[AI]大模型MCP快速入門及智能體執行模式介紹
一、MCP入門
介紹
MCP(Model Context Protocol,模型上下文協議)是一種由Anthropic公司于2024年提出的開放標準協議,旨在為大型語言模型(LLM)提供統一接口,使其能夠安全、便捷地連接外部數據源、工具和系統,從而突破傳統AI模型因數據孤島限制而無法實時獲取信息的瓶頸。
在MCP協議出來之前,各個大型AI公司各自為戰,大模型對外接口不統一,以至于我們開發了一個功能,比如AI操作數據庫。適配了ChatGPT,但是對于Deepseek模型卻不通用,導致需要重新開發一遍適配Deepseek的接口。效率極低,并且都是重復操作。
將MCP想象成一個“萬能插座”或“通用翻譯官”。就像不同電器通過統一的USB-C接口充電一樣,MCP為所有AI模型和數據源制定了標準化的通信規則。例如,當你想讓AI助手查詢公司數據庫時,MCP就像一位翻譯官,將AI的請求轉換成數據庫能理解的語言,再將結果翻譯回AI能處理的形式,整個過程無需開發者編寫復雜的定制代碼
工作流程:
用戶提問 → AI Host生成請求(運行AI的程序,比如IDE,cursor等) → MCP Client轉發 → MCP Server執行操作 → 返回結果 → AI生成最終回答
##基礎入門
我們將手動編寫一個mcp基礎案例,通過調用大模型完成對本地文件的寫入。
主要包含:
- client.py:連接mcp server,并操作大模型調用server.py提供的功能。
- server.py:對外暴露功能,供大模型調用。
- .env:env配置文件中配置大模型API_KEY、BASE_URL、MODEL等
本案例將通過FastMCP來演示如何快速搭建一個MCP Server,并且與大模型適配上。
實戰
①MCP Server搭建
這里將使用FastMCP來演示如何快速搭建mcp server。
1. 封裝mcp server提供的能力為func
其實這里的步驟就類似于我們之前編寫function_call的時候,將能力封裝為一個函數。然后將func上添加上
@mcp.tool()注解。
from mcp.server.fastmcp import FastMCP@mcp.tool()
def write_to_txt(filename: str, content: str) -> str:"""將指定內容寫入文本文件并且保存到本地。參數:filename: 文件名(例如 "output.txt")content: 要寫入的文本內容返回:寫入成功或失敗的提示信息"""try:with open(filename, "w", encoding="utf-8") as f:f.write(content)return f"成功寫入文件 {filename}。"except Exception as e:return f"寫入文件失敗:{e}"
2. 通過mcp協議暴露該能力
這里我們通過stdio傳輸,因為本案例我們的mcp server和mcp client都會放在一個機器上,所以通過標準的io傳輸數據即可。
目前mcp支持兩種協議:
- stdio:standard input output,標準輸入輸出,適用于mcp client和mcp server部署在同一個機器上,不涉及跨機器。
- sse:Server-Sent Events,服務器發送事件,是一個基于HTTP的協議。適用于mcp client與mcp server不在同一個機器中的場景,涉及網絡傳輸。
