1st author: Paul Soulos
paper: Differentiable Tree Operations Promote Compositional Generalization ICML 2023
code: psoulos/dtm: Differentiable Tree Machine
1. 問題與思路
現代深度學習在連續向量空間中取得了巨大成功,然而在處理具有顯式結構(Structure),尤其是離散(Discrete) 符號結構的任務時,例如程序合成、邏輯推理、自然語言的句法和語義結構,其組合泛化(Compositional Generalization) 能力常常捉襟見肘。傳統的符號系統(GOFAI)天然具備結構處理和組合泛化能力,但其離散性導致難以與基于梯度的端到端學習框架兼容。這篇論文正是試圖彌合這一裂痕,其關鍵是:如何在連續向量空間中實現可微(Differentiable) 的、結構感知(Structure-aware) 的符號操作,從而賦予神經網絡強大的組合泛化能力。
1.1. 問題:結構操作的“不可微”
考慮對樹結構進行操作的任務,比如句法樹轉換、邏輯形式生成。這些任務本質上是應用一系列離散的、符號性的樹操作(如 Lisp 中的 car, cdr, cons)來轉換結構。問題在于,這些離散操作在數學上通常是不可微的,這意味著我們無法直接通過梯度下降來學習執行這些操作的序列或策略。現有的神經網絡模型,即使是 Tree-based Transformer 或 LSTM,雖然能編碼樹結構,但其內部的處理(通常是黑箱的非線性變換)仍然難以顯式地執行或學習離散的結構操作序列,導致在面對訓練中未見的結構組合時泛化能力差。

car,cdr,cons是 Lisp 對列表的三種操作, 其使用嵌套列表存儲樹.car表示取左子樹,cdr表示取右子樹,cons表示創建新樹。Fiugre 2 是三個操作的例子, 被操作的是圖片中間以 ‘NP’ 為根的一顆句法分析樹。
1.2. 思路:重定義操作為可微操作
這篇論文的獨特之處在于,它并沒有試圖去“軟化”離散操作本身,而是將離散的符號結構及其操作整體嵌入到一個連續的向量空間中,并在這個空間中定義出與原離散操作等價的可微線性變換。具體來說,他們使用了 張量積表示 (Tensor Product Representation, TPR) 來編碼樹結構。
TPR 的核心思想是將一個結構分解為角色 (Roles) 和填充物 (Fillers) 的綁定。對于樹結構而言,一個節點的位置可以看作一個“角色”,該節點的標簽或子結構則是這個“填充物”。一個完整的樹結構 T T T 被表示為所有 “角色-填充物” 對的張量積之和:
T = ∑ i f i ? r i T = \sum_i f_i \otimes r_i T=i∑?fi??ri?
其中 f i f_i fi? 是第 i i i 個位置的填充物(例如,詞匯的向量表示), r i r_i ri? 是第 i i i 個位置的角色(表示該位置在樹中的結構信息向量)。 ? \otimes ? 是張量積運算。
例如 f 011 f_{011} f011? 是從根節點開始以"左右右"路徑到達節點的填充物向量 (0表示左, 1表示右),下標從左往右讀。 f ? f_\epsilon f?? 表示根節點。
關鍵來了:如果在向量空間中精心設計角色向量 r i r_i ri?,就可以將 car, cdr, cons 這些離散的樹操作轉化為對這個 TPR 向量 T T T 的線性變換。
2. 可微樹操作
2.1. 定義可微操作
關于張量積與張量積表示 TPR的解釋可以看這篇文章: 張量積表示 (Tensor Product Representation, TPR)-CSDN博客
我們聚焦于二叉樹 ( b = 2 b=2 b=2)。假設樹的最大深度為 D D D。樹中可能的節點位置總數 N = ( 2 D + 1 ? 1 ) / ( 2 ? 1 ) = 2 D + 1 ? 1 N = (2^{D+1} - 1) / (2-1) = 2^{D+1} - 1 N=(2D+1?1)/(2?1)=2D+1?1。我們可以生成一組 N N N 個標準正交 (Orthonormal) 的角色向量 r i ∈ R d r r_i \in \mathbb{R}^{d_r} ri?∈Rdr?,其中 d r = N d_r = N dr?=N。
對于一個樹 T = ∑ i = 1 N f i ? r i T = \sum_{i=1}^N f_i \otimes r_i T=∑i=1N?fi??ri?,其中 f i f_i fi? 是填充物向量。由于角色向量是標準正交的,我們可以通過內積恢復任何位置的填充物: f i = ? T , r i ? f_i = \langle T, r_i \rangle fi?=?T,ri??。或者更一般地,通過與角色向量 r i r_i ri? 的對偶空間操作來實現 ( 論文中使用矩陣乘法 T r i Tr_i Tri?,如果將 T T T 看作一個高階張量,這等價于在角色維度上與 r i r_i ri? 做張量的收縮)。
現在,如何用矩陣操作實現 car, cdr, cons?
