HTTP
全稱為“超文本傳輸協議”,由名字可知,這是一個基于文本格式的協議,而TCP,UDP,以太網,IP...都是基于二進制格式的協議。
如何區別該協議是基于哪種格式的協議?
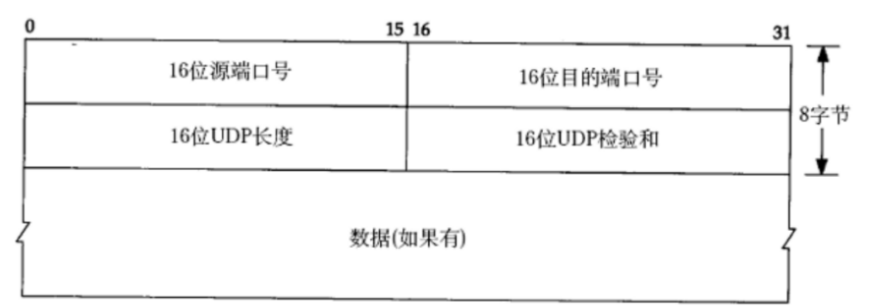
形如這種協議格式,按照xxx個字節,xxx個比特位,這樣的方式來安排的妥妥的就是二進制(不涉及任何字符)
超文本:文本包含了一些更復雜的內容,例如圖片、視頻、音頻、特殊字體、鏈接......
HTTP誕生于1991年,同時,Python,Linux,Vim,Qt(C++知名的庫)同時誕生于這一年。
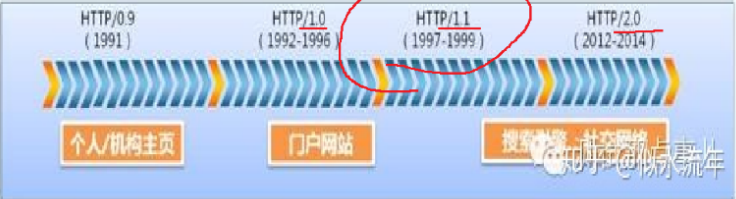
HTTP的各種版本
HTTP是應用層協議,傳輸層依賴于TCP來進行實現。(HTTP2.0及以前,是基于TCP;到了HTTP3.0,基于UDP)
因為TCP的傳輸效率更好,但是他的可靠性沒有UDP好
HTTP協議,是一個非常經典的“一問一答”模型。
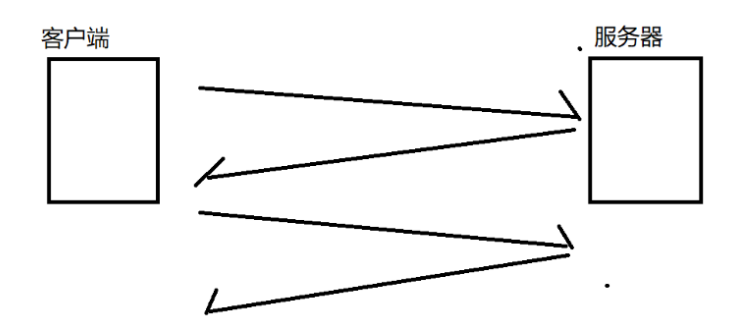
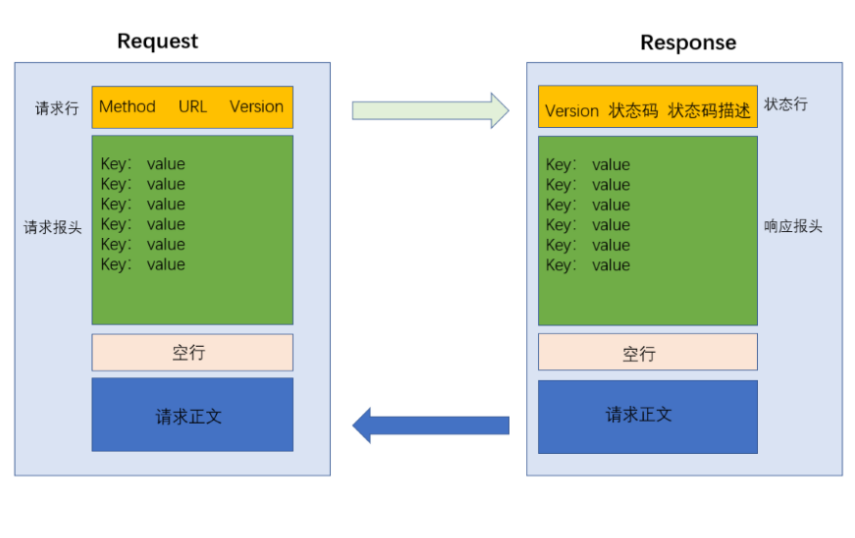
關心HTTP交互過程的時候,應該注重兩方面:一方面需要關心HTTP請求是什么樣子的,另一方面要關心HTTP響應是什么樣子的。而上述二者就構成了HTTP的協議格式。
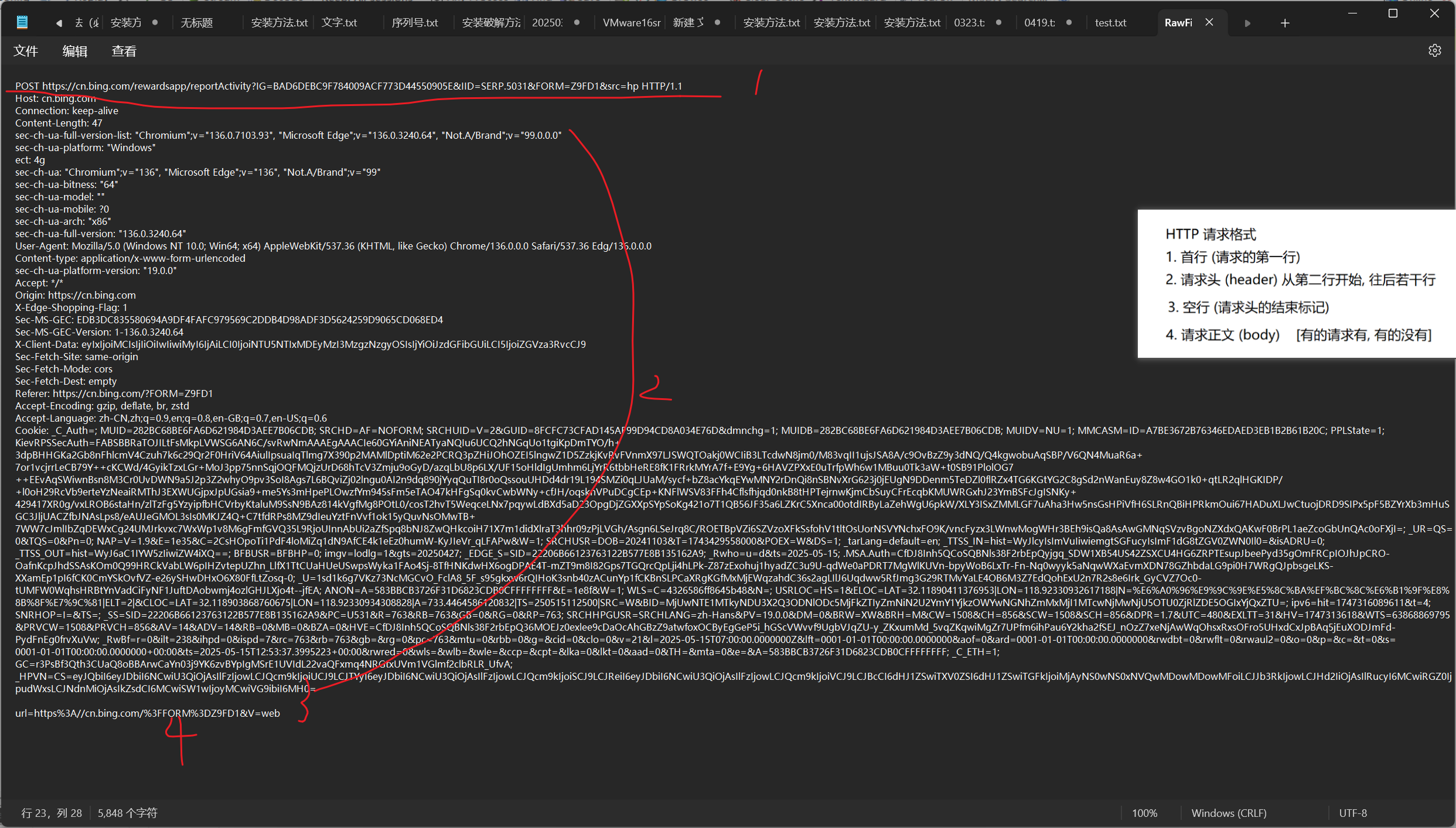
HTTP 請求格式
1. 首行 (請求的第一行)
