點擊藍字 關注我們
最近有用戶問到?zData X?的存儲底座?zStorage?分布式存儲為什么采用的是全閃存架構而非混閃架構?主要原因還是在于全閃存架構在性能和可靠性方面具有更顯著的優勢。zData X?的上一代產品?zData?的早期版本也使用了SSD盤作為緩存的技術架構,在當時的確是起了比較大的作用。但隨著SSD技術的演進、成本大幅降低以及緩存架構本身的一些問題,zData?后期的版本就去掉了SSD緩存。所以我們對于SSD作為緩存的這種技術架構也有一些經驗。這篇文章我系統地來講一講這兩種架構的優劣勢,以及為什么?zData X & zStorage 采用了全閃存架構。
混閃架構是指使用SSD盤做緩存,而主存或者說后端存儲用HDD盤(機械盤);全閃存架構是指存儲全部用SSD盤,沒有緩存這一層。值得注意的是,有些分布式存儲軟件雖然基于混閃架構,但是把主存儲從HDD盤換成SSD盤,即所有存儲介質都是SSD盤,這種方案從架構上來說仍然是混閃架構,相比全閃存架構來說,IO性能更差但成本反而更高了,本文不討論這種“偽全閃存架構”。
那么混閃架構相對于全閃存架構,有哪些優缺點呢?我先說在數據庫場景的結論(產品或方案的優劣勢都是在場景中體現,拋開場景談優劣勢都是耍流氓。本文主要講數據庫場景下兩種架構的對比):
優點:相同存儲容量下的成本降低。相對于全閃存架構,3存儲節點300TB裸容量的情況下,混閃架構整體成本降低約10%。該優勢在容量越大越突出,如果容量越小,則成本優勢越不明顯。但這個優點正隨著SSD盤價格的持續降低而導致優勢越來越小。
缺點:混閃架構在性能和可靠性方面存在不少缺陷。譬如,
①隨機IO延遲高:在存儲節點上,混閃架構的隨機IO延遲遠高于全閃存架構,全閃存架構的平均IO延遲優于混閃架構6-30倍。這會導致混閃架構在一些隨機IO較多的復雜SQL執行時,時間就非常長。全閃存架構下1000個隨機IO的SQL也只需要0.1s,而混閃需要0.6~3s。
②IO帶寬(吞吐量)低:為了避免大量數據把緩存中的熱點數據擠出,順序IO通常不經過緩存,要從主存HDD盤讀取,單存儲節點的IO帶寬只有1-3GB/s,而全閃存架構單存儲節點的IO帶寬在20GB/s以上。這會導致數據備份、批量數據處理、報表統計分析等場景下的IO性能非常差。
③性能穩定性和確定性差:全閃存架構的性能指標都是相對穩定的,在穩定的性能指標下,業務表現也是確定的。但混閃架構這方面的缺點比較明顯:數據訪問的性能嚴重依賴于緩存命中率,即數據的熱點程度。熱點程度差的數據,訪問的性能就非常差。
某些低頻但重要的業務,比如某個業務系統的某些復雜查詢類功能,使用不高頻,這種情況下數據不是熱點,要從機械盤上讀取,所以性能非常差。全閃存架構穩定執行0.5s,但是混閃架構可能需要15s。
假設一個業務80%的可能性只需要30分鐘處理完,但是有20%的可能性需要3小時處理完,而出現這種情況的時間點是無法預測的,故作為一個用戶也難以預先處理,那我寧愿這個業務穩定地在1小時處理完成。
④緩存的并發訪問、元數據管理、緩存數據冗余保護帶來的性能降低問題:緩存層要對緩存介質和主存介質的映射數據(類似于操作系統虛擬內頁面和物理內存頁面的映射,也是以“塊”或“頁面”為單位映射)、緩存塊是否是臟數據等元數據在內存中的管理和并發訪問,以及持久化到緩存盤上都會有非常大的性能消耗。為了避免壞單塊緩存盤導致整個節點不可用,所以緩存盤通常要多個緩存盤并且進行數據鏡像保護(相當于還要實現緩存數據的軟RAID),為了數據冗余的一致性和緩存數據至少寫2份都會帶來比較大的性能損耗。
