編者按: 我們今天為大家帶來的文章,作者的觀點是:RAG 技術的演進是一個從簡單到復雜、從 Naive 到 Agentic 的系統性優化過程,每一次優化都是在試圖解決無數企業落地大語言模型應用時出現的痛點問題。
文章首先剖析 Naive RAG 的基礎架構及其核心挑戰,繼而深入探討三大優化方向:查詢動態優化(包括查詢重寫、查詢擴展等策略)、語義理解增強(重點解析 Anthropic 提出的上下文檢索方法)、計算效率革新(客觀評價緩存增強生成(CAG)的技術邊界)。最終聚焦 Agentic RAG 的范式突破,詳解其兩大核心機制(動態數據源路由、答案驗證與修正循環)。
作者 | Aurimas Griciūnas
編譯 | 岳揚
基于 RAG(檢索增強生成)的 AI 系統,過去是,現在仍然是企業利用大語言模型(LLM)的最有價值的應用之一。我記得差不多兩年前我寫了第一篇關于 RAG 的文章,那時候這個術語還未被廣泛采用。
我當時描述的是一個以最基礎方式實現的 RAG 系統。自那以后,這個行業不斷發展,在此過程中引入了各種先進技術。
在這篇文章,我們將探討 RAG 的演進歷程 —— 從基礎版本(Naive)到 Agentic。閱讀本文后,您將理解 RAG 系統演進過程中的每一步都攻克了哪些挑戰。
01 Naive RAG 的出現
2022 年底 ChatGPT 的推出讓 LLMs 成為了主流,幾乎與此同時,Naive RAG 也應運而生。檢索增強生成(RAG)技術的出現旨在解決原生 LLM 所面臨的問題。簡而言之就是:
- 幻覺問題。
- 有限的上下文窗口大小。
- 無法訪問非公開數據。
- 無法自動獲取訓練截止日期后的新信息,且更新這些知識需要重新訓練模型。
RAG 的最簡單實現形式如下:
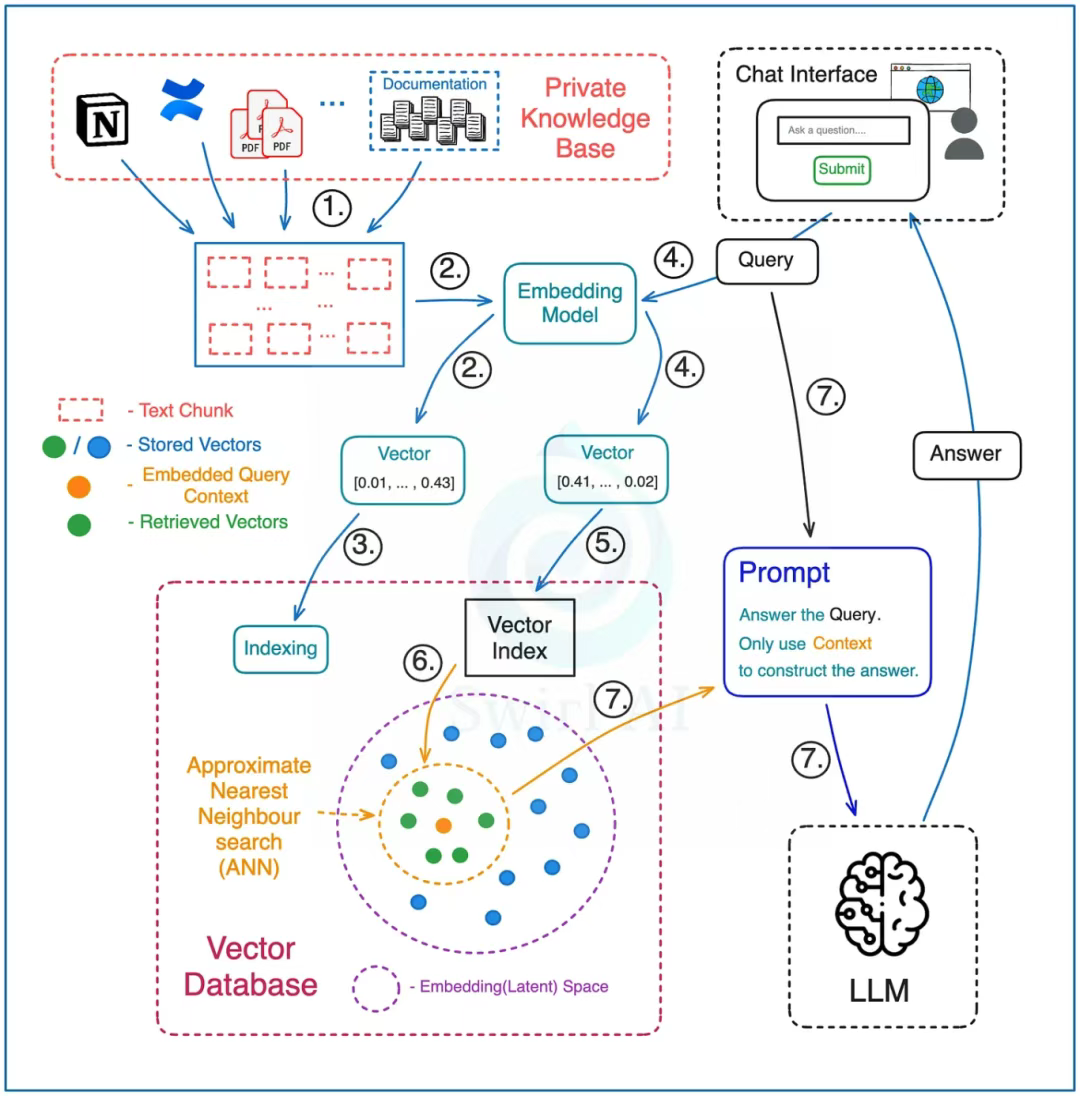
Naive RAG.
預處理過程(Preprocessing):
1)將整個知識庫的文本語料分割成文本塊(chunk) —— 每個文本塊代表一段可供查詢的上下文片段。目標數據可來自多種來源,例如以 Confluence 文檔為主、PDF 報告為輔的混合資料庫。
2)使用嵌入模型(Embedding Model)將每個文本塊轉換為向量嵌入(vector embedding)。
3)將所有向量嵌入存儲到向量數據庫(Vector Database)中。 同時分別保存代表每個嵌入的文本及其指向嵌入的指針。
檢索過程(Retrieval):
4)在向量數據庫或知識檢索系統中,為了確保查詢和存儲的知識能夠準確匹配,需要用同一個嵌入模型(Embedding Model)來處理存儲到知識庫中的文檔內容和用戶提出的問題或查詢。
5)使用生成的向量嵌入在向量數據庫的索引上運行查詢。 選擇要從向量數據庫中檢索的向量數量 —— 等同于你將檢索并最終用于回答查詢的上下文數量。
6)向量數據庫針對提供的向量嵌入在索引上執行近似最近鄰(ANN)搜索,并返回之前選定數量的上下文向量。 該過程會返回在給定嵌入空間(Embedding/Latent space)中最相似的向量,需將這些返回的向量嵌入映射到其對應的原始文本塊。
7)通過提示詞(prompt)將問題連同檢索到的上下文文本塊傳遞給 LLM。 指示 LLM 僅使用提供的上下文來回答給定問題。這并不意味著不需要提示詞工程(Prompt Engineering)——你仍需確保 LLM 返回的答案符合預期范圍,例如,如果檢索到的上下文中沒有可用數據,則應確保不提供編造的答案。
02 Naive RAG 系統的動態組件
即便不采用任何高級技術,在構建生產級 RAG 系統時也需要考慮許多動態組件。
