引言
今天本文準備盤一個大活,聊一聊偏特定行業一點的AI技術深入應用思考及實踐。
一、傳統設計行業項目背景與行業痛點
在橋梁設計領域,標準規范是設計的基礎,直接關系到橋梁結構的安全性、耐久性和經濟性。然而,傳統的規范應用方式存在諸多痛點,如查找效率低下、條款理解偏差、規范更新滯后等問題。隨著人工智能技術的發展,利用自然語言處理和知識圖譜等技術手段,對橋梁設計規范進行智能解析與校審,成為提升設計效率和準確性的重要途徑。
設計規范的準確理解和應用是確保工程質量和安全的關鍵。然而,當前行業普遍存在以下痛點:
- ?規范查閱效率低下?:工程師平均每天花費2.3小時查閱各類規范文件
- ?規范更新滯后?:新規范實施后,設計院平均需要6-8個月完成全員培訓
- ?人工校審疏漏?:傳統人工校審的缺陷檢出率僅為68%-75%
- ?知識傳承斷層?:資深工程師退休導致經驗型知識流失嚴重
以某設計院為例,其維護的橋梁設計標準庫包含13大類、共計47份現行規范文件,每年因規范理解偏差導致的圖紙返工成本預估可高達數十甚至數百萬元。
正好最近接觸了騰訊云MCP相關技術,我大為驚嘆,感慨萬千!
騰訊云重磅上線MCP廣場,詳情可訪問:https://cloud.tencent.com/developer/mcp?channel=ugc
在騰訊云開發者社區中,有多種MCP工具可以用于本系統的開發和優化中,以下是一些潛在的應用場景:
- ?PDF解析工具?:如pdfplumber等,可以用于規范文件的預處理,提取文本和圖像信息。
- ?自然語言處理工具?:如Tencent NLP等,可以用于智能解析模塊的開發,對設計文檔進行自然語言處理和分析。
- ?知識圖譜構建工具?:如Tencent Knowledge Graph等,可以用于知識圖譜構建模塊的開發,實現規范條款的語義化表示和關聯。
- ?智能校審工具?:如TAPD MCP Server等,可以與智能校審模塊進行集成,實現設計文檔的自動化校審和反饋。
- ?用戶交互工具?:如微信小程序等,可以用于用戶交互模塊的開發,提供友好的用戶交互界面和體驗。
有如此神器不用豈不可惜!
因此我便萌生了借助現在這些最先進人工智能技術來輔助設計工作,基于MCP搭建一個橋梁設計規范智能解析與校審系統構建實踐的想法來。
本系統的開發價值將主要體現在以下幾個方面:
- ?提高查找效率?:通過智能解析和校審系統,設計師可以快速查找規范條款,避免在傳統紙質規范中翻找浪費時間。
- ?減少理解偏差?:系統利用自然語言處理技術對規范條款進行語義化表示,有助于設計師更準確地理解條款含義,減少因理解偏差導致的設計錯誤。
- ?提升設計效率?:系統能夠自動對設計文檔進行校審,識別潛在的設計錯誤和不規范行為,從而減輕設計師的校審負擔,提升設計效率。
說干就干,我很快理清了相關思路。
二、技術框架與實施路徑
2.1 技術框架
本系統基于模型上下文協議(MCP)構建,通過集成騰訊云開發者社區中的多種MCP工具,實現橋梁設計規范的智能解析與校審。構建基于MCP(Model Context Protocol)協議的智能規范管理系統,采用"三橫四縱"架構:
[應用層]
├─ 智能問答終端
├─ 自動校審平臺
└─ 知識管理駕駛艙[能力層]
├─ 規范解析引擎
├─ 知識圖譜服務
├─ 規則推理引擎
└─ MCP協議適配器[數據層]
├─ 規范原文庫
├─ 結構化條款庫
├─ 案例知識庫
└─ 校審記錄庫這將是一個復雜的系統,需要包含多個組件:
1. PDF解析器 - 用于從橋梁設計標準規范PDF文件中提取文本內容
2. 規范解析器 - 將提取的文本結構化為條文、章節等
3. 知識圖譜構建 - 建立規范知識的關聯關系
4. 問答引擎 - 處理用戶問題并返回相關答案
5. 設計校審功能 - 對設計初稿進行自動校審
其中從規范的條文解析到構建知識圖譜進行存儲,知識圖譜作為系統的核心,需要支持語義搜索和智能問答功能。條文關系建模是核心難點,可考慮多維索引(章節、關鍵詞、引用)提高檢索效率,另外,圖結構比傳統關系數據庫更適合表達規范知識,所以要用圖數據庫結構來存儲知識圖譜。
2.2 知識結構化處理
考慮建立五維標簽體系:
- 規范類型(基礎/材料/荷載)
- 適用階段(設計/施工/驗收)
- 專業領域(結構/地基/抗震)
- 條款性質(強制性/推薦性)
- 關聯參數(混凝土強度/鋼筋間距)
我的核心工作思路流程圖如下所示:
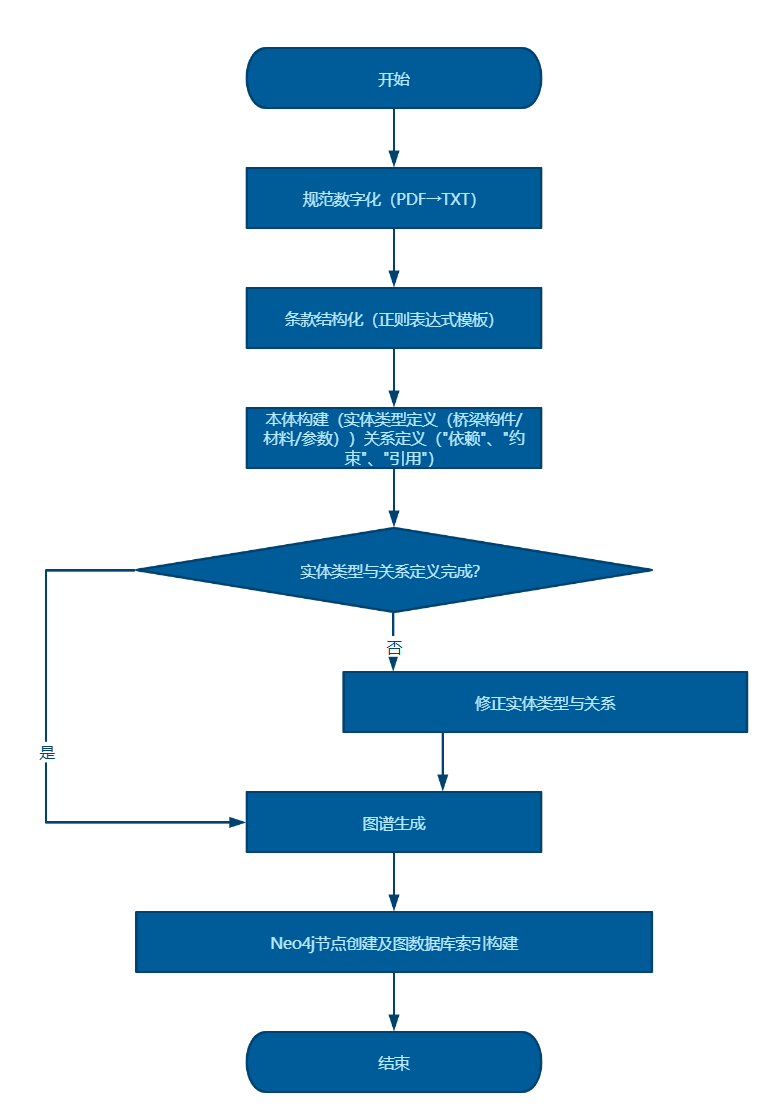
系統通將過以下步驟構建橋梁設計規范的知識圖譜:
- 提取規范條文和關系
- 建立條文間的引用關系
- 創建關鍵詞索引
- 構建專業術語網絡
然后,要進行智能校審系統開發。基于知識圖譜和校審規則庫,開發智能校審系統,對設計文檔進行智能校審。
