GPU訓練及類的call方法
知識點回歸:
- CPU性能的查看:看架構代際、核心數、線程數
- GPU性能的查看:看顯存、看級別、看架構代際
- GPU訓練的方法:數據和模型移動到GPU device上
- 類的call方法:為什么定義前向傳播時可以直接寫作self.fc1(x)
作業
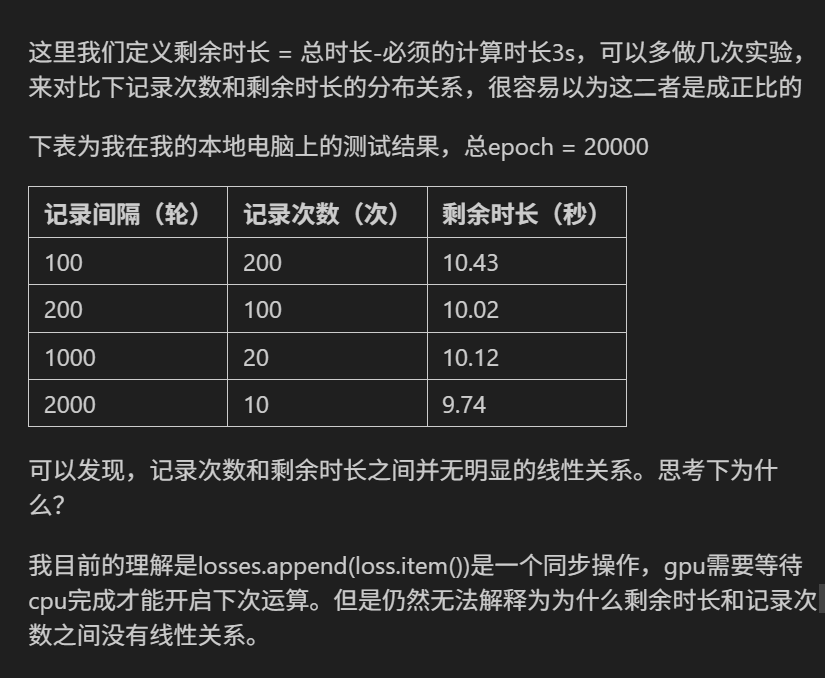
復習今天的內容,在鞏固下代碼。思考下為什么會出現這個問題。
?
?
CPU性能的查看:看架構代際、核心數、線程數:
# pip install wmi -i https://pypi.tuna.tsinghua.edu.cn/simple
# 這是Windows專用的庫,Linux和MacOS不支持,其他系統自行詢問大模型
# 我想查看一下CPU的型號和核心數
import wmic = wmi.WMI()
processors = c.Win32_Processor()for processor in processors:print(f"CPU 型號: {processor.Name}")print(f"核心數: {processor.NumberOfCores}")print(f"線程數: {processor.NumberOfLogicalProcessors}")
1. 型號解析:Intel Core i7-10875H
- i7:Intel酷睿家族的高端產品線,定位高性能計算(介于i5和i9之間)。
- 10:代表第十代酷睿處理器(Comet Lake架構,2020年發布)。
- 875:具體型號編號(同代中數字越大性能越強,875屬于i7系列的中高端型號)。
- H:表示"高性能移動版"(High Performance Mobile),通常用于游戲本/工作站筆記本,功耗較高(典型45W),性能釋放強于U/P系列低功耗移動處理器。
2. 核心與線程:8核16線程
- 8核(物理核心):CPU的實際計算單元,每個核心可獨立執行指令。
- 16線程(邏輯線程):通過Intel超線程技術(Hyper-Threading)實現,每個物理核心模擬2個邏輯線程,提升多任務并行處理能力(例如同時運行數據預處理、模型訓練監控等任務)。
3. 基礎頻率:2.30GHz
這是CPU的默認運行頻率(未滿載時的基礎頻率),實際運行中會根據負載動態調整(最大睿頻可達5.1GHz左右,具體取決于散熱和功耗限制)。
4. 對機器學習場景的適用性
- 優勢:8核16線程的配置非常適合機器學習中的多線程任務(如數據預處理、多模型并行測試、日志記錄等CPU密集型操作)。
- 注意:機器學習的核心計算(尤其是深度神經網絡訓練)通常依賴GPU加速(如你代碼中使用的CUDA),但CPU會影響數據加載/預處理的效率。此CPU的性能足以支撐大多數中小型機器學習項目的CPU側需求。
總結:這是一款面向高性能移動場景的第十代酷睿i7處理器,8核16線程的配置在多任務處理和機器學習輔助計算(非GPU核心計算)中表現優秀,能較好滿足你的研究項目需求。
?