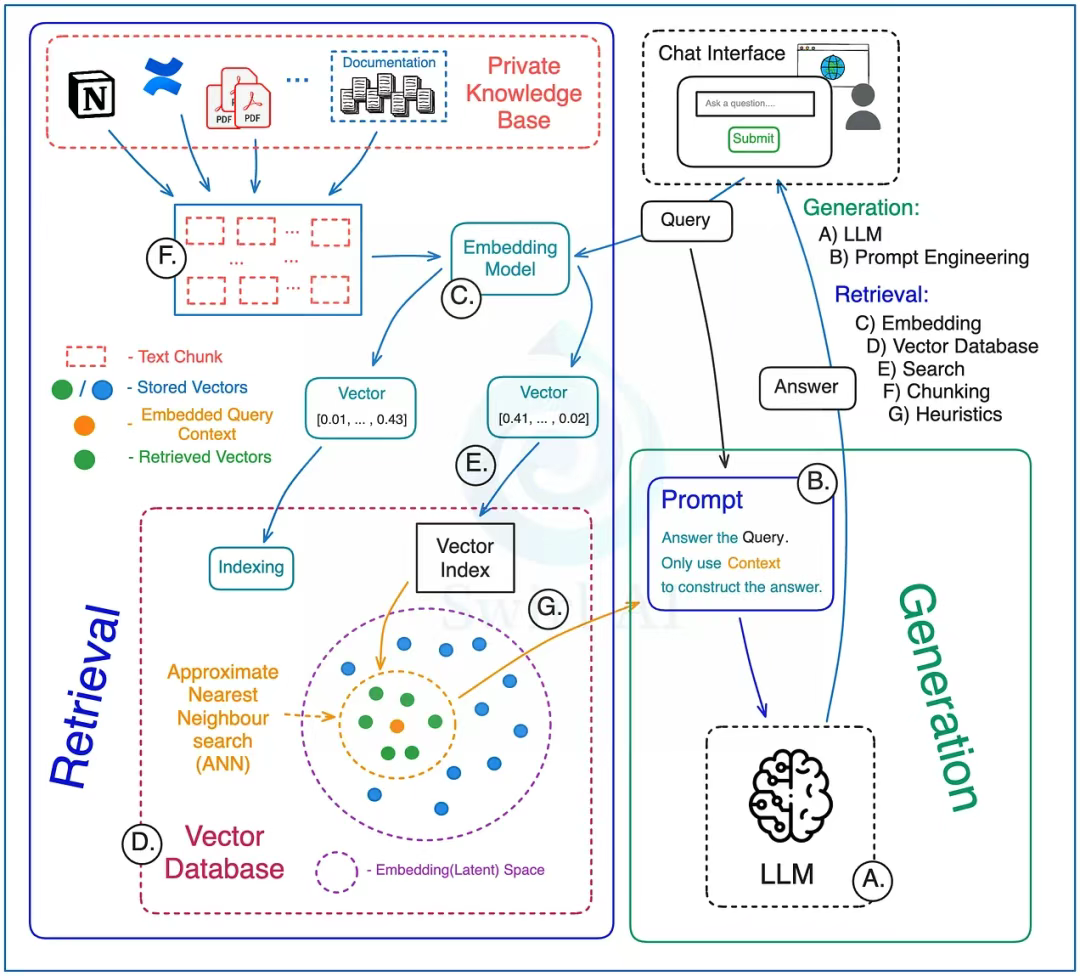
RAG - 動態組件
檢索環節:
F) 分塊策略 - 如何對用于外部上下文的數據進行分塊
- 小文本塊與大文本塊的選擇
- 滑動窗口或固定窗口的文本分塊方法
- 檢索時是否關聯父塊/鏈接塊,或僅使用原始的檢索數據
C) 選擇嵌入模型,將外部上下文嵌入到 latent space 或從 latent space 中查詢。 需要考慮上下文嵌入(Contextual embeddings)。
D) 向量數據庫
- 選擇哪種數據庫
- 選擇部署位置
- 應與向量嵌入一并存儲哪些元數據?這些數據將用于檢索前的預篩選和檢索后的結果過濾。
- 索引構建策略
E) 向量搜索
- 選擇相似度度量標準
- 選擇查詢路徑:元數據優先,還是近似最近鄰(ANN)優先
- 混合搜索方案
G) 啟發式規則 - 應用于檢索流程的業務規則
- 根據文檔的時間相關性調整權重
- 對上下文進行去重(根據多樣性進行排序)
- 檢索時附帶內容的原始來源信息
- 根據特定條件(如用戶查詢意圖、文檔類型)對原始文本進行差異化預處理
生成環節:
A) 大語言模型 - 為你的應用程序選擇合適的 LLM
B) 提示詞工程 - 即使能在提示詞(prompt)中調用上下文信息,也仍需精心設計提示詞 —— 你依然需要調整系統(譯者注:包括設定角色(Role)、規則(Rules)、輸出格式(Format)等對齊手段。),才能生成符合預期的輸出,并防范越獄攻擊。
完成上述所有工作后,我們才得以構建可運行的 RAG 系統。
但殘酷的事實是,此類系統往往難以真正解決業務問題。由于各種原因,這種系統的準確性可能很低。
03 改進 Naive RAG 系統的高級技術