⑤重構速率和數據可靠性問題:如果1塊硬盤故障,更換1塊新盤,進行數據重構。混閃架構下重構速率只有全閃存架構下的1/10,具體來說是200多MB/s與3GB/s的對比。即重構1個盤所花的時間是全閃存架構的10倍長。實際系統中HDD磁盤故障重構時間往往長達1周。重構時間越長,在此期間出現另一磁盤故障的概率就越大。
⑥混閃架構下的閃存盤壽命問題:SSD盤作為緩存,一方面因為讀數據時要從HDD讀出來然后寫入到SSD盤進行緩存,導致讀IO會產生SSD盤的寫操作;另一方面IO集中在1-2個緩存盤上,導致緩存盤的擦寫次數遠高于全閃存盤,那么混閃架構下的閃存盤壽命低,而閃存故障又會導致整個緩存失效,甚至節點不可用。
⑦運維復雜性問題:由于緩存命中率過于重要,圍繞緩存命中率的運維和監控,復雜性遠超于全閃存架構。
在上述問題中,由于熱點數據變動導致緩存命中率降低及性能降低的情況,在90%的數據都是歸檔的冷數據的情況下,這個問題發生的概率比較低,但其他問題普遍存在,不太好解決。
我們來詳細地說一下上述的問題:
我們先來說一說混閃架構,即使用SSD盤做緩存,HDD盤做主存這種方案的好處——很直接,就是為了省成本。我們簡單來算一筆賬:
按1個節點100TB左右的容量來計算(按此容量算的原因是3個節點裸容量在300TB能夠滿足絕大部分企業的數據庫使用),7.84TB的SSD盤和8TB的HDD盤都是需要13個。
U.2接口PCIe 4.0的NVMe SSD盤,800-1000元/TB,按800元/TB計算,13個7.84TB的SSD盤共81536元。
8TB SATA 7.2K 3.5in的企業級HDD盤,180元/TB,13個8TB的HDD盤共18720元。但是要注意,還需要2個緩存盤,共計12544元。緩存盤和主存盤的總價是31264元。這里為什么要2個緩存盤?原因是要考慮冗余,否則1個緩存盤故障,整個節點不可用。
那么3個節點共300TB裸容量的規模下,全閃存架構,磁盤共需要244608元;而混閃架構,磁盤共需要93792元,比全閃磁盤少了約15萬元,相對于全閃存的數據庫一體機150萬左右的總價,剛好節省了10%的費用。
所以混閃架構,一套系統大約節省10%總體費用。
事物都有兩面性,如果混閃架構只有優點沒有缺點,這個世界就不會有全閃存分布式存儲,也不會有全閃存磁盤陣列。那么混閃架構相對于全閃存架構的缺點有哪些呢?我們先從技術原理上對緩存進行解析:
1.?7200轉的機械盤和SSD盤的主要性能對比:
大容量HDD盤一般都是7200轉,故這里用以與SSD盤對比。

2.?緩存的技術特點:
①使用高性能的存儲介質作為低性能低成本存儲介質的緩存,本質上是利用數據局部性原理,即在某段短時間內,某些數據會被多次地訪問。在進行數據訪問時,訪問到熱點數據,從緩存直接進行訪問,稱之為“緩存命中”,如果不是熱點數據,很大概率要從主存即機械盤上訪問。緩存命中次數/總訪問次數稱之為“緩存命中率”。
②由于緩存容量遠低于主存容量,所以緩存只能存放一部分數據,緩存一般使用LRU算法,最近最少使用的數據會被移出緩存。