if __name__ == "__main__":# 因為我們這里mcp的server端和服務端都在同一個機器上,所以使用stdiomcp.run(transport='stdio') # 默認使用 stdio 傳輸
全部代碼
server.py
from mcp.server.fastmcp import FastMCPmcp = FastMCP("WriterServer")@mcp.tool()
def write_to_txt(filename: str, content: str) -> str:"""將指定內容寫入文本文件并且保存到本地。參數:filename: 文件名(例如 "output.txt")content: 要寫入的文本內容返回:寫入成功或失敗的提示信息"""try:with open(filename, "w", encoding="utf-8") as f:f.write(content)return f"成功寫入文件 {filename}。"except Exception as e:return f"寫入文件失敗:{e}"if __name__ == "__main__":# 因為我們這里mcp的server端和服務端都在同一個機器上,所以使用stdiomcp.run(transport='stdio') # 默認使用 stdio 傳輸
②MCP Client搭建
1. 封裝MCPClient工具
- chat_loop:
- process_query:封裝與大模型的交流,將client讀取到的tools和上下文內容傳給大模型,然后由大模型返回內容
- cleanup:清理資源
2. 封裝connect_to_server連接MCP工具
讀取mcp 服務端文件,通過stdio協議連接
async def connect_to_server(self, server_script_path: str):"""連接到 MCP 服務器參數:server_script_path: 服務器腳本路徑 (.py 或 .js)"""is_python = server_script_path.endswith('.py')is_js = server_script_path.endswith('.js')if not (is_python or is_js):raise ValueError("服務器腳本必須是 .py 或 .js 文件")command = "python" if is_python else "node"# 創建 StdioServerParameters 對象server_params = StdioServerParameters(command=command,args=[server_script_path],env=None)# 使用 stdio_client 創建與服務器的 stdio 傳輸stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))# 解包 stdio_transport,獲取讀取和寫入句柄self.stdio, self.write = stdio_transport# 創建 ClientSession 對象,用于與服務器通信self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))# 初始化會話await self.session.initialize()# 列出可用工具response = await self.session.list_tools()tools = response.toolsprint("\n連接到服務器,工具列表:", [tool.name for tool in tools])