為不斷提高 Naive RAG 系統的準確性,我們采用了以下一些較為成功的技術:
- 查詢改寫(Query Alteration) - 可采用以下幾種技巧:
-
- 查詢重寫(Query rewriting) :讓大語言模型(LLM)重寫原始查詢,以更好地適應檢索過程。重寫的方式有多種,例如,修改語法錯誤,或將查詢簡化為更簡短精煉的語句。
- 查詢擴展(Query Expansion):讓 LLM 對原始查詢進行多次改寫,創建多個變體版本(variations)。接著,多次運行檢索過程,以檢索更多可能相關的上下文。
- 重排序(Reranking) - 對初次檢索出的文檔,用比常規上下文搜索更復雜的方法進行重排序。通常,這需要使用更大的模型,并且在檢索階段有意獲取遠超實際所需數量的文檔。重排序(Reranking)與前文提到的查詢擴展(Query Expansion)配合使用效果尤佳,因為后者通常能返回比平時更多的數據。整個過程類似于我們在推薦系統中常見的做法。
- 嵌入模型的微調(Fine-Tuning of the embedding model) - 某些領域(如醫療)在使用基礎嵌入模型進行數據檢索效果不佳。此時,你就需要對自己的嵌入模型進行定制化微調。
接下來,我們再看些其它高級的 RAG 技術與架構。
04 上下文檢索(Contextual Retrieval)
上下文檢索(Contextual Retrieval)的概念由 Anthropic 團隊在去年年底提出。其目標在于提升基于檢索增強生成(RAG)的 AI 系統中檢索到的數據的準確性和相關性。
我非常喜歡上下文檢索的直觀性和簡潔性。而且它的確能帶來不錯的效果。
以下是上下文檢索的實現步驟:
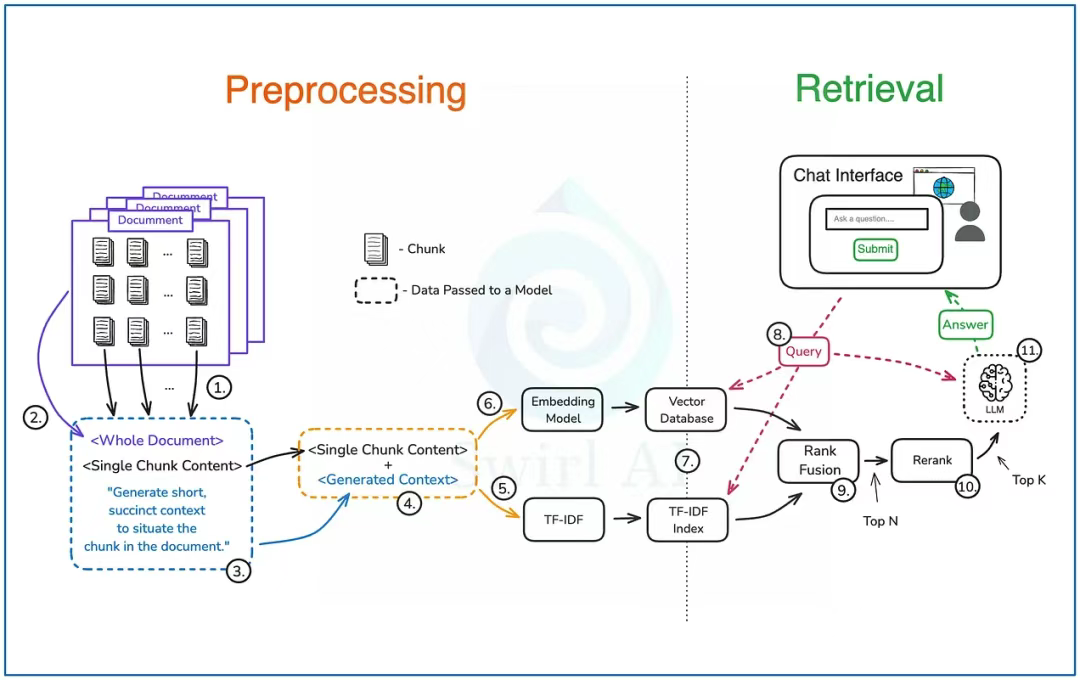
