source: https://archive.fosdem.org/2020/schedule/event/replacing_iptables_with_ebpf/attachments/slides/3622/export/events/attachments/replacing_iptables_with_ebpf/slides/3622/Cilium_FOSDEM_2020.pdf
使用Cilium,結合eBPF、Envoy、Istio和Hubble等技術,實現更高效、更安全的網絡策略。那么,問題來了:為什么我們需要替換掉iptables呢?它到底哪里出了問題?傳統的iptables確實存在不少痛點。
- 它必須通過重建整個規則鏈的方式來更新規則,這在高負載場景下效率極低。
- 它本質上是鏈表結構,所有操作都是O n復雜度,這意味著規則越多,性能越差。實現訪問控制列表ACL時,它通常采用順序列表,這在面對大規模變更時非常脆弱。
- 它只基于IP和端口進行匹配,完全不理解L7層協議,無法進行精細化的策略控制。每次添加新的IP或端口,都需要重新構建整個鏈表,這在Kubernetes這種動態環境中簡直是災難。結果就是資源消耗巨大,尤其是在服務數量增加時,延遲變得不可預測,性能急劇下降。
實測數據也顯示,隨著服務數量增長,性能和延遲都會顯著惡化。Kubernetes本身對iptables的依賴程度相當高。最核心的就是kube-proxy,它通過DNAT規則來實現Service和負載均衡。此外,很多CNI插件,特別是那些用于網絡策略的,也都在底層使用了iptables。這使得整個Kubernetes的網絡模型在面對復雜性時,顯得越來越力不從心。
那么,什么是BPF?它是一種強大的內核技術,允許我們編寫安全的、可執行的代碼,直接注入到內核的特定鉤點上,而無需修改內核源碼。這個過程是這樣的:開發者編寫代碼,通過LLVM和Clang編譯成字節碼,然后經過驗證器和即時編譯器的處理,最終生成匯編指令,注入到內核的網絡棧等特定位置。這樣,我們就能在內核層面高效地執行自定義邏輯,比如過濾、監控、負載均衡等等。Linux內核網絡棧非常復雜,經歷了多年的發展和演化,形成了多層抽象。從應用程序到硬件,層層遞進,每層都有其特定的功能。這種分層設計帶來了巨大的兼容性,但也意味著很難繞過這些層進行底層操作。
Netfilter模塊作為網絡過濾器,已經在Linux內核中存在了二十多年,它需要在數據包上下行穿越棧的過程中進行過濾。這種設計在早期很有效,但隨著網絡規模和復雜度的爆炸式增長,它的局限性就顯現出來了。BPF的強大之處在于,它可以在內核的多個關鍵點上插入鉤點,也就是所謂的BPF Hooks。
