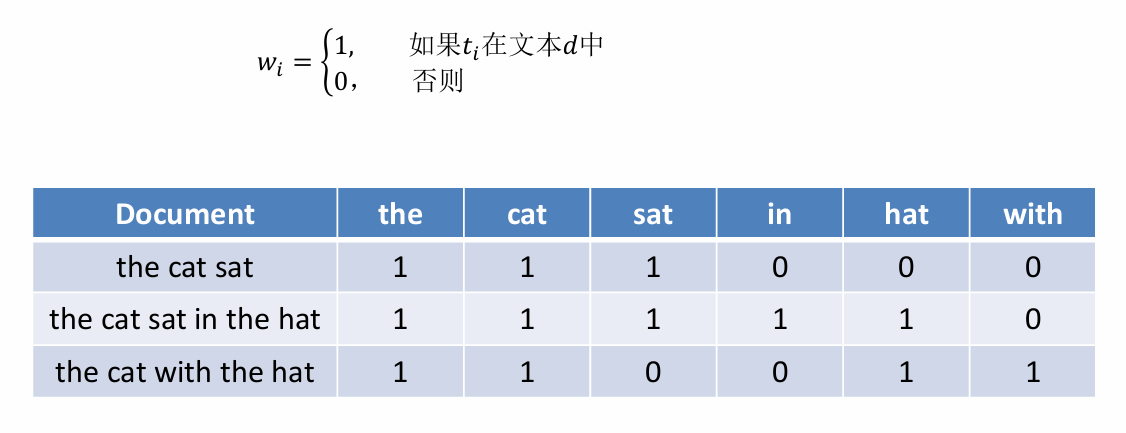
- 詞頻
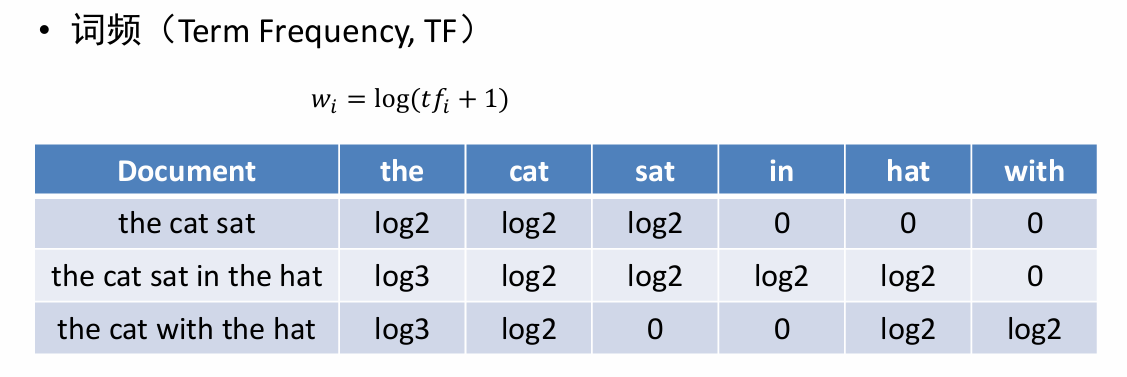
基于詞頻方法會有一個問題,如上圖所示,像the這樣子的詞特征權重會比較大,但是實際上這些詞在句子分析是效果甚微。 - 逆文檔頻率:定義為總的文檔數/單詞頻率,讓the這樣子的詞特征權重降為0.
