摘要:本文整理自淘天集團高級數據開發工程師朱奧老師在 Flink Forward Asia 2024 流式湖倉論壇的分享。內容主要為以下五部分:
1、項目背景
2、核心策略
3、解決方案
4、項目價值
5、未來計劃
01、項目背景
1.1 當前實時數倉架構
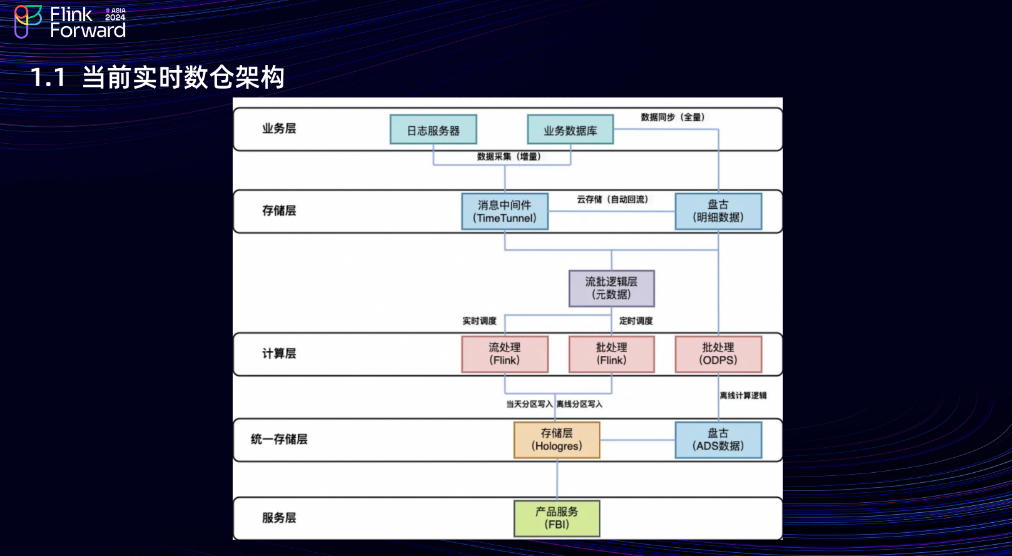
當前的淘天實時架構是從日志服務器和業務數據庫采集數據,實時數據采集到 TT (消息隊列中間件,對標 Kafka)中,離線數據采集到盤古存儲中;在公共層會啟一個流批任務做流批計算,實時運行流任務,定時調度批任務;在計算層,實時和離線數據會寫到 Hologres(OLAP 組件)中,服務層的數據產品會基于 Hologres 表做數據產品的搭建和數據看板的展示。可以看到,數據直接從 DWD 層寫到 ADS 層,沒有實時的DWS層,因為TT 不支持去重,Kafka 同樣如此。我們希望有一個流批一體的統一存儲組件,能把實時的 DWS 層建設好,并且公共層數據可見。
1.2 業務訴求與核心痛點

2024年初以來,業務方主要有兩個訴求,第一個是希望有更多的實時數據產品,第二個是業務 BI希望自定義的數據分析。這兩個訴求對流批數據開發效率提出一個很大的挑戰。當前流批數據鏈路的核心痛點,第一,流批存儲不統一,實時是 TT,離線是 ODPS;第二,實時數據的可見性差,TT 數據對于用戶不可見,TT 里面每一條數據都是一條字符串,業務無法直接基于字符串進行 OLAP 分析,雖然TT數據可以導出到離線分析,但數據時效性會降低到小時級或天級,并且有開發成本;第三,沒有實時 DWS 中間層;第四,中間的流批一體開發效率比較低,推廣比較困難,相關的工具化也比較弱;第五,沒有一個高效易用的分鐘級近實時數據加工方案。
02、核心策略
2.1 Paimon 技術引入

我們引入了Paimon 的技術,期望基于 Paimon 構建湖倉公共層的流批一體存儲,統一流批數據口徑,并且提高數據的可復用性。從系統架構角度,我們拿 Paimon 和 TT 做了對比,可以看到TT的性能可以達到 6000 萬每秒,這個是業務的峰值,非TT系統峰值。Paimon 底層是盤古 HDFS,對于非主鍵表峰值可達 4000 萬/秒,而主鍵表如 Page 日志,峰值可達 1200 萬/秒,雖然峰值比不上 TT,但對于業務已經夠用。穩定性方面,TT 用了很多年,幾乎沒有穩定性問題。Paimon 于今年開始使用,經歷了 618 和雙 11 大促等高并發場景,整體運行穩定。擴展性方面,TT 和 Paimon 都是分布式的架構,易擴展。TT 支持日志采集和數據的 Binlog 接入,Paimon 本身不具備這些功能,通過和FlinkCDC 結合可以支持這些功能。