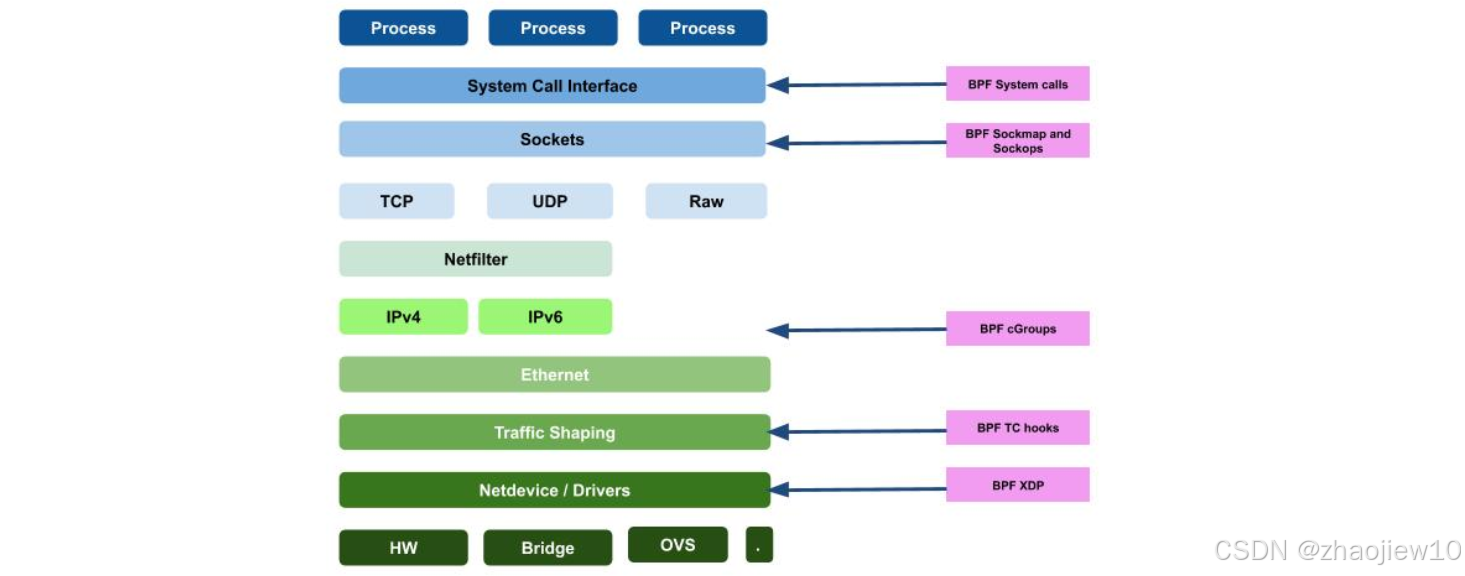
這張圖展示了BPF如何嵌入到Linux內核的各個層級。從用戶空間的進程,到系統調用接口,再到套接字層、Netfilter、IP層、以太網層,甚至底層的硬件驅動、橋接和OVS,BPF都能找到自己的位置。這意味著我們可以利用BPF來實現各種各樣的網絡功能,從流量控制、負載均衡到安全過濾,幾乎覆蓋了整個網絡棧。
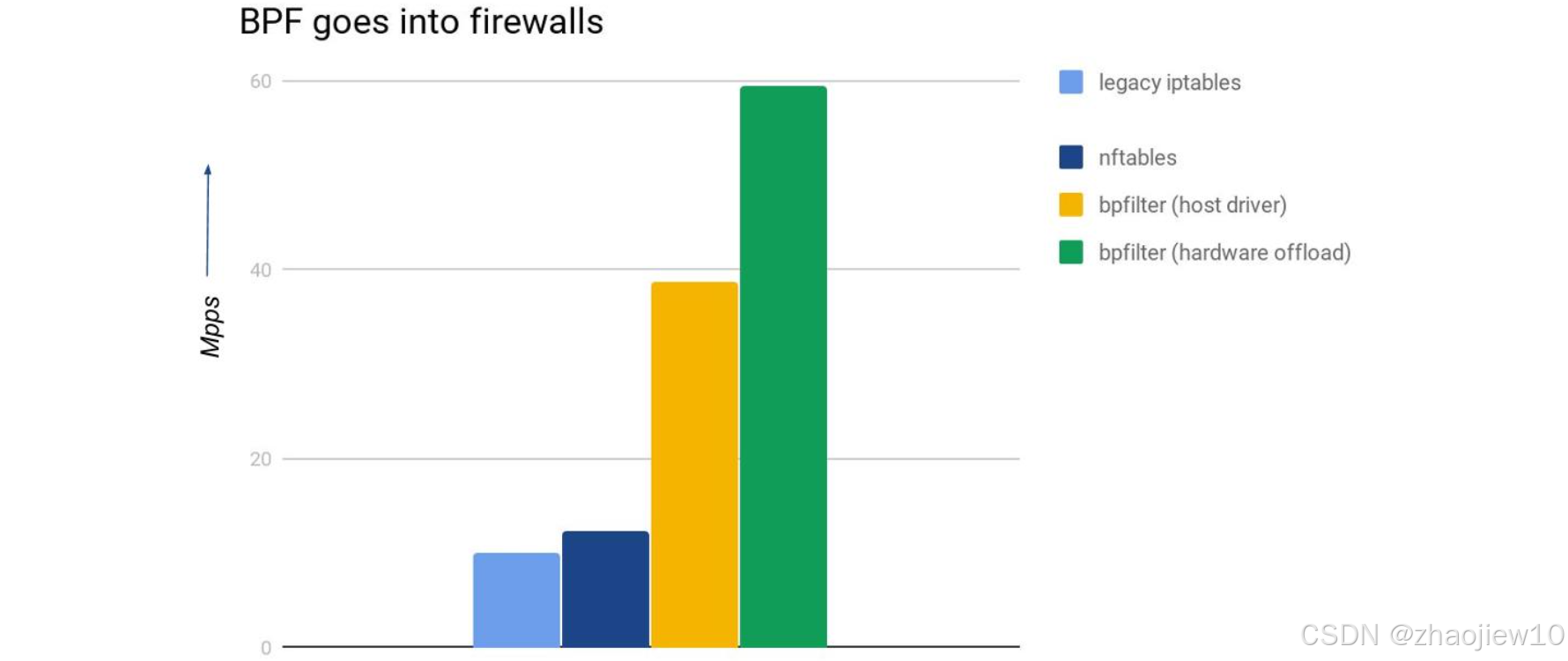
這張圖展示了不同網絡過濾技術的性能對比。橫軸是不同的技術,縱軸是每秒百萬包的處理能力。可以看到,基于硬件卸載的bpfiler性能達到了驚人的60Mpps,遠超其他技術。即使是純軟件驅動的bpfiler也有接近40Mpps。相比之下,傳統的legacy iptables和nftables性能則明顯落后。這直觀地說明了BPF在高性能網絡過濾方面的巨大優勢。
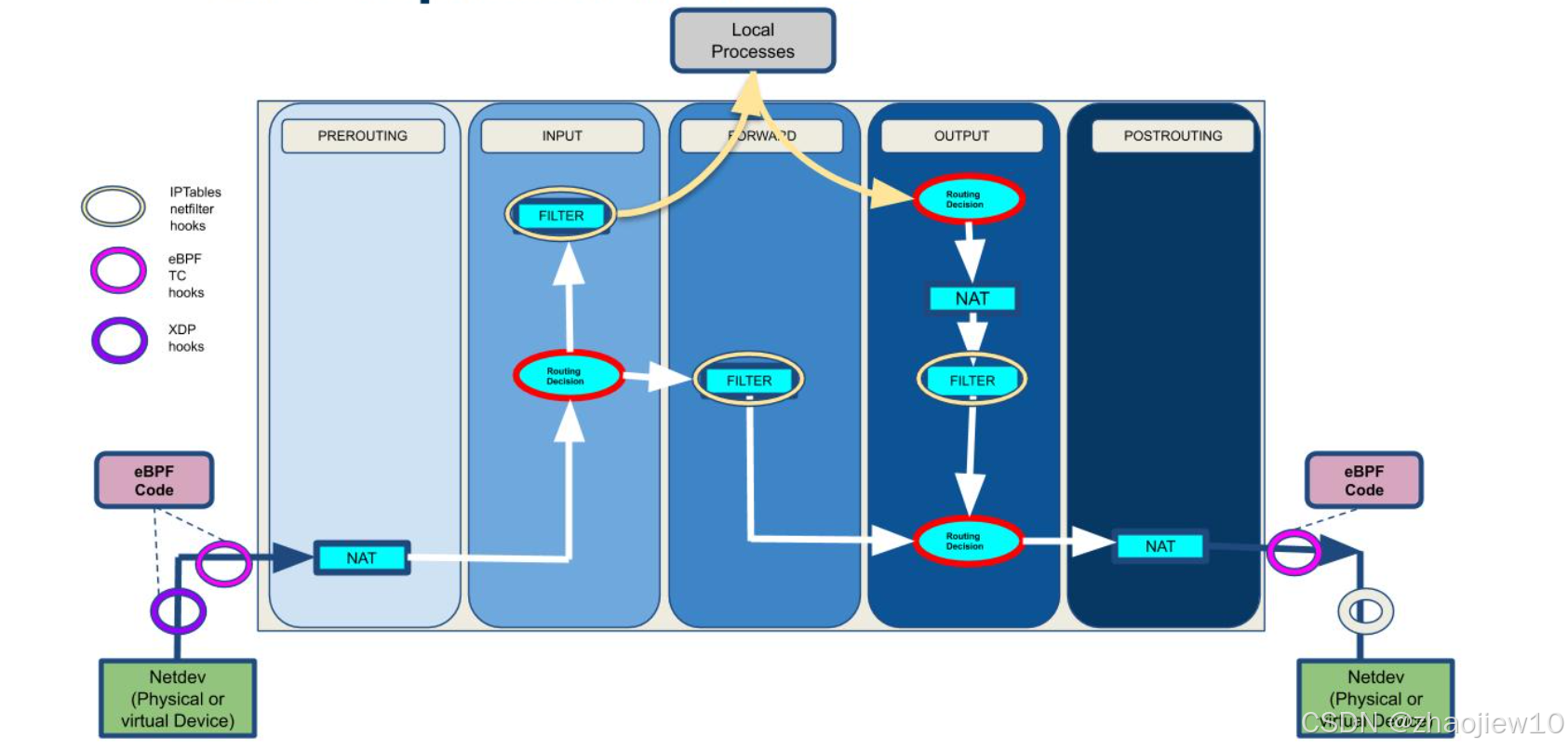
這張圖展示了BPF如何取代iptables。它清晰地展示了數據包在網絡棧中的五個主要階段:PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING。在每個階段,都可以看到eBPF和XDP的鉤點。這意味著我們可以利用BPF來實現更靈活、更高效的過濾、路由和NAT功能,而不再依賴于傳統的iptables規則鏈。BPF代碼可以直接在這些鉤點上運行,處理數據包,然后決定是繼續轉發還是丟棄。
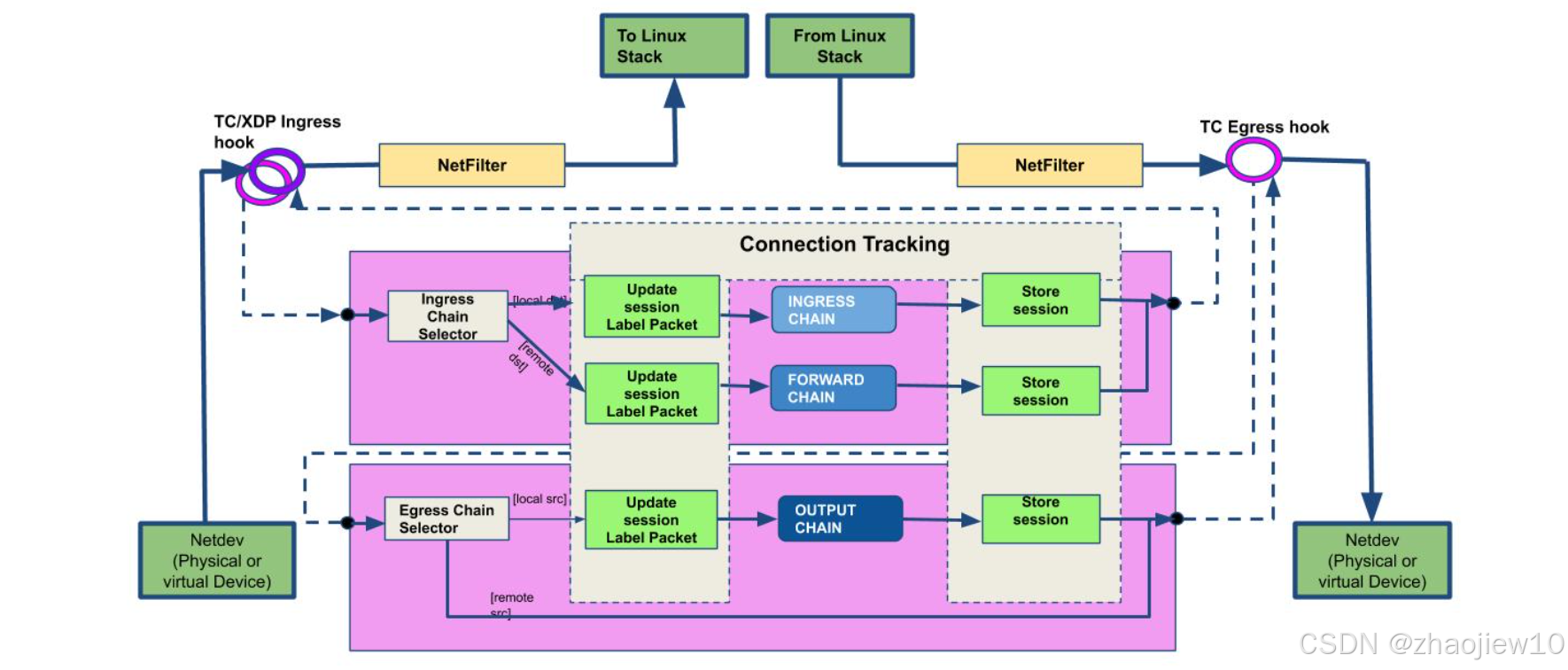
這張圖展示了基于BPF的過濾架構。它特別強調了連接跟蹤(Connection Tracking)的流程。
- 數據包從Linux棧進入,通過BPF的TC或XDP Ingress Hook,然后經過一個選擇器,根據源地址和目的地址選擇合適的鏈。
- 進入Ingress Chain,這里會更新會話標簽,并將會話信息存儲起來。
- 出站時,數據包也會通過Egress Hook,經過選擇器,進入Output Chain,更新標簽并存儲會話。
整個過程都是基于BPF的高效執行,而不是傳統的鏈表遍歷。
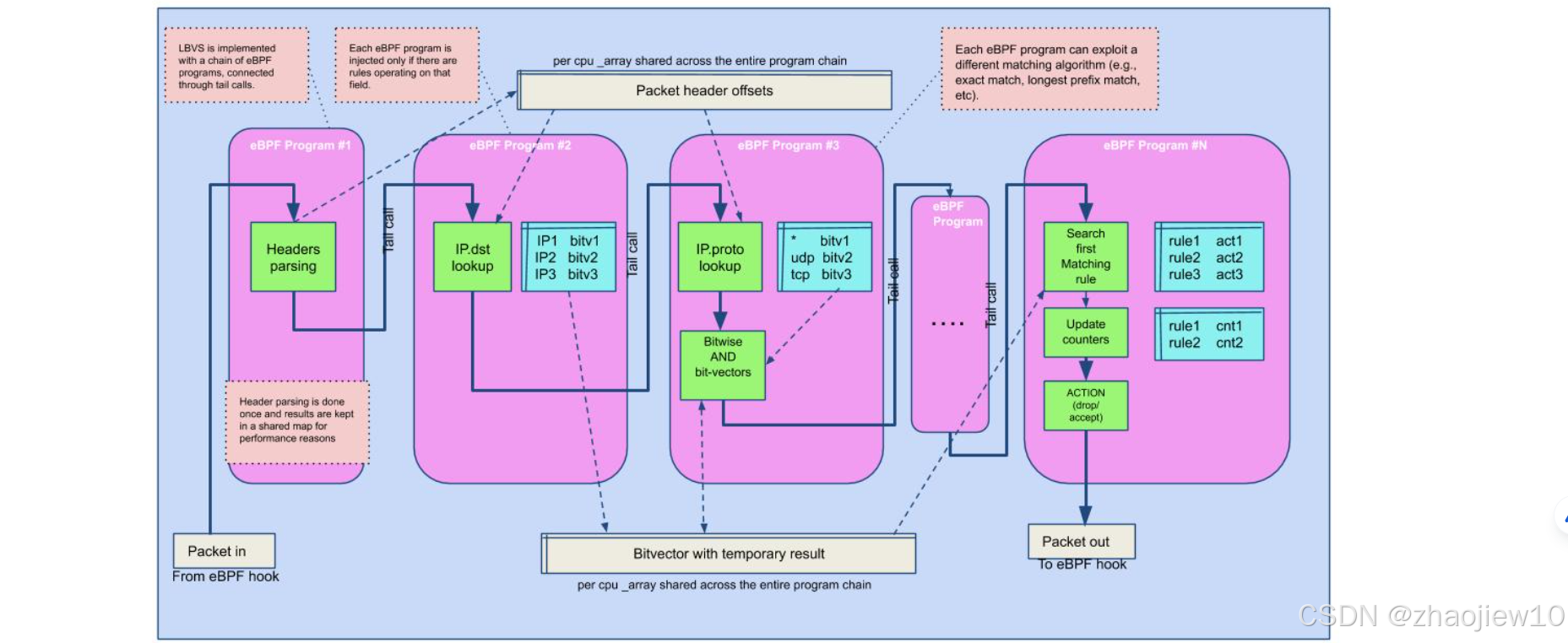
這張圖展示了BPF基于尾調用的機制。它展示了如何構建一個高效的程序鏈來處理網絡包。每個BPF程序只在需要執行相關操作時才被注入,它們通過尾調用(tail calls)連接起來,形成一個鏈式結構。這種機制避免了傳統的鏈表遍歷,極大地提高了性能。