論文中給出了基于角色向量的線性變換矩陣。考慮 car 操作,它提取根節點的左子樹。這需要將左子樹中的每個節點的“角色”向上移動一層。cdr 類似,提取右子樹。cons 則根據兩個子樹構建一個新的父節點樹。
定義矩陣 D c D_c Dc? 和 E c E_c Ec?:
D c D_c Dc? 矩陣用于提取第 c c c 個孩子( c = 0 c=0 c=0 為左孩子 car, c = 1 c=1 c=1 為右孩子 cdr),并將其子樹的角色向上提升一層。
E c E_c Ec? 矩陣用于將一個子樹的角色向下推一層,以便將其作為新樹的第 c c c 個孩子。
形式上,對于角色空間中的操作,這些矩陣定義為:
D c = I F ? ∑ x ∈ P r x r c x ? E c = I F ? ∑ x ∈ P r c x r x ? D_c = I_F \otimes \sum_{x \in P} r_x r_{cx}^\top\\ E_c = I_F \otimes \sum_{x \in P} r_{cx} r_x^\top Dc?=IF??x∈P∑?rx?rcx??Ec?=IF??x∈P∑?rcx?rx??
其中 I F I_F IF? 是填充物空間 F F F 上的單位矩陣, P = { r x ∥ ∣ x ∣ < D } P=\{r_x\|\:|x|<D\} P={rx?∥∣x∣<D} 是所有深度小于 D D D 的路徑對應的角色集合, r x r_x rx? 是路徑 x x x 的角色向量, r c x r_{cx} rcx? 是在路徑 x x x 前面加上 c c c 形成新路徑的角色向量。這兩個公式不太好理解, 可以看下一小節的例子。
這樣,可微的 car , cdr 和 cons 操作(將 T 0 T_0 T0? 作為左子樹, T 1 T_1 T1? 作為右子樹)可以表示為對 TPR 向量 T T T 的矩陣操作:
car ( T ) = D 0 T cdr ( T ) = D 1 T cons ( T 0 , T 1 ) = E 0 T 0 + E 1 T 1 \text{car}(T) = D_0 T\\ \text{cdr}(T) = D_1 T\\ \text{cons}(T_0, T_1) = E_0 T_0 + E_1 T_1 car(T)=D0?Tcdr(T)=D1?Tcons(T0?,T1?)=E0?T0?+E1?T1?
注意,cons 還需要指定新創建的根節點的填充物 s s s。也就是將 s ? r r o o t s \otimes r_{root} s?rroot? 加入到結果中 ( r r o o t r_{root} rroot? 是根節點的角色向量)。
所以,在向量空間中,這些原本離散的樹操作,就變成了 TPR 向量上的線性變換。整個 DTM 模型的核心操作步驟,就是對輸入的 TPR 樹進行這些可微的線性操作,并根據學習到的權重進行線性組合。
2.2. 以 cdr 操作為例

如上圖, T ′ = car ( T ) T'=\text{car}(T) T′=car(T), 其中 T T T 的 P = { r x ∥ ∣ x ∣ < 3 } = { r ? , r 0 , r 1 } P=\{r_x\|\:|x|<3\}=\{r_\epsilon,r_0,r_1\} P={rx?∥∣x∣<3}={r??,r0?,r1?}, 我們的目的是: 將節點 B 的位置 r 0 → r ? r_0\to r_\epsilon r0?→r??, 節點 D 的位置 r 00 → r 0 r_{00}\to r_0 r00?→r0?, 節點 B 的位置 r 01 → r 1 r_{01}\to r_1 r01?→r1?.