從業務角度,當前 TT 的成本高,而Paimon 只收取存儲費用,實時訂閱不收費,存儲在 HDFS 中,成本相對較低;在時效性方面,TT 更優是毫秒級,Paimon 是分鐘級;TT 實時數據存儲和離線ODPS存儲,不是一個存儲組件,在建映射表時需要逐個字段對齊離線表和 TT 的 Schema,比較費時費力,Paimon是流批一體存儲,流批數據存儲在一張底表中,不需要對齊 Schema 和口徑,可以提高開發效率;TT不支持OLAP分析,Paimon 目前支持 Hive,Hologres OLAP分析和 Flink 查詢;TT 需要全量拉取數據反序列化,把數據解析出來再根據某個字段過濾,Paimon 支持分區的存儲,并且存儲的數據有 Schema,可以使用分區過濾,特別像一些回追數據、分流的場景,用 Paimon 只需要讀取分流或者當天對應的分區,不用回追更早的歷史數據,以達到非常精準的過濾。
2.2 Hologres 動態表技術引入

第二個技術是Hologres,我們使用 Hologres 動態表做倉的建設。基于 Hologres 構建全增量一體的數倉分層,提升流批一體開發的效率,降低資源消耗。Hologres 支持增量計算,分鐘級更新數據,可以滿足業務的近實時需求;支持 Serverless 執行,將Hologres批任務提交到一個極大的共享資源池,批數據調度和回刷極快,同時支持自動規避機器的熱點,顯著提升運維效率;湖倉一體是指 Hologres 已實現直接讀取 Paimon 的湖表數據,而數據湖本身具備開放性,可以實現高效的近實時的湖倉架構方案。
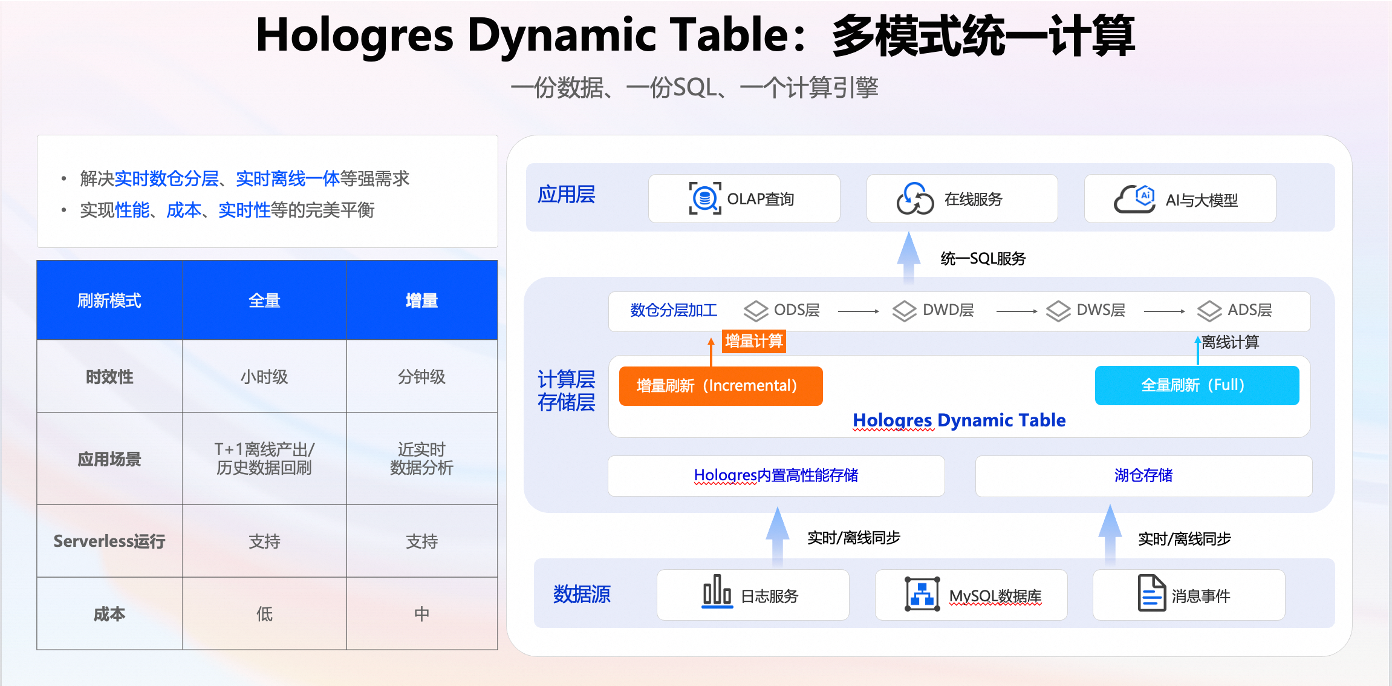
這是 Hologres 的一張圖,從最下面的數據源采集,采集完之后導入到存儲,在公共層用 Paimon 完成搭建后,在數倉的計算層主要用 Hologres 的增量更新和全量更新來計算,計算結果也會存儲在 Hologres 表中。基于Hologres 表做一些 OLAP 的查詢,在應用層服務于在線服務和 AI 大模型。
2.3 湖倉一體能力建設