圖中展示了多個程序,例如頭部解析、IP查找、協議查找等,它們共享一個全局的CPU數組,用于存儲中間結果,最終通過eBPF鉤子將結果傳遞出去。BPF的應用遠不止于防火墻。它已經滲透到各種關鍵的網絡組件中。比如
- 負載均衡器,像katran;
- 性能監控工具,像perf;
- 系統管理工具,像systemd;
- 入侵檢測系統,像Suricata;
- 虛擬交換機,像Open vSwitch的AF_XDP
可以說,BPF正在成為構建高性能、可擴展的網絡和系統工具的核心技術之一。BPF的應用場景非常廣泛,已經被眾多行業巨頭和開源項目采用。大家可以看到Facebook、SUSE、Google、Cloudflare、Cilium、Falco等公司的標志。這些公司在各自領域都面臨著巨大的挑戰,比如海量的流量、復雜的系統、嚴格的安全要求。BPF正是幫助他們解決這些挑戰的關鍵技術。它的靈活性和性能使其成為構建下一代云原生基礎設施的基石。
現在,讓我們聚焦到今天的主角:Cilium。它是一個基于eBPF的開源網絡項目,旨在為Kubernetes提供高性能、安全、可擴展的網絡解決方案。Cilium究竟是什么呢?它是一個網絡代理,但它的核心在于利用eBPF技術。
Cilium層包括CLI、策略庫、插件和監控器,由一個守護進程Cilium Daemon來協調。它通過字節碼注入的方式,將BPF程序直接嵌入到容器的網絡接口eth0中。這些BPF程序負責處理進出容器的數據包,實現網絡策略、安全檢查和性能優化。這與傳統的基于iptables的方案相比,完全是不同的范式。
CNI,即容器網絡接口,是CNCF的一個項目,它定義了容器網絡插件的規范和庫。CNI插件的主要職責是確保容器的網絡連通性。它通過ADD和DEL兩個核心操作來管理網絡接口。
- 對于ADD操作,容器運行時需要先為容器創建一個獨立的網絡命名空間,然后調用相應的CNI插件,為容器添加網絡接口,分配IP地址。
- 對于DEL操作,則是移除網絡接口,釋放IP地址。CNI的設計要求插件必須是冪等的,不能對同一個容器進行多次ADD操作,必須保證ADD操作最終會有一個對應的DEL操作。
Cilium作為CNI插件,遵循這些規范。
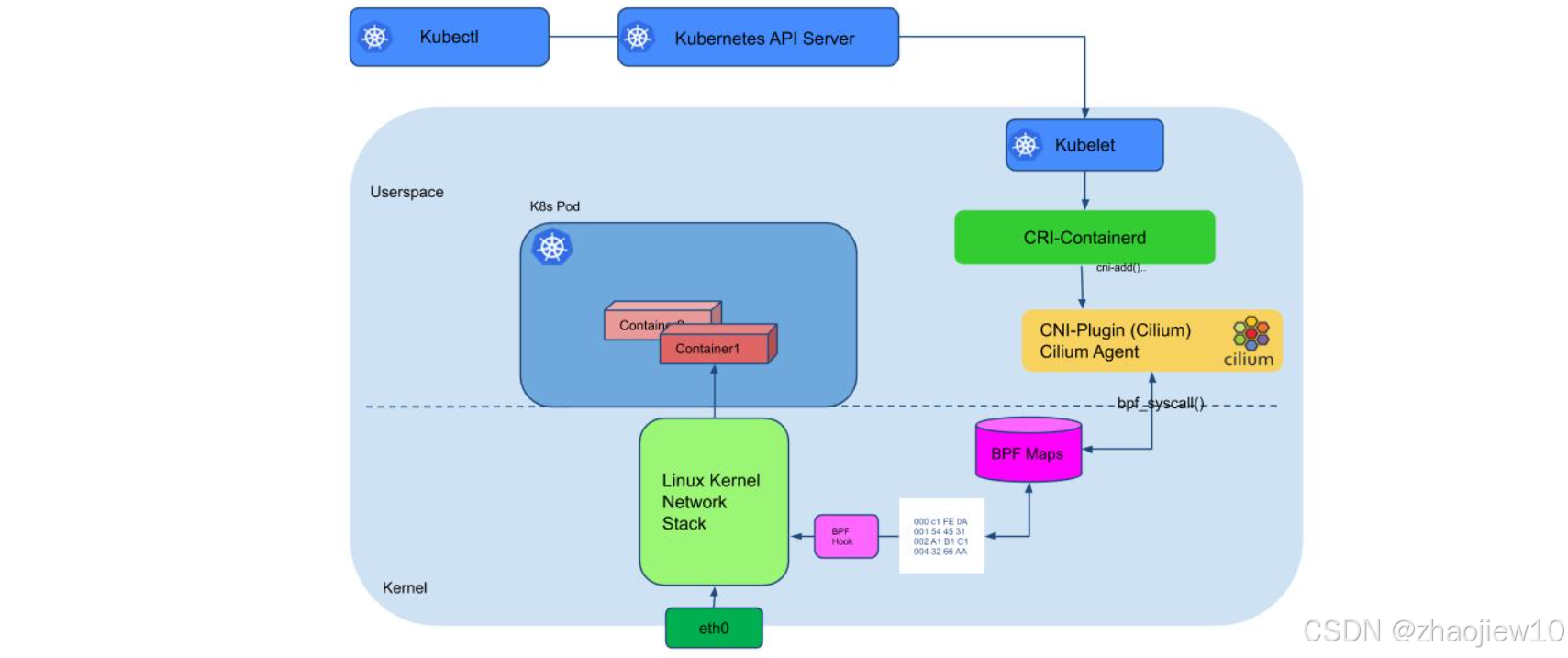
這張圖展示了Cilium作為CNI插件的控制流程。
- 當Kubernetes API Server收到Kubectl命令后,會通知Kubelet
- Kubelet再通過CRI接口與容器運行時Containerd交互。
- Containerd會調用CNI插件,這里是Cilium。