全部代碼
import os
import asyncio
from typing import Optional
from contextlib import AsyncExitStack
import json
import tracebackfrom mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_clientfrom openai import OpenAI
from dotenv import load_dotenv
import sysload_dotenv() # 加載環境變量從 .env文件中加載class MCPClient:def __init__(self):# 初始化會話和客戶端對象self.session: Optional[ClientSession] = None # 會話對象self.exit_stack = AsyncExitStack() # 退出堆棧self.openai = OpenAI(api_key=os.getenv("API_KEY"), base_url=os.getenv("BASE_URL"))self.model = os.getenv("MODEL")def get_response(self, messages: list, tools: list):response = self.openai.chat.completions.create(model=self.model,max_tokens=1000,messages=messages,tools=tools,)return responseasync def get_tools(self):# 列出可用工具response = await self.session.list_tools()available_tools = [{"type": "function","function": {"name": tool.name,"description": tool.description, # 工具描述"parameters": tool.inputSchema # 工具輸入模式}} for tool in response.tools]return available_toolsasync def connect_to_server(self, server_script_path: str):"""連接到 MCP 服務器參數:server_script_path: 服務器腳本路徑 (.py 或 .js)"""is_python = server_script_path.endswith('.py')is_js = server_script_path.endswith('.js')if not (is_python or is_js):raise ValueError("服務器腳本必須是 .py 或 .js 文件")command = "python" if is_python else "node"# 創建 StdioServerParameters 對象server_params = StdioServerParameters(command=command,args=[server_script_path],env=None)# 使用 stdio_client 創建與服務器的 stdio 傳輸stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))# 