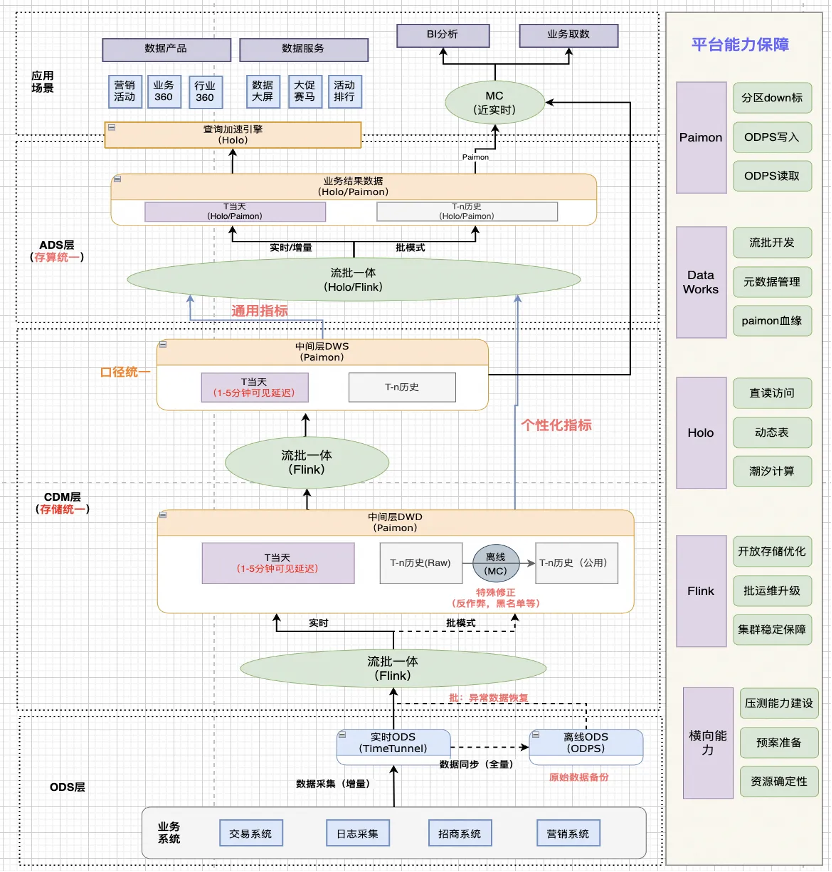
湖倉一體的能力建設是指基于 Paimon 構建湖倉公共層,然后基于Hologres 構建全增量一體的湖倉分層,還包括湖倉流批一體的能力建設、豐富的應用場景以及相關的平臺保障能力的建設。
03、解決方案
3.1 公共層入湖方案架構

