Vanna 核心功能、應用場景與技術特性詳解
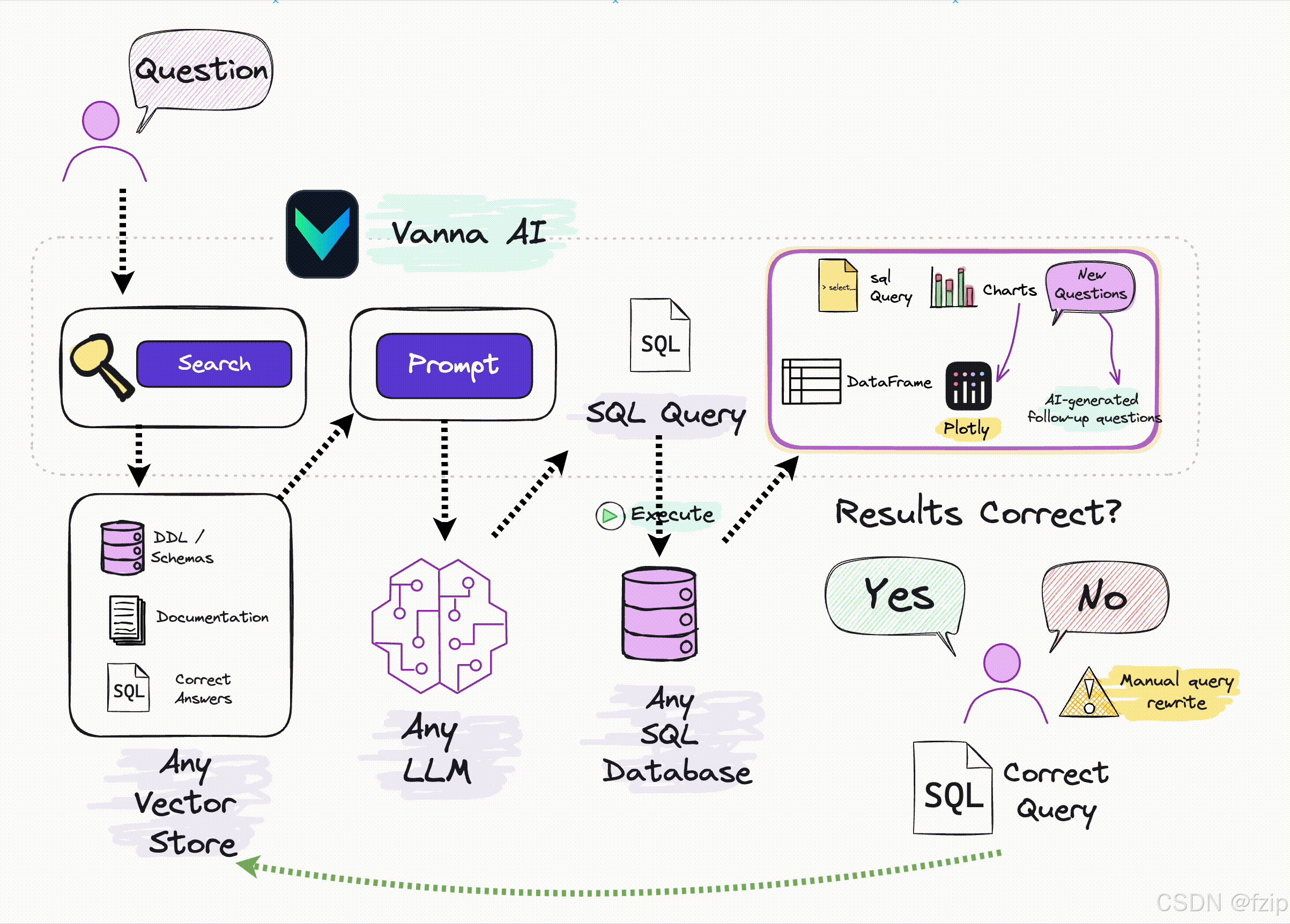
一、核心功能
1. 自然語言轉SQL查詢
Vanna 允許用戶通過自然語言提問(如“顯示2024年銷售額最高的產品”),自動生成符合數據庫規范的SQL查詢語句。其底層采用 RAG(檢索增強生成) 技術,結合向量數據庫存儲的上下文(表結構、歷史查詢模板)與大型語言模型(LLM)的生成能力,顯著提升SQL準確性。測試數據顯示,復雜場景下的生成準確率比傳統LLM提升40%以上。
2. 多數據庫兼容與自動執行
支持 PostgreSQL、Snowflake、BigQuery、DuckDB 等10+主流數據庫,通過SQLAlchemy實現統一連接適配。生成的SQL可直接在目標數據庫中執行,并返回結構化結果,避免人工復制粘貼操作。
3. 自動化數據可視化
集成Plotly等庫,根據查詢結果自動生成 交互式圖表(如折線圖、柱狀圖),支持導出CSV或對接Power BI等BI工具。例如,輸入“各渠道ROI趨勢”可同時獲得SQL結果與趨勢圖。
4. 持續自學習機制
通過用戶反饋(標記正確/錯誤SQL)、動態更新知識庫(新增表結構)和社區貢獻案例,實現模型性能的持續優化。某電商平臺案例顯示,人工修正比例從20%降至5%僅需3個月。
二、典型應用場景
| 場景分類 | 應用實例 | 價值體現 |
|---|---|---|
| 企業數據分析 | 銷售經理輸入“上月各地區銷售額排名”,自動生成多表關聯SQL并返回可視化報表 | 降低非技術人員使用門檻,縮短60%分析時間 |
| 教育與培訓 | 教學平臺構建SQL練習工具,學生提問后系統生成SQL并給出優化建議 | 幫助初學者理解SQL邏輯,提升學習效率 |
| 數據中臺集成 | 低代碼平臺將Vanna作為底層引擎,用戶通過拖拽配置生成ETL管道所需的復雜SQL | 簡化數據管道開發,減少50%編碼工作量 |
| 實時數據交互 | Slack/企業微信部署Vanna機器人,實時響應“當前庫存預警產品有哪些”等業務查詢 | 實現即時數據獲取,增強團隊協作效率 |
| 科研協作 | 研究團隊在Jupyter Notebook中快速驗證假設,通過auto_train積累領域特定查詢模板 | 減少重復編碼,聚焦數據洞察 |
三、關鍵技術特性
-
RAG架構突破傳統LLM限制
- 檢索階段:向量數據庫存儲表結構、字段注釋、歷史優質SQL模板,實時匹配用戶問題上下文
- 生成階段:LLM(如GPT-4、Llama 2)基于檢索結果生成語法規范的SQL,避免“幻覺”問題
- 效果:在涉及多表JOIN、窗口函數等復雜查詢中,準確率比純LLM方案提升超40%
-
模塊化技術棧兼容性
- LLM支持:OpenAI、Anthropic、Hugging Face等主流模型,可本地部署Ollama框架
- 向量數據庫:Chroma(輕量級)、Milvus(分布式)、Azure Search(企業級)自由切換
- 部署架構:單機腳本快速驗證概念,支持橫向擴展至每秒數千次高并發查詢
