目錄
- 第1章:引言
- 第2章:觀察與見解
- 2.1 總體觀察(Overall Observations)
- 2.2 從EfficientLLM基準中得出的新見解
- 第3章:背景
- 3.1 大語言模型(LLMs)
- 3.2 提升LLMs效率的方法
- 3.2.1 硬件創新
- 3.2.2 軟件優化
- 3.2.3 算法改進
- 第4章:提升LLMs效率的技術
- 4.1 LLMs效率的維度(Dimensions of LLM Efficiency)
- 4.2 預算效率:擴展法則(Budget Efficiency: Scaling Laws)
- 4.3 數據效率(Data Efficiency)
- **4.4 架構效率(Architecture Efficiency)**
- 4.5 訓練和微調效率(Training and Tuning Efficiency)
- **4.6 推理效率(Inference Efficiency)**
- 第5章:評估
- **5.1 EfficientLLM評估原則(Assessment Principles of EFFICIENTLLM)**
- **5.2 EfficientLLM實驗設置(Preliminaries of EFFICIENTLLM)**
- **5.3 架構預訓練效率評估(Assessment of Architecture Pretraining Efficiency)**
- **5.4 訓練和微調效率評估(Assessment of Training and Tuning Efficiency)**
- 5.5 量化推理效率評估(Assessment of Bit-Width Quantization Inference Efficiency)
- 第6章:EfficientLLM基準的可擴展性
- 6.1 Transformer基礎的LVMs架構預訓練效率(Efficiency for Transformer Based LVMs Architecture Pretraining)
- 6.2 PEFT在LVMs上的評估(Assessment of PEFT on LVMs)
- 6.3 PEFT在VLMs上的評估(Assessment of PEFT on VLMs)
- 6.4 PEFT在多模態模型上的評估(Assessment of PEFT on Multimodal Models)
- 第7章:相關工作
- 7.1 分布式訓練和系統級優化(Distributed Training and System-Level Optimizations)
- 7.2 對齊和強化學習效率(Alignment and RLHF Efficiency)
- 7.3 推理時間加速策略(Inference-Time Acceleration Strategies)
- 7.4 動態路由和模型級聯(Dynamic Routing and Model Cascades)
- 7.5 硬件感知訓練計劃(Hardware-aware Training Schedules)
- 7.6 討論(Discussion)
- 結論
《EfficientLLM: Efficiency in Large Language Models》由Zhengqing Yuan等人撰寫,系統地研究了大語言模型(LLMs)的效率問題,并提出了一個全面的基準框架EfficientLLM,用于評估不同效率優化技術在架構預訓練、微調和量化方面的表現。以下是對論文每一章節內容的脈絡概覽:
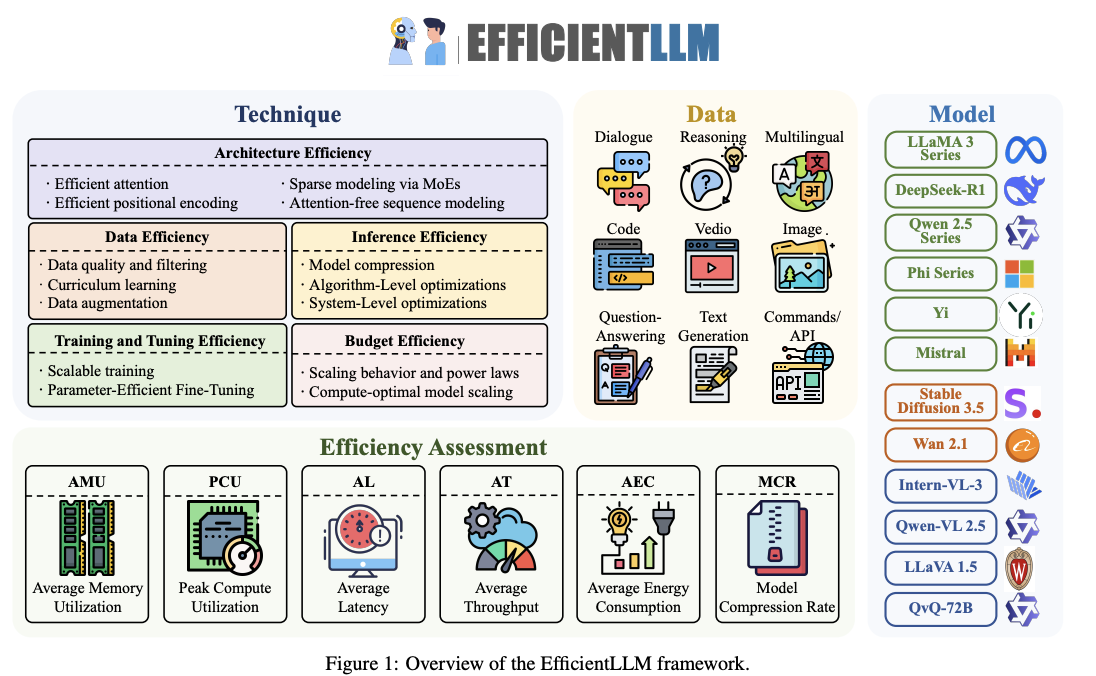
第1章:引言
- 研究背景
LLMs的突破性進展:LLMs如GPT系列和Pathways Language Model(PaLM)在自然語言處理(NLP)領域取得了顯著進展。這些模型通過深度學習技術在大規模文本數據上進行訓練,能夠生成復雜、連貫的語言內容,并在多種任務中表現出色。