?
GPU性能的查看:看顯存、看級別、看架構代際:?
import torch# 檢查CUDA是否可用
if torch.cuda.is_available():print("CUDA可用!")# 獲取可用的CUDA設備數量device_count = torch.cuda.device_count()print(f"可用的CUDA設備數量: {device_count}")# 獲取當前使用的CUDA設備索引current_device = torch.cuda.current_device()print(f"當前使用的CUDA設備索引: {current_device}")# 獲取當前CUDA設備的名稱device_name = torch.cuda.get_device_name(current_device)print(f"當前CUDA設備的名稱: {device_name}")# 獲取CUDA版本cuda_version = torch.version.cudaprint(f"CUDA版本: {cuda_version}")# 查看cuDNN版本(如果可用)print("cuDNN版本:", torch.backends.cudnn.version())else:print("CUDA不可用。")1.?CUDA可用!
CUDA是NVIDIA專門為GPU設計的“加速工具箱”,相當于給GPU裝了套“高效工作套餐”。這句話說明你的電腦/環境已經正確安裝了CUDA,GPU可以用來加速計算(比如深度學習訓練)。
2.?可用的CUDA設備數量: 1
“CUDA設備”就是支持CUDA的GPU顯卡。這句話說明你有1張能用于加速的NVIDIA顯卡(比如你后面提到的RTX 2060)。如果有2張顯卡,這里會顯示2。
3.?當前使用的CUDA設備索引: 0
如果有多個GPU(比如2張顯卡),計算機會給它們編號(0號、1號…)。這里“0”表示你當前的程序正在用第1張顯卡(編號從0開始)。如果只有1張顯卡,那肯定用0號。
4.?當前CUDA設備的名稱: NVIDIA GeForce RTX 2060
這是你顯卡的“全名”,相當于GPU的“型號”。RTX 2060是NVIDIA的中高端游戲/創作顯卡,支持CUDA加速,能高效處理深度學習、視頻渲染等任務。
5.?CUDA版本: 12.1
CUDA工具包的“版本號”,類似手機系統的版本(比如iOS 17)。不同版本支持不同的GPU功能:
- 12.1是較新的版本,能更好地兼容新模型(比如大語言模型、復雜神經網絡);
- 如果版本太舊,可能無法運行某些需要新特性的深度學習代碼。
6.?cuDNN版本: 90100
cuDNN(讀“Q-DNN”)是CUDA的“深度學習專用加速包”,相當于給GPU的深度學習任務裝了個“超級加速器”。版本號90100對應的是v9.1.0(9×10000 + 1×100 + 0 = 90100)。
- 它能大幅加速神經網絡的核心操作(比如卷積、全連接層);
- 版本越高,對新模型(如Transformer、擴散模型)的優化越好。
總結
這些信息說明你的GPU加速環境完全正常!你的RTX 2060顯卡+CUDA 12.1+cuDNN 9.1.0的組合,能高效運行深度學習任務(比如你之前用PyTorch訓練的MLP模型),比僅用CPU快幾倍到幾十倍
?
?