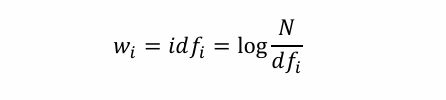
- TF-IDF=tfi * idfi,tfi是詞頻,idfi是逆文檔頻率,這是目前最好的一個方法。
特征選擇
文檔頻率
一個特征的文檔頻率是指在文檔集中含有該特征的文檔數目,假設 DF值低于某個域值的詞條是低頻詞,它們不含或含有較少的類別信息, 將這樣的詞條從原始特征空間中除去,不但能夠降低特征空間的維數,而且還有可能提高分類的精度。因此出現文檔數多的特征詞被保留的可能性大。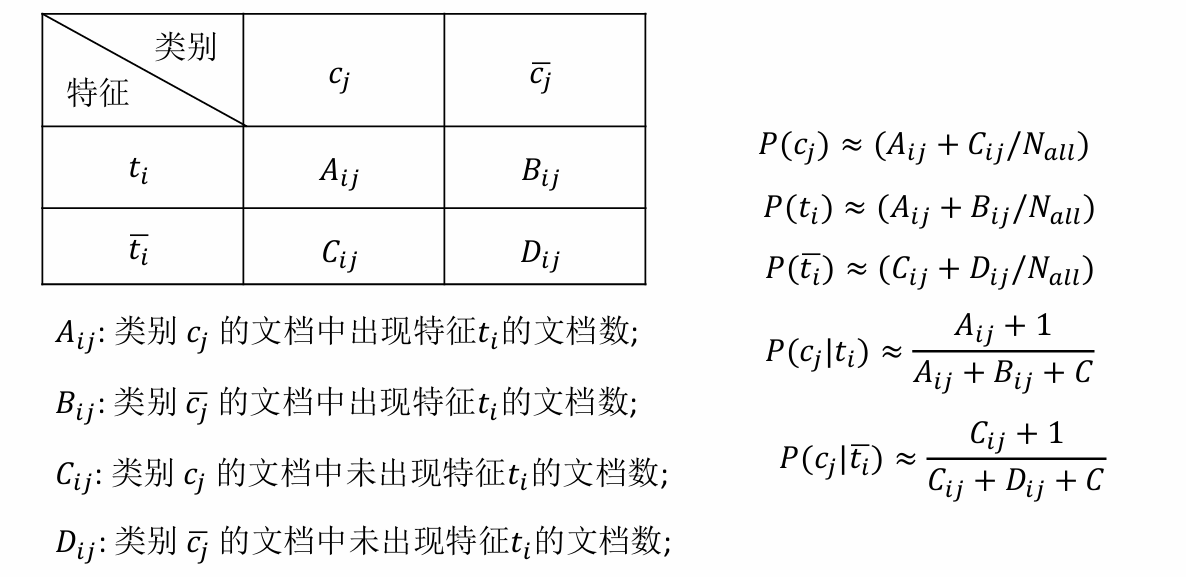
下面的兩個條件概率表示在有了ti這個特征之后屬于cj類別的概率,+1和+C是防止為0的變換(C表示類別的數量),即進行平滑處理。
互信息
互信息是關于兩個隨機變量互相依賴程度的一種度量
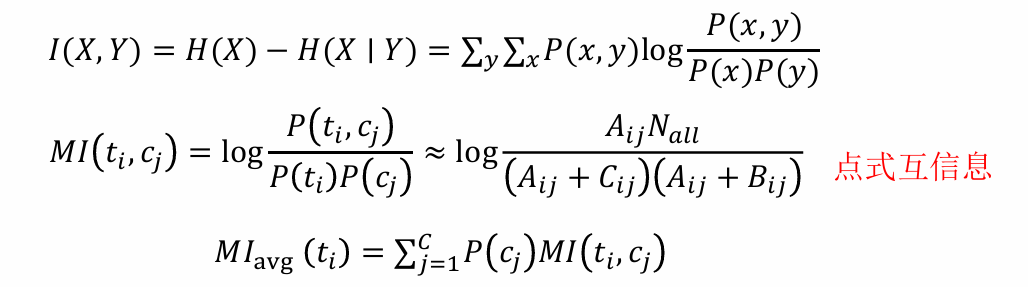
信息增益(IG)
IG衡量特征能夠為分類系統帶來多少信息
特征 𝑇 𝑖 𝑇_𝑖 Ti?對訓練數據集C的信息增益定義為集合C的經驗熵H?與特征 𝑇 𝑖 𝑇_𝑖 Ti?給定條件下C的經驗條件熵 H ( C ∣ 𝑇 𝑖 ) H(C|𝑇_𝑖) H(C∣Ti?)之差,即 I G ( C , T i ) = H ( C ) ? H ( C ∣ T i ) IG(C,T_i)=H(C)-H(C|T_i) IG(C,Ti?)=H(C)?H(C∣Ti?)