模型規模和資源需求:隨著模型參數規模的不斷增大(如Deepseek R1的671B參數),訓練和推理所需的計算資源、內存容量和能源消耗也急劇增加。例如,訓練GPT-3(175B參數)需要約3640 Petaflop/s-days的計算量,成本高達數百萬美元。
資源需求對應用的影響:這種資源需求的增長限制了LLMs的廣泛應用,尤其是在資源受限的環境中。因此,提高LLMs的效率成為了一個關鍵的研究方向。 - 研究動機
效率挑戰:盡管LLMs在性能上取得了巨大進步,但其高昂的計算和能源成本使其在實際部署中面臨挑戰。例如,GPT-3的訓練成本高達數百萬美元,推理時的硬件需求和能源消耗也非常可觀。
現有研究的局限性:現有的研究通常只關注特定的效率技術,缺乏對多種技術在不同模型規模和任務上的系統性比較。此外,許多研究缺乏對現代硬件(如GPU)能耗的全面評估,或者依賴于理論分析而非大規模實證驗證。
EfficientLLM框架的必要性:為了填補這一空白,作者提出了EfficientLLM框架,旨在通過大規模實證研究,系統評估LLMs在架構預訓練、微調和量化方面的效率優化技術。 - 研究目標
系統性評估:EfficientLLM框架通過在生產級集群(48×GH200,8×H200 GPUs)上進行大規模實驗,系統評估了超過100種模型與技術組合的效率表現。
多維度效率評估:提出了六個細粒度的效率評估指標,包括平均內存利用率(AMU)、峰值計算利用率(PCU)、平均延遲(AL)、平均吞吐量(AT)、平均能耗(AEC)和模型壓縮率(MCR),以全面捕捉硬件飽和度、延遲-吞吐量平衡和碳成本。
提供實際指導:通過實驗結果,為研究人員和工程師在設計、訓練和部署LLMs時提供數據驅動的指導,幫助他們在資源受限的環境中做出更明智的決策。 - EfficientLLM框架的核心概念
架構預訓練效率:評估不同架構優化技術(如高效注意力機制、稀疏建模等)在模型預訓練階段的效率表現。這些技術直接影響模型的計算和能源成本。
參數高效微調(PEFT):評估多種參數高效微調方法(如LoRA、RSLoRA等)在適應特定下游任務時的效率和性能。這些方法通過更新模型的一小部分參數來減少微調所需的資源。
量化推理效率:評估不同量化技術(如int4、float16等)在減少模型大小和推理延遲方面的效果。這些技術可以在不重新訓練的情況下直接應用于部署。 - 研究貢獻
系統性分類和回顧:對LLMs的效率技術進行了系統性分類和回顧,涵蓋了架構、訓練和推理等多個方面。
新的評估指標:提出了一套新的詳細評估指標,用于評估LLMs的多維效率,包括硬件利用率、性能、能耗和模型壓縮。
大規模實證基準:通過在大規模GPU集群上進行實驗,提供了關于LLMs效率的系統性、大規模實證比較。
實際應用指導:為研究人員和工程師在選擇高效模型架構和優化技術時提供了基于實際數據的指導,而不是僅依賴理論分析或啟發式選擇。
第2章:觀察與見解
2.1 總體觀察(Overall Observations)
效率優化的多目標權衡:EfficientLLM基準研究發現,沒有任何單一方法能夠在所有效率維度上實現最優。每種技術在提升某些指標(如內存利用率、延遲、吞吐量、能耗或壓縮率)的同時,都會在其他指標上有所妥協。例如,Mixture-of-Experts(MoE)架構雖然通過減少FLOPs和提升準確性來優化計算效率,但會增加顯存使用量(約40%),而int4量化雖然顯著降低了內存和能耗(最高可達3.9倍),但平均任務分數下降了約3–5%。這些結果驗證了“沒有免費午餐”(No-Free-Lunch, NFL)定理在LLMs效率優化中的適用性,即不存在一種通用的最優方法。
資源驅動的權衡:在資源受限的環境中,不同的效率技術表現出不同的優勢。例如,MQA在內存和延遲方面表現出色,適合內存受限的設備;MLA在困惑度(perplexity)方面表現最佳,適合對質量要求較高的任務;而RSLoRA在14B參數以上的模型中比LoRA更高效,表明效率技術的選擇需要根據模型規模和任務需求進行調整。