解包 stdio_transport,獲取讀取和寫入句柄self.stdio, self.write = stdio_transport# 創建 ClientSession 對象,用于與服務器通信self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))# 初始化會話await self.session.initialize()# 列出可用工具response = await self.session.list_tools()tools = response.toolsprint("\n連接到服務器,工具列表:", [tool.name for tool in tools])async def process_query(self, query: str) -> str:"""使用 OpenAI 和可用工具處理查詢"""# 創建消息列表messages = [{"role": "user","content": query}]# 列出可用工具available_tools = await self.get_tools()print(f"\n可用工具: {json.dumps([t['function']['name'] for t in available_tools], ensure_ascii=False)}")# 處理消息response = self.get_response(messages, available_tools)# 處理LLM響應和工具調用tool_results = []final_text = []for choice in response.choices:message = choice.messageis_function_call = message.tool_calls# 如果不調用工具,則添加到 final_text 中if not is_function_call:final_text.append(message.content)# 如果是工具調用,則獲取工具名稱和輸入else:# 解包tool_callstool_name = message.tool_calls[0].function.nametool_args = json.loads(message.tool_calls[0].function.arguments)print(f"準備調用工具: {tool_name}")print(f"參數: {json.dumps(tool_args, ensure_ascii=False, indent=2)}")try:# 執行工具調用,獲取結果result = await self.session.call_tool(tool_name, tool_args)print(f"\n工具調用返回結果類型: {type(result)}")print(f"工具調用返回結果屬性: {dir(result)}")print(f"工具調用content類型: {type(result.content) if hasattr(result, 'content') else '無content屬性'}")# 安全處理contentcontent = Noneif hasattr(result, 'content'):if isinstance(result.content, list):content = "\n".join(str(item) for item in result.content)print(f"將列表轉換為字符串: {content}")else:content = str(result.content)print(f"工具調用content值: {content}")else:content = str(result)print(f"使用完整result作為字符串: {content}")tool_results.append({"call": tool_name, "result": content})final_text.append(f"[調用工具 {tool_name} 參數: {json.dumps(tool_args, ensure_ascii=False)}]")# 繼續與工具結果進行對話if message.content and hasattr(message.content, 'text'):messages.append({"role": "assistant","content": message.content})# 將工具調用結果添加到消息messages.append({"role": "user","content": content})# 獲取下一個LLM響應print("獲取下一個LLM響應...")response = self.get_response(messages, available_tools)# 將結果添加到 final_textcontent = response.choices[0].message.content or ""final_text.append(content)except Exception as e:print(f"\n工具調用異常: {str(e)}")print(f"異常詳情: {traceback.format_exc()}")final_text.append(f"工具調用失敗: {str(e)}")return "\n".join(final_text)async def chat_loop(self):"""運行交互式聊天循環(沒有記憶)"""print("\nMCP Client 啟動!")print("輸入您的查詢或 'quit' 退出.")while True:try:query = input("\nQuery: ").strip()if query.lower() == 'quit':breakprint("\n處理查詢中...")response = await self.process_query(query)print("\n" + response)except Exception as e:print(f"\n錯誤: {str(e)}")print(f"錯誤詳情: {traceback.format_exc()}")async def cleanup(self):"""清理資源"""await self.exit_stack.aclose()async def main():"""主函數:初始化并運行 MCP 客戶端此函數執行以下步驟:1. 檢查命令行參數是否包含服務器腳本路徑2. 創建 MCPClient 實例3. 連接到指定的服務器4. 運行交互式聊天循環5. 在結束時清理資源用法:python client.py <path_to_server_script>如:python client.py server.py"""# 檢查命令行參數if len(sys.argv) < 2:print("Usage: python client.py <path_to_server_script>")sys.exit(1)# 創建 MCPClient 實例client = MCPClient()try:# 連接到服務器await client.connect_to_server(sys.argv[1])# 運行聊天循環await client.chat_loop()finally:# 確保在任何情況下都清理資源await client.cleanup()if __name__ == "__main__":asyncio.run(main())