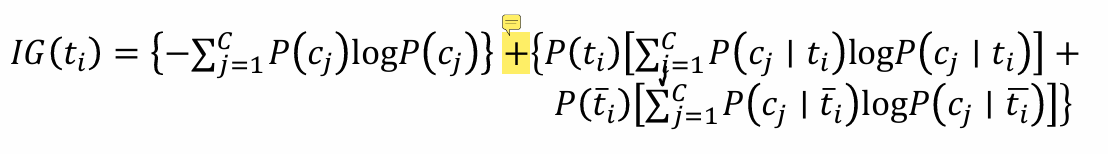
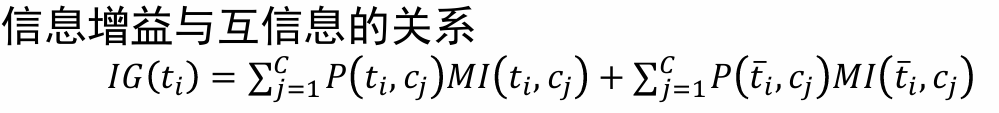
分類器設計
監督學習:訓練數據是人工標注的,用參數進行建模(構建目標函數),常見的監督學習模型有樸素貝葉斯、線性判別函數、支持向量機等等。
貝葉斯理論:
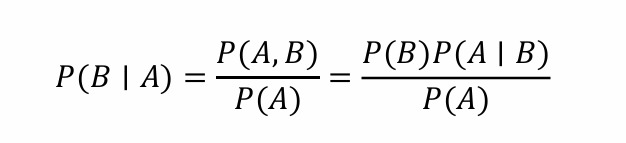
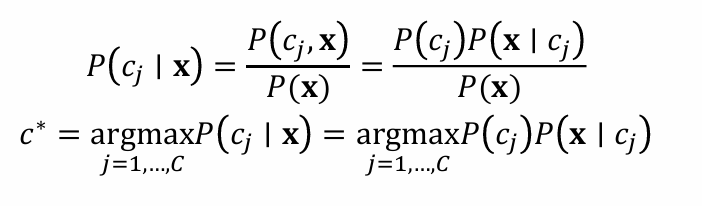
樸素貝葉斯假設:假設所有特征在給定類別的情況下是相互獨立的,這意味著每個特征對分類結果的影響是獨立的,與其他特征無關。
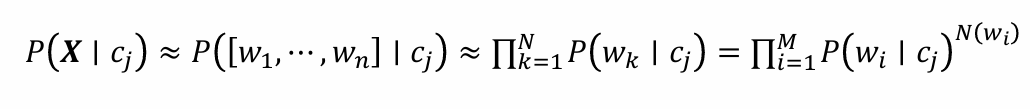
樸素貝葉斯分類模型中的參數估計:采用最大似然估計
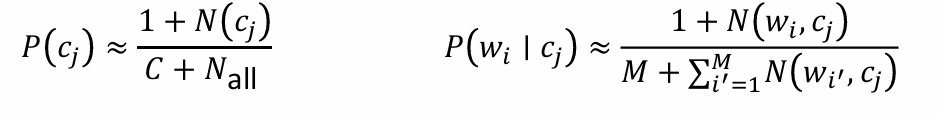
線性判別函數
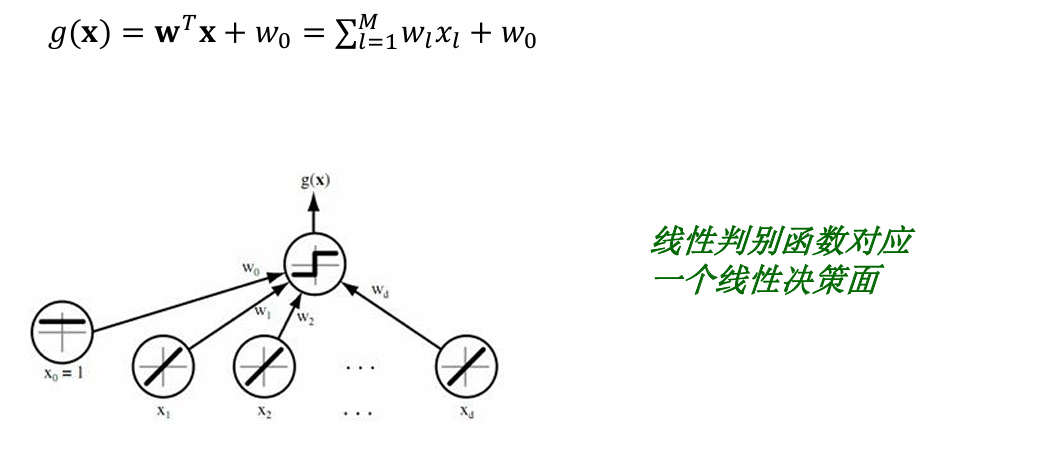