2.2 從EfficientLLM基準中得出的新見解
架構預訓練效率:
注意力機制的多樣性:在預訓練階段,不同的高效注意力變體(如MQA、GQA、MLA和NSA)在內存、延遲和質量之間存在不同的權衡。MQA在內存和延遲方面表現最佳,MLA在困惑度方面表現最佳,而NSA在能耗方面表現最佳。
MoE的計算-內存權衡:MoE架構在預訓練時可以顯著提高性能(如提升3.5個百分點的準確性),同時減少訓練FLOPs(約1.8倍),但會增加顯存使用量(約40%)。這表明在計算和內存資源之間存在明顯的權衡。
注意力自由模型的效率:注意力自由模型(如Mamba)在預訓練時表現出較低的內存使用量和能耗,但困惑度有所增加。RWKV在延遲方面表現最佳,而Pythia在生成質量方面表現最佳,盡管其困惑度較高。
深度-寬度比的平坦最優區域:實驗結果表明,Chinchilla的深度-寬度比在預訓練時存在一個平坦的最優區域,這意味著在該區域內調整模型的深度和寬度對性能的影響較小,為硬件對齊的架構調整提供了靈活性。
訓練和微調效率:
PEFT方法的規模依賴性:LoRA及其變體(如LoRA-plus)在1B到3B參數的模型中表現最佳,而RSLoRA在14B參數以上的模型中更有效。參數凍結(只更新特定層或組件)在需要快速微調的場景中表現出最低的延遲,盡管可能會略微降低最終任務的準確性。
全微調的收益遞減:對于24B參數以上的模型,全微調的收益遞減,損失改進通常小于0.02,而能耗翻倍。這表明在大規模模型適應中應優先采用PEFT方法。
DoRA的延遲權衡:DoRA在微調過程中保持了穩定的損失,但引入了顯著的延遲開銷,使其更適合于批處理微調管道,而不是實時或延遲敏感的部署場景。
量化推理效率:
量化對性能的影響:int4后訓練量化顯著提高了資源效率,將內存占用和吞吐量(每秒生成的token數)提高了約3.9倍,但平均任務分數下降了約3–5%。bfloat16在現代Hopper GPU架構上的一致性優于float16,分別在延遲和能耗上分別提高了約6%和9%。
量化精度的選擇:bfloat16在延遲和能耗方面表現優于float16,而int4量化在資源受限的環境中表現出色,尤其是在需要降低內存占用和能耗的場景中。這些結果表明,選擇合適的量化精度對于平衡推理效率和性能至關重要。
第3章:背景
該章節首先提供了關于大型語言模型(LLMs)的基礎知識,以及提升LLMs效率的主要方法。這一章節為后續章節的詳細技術評估和實驗結果提供了必要的背景信息。
3.1 大語言模型(LLMs)
- LLMs的定義和應用:LLMs是基于Transformer架構的復雜神經網絡,通過在大規模文本數據上進行深度學習訓練,能夠捕捉人類語言的復雜細節。這些模型在自然語言生成、復雜推理和問題解決等任務中表現出色,廣泛應用于NLP領域,如機器翻譯、文本摘要、問答系統等。
- 模型規模和訓練成本:LLMs的參數規模從數十億到數千億不等,甚至更大。例如,GPT-3擁有1750億參數,訓練成本高達數百萬美元。這些模型的訓練需要大量的計算資源和能源,限制了它們的廣泛應用。
- 模型架構:LLMs通常基于Transformer架構,采用自注意力機制(Self-Attention)來處理輸入序列。這種架構能夠并行處理輸入序列,有效捕捉長距離依賴關系,但其計算復雜度較高,尤其是隨著序列長度的增加。
3.2 提升LLMs效率的方法
3.2.1 硬件創新
- 現代AI加速器:詳細介紹了GPU和TPU等現代AI加速器的特點和優勢。這些硬件通過大規模并行計算能力顯著提高了LLMs的訓練和推理效率。
- 新型計算架構:探討了神經形態計算芯片和光子計算芯片等新型計算架構的潛力。這些架構通過模擬大腦神經元的稀疏脈沖信號或利用光子進行矩陣運算,有望實現更高的能效比。
- 硬件與軟件的協同設計:強調了硬件和軟件協同設計的重要性,通過定制化的硬件和優化的軟件框架,可以進一步提高LLMs的效率。
3.2.2 軟件優化