③緩存有3種策略,如下表所示:
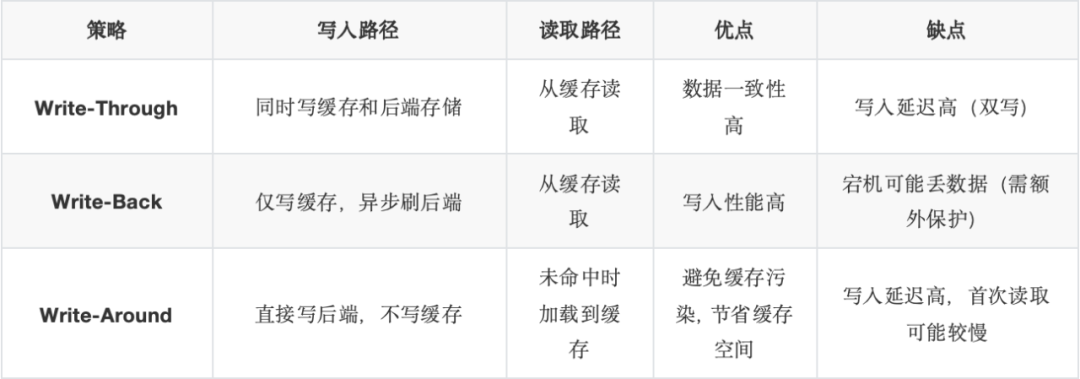
追求低延遲的數據庫場景只能選擇Write-Back緩存策略,否則10ms級的寫延遲在數字化時代的今天是完全不可接受的。
在了解緩存的技術原理的基礎上,我們再來看“混閃架構”分布式存儲的問題。
1.?混閃架構IO延遲遠高于全閃存架構
混閃架構下,緩存命中的IO性能達到SSD盤的水準,而緩存沒有命中的IO性能就奇差無比,即IO延遲在0.1ms~10ms之間,波動范圍非常大,最大值是最小值的100倍。反觀全閃存架構的IO延遲“穩定在亞毫秒級”,波動范圍非常小。
緩存命中率一般在70%-95%之間,假設1000個IO,幾種緩存命中率下這1000個IO所花費的總時間是多長呢?我們看下表所列:
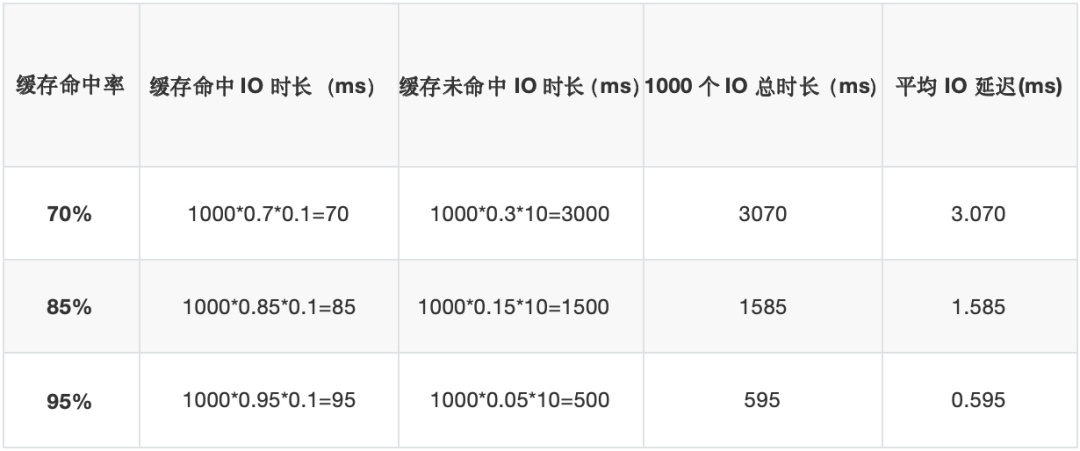
對于全閃存架構,1000個IO的總耗時基本就在100ms左右,是相對穩定和確定的。從上表的數據可以看到,即使是緩存命中率高達95%時,全閃存架構的IO延遲也只有混閃架構IO延遲的1/6,優勢明顯。如果某些數據緩存命中率不高,只有70%時,全閃存架構的IO延遲甚至優于混閃架構30倍。
混閃架構的這些延遲,在一些隨機IO較多的復雜SQL執行時,耗費時間就非常長。全閃存架構下1000個隨機IO的SQL也只需要0.1s,而混閃架構需要0.6~3s。
2.?混閃架構IO帶寬(吞吐量)遠低于全閃存架構
順序讀寫的數據通常不會被反復訪問,同時也要避免大量讀寫的數據把緩存中的熱點數據擠出去,所以順序讀寫通常是從主存儲即后端的HDD盤上直接訪問。這樣吞吐量基本上就受限于機械盤的能力,如前所述,一個HDD盤的吞吐量僅為100-200MB/s,所以10個并發訪問同時訪問10個盤時,吞吐量也僅有1-2GB/s。按本文所述1個存儲節點13個磁盤時,總吞吐量不足3GB/s。
在實際的業務中,順序讀寫的IO吞吐量則更低。比如順序讀寫128KB,如果按4K為存儲的塊單位,128KB就是32個4KB塊。當這32個塊部分數據在緩存中時,就需要把IO拆分成多個進行處理,嚴重影響性能。
3.?“性能不穩定”導致的“不確定性”
所謂“性能不穩定”,就是在緩存命中時IO性能達到SSD盤的水準,而緩存沒有命中的IO性能就奇差無比,波動范圍有100倍之差,不像全閃存架構的IO延遲那樣“穩定在亞毫秒級”。
那么“不確定性”是什么?是指IO性能不穩定帶來的業務功能執行時間不確定。比如某個DBA每天早上都要查一個報表,這個報表大部分時間執行只需要0.6s,但是有小部分時間執行時間要5s,這就會使用戶的使用體驗非常不好。再比如某個批處理,需要在早上6點前完成,性能好的時候,早上4點就完成了,但是有時也會出現早上8點都完成不了。這種情況下,用戶會感覺這系統隨時都可能因為緩存問題而出現爆雷。出現上述業務執行時間“不確定性“的原因,主要在于該業務對應的數據的緩存命中率下降了。
早些年Exadata就是以混閃架構為主,曾出現由于A業務導致了B業務的數據被擠出緩存,而后在做B業務時緩存命中率低,導致SQL性能非常差,問題難以處理。
