目錄
1、Memory引擎介紹
2、Memory內存結構
3、內存表的鎖
4、持久化
5、優缺點
6、應用
前言
????????Memory 存儲引擎?是 MySQL 中一種高性能但非持久化的存儲方案,適合臨時數據存儲和緩存場景。其核心優勢在于極快的讀寫速度,需注意數據丟失風險和內存占用限制。
????????在使用時需結合業務需求,合理配置參數(如?max_heap_table_size),并避免將其用于需要持久化或事務支持的場景。
1、Memory引擎介紹
????????MySQL Memory引擎用于創建內存中的表,數據存儲在內存,訪問快速但重啟后數據丟失。通過--init-file啟動mysqld可持久化數據。
????????內存表默認使用hash索引,適用于臨時表,但有限制如不支持BLOB/TEXT,且所有用戶可見。可以利用其速度優勢創建內存臨時表替代MyISAM臨時表。
- 數據完全存儲在內存中:
- 數據和索引均存在于內存中,無磁盤 I/O 開銷。
- 重啟 MySQL 或異常關閉后,數據會丟失。
- 存儲限制:
- 受?
max_heap_table_size?和?tmp_table_size?參數限制。 - 不支持大字段(如?
TEXT、BLOB)。
- 受?
- 存儲結構:
- 僅支持哈希索引,適合等值查詢(
=),不支持范圍查詢(>、<、BETWEEN)。
- 僅支持哈希索引,適合等值查詢(
- 不支持事務
2、Memory內存結構
????僅支持哈希索引,數據存放將索引和數據分開存儲。
????????索引采用Hash的形式,存放主鍵id和指向數據的指針,而數據則按插入順序存放。稱這種數據組織方式為堆組織方式。
如下圖所示:
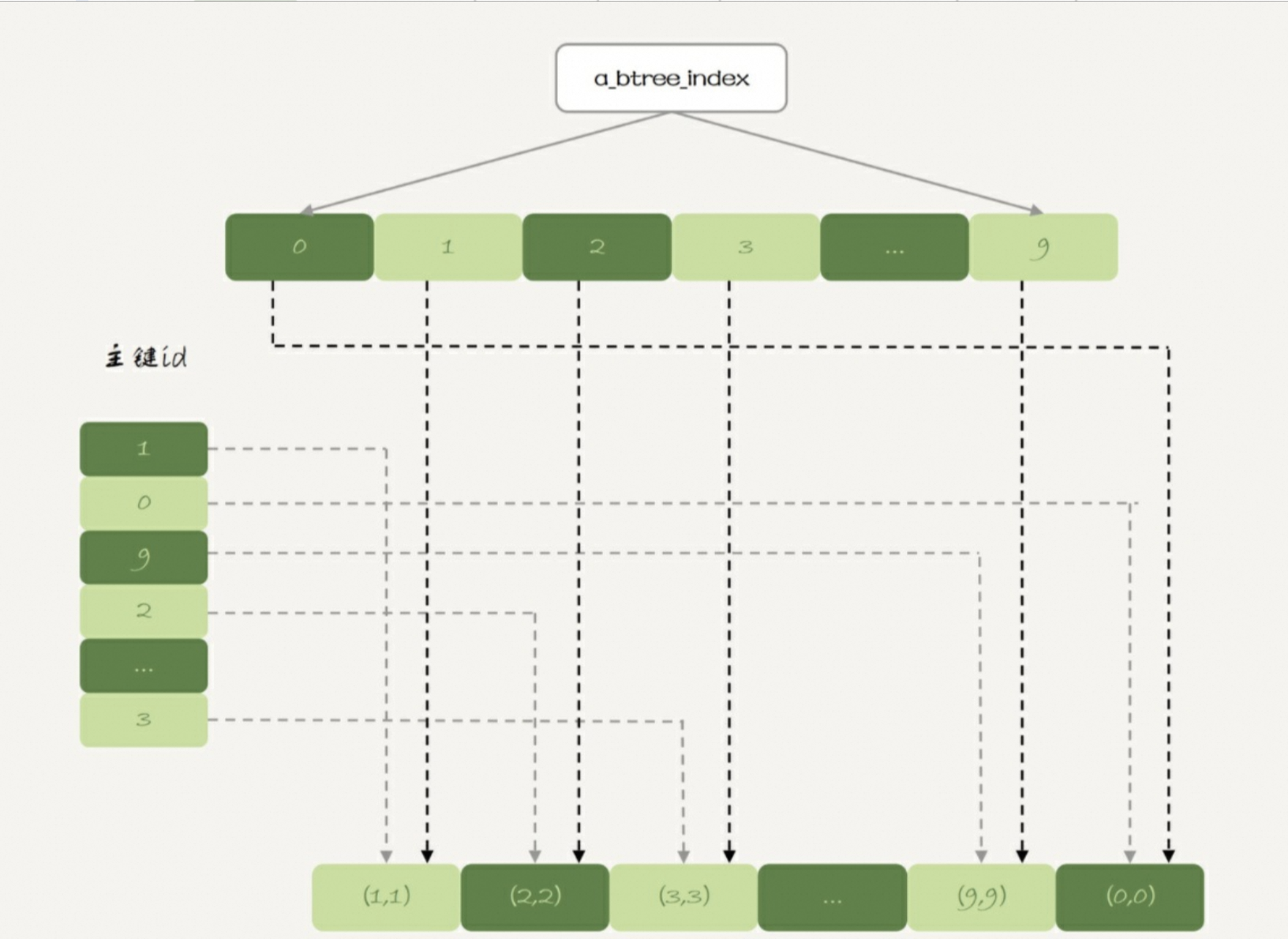
特點:且數據的hash的key也不支持有序,value也沒指定的順序。
3、內存表的鎖
????????內存表不支持行鎖,只支持表鎖。如果一張表有更新,就會堵住其它所有在這個表上的讀寫操作。導致了Memory存儲引擎在進行并發操作時會造成大量的阻塞,效率不高。