- 分布式訓練策略:介紹了數據并行、模型并行和流水線并行等分布式訓練技術,這些技術通過將大型模型的訓練分布在多個設備上,顯著提高了訓練效率。
- 混合精度訓練:討論了使用半精度浮點數(如FP16或bfloat16)進行訓練的優勢,包括減少內存使用量和利用硬件加速提高計算速度。
- 編譯器優化:介紹了深度學習編譯器(如XLA、TVM)的作用,這些編譯器通過操作融合、循環平鋪和內存布局優化等技術,生成高效的硬件執行代碼。
3.2.3 算法改進
- 高效注意力機制:詳細介紹了稀疏注意力機制(Sparse Attention)和多查詢注意力機制(Multi-Query Attention, MQA)等高效注意力機制,這些機制通過限制注意力計算的范圍,顯著降低了計算復雜度。
- 稀疏建模:探討了Mixture-of-Experts(MoE)架構的優勢,這種架構通過增加模型容量,同時在推理時只激活部分參數,顯著提高了模型的效率。
- 訓練過程優化:介紹了課程學習(Curriculum Learning)和數據增強等技術,這些技術通過逐步增加訓練數據的難度或生成更多的訓練樣本,加速模型的收斂速度。
第4章:提升LLMs效率的技術
4.1 LLMs效率的維度(Dimensions of LLM Efficiency)
- 模型大小與參數數量:模型的參數數量直接影響其內存占用和訓練/推理所需的計算資源。
- 計算成本(FLOPs):模型在前向傳播和反向傳播過程中所需的浮點運算次數。
- 吞吐量(Throughput):模型在單位時間內處理數據的速度,通常以每秒處理的token數或樣本數衡量。
- 延遲(Latency):從輸入到輸出的時間延遲,對于實時應用尤為重要。
- 內存占用(Memory Footprint):模型在訓練和推理過程中占用的內存大小。
- 能耗(Energy Consumption):模型在訓練和推理過程中消耗的電能,通常以瓦特(W)或千瓦時(kWh)衡量。
這些維度共同決定了LLMs在實際應用中的效率和可行性。
4.2 預算效率:擴展法則(Budget Efficiency: Scaling Laws)
- 擴展行為和冪律關系(Scaling Behavior and Power Laws):Kaplan等人發現,模型性能(如交叉熵損失或困惑度)與模型參數數量和訓練數據量之間存在冪律關系。這種關系表明,隨著模型規模的增加,性能會逐步提升,但提升的幅度逐漸減小。
- 計算最優模型擴展(Compute-Optimal Model Scaling):Hoffmann等人提出了計算最優模型的概念,即在給定的計算預算下,存在一個最優的模型規模和數據量組合,能夠實現最佳性能。例如,Chinchilla模型通過增加訓練數據量,顯著提升了性能,同時減少了模型參數數量。
- 數據約束和質量(Data Constraints and Quality):在數據受限的情況下,模型規模的增加可能會導致性能提升的收益遞減。因此,數據質量的提升和有效的數據利用策略對于提高模型效率至關重要。
- 開放問題(Open Problems in Scaling):盡管擴展法則提供了指導,但在實際應用中仍存在許多問題,例如如何在大規模模型中實現有效的訓練、如何處理數據分布的變化等。
4.3 數據效率(Data Efficiency)
數據效率是指如何在有限的數據量下最大化模型的性能。主要方法包括:
- 數據質量與過濾(Importance of Data Quality and Filtering):通過去除重復、低質量或不相關的數據,提高訓練數據的質量,從而提高模型的效率。
- 課程學習(Curriculum Learning):按照從簡單到復雜的順序逐步訓練模型,類似于人類的學習過程,可以提高模型的收斂速度和最終性能。
- 數據增強和合成數據(Data Augmentation and Synthetic Data):通過生成額外的訓練數據或對現有數據進行變換,增加數據的多樣性,從而提高模型的泛化能力。
