
for range 中賦值的變量,這個變量指向的是真實的地址嗎,還是臨時變量
不是真實地址,是臨時變量
package mainimport "fmt"func main() {slice := []int{4, 2, 3}for _, v := range slice {fmt.Println(v, &v) // 這里的 v 是臨時變量}for i := range slice{fmt.Println(i, &i)fmt.Println(slice[i], &slice[i])}fmt.Println("sjhdjaskhdjkashdkas")for _, v := range slice {fmt.Println(v, &v) // 這里的 v 是臨時變量}for i := range slice{fmt.Println(i, &i)fmt.Println(slice[i], &slice[i])}
}
如果在for range里面有一個函數,這個函數需要傳一個指針,這時候應該怎么寫,這時候會進行拷貝嗎
slice內容未改變, 換成另一個方法才會改變
for _,v := range x
是值拷貝
package mainimport "fmt"func main() {slice := []int{4, 2, 3}for _,v := range slice{fmt.Println(v, &v)doDubole(&v)fmt.Println(v, &v)}fmt.Println(slice)
}func doDubole(x *int){fmt.Println(*x, x)*x = *x*2
}
有用過go link?那么在什么情況下如果我不賦給一個新的變量,它也是沒問題的?
在 Go 語言中,link 通常指的是鏈接操作,主要用于將多個包和可執行文件組合成一個單一的可執行文件。
如果我要在defer里面修改return里面的值呢?這時怎么寫?
命名返回值
返回110
package mainimport "fmt"func main() {ans := get(10)fmt.Println(ans)
}
func get(x int)(ans int){defer func(){ans += 10}()ans = x*10return
}
map時協程安全嗎?有什么是協程安全的?
在 Go 中,map 不是協程安全的。如果多個協程同時讀寫同一個 map,可能會導致數據競爭和不確定的行為。因此,使用 map 時需要確保并發安全。
協程安全的解決方案:
-
使用
sync.Mutex或sync.RWMutex:- 通過互斥鎖確保對
map的訪問是安全的。
var mu sync.Mutex m := make(map[string]int)func safeWrite(key string, value int) {mu.Lock()m[key] = valuemu.Unlock() }func safeRead(key string) int {mu.Lock()value := m[key]mu.Unlock()return value } - 通過互斥鎖確保對
-
使用
sync.Map:- Go 提供了一個內置的并發安全的
map類型sync.Map,適合并發讀寫。
var m sync.Map// 存儲值 m.Store("key", 42)// 讀取值 value, ok := m.Load("key") - Go 提供了一個內置的并發安全的
-
使用通道 (Channels):
- 通過通道來同步對數據的訪問,而不是直接操作
map。
type request struct {key stringvalue intreply chan int }func mapHandler(requests <-chan request) {m := make(map[string]int)for req := range requests {m[req.key] = req.valuereq.reply <- m[req.key]} } - 通過通道來同步對數據的訪問,而不是直接操作
總結:
map在并發環境下不安全。- 使用互斥鎖、
sync.Map或通道可以實現協程安全。
channel有緩沖區和無緩沖區的區別?
