目錄
前言
?開散列概念
開散列實現
Insert
優化
?Find
Erase?
前言
上一章節我們用閉散列實現了一下哈希表,但存在一些問題,比如空間浪費比較嚴重,如果連續一段空間都已經存放值,那么在此位置插入新值的時候就會一直挪動,時間浪費也比較嚴重,當然可以通過二次探測來解決此問題,但今天我們來講解一下更優秀的解決方案。
?開散列概念
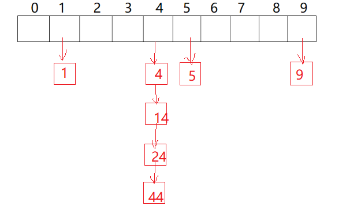
像這樣,我們在插入的時候,遇到哈希沖突,不用將它向后移動找到空位置,而是通過鏈表的形式,將他們一一連接起來,從而達到不影響其他位置的效果。開散列中每個桶中放的都是發生哈希沖突的元素。這樣就能有效解決查找和插入的問題。
開散列實現
開散列的實現需要一個指針數組,通過這個數組將插入值進行鏈接,就像上面的圖片。
template<class K, class V>struct HashNode{HashNode* _next;pair<K, V> _kv;HashNode(const pair<K, V>& kv):_kv(kv),_next(nullptr){}};首先先定義一個節點,節點里面包含下一個位置的指針,一個_kv,接下來開始實現。
template<class K, class V>class HashTable{typedef HashNode<K, V> Node;public:HashTable(){_tables.resize(10);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}private:vector<Node*> _tables;size_t _n = 0;};
在HashTable中定義一個指針數組vector<Node*> _tables,統計插入個數_n,在構造函數中先開10大小的空間,析構函數中一次遍歷該數組,如果不為空,依次進行delete,直到為空為止,然后將該數組位置置為nullptr。
Insert
在實現成基本結構后,我們來進行insert的實現。再拿出這個圖來鞭尸。
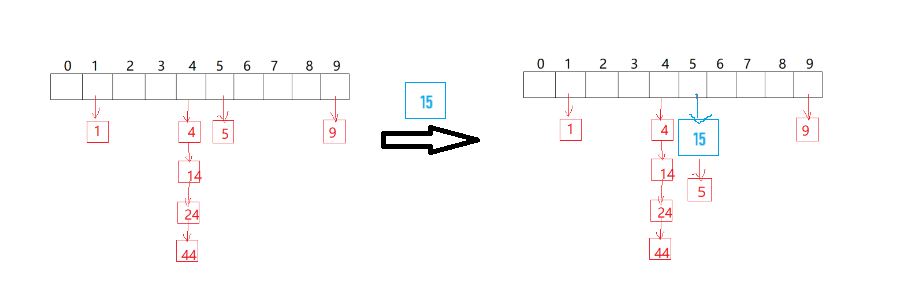
?當插入15時,我們找到5的位置,之后在此位置進行頭插操作,即可將15鏈接在這個桶上。
同樣和閉散列一樣,這種方式也需要考慮擴容的情況,但閉散列的空間利用率較低,負載因子控制在0.7左右,而開散列這種方式可以設置為1。
實現insert的方式有兩種,大家可以先自己看一下哪一個更優秀。
1:
bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 負載因子最大到1if (_n == _tables.size()){size_t newSize = _tables.size() * 2;HashTable<K, V> newHT;newHT._tables.resize(newSize);// 遍歷舊表for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while(cur){newHT.Insert(cur->_kv);cur = cur->_next;}}_tables.swap(newHT._tables);}size_t hashi = kv.first % _tables.size();Node* newnode = new Node(kv);// 頭插newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}2:
bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;if (_n == _tables.size()){vector<Node*> newTables;newTables.resize(_tables.size() * 2, nullptr);// 遍歷舊表for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while(cur){Node* next = cur->_next;// 挪動到映射的新表size_t hashi = cur->_kv.first % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = kv.first % _tables.size();Node* newnode = new Node(kv);// 頭插newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}?第一種方法用了閉散列實現時的方式,直接復用一下insert,這樣完成遍歷后就可以得到擴容后的哈希表,第二種方法選擇直接進行鏈接,然后將完成鏈接后的位置置空,同樣也可以完成擴容操作。
那么哪種情況會更好呢?答案是第二種,因為我們發現insert會new一個新節點然后再將其鏈接到哈希表中,而第二種情況是直接將現成的節點插入到擴容后的哈希表中,減少了空間的浪費,所以這種方法更優。
在第二種方法中,我們首先定義一個新的指針數組,然后依次遍歷舊表,將舊表中的值重新通過新的哈希函數進行轉換,得到的位置就是新插入的位置,然后將它頭插到表中即可,再將舊表位置置為空,完成便利后,我們只需要交換新舊表,這樣_tables就是擴完容后的哈希表。
優化
通常,我們的K為整形,但K為string時就不能轉換為關鍵字,這時就要用一個仿函數來進行完善。
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};// 11:46繼續
//HashFunc<string>
template<>
struct HashFunc<string>
{size_t operator()(const string& key){// BKDRsize_t hash = 0;for (auto e : key){hash *= 31;hash += e;}cout << key << ":" << hash << endl;return hash;}
};?我們特化了一個仿函數,當K為string時,直接調用下面的仿函數,里面用到了BKDR算法,它能夠將字符串轉化為關鍵字,并且盡可能的避免了哈希沖突的情況,這種方法被廣泛應用。這樣我們只需要在哈希表中增加一個模板即可完成string這種情況下轉為關鍵字的情況。
template<class K, class V, class Hash = HashFunc<K>>?Find
Node* Find(const K& key){Hash hf;size_t hashi = hf(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return NULL;}將要尋找的key轉換為關鍵字,該關鍵字可以映射哈希表中的一個位置,這時找到該位置,依次遍歷該鏈表,若能找到返回該節點指針,若到空還是不能找到,返回空。
Erase?
bool Erase(const K& key){Hash hf;size_t hashi = hf(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}?因為我們的節點里面只有next的指針,是一個單項鏈表,所以我們在刪除時要定義一個prev來指向前一個節點的位置。和前面類似,先通過哈希函數進行轉換,轉換為關鍵字后找到哈希表中對應的位置,進行查找,則會出現三種情況:
1.找到了該位置,前驅節點prev為空,說明該節點就是頭節點,只需要將哈希表中該位置鏈接到cur的next節點即可。
2.找到了該位置,前驅節點prev不為空,說明前面還有值,那么將prev的next更新為cur的next
即可完成鏈接。
3.循環結束后還沒返回,說明沒有此值。
erase還可以先用find查詢一下是否存在,若存在繼續進行刪除操作,不存在直接返回false。



學習)










)