4.4 架構效率(Architecture Efficiency)
架構效率涉及對模型架構的優化,以減少計算和內存需求。主要方法包括:
- 高效注意力機制(Efficient Attention Mechanisms):例如,多查詢注意力(MQA)、分組查詢注意力(GQA)、多頭潛在注意力(MLA)和原生稀疏注意力(NSA)等變體,通過減少計算復雜度或內存占用來提高效率。
- 高效位置編碼(Efficient Positional Encoding):改進位置編碼方法,如相對位置編碼(Relative Positional Encoding)和旋轉位置編碼(Rotary Positional Encoding),以更好地處理長序列。
- 稀疏建模(Sparse Modeling):通過Mixture-of-Experts(MoE)等技術,實現條件計算,減少每次推理時激活的參數數量。
- 注意力替代方案(Attention-Free Alternatives):探索不依賴自注意力機制的模型架構,如循環神經網絡(RNN)和狀態空間模型(State Space Models),以進一步降低計算復雜度。
4.5 訓練和微調效率(Training and Tuning Efficiency)
這一部分討論了如何在訓練和微調階段提高LLMs的效率。主要方法包括:
- 可擴展訓練策略(Scalable Training Strategies):例如,混合精度訓練、數據并行、模型并行和流水線并行等技術,通過充分利用硬件資源,加速大規模模型的訓練。
- 參數高效微調(PEFT):通過只更新模型的一小部分參數(如LoRA、RSLoRA、DoRA等),顯著減少微調所需的計算資源,同時保持模型性能。
- 訓練效率的系統優化:通過優化訓練過程中的各種參數(如學習率、批大小等),進一步提高訓練效率。
4.6 推理效率(Inference Efficiency)
推理效率涉及在模型部署階段如何提高效率。主要方法包括:
- 模型壓縮技術(Model Compression Techniques):例如,量化(Quantization)、剪枝(Pruning)和知識蒸餾(Knowledge Distillation),通過減少模型大小和計算需求,提高推理速度和能效。
- 算法級推理優化(Algorithm-Level Inference Optimizations):例如,稀疏注意力機制、高效解碼算法(如Speculative Decoding)等,通過優化算法實現更高的推理效率。
- 系統級優化和部署(System-Level Optimizations and Deployment):通過優化硬件資源的使用(如內存管理、多任務調度)和部署策略(如模型分片、分布式推理),進一步提高模型在實際應用中的效率。
第5章:評估
第5章“評估”(Assessment)是論文中對EfficientLLM框架進行系統性評估的核心部分。這一章節詳細介紹了EfficientLLM框架的評估原則、實驗設置、以及針對架構預訓練、訓練和微調、量化推理等不同維度的具體實驗結果。以下是該章節的詳細介紹:
5.1 EfficientLLM評估原則(Assessment Principles of EFFICIENTLLM)
在這一部分,作者提出了EfficientLLM框架的評估原則,旨在全面評估LLMs在不同效率優化技術下的表現。評估原則包括以下六個核心指標:
- 平均內存利用率(Average Memory Utilization, AMU):衡量模型在訓練和推理過程中內存的使用效率。
- 峰值計算利用率(Peak Compute Utilization, PCU):評估GPU等硬件資源在訓練過程中的利用率。
- 平均延遲(Average Latency, AL):衡量模型在推理過程中從輸入到輸出的平均時間延遲。
- 平均吞吐量(Average Throughput, AT):評估模型在單位時間內處理數據的能力。