GPU訓練的方法:數據和模型移動到GPU device上?:
# 設置GPU設備
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 定義設備:優先使用 GPU(如果可用),否則用 CPU
print(f"使用設備: {device}")# 加載鳶尾花數據集
iris = load_iris()
X = iris.data # 特征數據
y = iris.target # 標簽數據# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 歸一化數據
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 將數據轉換為PyTorch張量并移至GPU
# 分類問題交叉熵損失要求標簽為long類型
# 張量具有to(device)方法,可以將張量移動到指定的設備上
X_train = torch.FloatTensor(X_train).to(device)# 特征數據移到 GPU
y_train = torch.LongTensor(y_train).to(device)# 標簽數據移到 GPU
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()# 調用父類nn.Module的構造函數(PyTorch模型初始化的標準寫法)self.fc1 = nn.Linear(4, 10)# 定義第一個全連接層(輸入層→隱藏層):輸入4維特征(鳶尾花的4個特征),輸出10個隱藏單元self.relu = nn.ReLU()# 定義ReLU激活函數(引入非線性特征,增強模型表達能力)self.fc2 = nn.Linear(10, 3)# 定義第二個全連接層(隱藏層→輸出層):輸入10個隱藏單元,輸出3個神經元(對應3個分類)def forward(self, x):# 前向傳播函數:定義數據在模型中的計算流程(x是輸入的特征張量)out = self.fc1(x)# 將輸入數據通過第一個全連接層(fc1),得到隱藏層的線性輸出out = self.relu(out)# 對隱藏層的線性輸出應用ReLU激活函數,引入非線性變換(增強模型表達能力)out = self.fc2(out)# 將激活后的隱藏層輸出通過第二個全連接層(fc2),得到最終的3維輸出(對應3個類別的原始預測分數)return out# 返回最終的預測結果(未經過softmax,交叉熵損失會自動處理概率轉換)# 實例化模型并移至GPU
# MLP繼承nn.Module類,所以也具有to(device)方法
model = MLP().to(device) # 實例化模型并同時移到 GPU?
?
類的call方法:為什么定義前向傳播時可以直接寫作self.fc1(x)
我們用「快遞柜取件」的例子,類比解釋為什么可以直接寫?self.fc1(x):
假設場景:你有一個「智能快遞柜」(相當于?nn.Linear?層)
- 快遞柜的功能是「根據取件碼(輸入?
x),輸出對應的快遞(輸出結果)」。 - 快遞柜有兩個操作方式:
- 直接按取件按鈕(相當于?
self.fc1(x)); - 打開柜門手動翻找(相當于?
self.fc1.forward(x))。
- 直接按取件按鈕(相當于?
為什么推薦按按鈕(self.fc1(x))?
因為快遞柜被設計成:
當你按按鈕(觸發?__call__?方法)時,它會自動:
- 執行核心功能:根據取件碼找到快遞(調用?
forward?方法); - 記錄取件過程:比如幾點取的、誰取的(PyTorch 會記錄計算圖,用于后續反向傳播);
- 處理異常:比如取件碼錯誤時提示「不存在」(PyTorch 會處理張量維度不匹配等問題)。
對應到你的代碼里:
你代碼中的?self.fc1?是一個全連接層(nn.Linear?的實例),它就像這個智能快遞柜:
- 當你寫?
self.fc1(x)?時(按按鈕),PyTorch 會自動觸發它的?__call__?方法; __call__?方法內部會調用?self.fc1.forward(x)(執行核心計算),同時偷偷幫你記錄計算過程(計算圖);- 你完全不需要自己寫?
self.fc1.forward(x)(手動翻找快遞),既麻煩又容易漏記錄關鍵信息。
總結:
self.fc1(x)?是 PyTorch 設計的「懶人按鈕」—— 按一下就能觸發完整的計算流程(包括核心功能和后臺記錄),比手動調用?forward?更簡單、更安全。
?
?
?
問題思考:為什么一些小型模型或者數據,CPU計算時間比GPU短?
