網頁爬蟲(Web Crawler)是一種自動化程序,通過模擬人類瀏覽行為,從互聯網上抓取、解析和存儲網頁數據。其核心作用是高效獲取并結構化網絡信息,為后續分析和應用提供數據基礎。以下是其詳細作用和用途方向:
??一、核心作用??
-
??數據采集??
- 自動遍歷目標網站,提取文本、圖片、視頻、鏈接等公開數據。
- 支持定時抓取,實現數據的動態更新(如新聞、價格、社交媒體內容)。
-
??信息結構化??
- 將非結構化的網頁內容(如HTML)轉化為結構化數據(如JSON、CSV),便于數據庫存儲或分析。
-
??效率提升??
- 替代人工復制粘貼,處理大規模數據時速度更快、成本更低。
??二、主要用途方向??
1. ??搜索引擎優化(SEO)??
- ??搜索引擎索引??:Google、百度等通過爬蟲建立網頁索引庫,支撐搜索結果。
- ??競品分析??:抓取競品網站的關鍵詞、流量數據,優化自身SEO策略。
2. ??商業與市場分析??
- ??價格監控??:電商平臺(如亞馬遜、淘寶)抓取競品價格,動態調整定價。
- ??輿情分析??:爬取社交媒體、論壇評論,分析用戶對品牌/產品的評價。
3. ??學術與研究??
- ??文獻聚合??:自動收集學術論文、專利數據(如PubMed、arXiv)。
- ??社會趨勢研究??:分析新聞、博客內容,追蹤公共事件的發展脈絡。
4. ??金融與投資??
- ??實時數據獲取??:抓取股票行情、財報、加密貨幣價格(如Yahoo Finance)。
- ??風險預警??:監測企業負面新聞或行業政策變動。
5. ??人工智能與大數據??
- ??訓練數據來源??:為機器學習模型提供文本(NLP)、圖像(CV)數據集。
- ??語言模型訓練??:如ChatGPT的預訓練數據部分來源于爬蟲抓取的公開網頁。
6. ??生活服務??
- ??聚合平臺??:整合租房信息(如鏈家)、機票價格(如Skyscanner)。
- ??內容推薦??:新聞App(如今日頭條)爬取多源內容進行個性化推送。
7. ??技術運維與安全??
- ??死鏈檢測??:掃描網站內失效的鏈接或頁面錯誤。
- ??安全審計??:識別網站漏洞(如敏感信息泄露)。
8. ??政府與公共事務??
- ??政策監控??:自動抓取政府網站的政策更新或招標信息。
- ??災害預警??:收集氣象、地震等實時數據。
??三、注意事項??
- ??合法性??:遵守
robots.txt協議,避免抓取敏感或個人隱私數據。 - ??反爬機制??:需處理驗證碼、IP封鎖、動態加載(如JavaScript渲染)等技術挑戰。
- ??倫理問題??:尊重數據版權,避免過度請求導致服務器負載。
抓取網頁數據通常涉及以下幾個步驟:??發送HTTP請求 → 獲取網頁內容 → 解析數據 → 存儲結果??。以下是詳細方法和常用工具:
??一、基礎方法??
1. ??手動復制粘貼??
- ??適用場景??:少量靜態數據(如單頁文字、表格)。
- ??缺點??:效率低,無法自動化。
2. ??瀏覽器開發者工具(DevTools)??
- ??步驟??:
- 右鍵網頁 → 選擇“檢查”(或按?
F12/Ctrl+Shift+I)。 - 在?
Elements?標簽頁查看HTML結構,手動復制所需內容。 - 在?
Network?標簽頁分析API請求(適用于動態加載數據)。
- 右鍵網頁 → 選擇“檢查”(或按?
- ??適用場景??:快速查看網頁結構或API接口。
??二、編程抓取(自動化)??
1. ??使用 Python 的?requests?+?BeautifulSoup(靜態頁面)?
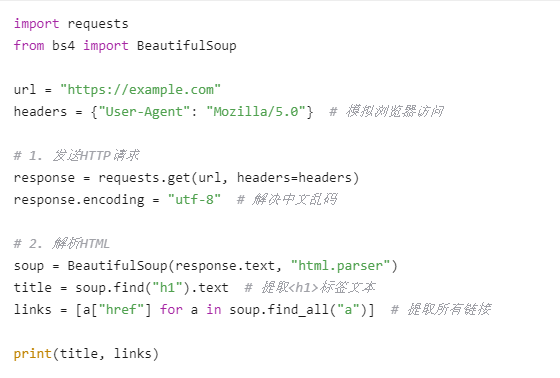
抓取網頁數據通常涉及以下幾個步驟:??發送HTTP請求 → 獲取網頁內容 → 解析數據 → 存儲結果??。以下是詳細方法和常用工具:
抓取網頁數據通常涉及以下幾個步驟:??發送HTTP請求 → 獲取網頁內容 → 解析數據 → 存儲結果??。以下是詳細方法和常用工具:
??一、基礎方法??
1. ??手動復制粘貼??
- ??適用場景??:少量靜態數據(如單頁文字、表格)。
- ??缺點??:效率低,無法自動化。
2. ??瀏覽器開發者工具(DevTools)??
- ??步驟??:
- 右鍵網頁 → 選擇“檢查”(或按?
F12/Ctrl+Shift+I)。 - 在?
Elements?標簽頁查看HTML結構,手動復制所需內容。 - 在?
Network?標簽頁分析API請求(適用于動態加載數據)。
- 右鍵網頁 → 選擇“檢查”(或按?
- ??適用場景??:快速查看網頁結構或API接口。
二、編程抓取(自動化)??
1. ??使用 Python 的?requests?+?BeautifulSoup(靜態頁面)?