car ( T ) = D 0 T = ( I F ? ∑ x ∈ P r x r c x ? ) ( ∑ i f i ? r i ) = ( I F ? ( ( r ? r 0 ? ? ) + ( r 0 r 00 ? ) + ( r 1 r 01 ? ) ) ? let = R ) ( ∑ i f i ? r i ) = ( I F ? R ) ( ( f ? ? r ? ) + ( f 0 ? r 0 ) + ( f 1 ? r 1 ) + ( f 00 ? r 00 ) + ( f 01 ? r 01 ) + ( f 10 ? r 10 ) ) = ( I F ? R ) ( f ? ? r ? ) + ( I F ? R ) ( f 0 ? r 0 ) + ? + ( I F ? R ) ( f 10 ? r 10 ) = ( I F f ? ) ? ( R r ? ) + ( I F f 0 ) ? ( R r 0 ) + ? + ( I F f 10 ) ? ( R r 10 ) = f ? ? ( [ ( r ? r 0 ? ? ) + ( r 0 r 00 ? ) + ( r 1 r 01 ? ) ] r ? ) + ? + f 10 ? ( [ ( r ? r 0 ? ? ) + ( r 0 r 00 ? ) + ( r 1 r 01 ? ) ] r 10 ) = 0 + f 0 ? ( r ? r 0 ? ? r 0 ) + 0 + f 00 ? ( r 0 r 00 ? r 00 ) + f 01 ? ( r 1 r 01 ? r 01 ) + 0 = f 0 ? r ? + f 00 ? r 0 + f 01 ? r 1 \begin{align} \text{car}(T)&=D_0T\\ &= \bigg( I_F \otimes \sum_{x \in P} r_x r_{cx}^\top \bigg)\bigg (\sum_i f_i \otimes r_i \bigg)\\ &= \bigg( I_F \otimes \underbrace{\big((r_\epsilon r_{0\epsilon}^\top)+(r_0 r_{00}^\top)+(r_1 r_{01}^\top)\big)}_{\text{let}=R} \bigg)\bigg (\sum_i f_i \otimes r_i \bigg) \\ &= \left (I_F \otimes R\right )\big( (f_{\epsilon}\otimes r_\epsilon)+(f_0\otimes r_0)+(f_1\otimes r_1)+(f_{00}\otimes r_{00})+(f_{01}\otimes r_{01})+(f_{10}\otimes r_{10})\big)\\ &= (I_F \otimes R) (f_{\epsilon}\otimes r_\epsilon)+(I_F \otimes R) (f_{0}\otimes r_0)+\dots+(I_F \otimes R)(f_{10}\otimes r_{10})\\ &= (I_Ff_\epsilon)\otimes (Rr_\epsilon)+(I_Ff_0)\otimes (Rr_0)+\dots+(I_Ff_{10})\otimes (Rr_{10})\\ &= f_\epsilon\otimes (\textcolor{green}{\big[(r_\epsilon r_{0\epsilon}^\top)+(r_0 r_{00}^\top)+(r_1 r_{01}^\top)\big]}r_\epsilon)+\dots+f_{10}\otimes (\textcolor{green}{\big[(r_\epsilon r_{0\epsilon}^\top)+(r_0 r_{00}^\top)+(r_1 r_{01}^\top)\big]}r_{10})\\ &= 0+f_0\otimes (r_\epsilon r_{0\epsilon}^\top r_0)+0+f_{00}\otimes (r_0 r_{00}^\top r_{00})+f_{01}\otimes (r_1 r_{01}^\top r_{01})+0\\ &= f_0\otimes r_\epsilon+f_{00}\otimes r_0+f_{01}\otimes r_1\\ \end{align} car(T)?=D0?T=(IF??x∈P∑?rx?rcx??)(i∑?fi??ri?)=(IF??let=R ((r??r0???)+(r0?r00??)+(r1?r01??))??)(i∑?fi??ri?)=(IF??R)((f???r??)+(f0??r0?)+(f1??r1?)+(f00??r00?)+(f01??r01?)+(f10??r10?))=(IF??R)(f???r??)+(IF??R)(f0??r0?)+?+(IF??R)(f10??r10?)=(IF?f??)?(Rr??)+(IF?f0?)?(Rr0?)+?+(IF?f10?)?(Rr10?)=f???([(r??r0???)+(r0?r00??)+(r1?r01??)]r??)+?+f10??([(r??r0???)+(r0?r00??)+(r1?r01??)]r10?)=0+f0??(r??r0???r0?)+0+f00??(r0?r00??r00?)+f01??(r1?r01??r01?)+0=f0??r??+f00??r0?+f01??r1???
上方推導過程中:
- 第 4 到第 5 步, 使用了線性性質的分配律. A ( B + C ) = A B + C D A(B+C)=AB+CD A(B+C)=AB+CD.
- 第 5 到 第 6步, 使用了張量積性質, ( A ? B ) ( v ? w ) = ( A v ) ? ( B w ) (A\otimes B)(v\otimes w)=(Av)\otimes(Bw) (A?B)(v?w)=(Av)?(Bw).
- 第 7 步中, 由于 r i r_i ri? 正交, 則 r i ? r i = 1 , r i ? r ≠ i = 0 r_i^\top r_i = 1, r_i^\top r_{\neq i} = 0 ri??ri?=1,ri??r=i?=0.
