引言
在計算機科學中,排序算法是最基礎且重要的算法之一。快速排序(Quick Sort)作為一種高效的排序算法,在實際應用中被廣泛使用。平均時間復雜度為?(O(n log n)),最壞情況下為?(O(n^2))。本文將詳細介紹快速排序算法的原理,結合具體代碼進行分析,給出兩種遞歸方法與一種非遞歸方法,并給出兩種優化方案。
快速排序原理
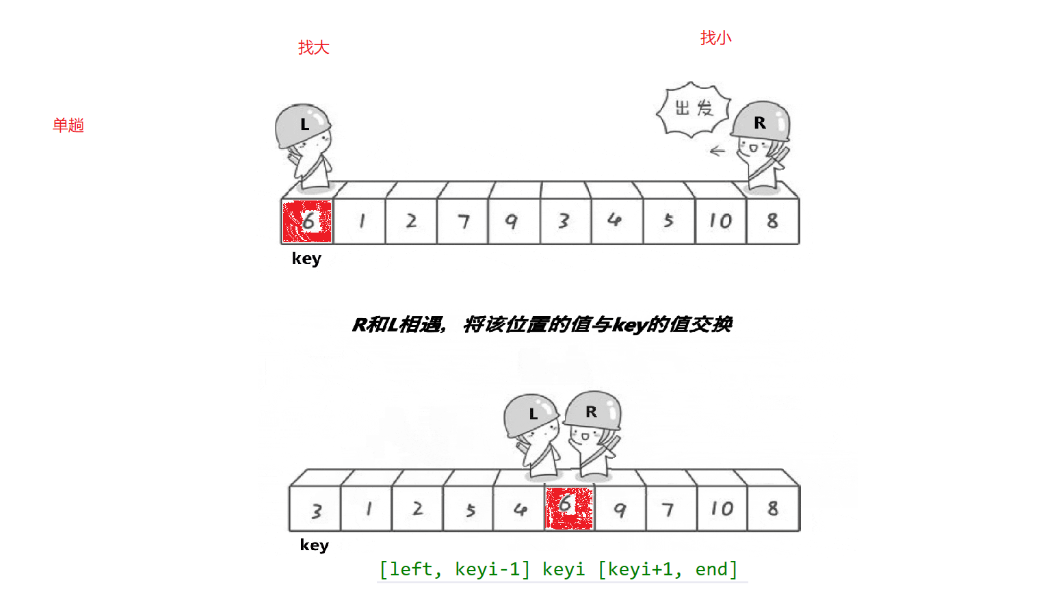
快速排序的基本思想是通過選擇一個基準元素(key),將數組分為兩部分,使得左邊部分的所有元素都小于等于基準元素,右邊部分的所有元素都大于等于基準元素。然后遞歸地對左右兩部分進行排序,最終得到一個有序的數組。
具體步驟如下:
- 選擇基準元素:從數組中選擇一個元素作為基準元素。
- 分區操作:將數組中的元素重新排列,使得所有小于等于基準元素的元素都在基準元素的左邊,所有大于等于基準元素的元素都在基準元素的右邊。這個過程稱為分區(partition)。
- 遞歸排序:對左右兩部分分別遞歸地應用快速排序算法。
代碼實現
1.hoare法(遞歸)
/交換
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}//快速排序
void QuickSort(int* a, int left, int right)
{if(left >= right)return;int key = left;int begin = left, end = right;while(begin < end){while(begin < end && a[end] > a[key]){end--;}while(begin < end && a[begin] <= a[key]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[key], &a[begin]);key = begin;QuickSort(a, left, key - 1);QuickSort(a, key + 1, right);}
}?2.雙指針法(遞歸)
//快排遞歸:雙指針
int PartSort2(int* a, int left, int right)
{//三數取中(優化)int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);int key = left;int prev = left;int cur = prev + 1;while(cur <= right){if(a[cur] < a[key] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[prev], &a[key]);return prev;
}
//快速排序(遞歸)
void QuickSort(int* a, int left, int right)
{if(left >= right)return;//小區間優化if((right - left + 1) < 10){InsertSort(a + left, right - left + 1);}else{// int key = PartSort1(a, left, right);int key = PartSort2(a, left, right);QuickSort(a, left, key - 1);QuickSort(a, key + 1, right);}
}代碼解釋:
Swap?函數:用于交換兩個整數的值。QuickSort?函數:- 遞歸終止條件:當?