2. 請求頭 (header) 從第二行開始, 往后若干行
3. 空行 (請求頭的結束標記)
4. 請求正文 (body) [有的請求有, 有的沒有]
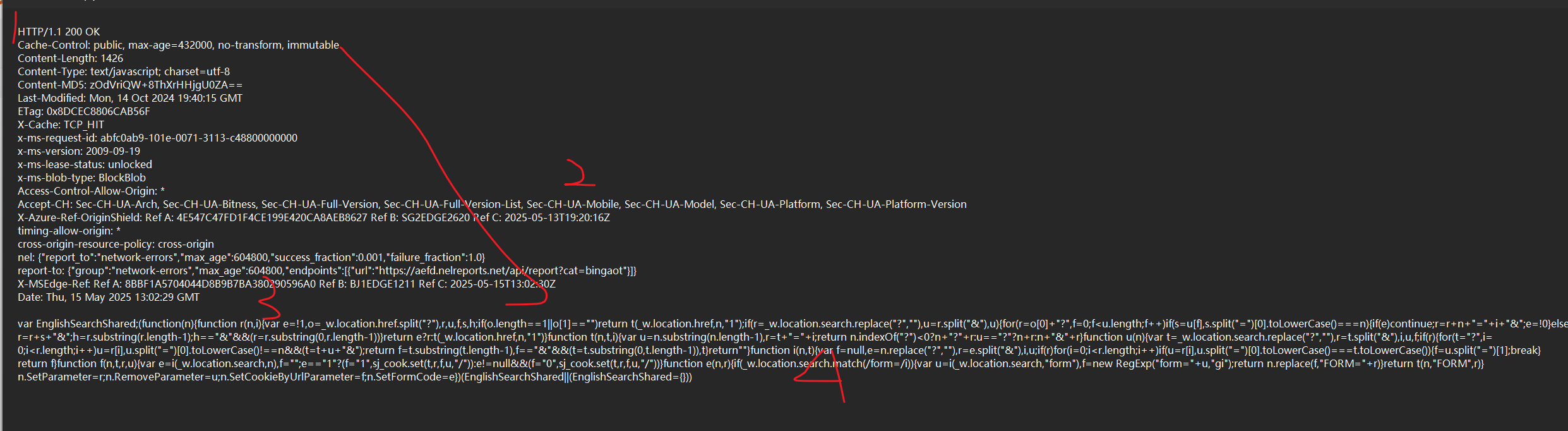
HTTP 響應,可能被壓縮的
Content-Encoding: gzip
本來是文本,壓縮了就變成二進制了。
網絡通信過程中,最貴的硬件資源,就是網絡帶寬
直接把原始數據進行傳輸,比較大,消耗的網絡帶寬就多了。
可以把數據進行壓縮,壓縮之后數據就變少了,通過網絡傳輸的內容也少了。
數據到了對端再通過 CPU 來進行解壓縮
壓縮 / 解壓縮
壓縮包 (rar, zip....) (一系列的壓縮算法)
一個不太恰當的例子
比如你的數據
aabbbccccccdddd
壓縮后
2a3b4c5d

點擊這個條條就能解壓縮
HTTP 響應格式
1. 首行
2. 響應頭 (header)
3. 空行 (響應報頭的結束標記)
4. 正文 (body)
(當前的正文部分就包含了網頁的 HTML)
URL
![]()
方法(method)? ? URL? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?版本號
URL:統一資源定位器,描述了網絡上的某個資源的具體位置,需要明確訪問網絡上的哪個資源


登錄信息(認證):淘汰了,現在已經沒有網站采取這種認證方式了。30年前,采取這樣的方式來進行身份認證。
服務器地址:服務器地址
服務器端口:服務器的端口號