- Cilium Agent接收到請求后,會與Linux內核網絡棧進行交互,通過bpf syscall與BPF Maps通信。
- BPF Maps存儲著網絡相關的數據,比如MAC地址映射。
- BPF程序通過BPF Hook作用于eth0接口,實現網絡的配置和管理。
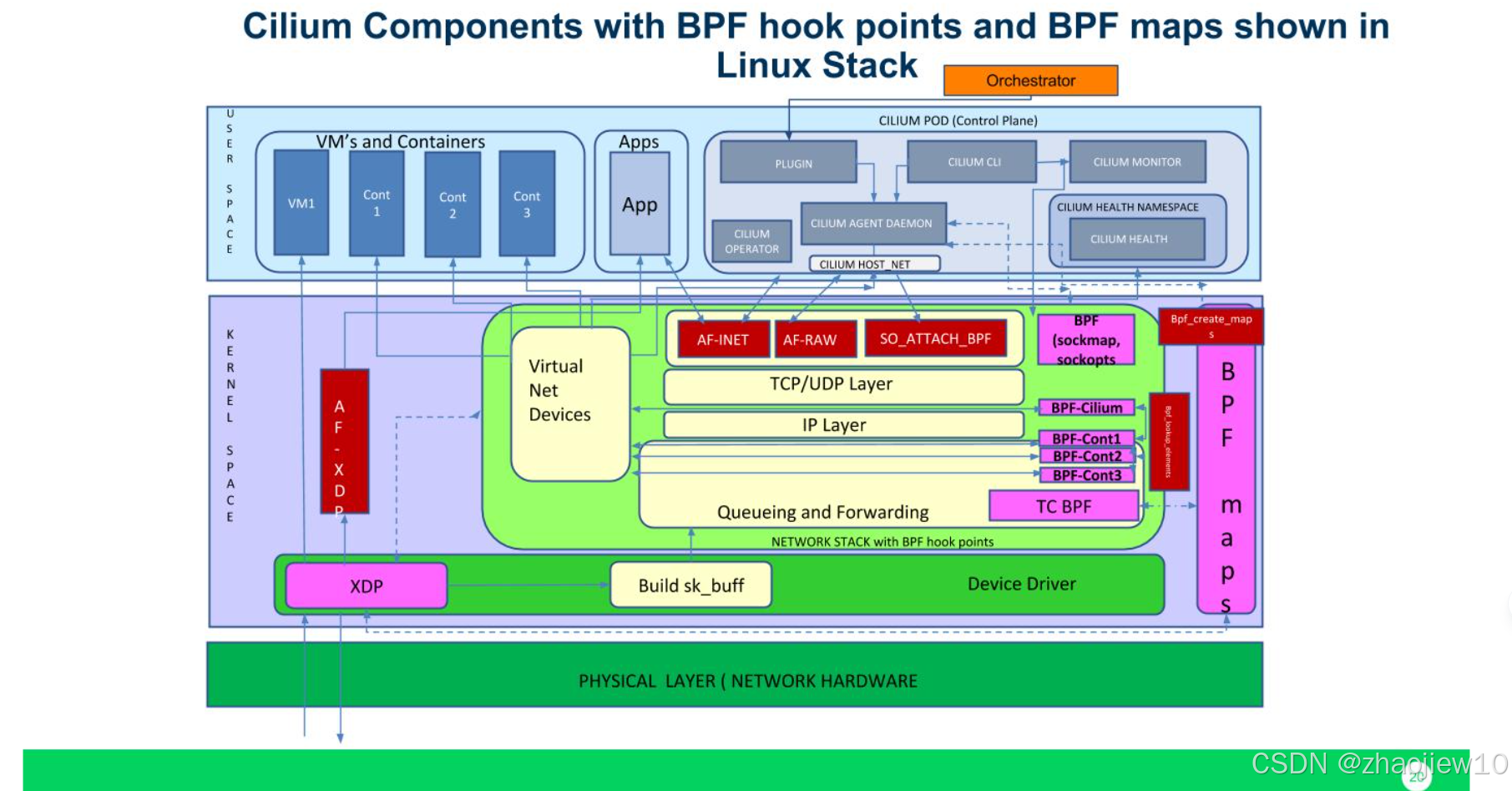
這張圖更詳細地展示了Cilium的組件以及BPF Hook點和BPF Maps在Linux網絡棧中的位置。
- 用戶空間部分有Cilium Agent、CLI、健康檢查和監控器等。
- 內核空間則展示了虛擬網絡設備、TCP/UDP、IP層、隊列和轉發層,以及關鍵的BPF Maps和XDP技術。
這些組件共同協作,實現了Cilium的網絡功能。注意看BPF Maps是如何連接用戶空間和內核空間的,以及BPF Hook是如何在數據包處理路徑上發揮作用的。
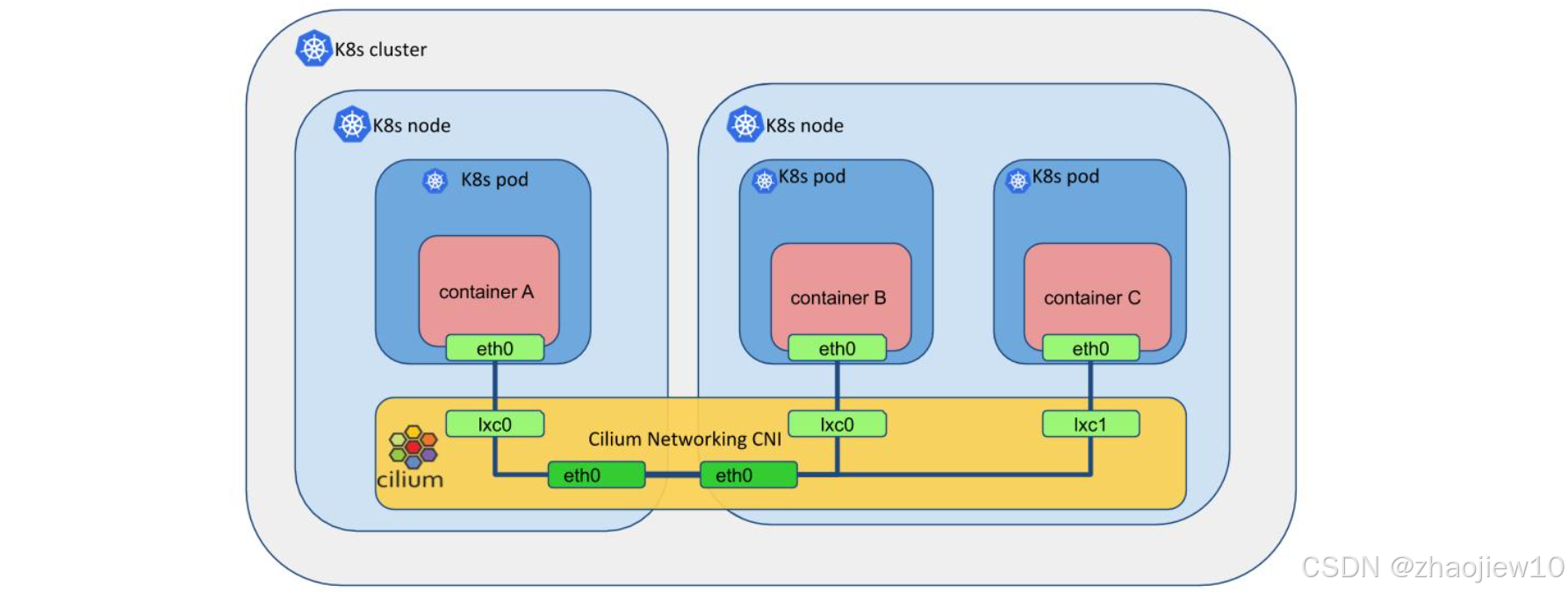
這張圖展示了Cilium作為CNI插件的典型部署。在Kubernetes節點上,每個Pod都有一個容器,比如容器A、容器B、容器C。每個容器通過eth0接口連接到一個虛擬網絡接口,比如lxc0或lxc1。這些虛擬接口由Cilium負責管理。Cilium通過eth0接口連接到物理網卡,實現了Pod之間的通信。這種架構下,Cilium不僅負責網絡連接,還負責執行網絡策略,提供隔離和安全。
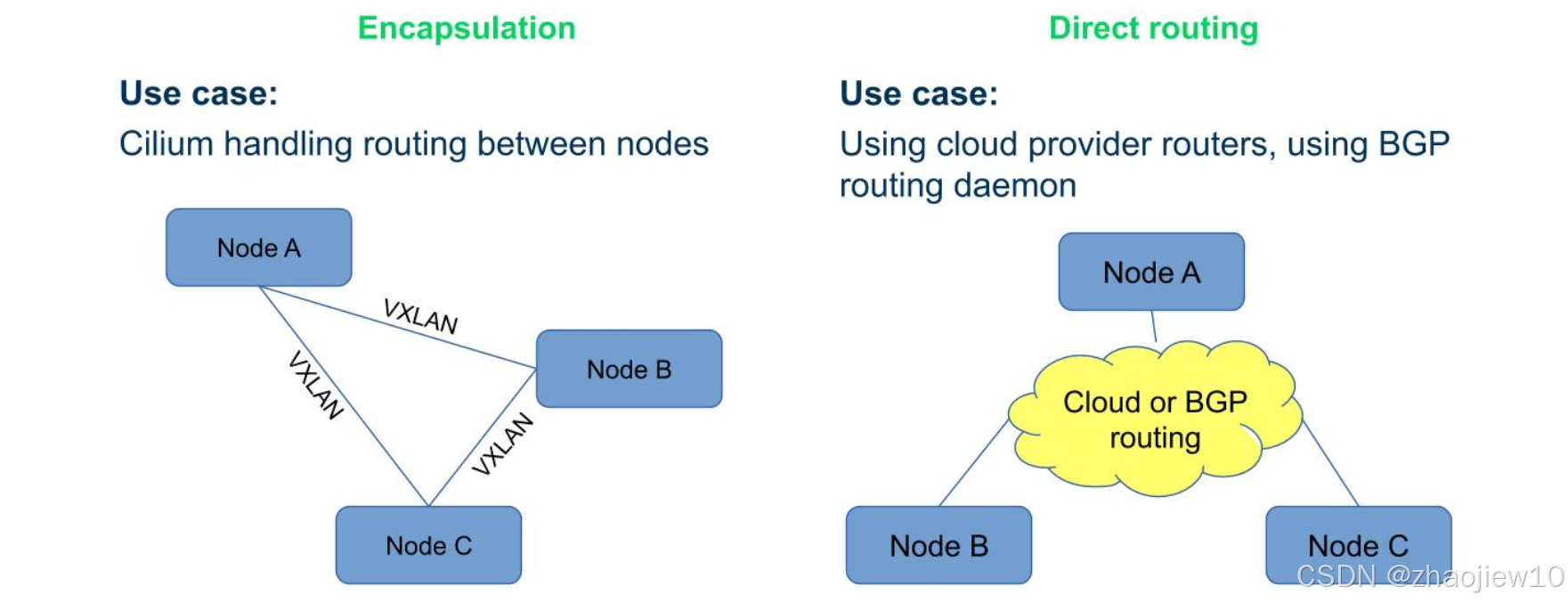
Cilium支持兩種主要的網絡模式:封裝模式和直接路由模式。
-
封裝模式下,Cilium負責在節點間路由,通常使用VXLAN隧道進行數據包封裝。這適用于需要跨節點網絡隔離的場景。
-
直接路由模式下,Cilium利用云提供商的路由器或BGP路由,實現Pod IP的直接路由。這適用于需要高性能、低延遲的場景,比如在云上使用云原生路由器或BGP路由。
選擇哪種模式取決于具體的應用場景和性能需求。
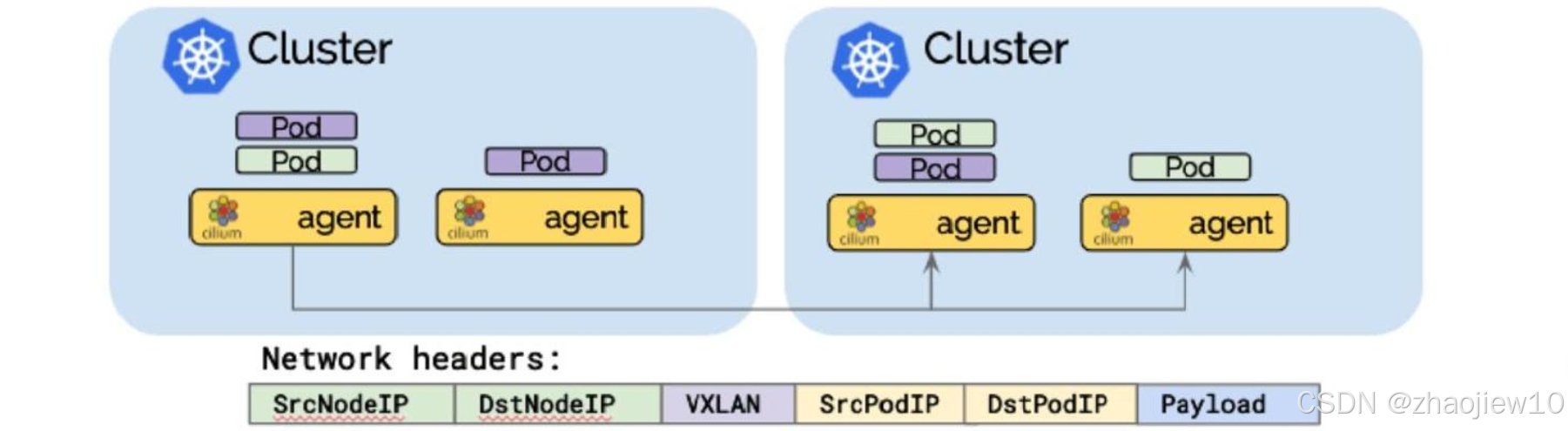
這張圖展示了Pod IP路由的Overlay模式(隧道模式)。在這種模式下,當兩個Pod需要跨節點通信時,數據包會被封裝在VXLAN隧道中。封裝后的數據包包含源節點IP、目標節點IP、VXLAN頭部信息以及原始的Pod IP和負載數據。Cilium負責在節點間轉發這些封裝后的數據包,直到目標節點解封裝,然后才能被目標Pod接收。這種方式保證了跨節點的網絡隔離。
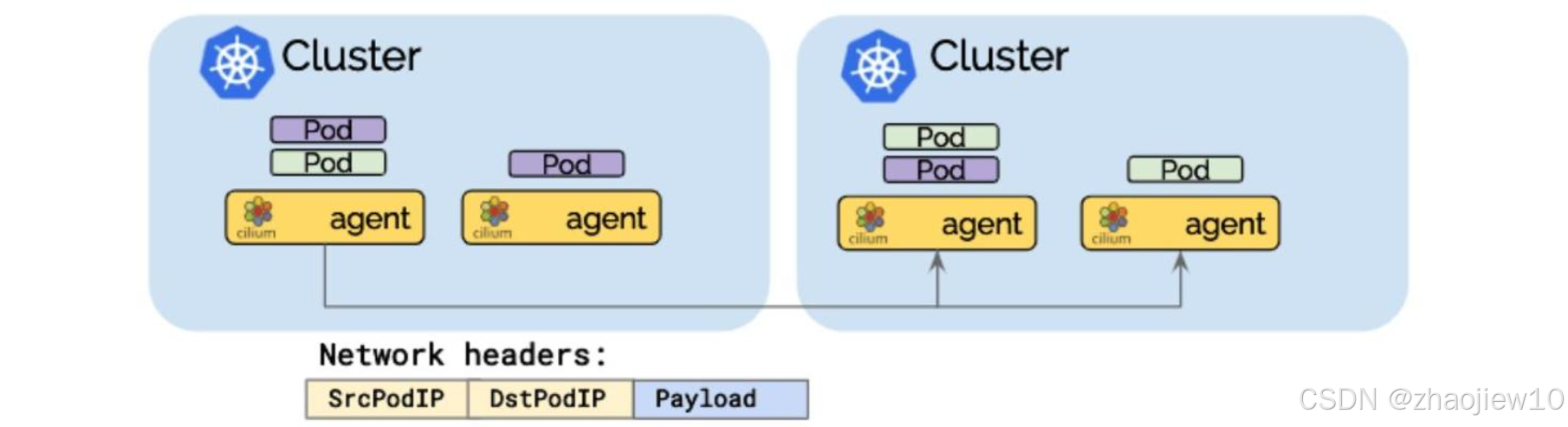