運行效果
# 運行項目
python client.py server.py
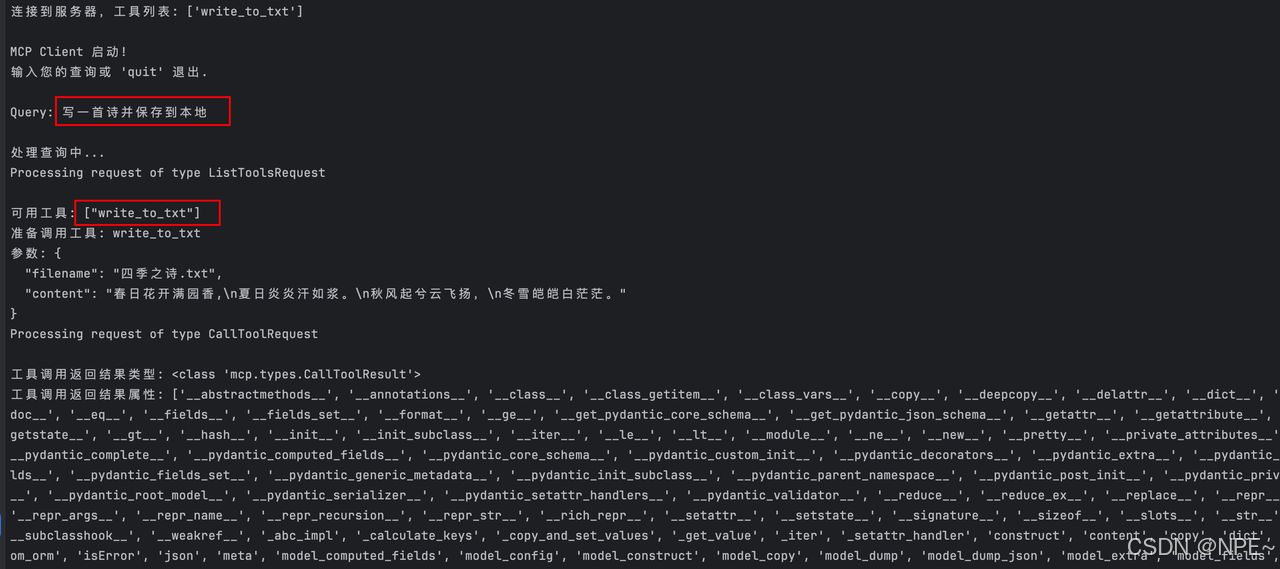
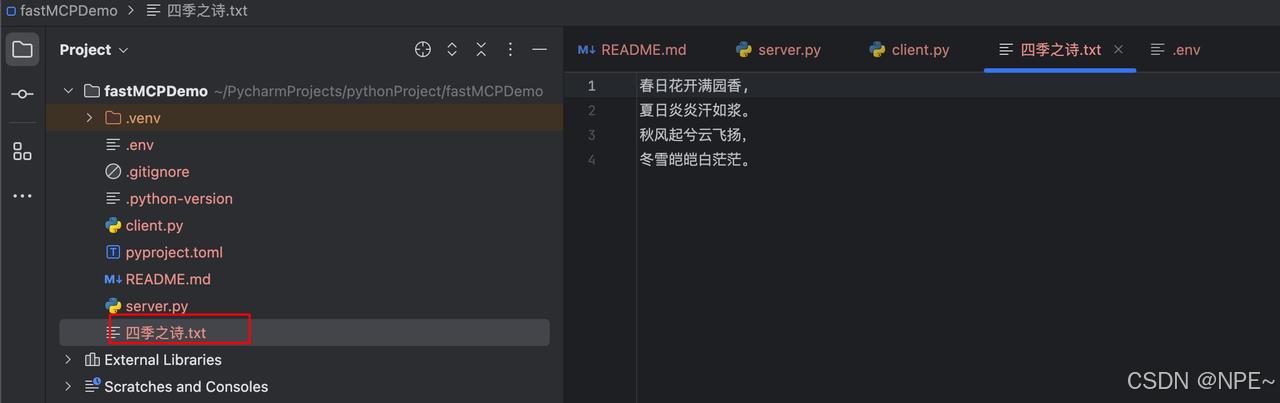
成功寫入到本地:
二、拓展(智能體的執行模式)
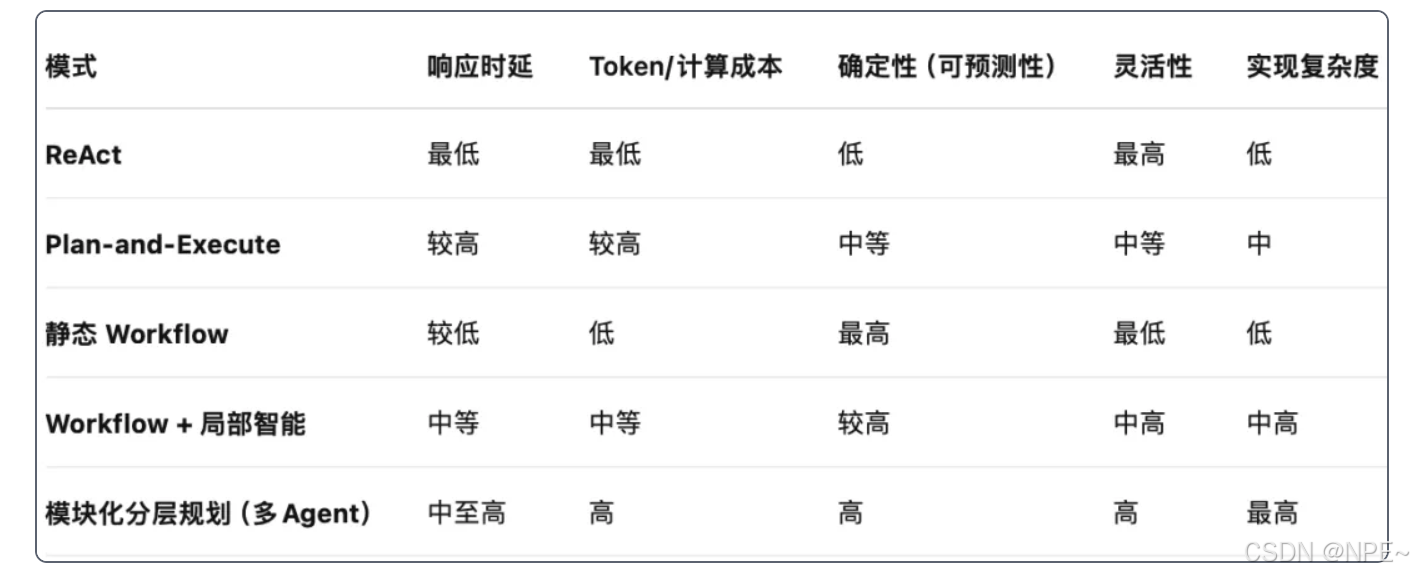
目前業界較為流行的智能體執行模式主要有以下5種:
- ReAct:全Agent,邊思考邊執行
- Plan-and-Execute:全Agent,先思考任務需要哪幾步(列計劃),然后一步步執行
- 靜態Workflow:幾乎無Agent,通過任務編排把步驟都規劃好,讓Agent執行極少數具體步驟
- Workflow + 局部智能:半Agent,通過任務編排將主要步驟都規劃好,具體執行讓Agent操作
- 模塊化分層規劃(多級Agent):全Agent且多級,一個總Agent調配下面多個子Agent完成任務
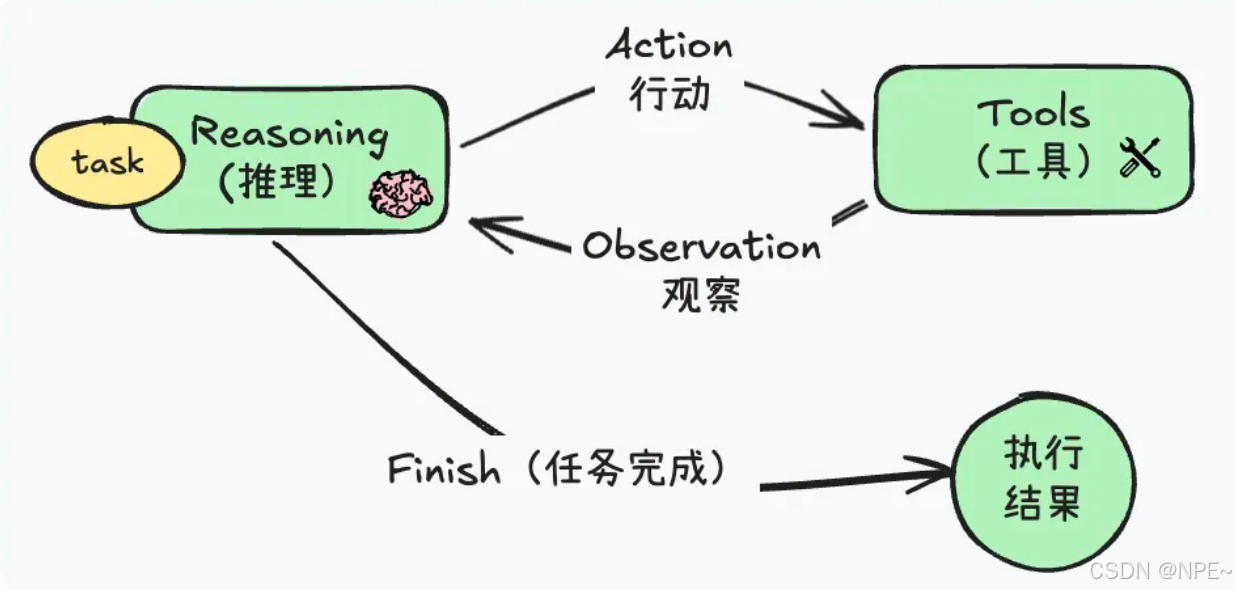
①ReAct:思考-行動交替的動態規劃執行
概念:Agent邊推理邊完成任務,響應速度快,成本低,但結果不確定性較高。
適用場景:任務流程不固定。
- ReAct 模式適用于相對中等復雜度的任務,尤其當任務步驟需根據中間結果動態調整時(如某個任務需要根據查詢資料來決定給后續);如果任務流程無法提前確定或需要頻繁工具調用,ReAct 能提供較好的靈活性和實時反應能力。
優點:
- 降低幻覺,提升可信度:ReAct將推理過程顯性地記錄下來,提升了模型的可信度和人類可解釋性。相比直接讓模型一蹴而就給出答案,ReAct 通過逐步推理有效降低了幻覺率。
- 響應速度快,成本較低:由于每一步只需考慮當前子問題,ReAct 響應速度較快,成本也較低。
缺點:
- 缺乏全局規劃,可能偏離用戶期望:因為一次只規劃一步,缺乏全局規劃,有時會使智能體短視,模型可能會在局部反復橫跳,重復思路。在沒有外部干預時,ReAct 智能體可能一直執行下去卻偏離用戶期望,無法適時收斂結果以完成任務。
②Plan-and-Execute:先規劃后調整
概念:先思考詳細步驟后執行。智能體在行動之前,先生成一個較完整的計劃。也就是將任務拆解成子任務清單,然后逐一執行。該方式任務完成度高,結果相比ReAct更準確,但響應較慢,成本較高。
適用場景:多步驟任務且步驟較為明確的場景。
- 適合較復雜的多步驟任務,尤其是可以在一定程度上預見步驟的場景 。例如數據分析任務可以先規劃“獲取數據->清洗->分析->可視化”的步驟。
- 當正確性比速度更重要時,相對ReAct來說,Plan-and-Execute 是值得選擇的策略 。
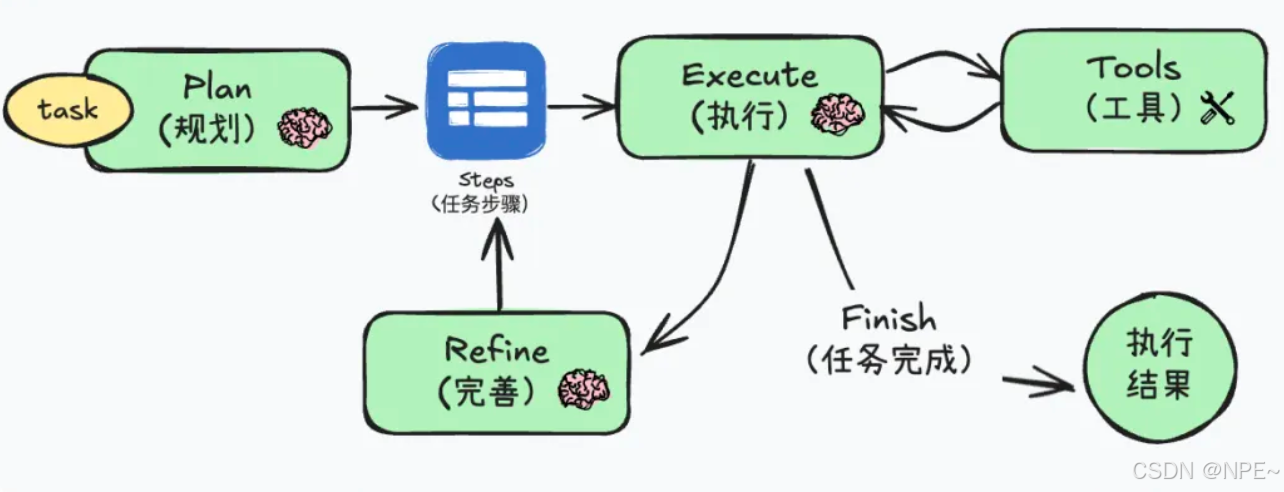
優點:
- 任務完成度較高:預先規劃賦予智能體一個全局視野,有助于提升復雜任務的準確率和完備性 ,特別是對于多工具、多步驟的復雜場景,能更好地分配步驟、協調順序。
- 結果相比ReAct更加準確:流程更可控 — 可以審查或調整生成的計劃,從而對最終執行有一定把控。一些測試證明在復雜任務中Plan-and-Execute 模式準確率要高于ReAct。