left >= right?時,說明數組已經有序,直接返回。 - 分區操作:使用雙指針法將數組分為兩部分,左邊部分的元素都小于等于基準元素,右邊部分的元素都大于等于基準元素。
- 遞歸排序:對左右兩部分分別遞歸地調用?
QuickSort?函數。
- 遞歸終止條件:當?
3.非遞歸法
遞歸方法來實現排序終歸有棧溢出的風險,所以這里提供一種非遞歸方式實現快速排序。
先給定棧的實現
//Stack.h
#pragma once#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#include <assert.h>typedef int STDataType;typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;//初始化與銷毀
void STInit(ST* pst);
void STDestory(ST* pst);//入棧 出棧
void STPush(ST* pst, STDataType x);
void STPop(ST* pst);//取棧頂數據
STDataType STTop(ST* pst);//判空
bool STEmpty(ST* pst);//獲取數據的個數
int STSize(ST* pst);//Stack.c
#include "Stack.h"//初始化與銷毀
void STInit(ST* pst)
{assert(pst);pst->a = NULL;pst->top = 0;pst->capacity = 0;
}
void STDestory(ST* pst)
{assert(pst);free(pst->a);pst->a = NULL;pst->top = pst->capacity = 0;
}//入棧 出棧
void STPush(ST* pst, STDataType x)
{assert(pst);//擴容if(pst->top == pst->capacity){int newcapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;STDataType* tmp = (STDataType*)realloc(pst->a, newcapacity* sizeof(STDataType));if(tmp == NULL){perror("realloc fail");exit(1);}pst->a = tmp;pst->capacity = newcapacity;} //入棧pst->a[pst->top] = x;pst->top++;}
void STPop(ST* pst)
{assert(pst);assert(pst->top > 0);pst->top--;
}//取棧頂數據
STDataType STTop(ST* pst)
{assert(pst);assert(pst->top > 0);return pst->a[pst->top - 1];
}//判空
bool STEmpty(ST* pst)
{assert(pst);return pst->top == 0;
}//獲取數據的個數
int STSize(ST* pst)
{assert(pst);return pst->top;
}?運用棧來實現非遞歸快排:
//快速排序(非遞歸)
void QuickSortNonR(int* a, int left, int right)
{ST st;STInit(&st);STPush(&st, right);STPush(&st, left);while(!STEmpty(&st)){int begin = STTop(&st);STPop(&st);int end = STTop(&st);STPop(&st);int key = PartSort2(a, begin, end);if(end > key + 1){STPush(&st, end);STPush(&st, key + 1);}if(begin < key - 1){STPush(&st, key - 1);STPush(&st, begin);}}STDestory(&st);