帶層次的文件路徑:path,一個機器上的一個服務器程序,可能管理著很多資源,這些資源可能是真實的文件,還可能是一些“虛擬的”“動態生成的”資源(根據請求,計算出來的響應)
查詢字符串:query string。請求中的參數,通過參數進行進一步的解釋說明。是鍵值對格式,=分割鍵和值,通過&分割多個鍵值對
片段標識符:標識網頁的某個部分,實現“頁面內跳轉功能”。文檔類網站會帶有這個。
完整的 URL 包含了很多信息
重點關心的主要是 4 個部分
1) IP
2) 端口
3) 路徑
4) 查詢字符串
https://www.sogou.com/ 只有 IP 地址, 其他的好像都沒有。
https://cn.vuejs.org/guide/introduction.html#single-file-components 沒有端口, 也沒有查詢字符串
一個 URL 中, 有些部分是可以省略的
如果沒有端口號, 瀏覽器會給一個默認值
一次通信, 需要
源 IP (瀏覽器客戶端, 端口號, 系統分配的空閑端口)
源端口
目的 IP
目的端口 (URL 中的端口, 描述了你訪問的服務器的端口, 不是你瀏覽器客戶端的端口)
URL 中目的端口如果不寫, 瀏覽器會給默認值. 根據協議類型確定.
http:// => 端口給 80 (http 服務器的端口號 也是作為 "知名端口號")
https:// => 端口給 443 (https 服務器的端口號也是 "知名端口號")
帶層次的路徑也能省略, 省略之后, 其實是一個 /
表示 "根目錄"
訪問一個服務器管理資源/目錄 中的最頂層的目錄/資源
通常就對應到一個網站的主頁
