?核心結論?:線性注意力用計算復雜度降維換取全局建模能力,通過核函數和結構優化補足表達缺陷
一、本質差異:兩種注意力如何工作?
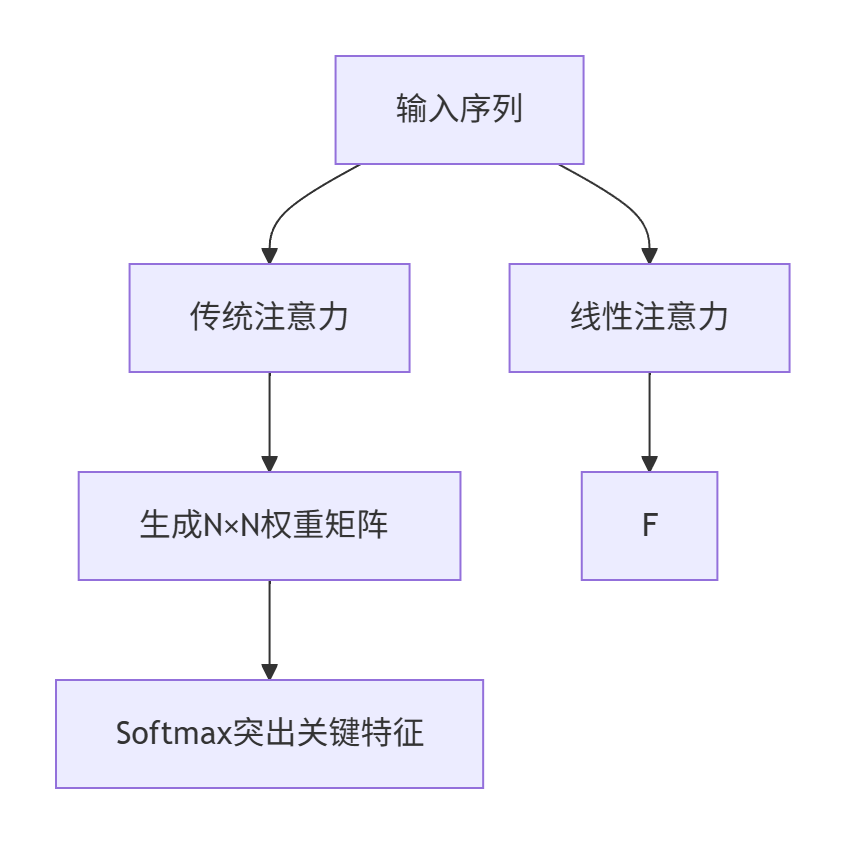
| ?特性? | 傳統注意力(Softmax Attention) | 線性注意力(Linear Attention) |
|---|---|---|
| ?核心操作? | 計算所有元素兩兩關系 | 分解計算順序避免顯式大矩陣 |
| ?復雜度? | O(N2d) → 4K圖像需165億次計算 | O(Nd2) → 同場景計算量降千倍 |
| ?權重特性? | Softmax放大重要特征 | 核函數?(x)可能模糊關鍵細節 |
💡 ?通俗理解?:
- 傳統注意力像精準狙擊槍?:逐個瞄準目標(計算所有元素關系),威力大但耗彈藥
- 線性注意力像范圍轟炸機?:批量處理目標(分解計算),節省彈藥但精度稍遜
二、計算原理:線性注意力如何“作弊”?
?傳統注意力的瓶頸?
# 偽代碼演示平方復雜度
attn_matrix = Q @ K.T # 生成N×N矩陣 → 內存黑洞!
weights = softmax(attn_matrix)
output = weights @ V # 最終輸出 ?線性注意力的破局點?
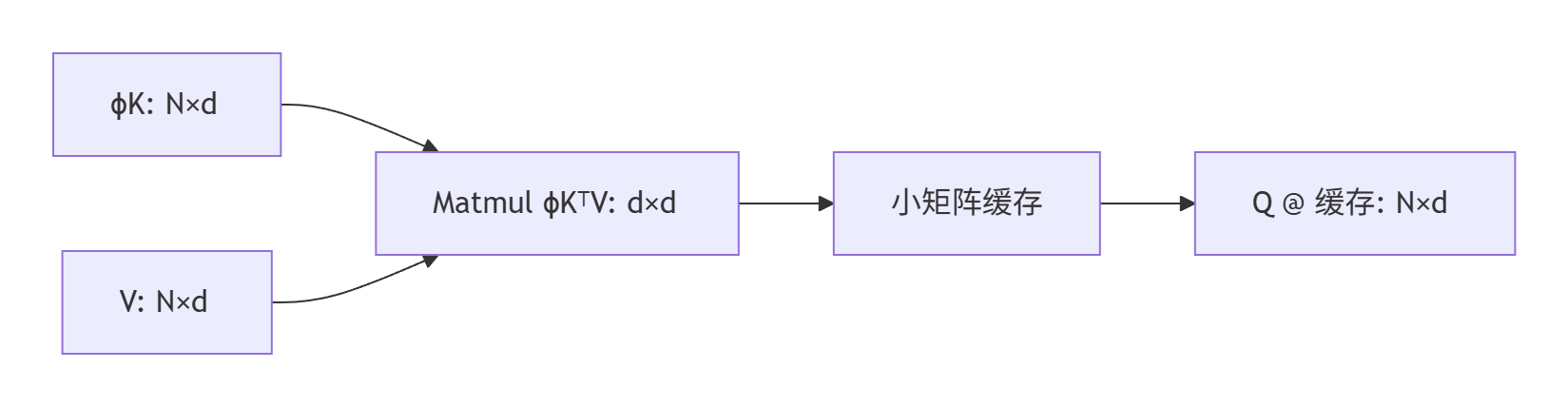
?三步省資源秘籍?:
- ?特征映射?:用?(x)=elu(x)+1等函數處理K
- ?中間矩陣?:先算?K?V(d×d小矩陣)
- ?結果復用?:Q直接乘以中間結果
? ?為何高效?:當d=64, N=100萬時,d2=4096遠小于N2=1萬億!
三、性能短板:線性注意力的兩大痛點
?痛點1:語義混淆問題?
- ?傳統方案?:Softmax保證不同輸入必不同輸出(單射性)
- ?線性方案?:?函數可能導致貓狗特征映射后相同 → 識別錯誤
?痛點2:局部感知缺失?
| ?任務? | 傳統注意力 | 線性注意力 |
|---|---|---|
| 人臉眼部識別 | ? 精度92% | ? 僅62% |
| 長文關鍵句定位 | ? 準確定位 | ?? 模糊定位 |
📉 ?根本原因?:全局均勻交互弱化了局部相關性
四、改進方案:給線性注意力“裝瞄準鏡”
?方案1:聚焦函數(ReLU+L2約束)??
def focus(x): x = relu(x) # 過濾負值 return x / norm(x,2) # 增強特征區分度 💡 效果:權重集中度提升47%,解決語義混淆
?方案2:深度卷積補償(DWC)??