上下文檢索(Contextual Retrieval)
預處理階段(Preprocessing):
1)使用選定的分塊策略將每份文檔分割成若干個文本塊。
2)將每個文本塊單獨與完整文檔一起加入提示詞中。
3)在提示詞中添加指令,要求 LLM 定位該文本塊在文檔中的位置,并為其生成簡短的上下文。隨后將此提示詞輸入選定的 LLM。
4)將上一步生成的上下文,與其對應的原始文本塊合并。
5)將組合后的數據輸入一個 TF-IDF 嵌入器(embedder)。
6)再將數據輸入一個基于 LLM 的嵌入模型(embedding model)。
7)將步驟 5 和步驟 6 生成的數據存入支持高效搜索的數據庫中。
檢索階段(Retrieval):
8)使用用戶查詢(user query)檢索相關上下文。使用近似最近鄰(ANN)搜索實現語義匹配,同時使用 TF-IDF 索引進行精確搜索。
9)使用排序融合(Rank Fusion)技術對檢索結果進行合并、去重,并選出排名前 N 的候選項。
10)對前一步的結果進行重排序(Rerank),將范圍縮小至前 K 個候選項。
11)將步驟 10 的結果與用戶查詢一起輸入 LLM,生成最終答案。
一些思考:
- 步驟 3. 聽起來(并且實際也)耗費驚人,但通過應用提示詞緩存技術(Prompt Caching),成本可以顯著降低。
- 提示詞緩存技術既可在專有(閉源)模型場景下使用,也可在開源模型場景下使用(請參閱下一段內容)。
05 緩存增強生成(Cache Augmented Generation)的曇花一現
2024 年底,一份白皮書在社交媒體上短暫刷屏。它介紹了一項有望徹底改變 RAG (檢索增強生成) 的技術(真的能嗎?)—— 緩存增強生成(Cache Augmented Generation, CAG)。我們已經了解了常規 RAG 的工作原理,下面簡要介紹一下 CAG:
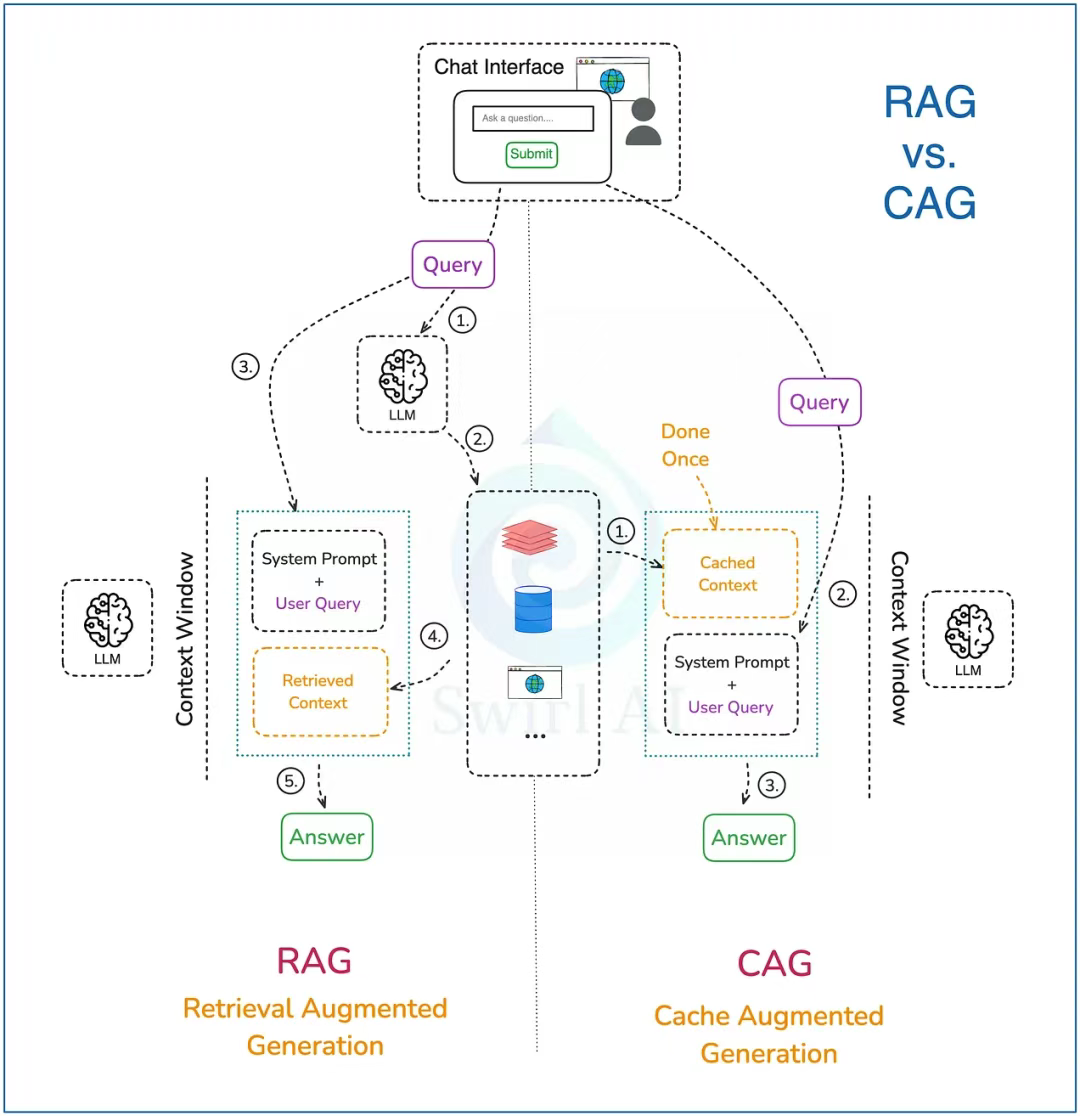
RAG vs. CAG
1)將所有外部上下文預計算至 LLM 的 KV 緩存中,并存入內存。該過程僅需執行一次,后續步驟可重復調用初始緩存而無需重新計算。
2)向 LLM 輸入包含用戶查詢(user query)的系統提示詞,同時提供如何使用緩存上下文的指令。
3)將 LLM 生成的答案返回用戶。完成后清除緩存中的臨時生成內容,僅保留最初緩存的上下文,使 LLM 準備好進行下一次生成。
CAG 承諾,通過將所有上下文存儲在 KV 緩存中(而非每次生成時只檢索部分數據),實現更精準的檢索。現實如何?
- CAG 無法解決因上下文極長而導致的不準確問題。
- CAG 在數據安全方面存在諸多局限性。
- 對大型組織而言,將整個內部知識庫加載到緩存近乎不可能。
- 緩存會失去動態更新能力,添加新數據非常困難。
事實上,自從多數 LLM 提供商引入提示詞緩存(Prompt Caching)技術后,我們已在使用的正是 CAG 的一種變體。我們的做法可以說是 CAG 與 RAG 的融合,具體實施過程如下:
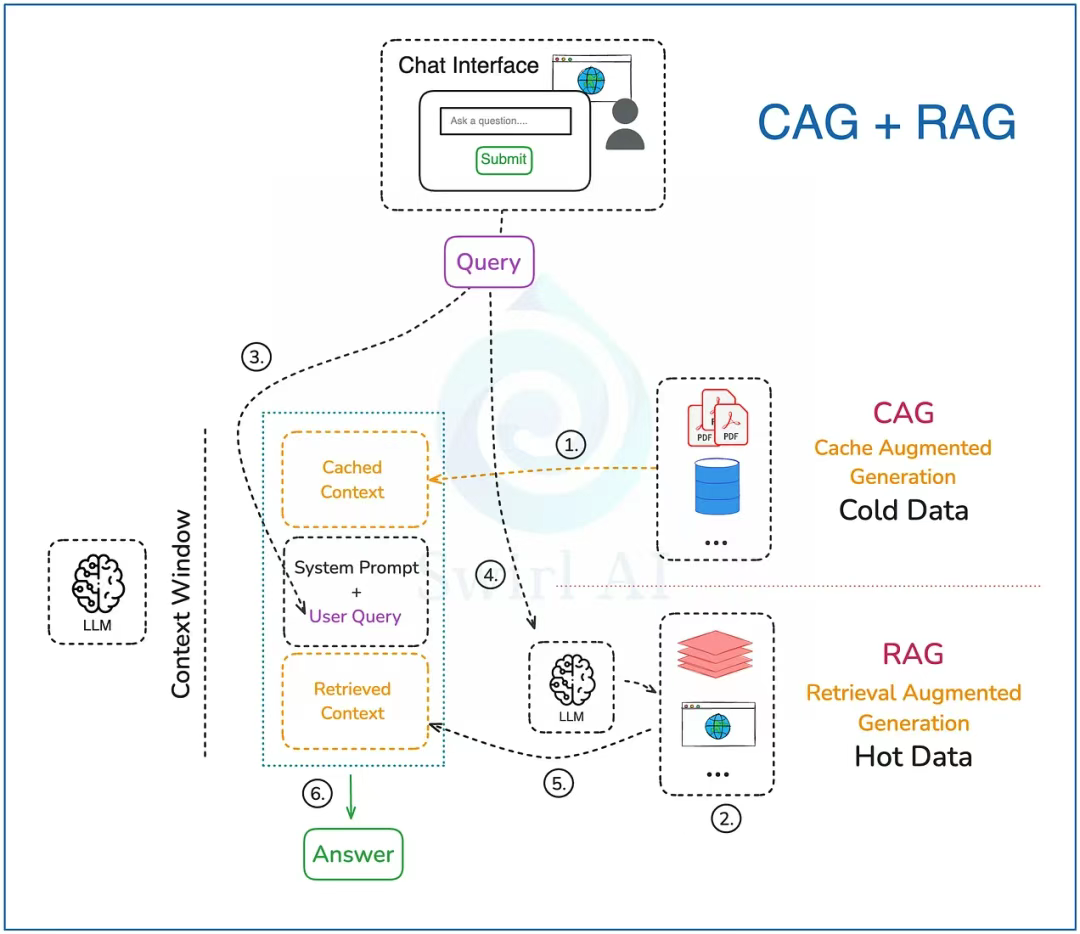
RAG 和 CAG 的融合
數據預處理:
1)在緩存增強生成(CAG)中,我們僅使用極少變化的數據源。除了要求數據更新頻率低外,我們還應該考慮哪些數據源最常被相關查詢命中。確定這些信息后,我們才會將所有選定的數據預計算至 LLM 的 KV 緩存中,并將其緩存在內存中。此過程僅需執行一次,后續步驟可多次運行而無需重新計算初始緩存。