- r x r c x ? r_x r_{cx}^\top rx?rcx??: 這是一個外積,得到一個矩陣。當這個矩陣作用于一個角色向量 r y r_y ry? 時,如果 y = c x y = cx y=cx,結果是 r x r_x rx?;否則結果是零向量(因為角色向量是正交的)。這實現了一個“將子節點位置的角色映射到父節點位置的角色”的操作。
- ∑ x ∈ P r x r c x ? \sum_{x \in P} r_x r_{cx}^\top ∑x∈P?rx?rcx??: 這個求和構建了一個總的矩陣,它將所有可能的“子節點位置 c x cx cx 的角色”映射到對應的“父節點位置 x x x 的角色”。
I F ? ( ∑ x ∈ P r x r c x ? ) I_F \otimes (\sum_{x \in P} r_x r_{cx}^\top) IF??(∑x∈P?rx?rcx??)整個算子 D c D_c Dc? 作用于一個樹的 TPR 表示 T = ∑ i f i ? r i T = \sum_{i} f_i \otimes r_i T=∑i?fi??ri? 時,由于張量積的性質 ( A ? B ) ( v ? w ) = ( A v ) ? ( B w ) (A \otimes B)(v \otimes w) = (Av) \otimes (Bw) (A?B)(v?w)=(Av)?(Bw),它會獨立地作用于填充物向量和角色向量。 I F I_F IF? 作用于 f i f_i fi? 保持不變,$ (\sum r_x r_{cx}^\top)$ 作用于 r i r_i ri?。如果 r i r_i ri? 是某個 r c x r_{cx} rcx?,它就會被映射到 r x r_x rx?;如果 r i r_i ri? 是其他角色,它會被映射到零向量。
3. DTM 架構與運作機制
基于上一部分提到的向量空間中的可微樹操作,論文構建了可微樹機器(Differentiable Tree Machine, DTM) 這一架構。DTM 的核心思想是,將離散的符號操作邏輯與連續的神經網絡決策過程解耦。
3.1. DTM 架構
DTM 主要由三個核心組件構成(如論文 Figure 1 所示):
- 神經樹 Agent (Neural Tree Agent): 一個學習組件,負責在每一步決策要執行什么操作 (car, cdr, cons) 以及操作作用在記憶中的哪些樹上。
- 可微樹解釋器 (Differentiable Tree Interpreter): 非學習組件,根據神經樹 Agent 的指令,執行上一節描述的、預定義的可微線性樹操作。
- 樹記憶 (Tree Memory): 一個外部記憶單元,用于存儲中間計算過程中產生的樹的 TPR 表示。
DTM 是個很有意思的設計:將復雜的、黑箱的非線性學習能力被封裝在神經樹 Agent 中,而對樹結構的顯式、結構感知操作則通過可微樹解釋器以透明、可微的方式實現。
3.1.1. 神經樹 Agent
神經樹 Agent 是 DTM 中唯一包含可學習參數的部分。它被實現為一個標準的 Transformer 層(包含多頭自注意力、前饋網絡等)。
在每個計算步驟(timestep l l l),神經樹 Agent (Neural Tree Agent) 會接收一個輸入序列。這個序列包括以下編碼:
- 操作編碼 (Operation Encoding)
- 根符號編碼 (Root Symbol Encoding)
- 樹記憶 (Tree Memory) 中所有樹的編碼。被讀取時,會從 TPR 維度 d t p r d_{tpr} dtpr? 被壓縮到 Transformer 輸入維度 d m o d e l d_{model} dmodel?,這通過一個可學習的線性變換 W s h r i n k ∈ R d t p r × d m o d e l W_{shrink}\in\mathbb{R}^{d_{tpr}\times d_{model}} Wshrink?∈Rdtpr?×dmodel? 實現。
Transformer 的輸入序列長度會隨著每個步驟的進行而增長,每一步包含前一步驟新產生的樹的編碼 (如論文 Fiuger 4)。
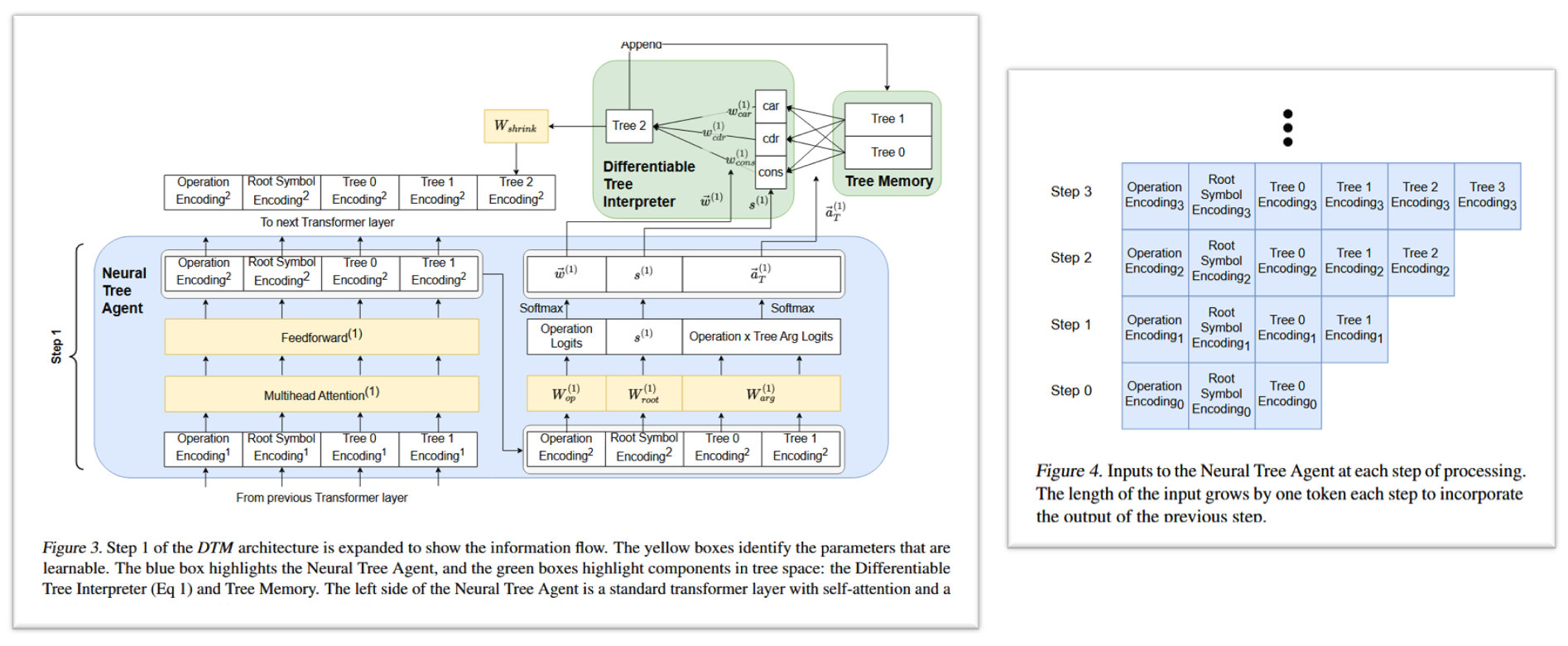
在每個計算步驟 l l l,神經樹 Agent 的輸出被用來做以下決策:
-