- 平均能耗(Average Energy Consumption, AEC):衡量模型在訓練和推理過程中消耗的電能。
- 模型壓縮率(Model Compression Rate, MCR):評估模型在壓縮后的大小與原始大小的比例。
這些指標共同捕捉了硬件資源的飽和度、延遲-吞吐量平衡和碳成本,為全面評估LLMs的效率提供了科學依據。
5.2 EfficientLLM實驗設置(Preliminaries of EFFICIENTLLM)
在這一部分,作者詳細介紹了EfficientLLM框架的實驗設置,包括:
- 模型列表(Curated List of LLMs):實驗涵蓋了多種LLMs,包括LLaMA 3系列、DeepSeek-R1系列、Qwen 2.5系列、Phi系列、Yi系列等,參數規模從0.5B到72B不等。
- 實驗數據集(Experimental Datasets):使用了多個數據集,如FineWeb-Edu(教育領域數據集)、OpenO1-SFT(文本生成數據集)、Medical-o1-reasoning-SFT(醫學領域數據集)等,以評估模型在不同任務上的表現。
這些設置確保了實驗的全面性和可重復性,為后續的詳細評估提供了基礎。
5.3 架構預訓練效率評估(Assessment of Architecture Pretraining Efficiency)
在這一部分,作者評估了不同架構優化技術在預訓練階段的效率表現,包括:
- 高效注意力機制(Efficient Attention Mechanisms):比較了MQA、GQA、MLA和NSA等不同注意力機制在內存利用率、延遲、吞吐量、能耗和困惑度方面的表現。例如,MQA在內存和延遲方面表現出色,而MLA在困惑度方面表現最佳。
- 稀疏建模(Sparse Modeling via MoE):評估了Mixture-of-Experts(MoE)架構在預訓練階段的效果。MoE通過增加模型容量,同時在推理時只激活部分參數,顯著提高了模型的效率。
- 注意力替代方案(Attention-Free Alternatives):探討了不依賴自注意力機制的模型架構,如Mamba、Pythia和RWKV等,這些架構在內存和能耗方面表現出色,但在困惑度上有所妥協。
這些評估結果為研究人員和工程師在設計和訓練LLMs時提供了重要的參考。
5.4 訓練和微調效率評估(Assessment of Training and Tuning Efficiency)
在這一部分,作者評估了多種參數高效微調方法(PEFT)在不同模型規模下的效率和性能,包括:
- LoRA及其變體(LoRA, LoRA-plus, RSLoRA):LoRA通過在模型中插入低秩分解矩陣來更新參數,顯著減少了微調所需的計算資源。RSLoRA在更大規模模型中表現出更高的效率。
- 參數凍結(Parameter Freezing):通過凍結模型的大部分參數,只更新特定層或組件,顯著降低了微調的延遲,但可能會略微降低最終任務的準確性。
- 全微調(Full Fine-Tuning):雖然全微調可以實現最佳性能,但在大規模模型中,其收益遞減,能耗顯著增加。
這些評估結果為研究人員和工程師在選擇合適的微調方法時提供了重要的指導。
5.5 量化推理效率評估(Assessment of Bit-Width Quantization Inference Efficiency)
在這一部分,作者評估了不同量化精度(如bfloat16、float16、int4)對模型推理效率和性能的影響,包括:
- 量化精度的選擇:int4量化顯著提高了資源利用率,將有效顯存容量增加了約4倍,吞吐量提高了約3倍,同時僅導致性能輕微下降(3–5個百分點)。bfloat16在延遲和能耗方面表現優于float16。
- 量化對性能的影響:雖然量化可以顯著提高推理效率,但可能會對模型性能產生一定影響。例如,某些任務(如數學推理)對量化精度更為敏感。
這些評估結果為研究人員和工程師在選擇合適的量化技術時提供了重要的參考。