關于公共層入湖,首先做一個環境驗證,開始排期開發搭建鏈路,最后在雙 11 做大促驗證。公共層入口的范圍主要包括交易,日志、預售架構和流量通道等

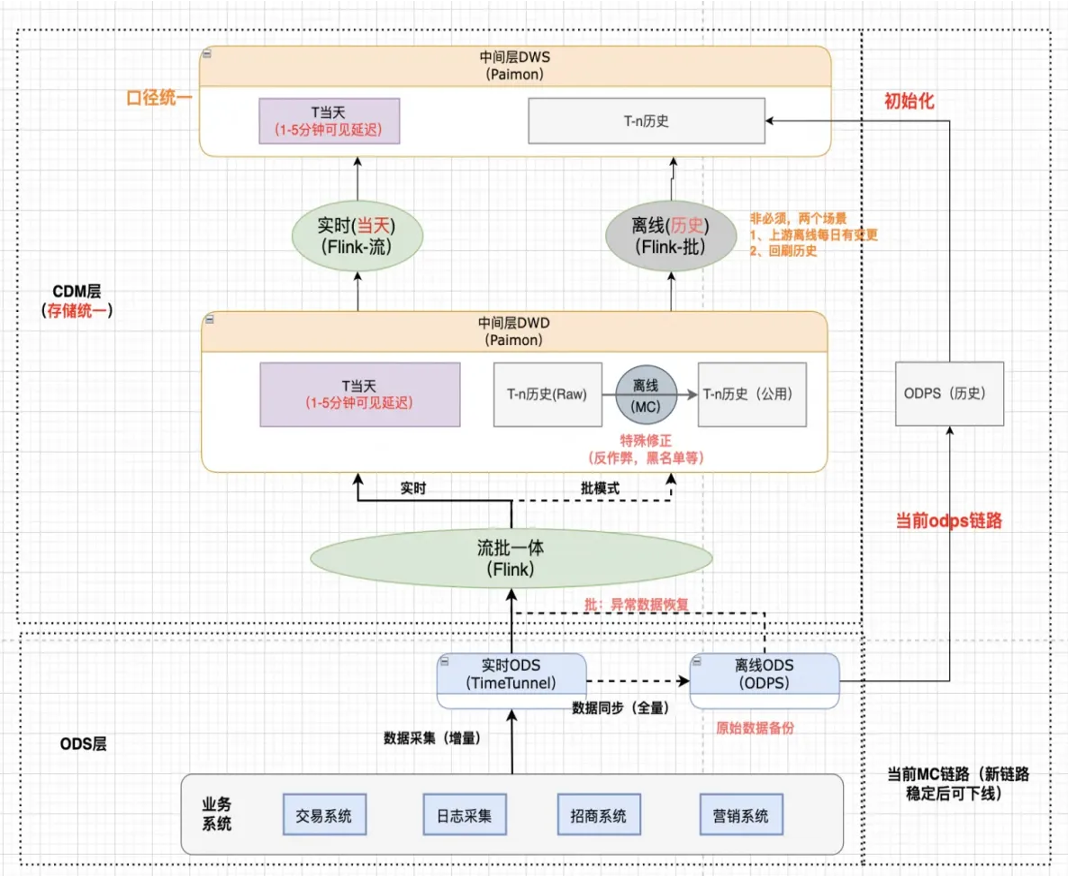
Paimon 的一個功能是數據分支功能—Branch,離線表默認是存儲在 Master 分支,實時的 Paimon 表默認存儲在 RT 分支,對于下游的業務,透出的是同一張 Paimon 表,業務在使用這張表的時候,默認會讀 Master 分支,即離線數據。如果離線數據讀不到,會去 RT分支上讀實時的數據,可以解決實時數據延遲覆蓋離線數據的問題。同時,Paimon支持不同with表參數的能力。比如實時場景,可能需要一張去重表,離線場景,可能就只需要append表。
3.2 愛橙交易域公共層入湖
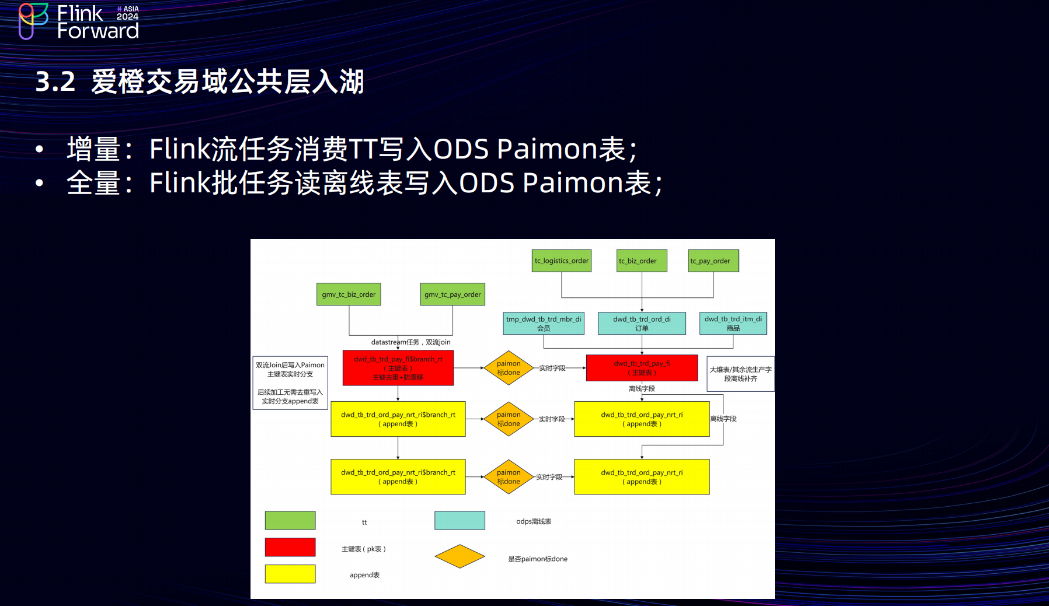
在愛橙的公共層入湖鏈路中,增量用 Flink 流任務消費 TT 寫到 ODS Paimon 表當中,全量任務用 Flink 批任務讀離線表,寫入 ODS Paimon 表中。架構圖最上面的是 TT,TT 會導到 ODPS 離線表中,然后會基于 Paimon 建PK表做數據去重。
3.3 愛橙流量域公共層入湖