操作選擇 ( w ( l ) w^{(l)} w(l)): 決定 car, cdr, cons 三種操作各自的權重。通過將一個特殊 token 的輸出投影到 3 維向量,再經過 softmax 得到 w ? ( l ) = ( w c a r ( l ) , w c d r ( l ) , w c o n s ( l ) ) \vec{w}^{(l)} = (w_{car}^{(l)}, w_{cdr}^{(l)}, w_{cons}^{(l)}) w(l)=(wcar(l)?,wcdr(l)?,wcons(l)?),其中 ∑ w i ( l ) = 1 \sum w_i^{(l)} = 1 ∑wi(l)?=1。
-
參數選擇 ( a T ( l ) a_T^{(l)} aT(l)?): 決定每種操作的輸入應該“讀取”記憶中的哪些樹,以及它們的權重。例如,對于 car 操作,它需要一個被操作樹 T c a r ( l ) T_{car}^{(l)} Tcar(l)? (輸入樹)。神經樹 Agent 會為記憶中的每一棵樹計算一個權重,然后通過 softmax 歸一化。最終 T c a r ( l ) T_{car}^{(l)} Tcar(l)? 是記憶中所有樹的加權和 (blended tree)。Cons 操作需要兩個輸入樹 T c o n s 0 ( l ) T_{cons0}^{(l)} Tcons0(l)? 和 T c o n s 1 ( l ) T_{cons1}^{(l)} Tcons1(l)?,同樣通過加權求和獲得。這組用于選擇參數的權重記為 a ? T ( l ) \vec{a}_{T}^{(l)} aT(l)?。
-
新根符號選擇 ( s ( l ) s^{(l)} s(l)): 如果 w ( l ) w^{(l)} w(l) 選擇了 cons 操作,還需要確定新創建的根節點的符號。神經樹 Agent 通過另一個特殊 token 的輸出預測一個符號向量 s ( l ) s^{(l)} s(l)。
這 3 個輸出是 Transformer 最后一層通過三個線性投影 W o p ∈ R d m o d e l × 3 ; W r o o t ∈ R d m o d e l × d s y m b o l ; W a r a ∈ R d m o d e l × 4 W_{op}\in\mathbb{R}^{d_{model}\times3};\ W_{root}\in\mathbb{R}^{d_{model}\times d_{symbol}};\ W_{ara}\in\mathbb{R}^{d_{model}\times4} Wop?∈Rdmodel?×3;?Wroot?∈Rdmodel?×dsymbol?;?Wara?∈Rdmodel?×4 得到 ( Figure 3 藍塊的右側)。
值得注意的是,Agent 的這些選擇(操作權重 w ( l ) w^{(l)} w(l) 和參數權重 a T ( l ) a_T^{(l)} aT(l)?)都是通過 softmax 產生的軟選擇(Soft Selection),這意味著在訓練初期,DTM 會在不同的操作和不同的輸入樹之間進行“混合”(blending)。論文的實驗表明,這種混合對于學習至關重要,盡管在訓練收斂后,權重通常會趨向于 one-hot 分布,退化為離散的操作序列。
3.1.2. 樹記憶
樹記憶是一個簡單的外部存儲,按順序存放每個計算步驟產生的 TPR 樹。在步驟 l l l 計算時,步驟 0 0 0 到 l ? 1 l-1 l?1 生成的所有樹都在記憶中,可以被神經樹 Agent 讀取并作為操作的參數。新的計算結果會被寫入下一個可用的記憶槽位。我們用 M ( l ? 1 ) \mathcal{M}^{(l-1)} M(l?1) 表示在步驟 l l l 時被操作的記憶樹。
3.1.3. 可微樹解釋器
將神經樹 Agent 的決策 (輸出) 與可微樹解釋器結合,(可微樹解釋器就是一個預定義的公式, 以產生輸出 O O O), DTM 的單步計算可以描述如下:
在計算步驟 l l l,神經樹 Agent 根據記憶中的樹(TPR 向量集合 M ( l ? 1 ) \mathcal{M}^{(l-1)} M(l?1))計算出操作權重 w ? ( l ) \vec{w}^{(l)} w(l)、參數選擇權重 a ? T ( l ) \vec{a}_{T}^{(l)} aT(l)? 以及新的根符號 s ( l ) s^{(l)} s(l)。
參數選擇權重 a ? ? T ( l ) \vec{a}*{T}^{(l)} a?T(l) 定義了每種操作的輸入樹。假設記憶中有 K K K 棵樹 M 1 , … , M K M_1, \dots, M_K M1?,…,MK?,則:
T c a r ( l ) = ∑ k = 1 K a c a r , k ( l ) M k T c d r ( l ) = ∑ k = 1 K a c d r , k ( l ) M k T c o n s 0 ( l ) = ∑ k = 1 K a c o n s 0 , k ( l ) M k ; T c o n s 1 ( l ) = ∑ k = 1 K a c o n s 1 , k ( l ) M k T_{car}^{(l)} = \sum_{k=1}^K a_{car,k}^{(l)} M_k\\ T_{cdr}^{(l)} = \sum_{k=1}^K a_{cdr,k}^{(l)} M_k\\ T_{cons0}^{(l)} = \sum_{k=1}^K a_{cons0,k}^{(l)} M_k;\ \ T_{cons1}^{(l)} = \sum_{k=1}^K a_{cons1,k}^{(l)} M_k Tcar(l)?=k=1∑K?acar,k(l)?Mk?Tcdr(l)?=k=1∑K?acdr,k(l)?Mk?Tcons0(l)?=k=1∑K?acons0,k(l)?Mk?;??Tcons1(l)?=k=1∑K?acons1,k(l)?Mk?
然后,可微樹解釋器根據操作權重 w ? ( l ) \vec{w}^{(l)} w(l) 對這些輸入樹應用對應的可微操作,并進行加權求和,得到本步驟的輸出樹 O ( l ) O^{(l)} O(l) 的 TPR 表示:
O ( l ) = w c a r ( l ) car ( T c a r ( l ) ) + w c d r ( l ) cdr ( T c d r ( l ) ) + w c o n s ( l ) ( cons ( T c o n s 0 ( l ) , T c o n s 1 ( l ) ) + s ( l ) ? r r o o t ) O^{(l)} = w_{car}^{(l)} \text{car}(T_{car}^{(l)}) + w_{cdr}^{(l)} \text{cdr}(T_{cdr}^{(l)}) + w_{cons}^{(l)} \big(\text{cons}(T_{cons0}^{(l)}, T_{cons1}^{(l)}) + s^{(l)} \otimes r_{root}\big) O(l)=wcar(l)?car(Tcar(l)?)+wcdr(l)?cdr(Tcdr(l)?)+wcons(l)?(cons(Tcons0(l)?,Tcons1(l)?)+s(l)?rroot?)
最后,這個輸出 TPR 向量 O ( l ) O^{(l)} O(l) 被寫入樹記憶的下一個順序槽位,成為下一步計算的可用輸入之一。整個過程持續固定的步數 L L L。最終,最后一步產生的樹 O ( L ) O^{(L)} O(L) 被視為模型的預測輸出樹。
3.2. 端到端訓練
DTM 是一個完全可微的模型,因此可以通過標準的反向傳播進行端到端的訓練。損失函數定義為預測輸出樹與目標樹之間的均方誤差(MSE)。具體來說,是對預測樹和目標樹中每個節點位置上的符號(填充物向量)計算 MSE。同時,對預測樹中目標樹為空的位置上的非零填充物進行 L2 懲罰,鼓勵生成稀疏、明確的樹結構。
L ( T p r e d , T t a r g e t ) = ∑ i ∈ Nodes ∥ recover ( T p r e d , r i ) ? recover ( T t a r g e t , r i ) ∥ 2 + λ ∑ i : target?node? i is?empty ∥ recover ( T p r e d , r i ) ∥ 2 \mathcal{L}(T_{pred}, T_{target}) = \sum_{i \in \text{Nodes}} \left\| \text{recover}(T_{pred}, r_i) - \text{recover}(T_{target}, r_i) \right\|^2 + \lambda \sum_{i: \text{target node } i \text{ is empty}} \left\| \text{recover}(T_{pred}, r_i) \right\|^2 L(Tpred?,Ttarget?)=i∈Nodes∑?∥recover(Tpred?,ri?)?recover(Ttarget?,ri?)∥2+λi:target?node?i?is?empty∑?∥recover(Tpred?,ri?)∥2