query string 本來就不是必須的. 都屬于程序員自行約定的
片段標識符, 也可以省略(需要頁面內跳轉, 才設定, 不需要的話就可以省略了)
程序員代碼中自定義的(前端內容)
URL encode
https://cn.bing.com/search?q=%E5%93%94%E5%93%A9%E5%93%94%E5%93%A9&qs=n&form=QBRE&sp=-1&lq=0&pq=%E5%93%94%E5%93%A9%E5%93%94%E5%93%A9&sc=12-4&sk=&cvid=7CD8656EDA4749B08D5958CCF80B8679

url 的 query string 中的 value 部分, 可能需要進行 "轉義" 的.
query string 的內容, 程序員可以自定義 (尤其是 value)
如果 value 中包含特殊符號, 就可能使 url 的解析出現錯誤.
url 中的特殊符號有特定含義.
中文也需要轉義 (中文通過 utf8/gbk 之類的編碼格式表示的, 有可能某個漢字的
utf8/gbk 編碼中的某個字節, 恰好和某個特殊符號的 ascii 碼相同了 還是可能造成誤會)
轉義的規則非常簡單
把特殊符號的 ascii 取出來, 按照字節維度, 插入一些 %
上述 utf8 的編碼解碼 過程不需要手動實現
都有專門的庫來進行
如果需要放中文/符號, 需要主動進行 url encode
否則, 瀏覽器/服務器可能解析失敗








)



:常見 緩存數據淘汰算法/緩存清空策略)

)