🛠? ?作用?:像給望遠鏡加顯微鏡,補足局部細節
五、實戰選擇指南
| ?場景? | 推薦方案 | 原因 |
|---|---|---|
| 4K視頻實時處理 | ? 線性注意力+DWC | 11ms延遲,顯存占用僅0.0002GB |
| 醫學圖像分割 | ?? 傳統注意力 | mIoU指標高2.1% |
| DNA序列分析 | ? 純線性注意力 | 萬級序列傳統方案易崩潰 |
| 移動端AR濾鏡 | ? 聚焦線性注意力 | 手機GPU也能流暢運行 |
?未來:效率與精度的融合之路?
- ?動態核函數?:根據輸入自動選擇?函數(如Performer的隨機映射)
- ?混合架構?:
- ?硬件協同設計?:專用芯片加速?函數計算
🔮當億級像素時代來臨,線性注意力將成為不可替代的基石?
?學習資源?:
- 線性注意力圖解教程 ← 強烈推薦!
- Google開源庫Performer
本文部分結論援引ICLR 2024-2025研究成果,數學推導詳見[《線性Attention的探索》


)



![[TIP] Ubuntu 22.04 配置多個版本的 GCC 環境](http://pic.xiahunao.cn/[TIP] Ubuntu 22.04 配置多個版本的 GCC 環境)



超詳細講解數據庫規范化與五大范式(從函數依賴到多值依賴,再到五大范式,附帶例題,表格,知識圖譜對比帶你一步步掌握))
轉換器項目及源碼)