假設一個業務80%的可能性只需要30分鐘處理完,但是有20%的可能性需要3小時處理完,而出現這種情況的時間點是無法預測的,故作為一個用戶也難以預先處理,那我寧愿這個業務穩定地在1小時處理完成。或者說軟件界面上的功能,80%的響應時間是0.5s,20%的響應時間是3s,那我寧愿100%的響應時間是1s。
導致緩存命中率降低,甚至緩存失效的主要原因有:
可能是新生成的數據不在緩存中,也可能是其他業務(如批處理)導致緩存中原來的“熱點”數據被擠出緩存。比如計費系統出賬,要訪問幾乎所有的賬戶相關數據,大量的數據進入緩存,使得緩存中原有數據被擠出。對于這個問題,如果系統中90%以上的數據是歸檔冷數據,出現的概率會小很多。
磁盤重構和重均衡會導致緩存的命中率大幅降低。磁盤故障進行重構和擴容增加磁盤或節點進行重均衡,都會使得后端主存儲上HDD的數據進行大量的搬移,使得緩存中的數據失效。
用于緩存的SSD盤故障,導致緩存失效帶來的問題更為嚴重,此時業務很大概率在性能上會下降到完全不可用的狀態。
如果緩存元數據沒有開啟持久化,存儲節點重啟后會導致緩存數據全部失效,此時緩存相當于完全失效。
存儲節點通過增加磁盤進行擴容,但是緩存盤本身沒有增加容量。比如原來緩存盤與主存儲的比率是1:10,增加了磁盤后變成了1:16。節點增加了磁盤,性能反而降低了;而全閃存在增加磁盤后性能是提升的。
4.?緩存的并發處理、元數據管理、緩存數據冗余保護帶來的性能降低問題
緩存層要對緩存介質和主存介質進行映射,比如主存上的第N個盤的第M個8K塊(也可以是其他大小的塊)的緩存數據在緩存盤A的第X個8K塊。除了映射信息之外,還要記錄緩存塊的狀態:有效、無效、是否臟數據等,映射數據是元數據的一部分,一般是以hash表在內存中組織,以方便快速查找。
對于8KB大小的緩存塊(標準術語稱為cache line),7.84TB的緩存盤大小至少需要15~20GB的內存用于元數據。這個巨大的hash內存結構和前面提到的LRU算法需要的內存結構要進行并發訪問,都會由于加鎖等同步訪問機制而產生性能損耗。
對于Write-Back緩存策略,在寫IO時元數據一定要持久化到緩存上,否則軟件或節點重啟后,臟塊信息丟失就會導致數據丟失。這樣在寫IO時還要寫元數據,降低了性能。
為了考慮可用性,緩存數據需要進行冗余保護,否則1個盤故障后,Write?Back的緩存上還沒有寫到后端主存的臟塊數據,就永久性丟失了。當然分布式存儲一個節點不工作,整個系統還有冗余保護,能保證數據不丟失和業務連續性,但是這會使得1個盤故障導致整個節點不可用,嚴重影響了系統可用性和性能。而用多個盤做緩存數據的冗余保護,則會使得冗余本身變得很復雜,影響性能。這個復雜性體現在如何用一個可靠的機制來保證兩個緩存盤的數據是一致的,這個機制越復雜就越影響性能。而同時為了數據冗余,緩存數據至少寫2份,也是性能較大損耗的點。
5.?重構速率和數據可靠性問題
如果1塊硬盤故障,更換1塊新盤,進行數據重構。為保證業務性能,最多使用30%的IO帶寬用于重構,那么1個機械盤能用于重構的帶寬是30-60M/s,取中間數45M/s。本文按13個盤舉例,那么壞1個盤,在12個盤之間進行重構,就是45*12/2=270MB/s(除以2是因為一份數據要進行讀和寫)。而 zStorage?在只影響性能20%的情況下,重構速率可以達到3GB/s,因此混閃架構下重構速率只有全閃存架構下的1/10,即重構1個盤所花的時間是全閃存架構的10倍長。重構時間越長,在此期間出現另一磁盤故障的風險就越大。