2)對于 RAG,如有必要,可將向量嵌入預計算并存入兼容的數據庫中,供后續步驟 4 檢索。有時對于 RAG 來說,只需更簡單的數據類型,常規數據庫即可滿足需求。
查詢路徑:
3)構建一個提示詞,需包含用戶查詢及系統提示詞,明確指導大語言模型如何利用緩存的上下文(cached context)及外部檢索到的上下文信息。
4)將用戶查詢轉化為向量嵌入,用于通過向量數據庫進行語義搜索,并從上下文存儲中檢索相關數據。若無需語義搜索,則查詢其他來源(如實時數據庫或互聯網)。
5)將步驟 4 中獲取的外部上下文信息整合至最終的提示詞中,以增強回答質量。
6)向用戶返回最終生成的答案。
接下來,我們將探討最新的技術發展方向 —— Agentic RAG。
06 Agentic RAG
Agentic RAG 新增了兩個核心組件,試圖降低應對復雜用戶查詢時的結果不一致性。
- 數據源路由(Data Source Routing)。
- 答案驗證與修正(Reflection)。
現在,讓我們來探究其工作機制。
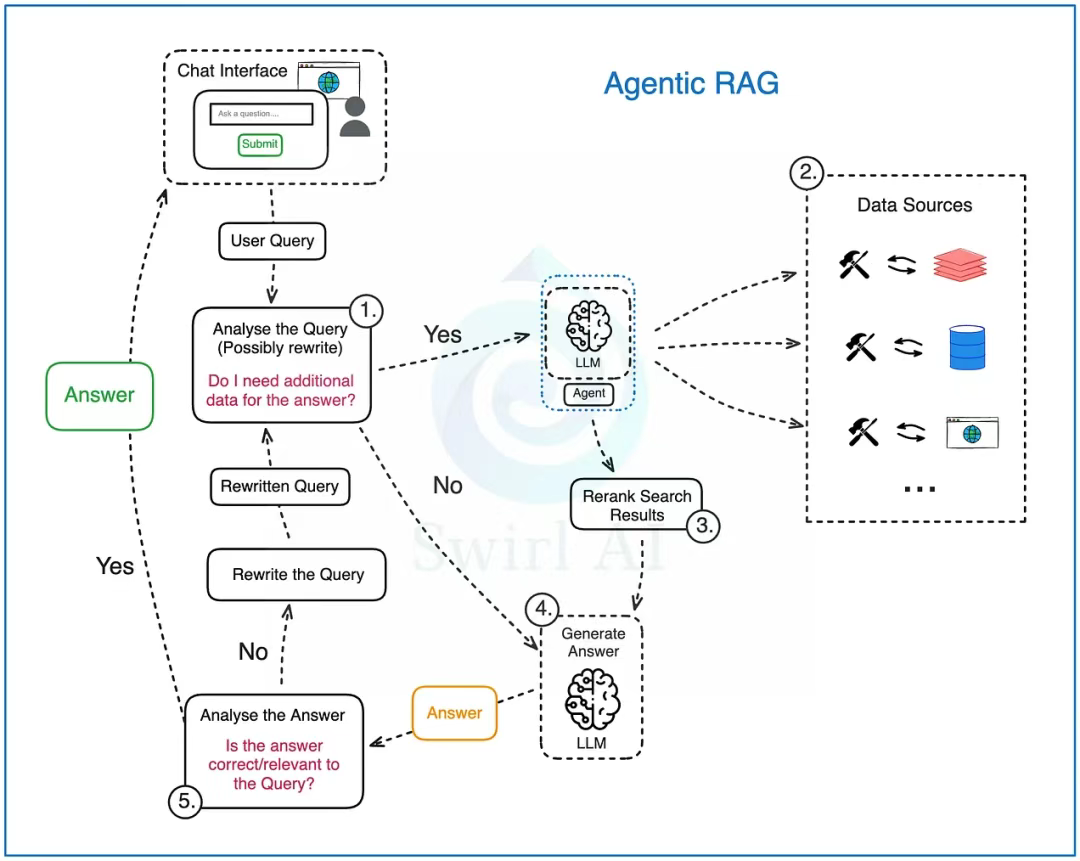
Agentic RAG
1)分析用戶查詢:將原始用戶查詢傳遞給基于大語言模型的智能體進行分析。在此階段:
a. 原始查詢可能會被改寫(有時需多次改寫),最終生成單個或多個查詢傳遞至后續流程。
b. 智能體判斷是否需要額外數據源來回答查詢。這是體現其自主決策能力的第一環節。
2)如果需要其他數據,則觸發檢索步驟,此時進行數據源路由(Data Source Routing)。 系統中可預置一個或多個數據集,智能體被賦予自主權來選擇適用于當前查詢的具體數據源。舉幾個例子:
a. 實時用戶數據(如用戶當前位置等實時信息)。
b. 用戶可能感興趣的內部文檔。
c. 網絡公開數據。
d. …