線性判別函數需要考慮兩個方面:一個是考慮哪個分類面更優,一個是考慮選擇哪個學習準則。常見的線性判別函數的學習準則有感知器準則、最小均方差、交叉熵等。
文本分類性能評估
假設一個文本分類任務共有M個類別,類別名稱分別為 𝐶 1 , … , 𝐶 𝑀 𝐶_1,…,𝐶_𝑀 C1?,…,CM?。
在完成分類任務以后,對于每一類都可以統計出真正例、真負例、假正例和假負例四種情形的樣本數目。
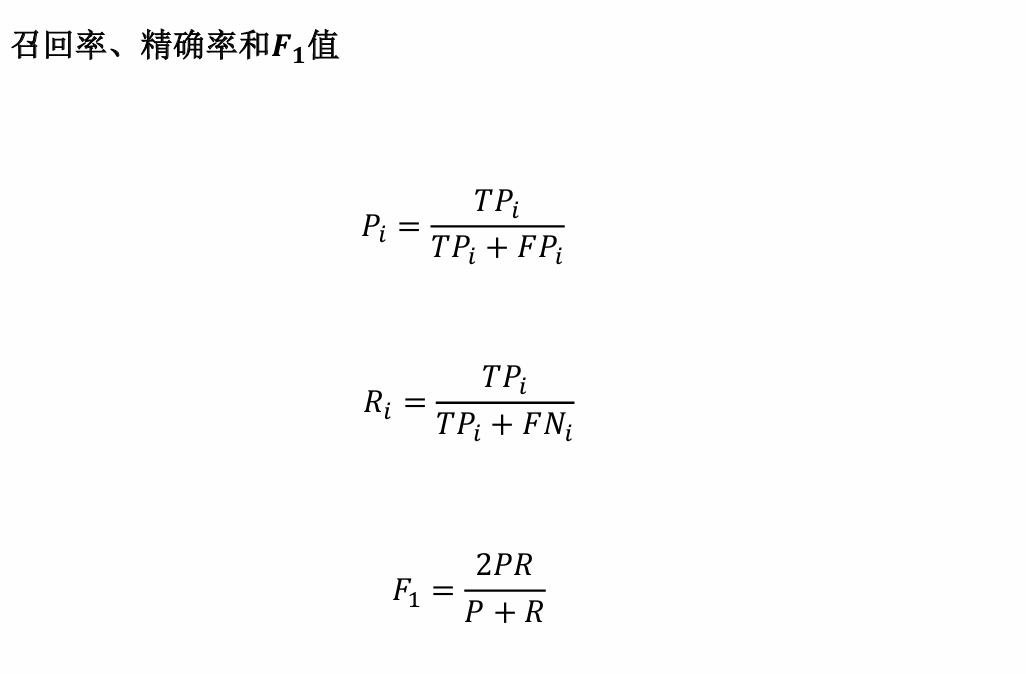
- 真正例 (True Positive, TP):模型正確預測為正例(即模型預測屬于該類,真實標簽屬于該類)。
- 真負例 (True Negative, TN): 模型正確預測為負例(即模型預測不屬該類,真實標簽不屬該類)。
- 假正例 (False Positive, FP):模型錯誤預測為正例(即模型預測屬于該類,真實標簽不屬該類)。
- 假負例 (False Negative, FN):模型錯誤預測為負例(即模型預測不屬該類,真實標簽屬于該類)。