這張圖展示了Pod IP路由的直接路由模式。在這種模式下,Pod的IP地址可以直接路由到網絡中。當一個Pod需要訪問另一個Pod時,數據包直接攜帶目標Pod的IP地址和負載信息,通過網絡路由轉發。這種模式下,網絡頭部信息非常簡潔,只包含源Pod IP和目標Pod IP以及負載。這使得通信效率更高,延遲更低,適合對性能要求高的場景。
現在我們來看Cilium的網絡策略功能,首先是基于標簽的三層過濾,針對入站流量。
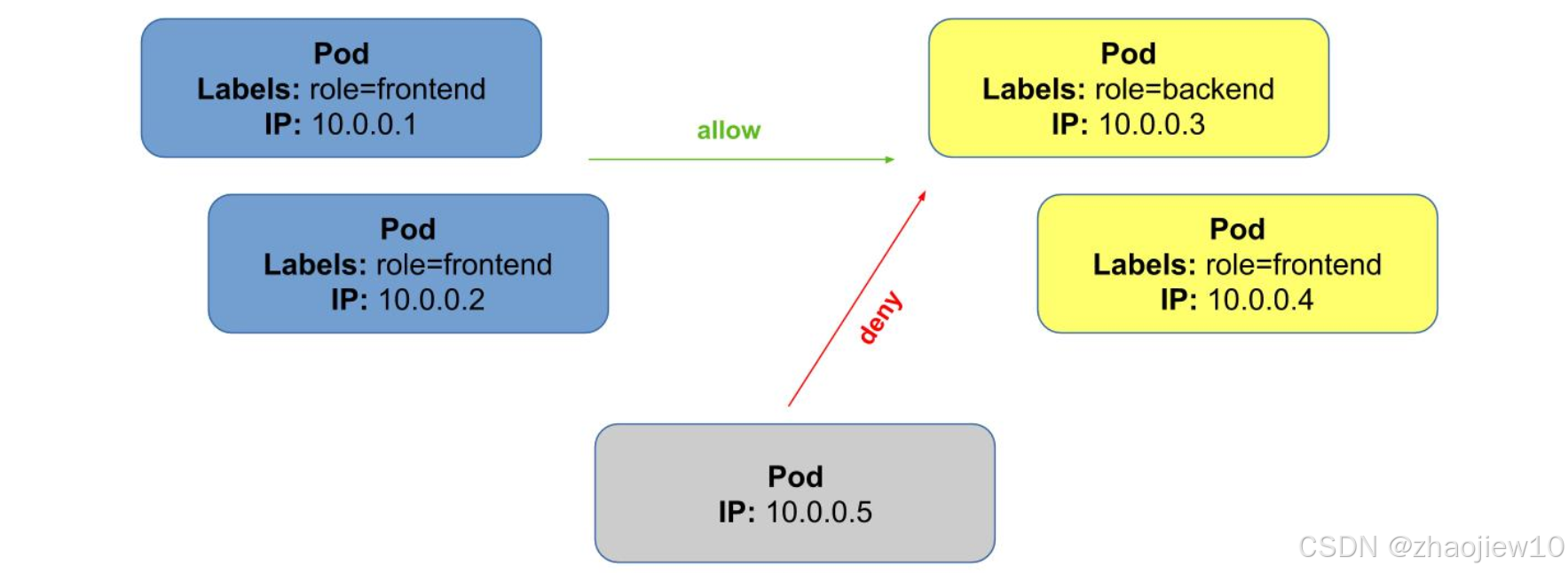
這張圖展示了如何定義一個策略,允許特定標簽的Pod訪問另一個標簽的Pod。例如,允許所有標簽為frontend的Pod訪問標簽為backend的Pod。這通過CiliumNetworkPolicy資源來定義,非常直觀。注意,這里的策略是基于標簽的,而不是基于IP的,這使得策略管理更加靈活,尤其是在Pod動態調度的情況下。
接下來是基于CIDR的三層過濾,針對出站流量。例如,允許一個標簽為backend的Pod訪問10.0.1.0/24這個子網,但拒絕訪問其他子網,比如10.0.2.0/24。這在需要控制Pod出站流量的場景下非常有用,例如限制后端服務只能訪問特定的數據庫或緩存集群。它定義了一個名為backend-backend的策略,作用于所有標簽為backend的Endpoint。在egress部分,它允許訪問到10.0.1.0/24這個CIDR地址。同樣,配置非常清晰地表達了允許后端訪問特定子網的策略。
除了三層過濾,Cilium還支持四層過濾,即基于端口和協議的過濾。這張YAML示例展示了如何定義一個策略,只允許訪問標簽為backend的Pod的TCP端口80。這意味著,即使兩個Pod之間有三層策略允許通信,但如果沒有四層策略允許訪問特定端口,該端口的流量也會被阻斷。這張圖直觀地展示了四層過濾的效果。對于一個標簽為backend的Pod,只有TCP端口80的流量是綠色的,表示允許通過,而其他端口的流量是紅色的,表示被拒絕。這保證了只有期望的端口才能被訪問,增強了安全性。
Cilium最強大的功能之一是七層過濾,也就是基于應用層協議,特別是HTTP協議的過濾。這張圖展示了如何實現基于API的訪問控制。比如,一個Pod可以訪問另一個Pod的GET斜杠articles斜杠id API,但無法訪問GET斜杠private API。這需要對HTTP請求的內容進行解析,才能做出正確的決策。這是實現七層過濾的YAML示例。它定義了一個名為frontend-backend的策略,作用于所有標簽為backend的Endpoint。在ingress部分,它允許訪問端口80,并且通過L7規則,允許特定的HTTP請求路徑。這使得我們可以基于具體的API請求來控制訪問權限,實現更精細化的安全策略。