第6章:EfficientLLM基準的可擴展性
該章節探討了EfficientLLM框架在不同模態(語言、視覺、多模態)和不同模型規模下的可擴展性。這一章節通過將EfficientLLM框架應用于大型視覺模型(LVMs)和視覺語言模型(VLMs),驗證了這些效率技術在不同領域的適用性和有效性。
6.1 Transformer基礎的LVMs架構預訓練效率(Efficiency for Transformer Based LVMs Architecture Pretraining)
這一部分將EfficientLLM框架中的效率技術應用于大型視覺模型(LVMs),特別是基于Transformer架構的模型。實驗結果表明,這些技術在視覺領域同樣有效,能夠顯著提升模型的預訓練效率。具體評估內容包括:
- 高效注意力機制:例如,將MQA、GQA等注意力機制應用于視覺Transformer模型,如DiT(Diffusion Transformer)架構。實驗結果表明,這些注意力機制在視覺生成任務中能夠顯著降低內存占用和計算復雜度,同時保持較高的生成質量。
- 稀疏建模(MoE):將MoE技術應用于視覺Transformer模型,通過條件計算減少每次推理時激活的參數數量。實驗結果表明,MoE在視覺生成任務中能夠顯著提高模型的效率,同時保持生成質量。
- 注意力替代方案:例如,將Mamba(基于狀態空間模型的注意力替代方案)應用于視覺生成任務。實驗結果表明,Mamba在內存和能耗方面表現出色,但在生成質量上有所妥協。
6.2 PEFT在LVMs上的評估(Assessment of PEFT on LVMs)
這一部分評估了參數高效微調(PEFT)方法在大型視覺模型(LVMs)中的表現。實驗結果表明,PEFT方法在視覺領域同樣有效,能夠顯著減少微調所需的計算資源。具體評估內容包括:
- LoRA及其變體:例如,LoRA、LoRA-plus和RSLoRA等方法在視覺Transformer模型中的表現。實驗結果表明,這些方法在視覺生成任務中能夠顯著減少微調所需的計算資源,同時保持較高的生成質量。
- 參數凍結:通過凍結模型的大部分參數,只更新特定層或組件,顯著降低了微調的延遲。實驗結果表明,參數凍結在視覺生成任務中表現出色,尤其是在需要快速微調的場景中。
6.3 PEFT在VLMs上的評估(Assessment of PEFT on VLMs)
這一部分評估了參數高效微調(PEFT)方法在視覺語言模型(VLMs)中的表現。實驗結果表明,PEFT方法在多模態任務中同樣有效,能夠顯著減少微調所需的計算資源。具體評估內容包括:
- LoRA及其變體:例如,LoRA、LoRA-plus和RSLoRA等方法在視覺語言模型中的表現。實驗結果表明,這些方法在多模態任務中能夠顯著減少微調所需的計算資源,同時保持較高的任務性能。
- 參數凍結:通過凍結模型的大部分參數,只更新特定層或組件,顯著降低了微調的延遲。實驗結果表明,參數凍結在多模態任務中表現出色,尤其是在需要快速微調的場景中。
6.4 PEFT在多模態模型上的評估(Assessment of PEFT on Multimodal Models)
這一部分進一步探討了PEFT方法在多模態模型中的表現,特別是在處理視覺和語言任務時的效率和性能。實驗結果表明,PEFT方法在多模態任務中能夠顯著減少微調所需的計算資源,同時保持較高的任務性能。具體評估內容包括:
- 多模態任務的挑戰:多模態任務需要模型同時處理視覺和語言信息,這增加了模型的復雜性和計算需求。PEFT方法通過只更新模型的一小部分參數,顯著減少了微調所需的計算資源。
- 實驗結果:通過在多個多模態任務上進行實驗,驗證了PEFT方法在多模態模型中的有效性。實驗結果表明,PEFT方法在多模態任務中能夠顯著減少微調所需的計算資源,同時保持較高的任務性能。
第7章:相關工作
該章節總結了與EfficientLLM框架相關的現有研究成果,還討論了這些研究的局限性和未來的研究方向。
