目錄
1 什么是MapReduce?
2 MapReduce的核心特點
2.1 分布式處理
2.2 容錯機制
3 MapReduce的完整工作流程
4 MapReduce的優缺點分析
4.1 優勢
4.2 局限性
5 MapReduce典型應用場景
5.1 適用場景
5.2 不適用場景
6 MapReduce與其他技術的對比
7 總結
1 什么是MapReduce?
MapReduce是一種用于大規模數據集(大于1TB)并行運算的編程模型,由Google在2004年提出,主要用于解決海量數據的分布式計算問題。它將復雜的、運行于大規模集群上的并行計算過程高度抽象為兩個函數:Map和Reduce。

- 輸入數據:原始數據被分割成多個小塊
- Map階段:并行處理輸入數據塊,生成中間鍵值對
- Shuffle階段:將相同key的中間結果傳輸到同一個Reducer
- Reduce階段:對相同key的值進行歸約處理
- 輸出結果:生成最終計算結果
2 MapReduce的核心特點
2.1 分布式處理
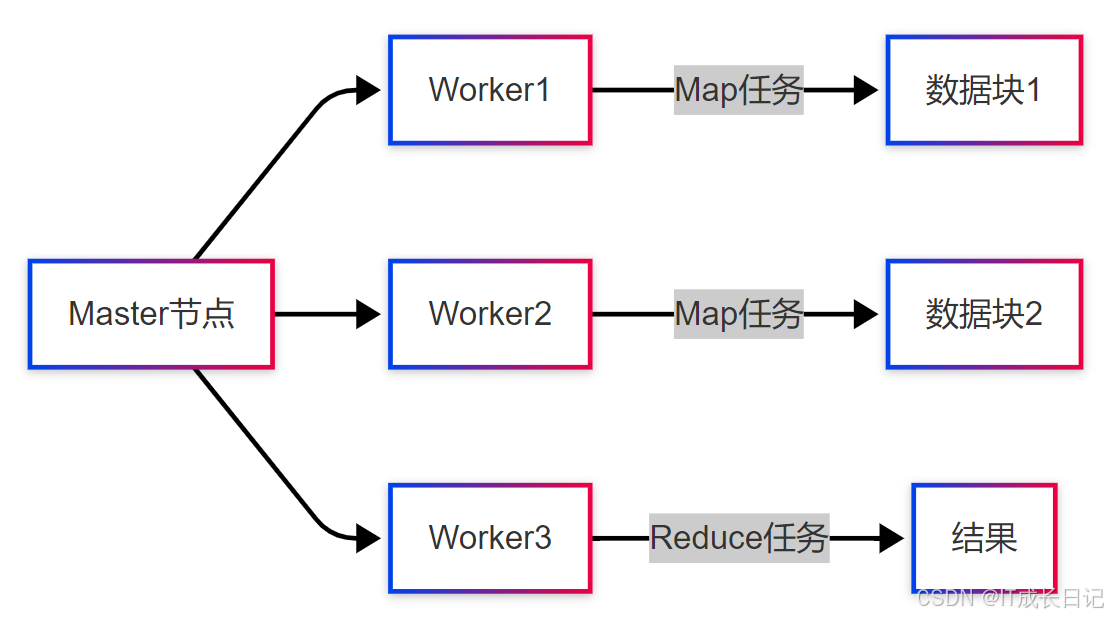
- 主從架構:1個Master節點管理多個Worker節點
- 數據本地化:計算向數據移動,而非數據向計算移動
- 自動并行化:框架自動處理并行執行和任務調度
2.2 容錯機制