1個8TB的盤,使用率假設到了75%,即存儲了6TB數據,混閃架構下重構需要6小時,而 zStorage?全閃存架構只需要34分鐘。
從計算來看HDD盤的重構時間還挺長,但是實際上由于業務IO的壓力,導致磁盤重構的速率遠低于計算值。根據經驗,HDD盤故障后的重構時間往往長達一周,因此HDD磁盤故障后的風險非常大。
6.?混閃架構下的閃存盤壽命問題
SSD盤作為緩存,一方面連讀IO都會在SSD盤上寫數據,另一方面IO集中在1-2個緩存盤上,導致緩存盤的擦寫次數遠高于全閃存盤。這意味著混閃架構下的閃存盤壽命低,而閃存故障又會導致整個緩存失效,甚至節點不可用。
而對于全閃存架構來說則不存在此問題,大多數業務都是讀多寫少,磁盤的擦寫次數少,并且寫是均勻分布在所有磁盤上,基本上不會因為擦寫而導致SSD盤的壽命中止和故障。
其實還有其他一些問題,包括運維復雜性問題,由于緩存命中率實在關鍵,混閃架構要隨時關注緩存命中率,磁盤的替換操作也要比全閃存架構復雜不少。
結語
最后我們再回到緩存解決的成本問題上。云和恩墨的?zData?產品在2015年銷售時,SSD盤的價格在10000元/TB以上,而十年過去了,其價格已降到約800元/TB,降幅十幾倍;單盤容量從1.6TB增加到了如今主流的7.84~15.68TB;單存儲節點從PCIe接口能插入2~4個SSD盤到現在可以插入超過24個U.2接口的SSD盤。
緩存作為軟件系統架構中一項關鍵技術,在軟件產品中起著非常重要的作用。在過去SSD盤價格高昂、單盤容量低、接口還是PCIe直插主板或用SATA?SSD的時代,SSD緩存起到了巨大的作用。如果?Intel 沒有停產Optane,那么的確還可以考慮將Optane作為緩存層使用,可以進一步降低全閃存儲系統的IO延遲,在需要更低IO延遲的場景中發揮作用。
然而時至今日,隨著軟硬件技術的不斷進步,可以預見SSD盤的價格還會持續下降。因此,在數據庫場景,我們應該選擇更先進的技術,而不是還采用混閃這種成本優勢不大、但缺點太多的架構。這便是為什么全閃分布式存儲和全閃存儲陣列成為主流,zData X?&?zStorage?采用全閃存架構的原因。

數據驅動,成就未來,云和恩墨,不負所托!
云和恩墨創立于2011年,是業界領先的“智能的數據技術提供商”。公司以“數據驅動,成就未來”為使命,致力于將創新的數據技術產品和解決方案帶給全球的企業和組織,幫助客戶構建安全、高效、敏捷且經濟的數據環境,持續增強客戶在數據洞察和決策上的競爭優勢,實現數據驅動的業務創新和升級發展。
自成立以來,云和恩墨專注于數據技術領域,根據不斷變化的市場需求,創新研發了系列軟件產品,涵蓋數據庫、數據庫存儲、數據庫管理和數據智能等領域。這些產品已經在集團型、大中型、高成長型客戶以及行業云場景中得到廣泛應用,證明了我們的技術和商業競爭力,展現了公司在數據技術端到端解決方案方面的優勢。




![洛谷B3840 [GESP202306 二級] 找素數](http://pic.xiahunao.cn/洛谷B3840 [GESP202306 二級] 找素數)

: 文件輸入輸出庫 —— <fstream>)


——提示工程(Prompt Engineering))


:數據共享架構)