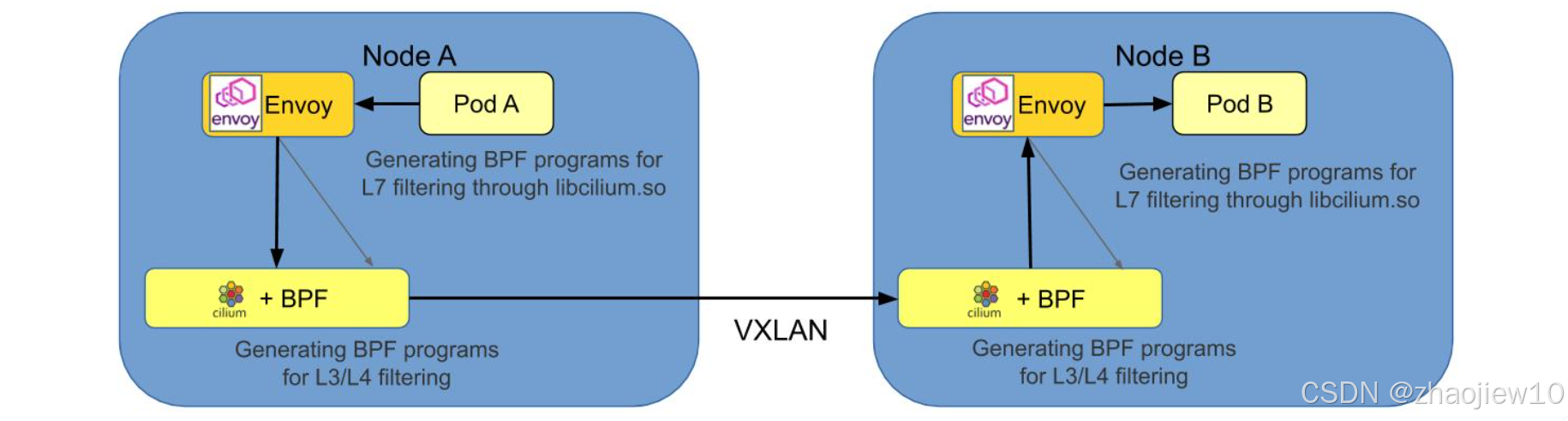
這張圖展示了如何將Cilium與Envoy這樣的獨立代理結合使用,實現七層過濾。在Node A上,Envoy通過libcilium.so生成L7過濾程序,然后通過Cilium和BPF模塊進行L3斜杠L4過濾。Node B也類似。這種方式下,Envoy負責處理復雜的七層邏輯,而Cilium利用BPF進行高效的底層處理,實現了性能和功能的平衡。
接下來,我們來看Cilium的其他一些關鍵特性。Cluster Mesh是Cilium的一個重要特性,它允許跨集群的網絡通信。
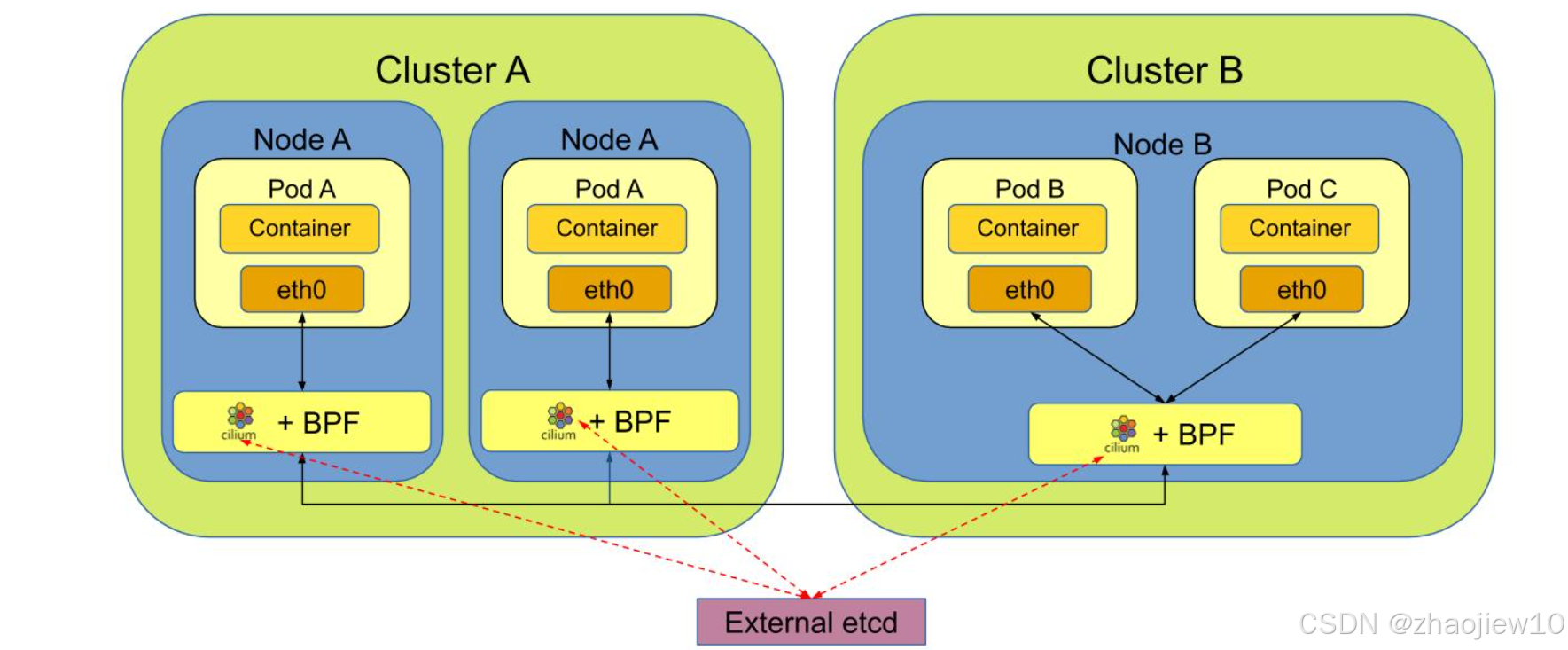
這張圖展示了兩個集群,A和B,它們都運行了Cilium。通過Cluster Mesh,集群A中的Pod可以訪問集群B中的Pod,反之亦然。這使得多集群環境下的服務發現和網絡通信變得非常方便。圖中Pod A和Pod B、C都通過Cilium連接到一個共享的etcd實例,用于協調和管理跨集群的網絡配置。
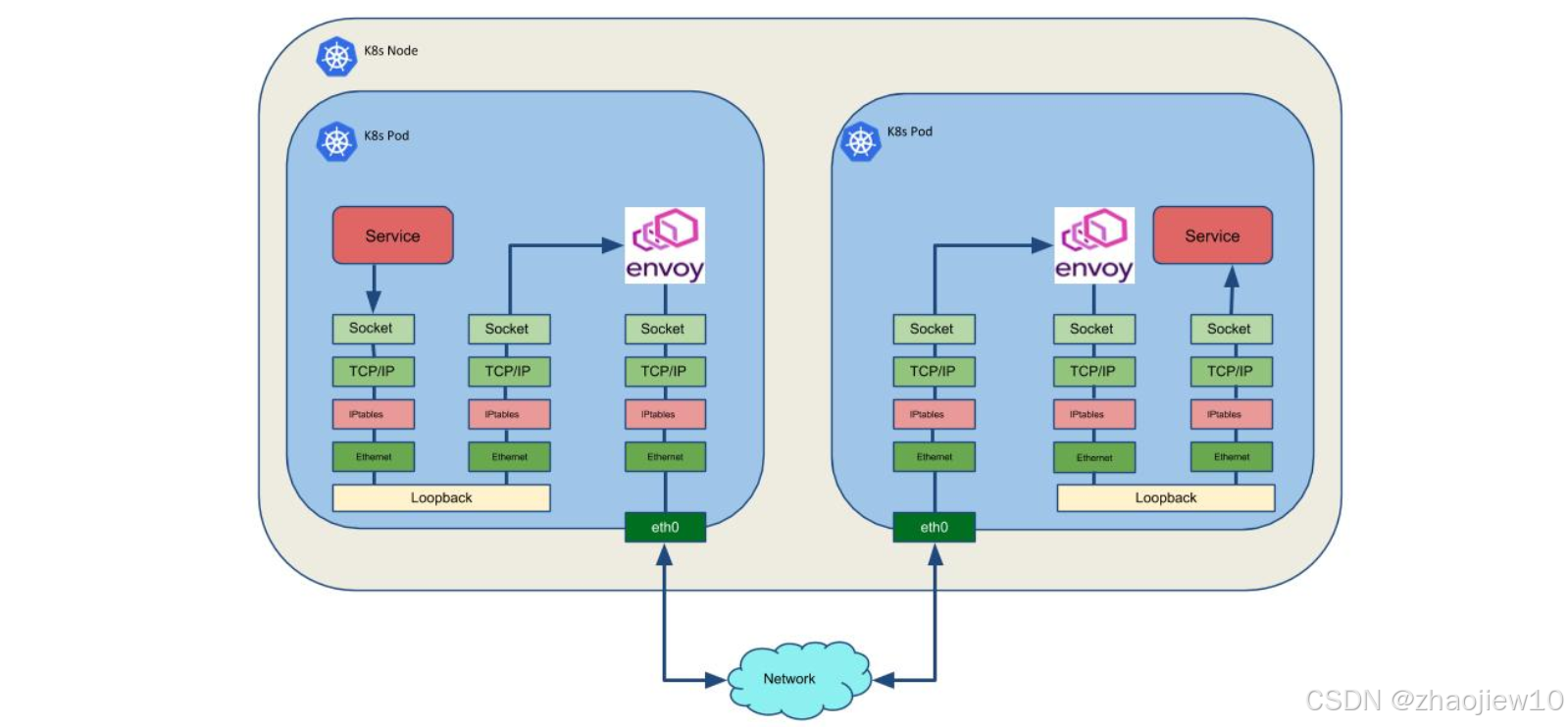
這張圖展示了在沒有Cilium的情況下,Istio如何實現透明的Sidecar注入。可以看到,Envoy代理被注入到Pod中,與應用進程共享網絡命名空間。Envoy通過監聽應用端口,攔截流量,然后轉發給應用。這種方式需要在應用端口和Envoy端口之間建立連接,可能會引入額外的延遲和復雜性。
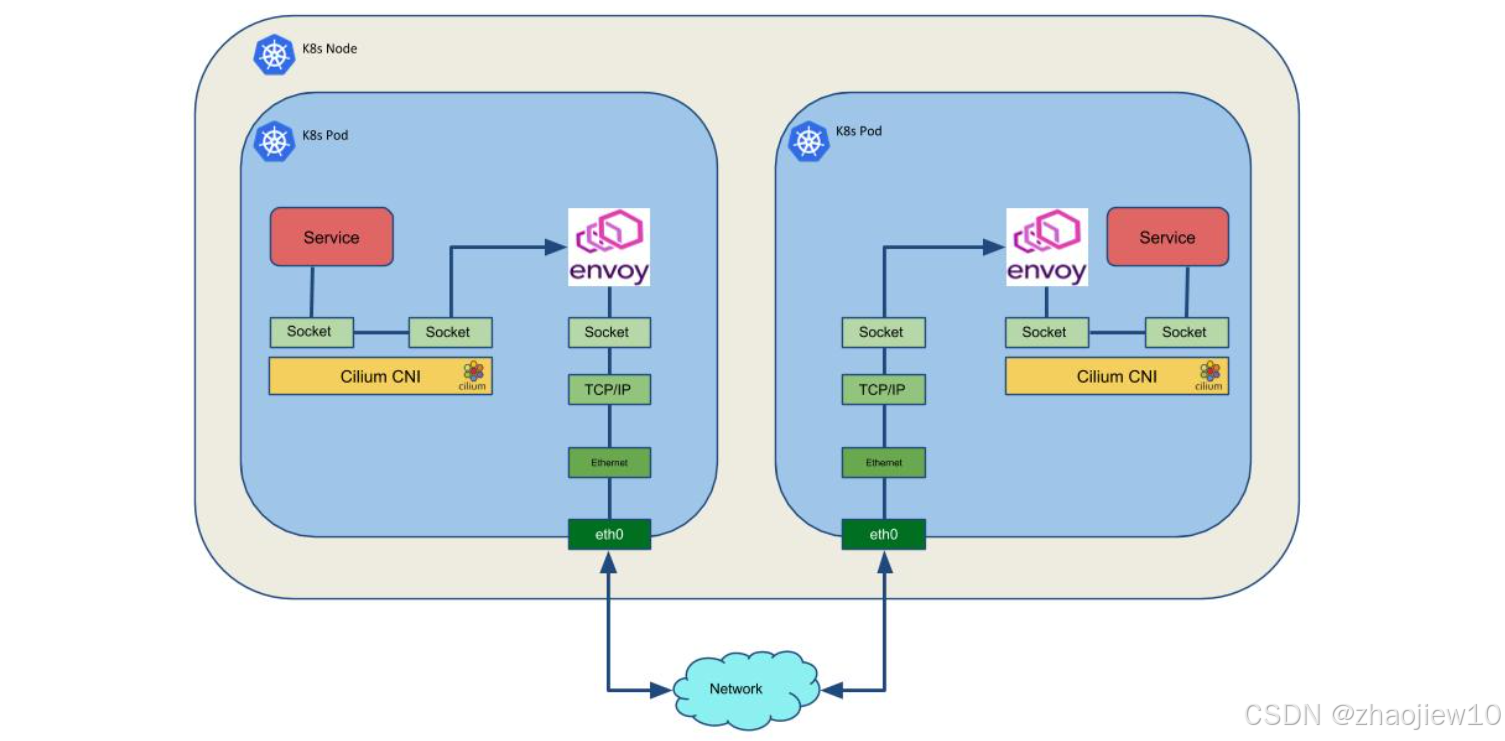
這張圖展示了Istio與Cilium和sockmap結合后的架構。Cilium作為CNI插件,負責Pod的網絡連接。Envoy作為Sidecar,仍然被注入到Pod中。但是,Cilium通過sockmap技術,將Envoy的監聽端口映射到應用的端口。這樣,應用可以直接訪問Envoy,而無需建立額外的連接。這種方式利用了BPF的高效性,實現了更透明、更快速的Sidecar注入。
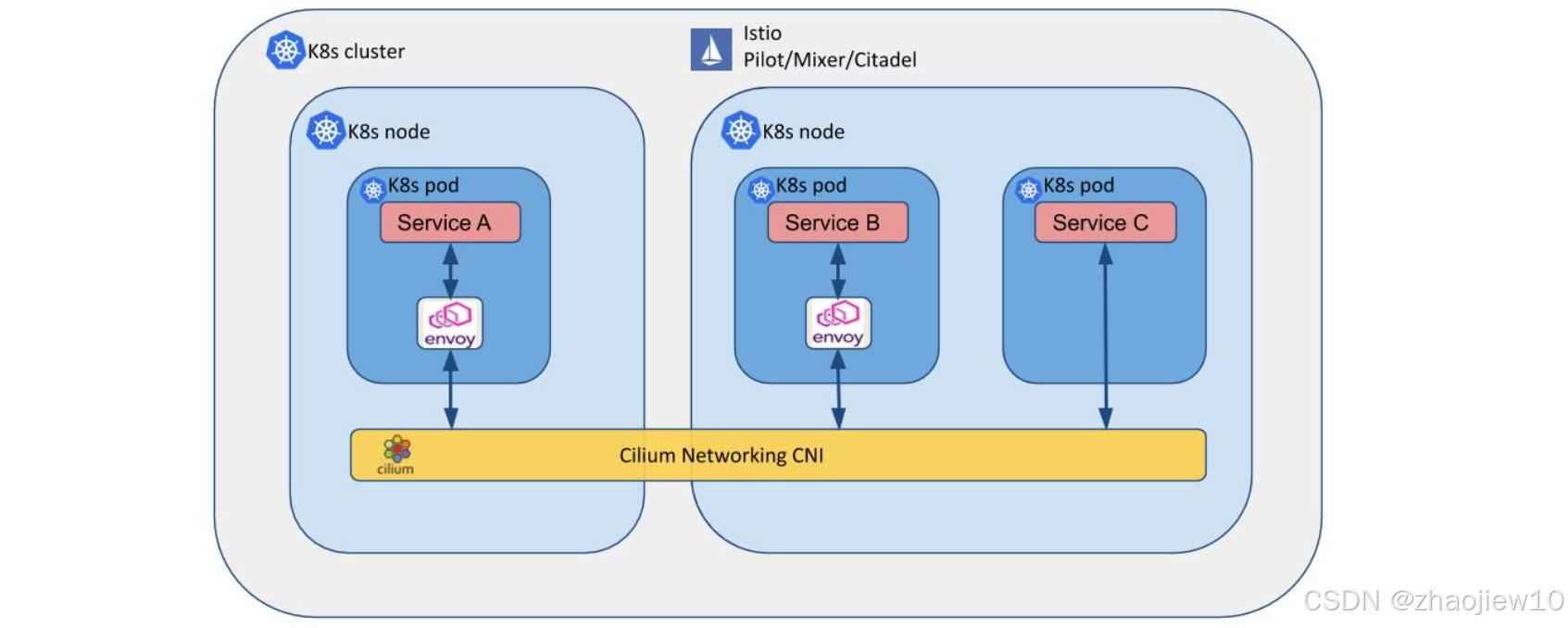
這張圖展示了完整的Istio和Cilium集成。可以看到,Istio的控制平面(Pilot、Mixer、Citadel)負責服務發現、路由和安全策略。數據平面則由Envoy代理和Cilium網絡組成。Cilium負責底層的網絡連接和數據包處理,Envoy負責七層的負載均衡、路由和安全策略。這種結合充分發揮了Cilium和Istio各自的優勢,構建了一個高性能、可擴展的服務網格。