主要是因為?GPU的「啟動成本」比CPU高,但「并行能力」比CPU強。就像你搬東西:
- CPU:像一個「靈活的小工」,雖然一次只能搬少量東西(核心少),但說干就干(啟動快),搬少量東西時效率高。
- GPU:像一個「大團隊的搬運隊」,雖然能同時搬很多東西(核心多,并行強),但每次開工前需要花時間集合隊伍、分配任務(啟動和數據傳輸的開銷)。如果東西很少(小模型/小數據),集合隊伍的時間可能比實際搬東西的時間還長,反而更慢。
具體來說:
- 小任務不需要并行:小模型/小數據的計算量少,CPU幾個核心就能快速搞定,不需要GPU的「人海戰術」。
- GPU的數據搬運耗時:用GPU時,數據需要從內存傳到顯存(顯卡內存),計算完再傳回來。小數據時,這個搬運時間可能比實際計算時間還長。
- GPU的啟動開銷:GPU的并行計算需要額外的調度(比如給每個核心分配任務),小任務時這些調度的時間會「拖后腿」。
舉個例子:
你要寫100字的小作文(小任務):
- 用CPU(自己寫):拿起筆立刻寫,5分鐘寫完。
- 用GPU(叫100個同學一起寫):需要花10分鐘把紙和筆分給100個同學(數據傳輸+任務分配),然后每人寫1個字,實際寫的時間1分鐘,但總時間11分鐘,反而更慢。
所以,小任務用CPU更快,大任務(比如幾萬張圖片訓練)用GPU的并行能力才能發揮優勢。
?
?
?
用舉例子的方式解釋代碼:
假設場景:教小朋友認3種水果(蘋果、香蕉、橘子)
- 數據集:準備了100張水果圖片(80張訓練,20張測試),每張圖有4個特征(大小、顏色、重量、形狀)。
- 模型(MLP):相當于「小朋友的大腦」,需要通過學習訓練集的圖片,學會根據4個特征判斷是哪種水果。
對應代碼的每一步解釋:
1. 數據準備(代碼前半部分)
# 加載數據集(準備100張水果圖片)
iris = load_iris()
X = iris.data # 特征數據(每張圖的4個特征:大小、顏色、重量、形狀)
y = iris.target # 標簽數據(每張圖的真實水果類型:0=蘋果,1=香蕉,2=橘子)# 劃分訓練集和測試集(80張給小朋友學,20張考試用)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 歸一化數據(把「大小」「重量」等特征統一到0-1范圍,避免「大小」數值太大欺負「顏色」)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 轉成PyTorch張量并移到GPU(把圖片和答案寫成「小朋友能看懂的語言」,并搬去「高速學習區」GPU)
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)?2. 定義模型(MLP類)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 第一層:輸入4個特征,輸出10個「臨時結論」(比如「可能是圓的」「可能是黃色的」)self.relu = nn.ReLU() # 激活函數:過濾掉沒用的「臨時結論」(比如「可能是方的」這種不可能的判斷)self.fc2 = nn.Linear(10, 3) # 第二層:把10個「臨時結論」匯總,輸出3個分數(對應3種水果的「像不像」)類比:小朋友的大腦分兩步處理信息:
- 第一步(fc1):根據4個特征,生成10個中間判斷(比如「大小像蘋果」「顏色像香蕉」...);
- 過濾(relu):去掉明顯錯誤的判斷(比如「顏色像蘋果但實際是綠色」);
- 第二步(fc2):把剩下的判斷匯總,得出「像蘋果」「像香蕉」「像橘子」的3個分數。
3. 訓練循環(核心代碼)?