無緩沖:必須有人接收才能發送,需要保證順序性
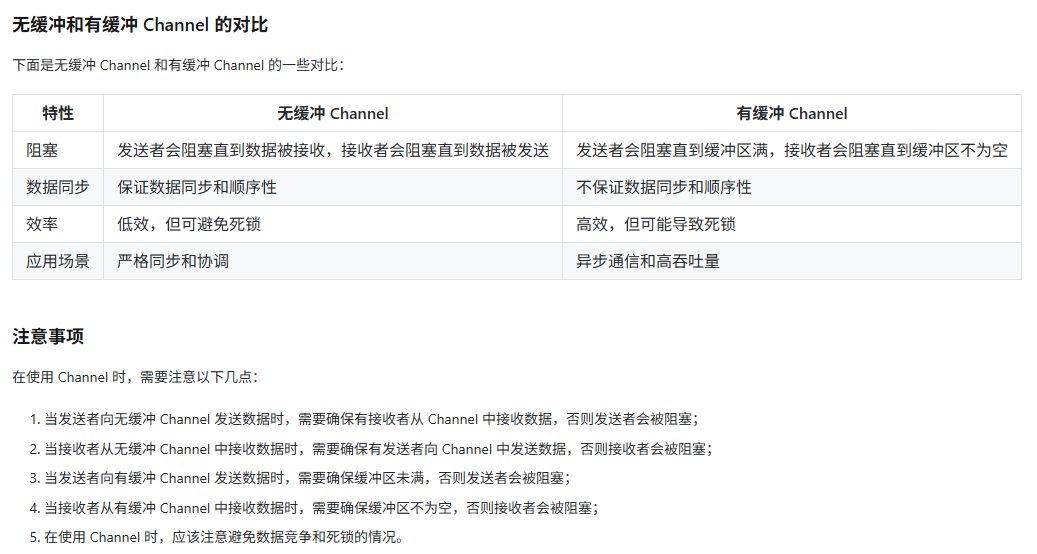
以下是有緩沖區和無緩沖區通道的實際應用場景示例。
1. 有緩沖區的通道:任務隊列
在一個工作池中,多個工作者從一個任務隊列中獲取任務。使用有緩沖區的通道可以存儲一定數量的任務,提高效率。
package mainimport ("fmt""time"
)func worker(id int, tasks <-chan int) {for task := range tasks {fmt.Printf("工作者 %d 處理任務 %d\n", id, task)time.Sleep(time.Second) // 模擬任務處理時間}
}func main() {tasks := make(chan int, 5) // 創建一個緩沖區為 5 的通道// 啟動多個工作者for i := 1; i <= 3; i++ {go worker(i, tasks)}// 發送任務for i := 1; i <= 10; i++ {fmt.Printf("發送任務 %d\n", i)tasks <- itime.Sleep(500 * time.Millisecond) // 模擬任務生成時間}close(tasks) // 關閉通道time.Sleep(5 * time.Second) // 等待所有任務完成
}
2. 無緩沖區的通道:同步信號
在兩個 goroutine 之間使用無緩沖區通道進行同步,確保一個 goroutine 在另一個完成后再繼續執行。
package mainimport ("fmt"
)func main() {done := make(chan struct{}) // 創建一個無緩沖區的信號通道go func() {fmt.Println("工作者正在處理任務...")// 模擬任務處理// ...done <- struct{}{} // 發送完成信號}()// 等待工作者完成<-donefmt.Println("任務完成,主程序繼續執行。")
}
總結
- 有緩沖區的通道適用于任務隊列等場景,可以提高并發性能。
- 無緩沖區的通道適用于需要同步的場景,確保操作的順序。
我能不能在寫入channel的時候,先判斷它阻不阻塞再寫?
在 Go 中,無法直接檢查一個通道是否會阻塞。通道的發送和接收都是阻塞操作,具體行為取決于通道的狀態和接收方是否準備好。
解決方案
如果你想在寫入通道之前判斷是否會阻塞,可以使用非阻塞發送配合 select 語句。例如:
package mainimport ("fmt"
)func main() {ch := make(chan int, 1) // 創建一個緩沖通道,容量為 1// 先嘗試發送select {case ch <- 42: // 非阻塞發送fmt.Println("寫入成功")default:fmt.Println("通道已滿,寫入阻塞")}// 再次嘗試發送select {case ch <- 99:fmt.Println("寫入成功")default:fmt.Println("通道已滿,寫入阻塞")}// 從通道讀取值value := <-chfmt.Println("讀取值:", value)
}
關鍵點:
select語句:允許你進行非阻塞操作。default分支:在通道不能發送或接收時執行,避免阻塞。
通過這種方式,你可以在寫入通道之前判斷通道的狀態,從而避免阻塞。
mutex是個悲觀鎖還是樂觀鎖,樂觀鎖和悲觀鎖的區別?