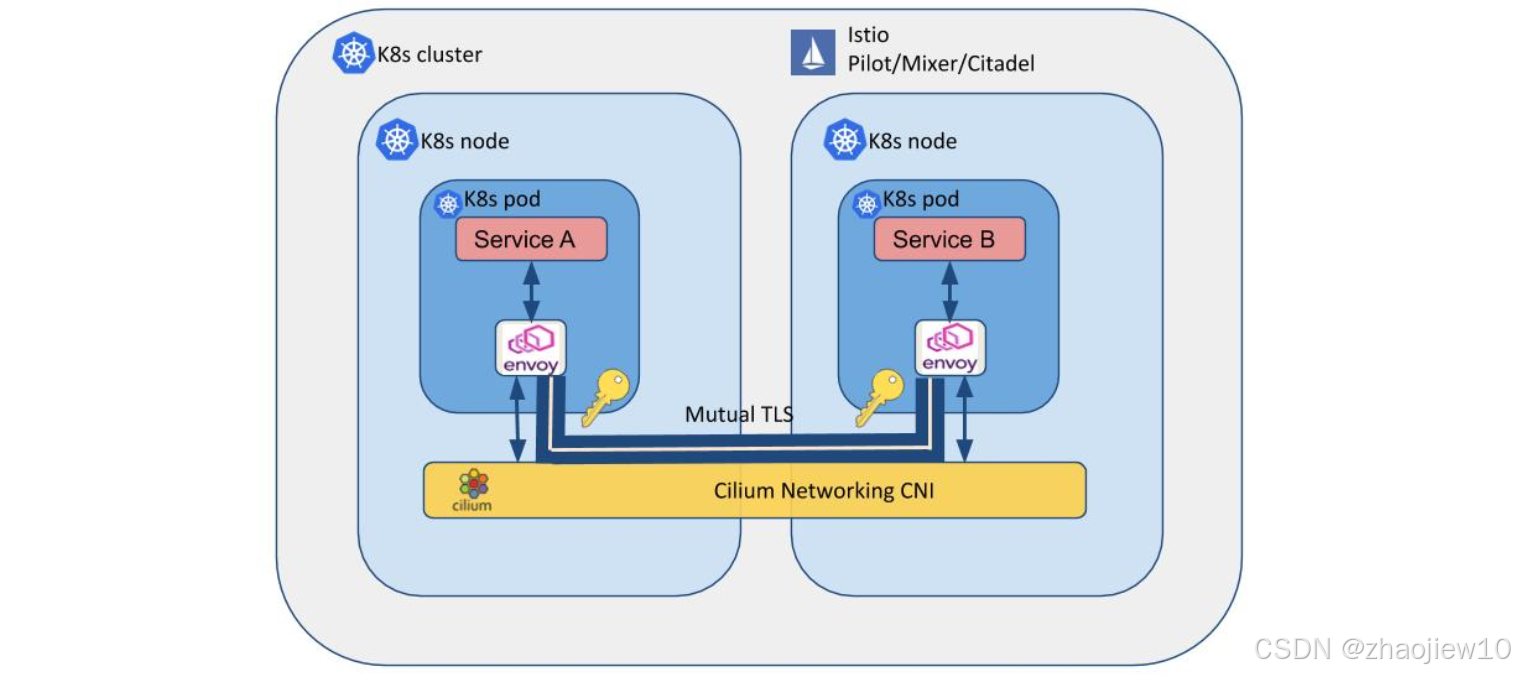
這張圖展示了Istio與Cilium結合實現的雙向TLS認證。可以看到,服務A和B之間的通信被加密,通過Mutual TLS確保了雙方的身份認證。這種安全通信是通過Istio的控制平面和Envoy的代理,以及Cilium的網絡基礎設施來實現的。
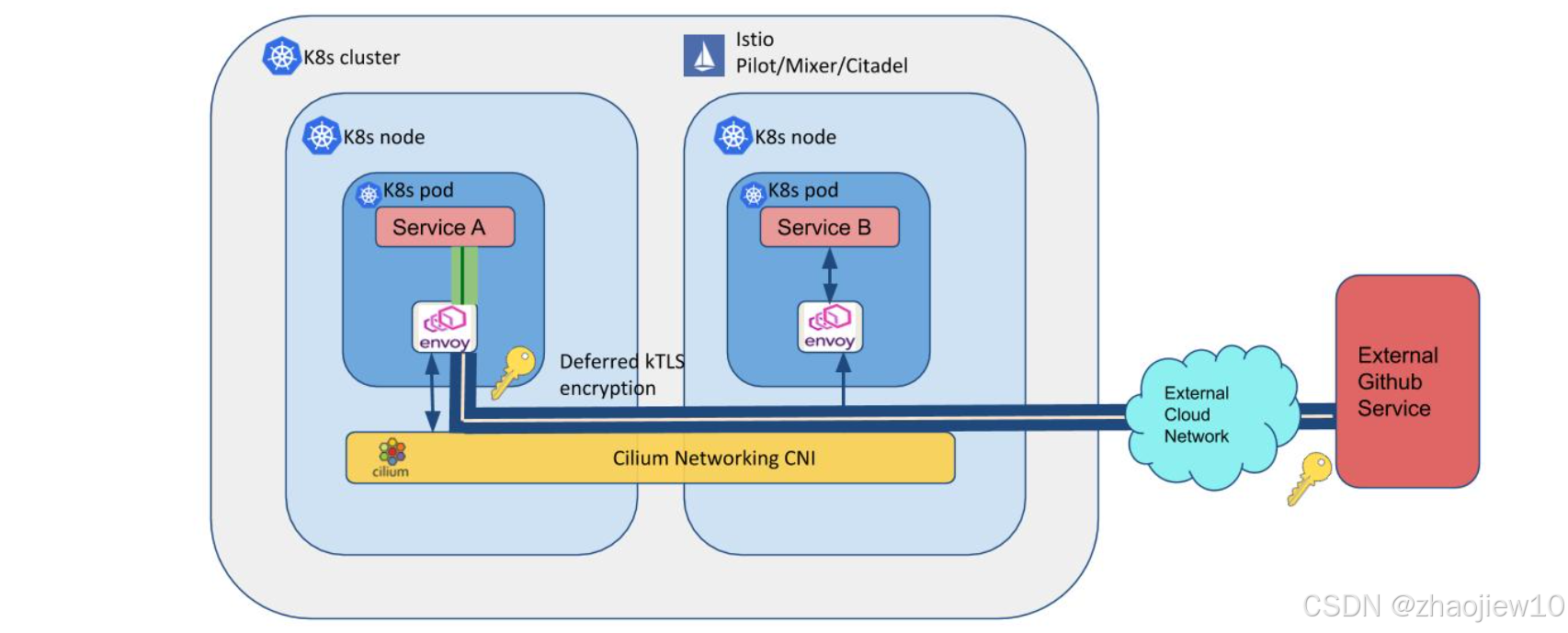
這張圖展示了Istio與Cilium結合的Deferred kTLS特性。kTLS,即Kernel TLS,是內核直接提供TLS加密功能。Deferred kTLS允許在需要時才進行TLS加密,而不是在所有連接上都強制開啟。這可以提高性能,尤其是在不需要加密的場景下。Cilium與Istio的結合,使得這種優化成為可能。
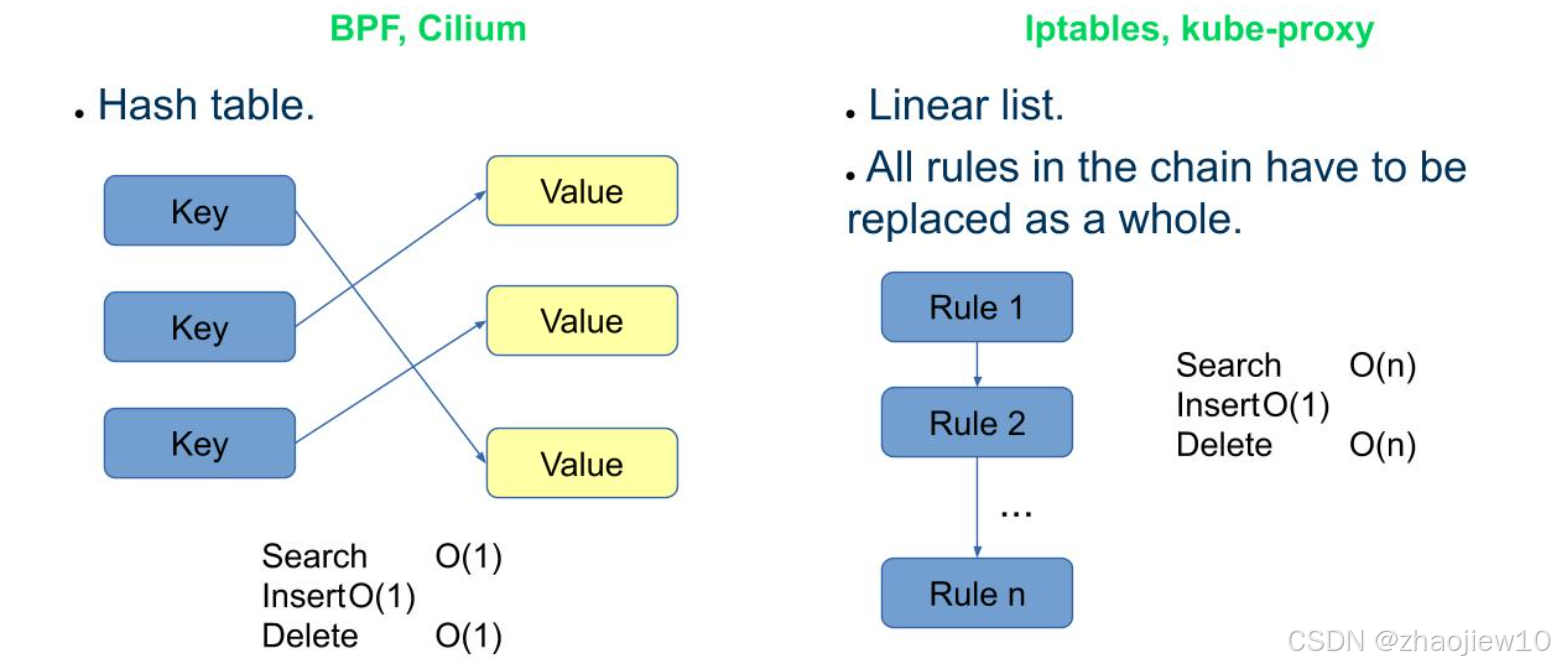
我們對比一下Kubernetes服務的實現方式。在Cilium和BPF中,服務路由通常使用哈希表。查找、插入和刪除操作都是O(1)常數時間復雜度,非常高效。而在傳統的Iptables和kube-proxy中,服務路由是基于線性列表的。查找是O(n)線性時間復雜度,插入和刪除也是O(n)。這意味著,當服務數量增加時,BPF的性能優勢會更加明顯。
這張圖展示了Kubernetes服務的基準測試結果。橫軸是集群中的服務數量,縱軸是響應時間。藍色柱代表Cilium(BPF),深藍色柱代表kube-proxy(legacy iptables)。可以看到,隨著服務數量增加,kube-proxy的響應時間急劇上升,而Cilium的響應時間基本保持穩定。這再次證明了BPF在處理大規模服務時的性能優勢。
Cilium可以與其他CNI插件鏈式使用。比如,你可以將Cilium與Flannel、Calico、Weave、AWS CNI、Azure CNI等結合。例如,你可以使用一個CNI插件負責基礎的網絡配置,比如IP地址分配和網絡接口配置,而Cilium則負責策略執行、負載均衡和多集群連接。這種鏈式組合提供了極大的靈活性,可以根據具體需求選擇合適的組件。
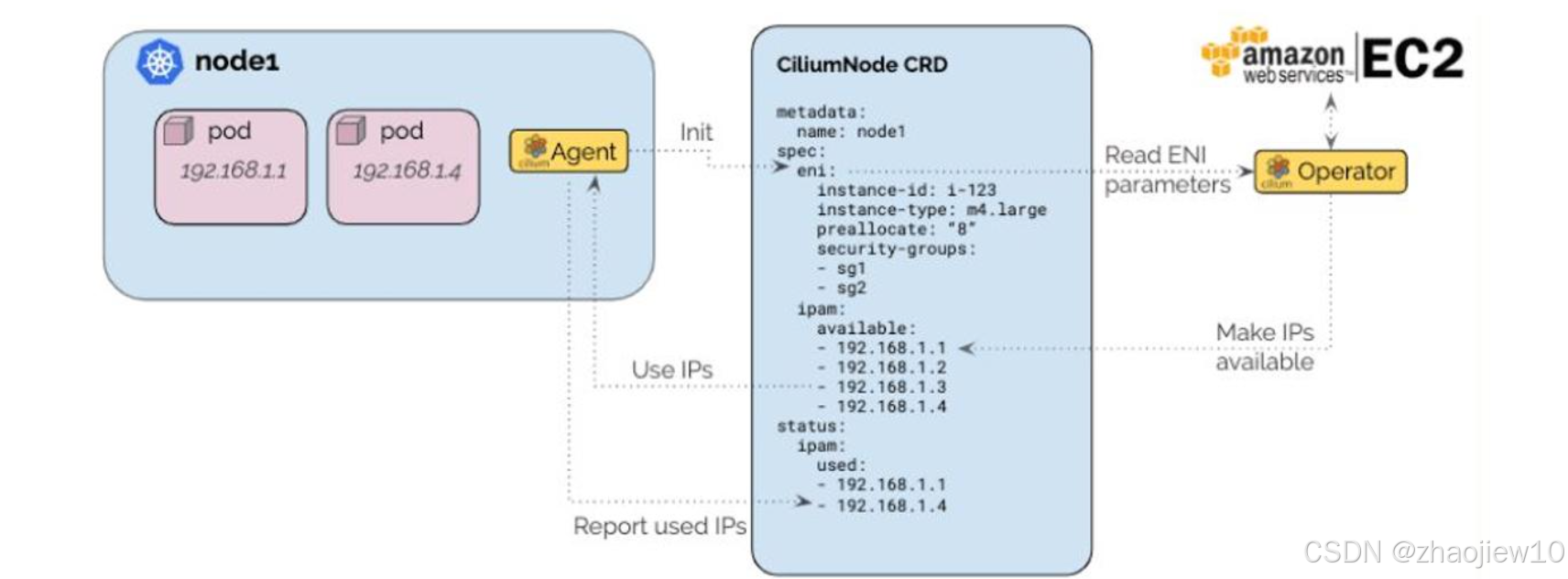