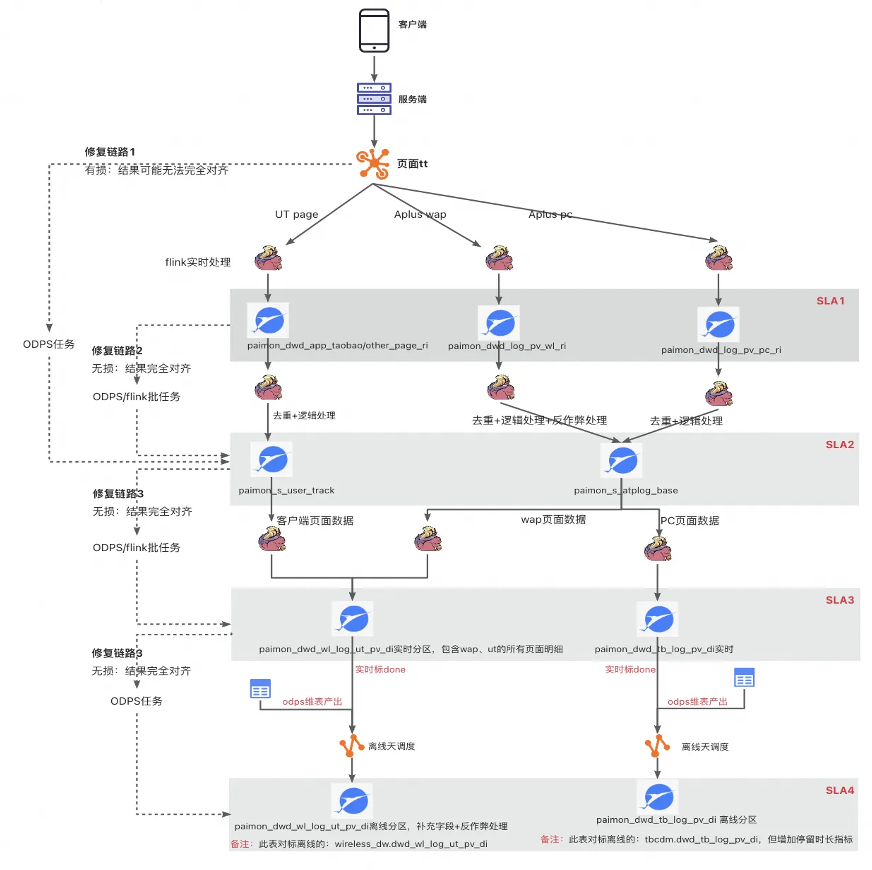
愛橙的流量域相對于交易域,數據要大很多,并且流量域的場景也更加復雜。我們把流量域分成四種服務協議等級來做保障,分別是 SLA1 到 4。第一種支持實時和離線,時效性在五分鐘以內,和對應的 TT 完全對齊;第二種,實時表和離線表測會有一些差異,缺少反作弊過濾;第三種缺少一些反作弊的維表過濾還有排序相關的一些字段;第四種只支持離線,和對應的離線表完全對齊。
在流量域公共層的架構圖中,首先是數據采集,從前端埋點采集到服務端,然后寫到 TT 中,主要是用 Flink 做一些計算,分別寫到不同的 Paimon 明細表中。因為流量域的日志字段比較復雜,比如一張流量表當中有 100 個字段,可能有 95 個字段是實時產出的,有另外五個字段,像反作弊和排序的字段不能實時產出,就會起一條修復的鏈路,用離線去回補這五個字段,反作弊和排序只能在離線算。實時也會做去重的邏輯處理,最后的數據寫到 DWD 層的 Paimon 表中,下游業務會基于 Paimon 表來建設 Paimon 的 DWS 層。
3.4 淘天公共層入湖
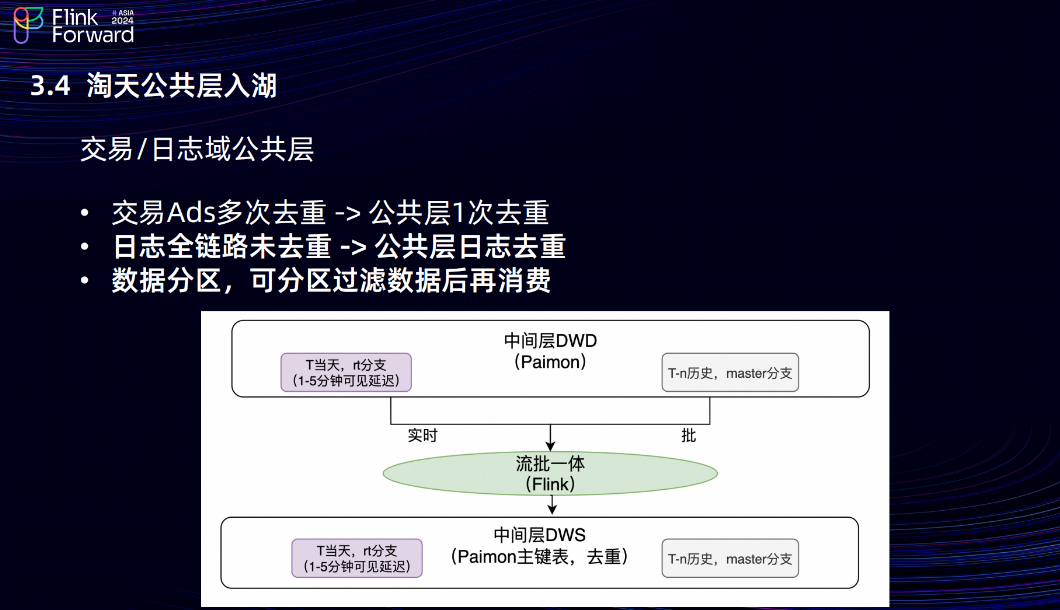