Mutex 是悲觀鎖,適用于高沖突的場景。
樂觀鎖 適用于低沖突的場景,減少了加鎖帶來的性能開銷。
需要知道一個goroutine里面的一個函數是否執行成功還是失敗,應該怎么寫
要在一個 goroutine 中檢查一個函數是否執行成功,可以使用通道(channel)來傳遞結果或錯誤信息。以下是一個示例,演示如何實現這一點:
示例代碼
package mainimport ("errors""fmt""time"
)func doWork(resultChan chan<- string, errChan chan<- error) {// 模擬一些工作time.Sleep(2 * time.Second)// 假設工作成功,返回結果// resultChan <- "工作成功"// 假設工作失敗,返回錯誤errChan <- errors.New("工作失敗")
}func main() {resultChan := make(chan string)errChan := make(chan error)go doWork(resultChan, errChan)select {case result := <-resultChan:fmt.Println("結果:", result)case err := <-errChan:fmt.Println("錯誤:", err)case <-time.After(3 * time.Second): // 設置超時fmt.Println("操作超時")}
}
關鍵點
-
通道:
- 使用
resultChan來傳遞成功結果。 - 使用
errChan來傳遞錯誤信息。
- 使用
-
select語句:- 通過
select等待通道中的結果或錯誤。 - 如果有結果返回,則打印結果;如果有錯誤返回,則打印錯誤。
- 通過
-
超時處理:
- 可以使用
time.After設置超時處理,避免等待太久。
- 可以使用
通過這種方式,你可以有效地在 goroutine 中檢查函數的執行狀態。
了解過Go的內存逃逸嗎?
是的,Go 的內存逃逸(Escape Analysis)是一個重要的功能,用于優化內存分配和管理。
什么是內存逃逸?
內存逃逸指的是在 Go 中某個變量的生命周期超出了其原本的作用域。這意味著該變量不能在棧上分配,而必須在堆上分配,以確保在函數返回后仍然能夠訪問。
如何工作?
-
棧 vs 堆:
- 棧:用于存儲局部變量,分配和釋放速度快,但生命周期受限于函數調用。
- 堆:用于動態分配內存,生命周期更長,但分配和釋放速度較慢。
-
逃逸分析:
- Go 編譯器會在編譯時分析變量的使用情況,判斷它是否會“逃逸”到堆上。
- 如果變量的地址被返回,或在函數外部使用,它將被分配到堆上。
示例
以下是一個簡單的例子,展示了內存逃逸的情況:
package mainimport "fmt"type Person struct {Name string
}func NewPerson(name string) *Person {return &Person{Name: name} // 逃逸到堆
}func main() {p := NewPerson("Alice")fmt.Println(p.Name)
}
在上面的代碼中,NewPerson 函數返回一個指向 Person 結構體的指針,這導致 Person 實例被分配到堆上,因為它的生命周期超出了函數的作用域。
逃逸分析的好處
- 性能優化:通過避免不必要的堆分配,提升性能。
- 內存管理:減少內存泄漏的風險,幫助開發者更好地管理內存。
如何檢查逃逸分析
可以使用 go build -gcflags -m 命令來查看編譯器的逃逸分析信息:
go build -gcflags -m yourfile.go
這將顯示哪些變量逃逸到堆上,以及相關的分析信息。
總結
內存逃逸分析是 Go 的一項重要特性,幫助編譯器優化內存分配,提高程序性能。理解內存逃逸有助于編寫更高效的 Go 代碼。
場景:1GB文件,每個單詞不超過16字節,在1M的內存里,得到出現頻率最高的100個單詞
由于文件大小為1GB,而內存的大小只有1MB,因此不能一次把所有的詞讀入到內存中去處理,可以采用分治的方法進行處理:把一個文件分解為多個小的子文件,從而保證每個文件的大小都小于1MB,進而可以直接被讀取到內存中處理。
第一步:使用多路歸并排序對大文件進行排序,這樣相同的單詞肯定是挨著的