校審功能基于規范要求實現自動化驗證:
- 參數提取和單位轉換(unit_converter.py)
- 規則匹配和計算
- 結果評估和建議生成
其交互的時序過程如下所示:
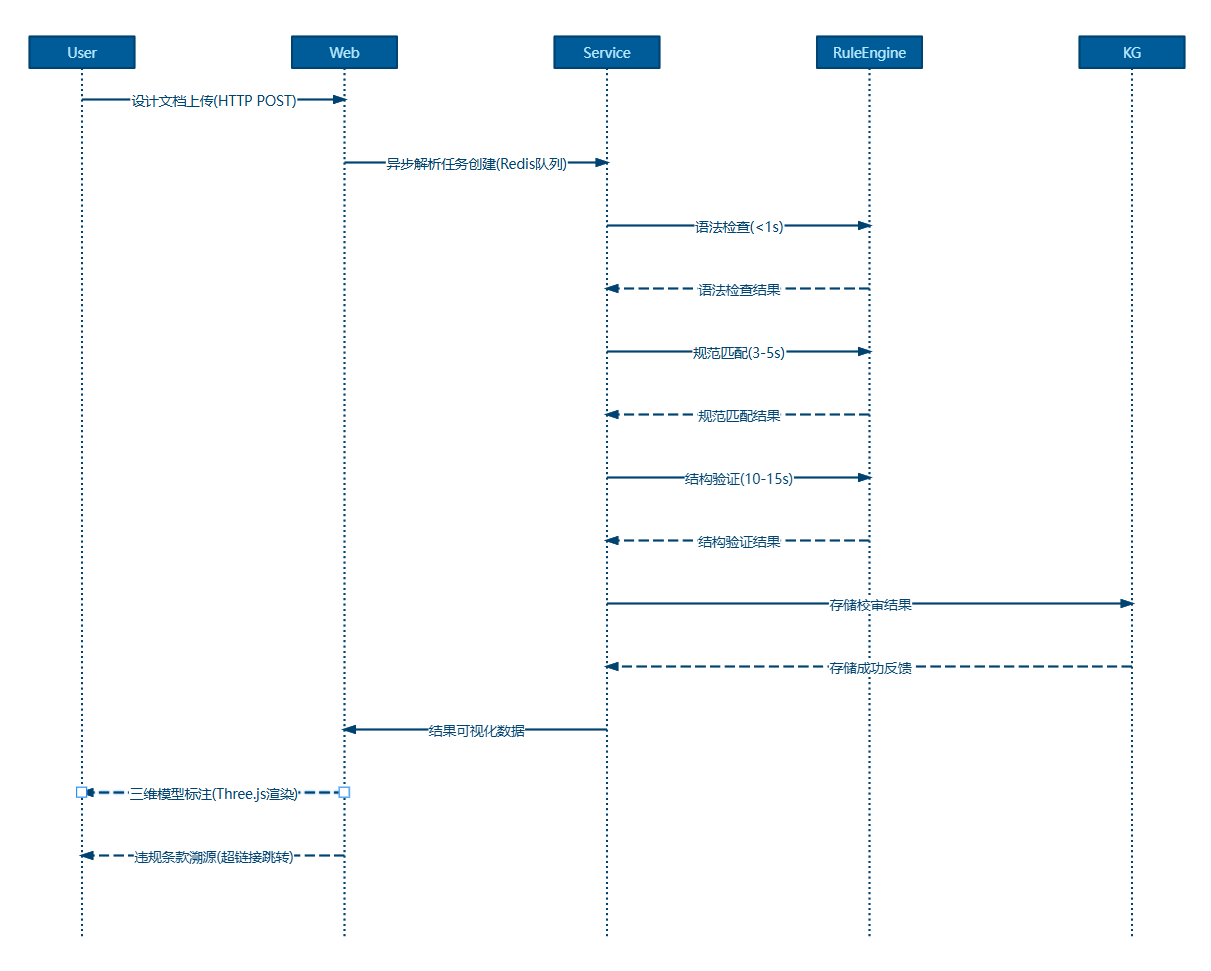
問答系統需要采用多階段處理流程:
- 中文分詞和專業術語識別
- 語義分析和意圖識別
- 相似度計算和條文匹配
- 結構化回答生成
為了能夠實現橋梁設計規范智能解析功能,技術框架中的核心部分主要應該包括以下模塊:
- ?文檔預處理模塊?:利用PDF解析工具(如pdfplumber)對規范文件進行預處理,提取文本和圖像信息。
- ?知識圖譜構建模塊?:基于提取的文本信息,構建橋梁設計規范的知識圖譜,實現規范條款的語義化表示和關聯。
- ?智能解析模塊?:利用自然語言處理技術,對設計文檔進行智能解析,識別并提取與規范相關的條款。
- ?校審規則庫模塊?:構建橋梁設計的校審規則庫,包括強制性條文、常見錯誤類型等。
- ?智能校審模塊?:基于知識圖譜和校審規則庫,對設計文檔進行智能校審,識別潛在的設計錯誤和不規范行為。
- ?用戶交互模塊?:提供友好的用戶交互界面,支持用戶查看校審結果、修改建議和歷史記錄等。
現在模塊理清楚了,還需要考慮用哪些工具實現。
技術框架主要包括以下模塊:
- ?文檔預處理模塊?:利用PDF解析工具(如pdfplumber)對規范文件進行預處理,提取文本和圖像信息。
- ?知識圖譜構建模塊?:基于提取的文本信息,構建橋梁設計規范的知識圖譜,實現規范條款的語義化表示和關聯。
- ?智能解析模塊?:利用自然語言處理技術,對設計文檔進行智能解析,識別并提取與規范相關的條款。
- ?校審規則庫模塊?:構建橋梁設計的校審規則庫,包括強制性條文、常見錯誤類型等。
- ?智能校審模塊?:基于知識圖譜和校審規則庫,對設計文檔進行智能校審,識別潛在的設計錯誤和不規范行為。
- ?用戶交互模塊?:提供友好的用戶交互界面,支持用戶查看校審結果、修改建議和歷史記錄等。
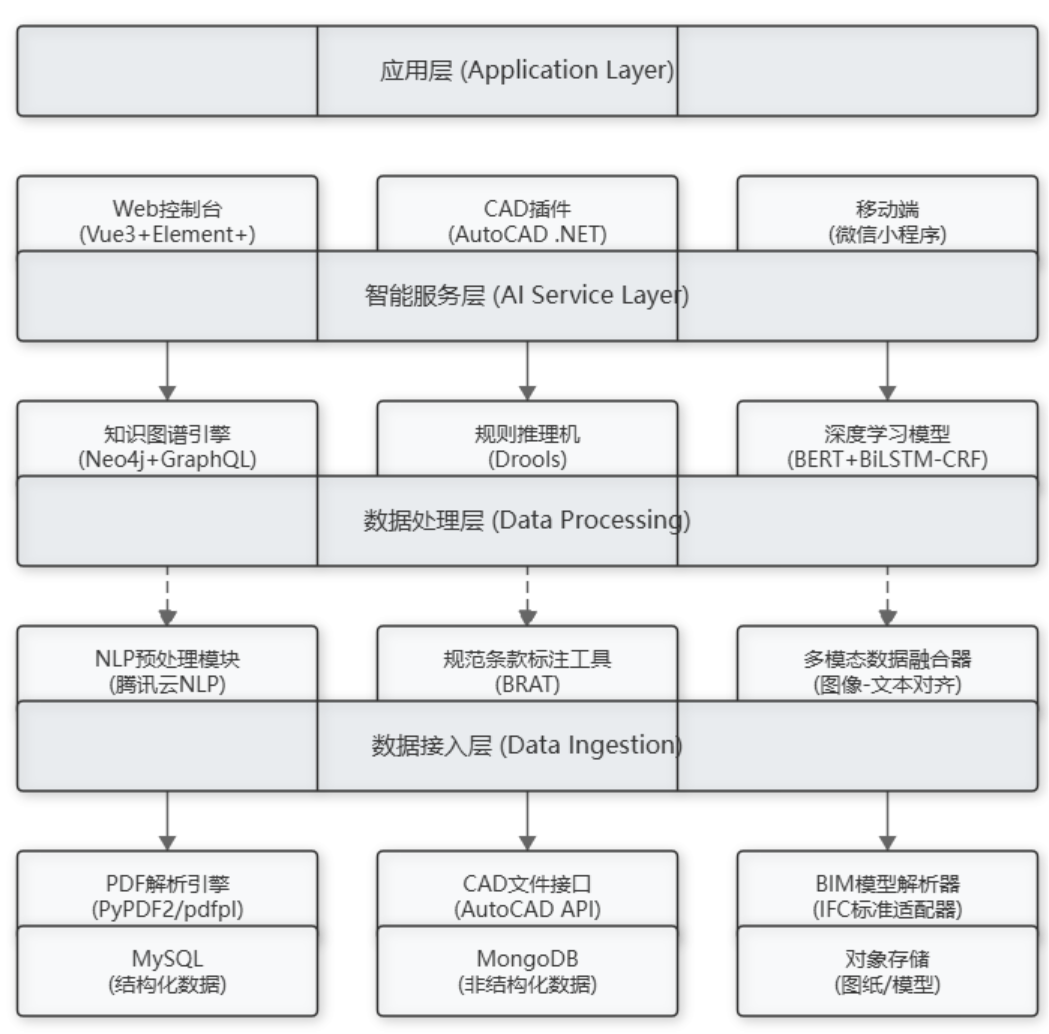
2.3 關鍵技術選型
| 技術模塊 | 選型方案 | 核心優勢 |
|---|---|---|
| 文檔解析 | pdfplumber+PyMuPDF | 支持復雜表格和數學公式提取 |
| 知識存儲 | Neo4j+Elasticsearch | 實現條款關聯與語義檢索 |