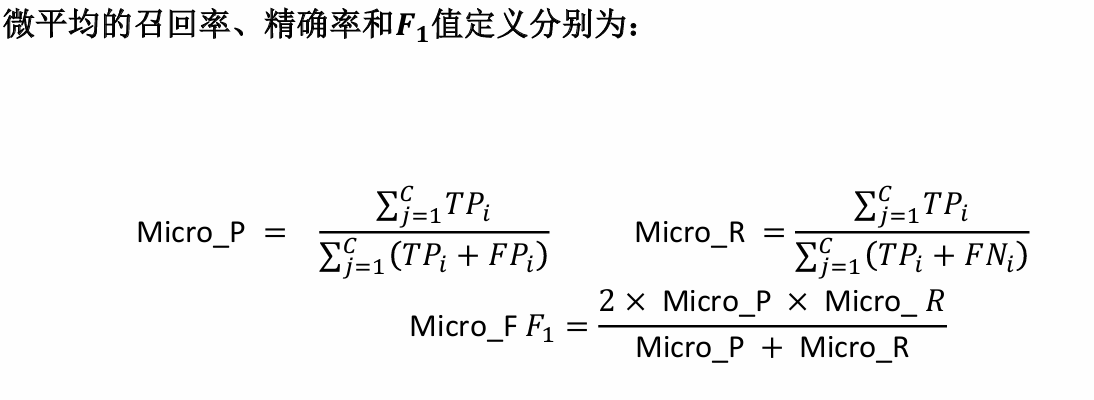
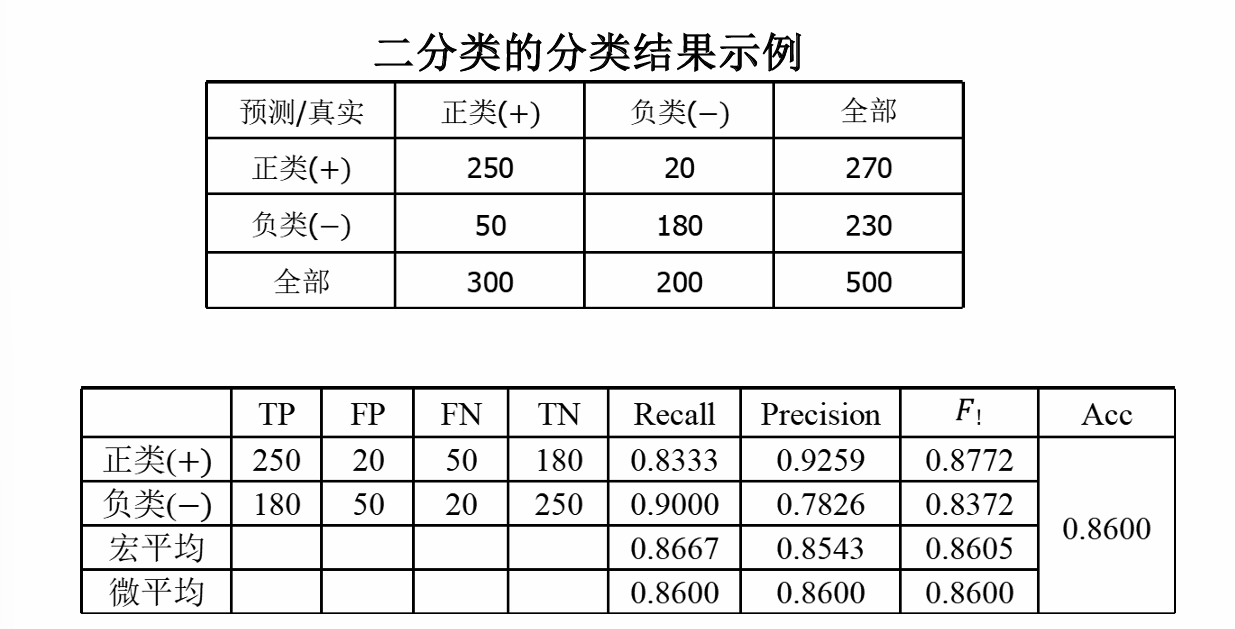
其中需要稍微解釋一下的是圖中宏平均和微平均的計算方法,宏平均是先計算每個類別的指標(如Recall、Precision、F1 Score),然后對這些指標求算術平均值。它平等對待每個類別,不考慮類別樣本數量的差異,所以宏平均只需要將正類和負類的各自指標值做一個平均即可。
但是微平均考慮了樣本數量的差異性,匯總所有類別的TP、FP、FN,然后用這些總和來計算整體的指標。它更關注樣本數量多的類別,因為樣本多的類別對總的TP、FP、FN貢獻更大。
注意:在二分類問題中,準確率 (Accuracy) 等于微平均 Recall、微平均 Precision 和微平均 F1 Score。
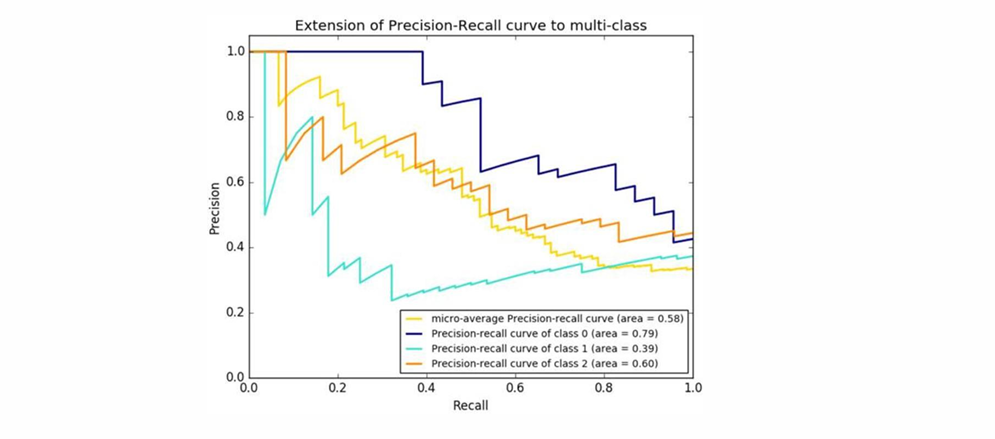
P-R曲線