然后是淘天公共層的入湖。淘天公共層的上游是愛橙,主要把交易域和日志域的公共層入湖,我們做的工作主要分三點。第一點,以前的交易實時公共層沒有去重,下游每一個 ADS 任務在消費 TT 的時候都要單獨做一次去重;我們把交易日志放在公共層用paimon去重,只需要去重一次,1次公共層去重抵得上N次ADS去重,收益非常高,Flink 比較難解的一個場景是去重的時候 State 如果過大任務會不穩定,這也有效提高了ADSFlink任務的穩定性;第二個是日志鏈路,之前全鏈路日志都沒有去重,這會產生一個問題,如果日志的實時任務重啟,對于下游的業務數據會重復,體現在數據產品上,如果上個小時對比昨天的數據增長 5%,下個小時差不多也增長 5%,但當前重啟的小時會增長百分之十幾。基于 Paimon 在公共層做日志去重,收益是不管任務重啟多少次,下游消費的數據都不會重復,都是exactly-once的語義。最后是數據的分區,Paimon 支持數據的分區,可以分區過濾數據后再消費,像一些分流的場景也可以把分流的 Tag 作為一個分區,下游消費的時候就不需要反序列化全量數據,只需要消費對應 Tag 的數據就可以,節省下游消費任務的計算資源。
3.5 基于 Hologres Dynamic Table 構建 ADS 近實時湖倉分層