示例:

????????在這個執行序列里, session A的update語句要執行50秒, 在這個語句執行期間session B的查詢會進入鎖等待狀態。 session C的show processlist 結果輸出如下:

????????跟行鎖比起來, 表鎖對并發訪問的支持不夠好。?
4、持久化
如果數據庫重啟,所有的內存表都會被清空。
在主備場景:
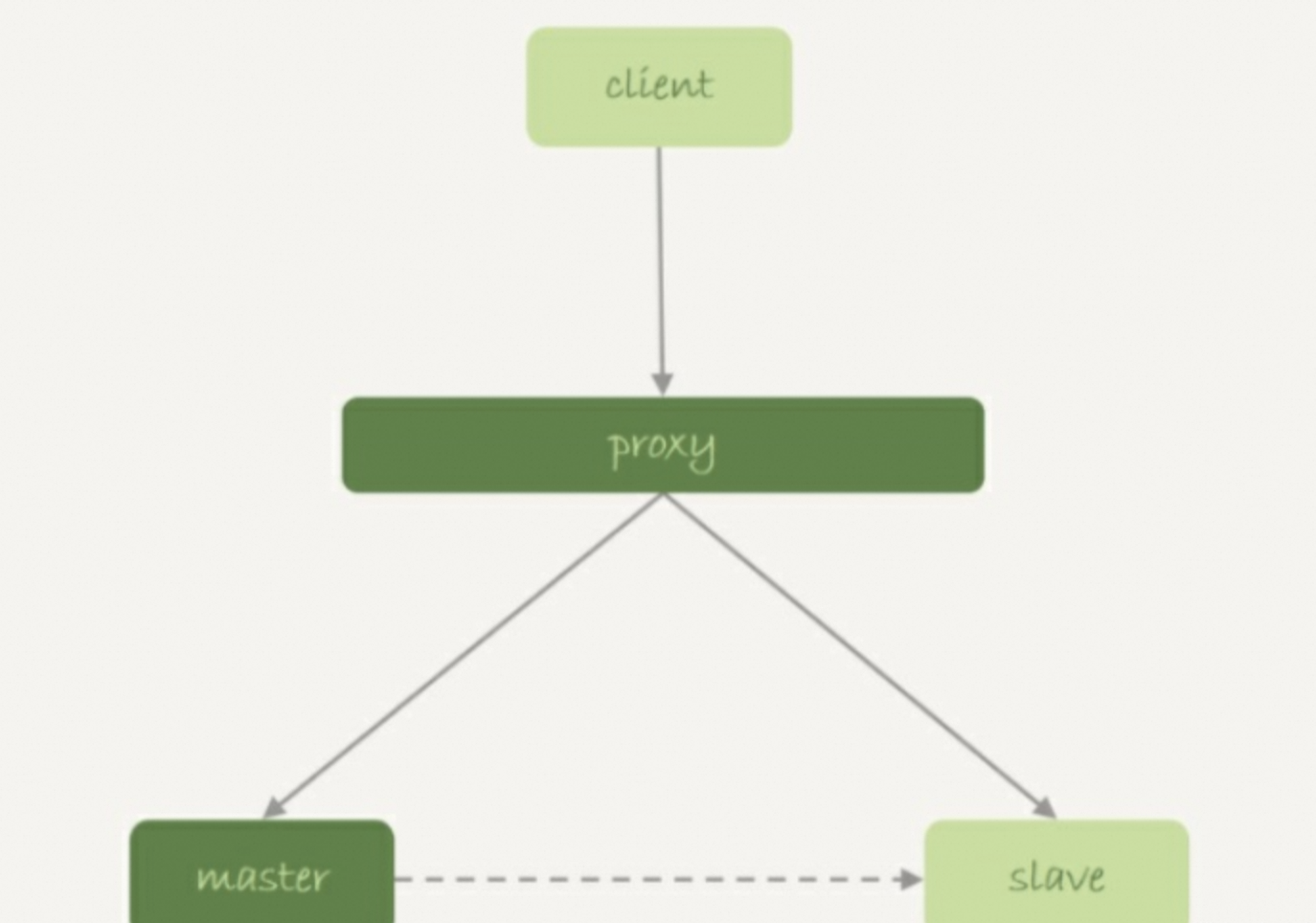
看一下下面這個時序:
- 業務正常訪問主庫。
- 備庫硬件升級, 備庫重啟, 內存表t1內容被清空。
- 備庫重啟后, 客戶端發送一條update語句, 修改表t1的數據行, 這時備庫應用線程就會報錯“找不到要更新的行”。
??注意:內存表可能導致主備不一致。
?解決方案:
????????所以, 擔心主庫重啟之后, 出現主備不一致, MySQL在實現上做了這樣一件事兒: 在數據庫重啟之后, 往binlog里面寫入一行DELETE FROM t1。
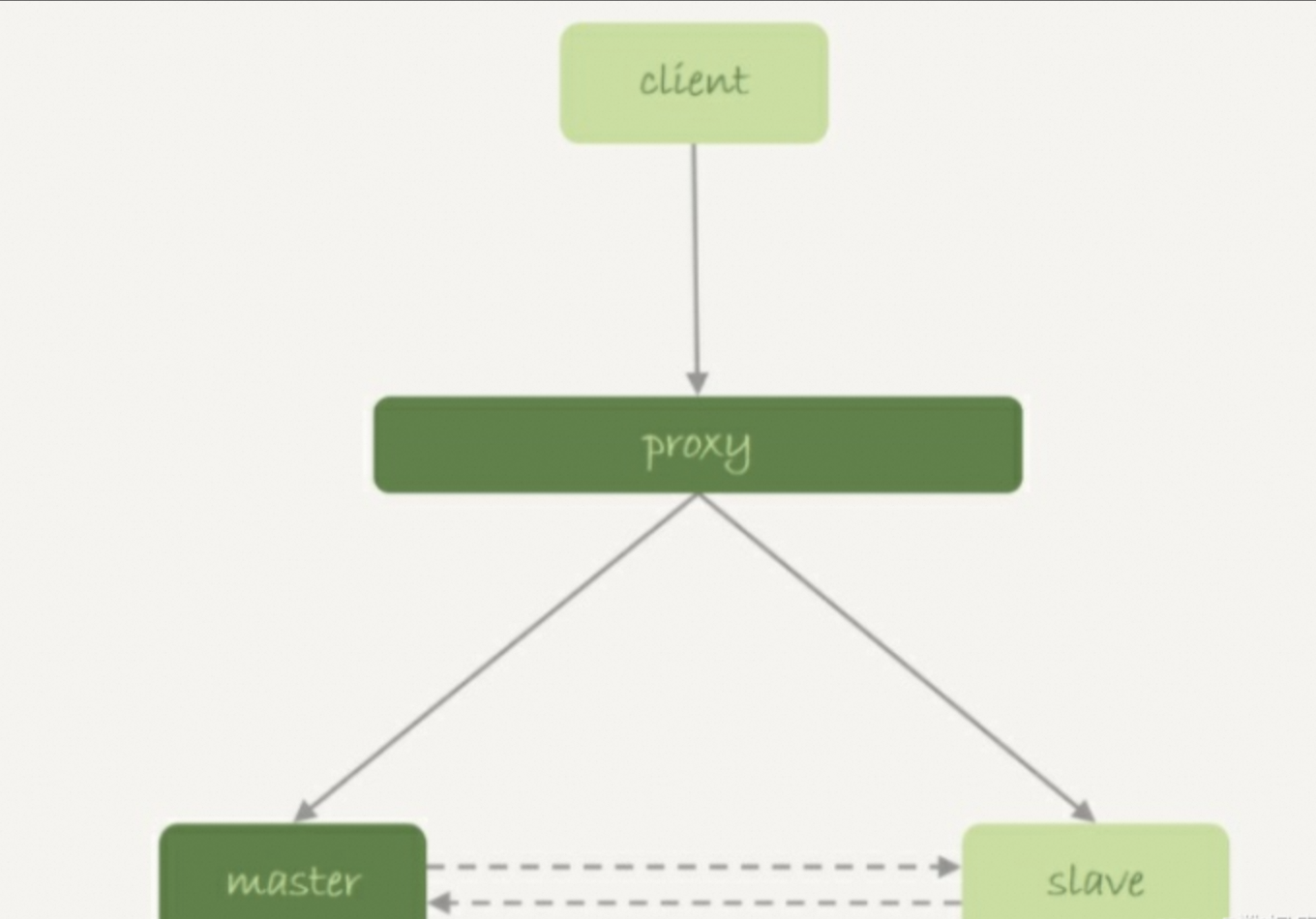
????????在備庫重啟的時候, 備庫binlog里的delete語句就會傳到主庫, 然后把主庫內存表的內容刪除。這樣使用的時候就會發現, 主庫的內存表數據突然被清空了。
無論是M-S架構,還是雙M架構,內存表都不適合在生產環境上作為普通數據表使用。
5、優缺點

6、應用
設置:
set sql_log_bin=off;
alter table tbl_name engine=innodb;假設有以下兩張表t1、t2,其中表t1是Memory引擎,表t2是InnoDB引擎。
-- 創建表t1,t2,分別使用Memory引擎和InnoDB引擎;
create table t1(id int primary key,c int) engine=Memory;