缺點:
- 成本相比ReAct更高:需要先額外一次(或多次)LLM調用來規劃,再逐步執行,整體響應速度比ReAct慢,token消耗也更高 (有測試結果表明上升約50%)。
- 最終結果強依賴模型生成的整體任務規劃:如果初始計劃不佳,執行階段可能走彎路甚至失敗。雖然可以動態調整,但調整本身又需要額外邏輯和模型交互。
③靜態Workflow:預設流程圖式的執行
概念:幾乎無Agent參與或只參與極少部分。該模式整體可控更穩定,但智能化程度低。
適用場景:流程明確固定,變化少的場景。
- 靜態工作流適合規則明確、變化少的任務。比如企業中的表單處理、固定報表生成、數據轉換管道等。特別在企業場景下,如果業務流程高度重復且標準化,靜態工作流能提供穩健的自動化方案 ,不必擔心AI“越俎代庖”引入不確定性和風險。
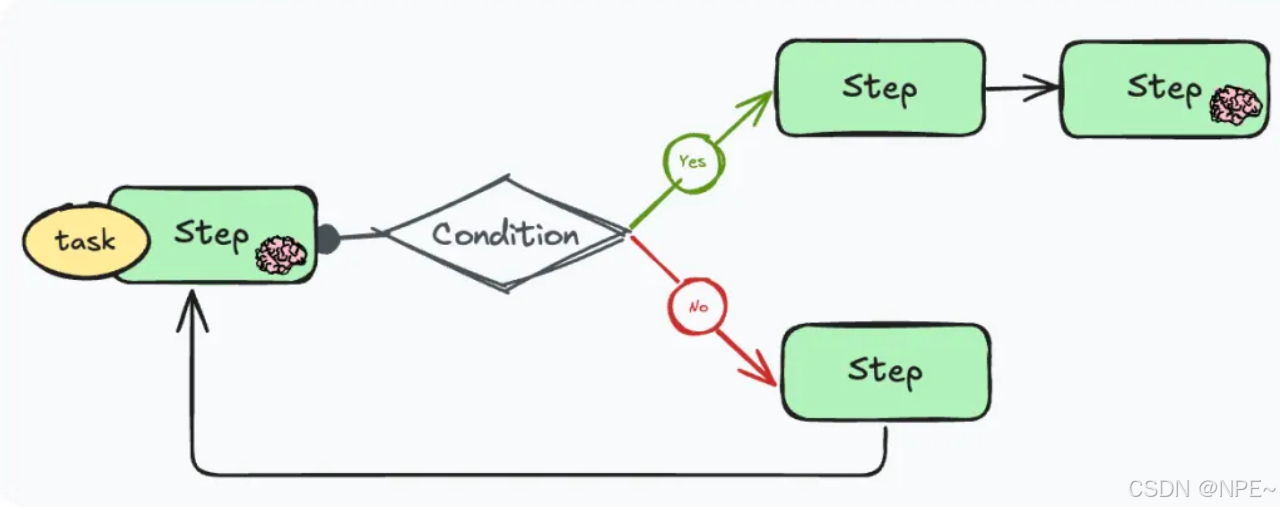
靜態工作流(Static Workflow)方式則幾乎不讓智能體自主決定流程,而是由開發者根據對任務的理解,將任務拆分成固定流程的子任務,并把這些子任務串起來執行。某些子任務可能由LLM完成(例如生成一段文字),但LLM在此不決定下一步做什么,因為下一步已經在程序固化。
也就是說,智能體遵循一個事先畫好的腳本/流程圖來執行,沒有決策自由度。Workflow的實現可以借助很多支持Workflow編排的框架來完成,比如LangGraph、LlamaIndex Workflow等低層框架,或Dify、FastGPT這樣低代碼平臺。
優點:
- 整體輸出更可控、更穩定:靜態工作流最大的優點是確定性和可控性。所有步驟由開發者掌控,因而系統行為可預測、易測試,避免了讓LLM自己規劃可能帶來的不確定性。從工程角度看,這種方式更像傳統軟件開發,調試和監控相對簡單。
- 成本低、速度快:靜態流程通常執行速度更快、成本更低,因為不需要額外的決策推理步驟。每個LLM調用都有明確目的,減少了無效對話。
缺點:
- 智能化不足:最大缺點是缺乏靈活性,智能化不足。一旦預設流程無法完全匹配實際任務需求,Agent 就會表現不佳甚至失敗。
- 有局限性,不通用:不具有通用智能,只能覆蓋開發者想到的那些路徑。特別對于未知領域或復雜任務,開發者往往難以提前設計出完善的流程圖。如果業務流程發生變化,通常需要進行應用的調整或升級,成本較高,不如讓智能體自主學習來得方便。
④Workflow+局部智能:兼顧確定性與智能化
概念:人為固定大流程,讓Agent去做每個細小分支的任務。該模式兼顧可控性與靈活性,但對開發者要求高,開發者需要評估哪些地方需要智能體參與。
適用場景:流程較固定,但部分分支需要發散泛化思維,智能決策。
- 混合法適用于流程較固定但存在關鍵智能決策點的任務場景。又或者一些長流程的子任務本身是復雜AI問題(如代碼生成、數據分析),就特別適合拆出來讓智能體發揮。實際項目中可以采用“靜態框架 + 智能插件”的思路:框架提供流程殼子,插件(Agent)完成具體智能任務。
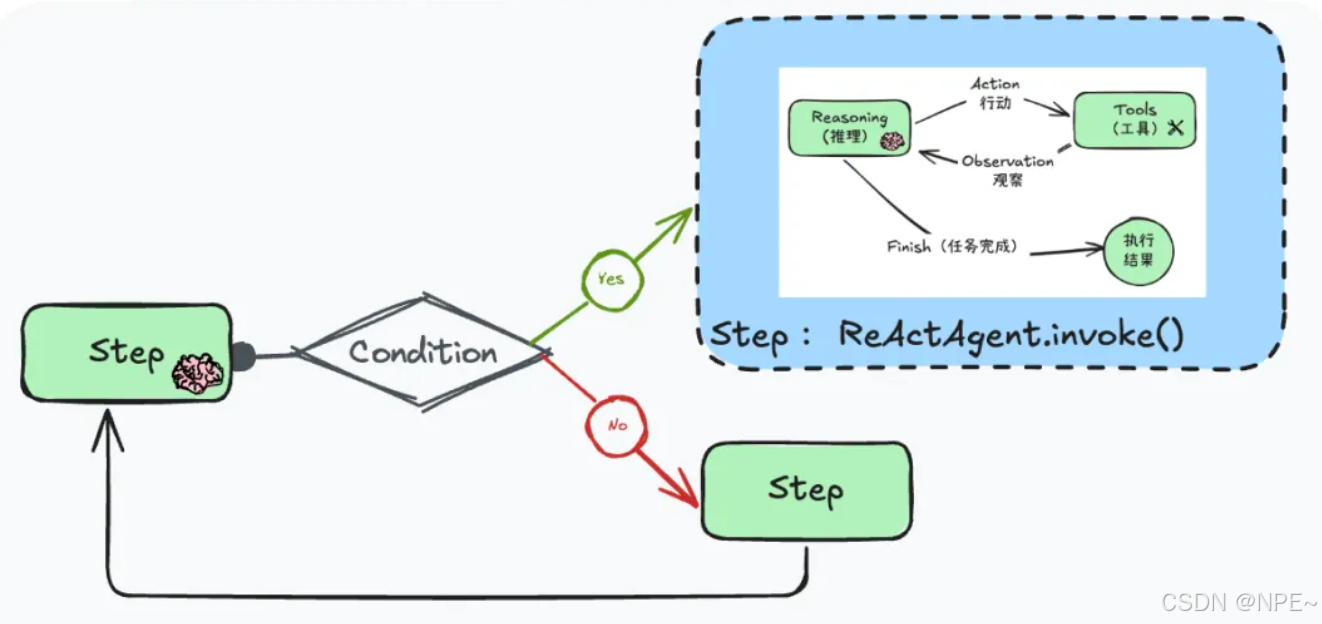
這種折衷的思路是將靜態規劃與智能體局部決策相結合。在整體上采用固定流程,但在特定步驟上授予智能體一定的自主規劃或推理權限。設計主流程時,識別出其中具有不確定性或需要動態決策的步驟,交給LLM智能體以子任務的形式在內部自行規劃或調用工具,完成后,流程繼續按照預定順序執行后續步驟。
換言之,大的流程圖是固定的,只有某些節點是“智能節點”,里面運行一個受控的Agent子流程。
優點:
- 兼顧可控性與靈活性:與全自主Agent相比,整體行為更可控,因為智能部分被限制在局部范圍內,不會干涉整個流程結構。相比純靜態流程,又具備了一定靈活應變能力——至少在那些標記出的復雜環節上,智能體可以隨機應變。
- 過渡性好:開發者可以逐步引入智能節點,從全靜態開始逐步引入智能環節。
缺點:
- 系統復雜度較高:增加系統復雜度,既要開發靜態邏輯又要集成Agent。
- 對開發者要求較高:如何劃分哪些步驟靜態哪些智能并無定式,依賴開發者對任務的理解和持續調整。
- 可控性隨智能節點增多而下降:局部智能體的表現仍然可能不穩定,如果智能節點過多,可控性也會相應下降。
⑤模塊化的分層規劃:化大為小逐層細化
概念:多級Agent。一個Agent當領導人,安排下面的Agent去完成各個模塊的任務。這種模式,職責分明,從單個智能體來看復雜度低。但后續整個流程調試以及優化較為繁瑣。
- 對于復雜場景,可以構建多個智能體形成一個層次化結構:由“高層”Agent負責宏觀規劃和決策,“低層”Agent執行具體子任務,各司其職又互相配合。這種模式最具代表性的就是Supervisor模式的多智能體系統。
分層規劃包含至少兩個層級:
- 高層Agent(規劃者/經理):面向最終目標,制定子任務或子目標清單,分配給低層Agent。高層Agent關注全局進展,可能不直接與環境交互,而是通過檢查下級完成情況來決定接下來做什么。
- 低層Agent(執行者/員工):接收高層指派的具體子任務,在其自己能力范圍內完成。低層Agent可能本身用ReAct或其他模式來解決子任務,然后將結果匯報給高層。
適用場景:任務模塊多,且每個模塊設計領域不同。
- 當任務規模龐大或專業模塊眾多時,分層/多Agent是很自然的選擇。例如一項軟件工程任務,從需求分析、設計、編碼、測試到文檔,每一步都可由不同Agent完成,由總負責人Agent協調。再如學術研究Agent,一個負責制定研究計劃,幾個分別去查文獻、做實驗、分析數據,最后綜合。
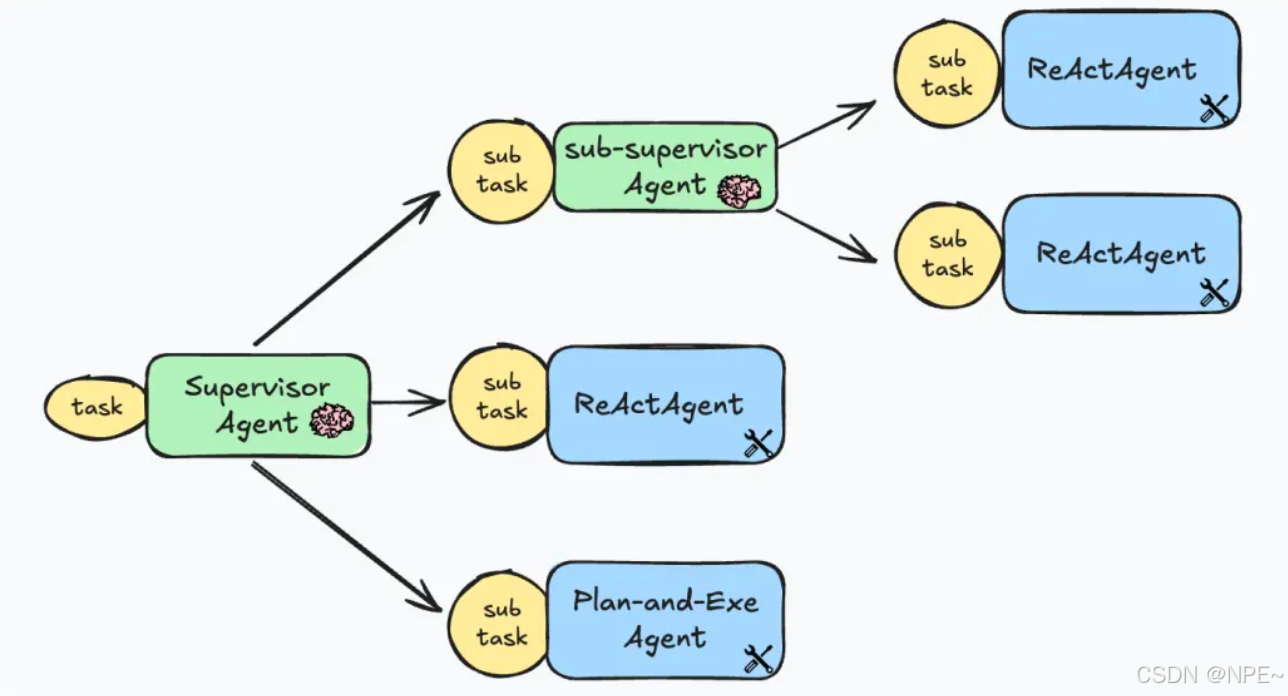
這種架構下,高層和低層可以都是LLM實例,扮演不同角色進行多輪協作:高層發號施令,低層報告結果,循環往復直到任務完成。
這種模式常借助多智能體系統的開發框架來完成。比如LangGraph、AutoGen、CrewAI等。
優點:
- 職責分離:充分利用了職責分離的思想,每個Agent專注于其擅長的層面,提高效率和效果。高層Agent擅長宏觀計劃,確保不偏離大方向;低層Agent專注微觀執行,可以投入更多細節推理(團隊協作勝過一人包辦)。
- 分治思想,單一智能體復雜度較低:在需要使用大量工具完成復雜任務的場景下,通過這種分治的模式可以大問題轉小問題,降低單一智能體的決策復雜度。而對于上層任務規劃,只需在低層Agent的“黑盒”接口層面做規劃和調度,決策空間與推理復雜度大大減小
- 并發度高,速度快:多子任務并行處理,提高速度(比如高層把任務分給兩個低層Agent同時做不同部分)。
- 健壯性好:某個子任務失敗可以局部重新規劃與執行,提高健壯性。
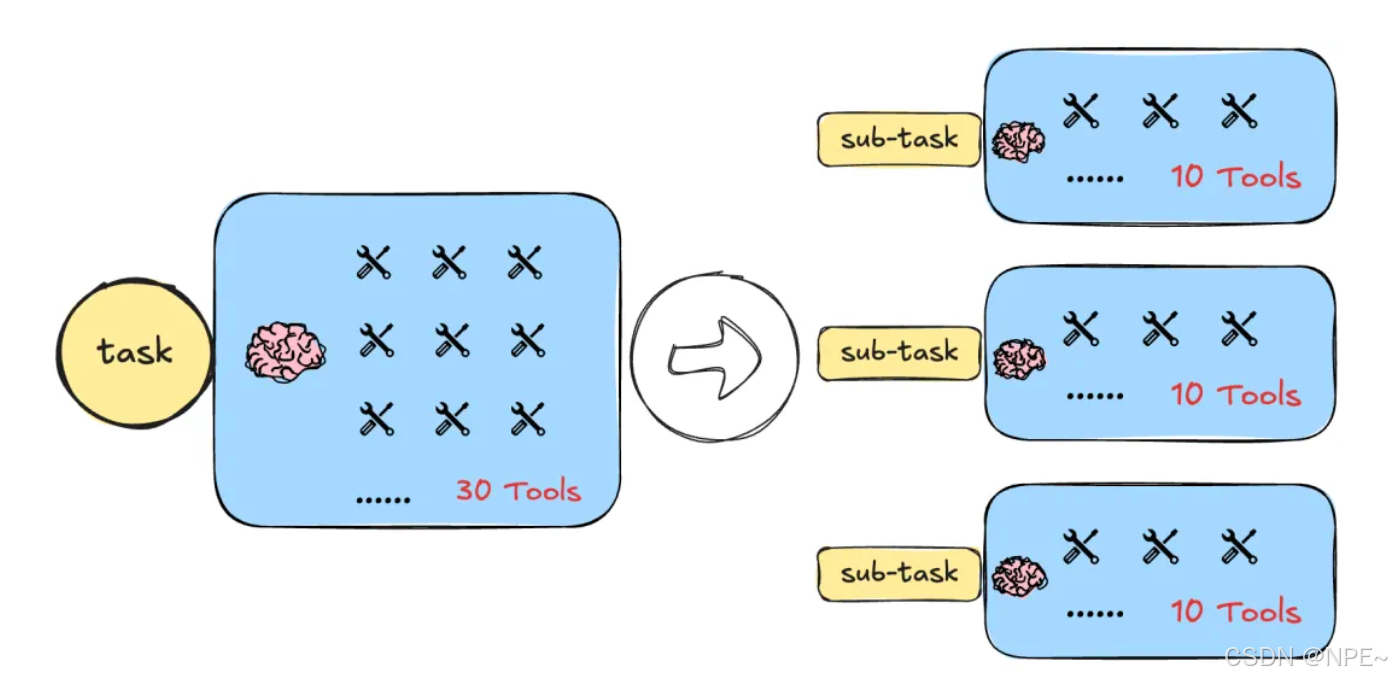
缺點:
- 整體復雜度較高:多智能體系統的實現復雜度高。需要處理Agent間的通信、上下文共享、結果整合等問題。
- 調優及問題排查較為困難:錯誤責任歸屬問題:任務失敗需要鑒別是高層計劃不當還是低層執行不力,調試困難度增加。
參考文章:https://mp.weixin.qq.com/s/TLekMTd3K6jLoMHYI_XIig



)


)








權威指南講解MCU內存架構與如何查看編譯器生成的地址具體位置)