7.1 分布式訓練和系統級優化(Distributed Training and System-Level Optimizations)
- 分布式訓練:介紹了如何通過數據并行、模型并行和流水線并行等技術,將大型模型的訓練分布在多個設備上,以提高訓練效率。這些技術通過優化數據傳輸和計算資源的利用,顯著減少了訓練時間。
- 系統級優化:討論了如何通過硬件和軟件的協同設計,進一步提高訓練效率。例如,使用高效的編譯器和優化的內存管理策略,可以減少訓練過程中的開銷。
- 現有工具和框架:介紹了如DeepSpeed、Megatron-LM等工具和框架,這些工具通過提供高效的并行化策略和優化技術,使得訓練大型模型成為可能。
7.2 對齊和強化學習效率(Alignment and RLHF Efficiency)
- 對齊技術:討論了如何通過強化學習從人類反饋(Reinforcement Learning from Human Feedback, RLHF)來對齊大型語言模型的行為,使其更符合人類的偏好和價值觀。這種技術通過訓練一個獎勵模型,并使用策略優化算法(如PPO)來優化模型的行為。
- 效率挑戰:雖然RLHF可以顯著提高模型的對齊效果,但它本身是一個資源密集型的過程。訓練獎勵模型和執行策略優化都需要大量的計算資源,這增加了模型訓練的復雜性和成本。
- 未來方向:提出了如何通過更高效的采樣方法、代理模型或知識蒸餾技術來減少RLHF的計算需求,從而提高對齊過程的效率。
7.3 推理時間加速策略(Inference-Time Acceleration Strategies)
- 動態推理方法:介紹了如動態路由、早停機制和稀疏激活等技術,這些技術通過在推理過程中根據輸入的復雜性動態調整計算資源的使用,顯著提高了推理速度。
- 現有方法:討論了如Speculative Decoding、Early Exiting等方法,這些方法通過提前生成或停止計算,減少了不必要的計算開銷。
- 未來方向:提出了如何通過進一步優化這些動態推理方法,以及開發新的算法來提高推理效率,特別是在資源受限的環境中。
7.4 動態路由和模型級聯(Dynamic Routing and Model Cascades)
- 動態路由:討論了如何通過動態路由技術,根據輸入的復雜性選擇合適的模型或模型組件進行推理。這種方法可以顯著減少推理過程中的計算資源消耗。
- 模型級聯:介紹了模型級聯的概念,即通過級聯多個模型來處理不同復雜度的任務,從而提高整體的推理效率。
- 未來方向:提出了如何通過開發更智能的路由機制和優化級聯策略,進一步提高動態路由和模型級聯的效率。
7.5 硬件感知訓練計劃(Hardware-aware Training Schedules)
- 硬件感知優化:討論了如何通過自動調度器(Auto-schedulers)來優化訓練過程中的并行化策略,以充分利用不同硬件配置的計算能力。
- 現有工具:介紹了如Zeus等工具,這些工具通過動態調整訓練過程中的并行化策略,提高了訓練效率。
- 未來方向:提出了如何通過進一步開發和優化這些自動調度器,使其能夠更好地適應不同的硬件環境和訓練任務。
7.6 討論(Discussion)
- EfficientLLM框架的局限性:討論了EfficientLLM框架的局限性,包括未涵蓋所有效率技術、硬件和基礎設施的限制、模型和任務覆蓋范圍有限、評估指標的靜態性以及缺乏經濟分析。
- 未來研究方向:提出了未來研究的挑戰和方向,如
多目標擴展法則、異構質量語料庫的優化、長上下文預訓練的課程設計、稀疏路由策略、非Transformer架構的優化、多模態和工具增強LLMs的PEFT、長序列的魯棒量化等。
結論
- 總結:總結了EfficientLLM框架的主要貢獻,強調了通過系統評估效率技術,為LLMs的設計和部署提供了重要的指導。
- 實際意義:指出這些發現為研究人員和從業者提供了明確的行動指南,幫助他們在實際應用中優化LLMs的效率和可持續性。








)





)

)
 recorder-core)