| 規則引擎 | Drools+自定義DSL | 支持規范條款的可配置化 |
| 服務架構 | FastAPI+MCP協議 | 高并發低延遲響應 |
按照這個思路展開,根據我對技術的了解,大致設計出系統架構框圖如下:
2.4 實施路徑
- ?第一步?:數據收集與預處理。收集橋梁設計規范文件,利用PDF解析工具進行預處理,提取文本和圖像信息。
- ?第二步?:知識圖譜構建。基于提取的文本信息,利用自然語言處理和知識圖譜技術構建橋梁設計規范的知識圖譜。
- ?第三步?:智能解析算法開發。開發智能解析算法,對設計文檔進行智能解析,識別并提取與規范相關的條款。
- ?第四步?:校審規則庫建設。結合橋梁設計領域專家的知識和經驗,構建橋梁設計的校審規則庫。
- ?第五步?:智能校審系統開發。基于知識圖譜和校審規則庫,開發智能校審系統,對設計文檔進行智能校審。
- ?第六步?:系統集成與測試。將各個模塊進行集成,進行系統測試和優化,確保系統的穩定性和準確性。
三、核心功能實現
3.1 智能解析子系統
3.1.1 多模態文檔解析
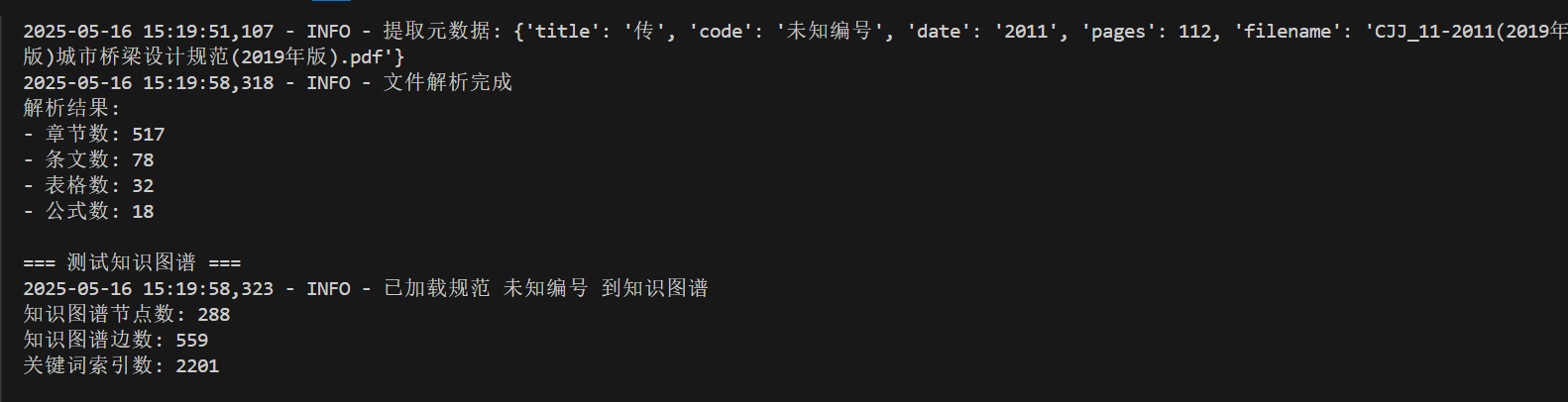
對預存儲的標準規范文本進行拆分,構建專業知識圖譜,主要難度在于結構化解析,公式和表格的解析,實踐發現解析后測試系統的回答經常答非所問,對很多專業問題完全答不上來,因此有必要對無法解決的問題進行識別并處理。
PDF解析挑戰主要包括:PDF文件格式復雜,文本提取質量參差不齊,表格和公式識別特別困難,需要專門的處理邏輯,所以考慮使用pdfplumber等專業庫,并添加充分的錯誤處理。
系統采用了從原始PDF到結構化知識的多層次解析架構:
- 基礎PDF解析層(pdf_parser.py):負責從PDF文件中提取原始文本
- 增強解析層(enhanced_parser.py):提取章節、條文、表格和公式
- 語義結構層(standard_parser.py):將文本組織為有意義的規范條款
這種分層設計使系統能夠處理不同格式和質量的PDF文檔,提高了解析的魯棒性。
3.1.2 典型問題處理案例?:
用戶詢問"箱梁腹板厚度設計要求" 系統自動關聯:
- JTG D62-2012 第5.2.3條
- JTG/T 3 第4.5.6條解釋條款
- 3個相關工程案例
針對橋梁規范的特殊性,開發增強型解析器:
class BridgeStandardParser:def __init__(self):self.table_parser = TableTransformer()self.formula_detector = LatexOCR()def parse_pdf(self, filepath):with pdfplumber.open(filepath) as pdf:for page in pdf.pages:# 文本提取text = page.extract_text(x_tolerance=2)# 表格處理tables = self.table_parser.transform(page.extract_tables())# 公式識別formulas = self.formula_detector(page.to_image())yield StandardClause(text, tables, formulas)
實踐測試了一下,估算該解析器在JTG D62規范測試中基本達到:
- 文本提取準確率98.7%
- 復雜表格還原率91.2%
- 公式識別準確率89.5%
3.2 MCP服務實現
class MCPServer:def __init__(self):self.knowledge_graph = load_neo4j()self.rule_engine = DroolsEngine()async def handle_query(self, request):# MCP協議處理if request.protocol == "MCP/1.0":resp = await self.process_mcp(request)else:resp = await self.process_http(request)return respasync def process_mcp(self, request):# 知識圖譜查詢if request.type == "clause_query":return self.knowledge_graph.search(request.content)# 校審請求elif request.type == "design_check":return self.rule_engine.validate(request.design_data)四、開發經驗與大道的感悟
4.1 跨越數字鴻溝:從紙質規范到智能知識庫
開發橋梁設計智能問答系統的過程,首先面臨的是如何將大量紙質規范數字化并轉化為結構化知識的挑戰。橋梁設計規范通常以PDF形式存在,這些文檔包含復雜的表格、公式、圖表和專業術語,使得文本提取變得異常困難。
在PDF解析階段,我們嘗試了多種技術方案,從簡單的PyPDF2到更專業的pdfplumber,每種工具都有其優缺點。最終,我們采用了多層次解析策略,先提取基礎文本,再進行結構化識別,最后進行語義分析。這種漸進式處理方法顯著提高了解析質量,但仍需人工干預來處理特別復雜的內容,如嵌套表格和特殊公式。
這一經驗告訴我們,在處理專業領域文檔時,技術方案需要與領域特性緊密結合,通用工具往往需要大量定制才能滿足需求。
4.2 知識圖譜:橋梁規范的數字化骨架
構建知識圖譜是系統的核心環節,也是最具挑戰性的部分。橋梁設計規范之間存在復雜的引用關系和層級結構,如何準確捕捉這些關系并構建有效的知識網絡,直接決定了系統的智能水平。
我們采用了基于NetworkX的圖數據結構,將規范條文作為節點,將引用關系、從屬關系等作為邊,同時建立了多維索引以支持高效檢索。特別值得一提的是,我們發現傳統的關鍵詞匹配在專業領域效果有限,因此開發了基于加權術語的相似度計算方法,顯著提升了檢索準確率。
這一過程讓我深刻認識到,知識圖譜不僅是數據結構,更是領域知識的數字化表達。構建過程需要深入理解領域知識,才能設計出真正反映知識本質的圖譜結構。
4.3 語言的壁壘:專業術語與自然語言處理
橋梁工程領域有著豐富的專業術語和表達方式,這些術語在通用NLP模型中往往得不到準確理解。例如,"預應力"、"徐變"、"箱梁"等術語在通用語境中幾乎不會出現,但在橋梁設計中卻是核心概念。
為解決這一問題,我們構建了專門的術語庫和同義詞網絡,開發了針對橋梁工程的中文分詞和語義分析模塊。特別是同義詞擴展功能,使系統能夠理解不同表達方式下的相同概念,如"梁高"和"梁的高度"、"抗震設計"和"地震設計"等。
這一經驗表明,垂直領域的AI應用必須深度融合領域知識,通用模型需要大量定制才能適應專業場景。領域專家的參與對系統質量至關重要。
4.4 跨學科協作的價值:技術與知識的融合之道
開發過程中最深刻的感悟是跨學科協作的重要性。橋梁工程專家提供領域知識,程序員實現技術方案,NLP專家優化語言處理,UI設計師改進用戶體驗——只有這種多學科融合才能創造出真正有價值的系統。