第二步:
① 初始化一個 100 個節點的小頂堆,用于保存 100 個出現頻率最多的單詞
② 遍歷整個文件,一個單詞一個單詞的從文件中取出來,并計數
③ 等到遍歷的單詞和上一個單詞不同的話,那么上一個單詞及其頻率如果大于堆頂的詞的頻率,那么放在堆中,否則不放
最終,小頂堆中就是出現頻率前 100 的單詞了
多路歸并排序對大文件進行排序的步驟如下:
① 將文件按照順序切分成大小不超過 512KB 的小文件,總共 2048 個小文件
② 使用 1MB 內存分別對 2048 個小文件中的單詞進行排序
③ 使用一個大小為 2048 大小的堆,對 2048 個小文件進行多路排序,結果寫到一個大文件中
json和protobuf的區別
JSON(JavaScript Object Notation)和 Protobuf(Protocol Buffers)是兩種常用的數據序列化格式。它們各自有不同的特點和適用場景。以下是它們之間的主要區別:
1. 數據格式
-
JSON:
- 人類可讀的文本格式,易于調試和查看。
- 數據使用鍵值對的結構表示,支持基本數據類型(字符串、數字、布爾值、數組和對象)。
-
Protobuf:
- 二進制格式,不易于人類直接閱讀。
- 需要預先定義數據結構(消息格式)并編譯生成代碼來處理數據。
2. 性能
-
JSON:
- 解析和序列化速度較慢,因為它是文本格式。
- 數據體積相對較大,尤其是在傳輸大量數據時。
-
Protobuf:
- 解析和序列化速度快,效率高。
- 數據體積較小,適合網絡傳輸和存儲。
3. 可擴展性
-
JSON:
- 結構靈活,不需要預定義模式,可以隨意添加字段,但對版本控制支持較差。
-
Protobuf:
- 需要預定義結構,但支持向后兼容和向前兼容,可以安全地添加或刪除字段。
4. 語言支持
-
JSON:
- 幾乎所有編程語言都支持 JSON 解析和生成。
-
Protobuf:
- 支持多種編程語言,但需要使用特定的工具生成代碼。
5. 使用場景
-
JSON:
- 適用于配置文件、Web API(如 RESTful API)、輕量級數據傳輸等場景。
-
Protobuf:
- 適用于高性能網絡通信、大規模數據存儲、微服務架構等場景。
總結
- JSON:易讀、靈活,但性能較低,適合簡單的應用場景。
- Protobuf:高效、可擴展,適合對性能和數據體積有較高要求的應用場景。
Go怎么調試的,會Goland遠程調試嗎?
-
安裝dlv
在Linux服務器上執行:go install github.com/go-delve/delve/cmd/dlv@latest,安裝dlv調試工具,因為是go編譯的可執行程序,可以隨意復制,其他環境甚至都可以不安裝go語言環境。 -
按照goland提示添加遠程調試
-
添加編譯配置
-
在服務器運行
將可執行程序上傳到服務器,并使用dlv運行:
dlv --listen=:2345 --headless=true --api-version=2 --accept-multiclient exec ./test001_linux
帶命令行參數,在可執行程序后面帶上 --,再后面就是命令行參數:
dlv --listen=:2345 --headless=true --api-version=2 --accept-multiclient exec ./test001_linux – -s 123
- 然后再window的goland上運行調試
算法:查找字符串子串,有哪些算法?
暴力匹配:簡單,但效率低。
KMP:高效,適合單個子串匹配。O(m+n)
部分匹配表(LPS 數組):
在開始匹配之前,KMP 算法首先構建一個部分匹配表(Longest Prefix Suffix,LPS)。
LPS 數組的每個元素 lps[i] 表示子串 pattern[0…i] 中的最長相等前后綴的長度。
LPS 數組可以幫助我們在匹配失敗時,不必回溯主串的指針,而是根據已匹配的部分直接跳到下一個可能匹配的位置。
匹配過程:
使用兩個指針,i 指向主串,j 指向子串。
逐個比較主串和子串的字符:
如果字符匹配,兩個指針同時向后移動。
如果不匹配且 j > 0,則根據 LPS 數組調整子串指針 j,而不移動主串指針 i。
如果 j 達到子串的長度,說明找到匹配,記錄匹配位置。




)







詳解)


)

)

)