- 任務失敗自動重新調度
- 定期心跳檢測Worker節點狀態
- 數據多副本存儲保證可靠性
3 MapReduce的完整工作流程
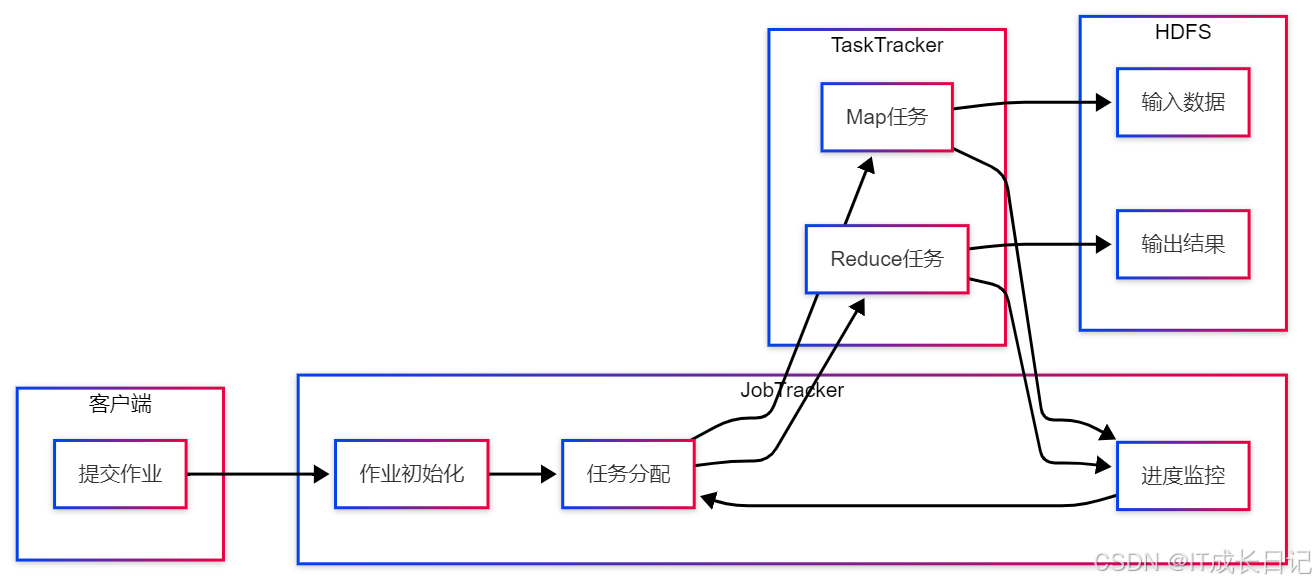
- 作業提交:客戶端提交MapReduce作業
- 作業初始化:JobTracker創建作業并分配ID
- 輸入分片:計算輸入數據的劃分方式
- 任務分配:將Map和Reduce任務分配給空閑TaskTracker
- 執行Map階段:TaskTracker執行Map任務,讀取輸入數據
- Shuffle階段:Map輸出經過排序、合并后傳輸給Reducer
- 執行Reduce階段:處理中間結果,生成最終輸出
- 作業完成:JobTracker收到所有任務完成通知后標記作業成功
4 MapReduce的優缺點分析
4.1 優勢
| 優點 | 說明 |
| 易于編程 | 只需關注業務邏輯,無需處理并行細節 |
| 良好擴展性 | 可線性擴展到數千節點 |
| 高容錯性 | 自動處理節點失敗 |
| 高吞吐量 | 適合批處理海量數據 |
4.2 局限性
- 不適合低延遲場景:批處理模型導致較高延遲
- 中間結果寫磁盤:Shuffle階段產生大量I/O開銷
- 表達能力有限:復雜算法難以用MapReduce表達
- 資源利用率低:Map和Reduce階段資源無法動態調整
5 MapReduce典型應用場景
5.1 適用場景
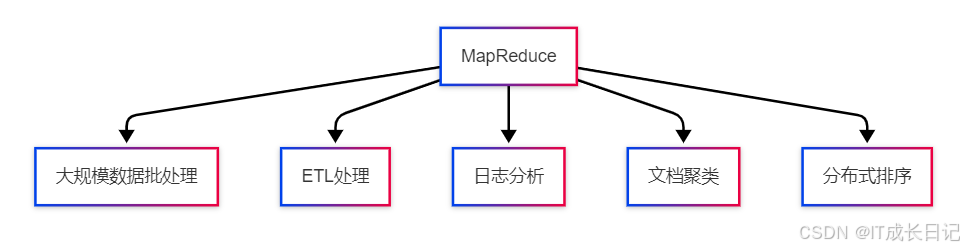
- 海量數據批處理:如網站日志分析、數據倉庫ETL
- 分布式排序:如搜索引擎倒排索引構建
- 機器學習:如PageRank算法實現
- 數據挖掘:如關聯規則挖掘
5.2 不適用場景
- 實時計算(考慮Storm/Flink)
- 迭代計算(考慮Spark)
- 流式計算(考慮Spark Streaming/Flink)
- 交互式查詢(考慮Hive/Impala)
6 MapReduce與其他技術的對比
| 技術 | 處理模型 | 延遲 | 適用場景 |
| MapReduce | 批處理 | 高 | 離線大規模數據處理 |
| Spark | 微批/內存計算 | 中 | 迭代計算、機器學習 |
| Flink | 流處理 | 低 | 實時計算、事件驅動 |
| Storm | 流處理 | 極低 | 實時消息處理 |
7 總結
MapReduce作為大數據處理的基石技術,雖然在某些場景下已被更先進的計算框架取代,但其設計思想和編程模型仍然深刻影響著大數據生態系統。理解MapReduce的原理和特點,對于學習后續的大數據技術如Spark、Flink等具有重要意義。


![[Spring]-組件的生命周期](http://pic.xiahunao.cn/[Spring]-組件的生命周期)












 的主要區別是什么?)