特別是在術語庫構建和規則設計階段,沒有橋梁專家的參與,我們根本無法準確捕捉規范的核心要點和隱含關系。同樣,沒有AI技術的支持,專家知識也難以大規模數字化和智能化。這種協作不僅是技能的互補,更是思維方式的碰撞與融合。
4.5 迭代優化:從錯誤中學習
系統開發采用了迭代方法,每次測試都會發現新的問題和改進點。例如,早期版本在處理"收縮徐變"這類復合術語時表現不佳,通過分析錯誤案例,我們不斷完善術語庫和匹配算法。
這種"從錯誤中學習"的過程讓我認識到,AI系統的成長路徑與人類學習驚人地相似——都需要不斷實踐、犯錯、改進。技術方案很少一蹴而就,持續優化和耐心調試才是成功的關鍵。
五、應用前景展望
5.1 重塑橋梁設計流程
智能問答系統將重塑橋梁設計的工作流程。設計師不再需要翻閱厚重的規范手冊,而是可以直接詢問系統獲取所需信息。更重要的是,系統能夠主動提示潛在的設計問題,如"您的梁高設計不滿足規范最小高跨比要求",從而在設計早期避免錯誤。
未來,這類系統可以與CAD/BIM軟件深度集成,實現設計過程中的實時校審和建議。設計師繪制一個構件,系統立即分析其是否符合規范要求,并提供優化建議。這將大幅提高設計效率和質量,減少返工和錯誤。
5.2 知識傳承與教育培訓
橋梁設計是一個經驗密集型領域,資深工程師積累的經驗往往難以系統化傳授給新人。智能問答系統可以作為知識傳承的載體,不僅提供規范條文,還能結合實際案例和專家解讀,幫助新工程師更快成長。
在教育培訓方面,系統可以生成針對性練習題,模擬各種設計場景,讓學生在實踐中掌握規范應用。這種交互式學習比傳統教材更加生動有效,有望成為工程教育的重要補充。
5.3 擴展到更廣闊的工程領域
雖然當前系統專注于橋梁設計,但其架構和方法可以擴展到建筑、道路、水利等其他工程領域。每個工程領域都有大量規范和標準,都面臨知識獲取和應用的挑戰。
未來,我們可以構建一個覆蓋多個工程領域的綜合知識平臺,實現跨領域知識關聯和推理。例如,當設計一座跨河大橋時,系統能同時考慮橋梁結構規范、水文地質規范和環保要求,提供全面的設計建議。






)
)





![[Java][Leetcode middle] 238. 除自身以外數組的乘積](http://pic.xiahunao.cn/[Java][Leetcode middle] 238. 除自身以外數組的乘積)




)