通過調整分類器的閾值,將按輸出排序的樣本序列分割為兩部分,大于閾值的預測為正類,小于閾值的預測為負類,從而得到不同的召回率和精確率。如設置閾值為0時,召回率為1;設置閾值為1時,則召回率為0。以召回率作為橫軸、精確率作為縱軸,可以繪制出精確率-召回率(precision-recall, PR)曲線。
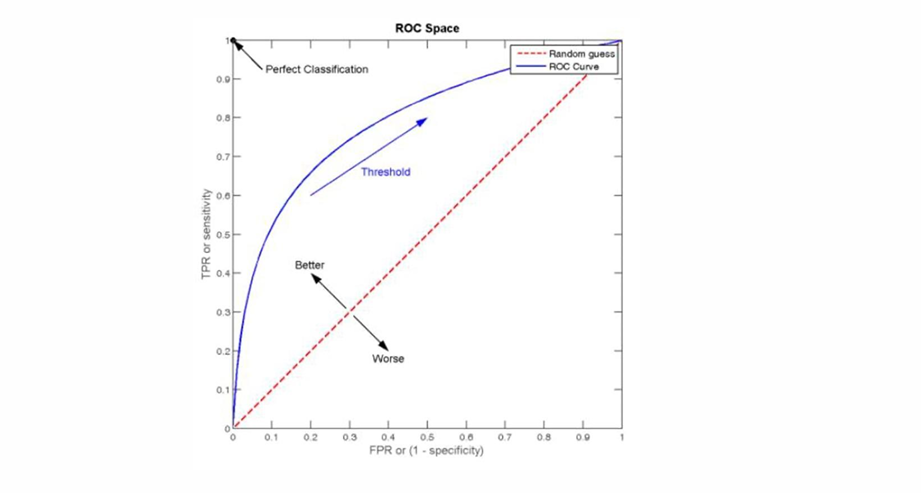
ROC曲線
以假正率(false positive rate)作為橫坐標,以真正率(true positive rate)(即召回率)作為縱坐標,繪制出的曲線稱為ROC(receiver operating characteristic)曲線。ROC曲線下的面積稱為AUC(area under ROC curve),AUC曲線越靠近左上方越好。AUC值越大,說明分類器性能越好。

![[論文閱讀] 人工智能+軟件工程 | 結對編程中的知識轉移新圖景](http://pic.xiahunao.cn/[論文閱讀] 人工智能+軟件工程 | 結對編程中的知識轉移新圖景)


:爬蟲偽裝)