create table t2(id int primary key,c int) engine=innodb;
insert into t1values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);
insert into t2values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);-- 執行查詢語句,得到結果如下圖:
select * from t1;
select * from t2;結果如下:
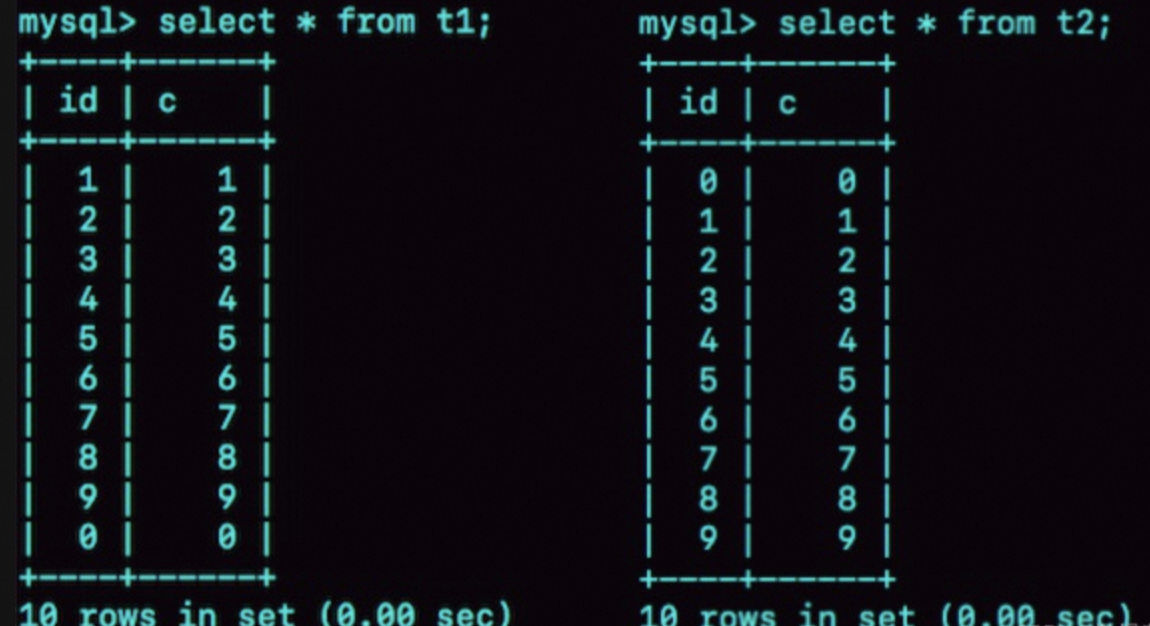
內存表t1的返回結果里面0在最后一行, 而InnoDB表t2的返回結果里0在第一行。
????????表t1是Memory表,而Memory表的數據和索引是分開的。
數據組織方式如下:
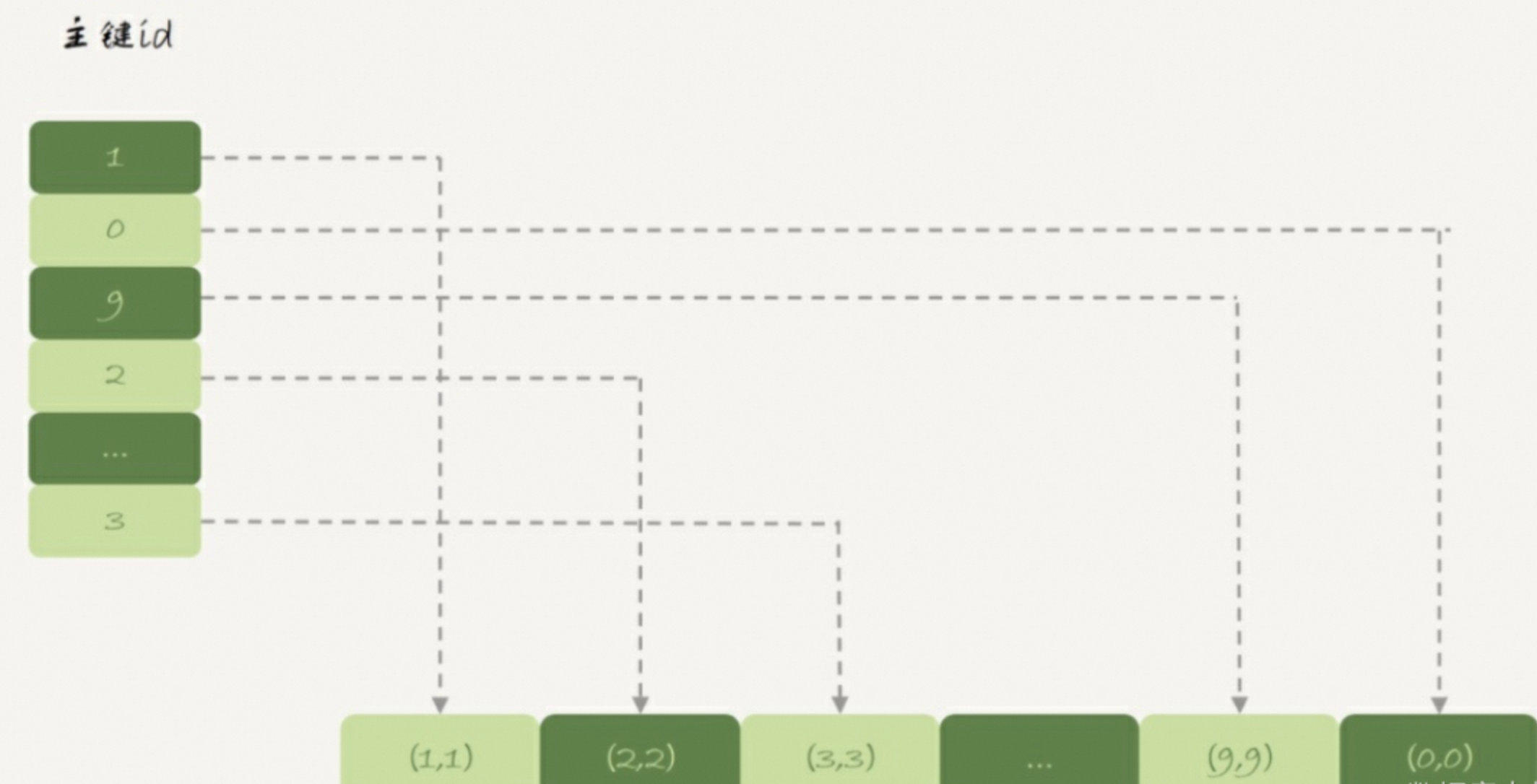