其中 recover ( T , r i ) \text{recover}(T, r_i) recover(T,ri?) 是從 TPR 向量 T T T 中恢復位置 i i i 的填充物向量的操作(例如 T r i Tr_i Tri?), λ \lambda λ 是懲罰系數。
T t a r g e t T_{target} Ttarget? 是目標樹(target tree),它來自用于訓練模型的數據集。
例如,在 Active ? \leftrightarrow ? Logical (主動語態轉邏輯形式) 任務中,數據集包含源樹和對應的目標樹。以下是一個來自數據集的例子:

這兩個樹的轉變是從句法結構樹 (Syntactic Tree) 到 邏輯形式樹 (Logical Form Tree) 的轉變。
- Source Tree (句法結構樹): 它展示了句子的語法結構,即單詞如何組成短語,短語如何組成句子。它反映了句子的表面結構。
S: 表示句子 (Sentence)NP: 表示名詞短語 (Noun Phrase)VP: 表示動詞短語 (Verb Phrase)DET: 表示限定詞 (Determiner)AP: 表示形容詞短語 (Adjective Phrase)N: 表示名詞 (Noun)V: 表示動詞 (Verb)ADJ: 表示形容詞 (Adjective)- 樹的結構顯示了短語的層級關系,例如
( NP ( DET some ) ( AP ( N crocodile ) ) )表示 “some crocodile” 是一個名詞短語,其中 “some” 是限定詞,“crocodile” 是名詞,而 “crocodile” 又被看作是一個形容詞短語的頭部 (在某些語法標注約定中可能會有這樣的表示方式)。- Target Tree (邏輯形式樹): 它試圖表示句子的語義或意義結構。它關注句子中主要動詞及其論元(Arguments),也就是誰做了什么,對誰做了什么。它反映了句子的深層結構或邏輯意義。
LF: 表示邏輯形式 (Logical Form)V: 表示動詞 (這里是句子的主要動詞)ARGS: 表示論元 (Arguments),也就是動詞作用的對象或參與者。- 樹的結構顯示了動詞 “washed” 是邏輯形式的核心,而它的論元是兩個名詞短語:
( NP ( DET some ) ( AP ( N crocodile ) ) )和( NP ( DET our ) ( AP ( ADJ happy ) ( AP ( ADJ thin ) ( AP ( N donkey ) ) ) ) ) )。這表示 “washed” 這個動作發生在 “some crocodile” 和 “our happy thin donkey” 之間。這種轉變是從關注句子的表面語法結構到關注句子的語義關系的抽象過程。
在這個例子中, T t a r g e t T_{target} Ttarget? 就是上述的 Target Tree。模型訓練的目標是使預測樹 T p r e d T_{pred} Tpred? 盡可能接近這個目標樹 T t a r g e t T_{target} Ttarget?。損失函數衡量了預測樹在每個節點上與目標樹的差異,并懲罰了在目標樹中為空但在預測樹中被填充的節點。
通過最小化這個損失,神經樹 Agent 學會選擇合適的操作和參數,從而引導可微樹解釋器執行一系列有效的樹轉換步驟,最終生成目標樹。這種設計巧妙地結合了神經網絡的靈活性和符號操作的結構性。
4. 實驗驗證
實驗是檢驗模型優劣的唯一標準。這篇論文設計了一系列合成的樹到樹轉換任務,尤其側重考察模型在分布外(Out-of-Distribution, OOD) 的組合泛化能力。
4.1. 實驗結果
論文在合成數據集(Basic Sentence Transforms)上評估了 DTM 與多種基線模型,包括 Transformer、LSTM 及其樹結構變體 (Tree2Tree LSTM, Tree Transformer)。這些任務包括根據 Lisp 操作符序列轉換樹 (CAR-CDR-SEQ),以及主動語態 / 被動語態到邏輯形式的轉換 (ACTIVE?LOGICAL, PASSIVE?LOGICAL, ACTIVE & PASSIVE→LOGICAL)。數據集精心構造了 OOD 詞匯 ( 未見過的詞匯出現在訓練過的結構位置 ) 和 OOD 結構 ( 未見過的結構組合,例如更深的樹或新的子結構組合 ) 劃分。
實驗結果令人矚目:在大多數任務的 OOD 詞匯和 OOD 結構測試集上,DTM 都取得了接近 100% 的準確率。相比之下,所有基線模型在 OOD 結構泛化上表現慘淡,準確率普遍低于 30%,在一些語言轉換任務上甚至接近 0%。