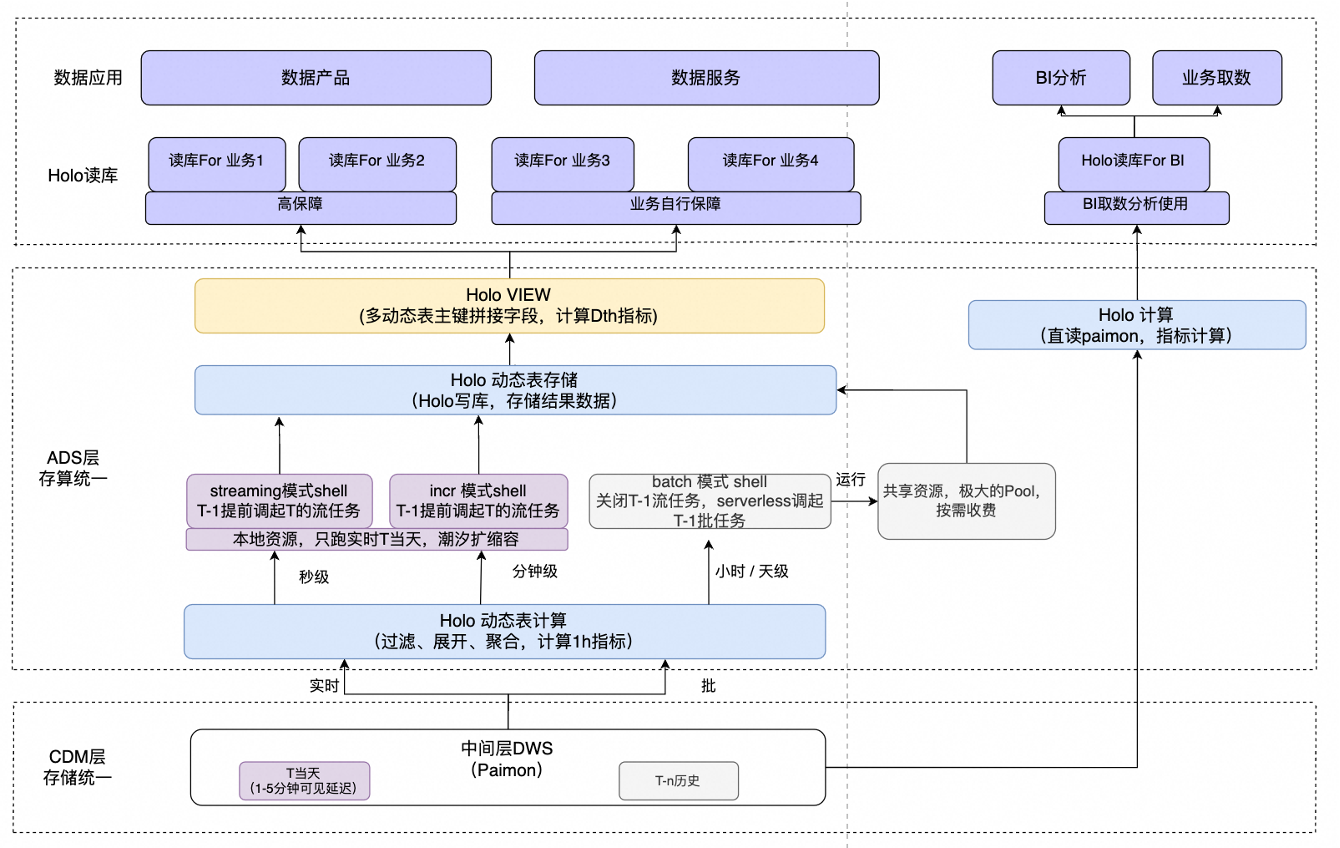
我們基于 Hologres 的動態表來構建 ADS層近實時的湖倉分層。Hologres 的外表支持直讀DWS層 Paimon表,并且可以做分鐘級的增量計算和離線場景的批計算,數據會在 ADS 層做動態表的過濾,展開,聚合和計算,分為增量和批兩種方式,增量任務用獨占的本地集群運行,批任務會提交一個極大的共享資源池中,共享資源池按需收費,并且它的資源比較大,可以用整個集群的資源瞬時跑批任務,運行速度極快,計算結果存儲在動態表中,然后用Hologres 視圖拼接多個動態表字段,視圖的作用是方便展示和開窗計算 DTH 指標。業務基于 Hologres 表做讀寫分離,分為高保障的和業務自行保障兩個等級。業務在讀庫上搭建數據產品和數據服務。
Hologres 已經支持直讀 Paimon。之前如果業務 BI 有一些需求提過來,需要數據開發搭建一條完整的數據鏈路,在數據產品上展示;Hologres 支持直讀 Paimon 后,如果業務 BI 有一些比較自定義的需求,并且需求不是很復雜,他完全可以自己通過 Hologres 直讀 Paimon 的中間層DWS 表,自己做一些簡單的數據開發和分鐘級報表搭建,這樣可以極大的節省實時數據研發的成本。同時,對于 BI 的取數效率也是巨大的提高。
04、項目價值