?
2. ??動態頁面抓取(如JavaScript渲染)??
- ??工具??:
Selenium?或?Playwright(模擬瀏覽器操作)。

3. ??通過API直接獲取數據??
- 許多網站(如Twitter、電商平臺)通過API返回JSON數據。

三、進階技巧??
-
??處理反爬機制??:
- 設置請求頭(如?
User-Agent、Referer)。 - 使用代理IP(如?
requests.get(proxies={"http": "ip:port"}))。 - 添加延遲(如?
time.sleep(2))。
- 設置請求頭(如?
-
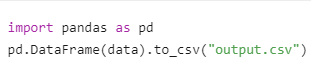
??數據存儲??:
- 保存為CSV/Excel:
-
- 存入數據庫(如MySQL、MongoDB)。
-
??框架推薦??:
- ??Scrapy??:高性能爬蟲框架,適合大規模抓取。
- ??PyQuery??:類似jQuery的HTML解析庫。
??四、注意事項??
-
??合法性??:
- 檢查目標網站的?
robots.txt(如?https://example.com/robots.txt)。 - 避免高頻請求(可能被封IP)。
- 檢查目標網站的?
-
??道德約束??:
- 不抓取個人隱私或付費內容。
- 遵守網站的服務條款。
??五、完整示例(豆瓣電影Top250)?

通過以上方法,你可以靈活應對不同場景的網頁抓取需求。如需更復雜的功能(如登錄、驗證碼識別),可結合OCR工具(如Tesseract)或自動化框架進一步擴展。
網絡爬蟲的應用場景和發展潛力遠超基礎的數據抓取,隨著技術進步和需求演變,其用途不斷擴展,未來還可能深度融合新興技術。以下是更廣泛的應用領域和未來趨勢分析:
??一、擴展應用場景??
1. ??垂直領域深度挖掘??
- ??醫療健康??
- 抓取醫學論文(PubMed)、藥品價格、臨床試驗數據,輔助疾病研究或藥物研發。
- ??農業與環境??
- 監測氣象數據、土壤報告、農產品市場價格,優化種植或供應鏈管理。
2. ??物聯網(IoT)與智慧城市??
- 爬取公共設施數據(如交通攝像頭、空氣質量傳感器),用于實時路況分析或污染預警。
3. ??區塊鏈與加密貨幣??
- 追蹤鏈上交易數據(如以太坊瀏覽器)、交易所動態,分析市場操縱或合規風險。
4. ??內容生成與AI訓練??
- ??自動化寫作??:抓取新聞生成摘要(如AI新聞聚合平臺)。
- ??多模態數據集??:收集圖像、視頻、音頻(如自動駕駛訓練需爬取街景圖片)。
5. ??反欺詐與安全??
- ??暗網監控??:爬取暗網論壇數據,追蹤數據泄露或犯罪交易(需合法授權)。
- ??虛假廣告檢測??:識別跨平臺的詐騙廣告模式。
6. ??教育與文化保護??
- ??古籍數字化??:自動抓取圖書館電子資源,構建文化遺產數據庫。
- ??慕課(MOOC)聚合??:整合多平臺課程資源供學習者檢索。
??二、未來發展趨勢??
1. ??技術融合與智能化??
- ??AI驅動的爬蟲??
- 結合NLP理解網頁語義,自動識別關鍵內容(如區分新聞正文與廣告)。
- 通過強化學習優化抓取路徑,避開反爬陷阱。
- ??低代碼/無代碼爬蟲??
- 工具如
Octoparse讓非技術人員也能快速配置爬取任務。
- 工具如
2. ??動態對抗升級??
- ??反爬技術進化??:網站可能采用更復雜的驗證(如行為指紋識別)。
- ??爬蟲的隱蔽性提升??:模擬人類操作(鼠標移動、滾動)的“無頭瀏覽器”將成為標配。
3. ??倫理與法規完善??
- ??GDPR/《數據安全法》合規??:爬蟲需明確數據來源授權,隱私保護技術(如差分隱私)可能被強制要求。
- ??數據確權??:區塊鏈可能用于記錄數據抓取鏈,確保可追溯性。
4. ??邊緣計算與分布式爬取??
- 利用邊緣節點(如CDN)分散請求,降低IP封鎖風險,同時提升抓取速度。
5. ??多模態數據融合??
- 從純文本轉向抓取并關聯視頻、語音、傳感器數據,構建更全面的分析模型(如輿情分析結合表情和語調)。
6. ??Web3.0與去中心化網絡??
- 爬蟲可能適配IPFS(星際文件系統)等去中心化存儲,抓取動態分布式內容。
??三、潛在挑戰與風險??
- ??法律灰色地帶??
- 不同國家對數據抓取的合法性界定不一(如美國“HiQ v. LinkedIn”案允許抓取公開數據,但歐盟更嚴格)。
- ??技術成本增加??
- 反爬措施(如Cloudflare的5秒盾)可能迫使企業投入更多資源破解。
- ??數據質量焦慮??
- 虛假信息泛濫(如AI生成內容)可能導致爬取數據可信度下降。
??四、總結??
網絡爬蟲的未來將呈現??“技術深度化、場景多元化、合規嚴格化”??三大特征。其核心價值在于??將無序的網絡信息轉化為結構化知識??,而隨著AI、物聯網、Web3.0的發展,爬蟲可能成為連接物理世界與數字世界的“神經末梢”。但能否持續發展,取決于如何在技術創新、商業需求與倫理法規之間找到平衡點。



)







![前端沒有“秦始皇“,但可以做跨端的王[特殊字符]](http://pic.xiahunao.cn/前端沒有“秦始皇“,但可以做跨端的王[特殊字符])
)






--gonet網絡框架重構+聚集發包)