Cilium原生支持AWS的彈性網絡接口(ENI)。這張圖展示了如何利用Cilium的Operator來讀取ENI上的預分配IP地址,然后將這些IP地址分配給Pod使用。這使得Cilium能夠充分利用AWS提供的網絡功能,實現高性能的網絡連接。Hubble是Cilium生態系統中的一個重要組件,它是一個分布式網絡和安全可觀測性平臺。它建立在Cilium和eBPF之上,提供了對云原生工作負載的深度洞察。Hubble提供服務依賴關系和通信圖譜、運維監控和告警、應用監控以及安全可觀測性。雖然目前還處于Beta階段,但其潛力巨大,是構建現代可觀測性平臺的關鍵工具。
Hubble由幾個核心組件構成。
- Hubble Agent運行在每個節點上,負責與Cilium Agent交互,收集流量信息,并提供查詢API和指標。Hubble Storage是一個內存存儲層,用于存儲收集到的流量信息。
- Hubble CLI是一個命令行工具,可以連接到Hubble Agent,查詢存儲的流量數據。
- Hubble UI則提供了圖形化的服務通信圖譜,基于Hubble Agent收集的數據。
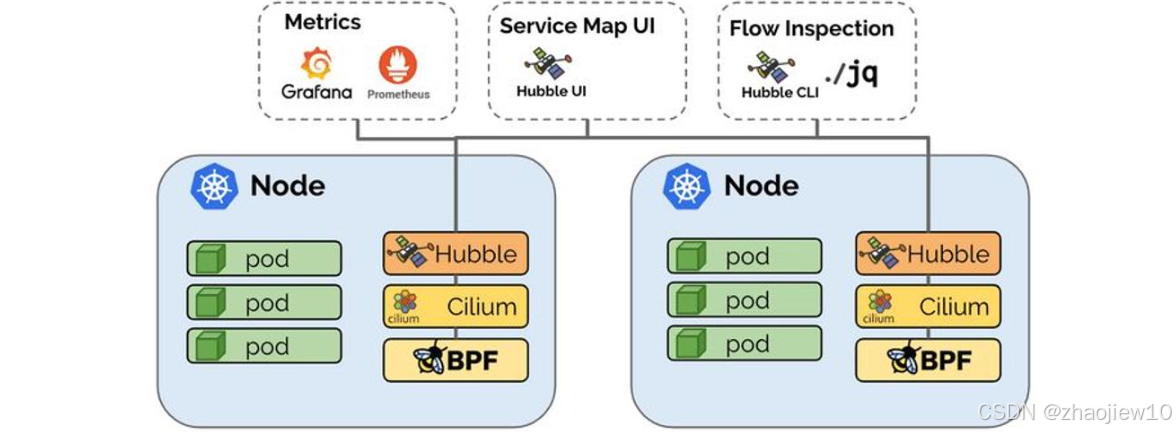
這張圖展示了Hubble在Cilium和eBPF之上的運行架構。可以看到,Hubble Agent與Cilium Agent緊密協作,收集網絡流量信息。這些信息通過Hubble的API暴露出來,供Hubble CLI和Hubble UI使用。同時,Hubble還可以與Grafana、Prometheus等監控系統集成,提供更全面的可觀測性。
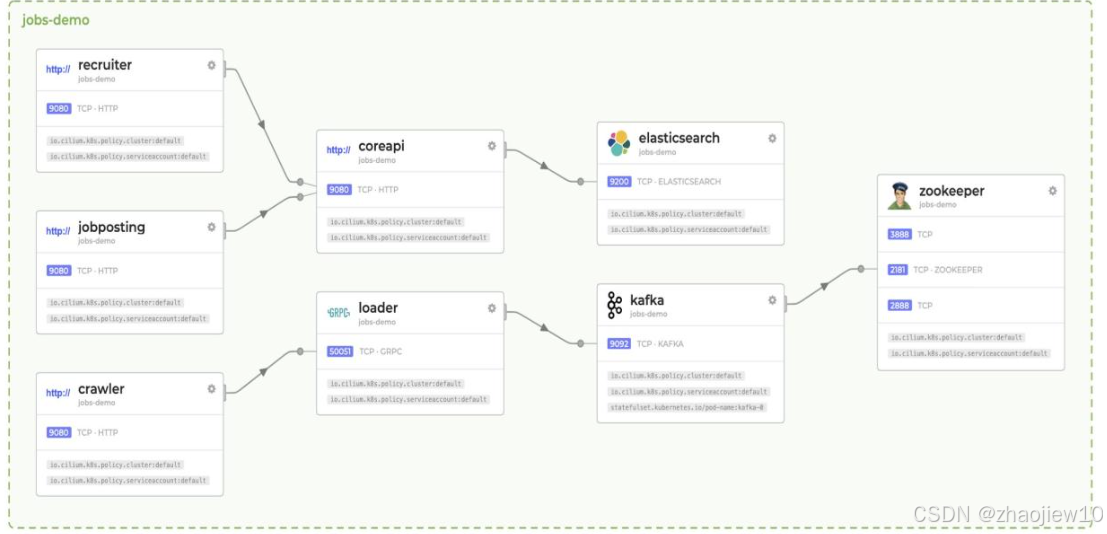
這張圖展示了Hubble提供的服務通信圖譜。它以圖形化的方式展示了不同服務之間的依賴關系和通信流量。例如,可以看到recruiter服務通過HTTP訪問coreapi,elasticsearch服務通過TCP訪問,kafka服務通過TCP訪問zookeeper等。這種可視化對于理解復雜系統的運行狀態至關重要。
Hubble還能提供豐富的HTTP指標。例如,這張圖展示了HTTP請求和響應的統計,包括請求量、響應量、狀態碼分布、以及不同百分位的請求響應時間(p50, p99)。這些指標對于監控應用性能、發現瓶頸問題非常有幫助。總結一下,Cilium利用eBPF技術,為Kubernetes帶來了革命性的網絡和安全能力。
為什么Cilium如此優秀?它消除了傳統iptables的弊端,始終從Linux內核中汲取最佳性能。它提供了多集群互聯能力,加速了Istio的性能,提供了基于Kubernetes資源的七層API感知過濾,并且能夠無縫集成其他流行的CNI插件。這些都是Cilium的核心價值。

)


:構建企業級可觀測性與安全的基石)



)





 與擴展運算符的深度解析與最佳實踐)