3)一旦從潛在的多個數據源檢索到數據,我們就會像在常規 RAG 中一樣對其進行重排序。 這也是一個關鍵步驟,因為利用不同存儲技術的多個數據源都可整合至此 RAG 系統中。檢索過程的復雜性可被封裝在提供給智能體的工具背后。
4)嘗試直接通過大語言模型生成答案(或生成多個答案,或生成一組操作指令)。 此過程可在第一輪完成,或在答案驗證與修正(Reflection)環節后進行。
5)對生成的答案進行分析、總結,并評估其正確性和相關性:
a. 若智能體判定答案已足夠完善,則返回給用戶。
b. 若智能體認為答案有待改進,則嘗試改寫用戶查詢并重復這個生成循環(generation loop)。此處體現了常規 RAG 與 Agentic RAG 的第二大差異。
近期 Anthropic 的開源項目 MCP,將為 Agentic RAG 的開發提供強勁助力。
07 總結 (Wrapping up)
至此,我們回顧了現代檢索增強生成(RAG)架構的演進歷程。RAG 技術并未消亡,也不會在短期內消失。 我相信其架構在未來一段時間內仍將持續演進。學習這些架構并了解何時使用何種方案,將是一項有價值的投資。
一般來說,方案越簡單越好,因為增加系統復雜性會帶來新的挑戰。 一些新出現的挑戰包括:
- 對端到端系統進行評估的困難。
- 多次調用大語言模型導致的端到端延遲增加。
- 運營成本的增加。
- …
END
本期互動內容 🍻
?Agentic RAG 引入的復雜性是否值得?你見過哪些場景必須用 Agentic 才能解決?
本文經原作者授權,由 Baihai IDP 編譯。如需轉載譯文,請聯系獲取授權。
原文鏈接:
https://www.newsletter.swirlai.com/p/the-evolution-of-modern-rag-architectures



