- 數據時效性提升:中間層產出效率提升,流量表產出時效提前40-60分鐘;
- 實時開發運維效率提升:流批一體,實時開發和運維效率提升50%以上,開發驗證時長從5天->2天,回刷速度提高15倍;
- 實時數據使用門檻下降:業務和BI同學獲取中間層分鐘級實時數據以支持臨時實時分析場景;
- 成本下降:存儲換用更廉價的hdfs,實時dws建設可降低tt重復讀取成本和下游去重成本;
05、未來計劃
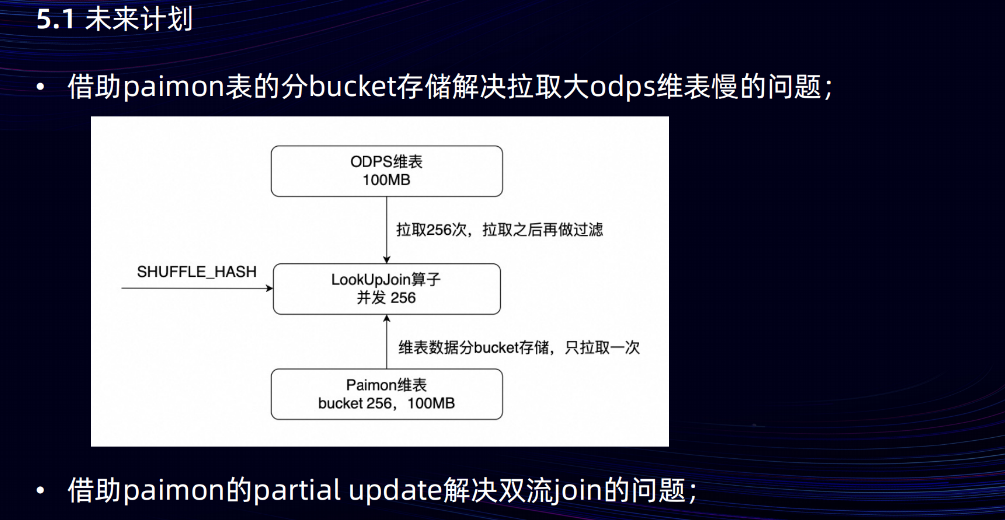
Paimon 表目前在雙 11 大促取得的效果比較好,后面會在集團內繼續大力推廣。第一部分是希望借助 Paimon 表的分 Bucket 存儲來解決拉取大ODPS維表 比較慢的問題。Flink 任務在重啟時,對于ODPS大維表, LookUpJoin算子是先拉取再過濾,全量數據會拉取多次,對于Paimon維表,LookUpJoin算子只拉取join key對應bucket的數據,全量數據只拉取一次,任務重啟時間從二三十分鐘提升到秒級。
第二個是希望借助 Paimon 的 Partial Update 解決雙流 Join 的問題。

第三個是希望在 Hologres 的全增量直讀湖基礎上,新增全增量的寫湖能力,主要是 Paimon 相關的和 OLAP 引擎的打通,也是增強的 Paimon 的開放性,擴展 Hologres 的動態表在近實時的湖倉分層應用的場景;第四個是希望后面探索用 Fluss 做流存儲的組件,希望可以用它代替像 Kafka,TT 等消息隊列組件;第五個,后面會沉淀新一代的湖倉數據架構,在集團內大范圍推廣。基于目前已經在 618 和雙 11 做的Paimon 探索,整體表現符合預期,甚至超出預期,在集團內已具備大范圍推廣基礎。





)





)

)
 recorder-core)


![[AI]大模型MCP快速入門及智能體執行模式介紹](http://pic.xiahunao.cn/[AI]大模型MCP快速入門及智能體執行模式介紹)