????????由上可知,內存表的數據部分以數組的方式單獨存放,而主鍵id索引里,存的是每個數據的位置。主鍵id是hash索引,可以看到索引上的key并不是有序的。
????????在對表t1執行select *的時候, 走的是全表掃描, 也就是順序掃描這個數組。 因此, 0就是最后一個被讀到, 并放入結果集的數據。
????????表t2是InnoDB表,其數據就放在主鍵索引樹上,主鍵索引是B+樹。
數據組織方式如下:
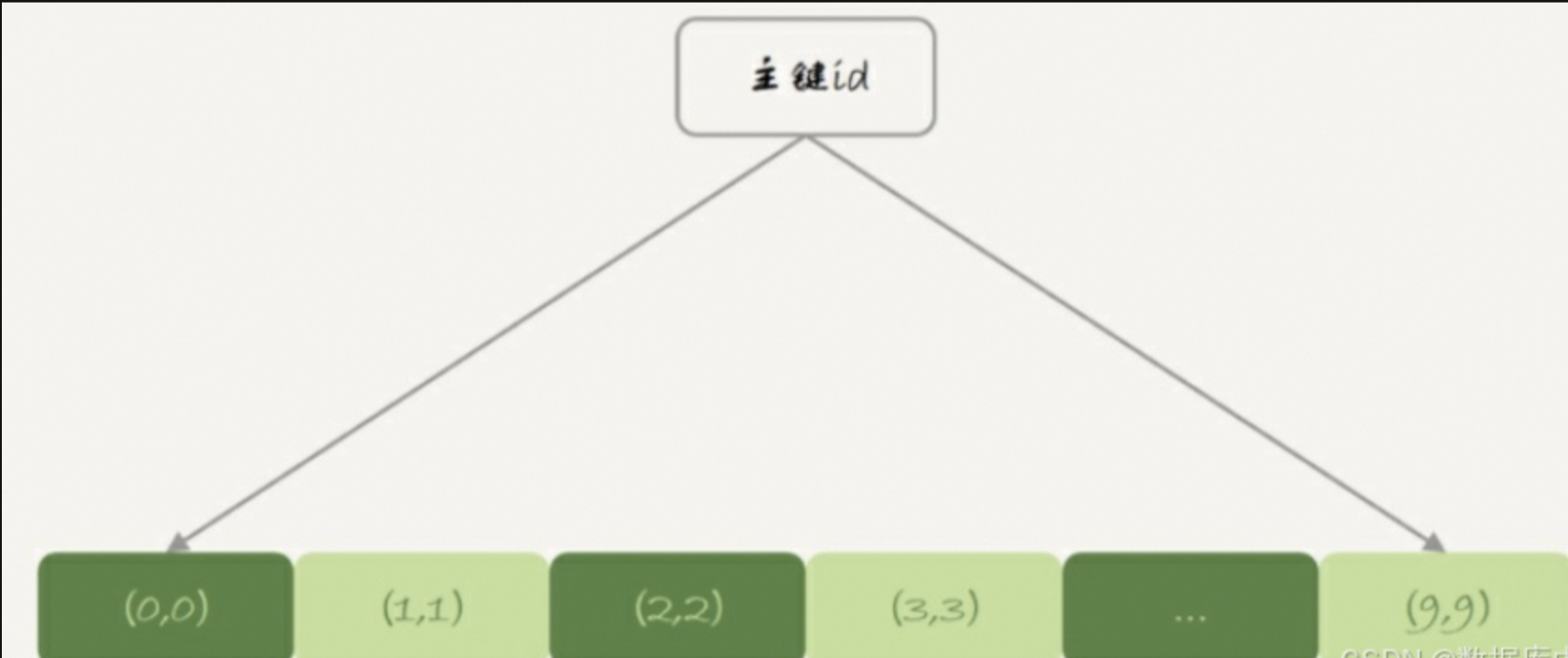
????????主鍵索引上的值是有序存儲的,在執行select *的時候, 就會按照葉子節點從左到右掃描, 所以得到的結果里, 0就出現在第一行。
關于三種不同引擎的總結

參考文章:
1、MySQL查詢執行(八):Memory引擎_mysql memory引擎-CSDN博客














)


:構建企業級可觀測性與安全的基石)