這有力地證明了 DTM 在處理結構化數據的組合泛化方面具有顯著優勢。其關鍵在于,DTM 學習的是如何組合基本的可微結構操作,而不是僅僅學習輸入和輸出序列或樹結構的關聯模式。這種學習策略使其能夠推廣到由已知元素組成但以新方式組合的結構。
4.2. 消融實驗
為了理解 DTM 成功的原因,論文進行了一些關鍵的消融實驗:
- 預定義操作 vs. 學習操作: 如果不使用預定義的、基于 TPR 的可微 car, cdr, cons 操作,而是讓神經樹 Agent 去學習這些結構轉換矩陣 D c , E c D_c, E_c Dc?,Ec?,模型在 OOD 結構泛化上的性能急劇下降。這證明了預定義結構化可微操作的必要性。這些預定義操作提供了正確的歸納偏置,確保了模型學習到的是真正的結構轉換邏輯,而不是對特定訓練結構的記憶。
- 混合 vs. 離散選擇: 前面提到,神經樹 Agent 使用 softmax 進行軟選擇。如果強制使用 Gumbel-Softmax 使選擇在訓練初期就變得離散,DTM 的性能會完全崩潰。這反直覺地表明,訓練初期的連續混合(Blending) 是必要的。它可能允許模型在不同操作和輸入樹之間進行探索,構建平滑的損失面,從而更容易找到有效的操作序列。最終收斂時,選擇趨于離散,恢復了程序的解釋性。
這兩個消融實驗從機制上解釋了 DTM 成功的兩個策略:提供正確的結構性“積木”(預定義操作)和采用有效的學習策略(訓練中的混合)。
4.3. 可解釋性
DTM 的另一個重要優勢是其可解釋性(Interpretability) 。由于最終模型的操作選擇權重趨于 one-hot,我們可以將 DTM 的推理過程解釋為一系列離散的樹操作序列,就像一個程序。
例如,在 CAR-CDR-SEQ 任務中,模型學習到如何根據輸入的 Lisp 操作符 token 轉化為執行相應的 car/cdr 序列。在語言轉換任務中,可以追蹤每一步記憶中樹的變化以及應用的具體操作。論文中給出了邏輯形式到被動語態轉換的例子(論文 Figure 5),清晰地展示了輸入樹如何通過一系列 car, cdr, cons 操作逐步轉換為輸出樹。

更有趣的是,論文通過追蹤這個“程序”執行流,發現了模型emergent operation。在 PASSIVE?LOGICAL 任務中,目標樹需要插入源樹中不存在的詞(如 “was” 和 “by”)。car, cdr, cons 本身并不能直接插入新節點。但模型學會了一個技巧:通過對一個單子節點樹執行 car 得到一個空樹(empty tree) 的 TPR 表示,然后將這個空樹作為 cons 的子樹,并提供新的填充物作為根節點,從而有效地“插入”了一個新節點(如插入 “was”)。這種從基本操作中組合出更復雜行為的能力,以及能夠通過追蹤中間步驟來發現這種行為,是 DTM 可解釋性的體現。
5. 總結/局限/展望
-
論文的核心思想是將傳統的、離散的符號操作(例如樹操作)通過張量積表示(TPR)嵌入到一個連續且可微的空間中。這樣做并非僅僅是讓操作本身連續化,并進一步使得神經網絡能夠通過基于梯度的學習方法,學會如何智能地組合和應用這些(現在是可微的)符號操作序列,從而學習到解決特定問題的“算法”或“程序”。
這與傳統的符號主義方法形成對比,后者通常需要人工專家來設計和編碼操作序列(即算法)。DTM 中的神經樹代理正是負責學習這個“操縱符號操作”的“算法”。
-
DTM 的架構可以被形象地理解為給神經網絡提供了一個包含特定“符號表示”(TPR編碼的樹)和“符號操作”(car, cdr, cons 的可微實現)的工具箱。神經網絡(神經樹代理)的任務就是通過學習,掌握如何有效地使用這個工具箱中的工具(選擇合適的操作、作用于記憶中的樹)來將輸入的樹轉換成目標的樹,從而解決任務。通過在大規模數據上訓練,神經網絡學會了使用這些基本工具來構建更復雜的結構轉換過程。
局限
論文很類似神經圖靈機 (Neural Turing Machine, NTM) 模仿圖靈機一樣,通過引入一個有意的結構偏置,帶來了可解釋性和泛化能力的優勢,但也可能限制了模型能夠解決的問題范圍和學習到的算法的類型。論文最后也提到了這一點,例如當前模型局限于樹結構輸入輸出、共享詞匯表以及預設的最大樹深度等,并提出未來可以探索其他樹函數或數據結構。
論文中使用的 car, cdr, cons 操作是基于 Lisp 語言的基礎操作,并且 TPR 表示的設計也針對二叉樹結構。這些工具是基于對符號操作和樹結構的理解而人為定義的。雖然這些操作被證明在論文研究的任務上非常有效,特別是在組合泛化方面,但它們可能不足以表達或高效地執行所有可能的樹操作或更廣義的符號操作。






 - 使用Java操作Redis詳解)











)