# 實例化模型(找一個「小朋友」開始學習)
model = MLP().to(device)# 損失函數(判斷小朋友猜得準不準的「打分器」:猜得越錯,分越高)
criterion = nn.CrossEntropyLoss()# 優化器(教小朋友調整自己的「學習方法」的「老師」,這里用SGD)
optimizer = optim.SGD(model.parameters(), lr=0.01)# 開始上課(訓練20000輪,相當于上20000節課)
num_epochs = 20000
start_time = time.time()for epoch in range(num_epochs):# 前向傳播(小朋友根據當前學習成果,猜訓練集的80張圖是什么水果)outputs = model(X_train) # 輸出3個分數(比如 [0.8, 0.2, 0.1] 表示「最像蘋果」)# 計算損失(打分器給小朋友的猜測打分:如果真實是蘋果,但小朋友猜成香蕉,分就很高)loss = criterion(outputs, y_train)# 反向傳播(分析哪里猜錯了:比如「顏色判斷」錯了,「大小判斷」對了)optimizer.zero_grad() # 清空之前的錯誤記錄(避免上節課的錯誤影響這節課)loss.backward() # 計算每個「臨時結論」(參數)對錯誤的「貢獻度」(梯度)# 優化器更新(根據錯誤分析,調整小朋友的「學習方法」:比如「顏色判斷」的權重調大)optimizer.step() # 每100節課匯報一次:「現在猜訓練集的錯誤分是XX」if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')類比:每一輪訓練(epoch)相當于一節課:
- 小朋友先猜訓練集的80張圖(前向傳播);
- 老師用打分器(損失函數)告訴小朋友猜得有多錯(計算損失);
- 老師分析錯誤原因(反向傳播算梯度),并指導小朋友調整自己的判斷邏輯(優化器更新參數);
- 重復20000次,直到小朋友猜得足夠準。
4. 可視化損失(最后幾行代碼)?
# 把每100節課的錯誤分畫成曲線,看小朋友是不是越學越準
plt.plot(range(len(losses)), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()?類比:老師把每節課的錯誤分記錄下來,畫成折線圖。如果曲線越來越低,說明小朋友越學越準;如果曲線波動大或不降,說明學習方法可能有問題(比如學習速度lr太快/太慢)。?
?
?
記錄次數和剩余時長之間并無明顯的線性關系可能的原因:
loss.item()?是同步操作(需要GPU→CPU數據傳輸并等待完成)確實可能影響單次記錄的耗時,但「剩余時長和記錄次數無線性關系」的核心原因其實更簡單:每次迭代(或記錄點)的實際耗時不穩定。
用「煮面」的例子類比解釋:
假設你要煮 10 碗面(總時長固定為 100 分鐘),每煮完 1 碗記錄一次「剩余時長」(總時長 - 已用時間)。但實際煮每碗面的時間可能波動:
- 第 1 碗:火大,用了 5 分鐘 → 剩余時長 95 分鐘;
- 第 2 碗:水沒開,用了 15 分鐘 → 剩余時長 80 分鐘;
- 第 3 碗:火穩了,用了 8 分鐘 → 剩余時長 72 分鐘;
……
這時候「記錄次數」(1、2、3…)和「剩余時長」(95、80、72…)的關系是亂的,因為每碗面的實際耗時不穩定(有時快、有時慢),導致剩余時長的減少幅度忽大忽小,無法用「每次固定減少 X 分鐘」的直線表示。
對應到你的場景:
訓練模型時,雖然總輪數(num_epochs)固定,但每輪(epoch)的實際耗時可能波動:
- GPU 可能被其他程序搶占(比如后臺下載文件),導致某輪計算變慢;
- 內存/顯存的分配可能不穩定(比如某輪需要加載更多數據到顯存),增加耗時;
loss.item()?雖然是同步操作,但每次傳輸數據的耗時可能因GPU負載不同而變化(比如某輪GPU更忙,傳輸更慢)。
這些波動會導致「剩余時長」(總時間 - 已用時間)的減少幅度不穩定,因此和「記錄次數」(比如每100輪記錄一次)之間沒有線性關系。
@浙大疏錦行?












—Tomcat簡化模型架構)
—— 從 OkHttp 攔截器來看 HTTP 協議二)





—言語:語句填空題(聽課后強化訓練))