-
企業級安全與隱私
- 數據隔離:SQL在用戶本地環境執行,僅向LLM發送脫敏元數據(如表名)
- 權限控制:RBAC機制限制用戶訪問范圍,審計日志記錄所有查詢操作
- 合規認證:滿足金融/醫療領域數據治理要求,支持私有化部署
-
開發者友好生態
- 多終端界面:提供Jupyter、Streamlit、Flask、Slack等現成模板,5分鐘即可搭建查詢工具
- API設計:
vn.ask("問題")單一接口封裝復雜邏輯,支持錯誤重試與語法校驗 - 社區驅動:開源社區貢獻案例持續豐富公共知識庫,加速跨行業適配
四、技術架構與擴展性
-
分層架構設計
-
擴展能力
- 自定義LLM:通過繼承
VannaBase類集成私有化模型 - 插件系統:開發數據清洗、異常檢測等擴展模塊
- 混合云部署:適配AWS/GCP/Azure云原生服務,支持Kubernetes集群管理
- 自定義LLM:通過繼承
五、安裝與快速入門
-
基礎環境搭建
# 安裝核心包與MySQL適配組件 pip install vanna[mysql,openai] -
初始化配置
from vanna.openai import OpenAI from vanna.chromadb import ChromaDB_VectorStoreclass MyVanna(ChromaDB_VectorStore, OpenAI):def __init__(self, config=None):ChromaDB_VectorStore.__init__(self, config=config)OpenAI.__init__(self, config=config)vn = MyVanna(config={"api_key": "sk-...", "model": "gpt-4"}) -
訓練與使用
# 注入領域知識 vn.train(ddl="CREATE TABLE sales (id INT, product VARCHAR(50), amount DECIMAL(10,2))")# 自然語言查詢 result = vn.ask("2024年銷售額最高的前5個產品是什么?") print(result.sql) # 輸出生成SQL result.plot() # 顯示可視化圖表
六、未來發展方向
- 增強型自然語言理解:支持多輪對話修正查詢條件
- 智能優化建議:自動推薦索引優化、查詢性能調優方案
- 跨模態交互:結合語音輸入與AR/VR數據展示
- 行業解決方案:預置零售、金融、醫療等垂直領域知識包
Vanna通過 開源協作+企業級功能 的雙輪驅動模式,正在重塑數據查詢范式。其設計平衡了易用性與專業性,既適合個人開發者快速驗證想法,也能滿足大型組織復雜的數據治理需求。
)

)

![[神經網絡]使用olivettiface數據集進行訓練并優化,觀察對比loss結果](http://pic.xiahunao.cn/[神經網絡]使用olivettiface數據集進行訓練并優化,觀察對比loss結果)


)