}這里使用棧來存儲指針begin與end?,棧在堆中存儲,能通過malloc不斷申請內存空間,有效規避了棧溢出的風險。
測試代碼
下面對快速排序做一個簡單的測試:
void TestOP()
{srand((unsigned int)time(NULL));const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);for(int i = 0; i < N; i++){a1[i] = rand();}int begin1 = clock();// 此處可調用 QuickSort 進行測試QuickSort(a1, 0, N - 1);int end1 = clock();printf("QuickSort:%d\n", end1 - begin1);
}int main()
{TestOP();return 0;
}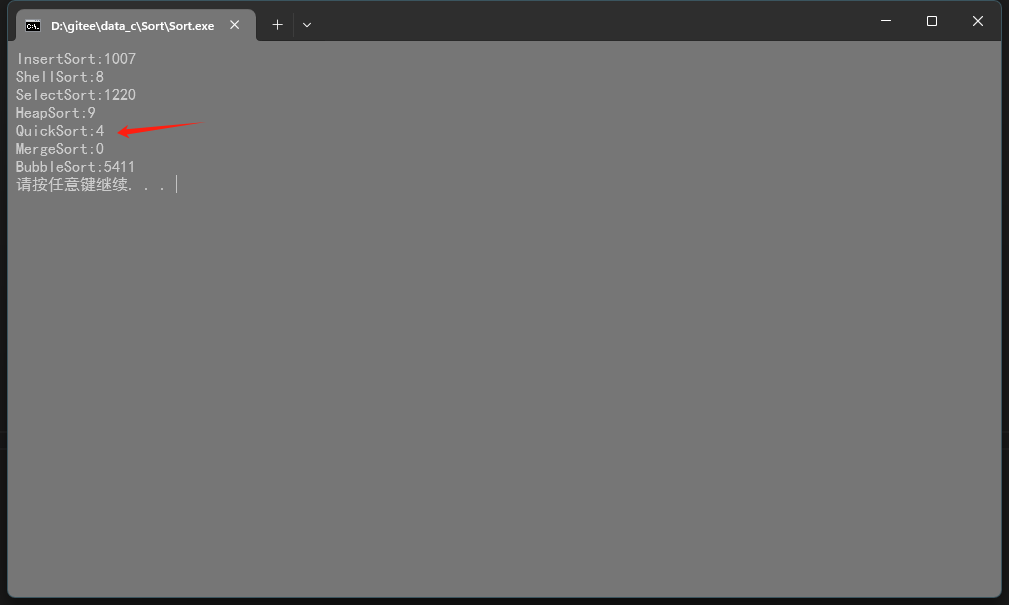 在這個測試文件中,我們生成了一個包含 100000 個隨機整數的數組,并調用?
在這個測試文件中,我們生成了一個包含 100000 個隨機整數的數組,并調用?QuickSort?函數對其進行排序,最后輸出排序所需的時間。
復雜度分析
- 時間復雜度:平均情況下為?(O(n log n)),最壞情況下為?(O(n^2))。
- 空間復雜度:遞歸調用棧的深度為?(O(log n)),因此空間復雜度為?(O(log n))。
優化方案?
1.三數取中
若數組排序前就有序,時間復雜度為O(n^2),那么此時三數取中就是消除這種接近有序帶來的大量重復計算的優化方法
代碼實現
//三數取中
int GetMid(int* a, int left, int right)
{int mid = (left + right) / 2;// left midi rightif (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[left] < a[right]){return right;}else{return left;}}else // a[left] > a[mid]{if (a[mid] > a[right]){return mid;}else if (a[left] < a[right]){return left;}else{return right;}}
}緊接著再把返回的mid值與left處值交換即可
//三數取中(優化)int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);
2.小區間優化
我們通過前面所學內容可以得知快排的遞歸是類似與二叉樹遞歸的一種算法,那么高度越高所消耗的空間越大,每個遞歸函數的調用會建立一個函數棧幀,為了避免出現棧溢出的情況,我們可以采取小區間優化來規避風險并高效實現排序。
代碼實現
(可任選一種時間復雜度為O(n^2)的排序,這里選擇更為高效的插入排序。)
//插入排序 最好O(N) 最壞O(N ^ 2)
void InsertSort(int* a, int n)
{for(int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while(end >= 0){if(tmp < a[end]){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}//小區間優化if((right - left + 1) < 10){InsertSort(a + left, right - left + 1);}3.其他
除了這些優化方案,可能有人會覺得快速排序難以理解,這里還有一種較為通俗的挖坑法(并沒有改變排序效率,只是更為通俗易懂),可以自行查閱資料。
總結
快速排序是一種高效的排序算法,通過分治法和分區操作,將數組不斷地分為兩部分進行排序。在實際應用中,通過三數取中和小區間優化,可以提高算法的性能。希望本文對你理解快速排序算法有所幫助。
)












)

)



